Darknet: Very low video detection while the mAP is ~97%
_If you have an issue with training - no-detections / Nan avg-loss / low accuracy:
* what command do you use?_
Running this command on Google Colab:
!./darknet detector demo data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights -dont_show test.mp4 -out_filename res.avi
I get a video that detects very few frames. Sometimes the bounding box is outside the target and some other times you can see both classes pointing the object. This is nowhere close the constant and accurate detection I see on youtube videos.
Also on some images it detects with ~98% accuracy and on some others it doesn't make any detection. (question 2. at the end of this post)
_If you have an issue with training - no-detections / Nan avg-loss / low accuracy:
* what dataset do you use?_
I used a dataset of 1,673 total images for the two classes at 10.000 iterations.
_If you have an issue with training - no-detections / Nan avg-loss / low accuracy:
* what Loss and mAP did you get?
* show chart.png with Loss and mAP_
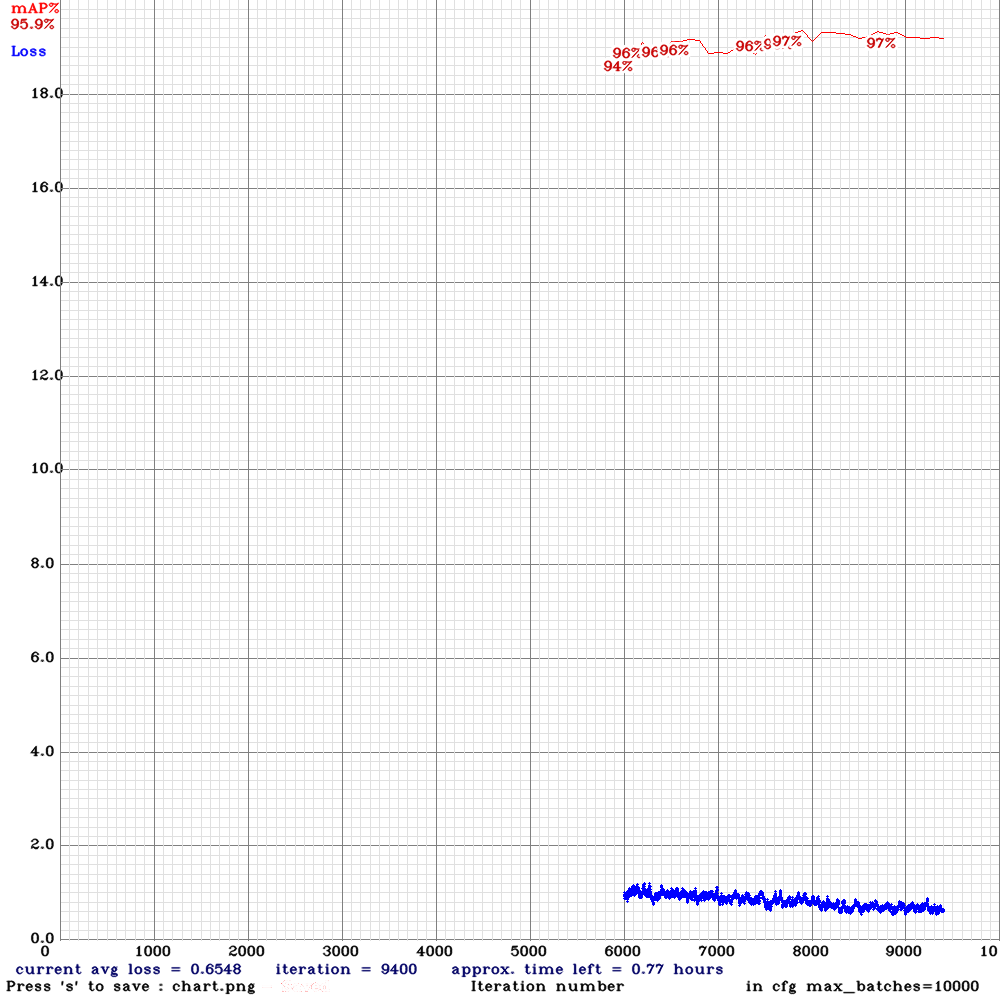
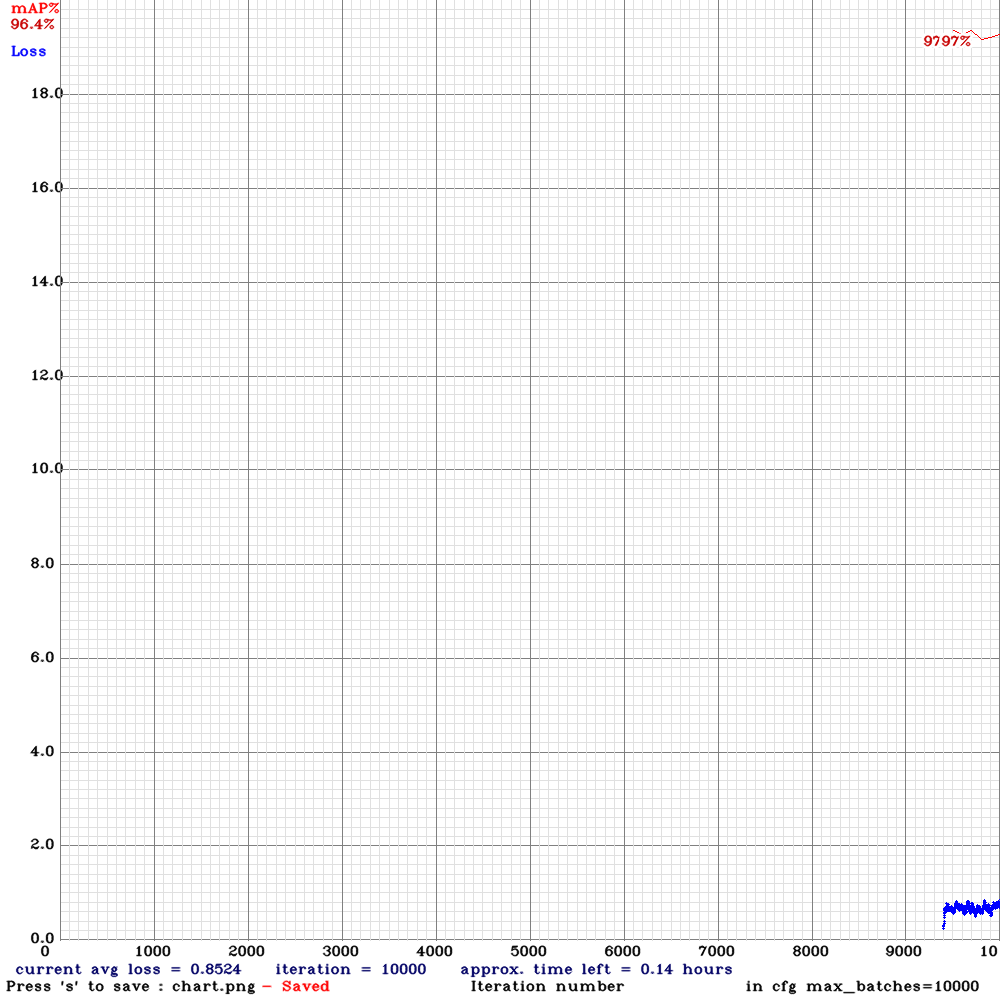
Sorry for the interrupted charts. I didn't know that every time I train a backup model it removes the previous graph lines.
Also running this command:
!./darknet detector map data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights
I get

note: test.txt contains 160 lines (160 images for validation) and train.txt contains 1,513 lines (1,513 images for training). This was the 0,9 dataset split I run after the 6.000 iterations.
From 0-6,000 iterations I split the dataset at 0.8 (the mAP at 6000 iterations was ~89%).
_If you have an issue with training - no-detections / Nan avg-loss / low accuracy:
* rename your cfg-file to txt-file and drag-n-drop (attach) to your message here_
Why I cannot have constant detection on videos/real-time?
Should I feed the dataset (/data/obj/) with images of high resolution in order to make the model detect in real time? as every device now runs on high resolution, rather than 600x600 images or less dimension images (matrices) that I fed the dataset.
Should I make any changes, for example, on .cfg file? like width and height?
I found a tool that takes an .mp4 and from a 9 seconds video it makes 193 frames and via opencv it tracks and makes bounding boxes very fast. Given that, should I make a dataset with this kind of images-frames? I mean, to combine the "yolo-obj_best.weights" I got so far(or even start training from the beginning), with a dataset, containing many images (mp4 frames) taken from my mobile phone that show me instead of random datasets of the internet.
and
If I do so, what the background has to be? (for the facemask detection project) does it play any key role, if for example I am in a forest or inside the house? The YOLOv4 understands the background or only the image inside the bounding box? I know it's a fundamental question I should have answered to myself long ago but I want to be sure on how to create a dataset (if dataset causes the problem of "low frames/non constant video/real-time object detection") that will then make great detections (accurate&constant).
I am trying to understand how it works, so I can have a model that makes constant detection in real-time and not just a few frames each time.
Thank you very much for your time, in advance.
Kind Regards,
Filippos
 koufopoulosf
koufopoulosf
All 18 comments
@AlexeyAB I would really appreciate an answer on this. Thank you.
koufopoulosf
on 8 Jun 2020
How is the result when you use: ./darknet detector demo data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights -dont_show test.mp4 -out_filename res.avi -avgframes 1?
 WongKinYiu
on 8 Jun 2020
WongKinYiu
on 8 Jun 2020
I get a video that detects very few frames. Sometimes the bounding box is outside the target and some other times you can see both classes pointing the object. This is nowhere close the constant and accurate detection I see on youtube videos.
It would be better if you will show an example.
If you get high mAP on valid dataset, but get low accuracy in the real life, then your dataset isn't suitable for the real life.
I found a tool that takes an .mp4 and from a 9 seconds video it makes 193 frames and via opencv it tracks and makes bounding boxes very fast. Given that, should I make a dataset with this kind of images-frames? I mean, to combine the "yolo-obj_best.weights" I got so far(or even start training from the beginning), with a dataset, containing many images (mp4 frames) taken from my mobile phone that show me instead of random datasets of the internet.
and
If I do so, what the background has to be? (for the facemask detection project) does it play any key role, if for example I am in a forest or inside the house? The YOLOv4 understands the background or only the image inside the bounding box? I know it's a fundamental question I should have answered to myself long ago but I want to be sure on how to create a dataset (if dataset causes the problem of "low frames/non constant video/real-time object detection") that will then make great detections (accurate&constant).
Yes, you should add images from real live to your training dataset: https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
for each object which you want to detect - there must be at least 1 similar object in the Training dataset with about the same: shape, side of object, relative size, angle of rotation, tilt, illumination. So desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds - you should preferably have 2000 different images for each class or more, and you should train 2000*classes iterations or more
 AlexeyAB
on 8 Jun 2020
AlexeyAB
on 8 Jun 2020
@WongKinYiu
How is the result when you use:
./darknet detector demo data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights -dont_show test.mp4 -out_filename res.avi -avgframes 1?
Same. On my video with the facemask, (it was a little bit dark in the room though and I don't think I have added images taken on evening/night in my dataset) it doesn't show my face very often and sometimes it makes a bounding box on my body rather than face. Or makes a bounding box next to my face (while wearing the facemask).
koufopoulosf
on 8 Jun 2020
@AlexeyAB
I get a video that detects very few frames. Sometimes the bounding box is outside the target and some other times you can see both classes pointing the object. This is nowhere close the constant and accurate detection I see on youtube videos.
It would be better if you will show an example.
If you get high mAP on valid dataset, but get low accuracy in the real life, then your dataset isn't suitable for the real life.
I found a tool that takes an .mp4 and from a 9 seconds video it makes 193 frames and via opencv it tracks and makes bounding boxes very fast. Given that, should I make a dataset with this kind of images-frames? I mean, to combine the "yolo-obj_best.weights" I got so far(or even start training from the beginning), with a dataset, containing many images (mp4 frames) taken from my mobile phone that show me instead of random datasets of the internet.
and
If I do so, what the background has to be? (for the facemask detection project) does it play any key role, if for example I am in a forest or inside the house? The YOLOv4 understands the background or only the image inside the bounding box? I know it's a fundamental question I should have answered to myself long ago but I want to be sure on how to create a dataset (if dataset causes the problem of "low frames/non constant video/real-time object detection") that will then make great detections (accurate&constant).Yes, you should add images from real live to your training dataset: https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
for each object which you want to detect - there must be at least 1 similar object in the Training dataset with about the same: shape, side of object, relative size, angle of rotation, tilt, illumination. So desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds - you should preferably have 2000 different images for each class or more, and you should train 2000*classes iterations or more
How weird!!! I downloaded a youtube video and tested on it. Here is the result!
also a screenshot from another video:

I am glad it works!!!
The command was:
!./darknet detector demo data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights -dont_show mask.mp4 -out_filename res.avi
The video is fully bright though and maybe this is the reason it doesn't detect the "real-world" videos? Due to the different sunlight levels?
For this, I guess I have to make a dataset, with pictures taken from my phone, at different hours of a day.
Does image resolution (my phone takes at high definition 1080p) affect the training?
If I wear the facemask and make a dataset containing me wearing a facemask/not wearing facemask, will it be able to detect other people wearing facemask?
Can I use all these:
https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
without resulting to a worse model?
koufopoulosf
on 8 Jun 2020
Thank you @WongKinYiu @AlexeyAB for taking a time to answer my questions, I really appreciate it, indeed.
koufopoulosf
on 8 Jun 2020
- Resolution of images doesn't matter
- Better to use real life photo/frames from videos for training with high diversity (with different persons / backgrounds)
- It improves accuracy, just don't recalculate anchors (most users do it wrong) https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
AlexeyAB
on 8 Jun 2020
Thanks for the reply!
Last two questions:
- If I want to train the /backup/yolo-obj_best.weights
command:
!./darknet detector train data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_last.weights -dont_show -map
with a new dataset (images/videos(frames) taken from real life / same classes), should I remove the previous /data/obj/ images and annotations and add the new ones or add/sum the new images and annotations with the previous images and annotations?
- What are the exact changes on .cfg file you would recommend in this case? (taken into consideration the (1.) if I leave previous images (low sizes) or if I remove them and use high resolution ones(I just checked an image from my phone and the resolution is 3008x4016)).
You are the best!
Thank you, indeed!!!!!:))))
koufopoulosf
on 8 Jun 2020
you should use sum. But if you change classes / number of classes you should traing from the begining with default pre-trained weights
I would recommend you to train from the begining - you will get higher accuracy. Also you can try to set
exposure = 2.5in cfg-file, so detector will be more robustness to brightness.Just add much more training images with high diversity and train more iterations - it will detect better then human.
AlexeyAB
on 8 Jun 2020
- you should use sum. But if you change classes / number of classes you should traing from the begining with default pre-trained weights
- I would recommend you to train from the begining - you will get higher accuracy. Also you can try to set
exposure = 2.5in cfg-file, so detector will be more robustness to brightness.- Just add much more training images with high diversity and train more iterations - it will detect better then human.
Great! When I referred to .cfg file I was thinking of "height" and "width" parameters. What size do you recommend to use there? also should I use random=1 flag?
Thanks!
koufopoulosf
on 8 Jun 2020
also _exposure = 2.5_ will be more robustness to brightness, but what about the darkness on dark environments(evening/night)? It applies the same?
koufopoulosf
on 8 Jun 2020
Great! When I referred to .cfg file I was thinking of "height" and "width" parameters. What size do you recommend to use there? also should I use random=1 flag?
width=608 height=608
If batch=64 subdivisions=16 lead to Out of memory, then use random=0
also exposure = 2.5 will be more robustness to brightness, but what about the darkness on dark environments(evening/night)? It applies the same?
It will be more robustness to low brightness - drakness.
But add also dark training images.
AlexeyAB
on 8 Jun 2020
Great! When I referred to .cfg file I was thinking of "height" and "width" parameters. What size do you recommend to use there? also should I use random=1 flag?
width=608 height=608
If batch=64 subdivisions=16 lead to Out of memory, then use random=0
You know better than I do, but shouldn't width and height be more than 608x608 ? as the pictures I get from my mobile phone are 3008x4016.
koufopoulosf
on 8 Jun 2020
I just noticed, yolov4-custom.cfg (aka yolo-obj.cfg) already uses random=1, no need to change.
koufopoulosf
on 8 Jun 2020
You know better than I do, but shouldn't width and height be more than 608x608 ? as the pictures I get from my mobile phone are 3008x4016.
The higher network resolution for training & detection - the higher accuracy - but the lower speed.
So you can try 608x608 or 640x640.
random=1 is required if you will try to change network resolution after training, f.e. you train 608x608, but then you use this one weights-file with cfg-file 512x512 or 640x640.
AlexeyAB
on 8 Jun 2020
You know better than I do, but shouldn't width and height be more than 608x608 ? as the pictures I get from my mobile phone are 3008x4016.
The higher network resolution for training & detection - the higher accuracy - but the lower speed.
So you can try 608x608 or 640x640.random=1 is required if you will try to change network resolution after training, f.e. you train 608x608, but then you use this one weights-file with cfg-file 512x512 or 640x640.
oh I was thinking of changing the resolution close to the images I take from the phone (f.e. 1920x1920). You are referring to training speed or the speed to detect an object? The speed goes dramatically low?
edit: this issue #5881 will definetely help a lot of people(!!)
koufopoulosf
on 8 Jun 2020
both train and detection speed = 1 / (networ_width * network_height)
AlexeyAB
on 8 Jun 2020
I learnt a lot! I am sure that a lot other people will learn from this issue/conversation too!
I really appreciate the time you took to answer my questions. I am covered.
If I get other questions, I will post another issue.
Be well mate and keep it up! You are doing excellent work.
Thank you. :)
koufopoulosf
on 8 Jun 2020
Related issues
 Cipusha
·
3Comments
Cipusha
·
3Comments
 bit-scientist
·
3Comments
bit-scientist
·
3Comments
 qianyunw
·
3Comments
qianyunw
·
3Comments
 jasleen137
·
3Comments
jasleen137
·
3Comments
 siddharth2395
·
3Comments
siddharth2395
·
3Comments
Most helpful comment
How is the result when you use:
./darknet detector demo data/obj.data cfg/yolo-obj.cfg backup/yolo-obj_best.weights -dont_show test.mp4 -out_filename res.avi -avgframes 1?