Dataverse: Custom home page for Harvard Dataverse
Harvard dataverse stakeholders would like a custom homepage for the repository. The goals are to:
- promote Harvard dataverse
- increase use of Harvard dataverse
- demonstrate the depth and breadth of the Harvard Dataverse
- present Harvard Dataverse as part of Harvard, and the Harvard libraries.
There are two phases planned; the image shown below and a revised version adding a visualization and links to an About Harvard Dataverse site. See the Design project doc, with links to related files for details.

 TaniaSchlatter
TaniaSchlatter
All 29 comments
@matthew-a-dunlap here's the doc we were just looking at that has notes from tech hours and later meetings with design: https://docs.google.com/document/d/1AtvODFY8aNQSE9BleeQEf5GkFsDWrziUB-IX-1xA0Y8/edit?usp=sharing
 pdurbin
on 1 Oct 2018
pdurbin
on 1 Oct 2018
Still waiting on new mockups from @TaniaSchlatter for the Recent Activity section, but here are some of the decisions we discussed in the design mtg.
- Instead of a general published datasets (which might show harvested results) and file downloads (which would require a new API plugged into guestbook) make all three columns published datasets by dataverse categories (like the third "journal" column is in the mockup)
- Based on the metrics on dataverse.org, the three category columns discussed were journals (2%), researchers (30%) and research projects (43%) -- but there maybe more discussion needed on these if the queries don't produce recent activity results expected
- The activity API's for datasets based dataverse category was hoped to be something that would also provide value to other installations who wanted to use this custom homepage template for their installation
 mheppler
on 1 Oct 2018
mheppler
on 1 Oct 2018
There is a new mock up in the doc and descriptions of dynamic content including our development discussions, and discussions with library folks: https://docs.google.com/document/d/1AtvODFY8aNQSE9BleeQEf5GkFsDWrziUB-IX-1xA0Y8/edit
TaniaSchlatter
on 3 Oct 2018
This issue is likely blocked by https://github.com/IQSS/dataverse/issues/3616 , in which the image urls provided by our search API are unusable. I say "likely" because I have some skepticism around using the search api in general for this page. I created a prototype javascript block for testing the "most recent datasets by category" functionality, and it seems pretty slow, but there are a number of tricks left to improve it (loading the content async, combining the two search calls into one endpoint, solr caching, etc).
 matthew-a-dunlap
on 4 Oct 2018
matthew-a-dunlap
on 4 Oct 2018
Added the first version of the new dynamic custom homepage template to the docs at source/_static/installation/files/var/www/dataverse/branding/custom-homepage-dynamic.html.
This has most of the styling and messaging from the latest version of the mockups, and can be used to start bringing dynamic content from the API's that @matthew-a-dunlap is working on.
Happy to help get the javascript into it as needed, when we're ready to start wiring it up.
mheppler
on 12 Oct 2018
The state of the homepage queries:
- We don't have an endpoint to get the past 30 days, right now we can just give the total up until a specified month. We could do so, but if the main goal is just to show activity, maybe we should switch this section to be "publications this month".
- Returning datasets via dataverse subjects works to some degree, but also has some issues:
- The max returned results returned by solr for our app is 1000 (coded in). We can change this or use paging to get around it.
- If we do get all Dataverses of a certain subject, the size of the http request with all those dataverses passed in the second call ("get all datasets in these subtrees") is so big the server rejects it outright
- Doing these two calls in the browser isn't as slow as I expected, but may be a fair bit slower in production with full results. I haven't fixed the two above issues because I think the correct approach may be to create a call that encapsulates these two into one request.
- Its worth noting that solr already caches some of the data from the two requests for subsequent calls, and we may be able to tweak that more or add our own caching in some cases.
- As a somewhat unrelated improvement, we should look to making the multiple subtrees available via the UI, even if its somewhat of a hidden feature (e.g. through the url string).
@scolapasta @mheppler I'd appreciate your thoughts. The javascript/html in doc/harvard_custom_homepage.html can be used but it will need more work depending on the outcome of discussion.
matthew-a-dunlap
on 12 Oct 2018
Discussing more with @mheppler, we need # 1 to provide the results for the past 30 days.
Currently the endpoint is based around historic totals up until a provided month (/api/info/metrics/datasets/toMonth/[Date]). We'll have to expand to at least return results for the past 30 days (e.g. /api/info/metrics/datasets/past30/). It'd be nice to do something a bit more generic ( e.g. /api/info/metrics/datasets/dateRange/[startDate]-[endDate]) but that won't work well with the caching system.
I feel we should at least add endpoints for the past 90 days and past year, as those will take little extra effort and some installation will probably want them at some point.
matthew-a-dunlap
on 12 Oct 2018
@scolapasta @matthew-a-dunlap @mheppler Let's talk today to scope this and keep it moving.
 djbrooke
on 16 Oct 2018
djbrooke
on 16 Oct 2018
Notes from today's custom homepage discussion:
- [x] Dataverses by Subjects
- [x] need to be alphabetical
- [x] parse out the N/A subject
- [x] content in columns running top to bottom, not left to right
- [x] number of items in column = 5, 5, and remainder, if 15 or fewer subjects
- [x] We need a real metric for past 30 days, not just the current month
- [x] For Datasets by Category, instead of using multiple subtrees we are going to try indexing the dataverse category for the dataset
- [x] this will involve reindex if the dv category changes
- [x] multiple subtrees will remain in the api, and needs extra tests for queries on nested ones.
- [x] Ok to try two columns instead of 3, with 3 or 4 results in each column (top to bottom)
- Datasets by category activity results need:
- [x] thumbnails
- [ ] parent dataverse name, link
- left for demo, may not do
- [x] format published date to "Oct 23, 2018"
- [x] Undo testing changes for multiple subtree queries (jetty, solr, code)
- [x] Dynamic base url for homepage
- [x] Update
...source/_static/installation/files/var/www/dataverse/branding/custom-homepage-dynamic.htmlversion of the template for the guides and remove the workingdoc/harvard_custom_homepage.htmlversion - [ ] Add deployment notes (solr change, etc)
matthew-a-dunlap
on 17 Oct 2018
I've updated Dataverse to index DV Category for datasets and files. This allows us to search for datasets via the dataverse category.
One downstream change is that the count for Dataverse Category on the search page now reflects datasets.
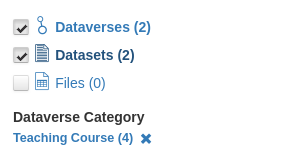
2 + 2 = 4 total for the category.
Is this what we want? The most straightforward way I can see to avoid datasets showing up for Dataverse Category is to index this data under a different name for datasets/files. The trade-off will be that users won't be as easily able to search for datasets by dataverse category.
matthew-a-dunlap
on 22 Oct 2018
@matthew-a-dunlap Good question. The category is "Dataverse Category." If we take that literally, then a count of 4 is inaccurate. The categories we have are most useful as describing dataverses, not datasets, so I don't see a problem that users won't be able to easily search for datasets by dataverse category. Other filters are more relevant for finding datasets.
TaniaSchlatter
on 23 Oct 2018
We should review sign up/login redirect bug #3225 when we next demo the custom hmpg.
mheppler
on 24 Oct 2018
Final(?) to-do list from latest demo:
OVERALL
- [x] Improve responsiveness
- [x] Add documentation link to new custom template
- [x] Add deployment notes (solr change, etc)
- [x] Update docs related to metrics
ACTIONS
- [x] Improve header font size/weight
- [x] Add missing "data and code..." text from mockup
SEARCH
- [x] Make "75,000 datasets..." count dynamic (rounded, e.g. "89,400") for input placeholder text
RECENT DATASETS
- [x] Improve dataset/hr spacing
- [x] Left align "ALL..." links
- [x] Wire up dataset parent names/links
OTHER LINKS
- [x] Confirm "All repositories at Harvard" link (https://library.harvard.edu/services-tools)
mheppler
on 25 Oct 2018
I just mentioned to @matthew-a-dunlap that we should probably revisit what's written at http://guides.dataverse.org/en/4.9.4/api/intro.html because I neglected to add "Metrics API" to the list at the top and we should probably revisit what we wrote about miniverse under "Metrics" at the bottom of that page. Here's how it looks now:


pdurbin
on 26 Oct 2018
Deployment notes:
- solr schema.xml needs to be updated. This involves restarting solr and reindexing.
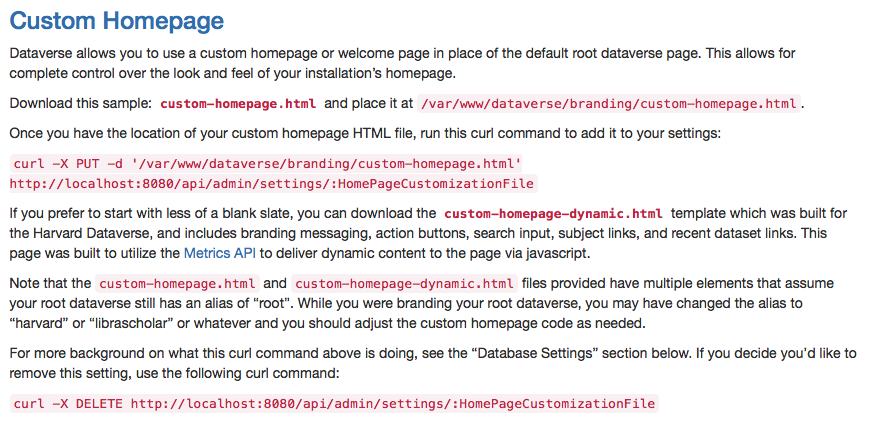
- setting the custom homepage needs to be performed, using the file in dataverse/doc/sphinx-guides/source/_static/installation/files/var/www/dataverse/branding/custom-homepage-dynamic.html . See this page for the api call: http://guides.dataverse.org/en/latest/installation/config.html#branding-your-installation
Testing notes:
- New metrics api calls were added.
- users can query the # of dataverses/datasets/files/downloads in the past X days, via
info/metrics/[type]/pastDays/[days]. After being queried, this value is cached for 24 hour, regardless of the cache config variable. - Datasets can be queried by subject
info/metrics/datasets/bySubject. This is affected by the cache variable:MetricsCacheTimeoutMinutes - To query the all-time count of dataverses/datasets/files/downloads, you can access it now without the toMonth path (e.g.
info/metrics/datasets).
- The old all-time call is still supported (
info/metrics/datasets/toMonth) - both are affected by the cache variable
:MetricsCacheTimeoutMinutes
- The old all-time call is still supported (
- users can query the # of dataverses/datasets/files/downloads in the past X days, via
- Search api was updated
- Datasets now return information about their immediate parent dataverse: identifier_of_dataverse , name_of_dataverse
- These values are indexed on creation of the dataset and updated on changes (the update is async so saving should not have to wait)
- Datasets and files can now be searched based upon the dataverse category. This is via the new solrField categoryOfDataverse, to ensure they do not show up in the UI search facets. An example query of this is
http://localhost:8080/api/search?q=*&type=dataset&fq=categoryOfDataverse:(%22Research+Project%22%20OR%20Researcher)&per_page=3
- This values are indexed on creation of the dataset and updated on changes (the update is async so saving should not have to wait)
- Search api now supports searching upon multiple subtrees. For example
localhost:8080/api/search?q=*&type=dataset&per_page=3&subtree=asdf&subtree=frog1
- This code is interconnected with our permissions checks for returning search results. I wrote a fair number of IT tests for this but a deeper look would be good.
- Note: This code was written to support homepage but did not work as using it required multiple queries
- Datasets now return information about their immediate parent dataverse: identifier_of_dataverse , name_of_dataverse
- Custom homepage itself
- [to write after last changes]
matthew-a-dunlap
on 26 Oct 2018
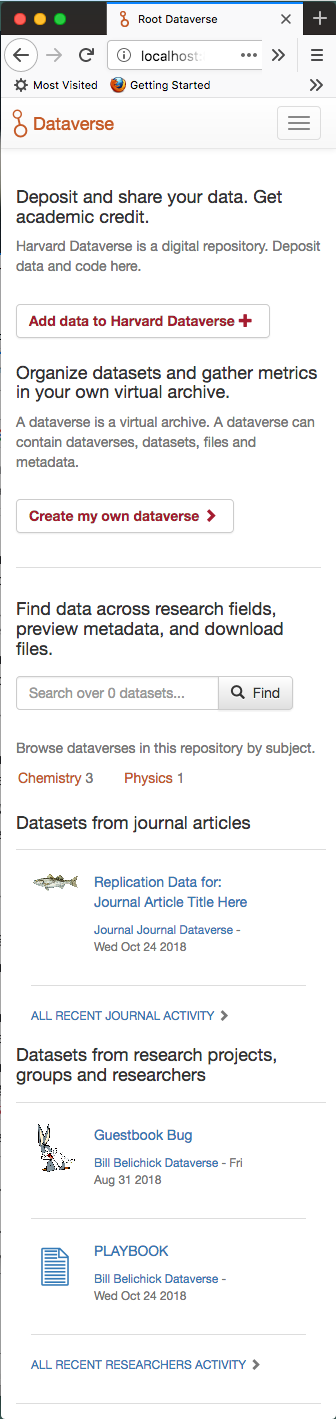
Now with improved responsiveness for browser windows 305 px in width (Firefox wouldn't go any smaller 😢 ).
mheppler
on 29 Oct 2018
Revised the new text in the Custom Homepage section of the Configuration > Installation Guide.
mheppler
on 29 Oct 2018
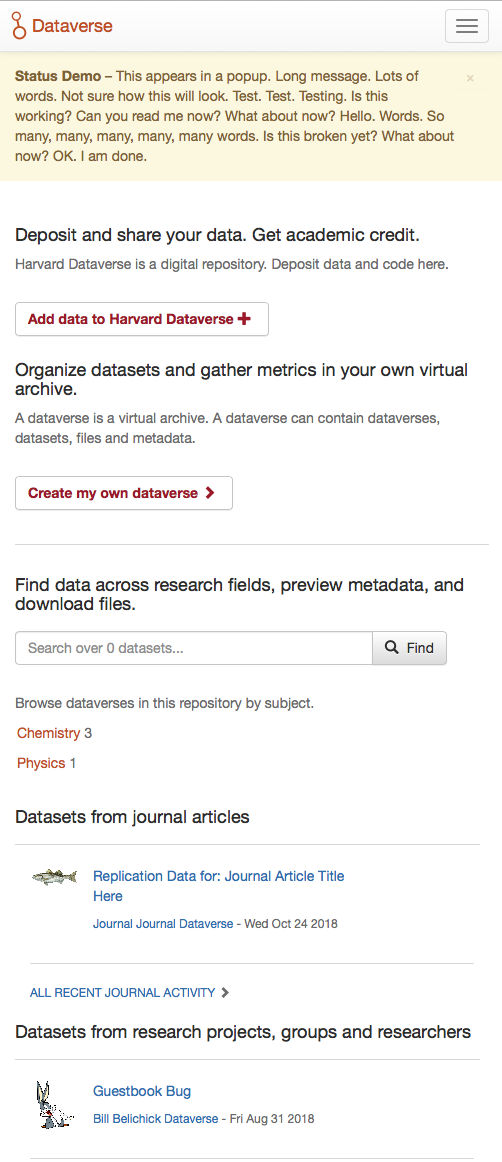
Now with responsive subject columns.
mheppler
on 30 Oct 2018
As of 2f52f13d2 I'm seeing failures on the following lines of SearchIT:
I should note that I also tried to run the full test suite in docker-aio a couple times but I'm getting strange failures and I suspect that Glassfish might be restarting or something.
pdurbin
on 30 Oct 2018
Fixed the researchers activity to now include "Research Groups". Cleaned up some minor layout spacing issues. Confirmed and revised other repositories link URL and text with the library folk.
mheppler
on 30 Oct 2018
I fixed the broken test and updated the metrics guide, let me know if you have any more feedback @pdurbin
matthew-a-dunlap
on 30 Oct 2018
As I mentioned at standup the other day, the scope of this issue has been increased slightly to add new "naked" endpoints such as...
- /api/info/metrics/dataverses
- /api/info/metrics/datasets
- /api/info/metrics/files
- /api/info/metrics/downloads
These return counts and if we're rethinking the namespace of the API perhaps we should add the word "count" in there like either of these...
- /api/info/metrics/counts/dataverses
- /api/info/metrics/dataverses/counts
... but not breaking backward compatibility with what's in production already.
I loaded up b1e685e on https://dev1.dataverse.org and learned that MyData is broken, throwing the following exception, so I'm moving this back into dev.
java.lang.NullPointerException at edu.harvard.iq.dataverse.search.SearchServiceBean.search(SearchServiceBean.java:246)
If we write some tests for MyData for this issue we will be ahead of the game for #5042.
pdurbin
on 2 Nov 2018
@pdurbin if it's back in dev., who's working on it?
I will remove my name from it then.
 landreev
on 2 Nov 2018
landreev
on 2 Nov 2018
As @pdurbin mentioned, we've updated the Metrics with new endpoints. We feel there may still be room for improvement with the api namespaces as well as the documentation for those namespaces.
The main open question we've had is how we organize our calls. In the doc they are currently listed as _counts_ and _other_, but could be changed to _by object_ and _by facet_. Regardless of the naming we have gone back and forth over whether the paths to the calls should reflect these categories, or if they should stay as is with the shorter structure.
Below is the current doc page.

matthew-a-dunlap
on 2 Nov 2018
Here are up-to-date release / testing notes on this issue:
- Setup steps:
- Update the solr schema
- Reindex
- Add the custom homepage via the jvm option http://guides.dataverse.org/en/latest/installation/config.html#custom-homepage
- Functionality added:
- Metrics
- New endpoint for all-time total
GET https://$SERVER/api/info/metrics/$type
- Old endpoint
GET https://$SERVER/api/info/metrics/$type/toMonthshould still work
- Old endpoint
- Past x days endpoint
GET https://$SERVER/api/info/metrics/$type/pastDays/$days
- Note that the caching on this metric is different from all the others (which are set via jvm option). It is cached every day regardless
- Dataverses by subject
GET https://$SERVER/api/info/metrics/dataverses/bySubject
- New endpoint for all-time total
- Search inside multiple dataverses (e.g. subtrees). For example:
https://demo.dataverse.org/api/search?q=data&subtree=birds&subtree=cats
- We ended up not using this for the homepage but the functionality is still there. It involved touching the permissions for what objects show up on search calls (e.g. whether unpublished/restricted files should show in a search).
- Search with/without doing database queries on the entities for additional facet data. This functionality was there but not configurable via api calls, now it is available via the API and turned off by default
- Change to how thumbnails are queried via api. If there is no thumbnail, Dataverse returns an error. Should not impact anything inside Dataverse itself, only the api endpoint was touched.
- New values indexed:
- categoryOfDataverse / identifierOfDataverse added to schema and indexed. dvName is also indexed for dataset (no schema add for this).
- These all update if the dataset is moved. They reflect the immediate parent dataverse
- Note that categoryOfDataverse / identifierOfDataverse were named differently as to ensure datasets don't show up in searches for the specific dataverse fields.
- categoryOfDataverse / identifierOfDataverse added to schema and indexed. dvName is also indexed for dataset (no schema add for this).
- Metrics
matthew-a-dunlap
on 7 Nov 2018
Issues:
-Categories, all recent links throw exceptions when root dataverse not named root.
 kcondon
on 8 Nov 2018
kcondon
on 8 Nov 2018
@kcondon The hardcoded "root" dataverse name was something known during development and accepted as this is a custom homepage template, and the dataverse name can be customized along with the other content, like which categories to show recent datasets from, because other installations might not have "Journals" or "Research Groups".
If this isn't clear in the documentation, we should add that changing of the root dataverse alias is required in the javascript and other links for those to work.
mheppler
on 8 Nov 2018
@mheppler was just concerned about deploying to production where it would act the same and was not aware of the cause of the problem, plus no errors indicating what the problem was.
kcondon
on 8 Nov 2018
@mheppler you mean this?
Note that the custom-homepage.html and custom-homepage-dynamic.html files provided have multiple elements that assume your root dataverse still has an alias of "root". While you were branding your root dataverse, you may have changed the alias to "harvard" or "librascholar" or whatever and you should adjust the custom homepage code as needed.
Kind of low on the usability scale IMHO.
kcondon
on 8 Nov 2018
Related issues
djbrooke
·
3Comments
 Fernand0S
·
4Comments
Fernand0S
·
4Comments
 poikilotherm
·
4Comments
poikilotherm
·
4Comments
 atrisovic
·
3Comments
atrisovic
·
3Comments
 amberleahey
·
3Comments
amberleahey
·
3Comments