Dataverse: Create Dataset: add support for migrating (with existing DOIs) via native API
One of the SBGrid migration requirements is to move the existing datasets, along with their DOIs, into Dataverse. Currently, it appears that this can only be done using the DDI XML import.
 bmckinney
bmckinney
All 75 comments
@bmckinney will create a new pull request to handle these two remaining items:
- Dataverse theme
- Dataset DOI
As of 4.5, one should be able to set the license via native API.
 pdurbin
on 15 Sep 2016
pdurbin
on 15 Sep 2016
@bmckinney I just added a34239c to your "sbgrid-migrate-doi" branch and created pull request #3377. At https://waffle.io/IQSS/dataverse I put this issue in Code Review. Please let me know if we can advance it to QA. Thanks!
pdurbin
on 22 Sep 2016
Also, I wanted to mention that setting a Dataverse theme was added by @sekmiller in 92e89d0 which already made it into 4.5. I'm taking @bmckinney 's word that it works properly. He seems satisfied with it at least.
@bmckinney again, when you have a minute, please let me know if a34239c looks ok and I'll send this to QA in Waffle.
pdurbin
on 22 Sep 2016
This is one of the two issues (the other being #3371) that @djbrooke @bmckinney and I all agree we'd like to get into 4.6 so I'm adding that milestone.
pdurbin
on 23 Sep 2016
This looks great to me and ready for QA!
bmckinney
on 23 Sep 2016
At https://waffle.io/IQSS/dataverse I just pulled this issue and associate pull request out of QA and into development because when you try to publish one of these datasets that has an existing DOI you get { "status": "ERROR", "message": "This dataset may not be published because it has not been registered. Please contact Dataverse Support for assistance."}
@sekmiller recommends setting globalidcreatetime to "now" so that's what I'll try.
pdurbin
on 28 Sep 2016
I just pushed a fix at 1740879 to pull request #3377 so that datasets migrated via JSON are able to be published (now exercised via an API test). @sekmiller reviewed and blessed the change.
At https://waffle.io/IQSS/dataverse I moved this issue and pull request back to QA.
pdurbin
on 28 Sep 2016
I've discussed this ticket with Phil and the scope is implementing import for datasets using json, specifically for SBGrid. There are known limitations: it does not support datasets with multiple versions, files, supports only doi, and it is a super user only feature.
 kcondon
on 14 Oct 2016
kcondon
on 14 Oct 2016
@pdurbin When you have a minute, can you share the api endpoint syntax for this as well as what the json format should be? I have a json export for a fully populated dataset and would like to use that to test this but likely it would need some tweaking.
kcondon
on 17 Oct 2016
Adding "importType=migration" as a query parameter to the regular "add dataset with JSON" curl command and using "dataset-finch2.json" from https://github.com/IQSS/dataverse/pull/3377/files should do the trick. Sorry for not mentioning this earlier! Possible values for "importType" (which is new) are "migration", "new", and "harvest". The query parameter "separator" is also new and defaults to "/". (The separator is between the "authority" and the "identifier".)
pdurbin
on 17 Oct 2016
I've found a few bugs that exist in this branch but not in production:
- creating a dataset as non super user does not grant dv defined access perms to creator, ie they have no direct perms on the dataset the just created, does not see draft card. This is most obvious in root dv where the user is likely not an admin.
- non super users can specify a doi when creating a dataset, this should be super user only.
- importType modes, including default, appear to do nothing: can specify doi in all, sets globalidcreatetime in all, not just migration.
- create dataset api endpoint does not accept dv alias in addition to id.
- the separator query parameter does not seem to set the doiseparator value in the dataset table.
kcondon
on 19 Oct 2016
@bmckinney @scolapasta @djbrooke @mheppler met today today to discuss this and other SBGrid-related issues. Notes are at https://docs.google.com/document/d/1VeD4mEUMb7qMT2_KSswEDTksTBTVpUi2gIR5PoduQMI/edit?usp=sharing
Two things are at issue:
- What do with pull request #3377
- What to do with this issue
We talked about three options for pull request #3377:
- Option 1: Do not merge to core. Bill builds his own war file (compostable fork) just long enough to perform a migration and then switches to an official (non-forked) version of Dataverse when migration is complete.
- Option 2: Merge pull request 3377 more or less as is now, accepting some technical debt.
- Option 3: Do all the work of a more complete migration story with no technical debt.
We decided on option 1, which means that we will close pull request #3377 though I did do a bit of cleanup at bede18b to fix some of the bugs @kcondon raised above to better reflect what @bmckinney and I envisioned for the pull request. Ideally, we'd keep the branch around if we ever want to pick up and work on option 3.
What is option 3 exactly? All the work. Well imagine "the idea is to replace Fedora with Dataverse" from https://groups.google.com/d/msg/dataverse-community/VjTHzWjP4NU/mPGOObw2BgAJ . Let's say someone wants to migrate from Fedora Commons or DSPace or some other popular platform to Dataverse. They're going to need a way to migrate their data into Dataverse and importing via high fidelity Dataerse-native JSON makes much more sense than DDI, which is so social science specific. Also, harvesting is out of scope for this story so I removed this from the issue title. Back to the backlog this issue goes in https://waffle.io/IQSS/dataverse
pdurbin
on 20 Oct 2016
"We need this to import existing datasets with DOIs into Dataverse. For that, the two options are to either import via OAI-PMH or to create the dataset with a "test" DOI and then change it to the "real" one via SQL." -- @adam3smith at https://groups.google.com/d/msg/dataverse-community/qmFQK5_sZoA/dNotwpkQAgAJ
pdurbin
on 26 Jun 2017
@adam3smith if you want to create a new issue for your use case, please go ahead. I'm closing this one. Thanks!
Folks reading this should note that the code at https://github.com/IQSS/dataverse/compare/sbgrid-migrate-doi that we didn't end up merging still might have some value.
pdurbin
on 29 Jun 2017
@pameyer thanks for kicking off the "approaches to migrating datasets with existing PIDs?" thread at https://groups.google.com/d/msg/dataverse-community/j1D8Fy9FJbc/PSjpvRrkAwAJ today and talking it through with me afterwards.
As I mentioned, since pull request #3377 was never merged (I think I was leaning toward Option 2 above, to just merge that thing) one thing you could try is a two phase approach of:
- phase 1: import via DDI - use the supported method for migrating a DVN 3 study to a Dataverse 4 dataset. Here's the integration test I mentioned (roundTripDdi method): https://github.com/IQSS/dataverse/blob/v4.8.5/src/test/java/edu/harvard/iq/dataverse/api/BatchImportIT.java#L117
- phase 2: replace using native JSON - once the dataset has the DOI you want, replace the metadata using native JSON. It works but please just be aware that it's quite confusing (see #3777).
I hope this helps. Maybe it's not a great idea. Perhaps it's something to try. 😄
(By the way, the original idea with the "roundTripDdi" method above is that you should be able to take DDI XML and create a dataset with it and then export the DDI XML and it should match. This method was named before we implemented DDI export in #2579. I never did revisit this code to make sure it really works but I kind of doubt it. That is to say, I expect the XML in and XML out is slightly different. I don't know.)
pdurbin
on 24 Jan 2018
BatchImportIT turns out to be one of the (presumably known) failing integration tests; but it looks like starting there is enough to track down how to use that API (although I haven't gotten that far yet).
 pameyer
on 25 Jan 2018
pameyer
on 25 Jan 2018
@pameyer cool, that was my hope, that it would show how to use that API. I'm not surprised the test fails. Thanks for taking a look.
pdurbin
on 25 Jan 2018
After some investigation of @pdurbin's suggestion (take advantage of existing import with DDI to support creating a dataset with an existing PID), it appears that "import via DDI" would need additional dev work (so probably no advantage over previous approach).
- export test dataset from DV as DDI
- change PID (to avoid identifier conflicts)
- copy DDI XML to DV application server, ensure readable by glassfish user. attempted to validate against DDI codebook; ran into problems, https://github.com/IQSS/dataverse/issues/3648 suggested that attempting to validate DDI prior to DV import would not be helpful.
curl -X GET -H "content-type: application/atom+xml" -H "X-Dataverse-key: ${ADMIN_KEY}" "http://localhost:8080/api/batch/migrate/?dv=${EXISTING_DV_ALIAS}&path=/tmp/ddi2.xml"(nothing in docs, so followed @pdurbin 's suggestion for tracking down arguments).- enormous stack track from
ImportServiceBean.doImportwhen calling create dataset command.
Current / tentative evaluation: import via DDI appears no longer supported; suggesting that work-around isn't a viable alternative.
pameyer
on 26 Jan 2018
@pameyer huh. That's bad news if import via DDI is truly broken because that's the path for DVN 3 installations to upgrade to Dataverse 4. I guess if one of the few remaining DVN 3 installations runs into that error and stacktrace, we can fix up import then. Sorry to send you down a fruitless path. 😞
I still recommend option 2 above, which is this: "Option 2: Merge pull request #3377 more or less as is now, accepting some technical debt." We'd need to merge the latest from develop in and resolve merge conflicts, of course.
@adam3smith what's your status on migrating datasets? I see you commented above. Are you all set?
pdurbin
on 26 Jan 2018
We're almost done, yes. We have a small collection so we did the following:
- With the API set to the EZID testing API, we manually ingested all our data&files
- We then replaced the DOIs in the database and moved the files (this was Gustavo's recommendation and it worked well).
- We'll then switch the EZID API to the regular one.
I don't think this will work for migrating into an already existing dataverse where you can't just switch to the testing API, though.
 adam3smith
on 26 Jan 2018
adam3smith
on 26 Jan 2018
@adam3smith interesting. Thanks. I see what you mean. You haven't gone live yet.
pdurbin
on 26 Jan 2018
From my notes on discussion earlier today:
- modify create dataset to take PID as parameter
- require admin user
- check to confirm that PID already exists (fail if not)
Assumption is that existing APIs are sufficient for importing package files. Some additional DB cleanup may be required (publication date, etc). Discussion of disabling pre-publish/post-publish workflows, general agreement to treat that as out of scope (and probably un-necessary for this particular case).
pameyer
on 13 Feb 2018
I heard at standup today that @michbarsinai may be working on this issue. Awesome. For the benefit of @pameyer who I had asked to look at BatchImportIT above, I wanted to mention that in b8090f0 I made the roundTripDdi test more sane. In that test we create a dataset using DDI XML (this is how one migrates from DVN 3 to Dataverse 4) and then we make assertions on the DDI we export from the created dataset.
pdurbin
on 27 Feb 2018
I indeed plan to work on this. Importing may add a more standardized way of migrating from dvn 3.x: Convert the DDIs to the migration JSON (using some command-line tool or so), and then import as usual. This will also allow us to reduce application size, by moving migration-specific code to an external project.
 michbarsinai
on 27 Feb 2018
michbarsinai
on 27 Feb 2018
Any ideas if correcting dataset.globalidcreatetime will violate assumptions Dataverse makes?
pameyer
on 7 Mar 2018
At standup today it was mentioned that code is starting to be written for this issue. @landreev sounded curious, as was I, and here's the branch: https://github.com/IQSS/dataverse/compare/3083-support-migration-with-dois
pdurbin
on 2 Apr 2018
Moving the "backlog" column just for organizational purposes.
 djbrooke
on 10 Apr 2018
djbrooke
on 10 Apr 2018
@michbarsinai any news?
pdurbin
on 31 May 2018
In progress. Currently blocked waiting for PR 4651, but it should be merged soon.
On 31 May 2018, at 14:25, Philip Durbin notifications@github.com wrote:
@michbarsinai https://github.com/michbarsinai any news?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-393499842, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJIokf2p_VRhYcyxkQhel8tgLP64pks5t39MVgaJpZM4IM3nw.
michbarsinai
on 31 May 2018
@michbarsinai thanks. Pull request #4651 was just merged so you're welcome, of course, to start resolving merge conflicts. Please be aware that the API test suite is failing after that pull request was merged and we are using #4725 to track the work of fixing it.
pdurbin
on 1 Jun 2018
Will do. Thanks for the heads up!
On 1 Jun 2018, at 3:58, Philip Durbin notifications@github.com wrote:
@michbarsinai https://github.com/michbarsinai thanks. Pull request #4651 https://github.com/IQSS/dataverse/pull/4651 was just merged so you're welcome, of course, to start resolving merge conflicts. Please be aware that the API test suite is failing after that pull request was merged and we are using #4725 https://github.com/IQSS/dataverse/issues/4725 to track the work of fixing it.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-393727181, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJLtpZnrA8EWpyzRtYm0HkUnwHBVaks5t4JG0gaJpZM4IM3nw.
michbarsinai
on 1 Jun 2018
@michbarsinai just a heads up that on Friday I fixed all the problems with the API test suite and closed #4725 so if you merge the latest from the "develop" branch into your branch the API tests should pass. Thanks!
pdurbin
on 5 Jun 2018
OK, Passing back to Code Review.
michbarsinai
on 11 Jun 2018
@michbarsinai this is a large enough refactoring (122 files changes) that it would be helpful if you would please summarize what you're up to with pull request #4606. The scope of this issue is more than supporting migration with existing DOIs, right? @landreev and I have been saying for a while that at the very least the title of this issue should be updated but a comment on the refactoring would be very welcome as well.
pdurbin
on 11 Jun 2018
@michbarsinai at standup this morning I said I'd link you to the part of the dev guide that explains how to run all the integration tests. Please see "To run the full suite of integration tests on your laptop, we recommend using the “all in one” Docker configuration described in conf/docker-aio/readme.txt." at http://guides.dataverse.org/en/4.9/developers/testing.html
The current process involves a few steps but you're welcome to try the newer streamlined approach in pull request #4727
On a related note, @pameyer just ran the test suite and found several failures: https://github.com/IQSS/dataverse/pull/4606#issuecomment-396359907 with a bottom line of Tests run: 72, Failures: 8, Errors: 2, Skipped: 0.
pdurbin
on 11 Jun 2018
The main task is really still the same: Allow importing of published datasets that have DOIs. At the moment, we only support packages, but the design could be extended to support files as well.
The large-ish nature of PR #4606 is due to the fact that instead of bolting more code on an already complex part of the application, @scolapasta and I have decided to refactor the area into multiple commands, and remove legacy and migration code. E.g instead of a single CreateDatasetCommand, we now have CreateHarvestedDatasetCommnad, CreateNewDatasetCommand, ImportDatasetCommand, and a base class. There were also some changes to the PID/DOI/GlobalId subsystem, which coincided with two other changes to that area (#898 and #3585) which cause further delay.
I think the clean up was much needed - see the deletion vs addition for PR #4606. It deletes almost as much as it adds.
michbarsinai
on 17 Jun 2018
would it be possible to separate the price into two: one which is only the refactoring of the old code, and another that contains the new functionality? this would likely make reviewing easier.
 oscardssmith
on 17 Jun 2018
oscardssmith
on 17 Jun 2018
No way. The whole point of the refactoring was to not add the functionality to the code at the state it was in.
On 17 Jun 2018, at 14:21, oscardssmith notifications@github.com wrote:
would it be possible to separate the price into two: one which is only the refactoring of the old code, and another that contains the new functionality? this would likely make reviewing easier.
—
You are receiving this because you were assigned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-397872027, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJCvRIA38G0jLn3ojlfVEO7s8iCAMks5t9jvQgaJpZM4IM3nw.
michbarsinai
on 17 Jun 2018
my point was to put the refactoring commit first, and then on top of that add the functionality in a separate commit. the theory is that it is much easier to review a pure refactoring, as you know it shouldn't be changing anything. then once the refactor is in, the feature change is a much smaller diff, allowing the reviewer to focus on the new functionally
oscardssmith
on 17 Jun 2018
I mentioned at standup this morning that @michbarsinai is having a little trouble running the integration tests and that @pameyer and I are helping him.
pdurbin
on 18 Jun 2018
I just ran the API test suite in docker-aio on d5f4636 and now there's only one failure:
Failed tests: testCuratorSendsCommentsToAuthor(edu.harvard.iq.dataverse.api.InReviewWorkflowIT): JSON path data.inReview doesn't match.(..)
Tests run: 72, Failures: 1, Errors: 0, Skipped: 0
pdurbin
on 18 Jun 2018
Line 287 of InReviewWorkflowIT is has .body("data.inReview", equalTo(false)) but true is being returned. Here's more context of the failing test:
// Successfully return dataset to author for reason: "You forgot to upload any files."
String comments = "You forgot to upload any files.";
jsonObjectBuilder.add("reasonForReturn", comments);
Response returnToAuthor = UtilIT.returnDatasetToAuthor(datasetPersistentId, jsonObjectBuilder.build(), curatorApiToken);
returnToAuthor.prettyPrint();
returnToAuthor.then().assertThat()
.body("data.inReview", equalTo(false))
.statusCode(OK.getStatusCode());
@michbarsinai it seems like the lock isn't being cleared after the curator sends comments to the author. Do you know why this is?
pdurbin
on 18 Jun 2018
Talked with @michbarsinai and @pameyer about this on the Helmsley Call.
@pameyer you mentioned you'd take an initial look and then let us know when it's ready to hit QA so @kcondon can take a look.
@michbarsinai sounds like we should fix the test @pdurbin mentioned in the previous comment.
djbrooke
on 18 Jun 2018
@djbrooke Hopefully the fixes in #4727 have already solved it.
michbarsinai
on 18 Jun 2018
I'm seeing the same Failed tests: testCuratorSendsCommentsToAuthor(edu.harvard.iq.dataverse.api.InReviewWorkflowIT): JSON path data.inReview doesn't match.(..) in docker-aio (2x w\ same container, 2x containers - does not appear to be docker / setupIT glitches)
pameyer
on 18 Jun 2018
@djbrooke Hopefully the fixes in #4727 have already solved it.
@michbarsinai no. To be clear, I was testing d5f4636 which is the most recent commit. Any ideas on why the behavior changed in your pull request?
pdurbin
on 19 Jun 2018
@pdurbin no idea. I'll look into it later today. I had it failing and then working again without me changing anything, so I assumes it was a Docker setup issue. Might have missed something, though.
michbarsinai
on 19 Jun 2018
@michbarsinai awesome. Thanks! At standup @landreev said he's available if you have any questions about locks.
pdurbin
on 19 Jun 2018
@michbarsinai any news? Are you blocked?
pdurbin
on 22 Jun 2018
I just ran this branch on our phoenix server. Here are the results: https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ . 9 failures, they all look reasonable to be in connection with the change.
I think this branch was close enough to develop that running it as I did shouldn't have caused environmental issues, but I may be wrong.
Let me know if there details around this folks want me to investigate.
 matthew-a-dunlap
on 26 Jun 2018
matthew-a-dunlap
on 26 Jun 2018
Great. Will you be able to post the server log somewhere? At the moment, we have one machine with a single failure, one with 29, and phoenix coming in second with 9. I'm still trying to make sense of it, so a log would be very helpful (I hope).
Thanks,
Michael
On 26 Jun 2018, at 19:46, matthew-a-dunlap notifications@github.com wrote:
I just ran this branch on our phoenix server. Here are the results: https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ . 9 failures, they all look reasonable to be in connection with the change.
I think this branch was close enough to develop that running it as I did shouldn't have caused environmental issues, but I may be wrong.
Let me know if there details around this folks want me to investigate.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-400384895, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJDmRck4bvCz-9paR7i3HFQ-zCL-wks5uAmV4gaJpZM4IM3nw.
michbarsinai
on 26 Jun 2018
@michbarsinai There are some segments of the logs in the results on here: https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/testReport/ . If you need deeper we can go on the box and pull them out!
matthew-a-dunlap
on 26 Jun 2018
https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ looks to be commit e12cc477b0668eb78483f1d1a2153a1dd53a0db9 , which might not be the latest for this branch.
For 97d2803aec329fceccaa2ee0b38c487802528e4c ; the one failure I'm seeing is Failed tests: testCuratorSendsCommentsToAuthor(edu.harvard.iq.dataverse.api.InReviewWorkflowIT): JSON path data.inReview doesn't match.(..)
@michbarsinai - which commit are you seeing 29 failures on?
pameyer
on 26 Jun 2018
97d2803aec329fceccaa2ee0b38c487802528e4c
The test you mention failed on my machine as well, back when there was only a single failure.
@matthew-a-dunlap: Thanks. These are the client logs, if possible, I need the server ones to see what goes wrong at the server side.
On 26 Jun 2018, at 20:23, pameyer notifications@github.com wrote:
https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ https://build.hmdc.harvard.edu:8443/job/phoenix.dataverse.org-apitest-develop/201/ looks to be commit e12cc47 https://github.com/IQSS/dataverse/commit/e12cc477b0668eb78483f1d1a2153a1dd53a0db9 , which might not be the latest for this branch.
For 97d2803 https://github.com/IQSS/dataverse/commit/97d2803aec329fceccaa2ee0b38c487802528e4c ; the one failure I'm seeing is Failed tests: testCuratorSendsCommentsToAuthor(edu.harvard.iq.dataverse.api.InReviewWorkflowIT): JSON path data.inReview doesn't match.(..)
@michbarsinai https://github.com/michbarsinai - which commit are you seeing 29 failures on?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-400396445, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJI-zWbzNOL_giDYF8DKL8nsccQaRks5uAm4ggaJpZM4IM3nw.
michbarsinai
on 26 Jun 2018
@michbarsinai I don't seem to have access to ssh onto phoenix, someone else on our team will have to help with that
matthew-a-dunlap
on 26 Jun 2018
@matthew-a-dunlap it's not great to use phoenix for branches other than "develop" because now it looks like "develop" is broken:
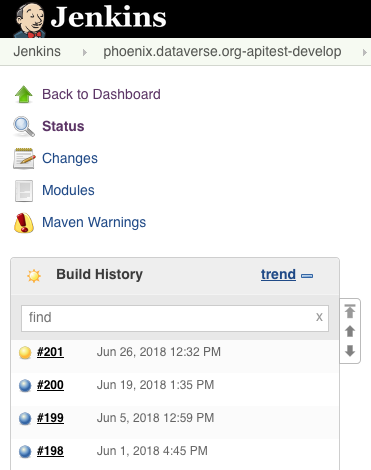
Recently @landreev and I discussed how we need more than one server for running API tests.
I believe that my comment from https://github.com/IQSS/dataverse/issues/3083#issuecomment-398179562 is still current as well as my question: @michbarsinai it seems like the lock isn't being cleared after the curator sends comments to the author. Do you know why this is?
pdurbin
on 27 Jun 2018
We needed the run on Pheonix to get "another opinion", as the API test results on Pete's machine and on my machine were very different (21 failures vs 1). Pheonix got 7 errors, so that didn't help :-)
I'll look into the lock issue - thanks for the diagnosis. Still unsure why this is happening though. Any pointers regarding the varying test results?
On 27 Jun 2018, at 17:41, Philip Durbin notifications@github.com wrote:
@matthew-a-dunlap https://github.com/matthew-a-dunlap it's not great to use phoenix for branches other than "develop" because now it looks like "develop" is broken:
https://user-images.githubusercontent.com/21006/41981230-6c4111a0-79f6-11e8-8cd2-3223c617ad73.png
Recently @landreev https://github.com/landreev and I discussed how we need more than one server for running API tests.I believe that my comment from #3083 (comment) https://github.com/IQSS/dataverse/issues/3083#issuecomment-398179562 is still current as well as my question: @michbarsinai https://github.com/michbarsinai it seems like the lock isn't being cleared after the curator sends comments to the author. Do you know why this is?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-400697583, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJJcv9lnhDCbP5rMypIkqIDsWcqfOks5uA5mTgaJpZM4IM3nw.
michbarsinai
on 27 Jun 2018
@michbarsinai I got a brain dump from @pameyer after standup this morning. Let me spend a few minutes on this and report back.
pdurbin
on 27 Jun 2018
Ok, indeed, as of the latest commit (97d2803) there are 7 API failing tests in the 3083-support-migration-with-dois branch (the one for pull request #4606) as judged by the run @matthew-a-dunlap and I just did on phoenix:
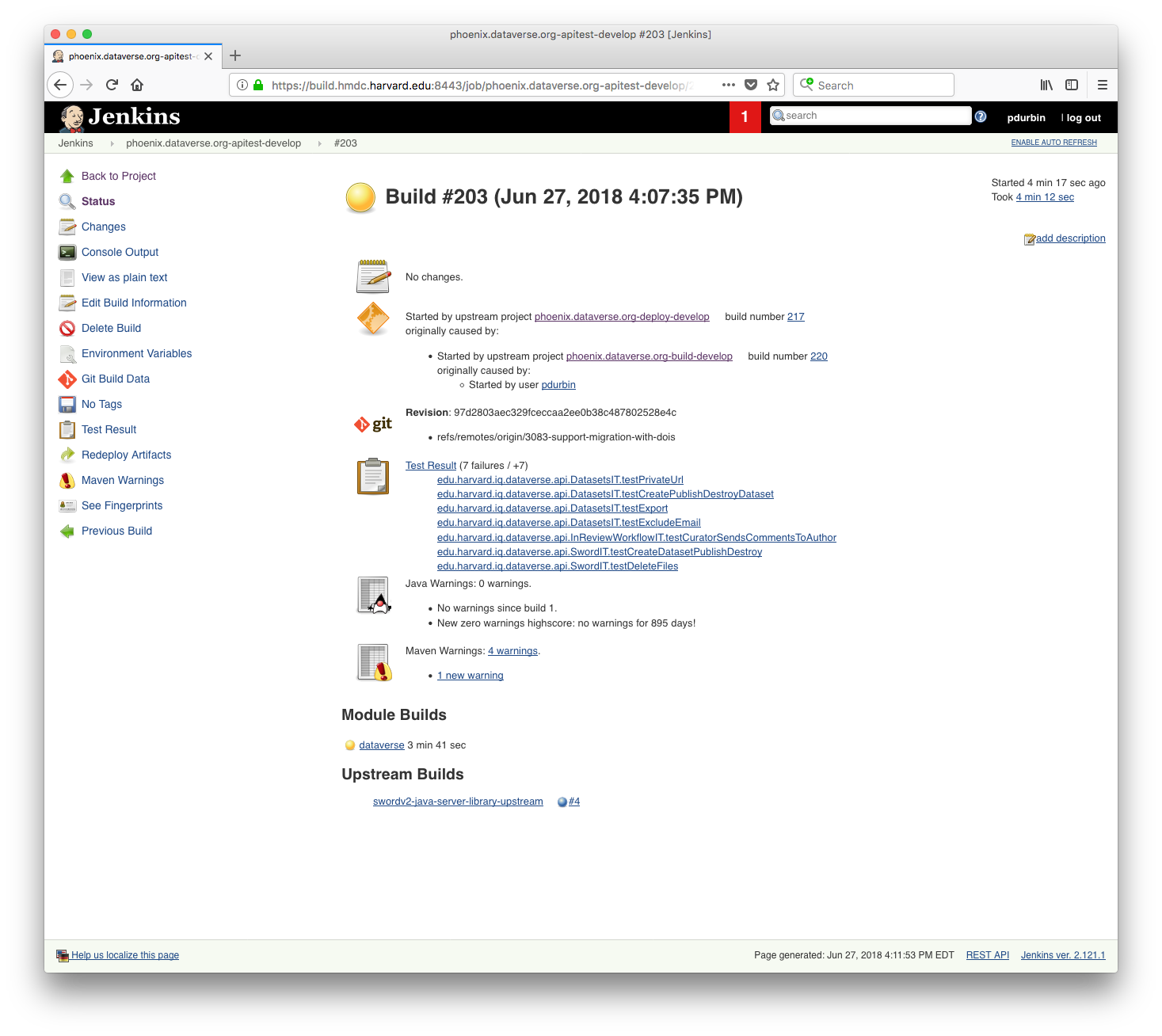
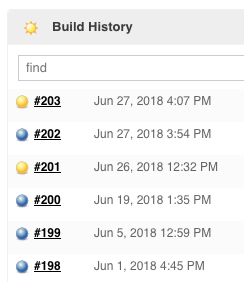
I should mention that just prior to the test above (job 203) we established a baseline using the "develop" branch to make sure that it's still passing (job 202):
So now someone needs to fix the following failing tests:
edu.harvard.iq.dataverse.api.DatasetsIT.testPrivateUrl
edu.harvard.iq.dataverse.api.DatasetsIT.testCreatePublishDestroyDataset
edu.harvard.iq.dataverse.api.DatasetsIT.testExport
edu.harvard.iq.dataverse.api.DatasetsIT.testExcludeEmail
edu.harvard.iq.dataverse.api.InReviewWorkflowIT.testCuratorSendsCommentsToAuthor
edu.harvard.iq.dataverse.api.SwordIT.testCreateDatasetPublishDestroy
edu.harvard.iq.dataverse.api.SwordIT.testDeleteFiles
@michbarsinai do you need some help with this? I don't have an explanation as to why you have 21 failures on your laptop but phoenix only shows 7 in your branch.
pdurbin
on 27 Jun 2018
Ok, as suggested by @pameyer and @matthew-a-dunlap we're doing another run on phoenix to see if the number of failing tests is still 7. Strangely, @pameyer reported that the number of failing tests on that commit (97d2803) was 1 for him: https://github.com/IQSS/dataverse/issues/3083#issuecomment-400396445
pdurbin
on 27 Jun 2018
Thanks. I'll look into this and report. If there's any relevant background experience with the tests acting inconsistently, I'll be grateful if you could refer me to it. Also - any idea how come @pameyer got only a single failure for the same commit?
On 27 Jun 2018, at 23:18, Philip Durbin notifications@github.com wrote:
Ok, indeed, as of the latest commit (97d2803 https://github.com/IQSS/dataverse/commit/97d2803aec329fceccaa2ee0b38c487802528e4c) there are 7 API failing tests in the 3083-support-migration-with-dois branch (the one for pull request #4606 https://github.com/IQSS/dataverse/pull/4606) as judged by the run @matthew-a-dunlap https://github.com/matthew-a-dunlap and I just did on phoenix:
https://user-images.githubusercontent.com/21006/41997208-4c18ad3c-7a25-11e8-88f4-b0a488b1142b.png
I should mention that just prior to the test above (job 203) we established a baseline using the "develop" branch to make sure that it's still passing (job 202):https://user-images.githubusercontent.com/21006/41997257-79b919b6-7a25-11e8-807f-c4b69cbafbc4.png
So now someone needs to fix the following failing tests:edu.harvard.iq.dataverse.api.DatasetsIT.testPrivateUrl edu.harvard.iq.dataverse.api.DatasetsIT.testCreatePublishDestroyDataset edu.harvard.iq.dataverse.api.DatasetsIT.testExport edu.harvard.iq.dataverse.api.DatasetsIT.testExcludeEmail edu.harvard.iq.dataverse.api.InReviewWorkflowIT.testCuratorSendsCommentsToAuthor edu.harvard.iq.dataverse.api.SwordIT.testCreateDatasetPublishDestroy edu.harvard.iq.dataverse.api.SwordIT.testDeleteFiles@michbarsinai https://github.com/michbarsinai do you need some help with this? I don't have an explanation as to why you have 21 failures on your laptop but phoenix only shows 7 in your branch.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-400815344, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJITU_D7FiKHAP8OtmTcz3sjp1QTDks5uA-ixgaJpZM4IM3nw.
michbarsinai
on 27 Jun 2018
Thanks. Interestingly, the one test that failed there was involving the issues with the locks and journal workflow. So that seems to be an applicative issue (starts digging)
michbarsinai
on 27 Jun 2018
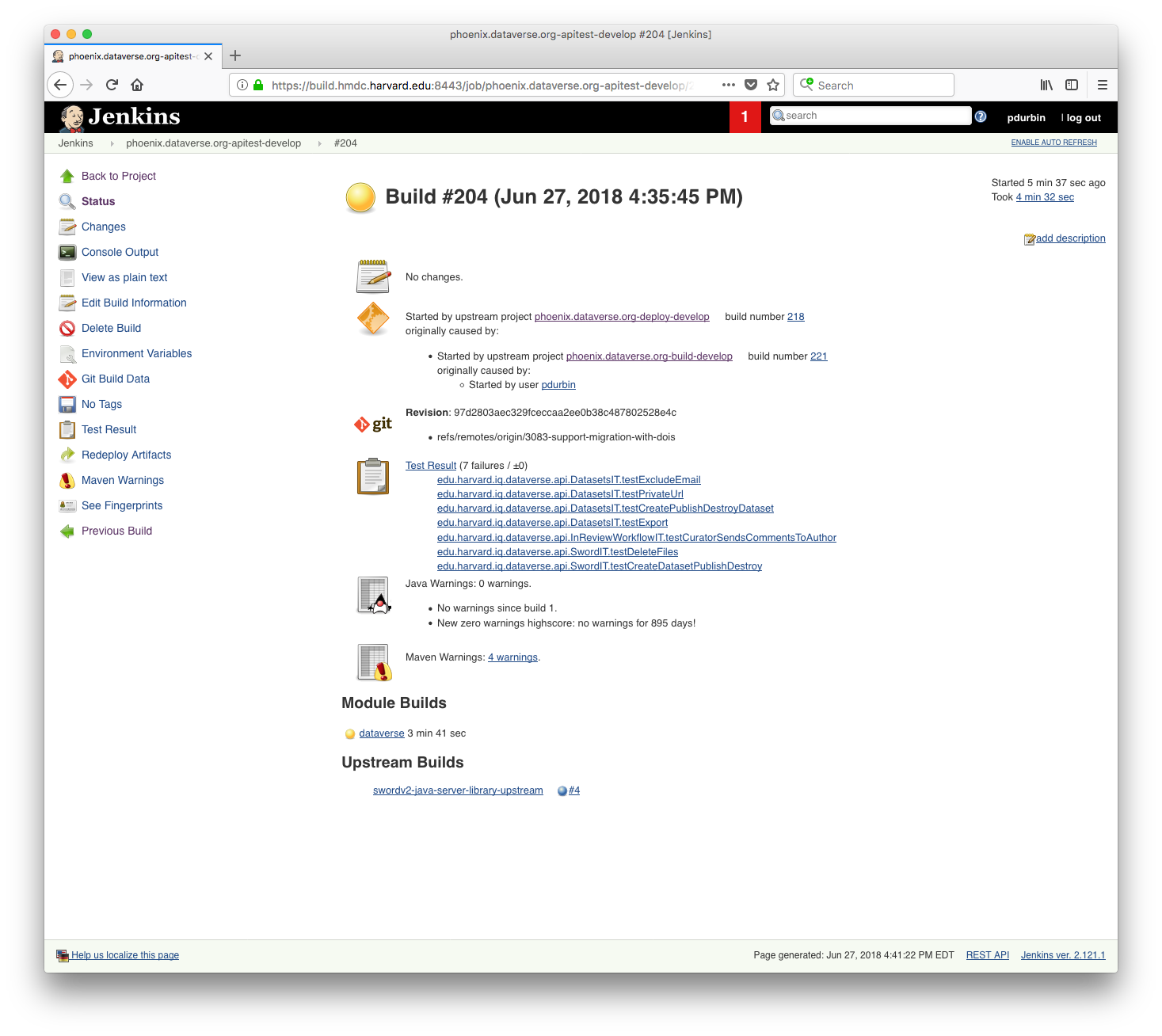
Ok, the same 7 tests continued to fail on the second run on phoenix of 97d2803:
pdurbin
on 27 Jun 2018
That's good (the stability, not the failures :-)). What about @pameyer 's laptop?
michbarsinai
on 27 Jun 2018
@pameyer said he ran the tests twice. I gotta run but maybe we can recruit @matthew-a-dunlap to run the test suite on his laptop. 😄
pdurbin
on 27 Jun 2018
I was running in docker-aio; 2x repeats of building the image and running conf/docker-aio/run-test-suite.sh 2x (aka - total 4x runs).
pameyer
on 27 Jun 2018
For something non-test related, any suggestions on the open question about "what should a user importing datasets specify as the storage identifier for imported package files?" ?
pameyer
on 29 Jun 2018
OK, basic regression testing works: create, update, publish datasets, harvest.
Tested basic import, both release and not release, handles and dois, including files and that works.
To effectively use this endpoint, some documentation and guidance is needed.
A bit more testing is needed around metadata blocks but generally completed.
Here are the issues and recommendations:
[x] Provide importable sample json files, simple, complex.
This would help shorten learning curve and help eliminate issues.[x] Storage identifiers.
These need to be specified for any files being imported. Internally we use a system generated string that becomes a pointer to a file (ie. filename) on the storage system (local disk, S3, Swift). What is the expected format for this id? Are there any constraints or limitations? For instance, must be a valid filename or reference in the storage system being used, must be unique within a dataset.[x] Document guidance on importing files.
Importing a dataset using json is only part of the process to import files. When using local file system storage, the storage identifier along with the dataset identifier, and the configured files directory, specify a file system location. The actual files need to be placed there for this to work. Also, care should be taken with respect to specifying actual file size, md5, file type for each file.[x] Document how to import a package file versus a single file.
[x] File PID behavior may be unexpected so should be changed or documented.
File PIDs are ignored in import json.
File PIDs are automatically generated based on currently configured authority and protocol and scheme (dependent/independent) on dataset publish as they are now. This may not be desired or expected behavior. This should either be changed or documented.[ ] Provide file system checks to ensure file integrity.
To ensure file integrity on import, it was suggested that files be in place at time of import and that import would check whether the storage identifier could be used to access the file and the file size and possibly the md5 are accurate.[x] Document Imported Dataset PID limitations.
Imported Dataset PIDs need to be resolvable by Dataverse (ie. published hdl or doi) at import or it will fail.
If the imported PID namespace (authority) is different the one Dataverse is configured to use, it will import as long as it is resolvable by Dataverse but may have expected follow on behavior.[x] Imported PIDs that use a different protocol or authority than Dataverse are imported if resolvable but then do not update PID metadata on subsequent update and publish.
[x] Documentation needs to give example of how to specify the PID in json in addition to command line. Sample file provides info but example uses outdated authority/identifier format before shoulder was moved from authority into identifier.
[ ] Import using PID in json file does not work, throws error.
kcondon
on 11 Jul 2018
Thanks, @kcondon.
We have some documentation, I'll see what can be improved (@pameyer - do you have anything?).
As for files, I think this is out-of-scope for #3083, which concentrates on packages. Files can be added later based on this work.
michbarsinai
on 11 Jul 2018
I do - @michbarsinai do you want first crack at native-api.rst, or should I do a first pass?
pameyer
on 11 Jul 2018
If you could give it a pass today, that would be great. I'll take a pass at it tomorrow morning (yay timezones!)
On 12 Jul 2018, at 0:17, pameyer notifications@github.com wrote:
I do - @michbarsinai https://github.com/michbarsinai do you want first crack at native-api.rst, or should I do a first pass?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/IQSS/dataverse/issues/3083#issuecomment-404312592, or mute the thread https://github.com/notifications/unsubscribe-auth/AB2UJDoF6ZKgb2xrpptRuqKSisfzrTdsks5uFmuHgaJpZM4IM3nw.
michbarsinai
on 11 Jul 2018
Ok - I gave it a first pass.
pameyer
on 12 Jul 2018
Gave it another pass. Added PID data to the JSON etc.
We now return to @kcondon at IQSS Central.
michbarsinai
on 12 Jul 2018
OK, I've added checkboxes to my list. Doc looks good, will check on files issues, and one remaining issue is doc how to specify pid in json. I tried using the sample file that was added but got this error:
{"status":"ERROR","message":"Please provide a persistent identifier, either by including it in the JSON, or by using the pid query parameter."}
kcondon
on 12 Jul 2018
One summery note on this: the automated integration tests ("docker-aio") were a crucial part of making sure this rather wide refactoring works. Kudos to @pdurbin for creating and maintaining them, and to @djbrooke for deciding we make sure they all pass before proceeding to manual testing.
michbarsinai
on 15 Jul 2018
Related issues
 shlake
·
4Comments
shlake
·
4Comments
 poikilotherm
·
4Comments
poikilotherm
·
4Comments
 Fernand0S
·
4Comments
Fernand0S
·
4Comments
 BPeuch
·
4Comments
BPeuch
·
4Comments
 bsilverstein
·
3Comments
bsilverstein
·
3Comments