Darknet: Discrepancy between CSPNet and CSPDarknet53
I'm reading the CSPNet paper again, and I'm noticing some discrepancies in how CSPDarknet53 adopted this mechanism.
In CSPNet, the base layer is split in two. One half goes into the block, and the other half is concatenated with the output of the block.
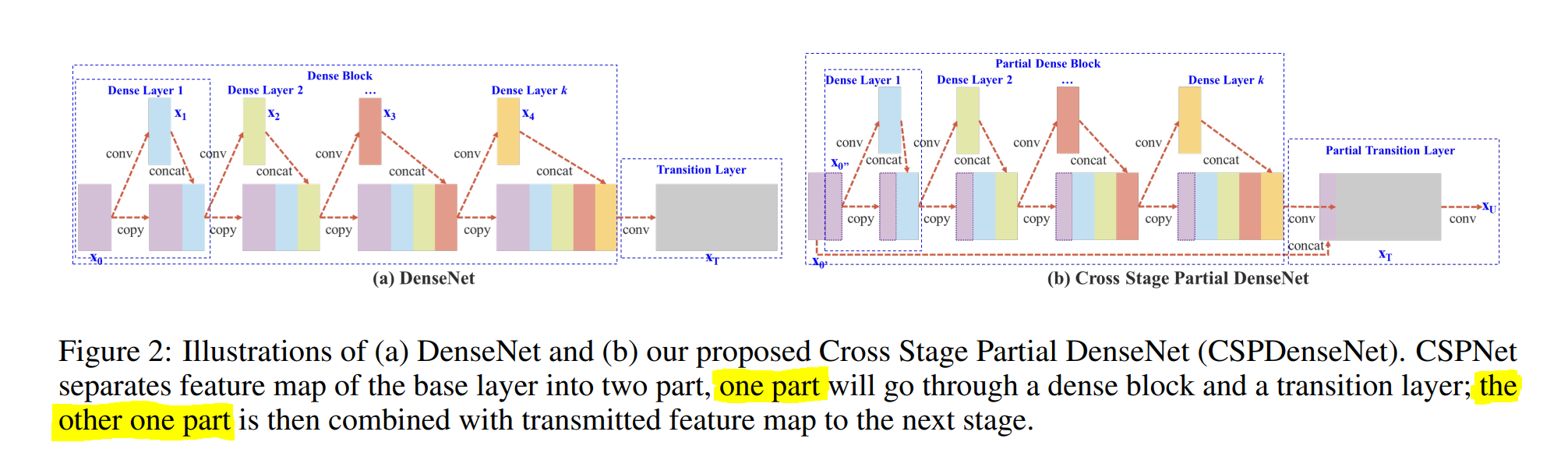
Maybe I'm interpreting the Darknet code wrong, but it looks like CSPDarknet53 does something a bit different. Like CSPNet, CSPDarknet53 splits the base layer in two, and then sends one half into the block. However, then it looks like the _entire_ base layer- not just the other half- is concatenated with the block output.
In yolov4-tiny.cfg, the route layer with the groups and group_id properties send forward only half of the channels to the following layers. However, then it looks like the entire base layer is concatenated to the block output- not just the other half. https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov4-tiny.cfg#L81
Also, in yolov4.cfg, I was having difficulty determining which layers were getting half of the feature map, and which were getting the full feature map.
I was also looking through some TensorFlow adaptions of CSPDarknet53, and of the three I looked at: all had different configurations.
This repo performs like CSPNet, where one half goes through the block and other other half is concatenated: https://github.com/sicara/tf2-yolov4/blob/master/tf2_yolov4/backbones/csp_darknet53.py#L30
This repo appears to concatenate the entire base layer onto the block output: https://github.com/hunglc007/tensorflow-yolov4-tflite/blob/master/core/backbone.py#L51
And this repo seems to mimick yolov4.cfg, where the filters are manually halved: https://github.com/RobotEdh/Yolov-4/blob/master/YoloV4_tf.ipynb
So which two of these four blocks (one pair for full and one pair for tiny) are correct?
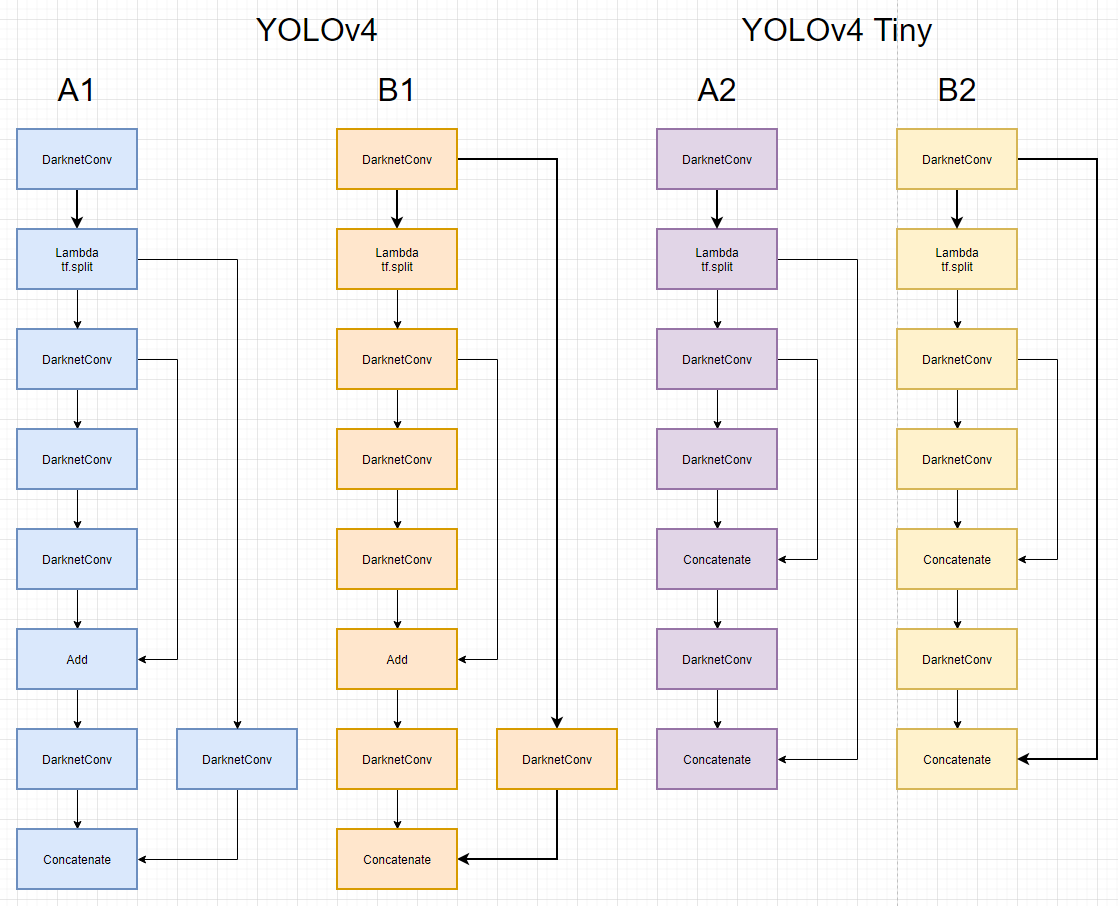
- Does YOLOv4 concatenate half of the base layer (A1), or the entire base layer (B1), to the output of the block?
- Does YOLOv4 Tiny concatenate half of the base layer (A2), or the entire base layer (B2), to the output of the block?
 willbattel
willbattel
All 8 comments
Hey @WongKinYiu I want to continue our discussion from #6086 in this thread. I made this new issue because I don't want to bother the other people in that thread.
When you say {2x, 2x} and {1x, 3x} are you referring to the increase in speed for each route? If so, can you please explain why VoVNet causes v4 Tiny to have {1x, 3x} and not {2x, 2x} if you split the base layer.
And when you say "_so we split it in computational block to make it be {2x, 2x}_" can you explain which computational block you are referring to?
Thanks!
willbattel
on 27 Jul 2020

 WongKinYiu
on 27 Jul 2020
WongKinYiu
on 27 Jul 2020
Okay. I understand that in v4 Tiny the cross-stage connection routes the entire base layer to the concatenation at the end. The only thing I'm still uncertain of is the computational block with the route layer groups in yolov4-tiny.cfg. Only half of the base layer goes into the CB, correct? I only ask because in your diagram it looks like the entire base layer goes into the block- but I'm assuming that's just a problem with the diagram and not what is actually supposed to happen. Also, I know the group_id property in the route layer determines which half is used, but can either half be used or does it matter which half goes into the block?
And then with the full YOLOv4 model (not tiny), the configuration is different: the base layer is split in half and one half goes into the block and the other half goes through the cross-stage connection to the end. Is that correct? Again, does it matter which half goes into the block?
willbattel
on 27 Jul 2020
Okay. I understand that in v4 Tiny the cross-stage connection routes the entire base layer to the concatenation at the end. The only thing I'm still uncertain of is the computational block with the route layer groups in yolov4-tiny.cfg. Only half of the base layer goes into the CB, correct? I only ask because in your diagram it looks like the entire base layer goes into the block- but I'm assuming that's just a problem with the diagram and not what is actually supposed to happen. Also, I know the group_id property in the route layer determines which half is used, but can either half be used or does it matter which half goes into the block?
I update the diagram https://github.com/AlexeyAB/darknet/issues/6348#issuecomment-664132451
WongKinYiu
on 27 Jul 2020
Hi, @WongKinYiu @willbattel
"And then with the full YOLOv4 model (not tiny), the configuration is different: the base layer is split in half and one half goes into the block and the other half goes through the cross-stage connection to the end. Is that correct? Again, does it matter which half goes into the block?"
Is the above correct ?
Thanks.
 aluds123
on 21 Aug 2020
aluds123
on 21 Aug 2020
@WongKinYiu Hello, I am sorry to bother, but I would greatly appreciate the CSP concept explanation:
Please correct me if I'm wrong, but as I understand this:
In the paper if we do partial split, we:
1) divide layer output by channel
2) second half is passed through more layers
3) second half is concatenated with untouched first half
so the implementation in https://github.com/AlexeyAB/darknet/issues/6086#issuecomment-652137590
should actually be:
(...)
def forward(self, x):
channel = x.shape[1]
first_half = x[:, channel // 2:, ...]
second_half = x[:, :channel // 2, ...]
x1 = self.layers0(second_half)
x2 = self.layers1(x1)
x3 = torch.cat((x2, x1), dim=1)
x4 = self.layers2(x3)
x = torch.cat((first_half, x4), dim=1)
if self.return_extra:
return x, x4
else:
return x
At least this is what's present in __Figure_ 5. b) Applying CSPNet to ResNe(X)t._ in the paper.
In this repo if we do partial split, we:
1) divide layer output by channel
2) second half is passed through more layers
3) second half is concatenated with original, full, not divided layer output from step 1).
This is also equivalent to the implementation mentioned in:
https://github.com/AlexeyAB/darknet/issues/6086#issuecomment-652137590
Are the above concepts correct?
 sebastian-sz
on 8 Sep 2020
sebastian-sz
on 8 Sep 2020
what's the difference between {1x,3x} and {2x,2x}?
 Lowell-IC
on 29 Sep 2020
Lowell-IC
on 29 Sep 2020
Compared with {1x,3x},can {2x,2x} help us improve the accuracy of the network?
Lowell-IC
on 29 Sep 2020
Related issues
 Greta-A
·
3Comments
Greta-A
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 zihaozhang9
·
3Comments
zihaozhang9
·
3Comments
 Mididou
·
3Comments
Mididou
·
3Comments
 Yumin-Sun-00
·
3Comments
Yumin-Sun-00
·
3Comments
Most helpful comment