Darktable: make darktable 3.0 use a different database
Many bugs have affected the 2.6 and 2.7 database migration to 3.0, between styles, pipeline order, etc. I fear we will not have time to defuse all the bombs before release, or at least we should consider what to do if we can't.
Once the db migration 2.x -> 3.x is done, there is no coming back and darktable 2.x will not run on a 3.x DB.
As a safety measure, I propose darktable 3.0 series copies the 2.x library.sql database to library-3.sql and update the DB structure of this DB, while leaving the original library as is. This way, users will be able to still use dt 2.x in parallel as a backup measure if 3.0 fails to import their old edits properly (or breaks them), and will still have the option to reimport the 2.x edits to the 3.x series once all bugs are fixed (maybe adding a button in UI to redo the import from 2.x to 3.x upon user request).
Pinging @jenshannoschwalm @TurboGit @parafin as they took part in this.
 aurelienpierre
aurelienpierre
All 36 comments
Idea isn’t bad, but using 2.6 and 3.0 in parallel also presents a problem with XML sidecar files. They are also incompatible and they will be overwritten by each darktable version in this case. I propose not to give an impression that this is workable usage of darktable and instead backup old database to library-2.6.db while continuing to use library.db.
 parafin
on 16 Nov 2019
parafin
on 16 Nov 2019
Aaah… forgot about those bloody XMP. Isn't there some way to tag the XMP fields with darktable:2 or darktable:3 classes ?
aurelienpierre
on 16 Nov 2019
This just looks like a giant can of worms :)
 TurboGit
on 16 Nov 2019
TurboGit
on 16 Nov 2019
And anyway, far too late now. We cannot start such change for 3.0.
TurboGit
on 16 Nov 2019
I fear this will introduce more new problems as it solves.
 c-h-r-i-s-t-i-a-n
on 16 Nov 2019
c-h-r-i-s-t-i-a-n
on 16 Nov 2019
Nothing to add. Also i am confident we have either fixed everything yet or will be able to do so.
 jenshannoschwalm
on 16 Nov 2019
jenshannoschwalm
on 16 Nov 2019
Nothing to add. Also i am confident we have either fixed everything yet or will be able to do so.
None of us saw the pile of bugs we got these last few weeks coming. Trust, faith or confidence are out of the plan right now: we need a fallback in case things go south.
And anyway, far too late now. We cannot start such change for 3.0.
Too late will be when a full user-base discover that they lost years of edits while updating darktable. The code we have to setup IOP priorities is brittle. The proper way to do it would be like how GPS compute the shortest path through several cities: state the relative priority (== distance) of modules one to one, then solve globally for the shortest path with a 2D matrix of priorities. Right now, it's a fair-enough 1D insertion by bisection that has been patched over and over until we buried enough dust enough the carpet to pretend it's working. To be honest, I have little confidence in it.
So what if, for now, we just silently backup the 2.6 database as parafin suggested, while updating from 2.6 to 3.0, and at least get a restore point ? I believe it's only a couple of file handling lines, shouldn't break the code, right ?
aurelienpierre
on 16 Nov 2019
I quite like the idea of db backup.
I would even vote for extending this to each db update. iirc, it has been discussed at some point, but I don't remember the content or why it hasn't been implemented...
As a personal usage, I always backup this sort of things before applying any major update (not only for dt)
And it's not for allowing people to use 2.6 and 3.0 in parallel, it's just a backup in emergency cases, to at least have some "ok" state to recover from (so no need to save xmp)
 AlicVB
on 16 Nov 2019
AlicVB
on 16 Nov 2019
in my opinion duplicating the database instead of updating it seems to be the best solution. Even if xmps will be updated they can be restored from the old database - but the database contains some more information on the application that cant be restored from xmps.
 MStraeten
on 16 Nov 2019
MStraeten
on 16 Nov 2019
So what if, for now, we just silently backup the 2.6 database as parafin suggested, while updating from 2.6 to 3.0, and at least get a restore point ?
I don't know about that "silently" part, I would say make it as easy as clicking "ok" one more time along with the current update confirmation dialogs, after displaying information about the amount of disk storage involved. Just making it "opt-out" rather than "opt-in" means it would happen in almost every case, except for the ones where the user has a reason (limited storage on an old laptop or whatever).
EDIT: Actually, it could even just be a selected-by-default checkbox on the current dialogs.
 junkyardsparkle
on 16 Nov 2019
junkyardsparkle
on 16 Nov 2019
I don't know about that "silently" part, I would say make it as easy as clicking "ok" one more time along with the current update confirmation dialogs, after displaying information about the amount of disk storage involved. Just making it "opt-out" rather than "opt-in" means it would happen in almost every case, except for the ones where the user has a reason (limited storage on an old laptop or whatever).
Silently means doing it without letting users decide.
aurelienpierre
on 16 Nov 2019
Silently means doing it without letting users decide.
Yes. I'm suggesting being slightly better behaved than that, but in a way that would still effectively accomplish what you're looking for. Of course, the checkbox label will have to use heiroglyphics, because string freeze... :rofl:
junkyardsparkle
on 16 Nov 2019
I think we must have a good understanding of the problems first before deciding what and how to backup.
@aurelienpierre None of us saw the pile of bugs we got these last few weeks coming. Trust, faith or confidence are out of the plan right now: we need a fallback in case things go south.
All dt2.7-3.0 problems with history, iop_order have been related to a few severe problems. What did we have?
The database problems were all related to mulithreading. (reading & writing to database were not synchronized). This was not easy to detect in 2.6 as we had fixed iop_orders but the problems was there already. Fixed by some mutexes.
reordering of the pipeline (non-constant iop_orders) was implemented in a way, that lead to problems when introducing the new set of iop_orders as the precision of iop_order was sufficient only in the database. (Lengthy discussions about iop_order stress)
the 2.7-30 sidecar files were broken for reading and writing as the iop_order in xmp file was the same for completely different modules because of rounding errors (only a few digits written)
one to one, then solve globally for the shortest path with a 2D matrix of priorities. Right now, it's a fair-enough 1D insertion by bisection that has been patched over and over until we buried enough dust enough the carpet to pretend it's working. To be honest, I have little confidence in it.
The bisectionioning has not been modified at all. What we do is a flattening for the defaults.
The analogy of gps and 2D insertions ... are you serious? iop_order is 1D by definition :-)
If you mean, we need a better algorithm to select a proper iop_order when reordering i absolutely agree. (Just go into one of the module groups, select a module and move it up and down again, you will have a different iop_order than before. Something i am already working on for >3.0.0)
Again about backup.
@AlicVB And it's not for allowing people to use 2.6 and 3.0 in parallel, it's just a backup in emergency cases, to at least have some "ok" state to recover from (so no need to save xmp)
I think this is not correct. If something goes wrong while updating the database there will probably be some sidecars changed leading to inconsistencies between database / sidecars.
Finally: If there is doubt about correctness what we have now we have to test, test and test again to make sure or delay release...
jenshannoschwalm
on 17 Nov 2019
There is no doubt about incorrectness in my view:)) E.g. I'm pretty sure that a lot of database accesses are unprotected by mutex and in theory could lead to corruptions. This isn't solved by testing, but by careful review, which nobody is willing to do.
As for iop order - I think major problems are resolved by now, but due to the absence of any real design for this feature some corner cases probably still exist.
In general any software has bugs, thinking that you could fix all of them is over-ambitious and unrealistic. So backup is always a good thing. I don't think disk space is a real issue - I mean how big are the biggest darktable databases out there? I would just inform users that backup was made when upgrading the database scheme, so they could delete it if they want.
parafin
on 17 Nov 2019
@parafin There is no doubt about incorrectness in my view:))
I expected this :-)
jenshannoschwalm
on 17 Nov 2019
The proper way to do it would be like how GPS compute the shortest path through several cities: state the relative priority (== distance) of modules one to one, then solve globally for the shortest path with a 2D matrix of priorities
🤔 I did a lot on graph algorithms in my university time and I still can't see how the shortest path problem relates to iop ordering
 pitbuster
on 17 Nov 2019
pitbuster
on 17 Nov 2019
I think we must have a good understanding of the problems first before deciding what and how to backup.
Backup is just copying an SQL file and changing its name to give us options to revert/recover stuff later. We don't need to understand what we backup, we backup precisely because we don't understand.
The analogy of gps and 2D insertions ... are you serious? iop_order is 1D by definition :-)
It's not because your solution is a 1D vector that the system of equations modelling your problem is not a 2D matrix. It's not an analogy, it's how we do it. Scheduling problems come back to the 1960's, it's nothing new : https://www.jstor.org/stable/167291?seq=1#page_scan_tab_contents
Previously, in a Python file (tools/iop_dependencies.py) that shouldn't have been deleted, it was done using a directed graph optimization. Find it back here:
https://github.com/darktable-org/darktable/commit/0a27c4694bebea05f038cf2942f0d23c537e31db#diff-65175d22d8d20ce5a19ffe90906a7de1
- Relationships between nodes were defined module to module:
gr.add_edge(('profile_gamma', 'exposure')) # put profile_gamma after exposure
gr.add_edge(('profile_gamma', 'highlights')) # put profile_gamma after highlights
gr.add_edge(('colorout', 'bloom')) # put colourout after bloom
gr.add_edge(('colorout', 'nlmeans')) # put colourout after nlmeans
- Then, the program drew the relationship between nodes/edges iop_deps.pdf, which is essentially the 2D matrix you see below,
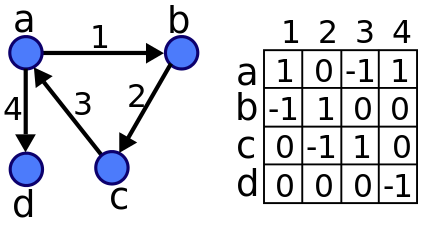
- Finally, the graph was solved to get a vector, which is essentially diagonalizing that matrix with a gaussian elimination. Each coefficient in this vector is the priority associated with the corresponding node, just stack up the nodes in decreasing or increasing priority order (depending in which direction you built the graph), and you got your path / pipe / whatever sequence of operations you tried to schedule.
I don't know why the current C code doesn't emulate the same behaviour, but it's how it should be done. The theory is here : https://en.wikipedia.org/wiki/Directed_graph and you see that, indeed, you build a 2D matrix from the nodes.
In this code, because each module-to-module constraint is only adding a column to the 2D matrix, and the 2D matrix is solved in one shot, asynchronously, the order of definition of the constraints doesn't matter. That 2D matrix is nothing but a way to collapse your system of equations (which is a set of constraints here).
In the code we have, because we insert modules between modules, synchronously, by bisection, the order in which you define the constraints matters and the same constraints defined in a different order will produce a different pipe, which is why the current code is utterly broken, no matter how you tweak it.
aurelienpierre
on 17 Nov 2019
Scheduling problems come back to the 1960's, it's nothing new
Scheduling is assigning m task to n workers (maybe with a set of constrains), so again I don't see the connection.
Reading the rest of your message, I think you mean a topological sort (and ordering of the vertices that respects the direction of the edges) of the directed graph and in this case I agree. Luckily, solving that is simpler than the complex explanation you stated, the algorithm is basically a modification of DFS, so no system of equations nor linear algebra are required ☺️
pitbuster
on 17 Nov 2019
Scheduling is assigning m task to n workers (maybe with a set of constrains), so again I don't see the connection.
Whatever you call that. For me scheduling is organizing a sequence of operations, going from local constraints to a global flow.
aurelienpierre
on 17 Nov 2019
Whatever you call that. For me scheduling is organizing a sequence of operations, going from local constraints to a global flow
Well, you should be careful with names when there are standard names for known problems. Even the paper you linked defines scheduling the same as "whatever I call that".
On the original issue, if anyone is willing to do the topological sort, I may try to help.
pitbuster
on 17 Nov 2019
I believe it's only a matter of reproducing https://github.com/jciskey/pygraph/blob/037bb2f32503fecb60d62921f9766d54109f15e2/pygraph/classes/directed_graph.py#L8 with struct since C++ is not allowed, then implementing https://github.com/jciskey/pygraph/blob/master/pygraph/functions/searching/depth_first_search.py
aurelienpierre
on 18 Nov 2019
@aurelienpierre where is the current iop ordering code?
 groutr
on 18 Nov 2019
groutr
on 18 Nov 2019
@groutr
there is a script provided with master:
iop-layout-legacy.sh
 ptilopteri
on 18 Nov 2019
ptilopteri
on 18 Nov 2019
iop-layout-legacy.sh affects only the UI. The pipeline is set in src/common/iop_order.c (static int _ioppr_legacy_iop_order_step and following).
aurelienpierre
on 18 Nov 2019
use dt -d ioporder and you will see it after dt_ioppr_set_default_iop_order
jenshannoschwalm
on 18 Nov 2019
@aurelienpierre , @jenshannoschwalm thanks.
In most cases, a topological sort is not unique. It sounds like iop order is fixed order. If there is a switch to a topological sort based approach, how are differences in valid topological sortings going to be resolved?
groutr
on 19 Nov 2019
I would go for:
- init a fixed order (default) and a corresponding set of vertices/edges (not used by default)
- if user changes order:
- update the set of edges
- if there is an hamiltonian path in the DAG (ie if a unique topological order exists)
- do a topological sort
- else restore the previous edges
That should void the need for fences altogether.
aurelienpierre
on 19 Nov 2019
Or maybe we are over-engineering that. Going from a fixed default pipe with integer positions in the stack, you just increment/decrement all modules positions relatively to the moved module.
What put us in trouble here is the float priority, with halving the distance between contiguous modules while inserting modules. After a while, you mess up the priorities entirely.
aurelienpierre
on 19 Nov 2019
Or maybe we are over-engineering that
Glad to read this :-)
What put us in trouble here is the float priority, with halving the distance between contiguous modules while inserting modules. After a while, you mess up the priorities entirely.
That was exactly the problem discussed in some PR#s related to iop_order stress.
Having a 64bit integer would allow ~55 bisections, a double float somewhat less so this is just a small improvement. If we want to keep iop_orders as they are we will have to flatten the iop_orders on-the-fly respecting the defaults to allow further bisections. I will be happy to discuss in detail right after release.
jenshannoschwalm
on 19 Nov 2019
For those who work with XMP, this command (Linux) backups all XMP recursively from a given directory structure:
rsync -avm --include='*.xmp' -f 'hide,! */' . /targetpath
For example you have a directory structure like
/RAW
/RAW/2018_Christmas/image01.dng
/RAW/2018_Christmas/image01.xmp
/RAW/2018_vacation/image02.dng
/RAW/2018_vacation/image02.xmp
When you run the command in a terminal from the /RAW directory the command searches for .xmp files and copies them to the target path including the subdirectory to this result:
/targetpath
/targetpath/2018_Christmas/image01.xmp
/targetpath/2018_vacation/image02.xmp
In the context of this issue you can backup your XMP's from DT 2.6.2 and then go for DT 3.0.
In the case of a rollback you just copy the backup structure over the original files and overwrite everything.
 pphotography
on 19 Nov 2019
pphotography
on 19 Nov 2019
in my opinion theres a hight risk of over engineering: i doubt that 55 instances of the same module will be very common - at least not in one editing session. So even if fixed numbers for the first occurence of a module simplifies future migrations it might make sense to do a renumbering of the pipe entries after each editing session: using 2 decimal digits for additional occurrences of a module we get place for 99 additional occurences of a module. (if thats not enough we can go for 3 digits)
Each time a user is adding or removing a module instance a renumbering of the subsequent module instances occurs --> but i'm not sure on the sideeffects on performance
MStraeten
on 19 Nov 2019
Having a 64bit integer would allow ~55 bisections, a double float somewhat less so this is just a small improvement. If we want to keep iop_orders as they are we will have to flatten the iop_orders on-the-fly respecting the defaults to allow further bisections. I will be happy to discuss in detail right after release.
This is still over-engineering. Inserting in an ordered list is stupid simple if you forget that bloody bisection.
Say you have that pipe (letters : module names, numbers : index in list) :
A (0) -> B (1) -> D (2) -> C(3) -> E(4)
You want to insert module C (current) between modules and D (upper) and B (lower).
- increment the index of modules between ] lower; current [ aka between] B ; C [ :
A (0) -> B (1) -> D (2 + 1) -> C(3) -> E(4) - remove C :
A (0) -> B (1) -> D (3) -> E(4) - insert C at position (index_of(B) + 1)= 2 :
A (0) -> B (1) -> C(2) -> D (3) -> E(4)
You can do that forever, it will never break.
Since the IOP order is a GTK GList type, you don't even have to sort it yourself, just use https://developer.gnome.org/glib/stable/glib-Doubly-Linked-Lists.html#g-list-insert-before.
Now the problem remains : what happens when we insert a newly introduced module in an old pipe ?
Let's say the pipe is v 3.0, I want to insert some fancy_module in 3.2. Fancy module needs to be between colorin and colorout for technical reasons, and between filmic and colorbalance for convenience reasons. To assert all these constraints, I think you can't escape the digraph and topological sorting.
aurelienpierre
on 19 Nov 2019
in my opinion theres a hight risk of over engineering: i doubt that 55 instances of the same module will be very common - at least not in one editing session.
My definition of over-engineering is solving a simple problem with a very complex solution. Its opposite is not disregarding possible issues and hoping everything will be fine ;-)
aurelienpierre
on 19 Nov 2019
Is the pixelpipe required to be linear? If so, then I agree, a graph approach might be overkill. What purpose do the priorities serve? Wouldn't the index in a fixed pixelpipe determine the priority?
Are iops required to take only as input the output of the previous iop? Or can an iop request data from any prior iop in the pipeline in addition to the output from the previous iop? As an example, there are several iops which seem to destructively modify elements of the image (like tonecurve or globaltonemap are noted to damage color information in iop_order.c). Could later iops like colorcorrection or colorcontrast refer back to the state of the image before tonecurve in addition to the output of globaltonemap when making decisions about color (pre contrast adjustments)?
groutr
on 19 Nov 2019
Is the pixelpipe required to be linear?
Yes.
Are iops required to take only as input the output of the previous iop?
Yes.
Or can an iop request data from any prior iop in the pipeline in addition to the output from the previous iop?
No. An IOP can request a rasterized mask from earlier in the pipe, but only for blending and masking.
Could later iops like colorcorrection or colorcontrast refer back to the state of the image before tonecurve in addition to the output of globaltonemap when making decisions about color (pre contrast adjustments)?
No, that's why the right IOPs need to be at the right place in the pipe. It's all serialized.
aurelienpierre
on 19 Nov 2019
TL;DR, but if we are not sure that dt 3.0 is not breaking people's db, edits, ... then we have to postpone the release. I won't agree to releasing something just to be in time and rely on some automated backups.
 houz
on 6 Dec 2019
houz
on 6 Dec 2019
Related issues
 jade-nl
·
3Comments
jade-nl
·
3Comments
 bapBardas
·
6Comments
bapBardas
·
6Comments
 schwerdf
·
4Comments
schwerdf
·
4Comments
 dim162
·
3Comments
dim162
·
3Comments
 lovesegfault
·
3Comments
lovesegfault
·
3Comments
Most helpful comment
None of us saw the pile of bugs we got these last few weeks coming. Trust, faith or confidence are out of the plan right now: we need a fallback in case things go south.
Too late will be when a full user-base discover that they lost years of edits while updating darktable. The code we have to setup IOP priorities is brittle. The proper way to do it would be like how GPS compute the shortest path through several cities: state the relative priority (== distance) of modules one to one, then solve globally for the shortest path with a 2D matrix of priorities. Right now, it's a fair-enough 1D insertion by bisection that has been patched over and over until we buried enough dust enough the carpet to pretend it's working. To be honest, I have little confidence in it.
So what if, for now, we just silently backup the 2.6 database as parafin suggested, while updating from 2.6 to 3.0, and at least get a restore point ? I believe it's only a couple of file handling lines, shouldn't break the code, right ?