Hi!
I've trained a container recognition model and inferenced with a few videos. At ./darknet detector demo ... ... ... -out_filename ..mp4 file, I've encountered 1 frame that was really weird. It like overlay of the detection pre-rendered to the scene before the actual detection. Can anyone confirm this issue?
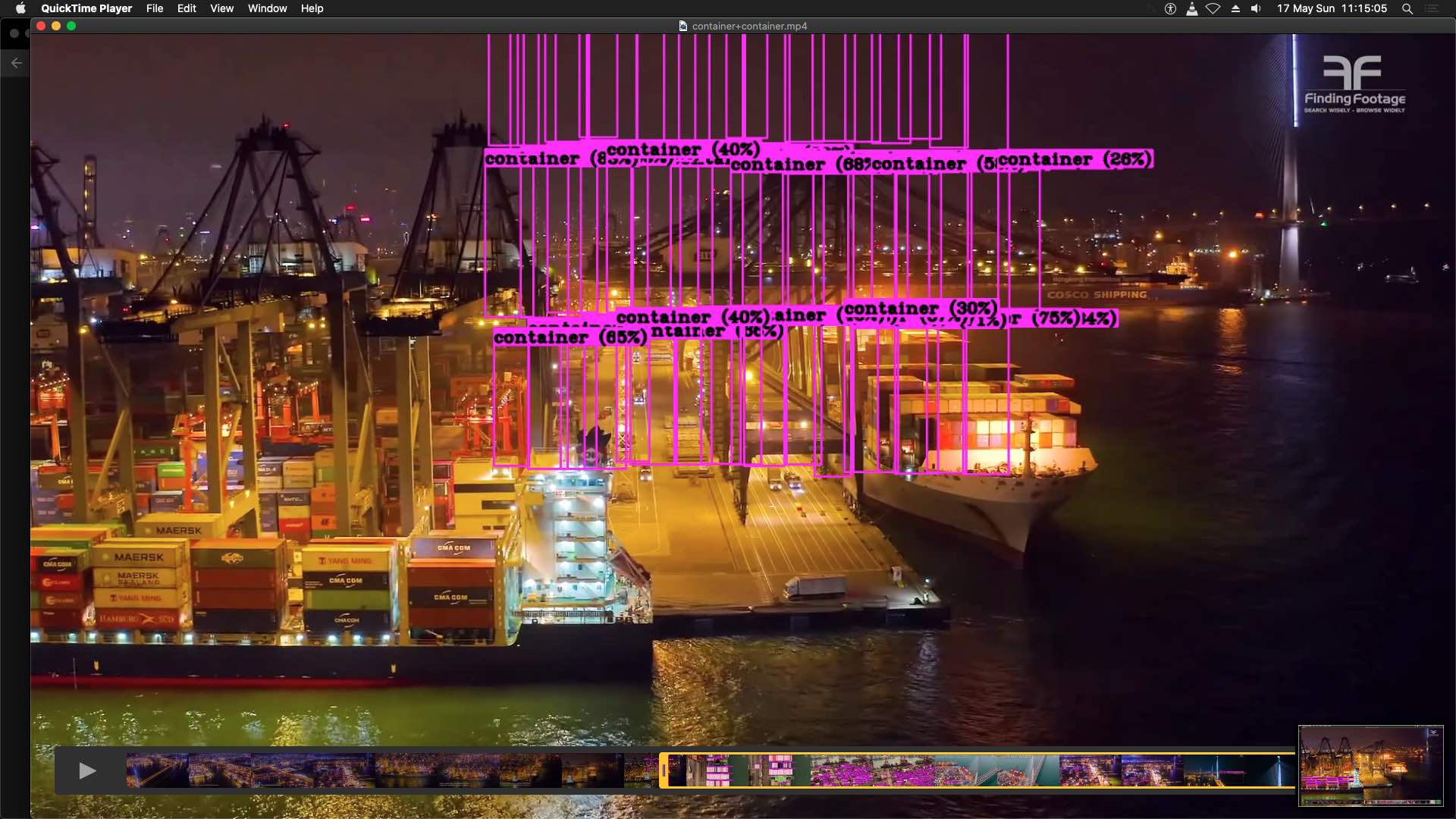

Regards
 CSTEZCAN
CSTEZCAN
>All comments
It averages detections on video across 3 frames by default.
I just made it switchable, download the latest Darknet version and use flag -avgframes 1:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -avgframes 1
 AlexeyAB
on 18 May 2020
AlexeyAB
on 18 May 2020
🚀1
😄1
👍1
Was this page helpful?
0 / 5 - 0 ratings
Related issues
 bit-scientist
·
3Comments
bit-scientist
·
3Comments
 Jacky3213
·
3Comments
Jacky3213
·
3Comments
 PROGRAMMINGENGINEER-NIKI
·
3Comments
PROGRAMMINGENGINEER-NIKI
·
3Comments
 HilmiK
·
3Comments
HilmiK
·
3Comments
 Greta-A
·
3Comments
Greta-A
·
3Comments
Most helpful comment
It averages detections on video across 3 frames by default.
I just made it switchable, download the latest Darknet version and use flag
-avgframes 1:./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -avgframes 1