Dataverse: Add schema.org markup to Dataset pages
This would make it easier for search engines to parse information about the title, author, timeperiod etc.
Relevant types to do markup for:
http://schema.org/Dataset and http://schema.org/DataCatalog
Validation and testing of markup can be done on this page:
https://developers.google.com/structured-data/testing-tool/
The markup can be done directly in the html template.
 borsna
borsna
All 60 comments
Related to: https://github.com/IQSS/dataverse/issues/1393
 posixeleni
on 5 Jun 2015
posixeleni
on 5 Jun 2015
I don't know whether having this, or using the meta tags as in #1393 would have a greater impact. In theory this isn't a big task and it is invisible to users in the browser (unless some browser plugin detects the markup and acts on it, of course).
In terms of semantics: this is one vocabulary for expressing metadata. For the citation metadata (block), the fields map very well to either Schema.org or DC Terms/Elements. This mapping would be implicit business logic if you were to just go ahead and make changes to the UI without making the connection between metadata fields in Dataverse and ontology properties like the ones in DC Terms. The idea I'm trying to get at is similar to what I mentioned in comments on #947, but for the field names instead of field values.
Let me create a new issue for this. I can't believe I didn't do so yet :)
 bencomp
on 15 Jul 2015
bencomp
on 15 Jul 2015
@bencomp I think both and tagging in the markup should be implemented.
If more portals provides this kind of tagging search engines will do a better job in finding public dataset using schema.org tagging, its already widely used for events, movies etc.
ICPSR and other data archives are already doing it the markup for the basic sets of fields .
Test this url in the validator: http://www.icpsr.umich.edu/icpsrweb/ICPSR/studies/36057
If i understand your comment the idea is to provide a mapping for custom fields added to a dataset?
borsna
on 15 Jul 2015
Just came across this article about SEO for libraries, including adding Schema.org to pages: https://journal.lib.uoguelph.ca/index.php/perj/article/view/3328/0
@borsna the ideas outlined in #2357 concern "custom" fields added to a installation of Dataverse - I'm actually not sure you can add fields to a single dataset only. These Dataverse-wide fields actually come from existing ontologies, like DDI and ISA-Tab, but the only way to read the definitions of the fields is to parse the text files in the source code.
bencomp
on 15 Jul 2015
Interesting article, thanks for the link :)
@bencomp okay, was not thinking about unique custom fields for a single dataset, rather configured fields for a dataverse installation or similar.
borsna
on 16 Jul 2015
@borsna #2717 is related and there's been some discussion there in the past week or two.
 pdurbin
on 5 Nov 2016
pdurbin
on 5 Nov 2016
This was posted two days ago: https://research.googleblog.com/2017/01/facilitating-discovery-of-public.html . Thanks for pointing it out, @eugene-barsky
pdurbin
on 26 Jan 2017
Related to @pdurbin 's previous comment: Google has recently published new guidelines for describing scientific datasets using Schema.org vocabulary: https://developers.google.com/search/docs/data-types/datasets
These guidelines refer to Schema.org's list of markup properties related to datasets: http://schema.org/Dataset
Schema.org represents a collaboration between all major search engine companies (Google, Microsoft, Yahoo, and Yandex) and has been developed to support each of these search engines. As such, marking up dataset pages using Google's recommended Schema.org metadata fields would likely improve each of these search engines' ability to display relevant results from Dataverse. It would also likely increase the pagerank of our dataset pages, meaning Dataverse datasets would appear more frequently and more visibly in search results. This would help our datasets be more discoverable to the public.
Libraries and data repositories frequently make use of Schema.org markup for these reasons. Viewing the page source of a Mendeley Data dataset page provides a solid example of how Schema.org markup can be implemented by a data repository.
It's also worth noting that Schema.org can incorporate Dublin Core (AKA DC) terms by using a "dc" prefix, though this does not conform to Google's recommendations for marking up datasets.
 dlmurphy
on 2 Feb 2017
dlmurphy
on 2 Feb 2017
This is also one of the 11 recommendations made in A Data Citation Roadmap for Scholarly Data Repositories (https://doi.org/10.1101/097196).
I started mapping the Schema.org elements Google recommends to elements in Dataverse's citation metadata block. (Each tab on that spreadsheet is a different metadata block.)
We can also expose file and variable level metadata with Schema.org. I'm thinking those mappings (when Schema.org terms exist for it) can be recorded in that spreadsheet's other tabs and possibly here, where ingested tabular file metadata is listed and mapped to other standards. I'm not sure how accurate this last spreadsheet is.
 jggautier
on 23 Feb 2017
jggautier
on 23 Feb 2017
Right now Google's recommended Schema.org properties don't include dataset persistent IDs, but persistent IDs should be embedded in dataset landing pages in json-ld as well.
jggautier
on 13 Mar 2017
persistent IDs should be embedded in dataset landing pages in json-ld as well
@jggautier (and others) you might be interested in @csarven saying, "Virtually nothing in particular is consuming granular citations in Linked Data." More at https://gitter.im/linkedresearch/chat?at=58f5f3acad849bcf42962e56
pdurbin
on 18 Apr 2017
Interesting conversation. Thanks @pdurbin!
jggautier
on 20 Apr 2017
@borsna heads up that #1393 is shipping with Dataverse 4.7.
Are you or others still interested in this schema.org feature?
pdurbin
on 23 Jun 2017
Related: #3700
pdurbin
on 25 Jun 2017
3793 is highly related. I'm not sure what the difference is.
pdurbin
on 31 Oct 2017
If its easier to add the metadata as json-ld in the head it will do the same thing :)
borsna
on 31 Oct 2017
Working on a bare-bones Schema.org template for datasets using Schema.org's schema for datasets (https://schema.org/Dataset) and Google's structured data tool (https://search.google.com/structured-data/testing-tool/u/0/?authuser=0)
Draft Schema.org template for datasets:
{
"@context": "http://schema.org",
"@type": "Dataset",
"@id": "{PID in https form}",
"name": "{Dataset title}",
"author": {
"name": "{Author name}"
},
"dateModified": "{date of latest published version}",
"schemaVersion": "https://schema.org/version/3.3",
"publisher": {
"@type": "Organization",
"name": "{Name of installation}"
},
"provider": {
"@type": "Organization",
"name": "Dataverse"
}
}
Just some notes: DataCite's Schema.org/JSON-LD export is somehow figuring out if the value in the author name is a person or not (some kind of text parsing?), and using the person author type if it's a person. DataCite.search has been slow and timing out these past couple of weeks, so it's hard to test how well it's doing this.
@pdurbin Under "author", I removed the lines with @type, and first and last name. This makes the @type default to "Thing", which isn't a type the schema expects for "author", but Google's structured data tool doesn't report any errors.
jggautier
on 1 Nov 2017
I just made pull request #4252 and am moving this to Code Review at https://waffle.io/IQSS/dataverse
pdurbin
on 1 Nov 2017
Moved this back to develop after @pdurbin and I agreed that the code shouldn't try to guess if the author is a person or organization.
jggautier
on 1 Nov 2017
About "datePublished": "{Publication Date}":
It should match the date used in the dc.date field of the dataset metatags (#1393), which is "the date when the dataset's last version was published."
jggautier
on 2 Nov 2017
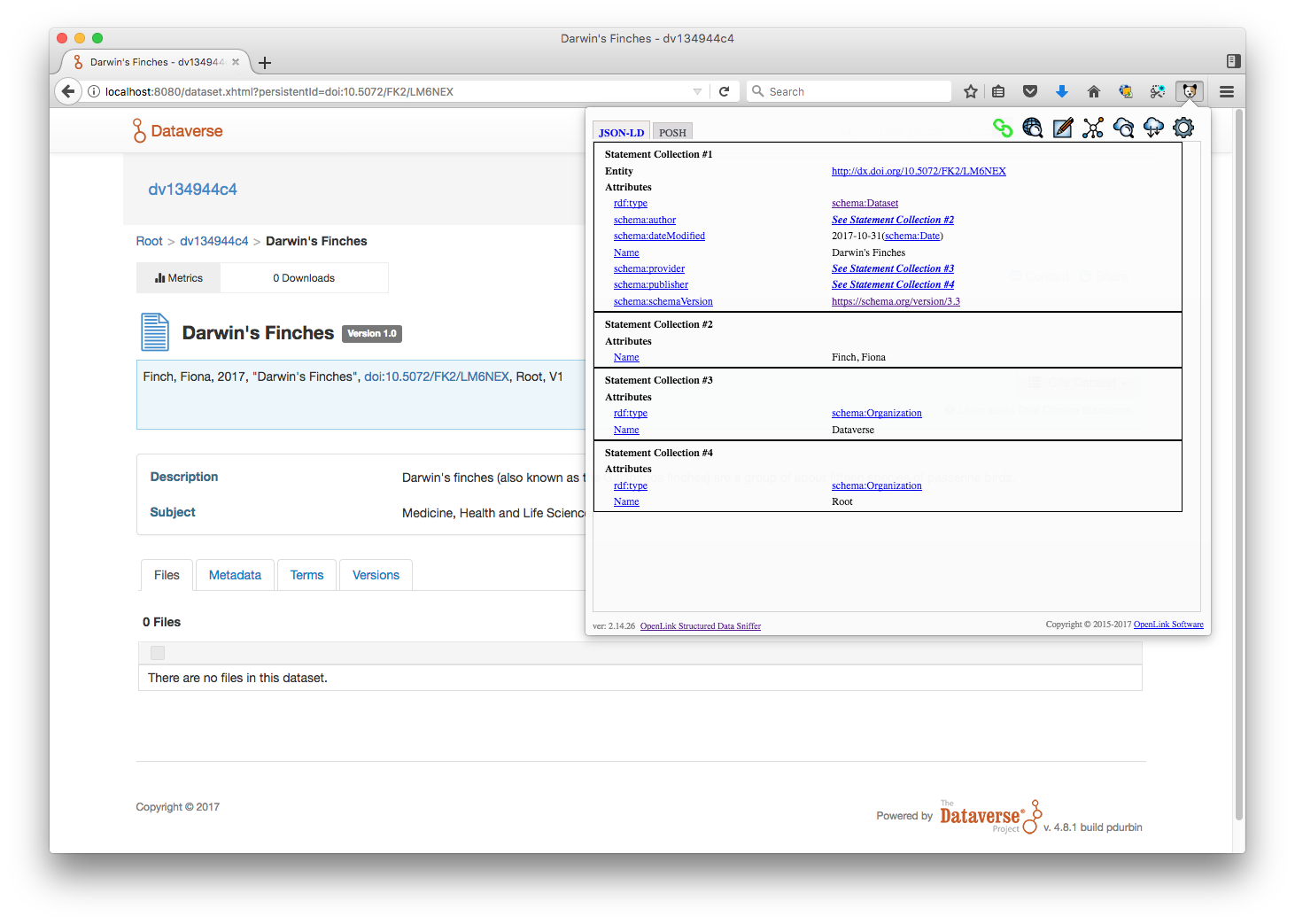
I made changes the @scolapasta and @jggautier requested. Moving to Code Review.
pdurbin
on 2 Nov 2017
I'm working on the changes requested by @scolapasta at https://github.com/IQSS/dataverse/pull/4252#pullrequestreview-73937896
pdurbin
on 3 Nov 2017
I made all the changes @scolapasta requested and added some tests. @scolapasta I'm assigning this back to you to move this to QA if you're happy.
In b1db8ee I also added a note about why we're using "dateModified" rather than "datePublished". After looking at the definitions at https://schema.org/version/3.3 I see why @jggautier asked for this change.
pdurbin
on 3 Nov 2017
@scolapasta and @jggautier want to add some more fields so I'm assigning this to @jggautier to leave a comment and moving it back to Development.
pdurbin
on 3 Nov 2017
Thanks Phil. @scolapasta encouraged me to list the fields that we want to add (as opposed to the minimum that have been added). Then we would decide if the effort and time it takes to add more fields is justified by the benefits, otherwise we'll consider those fields in other github issues.
Additional fields (I've included the fields that schema.org has properties for, what Google recommends, and what other repositories are using (e.g. ICPSR, Mendeley Data and PANGAEA) that I think would add the most discoverability and reusability):
- dataset description - use schema.org's "description" property
- date published - use "datePublished"
- subject - use "keyword", see json example below for how it should be concatenated
- keywords - use "keyword", see json example below for how it should be concatenated
- topic classification - use "keyword", see json example below for how it should be concatenated
- major version number - use "version"
- dataset citation - use "citation"
- contributorName when contributorType = Funder - use "funder"
- grantNumberAgency - use "funder"
- geographicCoverage - use spatialCoverage (concatenating City, State/Province, Country/Nation, and Other, separated with a comma and a space)
- timePeriodCovered - use temporalCoverage (concatenating Start and End dates, separated with a backslash)
What's excluded:
- License - important, but I excluded it because schema.org recommends including a URL to the license, and all repositories I've seen using schema.org use a URL, which is easy if the Dataverse dataset is CC0 (https://creativecommons.org/publicdomain/zero/1.0/), but not for datasets that don't have CC0.
- Author identifiers - important, but it seems best practice right now to use the URL of the identifier, e.g. https://orcid.org/0000-0000-0000-0000, and I'm not sure if it's easy to get URLs of the different identifiers (ORCID, ISNI, LCNA) out of Dataverse.
- Geographic Bounding Box - Need to do some more thinking about how to include this info
I've included an example below with these additions:
{
"@context": "http://schema.org",
"@type": "Dataset",
"@id": "{PID in https form}",
"name": "{Dataset title}",
"author": [
{
"name": "{authorName 1}"
},
{
"name": "{Author name 2}"
}
],
"datePublished": "{date of publication}",
"dateModified": "{date of latest published version}",
"version": "{major version number of dataset}",
"keywords": [
"{datasetsubject1}",
"{datasetsubject2}",
"{datasetsubject3}",
"{datasetkeyword1}",
"{datasetkeyword2}",
"{datasetkeyword3}",
"{datasettopicclassification1}",
"{datasettopicclassification2}",
"{datasettopicclassification3}"
],
"citation": {
"@type": "Dataset",
"text": "{dataset citation}"
},
"temporalCoverage": [
"2002/2005",
"2001-10-01/2015-11-15"
],
"spatialCoverage": [
"El Tuma La Dalia, Matagalpa, Nicaragua",
"Boston, Massachusetts"
],
"funder": [
{
"@type": "Organization",
"name": "{contributorName when contributorType = Funder}"
},
{
"@type": "Organization",
"name": "{grantNumberAgency}"
}
],
"schemaVersion": "https://schema.org/version/3.3",
"publisher": {
"@type": "Organization",
"name": "{Name of installation}"
},
"license": {
"@type": "Dataset",
"text": "CC0",
"url": "https://creativecommons.org/publicdomain/zero/1.0/"
},
"provider": {
"@type": "Organization",
"name": "Dataverse"
}
}
I only had a couple of hours to work on this yesterday, so I addressed the simpler things from @jggautier's wish list:
- added "datePublished"
- added "version"
- added "citation"
- added "temporalCoverage"
left the following, trickier parts of the wish list as TODOs in the code:
- "subject" (needs to be populated with an aggregate of several metadata fields
- "funder"
- "spatialCoverage"
Also, please note that the last comment specifies that the license should be excluded, but the provided example does have the "license" entry. I assumed that it should be excluded.
 landreev
on 7 Nov 2017
landreev
on 7 Nov 2017
Thanks @landreev.
Would it be simpler to include only the dataset subject in schema.org's "keyword" property, excluding the keywords and topic classifications for now? This is what we did for Dublin Core metadata in dataset html metatags.
Yes, I forgot to remove license from that json example, and it should also be thought about for another issue. Thanks for catching that.
I'm okay with funder and spatialCoverage being worked on in another issue.
Hoping to hear from @scolapasta.
jggautier
on 7 Nov 2017
@jggautier as part of this pull request we removed the DatasetPage.publicationDate method and consolidate the logic for "DC.date" (DC Terms) and dateModified (schema.org) into a new centralized getPublicationDateAsString method. By the same logic, maybe it makes sense to remove the DatasetPage.datasetSubjects method (highlighted in blue below) and consolidate the logic into a centralized method:
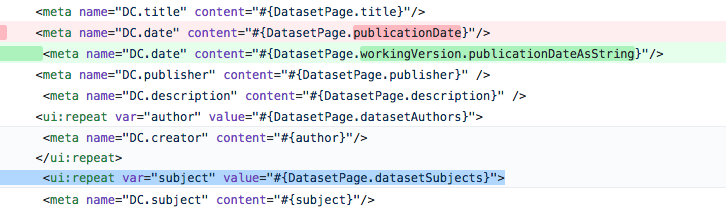
pdurbin
on 7 Nov 2017
Would it be simpler to include only the dataset subject in schema.org's "keyword" property, excluding the keywords and topic classifications for now? This is what we did for Dublin Core metadata in dataset html metatags.
In 7d03e70 I implemented this. For consistency, DC.subject and JSON-LD's keywords (just added) now call into the same getDatasetSubjects() method.
It sounds like the rest of the items are "nice to have" so I'm moving this into code review.
pdurbin
on 7 Nov 2017
Thanks @pdurbin.
I've been emailing Natasha from Google, who gave that talk about schema.org for datasets. Working on adding her recommendations (with Gustavo's and Pete's help). Will update issue later today or first thing tomorrow.
jggautier
on 8 Nov 2017
@pdurbin @jggautier Can I suggest that the mapping schema.org "keyword" to the Dataverse dataset "subject" here, as it is used in Dataverse, is not particularly informative. As the Dataverse subject field only allows the default 14 subjects, there are limitations on the subject in describing and distinguishing the contents of a dataset. I think what may be more useful is the Dataverse "Keyword" field.
For example, virtually all datasets in the ADA collection will have the "Social Sciences" subject - so it doesn't help users to differentiate between content in our collection at all. Other dataverses are similarly dominated by the Social Sciences subject - the Odum dataverse has 280 of ~4,000 datasets with Social Sciences (and Medical with ~230), while the Dataverse.nl dataverse has 137 of 488 datasets with the subject Social Science (next is Medical et al with 25).
There are limitations to Keyword as well - these are often not drawn from a controlled vocabulary, nor are Keyword terms consistently applied. Keyword and Subject are often also used interchangeably.
There is some history to this - see the Acknowledgement at the end of the schema.org Dataset description (http://schema.org/Dataset):
"This class is based upon W3C DCAT work, and benefits from collaboration around the DCAT, ADMS and VoID vocabularies. See http://www.w3.org/wiki/WebSchemas/Datasets for full details and mappings."
The VoID vocabulary (https://www.w3.org/TR/void/#subject) includes a discussion of what should be included as a "subject", while the DCAT "dataset" includes a "keyword" (https://dvcs.w3.org/hg/gld/raw-file/default/dcat/index.html#Property:dataset_keyword), and Dublin Core includes DC:subject (http://purl.org/dc/elements/1.1/subject).
I think the most useful discussion on this from the above is the VoID proposal:
https://www.w3.org/TR/void/#subject
They start with asking a question: "When someone wants to select a dataset, one of the fundamental questions is, what does the dataset actually offer?" My concern is that I'm not sure that describing something as "Social Science" (which is what mapping schema.org/keyword to dataverse/subject will do) will really help the user much.
Unfortunately I don't have a better approach for you on this - just highlighting the limitations of the Dataverse Subject field in this area.
 stevenmce
on 8 Nov 2017
stevenmce
on 8 Nov 2017
@stevenmce thanks for your comment. I can revert 7d03e70 if that's best.
pdurbin
on 8 Nov 2017
@pdurbin - I don't know if it's worth reverting your commit; (but it could be argued that having these subjects in the "keywords" entry is better than nothing...)
To me it sounds like @jggautier's original idea, of populating the "keywords" block with the Subject, Keyword and TopicClassification metadata field values, is still the right way to go about it. It shouldn't be hard to do; I just didn't have time to go through it all yesterday, as I had to go back to working on something else.
(to confirm though, is it definitely true, that our Subjects can only contain the values from the 14 controlled vocabulary elements? didn't we have a provision for being able to add custom subjects? - I may be totally off on this...)
landreev
on 8 Nov 2017
is it definitely true, that our Subjects can only contain the values from the 14 controlled vocabulary elements?
It's true. I forget how many there are but they're hard coded. There was an effort within the past year to answer "What's in this thing?" with regard to a Dataverse installation, but I'm not sure about the current status. I think this is/was the card that was tracking this: https://trello.com/c/x10i7aaB/2-harvard-dataverse-hmpg-47
pdurbin
on 8 Nov 2017
@stevenmce thanks a lot for the resources you linked to and the excellent summary of what I see as other improvements that have to be made so that there's more value in exporting metadata in schema.org (and other standards), e.g. support for controlled vocabs; encouraging, and making it easier for depositors and curators to maintain, consistency. I think these goals are represented in several github issues.
I agree about the limits of using only the 14 subjects terms, and that using keywords would be even more helpful for the schema.org "keywords" field. The idea was to map Dataverse "subjects" first, and add keywords and topic classifications later (which I think is also the plan for dc.subject in the dataset metatags).
For consistency, DC.subject and JSON-LD's keywords (just added) now call into the same getDatasetSubjects() method.
I'd like to defer to others about the best methods for mapping Dataverse metadata to the dc.subject and schema.org keyword fields. But I think we do, eventually, want to add keywords and topic classifications to those fields.
@pameyer noticed that we (and other repos) are using schema.org's citation property incorrectly (and that there isn't much value in this mapping anyway). So we should remove our mapping of dataset citation to schema.org's citation field.
Natasha Noy from Google recommended we use the "identifier" property. So we should change "@id" to "identifier":
"identifier": "{PID in https form}" instead of "@id": "{PID in https form}"
I just emailed Natasha about other recommendations for "adding information on who provided/created the dataset" and adding terms metadata that isn't a URL. I recommended we map Dataverse's producerName to schema.org's producer, and that we map Terms of Use to schema.org's license when CC0 is waived. Waiting to hear back.
jggautier
on 8 Nov 2017
Update: Getting clarification from Natasha from Google about adding information on who provided/created the dataset. Hope to update very soon on this point soon.
The fields in the table below are unambiguous, can be added; many have already been included in the code. Below the table are fields to remove/replace based on discussion with Natasha and @pameyer, and below that are fields we're thinking of adding later.
Example json is in this Google doc. (The structured data testing tool reports a warning regarding authorAffiliation. We're ignoring that error for now.)
Fields to include for this issue:
Dataverse metadata | Scheme.org property | Notes
-- | -- | --
Dataset Persistent ID | identifier | in https form: http://dx.doi.org/10.7910/DVN/00000 instead of doi:10.7910/DVN/00000
title | name |
authorName | name (subtype of author) |
authorAffiliation | affiliation (subtype of author) |
dsDescriptionValue | description |
Publication Date | datePublished |
Version Date | dateModified |
major version number | version |
subject | keyword |
keywordValue | keyword |
topicClassValue | keyword |
timePeriodCovered | temporalCoverage | concatenating Start and End dates, separated with a backslash
publicationCitation | citation |
CC0 or "Terms of Use" | license | if CC0: "https://creativecommons.org/publicdomain/zero/1.0/"; if CC0 waived, use text of Terms of Use
Name of software producing the metadata | provider| Dataverse
Name of installation | includedInDataCatalog | Ex. Harvard Dataverse
What should be removed:
- "@id" (replaced with identifier)
- "publisher" (replaced with includedInDataCatalog)
What's excluded now/being punted for another issue:
- Author identifiers: Seems best practice right now to use the URL of the identifier, e.g. https://orcid.org/0000-0000-0000-0000, and I'm not sure if it's easy to get URLs of the different identifiers (ORCID, ISNI, LCNA) out of Dataverse.
- contributorName (when contributorType = Funder) mapped to funder
- grantNumberAgency mapped to funder
- geographicCoverage mapped to spatialCoverage (concatenating City, State/Province, Country/Nation, and Other, separated with a comma and a space)
- Geographic Bounding Box mapped to spatialCoverage
jggautier
on 9 Nov 2017
Incorporated recent feedback back from Natasha. We're unblocked and I'm done with the issue for now, unassigning myself. The metadata mapping in the comment above should be set and the example json is up to date.
The schema.org json that Dataverse produces and puts in the html headers of published datasets should pass Google's structured data testing tool, with only warnings regarding the authorAffiliation property ("The property affiliation is not recognized by Google for an object of type Thing."), which we're ignoring for now.
jggautier
on 14 Nov 2017
Over in ad71c6a and 7d03e70 I was attempting to keep fields like "DC.date" and "DC.subject" (HTML head meta tags) consistent with what we are now implementing for JSON-LD. A single code path and a consistent user experience. @pameyer has mentioned that in his fork of Dataverse, he hides "DC.subject" because it's meaningless for him since every single one of his datasets have a subject of "Medicine, Health and Life Sciences". Knowing this, in his original implementation, he didn't even implement the "DC.subject" meta tag. (Another developer worked on it later.) The new JSON-LD "keywords" has some richness and diversity that we should probably include in the "DC.date" meta tag some day, if for not other reason than consistency.
pdurbin
on 16 Nov 2017
@pdurbin - slight correction; haven't taken any efforts to hide it in meta tags
 pameyer
on 16 Nov 2017
pameyer
on 16 Nov 2017
Just my 2 cents - I feel the way to phrase the question is "would it be more useful to populate our DC.subject the same way as the LD JSON "keyword" in this branch - with the combination of all 3: our "subject", "keyword" and "topicclassification"? can it possibly hurt anyone if we do that?" - If the answers are "yes" and "no", somebody with stronger feelings on the issue should volunteer to quickly implement it; the code change would be straightforward.
But I do want to say that I don't think the "consistency" is an obvious argument necessarily. I know the way this was discussed with the google person, it was pretty specific to how they understand what "keyword" means in their schema, what they do with that metadata, etc. I don't think this should automatically translate into what we put into other formats...
landreev
on 16 Nov 2017
The part about every dataset in the dataverse being "social science" or "health care" - isn't it still useful, in the context of global crawling and indexing? Even if it's not specific/granular enough, it's still useful knowledge, that your research is in health care, and not in astronomy or bacon science - no?
landreev
on 16 Nov 2017
Mmm. Bacon science. :bacon: :bacon: :bacon: . Good points, @landreev . I don't feel strongly about all this to open an issue but if someone out there does, they should.
Apologies, @pameyer . I must be thinking about something else in your fork that you mentioned.
pdurbin
on 16 Nov 2017
that wasn't totally random, about "bacon science" - we saw some quantitative pork belly data published somewhere recently... it was on slack.
landreev
on 16 Nov 2017
"would it be more useful to populate our DC.subject the same way as the LD JSON "keyword" in this branch - with the combination of all 3: our "subject", "keyword" and "topicclassification"?
It would be more useful. dc.subject and schema.org's keywords are very broadly defined.
But for this issue, I don't think it's vital to add keywords and topic classifications (or anything else) to dc.subject. I'll be happy to open another issue for adding more metadata to the Dublin Core in the metatags.
But I do want to say that I don't think the "consistency" is an obvious argument necessarily. I know the way this was discussed with the google person, it was pretty specific to how they understand what "keyword" means in their schema, what they do with that metadata, etc. I don't think this should automatically translate into what we put into other formats...
I agree. The same things should go into dc.subject and schema.org's keywords, but less because of consistency and more because they're defined and used in similar ways. I've been working on a few docs, like this one, to see all of the use cases when considering issues like this.
jggautier
on 16 Nov 2017
@jggautier I hadn't seen that "Metadata export use cases" doc before. Good stuff. Thanks.
pdurbin
on 16 Nov 2017
@jggautier thanks for stopping by. I just deployed v. 4.8.1 build 2243-schema.org-json-ld-e0399c1 to https://dev1.dataverse.org for you to poke around. Feedback is very welcome!
pdurbin
on 16 Nov 2017
Hmm, I'm already seeing some problems errors at https://search.google.com/structured-data/testing-tool/
Here's a screenshot:
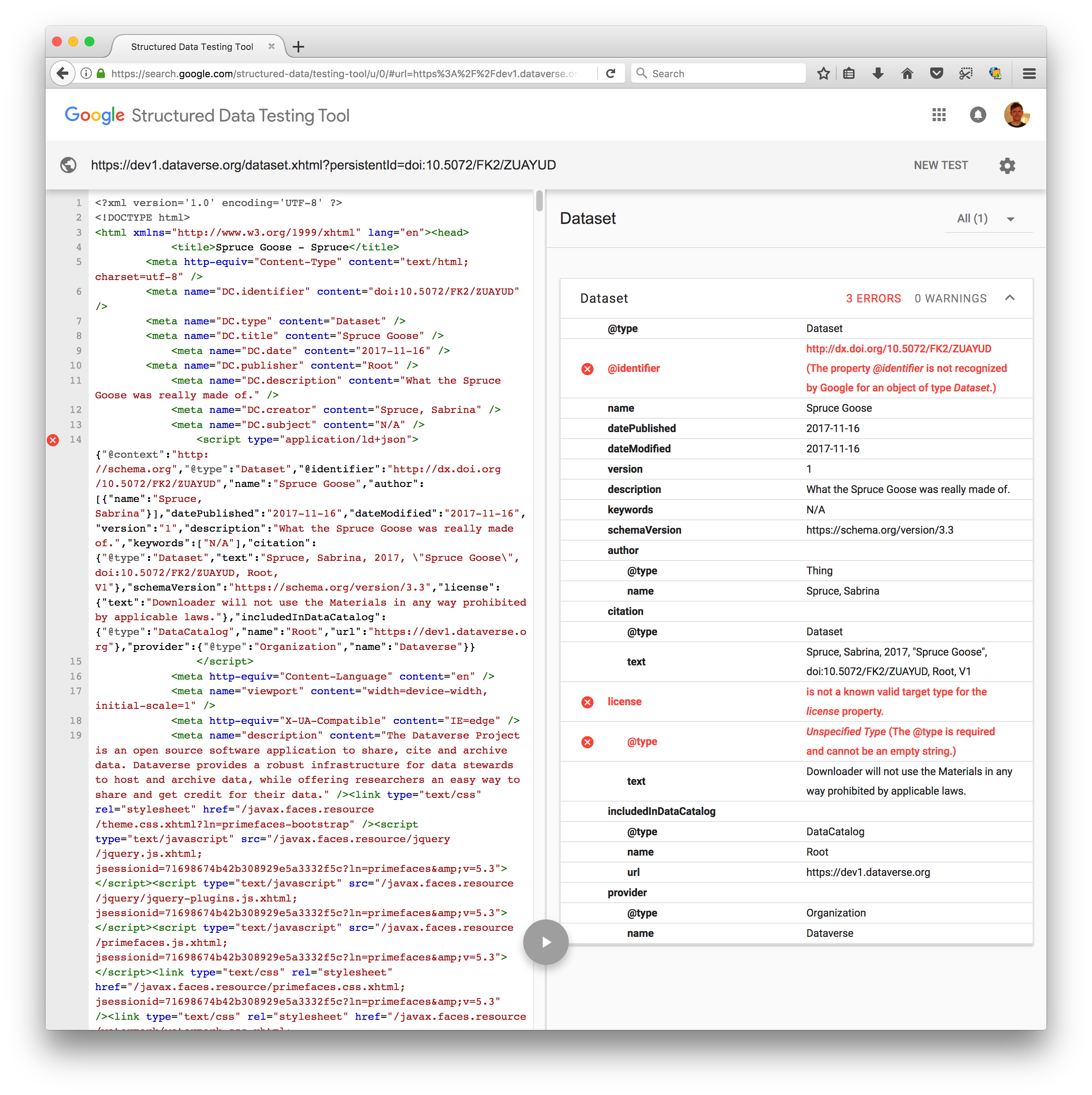
I'm going to let @jggautier do some testing. He knows more what he's looking for and knows which fields to exercise. I'm glad we have this tool to test against.
pdurbin
on 17 Nov 2017
Thanks @pdurbin! And thanks @landreev!
These seem like small errors to fix.
- [x] "identifier" has an @ sign in front of it, "@identifier". The @ just needs to be removed. (Probably left over from when "@id" was being used?)
- [x] Each time "license" is used, an "@type" needs to be included. It's included when the license is CC0, but not when CC0 is waived and Terms of Use is used instead. I wasn't clear about this in my comment or example json doc. So it should be:
- When CC0's waived:
- "license": {
"@type": "Dataset",
"text": "Downloader will not use the Materials in any way prohibited by applicable laws."
} - Or when CC0's not waived:
- "license": {
"@type": "Dataset",
"text": "CC0",
"url": "https://creativecommons.org/publicdomain/zero/1.0/" },
- [x] "affiliation" for each author isn't showing
- [x] "Citation" should have publicationCitation metadata (from the Related Publication fields). It looks like the citation of the dataset is being mapped, instead. I should've been explicit about this, since I interpreted "citation" the same way at first, and other repositories are also using "citation" as the dataset citation instead of a "citation or reference to another creative work, such as another publication, web page, scholarly article."
Only thing I haven't checked is "datePublished" and "dateModified". Going to have to wait for tomorrow for that. datePublished and dateModified are also working as intended.
jggautier
on 17 Nov 2017
Will fix first thing in the morning; yes, looks trivial.
Thanks @pdurbin - I did miss that part, that they provide this nice test tool.
landreev
on 17 Nov 2017
In addition to the small fixes above, @scolapasta, @landreev and I agree that the metadata in schema.org json/ld for only the most recent version of a dataset should be in the HTML of only the most recent version's landing page.
In other words:

jggautier
on 17 Nov 2017
OK, checked in the code to address the items from the latest checklist;
the json fragment is now passing validation by the google test tool.
(that is, my test dataset is passing validation).
landreev
on 17 Nov 2017
The only thing I had to add, to what's specified above - the "author" entry needs to have an additional "@type: Person" attribute for the whole thing to be valid. (I've updated the Googledoc to reflect this)
landreev
on 17 Nov 2017
I've checked in the last (I hope) change, that makes the ld json fragment appear in the LATEST published version ONLY.
OK to drag it directly into QA? - it looks like it's been reviewed to death already, right - ?
landreev
on 17 Nov 2017
The only thing I had to add, to what's specified above - the "author" entry needs to have an additional "@type: Person" attribute for the whole thing to be valid. (I've updated the Googledoc to reflect this)
Thanks for checking @landreev. I spoke with Natasha about this issue, and we agreed it's okay to ignore the warning that Google's tool gives when @type is "Thing" (which it defaults to when there's no @type) and an affiliation is included. The less-preferred alternatives are (1) saying that every author is a person, which isn't true, and Dataverse has no way of knowing which author is a person and which is an organization (the other @type), or (2) not including an affiliation.
jggautier
on 17 Nov 2017
OK, I reversed the type=person change.
landreev
on 17 Nov 2017
Regarding how DataCite tries to determine whether an author is a person or an organization: we spent a lot of effort on this, and have gone through multiple iterations. The code is here: https://github.com/datacite/bolognese/blob/master/lib/bolognese/author_utils.rb#L72-L87.
We assume the author is a person if
- we have
familyNamemetadata - we have an ORCID ID
- the author is in the format
familyName, givenName - the author is in the format
givenName familyNameand thegivenNameis in a dictionary of first names.
The above gives us a > 90% accuracy. The reason we need this is not so much that it is required for schema.org, but that we need this to do proper citation formatting and bibtex export.
 mfenner
on 18 Jan 2018
mfenner
on 18 Jan 2018
Also, while @id is a complex topic, I think it really matches well to what the DOI (expressed as URL). For practical reasons I like to use the DOI in both @id and identifier.
mfenner
on 18 Jan 2018
@mfenner thanks. This is helpful and interesting.
pdurbin
on 18 Jan 2018
Using a dictionary of given names worked really well for us. False negatives were mainly names from China and India, false positives the rare organization where the name starts with a given name, e.g. Alfred P. Sloan Foundation.
Because this is so painful, the DataCite Schema 4.1 released in September 2017 added an attribute to creator and contributor: nameType (controlled list of either personal or organizational).
The simplest solution is obviously to use givenName and familyName from the start.
mfenner
on 18 Jan 2018
Thanks, that nameType attribute sounds useful. I just mentioned it over at https://github.com/IQSS/dataverse/issues/4318#issuecomment-358643745
pdurbin
on 18 Jan 2018
Related issues
 qqmyers
·
79Comments
qqmyers
·
79Comments
 astrofrog
·
62Comments
astrofrog
·
62Comments
 eaquigley
·
44Comments
eaquigley
·
44Comments
 stevenferey
·
42Comments
pdurbin
·
86Comments
stevenferey
·
42Comments
pdurbin
·
86Comments
Most helpful comment
@pdurbin @jggautier Can I suggest that the mapping schema.org "keyword" to the Dataverse dataset "subject" here, as it is used in Dataverse, is not particularly informative. As the Dataverse subject field only allows the default 14 subjects, there are limitations on the subject in describing and distinguishing the contents of a dataset. I think what may be more useful is the Dataverse "Keyword" field.
For example, virtually all datasets in the ADA collection will have the "Social Sciences" subject - so it doesn't help users to differentiate between content in our collection at all. Other dataverses are similarly dominated by the Social Sciences subject - the Odum dataverse has 280 of ~4,000 datasets with Social Sciences (and Medical with ~230), while the Dataverse.nl dataverse has 137 of 488 datasets with the subject Social Science (next is Medical et al with 25).
There are limitations to Keyword as well - these are often not drawn from a controlled vocabulary, nor are Keyword terms consistently applied. Keyword and Subject are often also used interchangeably.
There is some history to this - see the Acknowledgement at the end of the schema.org Dataset description (http://schema.org/Dataset):
"This class is based upon W3C DCAT work, and benefits from collaboration around the DCAT, ADMS and VoID vocabularies. See http://www.w3.org/wiki/WebSchemas/Datasets for full details and mappings."
The VoID vocabulary (https://www.w3.org/TR/void/#subject) includes a discussion of what should be included as a "subject", while the DCAT "dataset" includes a "keyword" (https://dvcs.w3.org/hg/gld/raw-file/default/dcat/index.html#Property:dataset_keyword), and Dublin Core includes DC:subject (http://purl.org/dc/elements/1.1/subject).
I think the most useful discussion on this from the above is the VoID proposal:
https://www.w3.org/TR/void/#subject
They start with asking a question: "When someone wants to select a dataset, one of the fundamental questions is, what does the dataset actually offer?" My concern is that I'm not sure that describing something as "Social Science" (which is what mapping schema.org/keyword to dataverse/subject will do) will really help the user much.
Unfortunately I don't have a better approach for you on this - just highlighting the limitations of the Dataverse Subject field in this area.