Dataverse: As an installation admin, I want my repository to export OpenAIRE-compliant metadata to improve discoverability, reusability of research data
@philippconzett (Dataverse Network Norway) wrote in https://groups.google.com/forum/#!msg/dataverse-community/lgSTeI-0zkQ/R7W8CfzvAAAJ:
The EU-sponsored research infrastructure project openAIRE aims to promote open scholarship and substantially improve the discoverability and reusability of research publications and data. Their guidelines have by now gained status as de-facto standards for OA research publication and data providers. In their Guidelines for Data Archives, they state i.a. what kind of metadata information research data archives should provide.
...
For us, and I guess for other Dataverse installations/users in Europe, compliance with the openAIRE guidelines is important. So, I wonder whether information about access and license(s) could be complemented in a new version?
@juancorr shared in another issue about adding DataCite metadata to the Export Metadata pulldown that Dataverse e-cienciaDatos
has expanded its DataCite metadata to be compliant with the European OpenAIRE guidelines (https://guidelines.openaire.eu/en/latest/data/index.html)...
If you want develop this feature we can collaborate.
The definition of done for this issue will be a Dataverse admin being able to have OpenAIRE harvest OpenAIRE-compliant metadata from her installation.
 jggautier
jggautier
All 80 comments
We have use some ugly tricks to have the OpenAIRE compatibility because Dataverse has not all metadata that need OpenAIRE. You can see them in the file https://github.com/Consorcio-Madrono/dataverse/blob/v4.6WithOpenAIRE/src/main/resources/templates/datacite_40.ftl .
- In e-cienciaDatos there are only open access data. We put the field <rights rightsURI="info:eu-repo/semantics/openAccess" /> in all oai records. We should need a field with the right access in Dataverse to map it in a clear way.
- In Dataverse, there are not a "Grant Agency Identifier" field. We have adapted the file https://github.com/Consorcio-Madrono/dataverse/blob/v4.6WithOpenAIRE/src/main/resources/templates/datacite_40.ftl to include the
agency identifiers by the name. It is possible for us because we have a few records with a few funders. Example:
<#if funder.name == "Ministerio de Ciencia y Tecnología" || funder.name == "Ministry of Science and Technology" || funder.name == "Spanish Ministry of Science and Technology" || funder.name == "MICYT">
http://dx.doi.org/10.13039/501100006280
 juancorr
on 3 Nov 2017
juancorr
on 3 Nov 2017
datacite_40.ftl
This .ftl file must be an FreeMarker file. I see the dependency has been added to the pom.xml at https://github.com/Consorcio-Madrono/dataverse/blob/025df77e0a25a8ad9221fec61925af88ed09053a/pom.xml#L57 . Perhaps this would be better discussed at https://groups.google.com/forum/#!forum/dataverse-dev (please feel free to start a thread there if you like, @juancorr ) but I'm curious about why you've introduced FreeMarker into your branch and if there is any alternative that's already part of the Java EE standard. I'm not trying to criticize. I'm just curious. I've never used FreeMarker.
 pdurbin
on 3 Nov 2017
pdurbin
on 3 Nov 2017
We have used the sbgrid code as base (https://github.com/sbgrid/sbgrid-dataverse/tree/feature/datacite-xml). We only have patched these code, the Dataverse code and adapted the inital sbgrid FreeMarker file to have a valid DataCite XML code and accomplish OpenAIRE guidelines.
It is the first time that I use a FreeMarker file too, but it is easily adaptable to accomplish other institutions requirements and to have special cases out of the java code. This works very well with e-cienciaDatos, but we have 12 datasets. We have not tested it in a large Dataverse installation.
Sorry, I have not enough experience with this files to discuss about it.
juancorr
on 3 Nov 2017
@juancorr oh! So you weren't the one to add the FreeMarker dependency. It's from the SBGrid branch. Thanks. I understand now.
pdurbin
on 3 Nov 2017
Yes, I had said it in my first comment in https://github.com/IQSS/dataverse/issues/3697 , but I should have emphasized it.
juancorr
on 3 Nov 2017
Dear all,
I’m glad to announce that our proposal to enhance the interoperability of several open source platforms has been awarded by OpenAIRE, see https://www.4science.it/en/2018/02/23/4science-awarded-by-openaire/
In our proposal, we have included the implementation of the Data Repository Guidelines in Dataverse, more specifically the support for the datacite schema 4.1, to be ready for the new version of the guidelines that are expected soon.
We have just found this thread, I’m really happy to see our assumptions about the benefit of this development confirmed by the community and I will be happy to contribute to develop a general solution that works for all and hopefully can be included by default in a next Dataverse version
 abollini
on 27 Feb 2018
abollini
on 27 Feb 2018
@abollini that's great news! Can you please also start a new thread about this at https://groups.google.com/forum/#!forum/dataverse-community to spread the word? Thanks!
pdurbin
on 27 Feb 2018
@abollini thanks for posting https://groups.google.com/d/msg/dataverse-community/OALTzINxkX0/v_WwJ4cvAwAJ ! Also, I mentioned your proposal in the Dataverse Community News yesterday: https://groups.google.com/d/msg/dataverse-community/AlZHT6tQM3U/0RrMUOv1AgAJ
Next it would be great to get a shared understanding of what you think the pull request will look like, what the scope of change will be. To get on the same page literally, it would be nice to have a Google doc or similar for what you have in mind. For now I'm linking to this issued in the "Dev Efforts by the Dataverse Community" spreadsheet at https://docs.google.com/spreadsheets/d/1pl9U0_CtWQ3oz6ZllvSHeyB0EG1M_vZEC_aZ7hREnhE/edit?usp=sharing but please feel free to create new issues as needed if you want to divide the work into smaller chunks. In our experience, smaller chunks move more easily across our kanban board at https://waffle.io/IQSS/dataverse
In short, please let us know if there is anything you need!
pdurbin
on 2 Mar 2018
We have created a PR with the result of our development: https://github.com/IQSS/dataverse/pull/4664/
we will be happy to receive feedback and improve it as needed
abollini
on 12 May 2018
@abollini hi! Thanks for the pull request! I just advanced it to Code Review at https://waffle.io/IQSS/dataverse and left you a review.
@juancorr are you interested in giving a review as well?
pdurbin
on 14 May 2018
Thanks Philip,
yes I am very interested. I will review it.
Juan Corrales
2018-05-14 2:43 GMT+02:00 Philip Durbin notifications@github.com:
@abollini https://github.com/abollini hi! Thanks for the pull request!
I just advanced it to Code Review at https://waffle.io/IQSS/dataverse and
left you a review.@juancorr https://github.com/juancorr are you interested in giving a
review as well?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/IQSS/dataverse/issues/4257#issuecomment-388668677,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AAT5CD1fkBu1ZqMjf69lOt1NmPOkEtYvks5tyNM4gaJpZM4QQ_o5
.
juancorr
on 14 May 2018
Great! Thanks @abollini and team for the PR, @pdurbin for the feedback, and @juancorr for taking a look!! :) I'll move this to Inbox column on our Waffle board for now, as it's a large PR there's already some feedback and community review offers.
 djbrooke
on 14 May 2018
djbrooke
on 14 May 2018
@abollini any news? Are you blocked? Do you need anything? @juancorr and I have been chatting a bit in IRC if you'd like to join us some day. 😄
pdurbin
on 23 May 2018
In 4b28306 I added "DataCite OpenAIRE" to the list of export formats. @djbrooke and I just spoke about how tests would be nice but they're tricky for external developers to write so I went ahead and moved this issue (and #3697) to QA.
pdurbin
on 29 May 2018
I haven't begun testing yet but during a test deployment, found that OpenAire was not appearing in export list and this error is in server log: Could not find key "dataset.exportBtn.itemLabel.dataciteOpenAIRE" in bundle file.
 kcondon
on 30 May 2018
kcondon
on 30 May 2018
@kcondon good catch. Fixed in 7c11bc0. Here's how it looks:

pdurbin
on 30 May 2018
@abollini @lap82 @francescopioscognamiglio @juancorr please take a look at the tests I added as of 5336e67. As of this writing OpenAireExportUtil.java, for example, has 51.79% code coverage, up from 0%. 😄 Here's how it looks in Netbeans:

pdurbin
on 31 May 2018
Thanks @pdurbin , I have just starting my war with code coverage tools (Ok, NetBeans is a good ally), I did not know it. I will see the tests. What is the right method to suggest more tests?.
juancorr
on 1 Jun 2018
@pdurbin @abollini @lap82 @francescopioscognamiglio I have added some new tests and have found two little bugs in openAIRE code related to geolocalization and the alternative title. Should I open a pull request to @abollini code for bugs and another pull request to main develop Dataverse branch for tests?.
juancorr
on 4 Jun 2018
@juancorr we try to work in small chunks so multiple pull requests sounds better. Thanks!
pdurbin
on 4 Jun 2018
Hi everyone,
Is there a crosswalk or any documentation I could peak at for this PR? It's really cool being able to poke at this work, but might be helpful if there's a crosswalk or something explaining how fields are being mapped.
For now, here are other potential problems I've seen with the OpenAIRE metadata in the PR as of last week. I'm not sure how important it is to fix many of these problems for this github issue, but I would argue that at least the first is considered and fixed:
- If any file is restricted, the rights property is "closedAccess." The definition of closedAccess, https://wiki.surfnet.nl/display/standards/info-eu-repo#info-eu-repo-AccessRights, is access "by financial means," or toll gated. restrictedAccess seems more appropriate.
But maybe it's best to try following how closedAccess and restrictedAccess are used by Zenodo (which doesn't use closedAccess as "toll gated"):
-- If any of the files in the dataset are restricted and the option to request access is enabled (people are allowed to request access), the dataset is restrictedAccess
-- If any of the files in the dataset are restricted and the option to request access is disabled, the dataset is closedAccess
- Dataverse's "language" field and OpenAIRE's "language" property should define the language of the resource (i.e. dataset). But here the Dataverse language field is being used to populate the xml language attributes of certain OpenAIRE fields:
`<title xml:lang="English">Historical Climate Model Output Of Echam5-Wiso From 1871-2011 At T106 Resolution</title>`
When a Dataverse depositor chooses English, she's saying that the dataset is in English. But this PR uses English to describe the language of the metadata as well, which isn't always true.
Could the xml attributes not be used for now?
It looks like the NameType attribute is always set to "personal" (as opposed to Organization) if there's a comma in the entry. But there being a comma doesn't guarantee that the entry is a personal name. nameType isn't mandatory. Can it be removed?
There might be an issue with the funder property and Dataverse's Grant Information field. I haven't had a chance to explore how the funder information in Dataverse's Grant Information fields are mapped to OpenAIRE.
Lastly, when OpenAIRE harvests the openaire set, are they getting the xml document that's in the metadata download pulldown or another xml document? I ask because the document in the pulldown points to DataCite's xml schema, but I would think that OpenAIRE has its own xml schema since it's doing things that DataCite's 4.0 schema would find invalid.Update: Just noticed that OpenAIRE does say that it expects metadata encoded "in the DataCite format (prefix oai_datacite)" (https://guidelines.openaire.eu/en/latest/data/use_of_oai_pmh.html). So I guess that means it's okay to point to DataCite's xml scheme. What's confusing me now is if it's okay to point to DataCite's 4.0 schema, when OpenAire is based on DataCite 3.1. For example, OpenAire uses DataCite's "funder" contributor role, which was deprecated by DataCite 4.0. Not sure if this will cause problems.
I hope this helps!
jggautier
on 4 Jun 2018
Since the purpose of this pull request is mainly to get Dataverse to export OpenAIRE complaint metadata so that OpenAIRE can harvest it, I'm adding OpenAIRE's validator page, https://www.openaire.eu/validator/welcome, which also includes a link to register your repository.
jggautier
on 4 Jun 2018
@jggautier I thought #4318 was about harvesting. This issue is about export.
pdurbin
on 4 Jun 2018
@jggautier @kcondon and I just talked this out. @jggautier is going to work on figuring out what work remains before this issue about OpenAIRE goes to QA.
pdurbin
on 4 Jun 2018
Thanks @jggautier,
I will try answer some points related to OpenAIRE compatibility. I hope can explain it in English.
Development done with #4318 allow Dataverse be compatible with OpenAIRE 4.0 guidelines which are in DRAFT version yet, but compatible dataverses or Dataverse installations should fill all required OpenAIRE metadata. I think that this development is compatible with current guidelines, but I have not checked it yet.
I think as @jggautier about nameType. It is not shown in guidelines http://openaire-guidelines-for-literature-repository-managers.readthedocs.io/en/latest/field_creator.html#dci-creator and is optional in xsd file: http://schema.datacite.org/meta/kernel-4.1/metadata.xsd
Funder information section have not a complete definition in OpenAIRE guidelines (which sections are mandatory): "Grant Agency" is mapped to "funderName" and "Grant Number" to "awardNumber" and xsd is validated.
A repository need be harvested to be OpenAIRE compliant.
juancorr
on 5 Jun 2018
@abollini @lap82 @francescopioscognamiglio please note that @juancorr has made a pull request against your pull request at https://github.com/4Science/dataverse/pull/4 to add some more tests.
pdurbin
on 5 Jun 2018
Thanks @juancorr. I'm hoping we can use @abollini's Google Groups thread to get a shared understanding of the scope of this issue, which will be helpful when it comes time to test this PR. Everyone who's interested, please feel free to add your thoughts. Thanks!
jggautier
on 5 Jun 2018
I just read through post by @jggautier above and it's a great summary of the conversation he, @kcondon and I had yesterday. @abollini @lap82 @francescopioscognamiglio @juancorr please take a look and let's talk about the scope of the pull request and how much more development needs be done before we advance it from code review to QA. Thanks! Others are welcome to comment as well, of course!
pdurbin
on 6 Jun 2018
@abollini what do you think?
pdurbin
on 11 Jun 2018
I need to get up to speed on this with @jggautier early this week, post Community Meeting. :)
@abollini @lap82 @francescopioscognamiglio @juancorr we should have some feedback soon.
djbrooke
on 18 Jun 2018
Thanks, @djbrooke, for discussing with me. We're looking forward to getting @abollini's input on:
- This PR's scope, written about in this Google Groups thread
- Metadata mapping concerns I wrote about earlier in this github issue and have been updating
- Concerns about how to test the PR. @juancorr wrote about problems with testing it that I'll follow up with (in the Google Groups thread)
jggautier
on 18 Jun 2018
Thanks @jggautier, moving back to Development until this feedback is implemented or responded to.
djbrooke
on 18 Jun 2018
Hey @abollini - any news? Let us know if there's anything we can do. Thanks!
djbrooke
on 25 Jun 2018
hi all,
sorry for the delay. We will try to reply to your comments by the end of next week at latest
abollini
on 27 Jun 2018
@abollini hi! Any news?
pdurbin
on 9 Jul 2018
Last week @jggautier indicated he's interested in trying something on a running server with the openaire branch on it. This morning I pinged @juancorr at http://irclog.iq.harvard.edu/dataverse/2018-07-16#i_70126 and he's going to set up a server for testing soon. Thanks!
While I'm writing, any news, @abollini ?
pdurbin
on 16 Jul 2018
I've been out for a week. Any news on this issue? I see @jggautier left a longish comment at https://github.com/IQSS/dataverse/pull/4664#issuecomment-405722192 but that was three weeks ago.
pdurbin
on 7 Aug 2018
@jggautier when you get a chance can you please summarize the status of this issue?
pdurbin
on 4 Jan 2019
Moving to the inbox until there's additional work on this.
djbrooke
on 4 Jan 2019
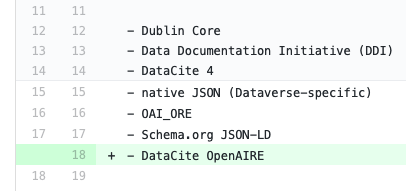
I just noticed that @fcadili resolved the merge conflicts in pull request #4664. Thanks!
Does that mean you are ready for code review? Please let us know how we can help. 😄
pdurbin
on 10 Apr 2019
@jggautier I spun up the branch (openaire-103925a) at http://ec2-100-27-31-230.compute-1.amazonaws.com:8080 if you'd like to poke around. The password is "admin1".
pdurbin
on 11 Apr 2019
Thanks @pdurbin! I'm trying to see the exported OpenAIRE metadata for a dataset, but when I try to export it, or export any metadata really, I get a "This site can’t be reached" page. Is it possible to export the OpenAIRE metadata?
jggautier
on 11 Apr 2019
@jggautier whoops! My fault! I hadn't configured dataverse.siteUrl. http://ec2-100-27-31-230.compute-1.amazonaws.com:8080/api/datasets/export?exporter=oai_datacite&persistentId=doi%3A10.5072/FK2/G251YB should now work, which is a link from Export Metadata at http://ec2-100-27-31-230.compute-1.amazonaws.com:8080/dataset.xhtml?persistentId=doi:10.5072/FK2/G251YB
pdurbin
on 11 Apr 2019
Yes, I'm working on it. I'm double checking to have applied the received feedback and I will comment on the PR about it that soon.
Thanks for reviewing it.
 fcadili
on 11 Apr 2019
fcadili
on 11 Apr 2019
@fcadili great! I just invited you to join https://github.com/orgs/IQSS/teams/dataverse-readonly/members . If you're ok being assigned to this issue, I'll move it from "Inbox" to "Community Dev" at https://waffle.io/IQSS/dataverse
pdurbin
on 11 Apr 2019
Thanks @fcadili for the updated PR. I'm assigning myself and @jggautier so that we can check out what was implemented from a metadata perspective. We may have some questions, but after that we'll move it along so a developer can review it. Thanks again!
djbrooke
on 12 Apr 2019
Thanks @fcadili! The concerns I had about funder, language and rightsList metadata seem resolved. Looks great!
The rules being used for figuring out the creator "nametype" seem to have changed. They seem to be:
- if Identifier Scheme is set to ORCID and there's a value in Identifier, "nametype" is set to "Personal"
- if there's an affiliation, "nametype" is set to "Personal"
- otherwise, "nametype" isn't used
The first rule is great I think, since it seems that ORCID is intended for only researchers. But I think the second rule will result in a lot of creators being tagged as "personal" when they're not. I see a lot of datasets in Dataverse repositories (and in non-Dataverse repositories harvested by Harvard Dataverse, like ICPSR and ODESI) where the author is an organization, and the affiliation field contains another organization, like the organization's host institution.
Sending metadata that indicates that an author is a person or an organization seems to be important (e.g. https://github.com/IQSS/dataverse/issues/5029, studies being done into authorship decisions, generating citations in different styles). I just don't know how tolerant of miscategorized creators we should be. DataCite uses an algorithm that we're told is right about 90% of the time.
jggautier
on 15 Apr 2019
Moving back to Community Dev for now. @fcadili let us know your thoughts on the above!
djbrooke
on 15 Apr 2019
I'm working on creator nametype in order to apply DataCite algorithm described in https://github.com/IQSS/dataverse/issues/2243#issuecomment-358615313. When done I will comment on the PR about it.
Thanks for reviewing it.
fcadili
on 16 Apr 2019
Thanks @fcadili. I saw the latest comment in your PR (https://github.com/IQSS/dataverse/pull/4664#issuecomment-484387154) about using that algorithm. Moving this to code review.
jggautier
on 18 Apr 2019
I just approved pull request #4664
A few things for QA:
- There's code in here having to do with first names so I'd suggest testing in this area. I added a couple more test in 03c959b because we have related code for Shibboleth. Please note that a couple large-ish files were added:
- 48,821 lines: src/main/resources/edu/harvard/iq/dataverse/firstNames/nam_dict.txt
- 32,469 lines: src/main/resources/edu/harvard/iq/dataverse/firstNames/yob2017.txt
- I find the UI slightly confusing because now there are two "DataCite" formats. I'll add some screenshots below.
Here's the UI:
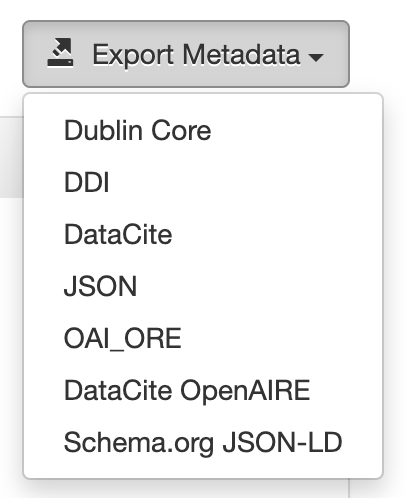
Note that in the guides we call the first one "DataCite 4":
pdurbin
on 22 Apr 2019
I find the UI slightly confusing because now there are two "DataCite" formats. I'll add some screenshots below.
Good point. It's OpenAIRE's spec, based on DataCite. Maybe: "OpenAIRE (DataCite)"?
(I'll open another issue about the mismatch between the guide's "native JSON (Dataverse-specific)" and the pull down menu's "JSON".)
jggautier
on 22 Apr 2019
I just approved pull request #4664
I just stumbled across these GitHub issues today, and am so happy to see this being done. I'm in the process of registering our Dataverse with a discovery layer, and the OpenAIRE DataCite schema will help with some of the issues I am having with using the DDI or DC metadata from the OAI feed (mainly the dataset rights).
I find the UI slightly confusing because now there are two "DataCite" formats. I'll add some screenshots below.
Good point. It's OpenAIRE's spec, based on DataCite. Maybe: "OpenAIRE (DataCite)"?
I like this name, makes sense to me!
 rreka
on 22 Apr 2019
rreka
on 22 Apr 2019
@fcadili @jggautier Hi, we're testing your OpenAire implementation and it's working pretty well over all. We did notice one issue: the nameType for the creator and contact does not function as expected: for creator, nameType=personal seems to always be true if identifier type is ORCID and the ORCID identifier is present, regardless of the name. For contact, nameType is always personal when there is an affiliation value, regardless of the name. What were your expectations for how the Datacite name recognition algorithm worked?
Thanks, Kevin
For example:
<creatorName nameType="Personal">The Institute For Quantitative Social Science</creatorName>
<nameIdentifier nameIdentifierScheme="ORCID">1234</nameIdentifier>
<affiliation>dataverse.org</affiliation>
</creator>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">The Institute For Quantitative Social Science</contributorName>
<affiliation>dataverse.org</affiliation>
For the fist example:
<creatorName nameType="Personal">The Institute For Quantitative Social Science</creatorName>
<nameIdentifier nameIdentifierScheme="ORCID">1234</nameIdentifier>
<affiliation>dataverse.org</affiliation>
</creator>
The nameType is set to personal since the ORCID identifier is present as described in #2243 (comment).
For the second example:
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">The Institute For Quantitative Social Science</contributorName>
<affiliation>dataverse.org</affiliation>
I will release a fix to handle nameType in proper way:
- nameType set to personal if contributorName has formats "Family Name, First Name" or "First Name Family Name", and First Name is a known name.
- Organizational otherwise.
fcadili
on 24 Apr 2019
@fcadili thanks! From the perspective of our kanban board at https://waffle.io/IQSS/dataverse this issue is in Community Dev but please let us know when it's ready for QA (when the nameType fix is ready or whatever). Also, if you have any questions about the code, please let us know! Thanks!
pdurbin
on 24 Apr 2019
@fcadili Thanks, I will test it when it's ready. Also thanks for the pointer to Martin's Datacite rules.
I should mention that when I had put my personal name, Kevin Condon or Condon, Kevin as both creator (author) and contact, it did not select as personal until I added an affiliation. I'll retest and add an example.
kcondon
on 24 Apr 2019
@fcadili I'm not sure whether you are finished but since the commits are quiet I decided to do a quick test.
From Martin's comment these are the conditions for personal:
- we have familyName metadata
- we have an ORCID ID
- the author is in the format familyName, givenName
- the author is in the format givenName familyName and the givenName is in a dictionary of first names.
Practically speaking it seems that 1. is not something we can check directly since the field contains both first and last name. I can test cases 2,3,4, and 4 being the case you'd fixed.
Here is what I found:
Case 2. we have an ORCID ID:
This works as expected for creator when ORCID ID is present. Minor side issues, likely can ignore, if ORCID type is selected but no id, still says personal for creator. If the same user was determined to be personal based on ORCID ID and exists in contact, it is not automatically also set as personal. I know the fields are not connected so this is understandable. Just noting it to see whether we care about it. The contact could be the same name but use an institutional email, etc.
<creatorName nameType="Personal">ABCD</creatorName>
<nameIdentifier nameIdentifierScheme="ORCID">1234</nameIdentifier>
</creator>
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">ABCD</contributorName>
</contributor>
Case 3. the author is in the format familyName, givenName:
Smith, John as author (creator) and contact and no affiliation or identifier has no nameType as author (creator) but has Organization nameType for contact. Wouldn't both names be detected as personal using the lastname, firstname format?
<creator>
<creatorName>Smith, John</creatorName>
</creator>
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">Smith, John</contributorName>
</contributor>
Case 4. the author is in the format givenName familyName and the givenName is in a dictionary of first names:
Wouldn't in both cases the name John be detected? Is there some configuration I need to make that I have missed?
<creator>
<creatorName>John Smith</creatorName>
</creator>
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">John Smith</contributorName>
</contributor>
Please let me know if I am misinterpreting the detection rules or whether there was some other decision made that I've missed. Thanks! Kevin
Meant to include @djbrooke @jggautier
kcondon
on 24 Apr 2019
I will check the code using your example and add some unit test to verify its result.
Thanks for reviewing it.
fcadili
on 24 Apr 2019
At standup I volunteered to make a couple small tweaks agreed upon at standup this morning. The commit is 3a8247c04
We changed the button label to just "OpenAIRE" like this:
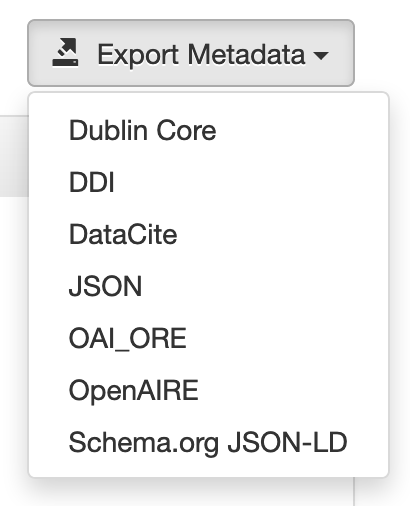
We also noticed that the list of exported formats was in both the Admin Guide as a bulleted list and the User Guide as a non-list. @jggautier and I decided to make the User Guide authoritative (since it's a user-facing feature) and now we link from the Admin Guide to the User guide.

pdurbin
on 25 Apr 2019
I'm moving this back to code review for now and assigning myself for some further review.
I'm unsure if we should implement the algorithm on the Dataverse side. I think we should export the values without additional processing and let the export's consumer implement any desired algorithms.
Will discuss with @jggautier and @mercecrosas, but other thoughts welcome.
djbrooke
on 25 Apr 2019
The key bit of information I learned at standup this morning is that nameType is optional. So, we could simply remove it. That is, we would change this...
<creators>
<creator>
<creatorName nameType="Personal">Finch, Fiona</creatorName>
<givenName>Fiona</givenName>
<familyName>Finch</familyName>
<nameIdentifier nameIdentifierScheme="ORCID">0000-0002-9528-9470</nameIdentifier>
<affiliation>Birds Inc.</affiliation>
</creator>
</creators>
... to this (removing nameType)...
<creators>
<creator>
<creatorName>Finch, Fiona</creatorName>
<givenName>Fiona</givenName>
<familyName>Finch</familyName>
<nameIdentifier nameIdentifierScheme="ORCID">0000-0002-9528-9470</nameIdentifier>
<affiliation>Birds Inc.</affiliation>
</creator>
</creators>
.. and this...
<contributors>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">Finch, Fiona</contributorName>
</contributor>
</contributors>
... to this (again, removing nameType)...
<contributors>
<contributor contributorType="ContactPerson">
<contributorName>Finch, Fiona</contributorName>
</contributor>
</contributors>
Someday it would be nice to implement Martin's algorithm, especially to fix #5029 ("Improving Dataverse's JSON-LD schema to enable author names display in Google Dataset Searches"). Once we have the algorithm in place, implemented in a central location, we can apply it to multiple places in the code, rather than just nameType for OpenAIRE. I think the algorithm should make suggestions to dataset metadata editors to improve dataset quality rather than manipulating data we send across the wire to DataCite or that Google pulls across the wire from Dataverse. That said, it doesn't make sense to suggest edits ("We think this is an organization rather that a person. Do you agree?") until Dataverse supports the concept of indicating than certain fields (author, contact, depositor, etc.) are a person or not. We'd need to store this extra information in our database. And present a nice UI to the users, a checkbox for "person" or a slider that slides between "person" and "organization" or something.
pdurbin
on 25 Apr 2019
@jggautier - passing this back to you.
@mercecrosas and the OpenAIRE folks are OK with adding the algorithm, and Merce suggested that we should expect similar things in the future in efforts to support and expand data curation.
Can you lead on getting this PR through any additional changes/code review/QA? Also we should talk about future issues that cover any additional information we need to provide in exports about noting generated vs. curator-added values.
djbrooke
on 29 Apr 2019
@fcadili @jggautier @djbrooke @pdurbin
Update on testing:
The current issues still exist in the algorithm:
x 1. It does not detect personal nameType for creator (author) when there is no ORCiD id but the name is in last, first format:
<creator>
<creatorName>Smith, John</creatorName>
<affiliation>Dataverse.org</affiliation>
</creator>
x 2. It does not detect personal nameType for creator (author) when there is no ORCiD id but the name is in first last, with first presumably in the dictionary:
<creator>
<creatorName>John Smith</creatorName>
</creator>
x 3. It does not detect personal nameType for contributor (contact) but instead chooses organizational when the name is in last, first format:
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">Smith, John</contributorName>
<affiliation>Dataverse.org</affiliation>
</contributor>
x 4. It does not detect personal nameType for contributor (contact) but instead chooses organizational when name is in first last format and name presumably is in the dictionary:
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">John Smith</contributorName>
</contributor>
x 5. It does not detect personal nameType for contributor (contributor) when name is in last, first format:
<contributor contributorType="DataCollector">
<contributorName>Smith, John</contributorName>
</contributor>
x 6. It does not detect personal nameType for contributor (contributor) when name is in first last name format and name presumably is in dictionary:
<contributor contributorType="DataCollector">
<contributorName>John Smith</contributorName>
</contributor>
Update from Julian: Kevin and I tested this and we found the following works:
Anytime ORCiD chosen, regardless of whether the ORCiD ID is entered or valid (16 characters with dashes), it identifies the nameType as "Personal". I'm okay with this behavior because selecting ORCiD indicates intent, even when an ID isn't entered, and the outcome is what's expected:
<creator>
<creatorName nameType="Personal">Smith, John</creatorName>
<givenName>John</givenName>
<familyName>Smith</familyName>
<nameIdentifier nameIdentifierScheme="ORCID">1234-1234-1234-1234</nameIdentifier>
</creator>
<creator> <--ORCiD is selected, but no ID is entered.-->
<creatorName nameType="Personal">Smith, John</creatorName>
<givenName>John</givenName>
<familyName>Smith</familyName>
</creator>
<creator>
<creatorName nameType="Personal">Smith, John</creatorName>
<givenName>John</givenName>
<familyName>Smith</familyName>
<nameIdentifier nameIdentifierScheme="ORCID">1234</nameIdentifier>
</creator>
This is great. Thanks @kcondon.
I'm worried that there's another conversation happening in the associated PR that's relevant but maybe not being considered. Could we keep the conversation in this GitHub issue?
@fcadili, you wrote in the PR last week:
I posted an updated version of the code that resolve @kcondon questions.
nameType attribute is still used, but it can be removed when needed.
Do you mean that the PR currently includes a way for individual installations to not use the algorithm? If so, how do we choose if it's optional or not? Or do you mean that it's possible to add this functionality later on?
we still need to establish that creatorName is a person, since elements givenName and familyName have to be generated.
Could you write more about this? If nameType isn't specified, why does the givenName and familyName have to be generated?
jggautier
on 30 Apr 2019
The question was related to making nameType optional. The reply was that it can be removed if required, but since we have to generate givenName and familyName when needed the alghorith is still required.
For @kcondon question I wrote a junit test for points 2, 4 and it works as expected. Points 1, 3 should work whereas 5 and 6 probably not. I'll double check all suggested test case and fix the code as needed.
fcadili
on 2 May 2019
I released a new version: the problem was related to resource files that was not deployed with dataverse.war. I checked all @kcondon examples and all seems work fine.
fcadili
on 2 May 2019
@fcadili I've confirmed your latest fix fixes all the issues I've reported. Thanks! Kevin
kcondon
on 2 May 2019
Thanks @fcadili and @kcondon. @djbrooke and @scolapasta agreed that for now we won't have to worry about implementing a way to turn off the algorithm.
But when you write that "we have to generate givenName and familyName when needed," I don't understand why. Could you share where you see this requirement?
jggautier
on 2 May 2019
The requirements I found are described in datacite profile:
- creatorType is recommended for Author and Creator;
- givenName and familyName are optional for Creator and recommended for Author.
fcadili
on 3 May 2019
Thanks @fcadili
jggautier
on 3 May 2019
@fcadili Now that the personal nameType issues seem to be resolved I focused on testing organizational type names. I've found some issues here (see below) but also wondered what the logic for detecting organizational types was.
- Simple one or two word names are not identified as either type, except when contact:
<creators>
<creator>
<creatorName>IBM</creatorName>
</creator>
<creator>
<creatorName>Harvard University</creatorName>
</creator>
</creators>
<contributors>
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">Harvard University</contributorName>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Organizational">IBM</contributorName>
</contributor>
<contributor>
<contributorName>IBM</contributorName>
</contributor>
<contributor>
<contributorName>Harvard University</contributorName>
</contributor>
</contributors>
- More complex, multi word names always are identified as personal and the extraction of first, last names is unusual in some cases:
<creator>
<creatorName nameType="Personal">The Institute for Quantitative Social Science</creatorName>
<givenName>The</givenName>
<familyName>Institute for Quantitative Social Science</familyName>
</creator>
<creator>
<creatorName nameType="Personal">Council on Aging</creatorName>
<givenName>on</givenName>
<familyName>ncil on Aging</familyName>
</creator>
<creator>
<creatorName nameType="Personal">The Ford Foundation</creatorName>
<givenName>The Ford</givenName>
<familyName>Foundation</familyName>
</creator>
<creator>
<creatorName nameType="Personal">
United Nations Economic and Social Commission for Asia and the Pacific (UNESCAP)
</creatorName>
<givenName>Asia the</givenName>
<familyName>
tions Economic and Social Commission for Asia and the Pacific (UNESCAP)
</familyName>
</creator>
<creator>
<creatorName nameType="Personal">Michael J. Fox Foundation for Parkinson's Research</creatorName>
<givenName>Michael Fox</givenName>
<familyName>ox Foundation for Parkinson's Research</familyName>
</creator>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">Council on Aging</contributorName>
<givenName>on</givenName>
<familyName>ncil on Aging</familyName>
<affiliation>Dataverse.org</affiliation>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">The Institute for Quantitative Social Science</contributorName>
<givenName>The</givenName>
<familyName>Institute for Quantitative Social Science</familyName>
<affiliation>[email protected]</affiliation>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">The Ford Foundation</contributorName>
<givenName>The Ford</givenName>
<familyName>Foundation</familyName>
<affiliation>[email protected]</affiliation>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">
United Nations Economic and Social Commission for Asia and the Pacific (UNESCAP)
</contributorName>
<givenName>Asia the</givenName>
<familyName>
tions Economic and Social Commission for Asia and the Pacific (UNESCAP)
</familyName>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">Michael J. Fox Foundation for Parkinson's Research</contributorName>
<givenName>Michael Fox</givenName>
<familyName>ox Foundation for Parkinson's Research</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">
United Nations Economic and Social Commission for Asia and the Pacific (UNESCAP)
</contributorName>
<givenName>Asia the</givenName>
<familyName>
tions Economic and Social Commission for Asia and the Pacific (UNESCAP)
</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">The Institute for Quantitative Social Science</contributorName>
<givenName>The</givenName>
<familyName>Institute for Quantitative Social Science</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">Council on Aging</contributorName>
<givenName>on</givenName>
<familyName>ncil on Aging</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">
United Nations Economic and Social Commission for Asia and the Pacific (UNESCAP)
</contributorName>
<givenName>Asia the</givenName>
<familyName>
tions Economic and Social Commission for Asia and the Pacific (UNESCAP)
</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">The Ford Foundation</contributorName>
<givenName>The Ford</givenName>
<familyName>Foundation</familyName>
</contributor>
<contributor>
<contributorName nameType="Personal">Michael J. Fox Foundation for Parkinson's Research</contributorName>
<givenName>Michael Fox</givenName>
<familyName>ox Foundation for Parkinson's Research</familyName>
</contributor>
</contributors>
I released a new version which fixed Organizational nameType. I've checked all @kcondon examples and they work fine with the new version.
fcadili
on 6 May 2019
Thanks @fcadili - we'll review this and QA it.
djbrooke
on 6 May 2019
@fcadili Thanks for fixing these. I've retested the org cases and they all work. We did test a few more actual organizations depositing on Dataverse and found a few that did not work. Is this because of the characters, ',' and '-'? Should we look for more examples?
Here are the failing cases:
1.Some org creators with nameType as personal, some with no nameType:
<creator>
<creatorName nameType="Personal">
Digital Archive of Massachusetts Anti-Slavery and Anti-Segregation Petitions, Massachusetts Archives, Boston MA
</creatorName>
</creator>
<creator>
<creatorName nameType="Personal">
U.S. Department of Commerce, Bureau of the Census, Geography Division
</creatorName>
</creator>
<creator>
<creatorName>Harvard Map Collection, Harvard College Library</creatorName>
<affiliation>Harvard University</affiliation>
</creator>
<creator>
<creatorName>Geographic Data Technology, Inc. (GDT)</creatorName>
</creator>
- Some contact fields with nameType as personal:
<contributorName nameType="Personal">
Digital Archive of Massachusetts Anti-Slavery and Anti-Segregation Petitions, Massachusetts Archives, Boston MA
</contributorName>
</contributor>
<contributor contributorType="ContactPerson">
<contributorName nameType="Personal">
U.S. Department of Commerce, Bureau of the Census, Geography Division
</contributorName>
</contributor>
- Some contributor with nameType as personal, some no type:
<contributor contributorType="DataCollector">
<contributorName nameType="Personal">
Digital Archive of Massachusetts Anti-Slavery and Anti-Segregation Petitions, Massachusetts Archives, Boston MA
</contributorName>
</contributor>
<contributor contributorType="DataCollector">
<contributorName nameType="Personal">
U.S. Department of Commerce, Bureau of the Census, Geography Division
</contributorName>
</contributor>
<contributor contributorType="DataCollector">
<contributorName>Harvard Map Collection, Harvard College Library</contributorName>
</contributor>
</contributors>
<contributor>
<contributorName>Geographic Data Technology, Inc. (GDT)</contributorName>a
</contributor>
I think if these are fixed then we will be in good shape. Sorry I did not see these sooner. We'll discuss briefly with @djbrooke and @jggautier tomorrow morning to confirm.
kcondon
on 6 May 2019
I released a new version which fixes Operational nameType when the name contains commas or dashes. I've checked the latest @kcondon examples and they work fine with the new version.
fcadili
on 7 May 2019
@fcadili @jggautier @djbrooke
I've retested the latest test cases and all are working now. I think this shows both org and personal nameType are functioning reasonably well. I'm ok to merge unless we want a more comprehensive test such as looking at all orgs in prod. I think there was a plan to iterate once we gain more experience in prod?
kcondon
on 7 May 2019
Thanks @kcondon, I'll briefly check in with @jggautier and give the go ahead here in a few.
Thanks @fcadili for the great responsiveness and quick fixes on this!
djbrooke
on 7 May 2019
Thank you.
fcadili
on 7 May 2019
@kcondon merge away!
djbrooke
on 7 May 2019
Related issues
 poikilotherm
·
4Comments
poikilotherm
·
4Comments
 atrisovic
·
3Comments
atrisovic
·
3Comments
 BPeuch
·
3Comments
jggautier
·
4Comments
BPeuch
·
3Comments
jggautier
·
4Comments
 bsilverstein
·
4Comments
bsilverstein
·
4Comments