Dataverse: Code Deposit - Github Integration
Zenodo now provides a really convenient way to archive a Github repository, using git tags (i.e., Github releases). This is a really convenient way to attach a DOI to a Github repository. Being able to do the same with Dataverse would be awesome.
The reason I thought of it is that I was considering building a layer into the R client that would make it convenient to archive a version of a local git repository using the Dataverse SWORD API, but if this was all implemented natively within Dataverse that would probably be even better.
 leeper
leeper
All 21 comments
@leeper yes, this is something we've been considering, and you are right that Zenodo does this very well. Thanks for pointing it out and creating the issue.
 mercecrosas
on 16 Nov 2015
mercecrosas
on 16 Nov 2015
:+1:
mercecrosas
on 16 Nov 2015
I mentioned to @christophergandrud this morning that @leeper had opened this issue. At some point we should all put our heads together on this. 😄
 pdurbin
on 13 Jan 2017
pdurbin
on 13 Jan 2017
@leeper @christophergandrud shoot, we should have talked about this during the Community Meeting! @leeper now that you've added the "dataverse" package to CRAN, do you have any more thoughts on this issue? How can we unblock it?
pdurbin
on 25 Jun 2017
From an API perspective, this should be pretty easy because it's just a matter of doing git checkout on the appropriate tag, zipping the contents (sans the .git folder) and dumping to the right SWORD endpoint.
It might make sense in the user interface as a plugin (as @pdurbin and I talked about for the Dropbox add file dialog) that does this from a specified git repo.
leeper
on 25 Jun 2017
@leeper maybe I'm just hearing what I want to hear, but are you saying that you think it's possible to implement this feature entirely client-side, such as within https://github.com/IQSS/dataverse-client-r ? If so, can we move this issue to that repo?
pdurbin
on 25 Jun 2017
Let me try to make an example using R and then feedback to this issue about how well that goes.
leeper
on 25 Jun 2017
Nonetheless, it would be great if this was ultimately language agnostic.
(Sorry, off topic, but honestly my dream would be if Dataverse could act as a remote git repository).
 christophergandrud
on 26 Jun 2017
christophergandrud
on 26 Jun 2017
@christophergandrud interesting. I guess supporting git would be language agnostic. Yes, this is all off topic but please see my "A Thought Experiment: Datasets As Git Repos" at https://docs.google.com/document/d/18WDIS8hrFJvMJBcnRuQ8NfD-VxGq32vJ9WwlEgyyWZs/edit?usp=sharing which I originally shared at https://groups.google.com/d/msg/dataverse-community/5zJrr03R9ZE/6ahp8ZgQwt8J .
@leeper I see you opened https://github.com/IQSS/dataverse-client-r/issues/16 . Thanks! Please keep us posted.
pdurbin
on 26 Jun 2017
An example of a real-world use case, from our notes on a UX interview we conducted with an Astrophysics librarian in 2016 that touched on this issue:
The researchers she works with primarily use Zenodo because of its GitHub integration. “Zenodo has a hook into GitHub. If you’re putting your code on GitHub, you can mint a DOI for a release of your code, and then it’ll be indexed by the Astrophysics Data System (which is like the Pubmed of Astronomy).” The researcher’s software is required to process the data, which is in the form of FITS images. You need the images AND the code for the data to be meaningful.
 dlmurphy
on 26 Jun 2018
dlmurphy
on 26 Jun 2018
@leeper I keep thinking about the diagram you showed at the Dataverse Community Meeting (from https://osf.io/xfj5h/ ), how there was a mix of code and non-code (data.csv, paper, slideshow, website, citations, etc) in what I understand to be the recommendation for organizing your dataset in your field. For this "code deposit" feature, are you thinking you'd want anything that looks like this or are you thinking that you'd want a "code only" dataset that doesn't have your data, your paper, your slides, etc? Here's the diagram:
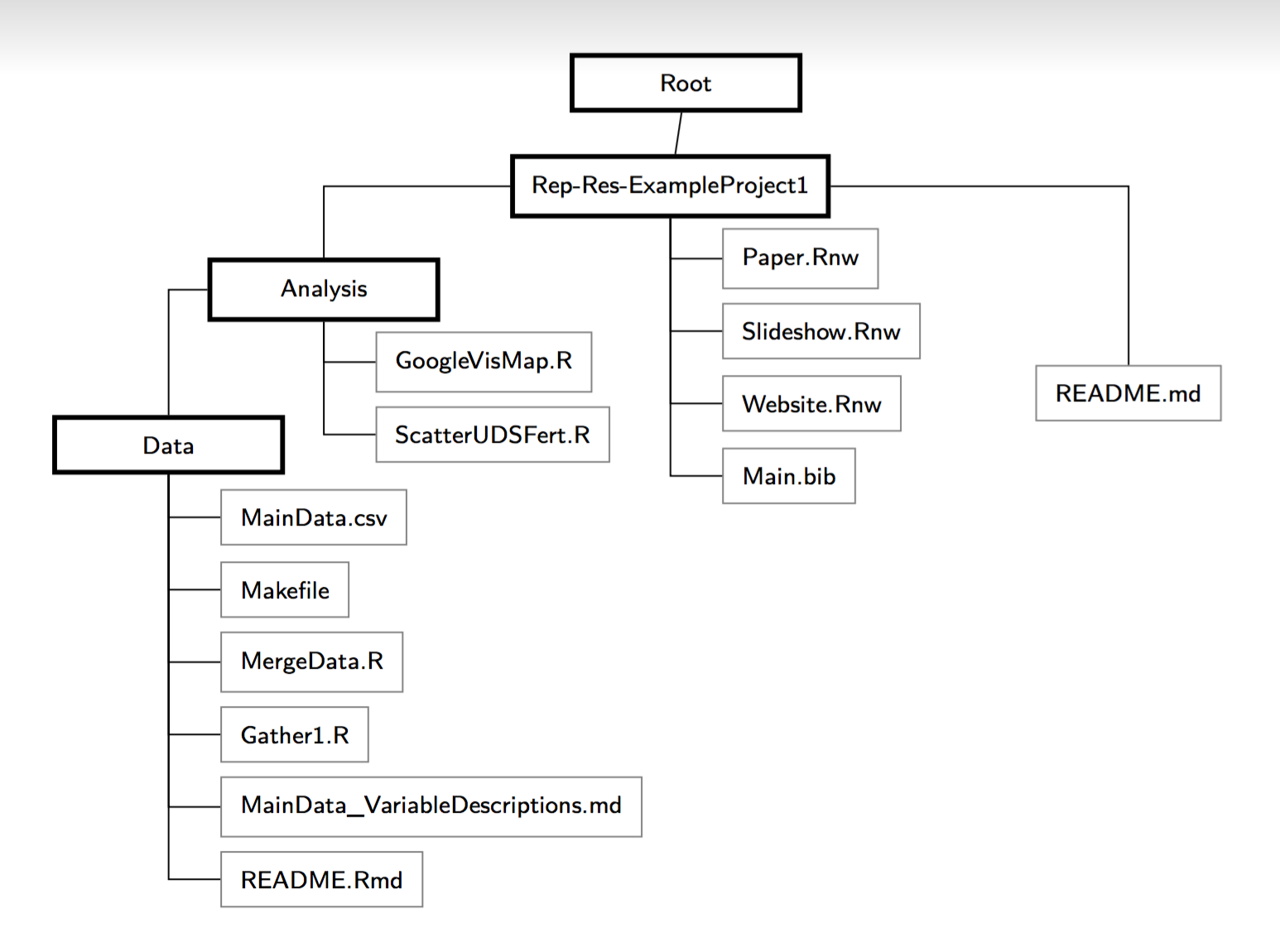
Others are welcome to comment on how this feature should work as well! I'm just asking Thomas since he opened it. 😄
pdurbin
on 28 Jun 2018
I'd want to deposit the whole project with folder/file hierarchies into single dataset.
leeper
on 28 Jun 2018
@leeper cool, thanks. Would https://github.com/leeper/rio be a good example of a repo that you'd consider depositing into Dataverse if/when this feature were available? Or are there other repos that would be better examples?
pdurbin
on 28 Jun 2018
Here is in excellent example from epidemiology on Zika data and code (of
which I was in a presentation last week):
https://github.com/cdcepi/zika
In this case, either this entire GitHub would become a dataset, keeping the
file hierarchy and everything. Alternatively, each folder could become a
separate dataset (and keeping the hierarchy within each folder). To
determine this, the user would need to specify what is preferred.
Zenodo uses the entire GitHub repo to generate one "dataset" (or data
package or software package, whatever we choose to call it) and maintains
the hierarchy. Here it is for the same Zika data:
https://zenodo.org/record/584136#.WzU4rxJKhTY
Mercè Crosas, Ph.D., Chief Data Science and Technology Officer, IQSS, Harvard
University
@mercecrosas https://twitter.com/mercecrosas
scholar.harvard.edu/mercecrosas
On Thu, Jun 28, 2018 at 1:48 PM, Philip Durbin notifications@github.com
wrote:
@leeper
https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_leeper&d=DwMCaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=M39IA2qLYEPCf8zlPxF92R4wrCkfmuMhwm4HoUykSPg&s=iGDgsyRYAI5eQLUQSW4Ai250pCuKvR7_zlfcNlg0H28&e=
cool, thanks. Would https://github.com/leeper/rio
https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_leeper_rio&d=DwMCaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=M39IA2qLYEPCf8zlPxF92R4wrCkfmuMhwm4HoUykSPg&s=QX6v0i6ROMXzItHmpmMM4TIzOk3kgNMTh4BbKCMAjIY&e=
be a good example of a repo that you'd consider depositing into Dataverse
if/when this feature were available? Or are there other repos that would be
better examples?—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_IQSS_dataverse_issues_2739-23issuecomment-2D401118491&d=DwMCaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=M39IA2qLYEPCf8zlPxF92R4wrCkfmuMhwm4HoUykSPg&s=JHtASQFP9d2Dg1eF_OJeoyHaBSiMkDwdAarWIAUq5N8&e=,
or mute the thread
https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_notifications_unsubscribe-2Dauth_AApQyMmQiBKdVfqmx-5FFa76PDv5fKKT3Tks5uBRcKgaJpZM4GioWR&d=DwMCaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=M39IA2qLYEPCf8zlPxF92R4wrCkfmuMhwm4HoUykSPg&s=4nKfpzGUY-ppQ7HT2jX5wF-dPrq5AIfmnAS2t5wc9VY&e=
.
mercecrosas
on 28 Jun 2018
Here's our design team's document for summarizing what we know about this issue and considering next steps:
https://docs.google.com/document/d/1Wa8OJBftzJs_v9QDeccRanx6S0MNoiuPjqnRaL20cNk/edit
dlmurphy
on 11 Jul 2018
A couple things:
- rOpenSci just published a blog post called "Building Reproducible Data Packages with DataPackageR" that says, "When a manuscript is submitted based on a specific version of a data package, one can make a GitHub release and automatically push it to sites like zenodo so that it is permanently archived." https://ropensci.org/blog/2018/09/18/datapackager/
- "Papers with code" seems like an interesting dataset that's highly related to this issue: https://github.com/zziz/pwc . I wonder if we should ask @zziz if there are any plans to publish this dataset in a repository.
Hat tip to @amoeba from @whole-tale for putting both of these on my radar!
pdurbin
on 20 Sep 2018
Dear @pdurbin, dataset is already available on the repository as a CSV file. But I don't recommend to use it just yet. I have very recently started this project and there are some works yet to be finished. You are welcome to use is it right now, but I recommend to check back in a month.
 zziz
on 20 Sep 2018
zziz
on 20 Sep 2018
My 2 cents to this: please keep in mind (at least for later extension):
- Compatibility to GitLab Webhooks
- Reuse standardization efforts: https://research-software.org/citation (informations about CFF and CodeMeta)
 poikilotherm
on 8 Nov 2018
poikilotherm
on 8 Nov 2018
Please let me bring to your attention that there are efforts to integrate GitLab with Zenodo (based on Invenio at CERN). Maybe the changes needed at the GitLab side could be usefull for or even aligned with Dataverse?
See especially this comment.
poikilotherm
on 21 Dec 2018
I promised @ethomson and @neovintage from GitHub that I would link up the notes from the fantastic meeting we had with them today. Here they are: https://groups.google.com/d/msg/dataverse-community/uEJRcNoghjY/RVnXkuxoBgAJ
pdurbin
on 14 Feb 2020
Heads up that @djbrooke and @jggautier discussed this briefly today, as this is related to #7077.
Please see my notes, including a link to a doc by marvelous @jggautier where he describes what still needs to be done to provide this feature.
poikilotherm
on 10 Aug 2020
Related issues
 bsilverstein
·
4Comments
poikilotherm
·
3Comments
bsilverstein
·
4Comments
poikilotherm
·
3Comments
 Fernand0S
·
4Comments
Fernand0S
·
4Comments
 lmaylein
·
3Comments
lmaylein
·
3Comments
 raprasad
·
5Comments
raprasad
·
5Comments
Most helpful comment
A couple things:
Hat tip to @amoeba from @whole-tale for putting both of these on my radar!