Dataverse: Dataset - Too Many "Unknown" Files, Friendly File MIME Type Display Names
As referenced in #2192, there are files in production that need friendly MIME Type labels.
From @landreev
The file in question is ./src/main/java/MimeTypeDisplay.properties
We should identify as many of these as possible, and give them friendlier display names that the one that @pdurbin found.

 mheppler
mheppler
All 24 comments
Also, I believe we should extend this "friendly name" functionality, to support wild cards.
As in:
image/jpeg=JPEG Image
image/gif=GIF Image
image/bmp=Windows Bitmap Image
image/*=Graphic Image
i.e., we provide friendly names for the types we know about; and a generic name for an image of type image/blah-blah that's not specifically listed.
We can do the same with MS documents and other types of files. Because we'll always be encountering file types we don't know about.
 landreev
on 1 Jun 2015
landreev
on 1 Jun 2015
Currently, the File Type values that are delivered from MimeTypeFacets.properties are lower case (see attached). I suggest that we capitalize them.

mheppler
on 18 Aug 2015
@scolapasta I'm passing this to you for a decision of what to do for 4.2.
 pdurbin
on 11 Sep 2015
pdurbin
on 11 Sep 2015
Related to #3288 #3333 #3334 #3335
mheppler
on 7 Sep 2016
This was briefly discussed during the tech hour.
What needs to be done can be summarized as 3 sub-tasks:
1) Curation work to better handle the mime types already in the database. (provide better user-friendly type/facet names; see the example below).
2) Investigate/find a file type identification solution better than the currently used Jhove. It was not actively maintained for a long time; but it appears that it came back to life, possibly under a different team, with new versions being released. So one lead is to just try the latest version (http://jhove.openpreservation.org/).
3) Develop an API for re-identifying the files already in a Dataverse. That would allow to try and assign better mime types to the files currently in production typed as "application/octet-stream" (which is a fancy way to say "type unknown").
An example of "curation" work, in 1) above:
We have almost 10K datafiles of type application/x-stata-syntax. These are Stata control cards, fairly popular format. However, the type is missing from both MimeTypeDisplay.properties and MimeTypeFacets.properties; so the files are not showing up as "Stata" or "Data" in the search results and in the file type facets, respectively. Adding the type to the properties files above is a very easy fix. There are most likely many other cases like this.
landreev
on 24 Apr 2019
@pameyer opened #4156 and said:
Noticed on https://dataverse.harvard.edu/file.xhtml?fileId=3052745&version=RELEASED&version=.0.
HDF5 is a reasonably widely used file format (https://www.hdfgroup.org/HDF5/)
Will check as part of this effort if updating the jhove library resolves that unknown file type.
mheppler
on 2 May 2019
@landreev opened #4943 and said:
Most CSV files are identified as "text/csv". But we also accept "text/comma-separated-values" (as an ingestable format).
However, we only keep a "pretty", display type for "text/csv". (the mime display type properties bundle needs to be updated).
Will add that to the updates to MimeTypeDisplay.properties and MimeTypeFacets.properties.
mheppler
on 2 May 2019
Added over 100 new content types to the MimeTypeDisplay and MimeTypeFacets properties files in order to better categorize the file types identified by current jhove library. (That is nearly half of all the file content types currently in production.) This will decrease the number of files categorized as Application or Text, and adds them to more appropriate categories like Data, Code, Document, or Archive.
We should review these new categorizations, as well as some that were changed ("ZIP" is now categorized as "Archive", along with over a dozen other content types), and some that should be changed (should "FITS", "Tabular Data" and "Shape" be grouped into "Data"?).
There are other content-types that represent A LOT of files (+76K), that I also have questions about.
data/various-formats | 67654
image/dicom-rle | 5156
chemical/x-xyz | 2314
application/postscript | 559
application/vnd.flographit | 197
application/vnd.isac.fcs | 107
application/download | 40
This effort alone should be enough to _"make Data # 1"_ but does not impact the number of Unknown files. That effort is currently being tackled by @pdurbin.
mheppler
on 2 May 2019
@mheppler I just upgrade jhove in d9e7d71df
I also added some tests. If you can think of other files to test that are already in the code base, please feel free to add them to the list.
pdurbin
on 2 May 2019
My $0.02 on the next steps with jhove:
Should be trivial to rebuild the app with the new version of jhove and then add a quick API for re-testing existing files for type identification.
However, we can only decide if this newhove is good enough to use once we test it on all the type-unknown files in production and confirm that it makes a difference. I would not be comfortable with pointing a test instance at the production S3 bucket. So I would create a standalone 15 line java program that runs jhove on a file and outputs the type. And then script it to run on all the unknown files in production.
landreev
on 3 May 2019
I went and collected 84 various files from production that represented over 20 of the most common unknown files, and put them through the new jhove library. 40 of them still uploaded as "Unknown". Those failed file types included:
.bin
.mat
.set
.nii
.swc
.m
.DATA
.db
.py
.MP3
.fdt
.h5
.img
.dcm
To the points raised by @pdurbin and @landreev, it appears we'd make the most gains battling against unknown files by running them through an API again, which should correctly identify the file types that are more common, like xls, ppt, docx, zip, rar, log, png that I was able to successfully upload locally in my test and correctly identify.
Those gains, plus the gains outlined above, adding new content types to the mime properties files, in order to provide the UI with friendlier looking labels, as well as to better categorize them in the File Type facets, will move miscategorized files from Text and Application, and put them in Data or Archive or Document categories.
Here is a full list of those new content types.
# Document
image/pdf=Adobe PDF
text/pdf=Adobe PDF
application/x-pdf=Adobe PDF
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet=MS Excel
application/vnd.ms-powerpoint=MS Powerpoint
application/vnd.openxmlformats-officedocument.presentationml.presentation=MS Powerpoint
application/vnd.openxmlformats-officedocument.wordprocessingml.document=MS Word
application/vnd.oasis.opendocument.spreadsheet=OpenOffice Spreadsheet
# Text
text/html=HTML
application/x-tex=LaTeX
text/x-tex=LaTeX
text/markdown=Markdown Text
text/x-markdown=Markdown Text
text/x-r-markdown=R Markdown Text
application/rtf=Rich Text Format
text/rtf=Rich Text Format
text/richtext=Rich Text Format
text/turtle=Turtle RDF
application/xml=XML
# Code
text/x-c=C++ Source
text/css=Cascading Style Sheet
text/javascript=Javascript Code
application/javascript=Javascript Code
application/x-javascript=Javascript Code
text/php=PHP Source Code
text/x-python=Python Source Code
text/x-python-script=Python Source Code
text/x-r-source=R Source Code
application/x-sh=Shell Script
application/x-shellscript=Shell Script
application/x-sql=SQL Code
text/x-sql=SQL Code
application/x-msdownload=Windows Executable
# Data
text/comma-separated-values=Comma Separated Values
application/x-stata-do=Stata DTA Script
application/x-stata-dta=Stata DTA Script
application/x-stata-syntax=Stata Syntax
application/x-spss-portable=SPSS Portable
application/x-spss-sav=SPSS Binary
application/x-spss-syntax=SPSS Syntax
application/x-spss-sps=SPSS Script Syntax
application/x-sas=SAS
application/x-sas-syntax=SAS Syntax
application/x-sas-data=SAS Data
application/x-sas-catalog=SAS Catalog
application/x-sas-log=SAS Log
application/x-sas-output=SAS Output
application/softgrid-do=Softgrid DTA Script
application/json=JSON
application/mathematica=Mathematica
application/x-matlab-figure=MATLAB Figure
application/x-matlab-workspace=MATLAB Workspace
application/x-xfig=MATLAB Figure
application/x-msaccess=MS Access
application/x-nsdstat=NSDstat
application/x-netcdf=Network Common Data Form
application/vnd.lotus-notes=Notes Storage Facility
application/vnd.realvnc.bed=PLINK Binary
application/x-hdf=HDF
application/x-hdf5=HDF5
# FITS
image/fits=FITS
# Archive
application/zip=ZIP Archive
application/x-zip-compressed=ZIP Archive
application/vnd.antix.game-component=ATX Archive
application/x-bzip=UNIX Archive
application/x-bzip2=UNIX Archive
application/vnd.google-earth.kmz=Google Earth Archive
application/gzip=GZIP Archive
application/x-gzip=GZIP Archive
application/rar=RAR Archive
application/x-rar=RAR Archive
application/x-rar-compressed=RAR Archive
application/tar=Tape Archive
application/x-tar=Tape Archive
application/x-compressed-tar=Tape Archive
application/x-7z-compressed=7Z Archive
application/x-xz=XZ Archive
# Image
image/jp2=JPEG-2000 Image
application/x-msmetafile=Enhanced Metafile
image/dicom-rle=DICOM Image
image/svg+xml=SVG Image
image/bmp=Bitmap Image
image/x-xbitmap=Bitmap Image
image/RAW=Bitmap Image
image/x-xpixmap=Pixmap Image
# Audio
audio/x-aiff=AIFF Audio
audio/mp3=MP3 Audio
audio/mpeg=MP3 Audio
audio/mp4=MPEG-4 Audio
audio/x-m4a=MPEG-4 Audio
audio/ogg=OGG Audio
audio/wav=Waveform Audio
audio/x-wav=Waveform Audio
audio/x-wave=Waveform Audio
# Video
video/avi=AVI Video
video/x-msvideo=AVI Video
video/mpeg=MPEG Video
video/mp4=MPEG-4 Video
video/x-m4v=MPEG-4 Video
video/ogg=OGG Video
video/quicktime=Quicktime Video
video/webm=WebM Video
dinky sorted list of UNC Dataverse's unknown filetype by extension
unknown_fileextensions.txt
and Mandy's official list:
.yml .slurm .ado .shp .dbf .prj .sbn .sbx .shx .sas .gwt .gal
 donsizemore
on 9 May 2019
donsizemore
on 9 May 2019
I just made pull request #5853 (draft pull request for now) but I'm a bit blocked. At tech hours this afternoon I asked @scolapasta and @sekmiller if they knew how to make the code worth with S3 and Swift but we all decided it would be easier to just ask @landreev when he gets back.
@landreev also requested a little 15 line Java program to try the new Jhove on production files. I think there might even be a jar file provided by the Jhove project we could use.
I did document a new "redetect file type" API that anyone reading this is welcome to try out.
I beefed up our detection based on file extension but right now I only have one file extension (.ipynb for "application/x-ipynb+json" for Jupyter notebooks) in the file I created: https://github.com/IQSS/dataverse/blob/f95a62778ec5f0907ecf3d15779933fff227b6a8/src/main/java/propertyFiles/MimeTypeDetectionByFileExtension.properties . My reasoning is that ".ipynb" files are really just JSON files so we need some way to identify them a Jupyter Notebook files and the file extension seems like the best and perhaps only way.
I can image a "talk after" for this issue to decide when we're done. Obviously, we need this to work on S3 at minimum. There's the list of 84 types from @mheppler above. I'd also like to make sure the list from @donsizemore above can be detected (perhaps by file extension) and @juancorr provided a list at http://irclog.iq.harvard.edu/dataverse/2019-05-10#i_93018 that I'll repeat below:
- tscopf_nonsync.gms - https://edatos.consorciomadrono.es/file.xhtml?persistentId=doi:10.21950/ZPRADY/JPSWTZ
- benchmark_survey.exp - https://edatos.consorciomadrono.es/file.xhtml?persistentId=doi:10.21950/AQ1CVX/UKWS0V
- modelo_datos.Rmd - https://edatos.consorciomadrono.es/file.xhtml?persistentId=doi:10.21950/O9TDMF/U6WSA3
I'm aware of tools like DROID ( https://github.com/digital-preservation/droid ) but I haven't tried them.
I did play a bit with detection with Tika but it seemed to fall back on file extensions a lot. This is the blog post I was looking at http://marxsoftware.blogspot.com/2015/02/determining-file-types-in-java.html
pdurbin
on 16 May 2019
There are other parts of the system where we read an existing stored file in order to do some processing on it. The code there could be reused or used as a model for accessing files for the purposes re-trying file type identification.
Thumbnail generation is an obvious example.
Also, we already have an API call that re-identifies file type; it was created for a more narrow case - of an ingested tabular file for which the "original type" was not saved properly. But it relies on the same standard type checking code; and of course it needs to read the saved original file - from the filesystem or s3 or swift, wherever it lives; but you just go through our standard dataaccess framework and it handles it transparently.
The API call in question is /api/admin/datafiles/integrity/fixmissingoriginaltypes, and the implementing method is fixMissingOriginalType(long fileId) in IngestServiceBean.
landreev
on 20 May 2019
Also, I can definitely help with/work on this, and the part about building a script for checking the existing prod. unknown-type files, before we have a chance to deploy this new API in prod. - Unless there's something more urgent I should look into instead - ?
landreev
on 20 May 2019
Just had a brief discussion with @pdurbin about this; copy-and-pasting the code from the "fixMissingOriginalType" into the new method for re-identifying a generic unknown file would have a consequence of reading potentially A LOT of files from S3 in a prod. environment like ours. (in our case - terabytes, potentially??) Whether it's worth it is a good question... It's interesting that Jhove insists on having a whole file, in order to do its identification magic. Even though in practice it most likely only needs to read some fixed number of bytes at the beginning... Is it possible to cheat, and give Jhove the first few K of a file - and see if it still works?
It may not be such a big deal - seeing how a) this only needs to be done once; and b) s3 access while inside the cloud is cheap-ish and c) it is going to be up to the admin, which files to run this API on - so they can always decide to skip the largest files...
But it's definitely something to think of/experiment with.
landreev
on 20 May 2019
Both @mheppler and @landreev agreed that some additional docs on file type detection would be nice such as an overview of the techniques used so I just pushed 1f1985151 with this information. I also added a bit to the troubleshooting section of the Admin Guide. Here are some screenshots:
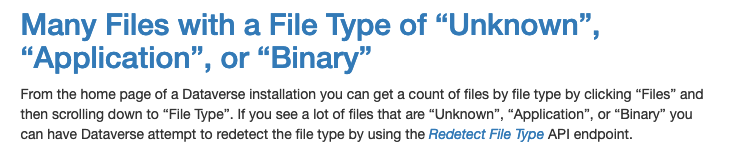

pdurbin
on 20 May 2019
As I mentioned earlier, I ran jhove on the unknown/un-typed prod. files, with abysmal results. I now realize it may have been a waste of cpu time/resources. I used their command line utility (supplied in jhove-apps); instead of writing my own 5 line java program. Which apparently fails on all sorts of files that DO get properly recognized by jhove when uploaded through the application. The reason for that appears to be that the command line utility tries to do much more, on top of simply detecting the type. It tries to parse individual sections of pdfs, pngs, etc. and validate the entire file... Which, again, appears to fail on even seemingly valid pngs, pdfs, etc.
So I'll have to write my own simple app and rerun it in prod.
landreev
on 30 May 2019
The thing I mentioned during standup: yes, jhove's xml module hangs for an hour+ if it can't download the schema as listed in the header. For example, we apparently have a whole bunch of previously unidentified Gephi files, and they all have headers like
<gexf xmlns="http://www.gexf.net/1.2draft" version="1.2" xmlns:viz="http://www.gexf.net/1.2draft/viz" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.gexf.net/1.2draft http://www.gexf.net/1.2draft/gexf.xsd">
and connections to www.getxf.net just time out.
(after hanging for an hour, jhove dutifully returns "text/xml")
landreev
on 31 May 2019
The final word on the new version of Jhove - it works; (aside from the new xml plugin, that has the problem above - which does not seem acceptable, so it's going to be excluded from the configuration). It gives some modest gains in detecting the types of some previously unidentified files (mostly png images, text files, including the specific encoding used, gzip and web archive files; I can post the exact percentages in relation to the number of prod. files currently listed as unknown).
But it should be an ongoing process of further improving this area; I will open a new issue for this specific area. We will still need to decide if we want to stick with Jhove (the only way to get more out of it would be by creating more type-specific plugins for it ourselves), or adopt something else instead of, or on top of it.
landreev
on 4 Jun 2019
(That is to say, I'm choosing the manageable chunks/incremental improvements approach here, just so that we can close this issue and move forward)
landreev
on 4 Jun 2019
At standup I said I wanted to to check if I had documented the new file type redetect API endpoint I added (phew, done already) and I see that @landreev just pushed a release note in ef40804 which looks good. I just moved this to QA. Also looked at the recent code-related commits that @landreev made since I last touched the branch and they all look good to me too.
pdurbin
on 5 Jun 2019
Something I should've done earlier - notes on how to test/what to look for:
There is more than one area of where things were improved:
- The new API for re-identifying the types of files currently stored as unknown (mime type: "application/octet-stream") in the database. The API is
/api/files/<FILEID>/redetect. Until this api is actually run in prod., the number that appears as "Unknown" in the type facets will not change. This API cannot be tested on the vm5 copy of the database - since it needs to read the actual files; and we don't want to point vm5 to the prod. s3 bucket. But it can be tested on some select files. - Better rules for classifying known mime types for the type facets indexing. This part can be tested on vm5 - a full reindex should affect the facet numbers, most notably:
the misleading "Application" (30K files in prod. currently) facet should disappear completely;
"Zip" facet (8K in prod.) should go away, replaced by "Archive", showing a higher number (all compressed and archived formats will be indexed under this type);
A new facet "Code" should appear, with a sizeable number of files (20K+)
A new facet "Other", with a relatively small number of files. (this is for the files previously indexed under the "Application" facet, that haven't been reclassified under more informative groupings). - More file types should have "friendly" type descriptions (as appear on the dataset and dataverse pages). See the diff on the MimeTypeDisplay.properties file.
- Jhove should do a better job identifying some file types. The recommended way of testing this is by uploading files via the API, to take the browser and the OS out of the picture. File types to try: png, gzipped. Changing/stripping the .png and .gz filename extensions would ensure that the type is identified by the contents, and not by the extension.
- The list of recognized filename extensions used to guess the content type has been extended. See the diff on MimeTypeDetectionByFileExtension.properties.
- It may be worth confirming that Mike's type-specific default thumbnails are still working properly - the code that selects those have been reorganized as part of this PR too.
landreev
on 7 Jun 2019
Peaked at the icons mentioned in "6" and suggested tweaks for data and archive icons. Put my random selection of 84 unknown files into dvn-build and Data went last (2 of 84), to first (18 of 84). The unknowns were still pretty high, but hopefully we see greater gains in the full 127,109 pool of unknowns in production since all 84 of those files were unknowns there originally.

mheppler
on 11 Jun 2019
Related issues
 rmo-cdsp
·
3Comments
rmo-cdsp
·
3Comments
 poikilotherm
·
4Comments
poikilotherm
·
4Comments
 amberleahey
·
3Comments
amberleahey
·
3Comments
 jggautier
·
3Comments
jggautier
·
3Comments
 raprasad
·
5Comments
raprasad
·
5Comments