Darknet: Data augmentation for aerial detection of floating objects
Hi,
I am using YOLOv3 for very specific purpouse: I am trying to train model that will be ablee to detect objects on water surface (like humans, boats, surfing boards etc.) from the drone camera. I am making dataset for few months and I already train a lot of models with nice mAP, but I am wondering about correct data augmentation for my pourpose.
I want to make model as "resistance" for "external conditions" as it is possible. By "external conditions" I mean for example: insolation, cloudiness and, mainly, water color. For already trained models I see that water color has to much importance and I want to elminate it - If I have in training set 100 photos taken in one day in one place with only, for example, jetski, when I later will verify work of the model for the same place and the same day (under the same conditions), but of course for other photos with other objects, model will be often flag object as a jetski for this place, without paying adequate attention to their shape and size but to their background (water) color.
How to make model as much "resistance" as it is possible for this type of factors?
Here I find some tips how to make model not paying to much atention for colors will be this settings correct for my purpose too?
Should I do some external image preprocesing?
I am paste here few photos from my dataset, to give you some examples how water color could be different :





I add that created be me dataset will be avaiable for free download from my website: http://afo-dataset.pl/en/ when I finish my project if someone will be interested to use it in his experiments.
Thanks in advance for your help :)
 Andropogon
Andropogon
All 36 comments
Show examples of bad detections
Do you want the network not to distinguish colors? set
hue=0.5 saturation=3.0in cfg-file and trainWhat cfg-file do you use?
 AlexeyAB
on 10 Dec 2019
AlexeyAB
on 10 Dec 2019
Thank you for your response.
I will try to describe you my problem with bad detections with few examples. First I present two photos with lets say "green" water color, with mostly correct detected humans (for two heights 30m and 60m - this are heights I mostly use):
This detections are mostly correct:


Above photos are frames from video that I am using in traning, so accuracy is very good, but I have other video with similar water color but with surfers and there surfers are moslty detected as humans (surfer and human are diferent labels in my dataset):
Example of bad detection:


You can think that I have to small amount of surfer in training set but for other water color (with was training moslty on photos contains surfers), humans are labeled as surfers:
Example of bad detection:
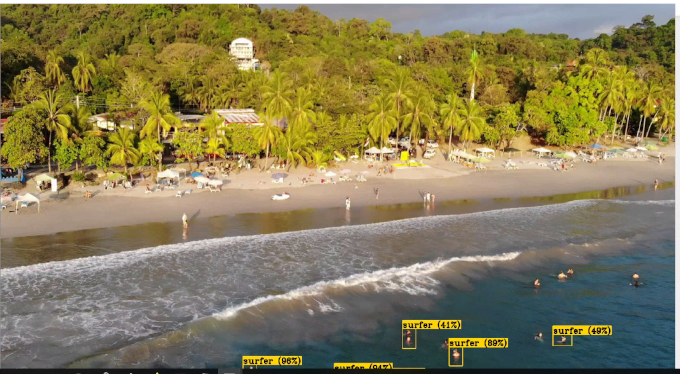
This is maybe not the best example because angle of camera is other, but I want to show that model is selecting objects as surfers too. Here is one more photo where surfers are corrected recognised as surfers:
Another correct detection:

Of course I am not saying that YOLOv3 is working bad for my dataset, all of this is pretty impresive for me, but I am trying to make this model as good as possible, so I post this question for some help :)
I was using default cfg-file: yolo-obj.cfg and I was changing only: batch, subdivisions, width, height and max_batches (and classes and filters for yolo layers) but if I understand it correctly I should make some experiments with changing: saturation, exposure, and hue. Later compare the results and find the best settings.
I am not sure about "making network not to distinguish colors" because water has diferent colors but from some limited set (I mean that water color can not be red). So maybe I should made it less important, but not completly without matter?
If you have any tips I will be really gratefull.
Andropogon
on 10 Dec 2019
Attach your cfg-file in zip-archive.
How many images do you have in your training dataset?
but I have other video with similar water color but with surfers and there surfers are moslty detected as humans (surfer and human are diferent labels in my dataset):
You can think that I have to small amount of surfer in training set but for other water color (with was training moslty on photos contains surfers), humans are labeled as surfers:
- I would advise including more of these images in the training dataset.
Read: https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
for each object which you want to detect - there must be at least 1 similar object in the Training dataset with about the same: shape, side of object, relative size, angle of rotation, tilt, illumination. So desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds - you should preferably have 2000 different images for each class or more, and you should train 2000*classes iterations or more
I am not sure about "making network not to distinguish colors" because water has diferent colors but from some limited set (I mean that water color can not be red). So maybe I should made it less important, but not completly without matter?
Yes.
Also set mosaic=1 in [net] in cfg-file.
AlexeyAB
on 11 Dec 2019
- I was using different config files but here is the last one:
yolo-obj.zip I have only 2000 images, but with approximately 30.000 seleted objects (mostly humans), here is like dataset looks for now:
I am constantly adding new images to dataset. I know that for most of classes don't have this minimal 2000, but I was wondering that there are any "tricks" connected with data augmentation, that could be helpfull :)
Andropogon
on 11 Dec 2019
- try to use these changes https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
for training for small objects (smaller than 16x16 after the image is resized to 416x416) - set layers = -1, 11 instead of https://github.com/AlexeyAB/darknet/blob/6390a5a2ab61a0bdf6f1a9a6b4a739c16b36e0d7/cfg/yolov3.cfg#L720 and set stride=4 instead of https://github.com/AlexeyAB/darknet/blob/6390a5a2ab61a0bdf6f1a9a6b4a739c16b36e0d7/cfg/yolov3.cfg#L717
Also set width=608 height=608 and train
Must be always batch=64
I am constantly adding new images to dataset. I know that for most of classes don't have this minimal 2000, but I was wondering that there are any "tricks" connected with data augmentation, that could be helpfull :)
Change hue, saturation, exposure https://github.com/AlexeyAB/darknet/wiki/CFG-Parameters-in-the-%5Bnet%5D-section
and set mosaic=1
AlexeyAB
on 11 Dec 2019
I will make all this changes. Thank you :)
Andropogon
on 11 Dec 2019
@Andropogon Hi,
I implemented special features for detecting objects from the air. Download the latest Darknet version.
Can you train these 4 cfg-files by using command ./darknet detector train obj.data yolov3-tiny_3l.cfg.txt -map wihtout pre-trained weights-file and attach result chart.png for each of cfg-file?
Based on this result I will make the best network - for objects photographed from the air/satellite (aerial detection).
Just change classes= and filters= according to your number of classes.
Use the latest version of Darknet:
Also can you write
- how many classes do you have?
- How many objects of each class do you have in your training dataset?
I will add another new model.
AlexeyAB
on 18 Dec 2019
@AlexeyAB thank you, I am going to make these trainings. Tomorrow I will post results and more information about my dataset.
Andropogon
on 19 Dec 2019
Hello @AlexeyAB
Sorry for the delay, I have run this training parallel on multiple GPUs and each of them overrode others chart.png. Later to avert it I made trainings for max_batches = 20000, to make screenshot before end of the training. Finally, I have the results:
At first, I want to notice that while preparing trainings for other than "yolov3-tiny_3l.cfg" file I was getting these messages on terminal:
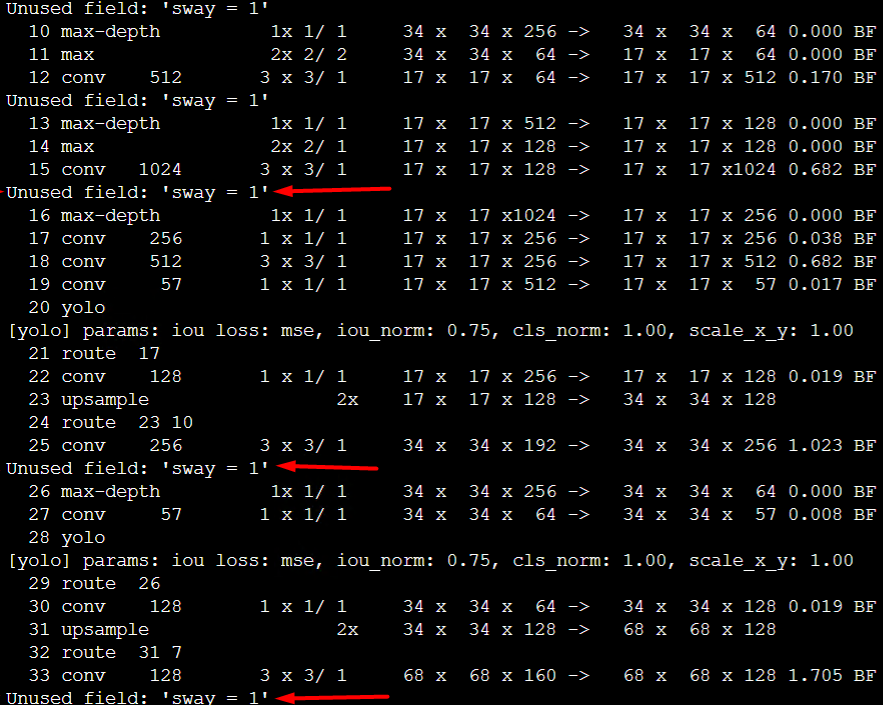
For "rotate" I was getting the same message but which "Unused field rotate = 1" and which stretch the same. Is it wrong? I was using the last version of darknet.
If it is correct here are results:
yolov3-tiny_3l.cfg.txt
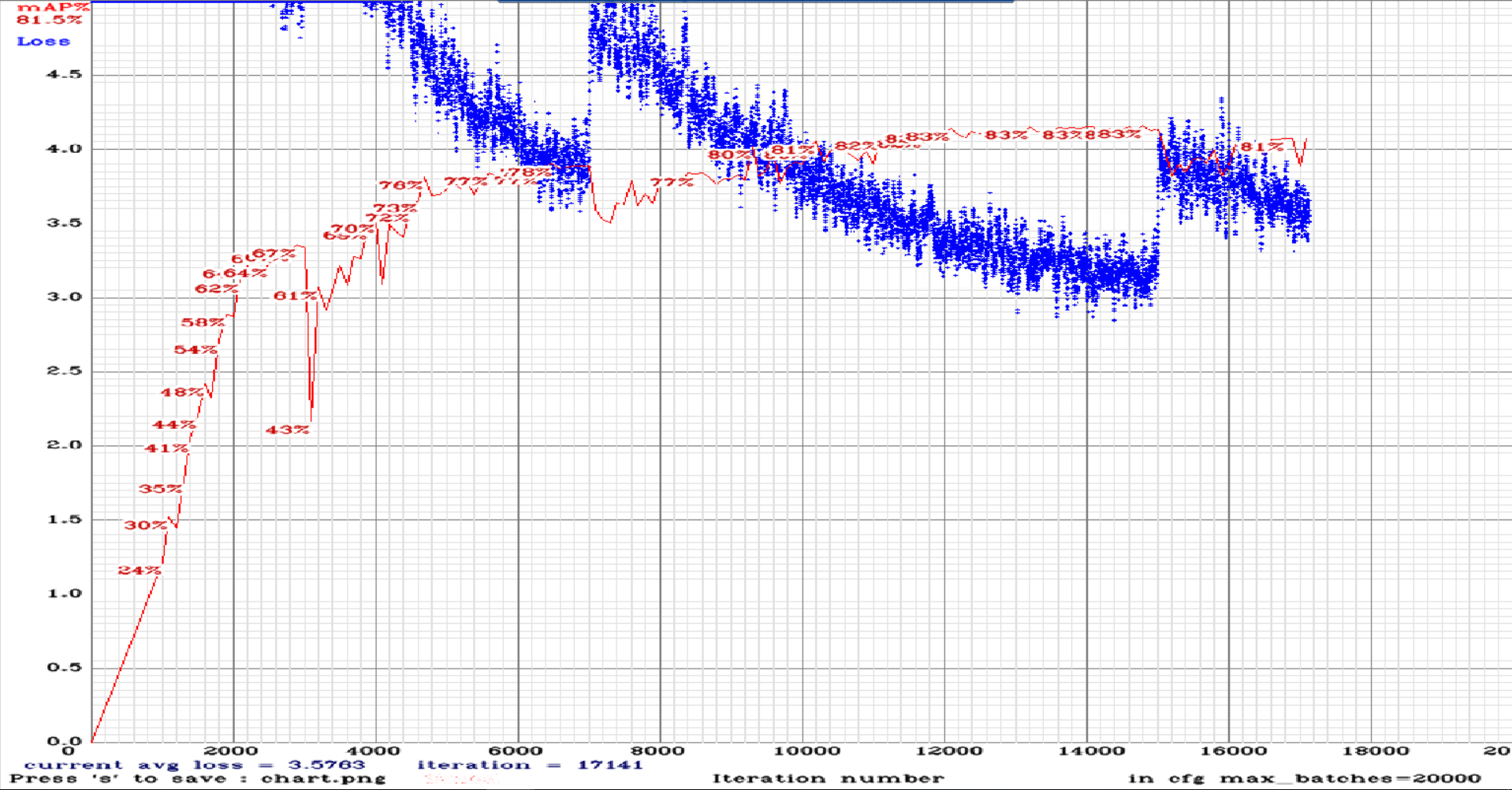
yolov3-tiny_3l_stretch_maxout.cfg.txt
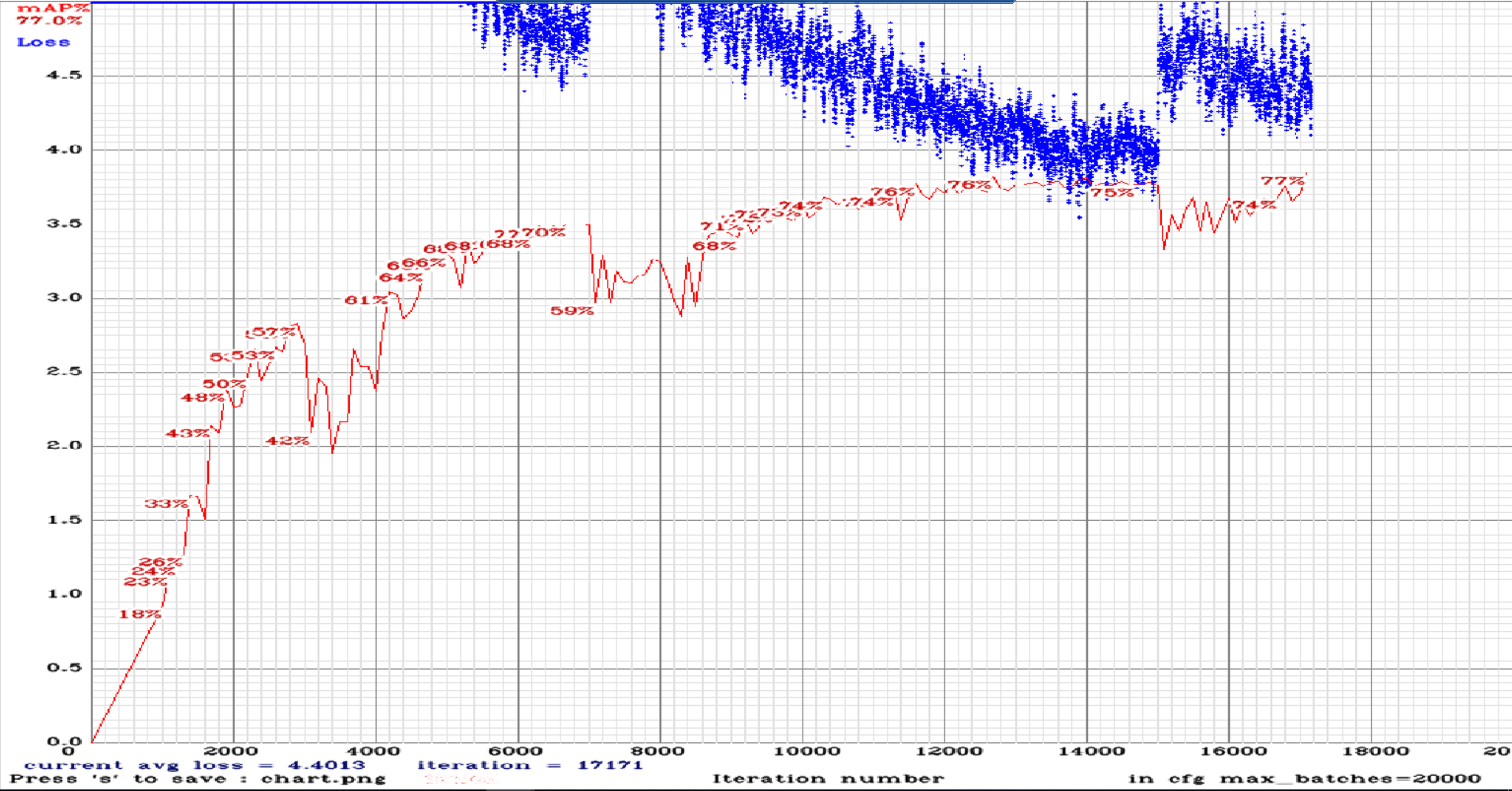
yolov3-tiny_3l_rotate_maxout.cfg.txt
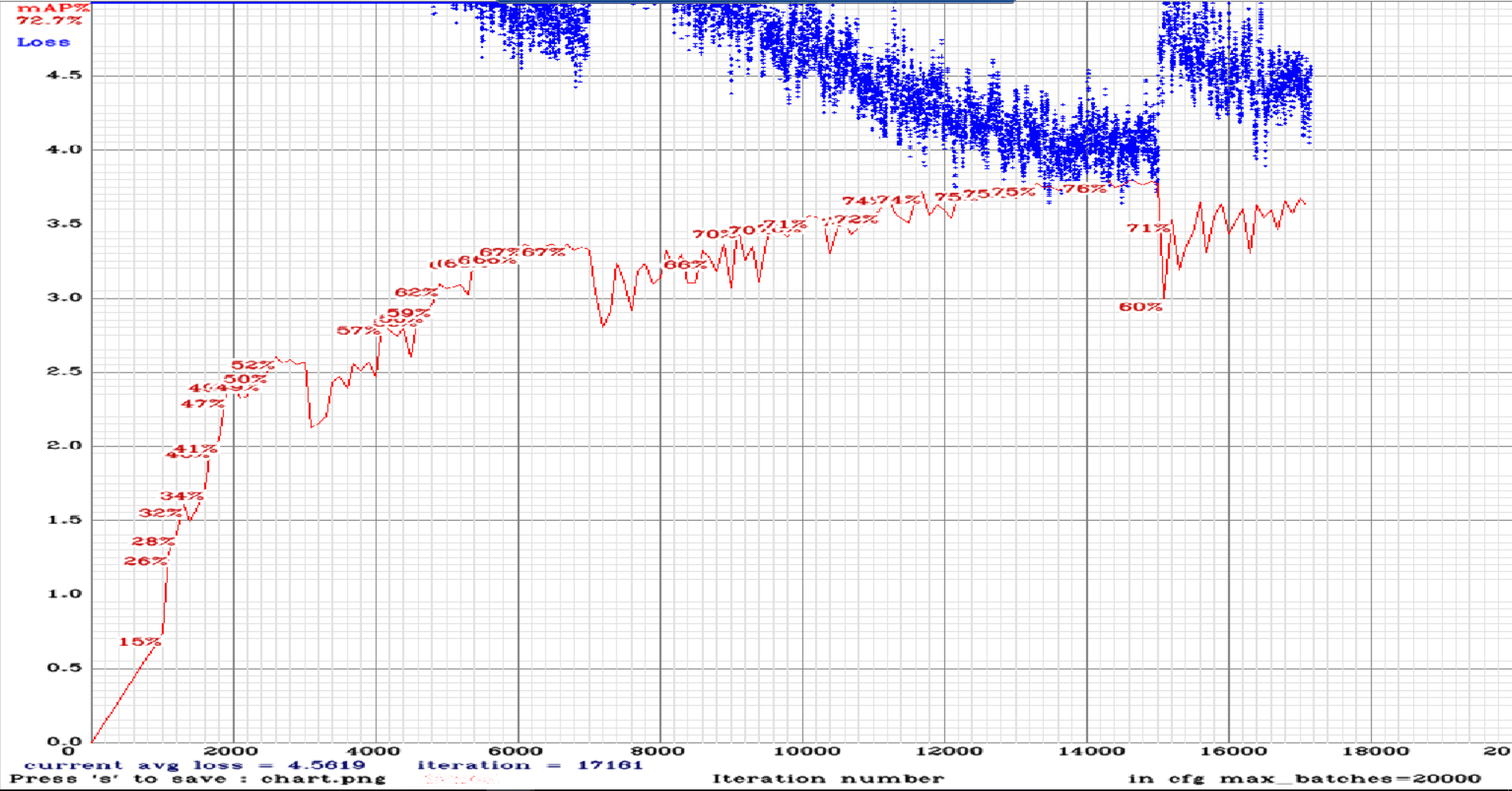
yolov3-tiny_3l_sway_maxout.cfg.txt
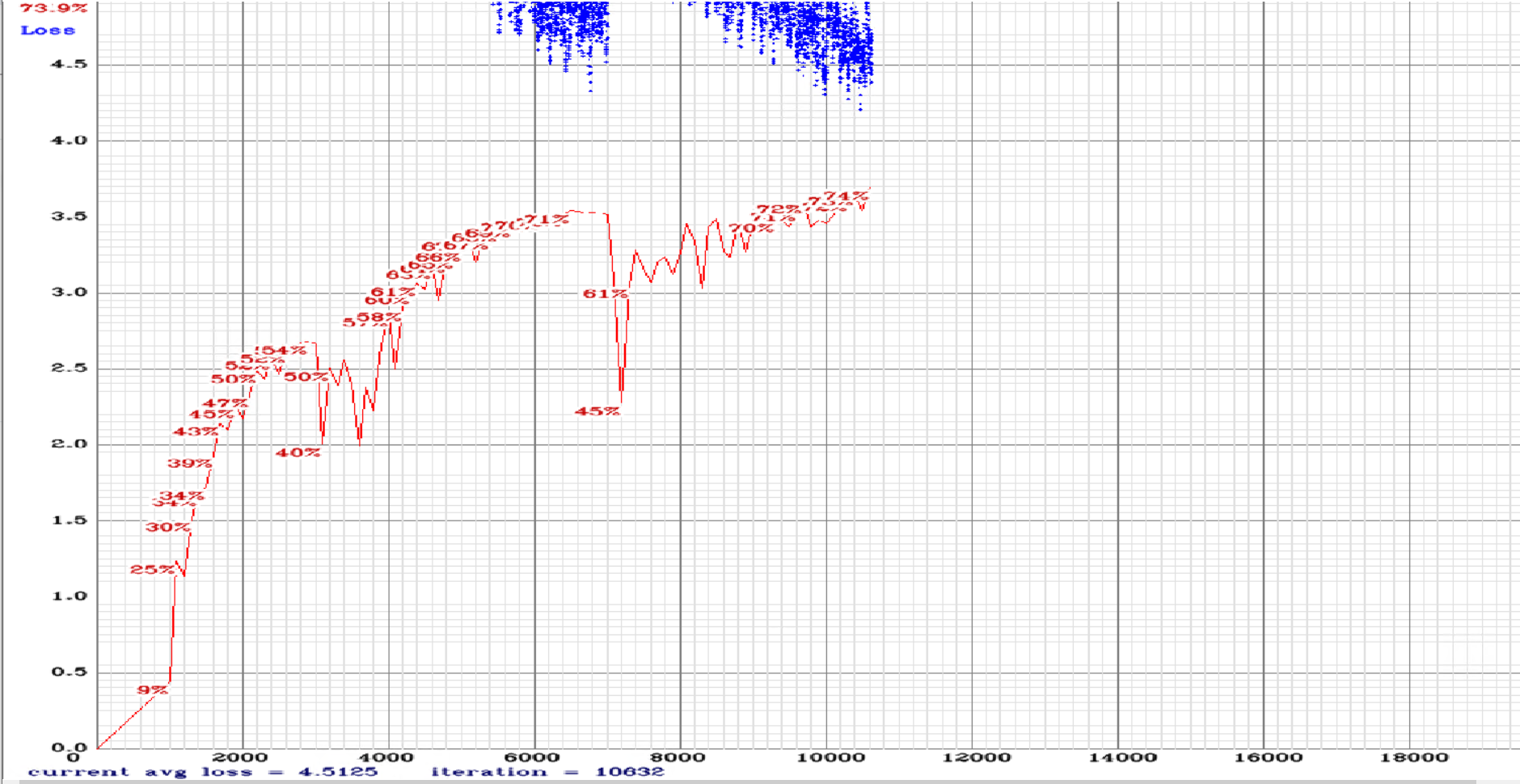
And as a bonus for comprahasion:
yolo-obj.cfg with this config: yolov3-tiny-obj.txt
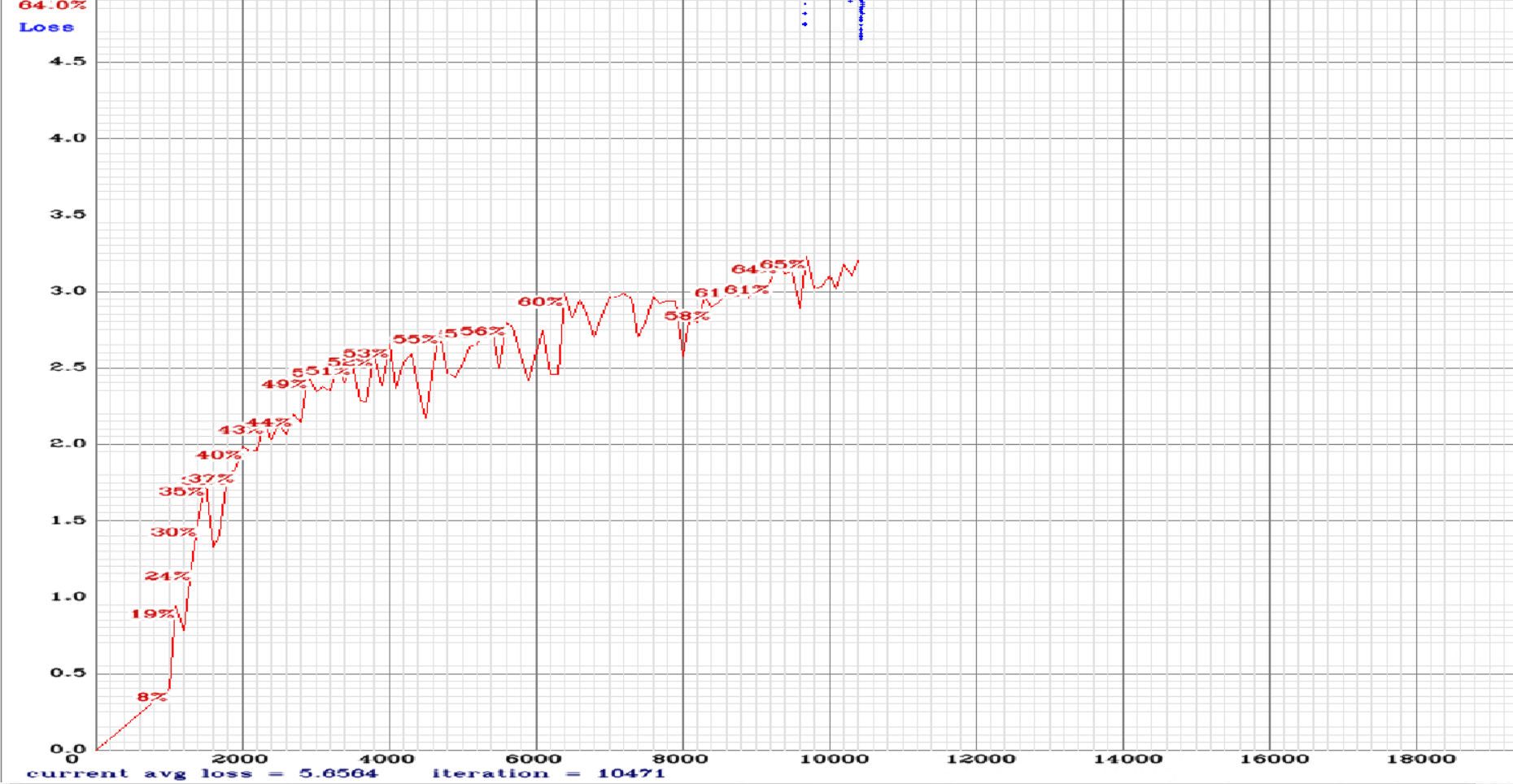
As for dataset related questions:
- How many classes do you have?
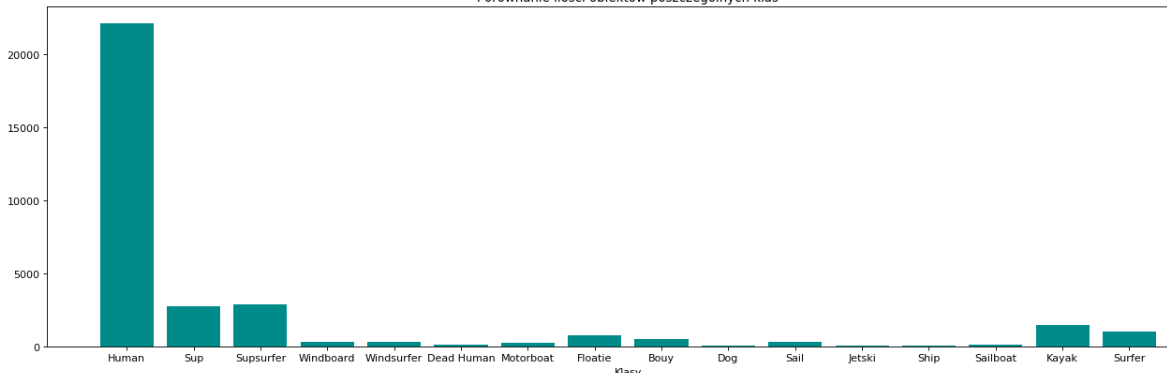
My dataset is highly unbalanced:

Human class is the most important one for me, but I want to try to create an object detector for other classes too, there is data distribution for classes without "human" one:
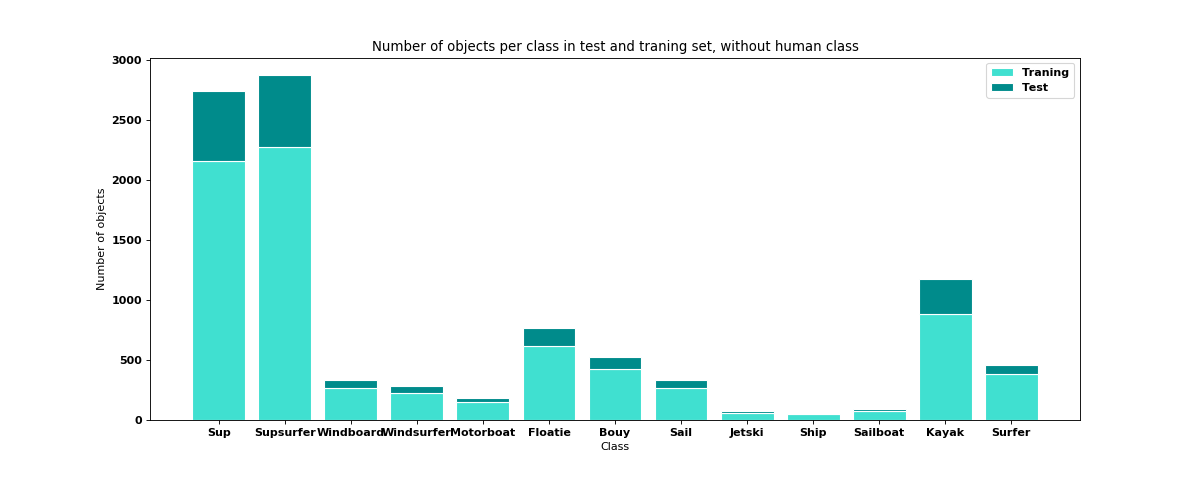
Because of these problems with class imbalance, I created several datasets with various divisions into classes for which I train:
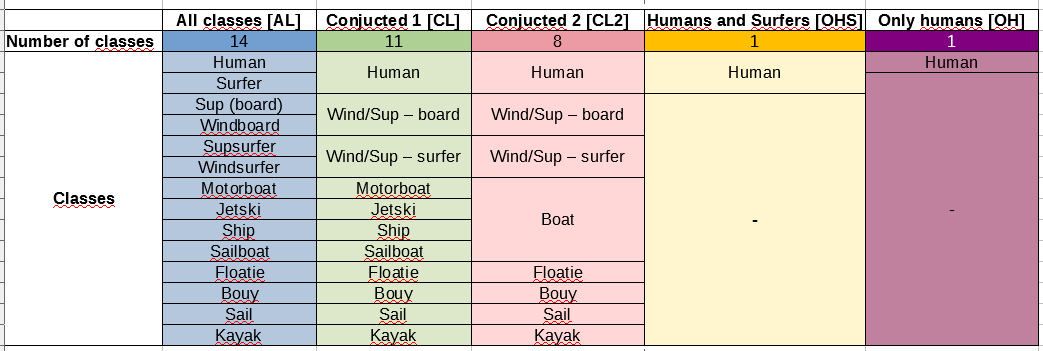
Above results are from AL dataset (which all 14 classes). Now I am going to try the same models on CL2 dataset, which class distribution like this (without human class which has 25k objects):
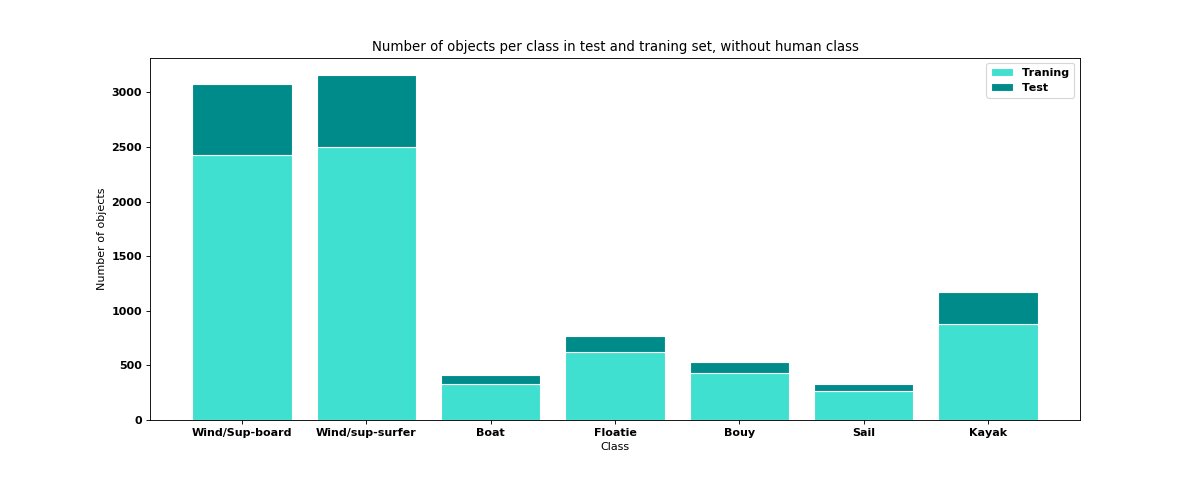
- How many images do you have in your training dataset?
In the training set, I have only 2000 images but which 32000 objects as showed above.
Do you want some more information :) ?
Andropogon
on 22 Dec 2019
@Andropogon Hi,

Is it wrong? I was using the last version of darknet.
Yes, this is wrong.
You should use the latest version of Darknet: https://github.com/AlexeyAB/darknet/issues/4495#issuecomment-567163867
Use the latest version of Darknet
Since these features were added recently.
You should download new Darknet version and recompile.
Can you write number of your classes in the form:
- class-0 - 22000
- class-1 - 2600
- class-2 - 2700
... - class-13 - 500
Or even better like:
counters_per_class = 22000, 2600, 2700, ..., 500
AlexeyAB
on 22 Dec 2019
@AlexeyAB I forgot to copy built darknet.exe file to correct directory where I am using them... Now I don't have these warning messages, so I am going to make trainings one more time :)
About numbers of objects in classes:
For AL dataset (all 14 classes):
counters_per_class = 17379, 2160, 2275, 268, 228, 147, 620, 427, 263, 62, 49, 75, 883, 384
For CL2 dataset (8 classes):
counters_per_class = 17763, 2428, 2503, 333, 620, 427, 263, 883
Andropogon
on 22 Dec 2019
@AlexeyAB So here are charts for rotate, strech and sway maxout.:
yolov3-tiny_3l_stretch_maxout.cfg.txt
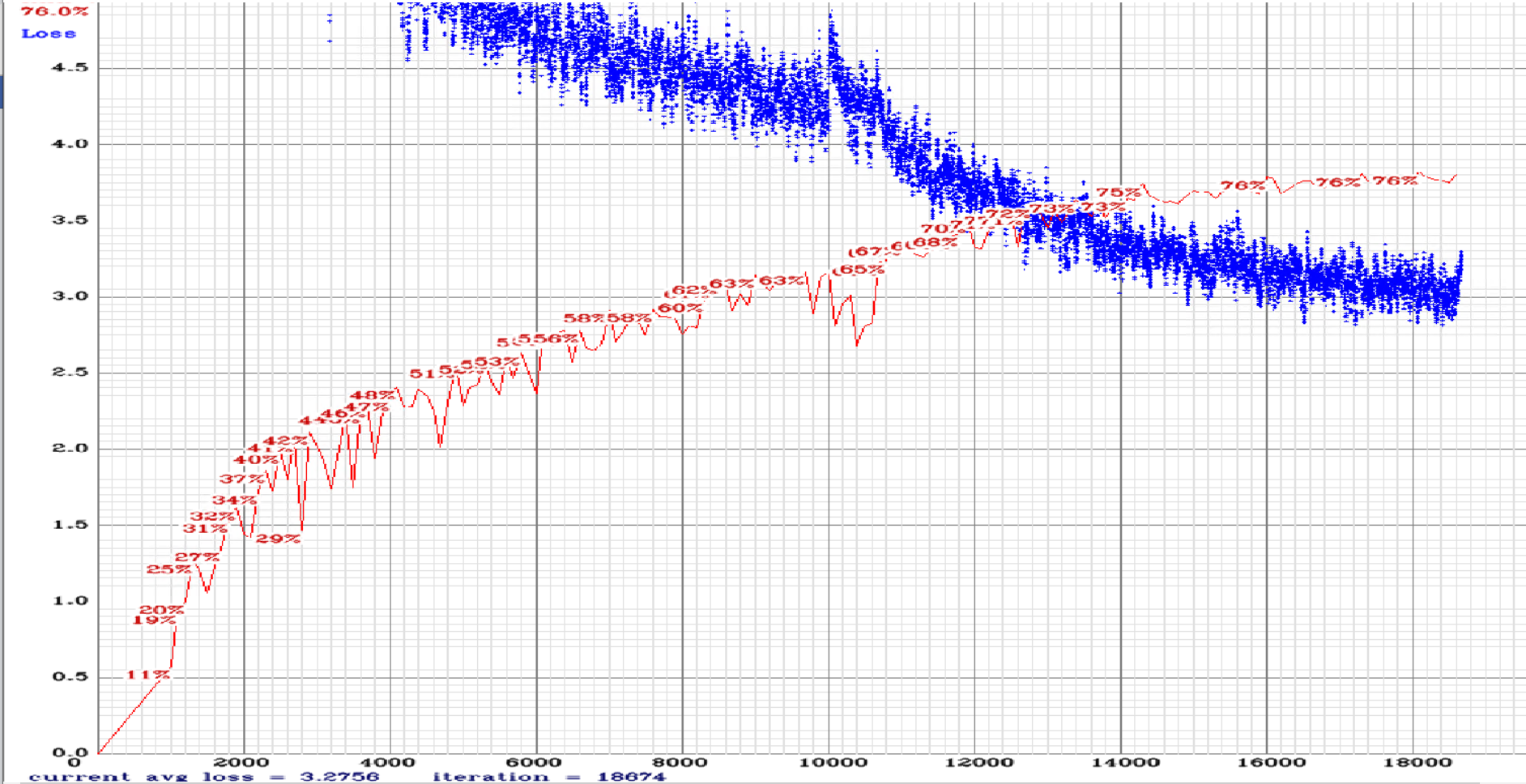
yolov3-tiny_3l_rotate_maxout.cfg.txt
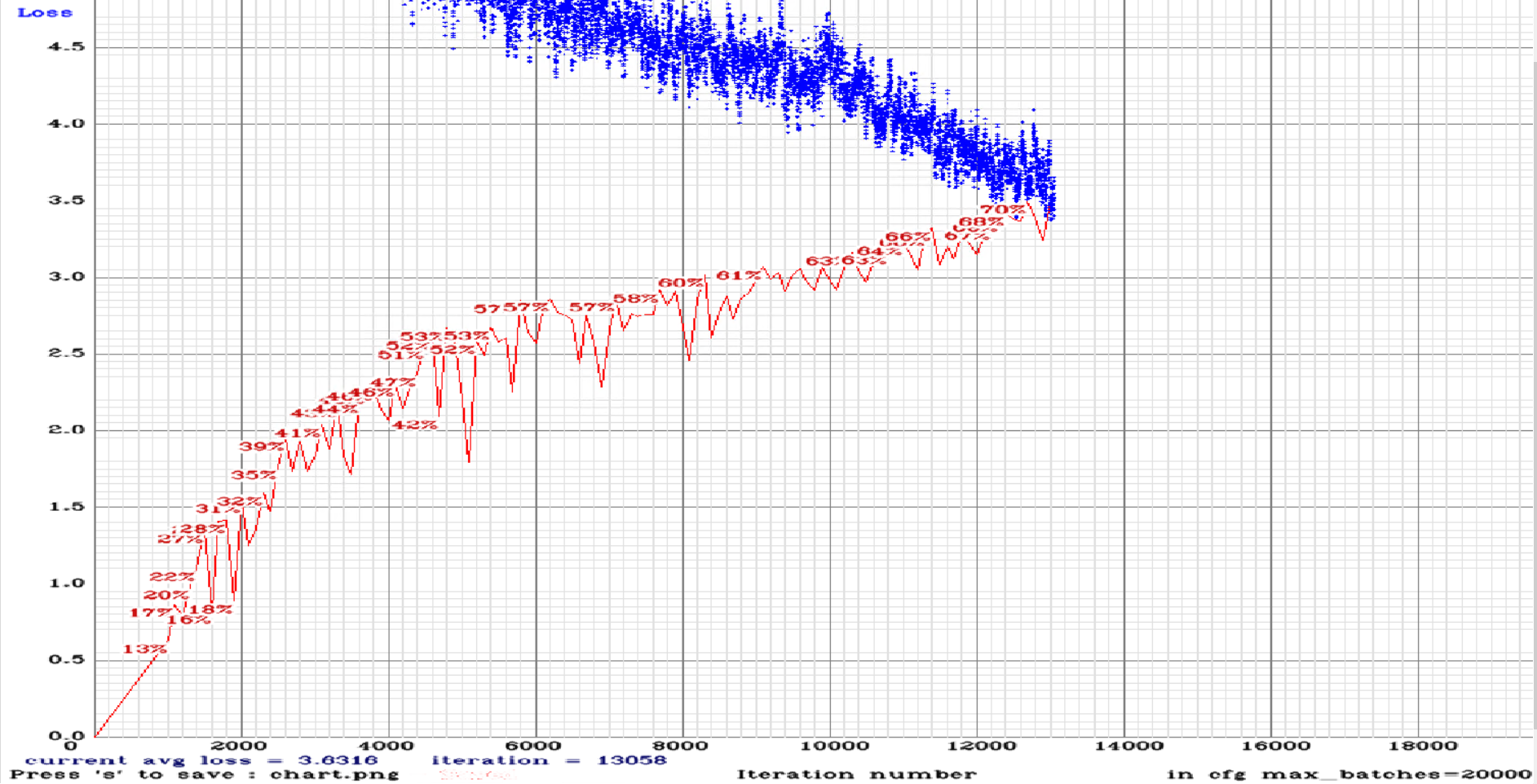
yolov3-tiny_3l_sway_maxout.cfg.txt
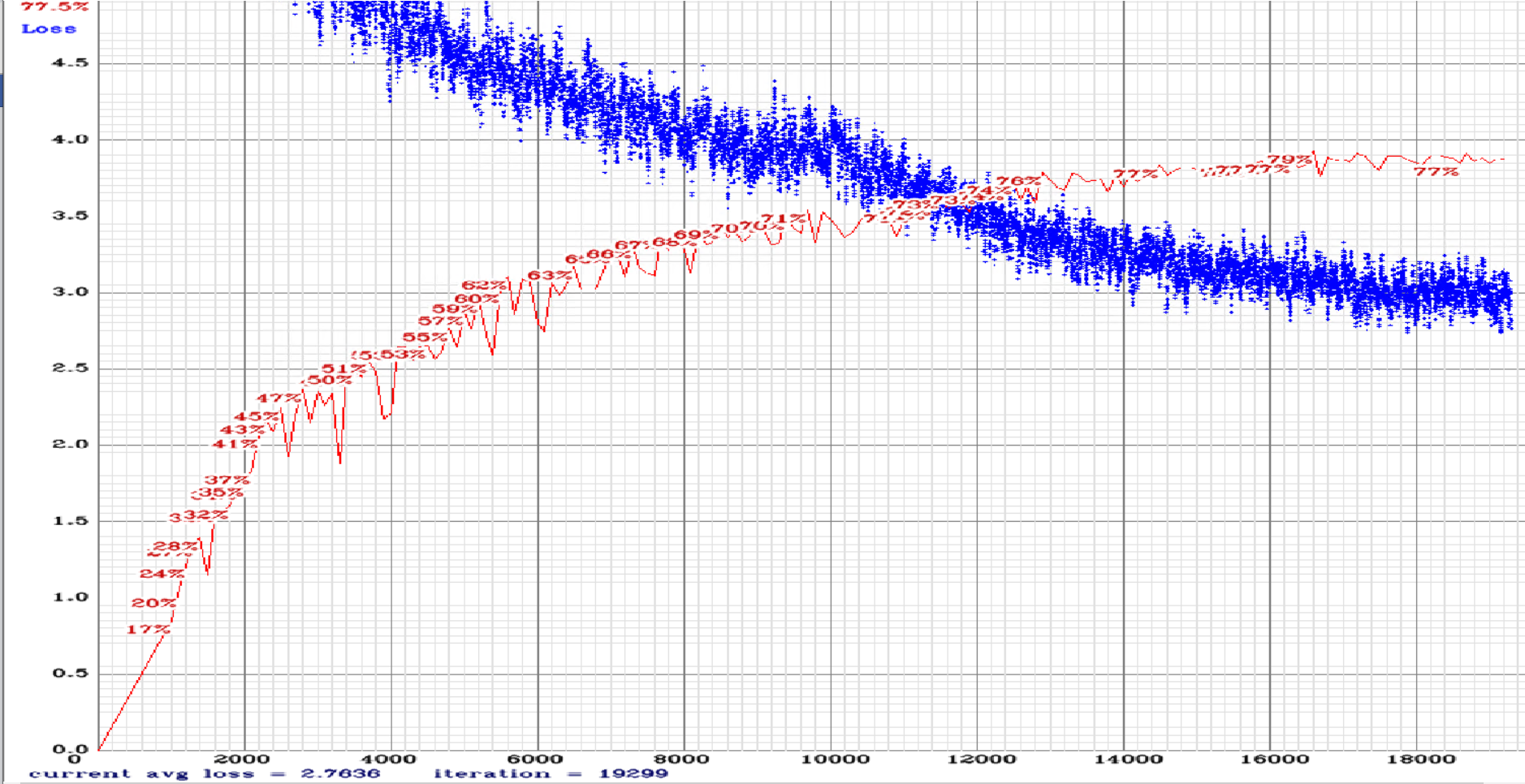
For AL dataset (14 classes described above).
Andropogon
on 23 Dec 2019
@Andropogon Hi, Thanks!
Did you use separate validation dataset for mAP measurement? Show content of
obj.datafile.You didn't use any pre-trained weights for all trainings:
yolov3-tiny_3l.cfg.txt, yolov3-tiny_3l_stretch_maxout.cfg.txt, yolov3-tiny_3l_rotate_maxout.cfg.txt, yolov3-tiny_3l_sway_maxout.cfg.txt?
You should train without pre-trained weights files.
Based on your results, try to train these 4 models in the same way (without pre-trained weights files, and with max_batches = 20000)
AlexeyAB
on 23 Dec 2019
@Andropogon I just fixed yolov3-tiny_3l_resize.cfg.txt
AlexeyAB
on 23 Dec 2019
@AlexeyAB
Did you use separate validation dataset for mAP measurement? Show content of obj.data file.
Yes and no, I am using a separate test set but its content contains random images drawn in proportion 20/80 from one bank -> and bank (whole dataset) is created from 30 videos, so a lot of images in training and test set are pretty similar, for example it could be two frames from one video with only 1-second delay:
Frame from training set:

Frame from test set:

This is why mAP is so good.
There is the content of obj.data file:
classes= 14
train = data/train.txt
valid = data/test.txt
valid2 = data/validation.txt
names = data/obj.names
backup = backup/
But now I am creating the correct validation set (this one named "valid2 = data/validation.txt" in above file), with only frames from other videos than this used in training set, but its content is very unbalanced for this moment (it is not to easy to get good videos from drone recording objects on water surface :)):
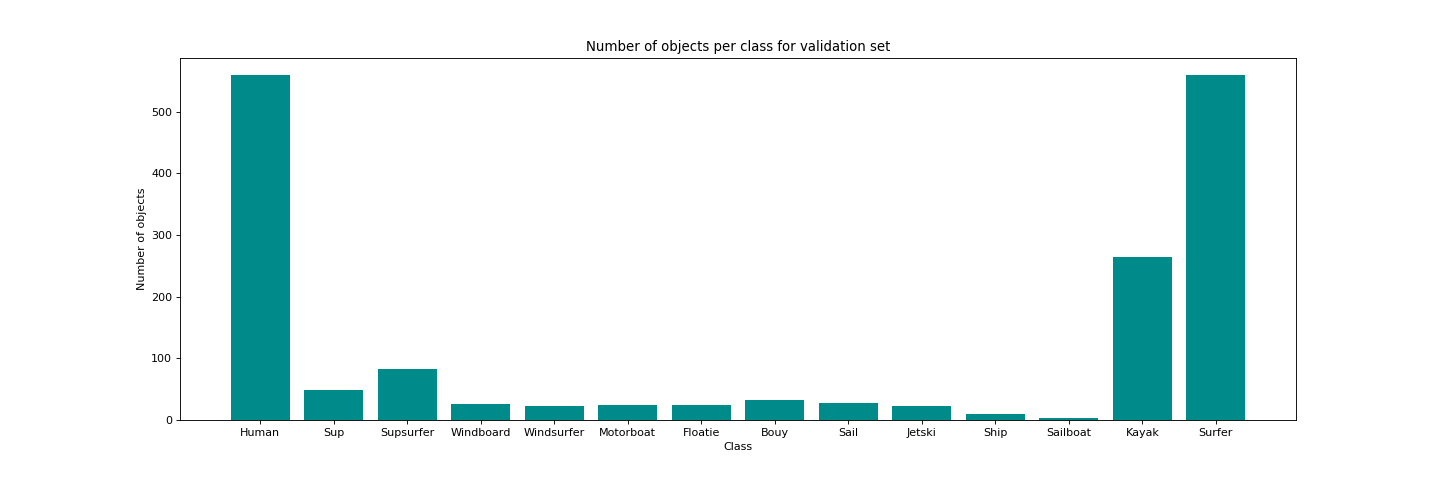
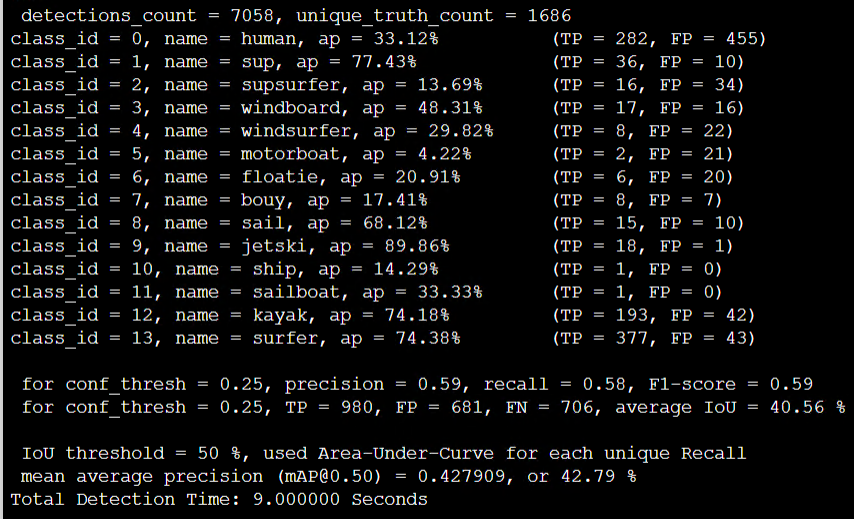
For this set, I am getting for 10000_weights from above trainings these results:
Tiny 3l. mAP 81% -> 42.79%
Rotate_maxout. mAP 63% -> 40.37%
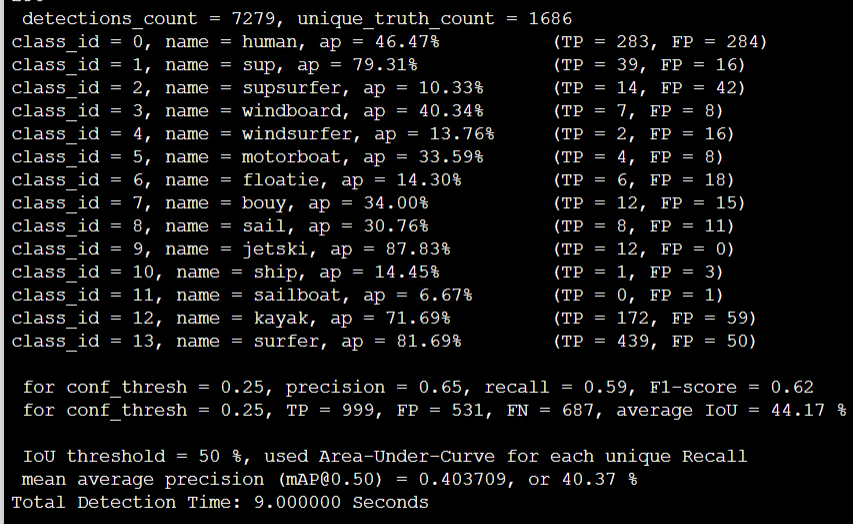
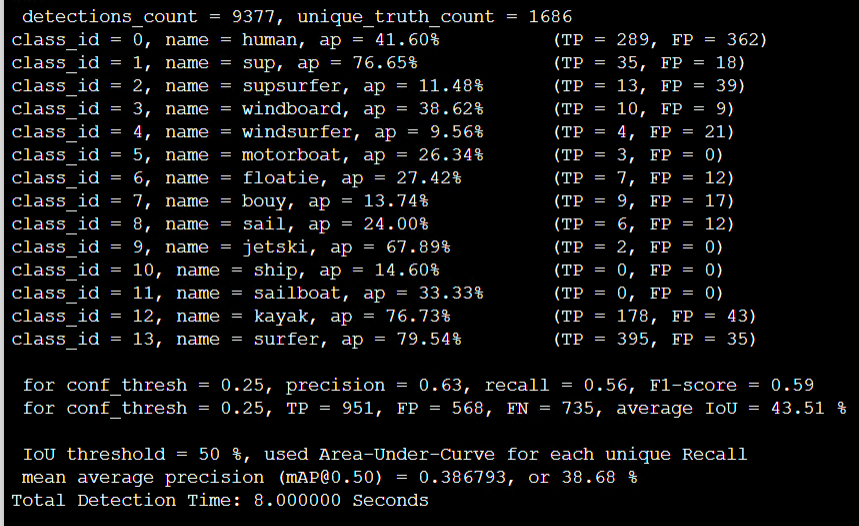
Strech maxout 64% -> 38.68%:
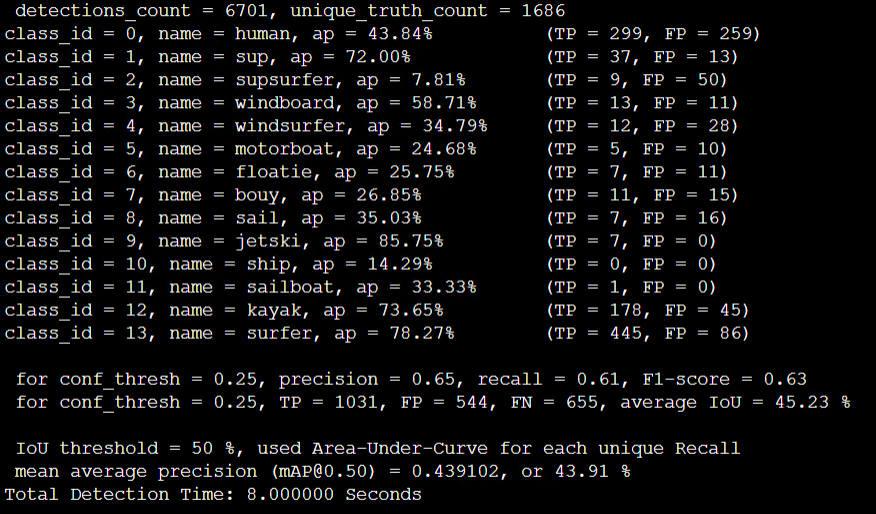
Sway maxout. mAP 70% -> 43.91% :
I should tell you about it earlier. Should I draw charts for this validation set that contains only images from other videos than this in training set?
You didn't use any pre-trained weights for all trainings: yolov3-tiny_3l.cfg.txt, yolov3-tiny_3l_stretch_maxout.cfg.txt, yolov3-tiny_3l_rotate_maxout.cfg.txt, yolov3-tiny_3l_sway_maxout.cfg.txt ?
No, I wasn't using any pre-trained weights, all trainings were called by a command like this:
./darknet detector train data/obj.data yolov3-tiny_3l_sway_maxout.cfg.txt -map -gpus 1
Based on your results, try to train these 4 models in the same way (without pre-trained weights files, and with max_batches = 20000)
Ok, thanks, I am going to make these trainings, do you want to draw chart.png for mAP calculated on images from this "test-set" that I was using previously or for this "validation-set" for which I past results now?
Is there any option to specify name of the chart file? It could be useful for parallel training on few gpus because otherwise, chart.png are overriding each other from various trainings.
P.S.
Merry Christmas
Andropogon
on 23 Dec 2019
@Andropogon Hi,
Ok, thanks, I am going to make these trainings, do you want to draw chart.png for mAP calculated on images from this "test-set" that I was using previously or for this "validation-set" for which I past results now?
No. Just attach chart.png only for new 4 cfg-files.
Is there any option to specify name of the chart file? It could be useful for parallel training on few gpus because otherwise, chart.png are overriding each other from various trainings.
I will add this feature in a few days so filename will be chart_your_cfg_name.png
Merry Christmas
AlexeyAB
on 23 Dec 2019
@AlexeyAB I started trainings for three new configs, but for "yolov3-tiny_3l_resize.cfg.txt" I am getting this error:
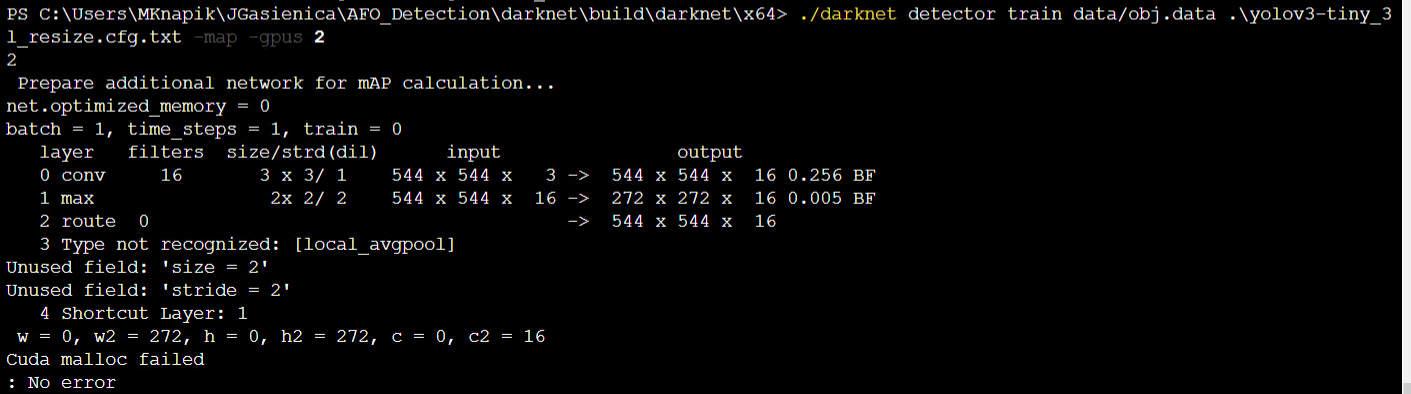
Should I update the whole darknet? Because I only downloaded these new configs that you paste above. You had write "I just fixed yolov3-tiny_3l_resize.cfg.txt" but from this comment, I can't download anything so I downloaded from the above one.
I will add this feature in a few days so filename will be chart_your_cfg_name.png
Thanks, It is a small upgrade, but I think it could be useful for parallel training and more convenient.
Andropogon
on 23 Dec 2019
@Andropogon
Should I update the whole darknet?
Yes.
I added [local_avgpool] layer 3 days ago.
Should I update the whole darknet? Because I only downloaded these new configs that you paste above. You had write "I just fixed yolov3-tiny_3l_resize.cfg.txt" but from this comment, I can't download anything so I downloaded from the above one.
Yes, that's right. I updated it in the above comment.
AlexeyAB
on 23 Dec 2019
@Andropogon
I will add this feature in a few days so filename will be chart_your_cfg_name.png
Thanks, It is a small upgrade, but I think it could be useful for parallel training and more convenient.
I added this feature.
Avg-loss will be saved to the 2 images: chart.png & chart_your_cfg_name.png
AlexeyAB
on 24 Dec 2019
@AlexeyAB
Thanks, it will be useful.
I will have tomorrow results from new trainings, but I have problem with "yolov3-tiny_3l_sway_5x5_maxout.cfg.txt", on first mAP calculation (1000 iteration), I am getting this error:

I increased number of subdivisions and run training one more time.
EDIT:
With subdivisions = 32 everything is working correctly.
Andropogon
on 25 Dec 2019
@AlexeyAB
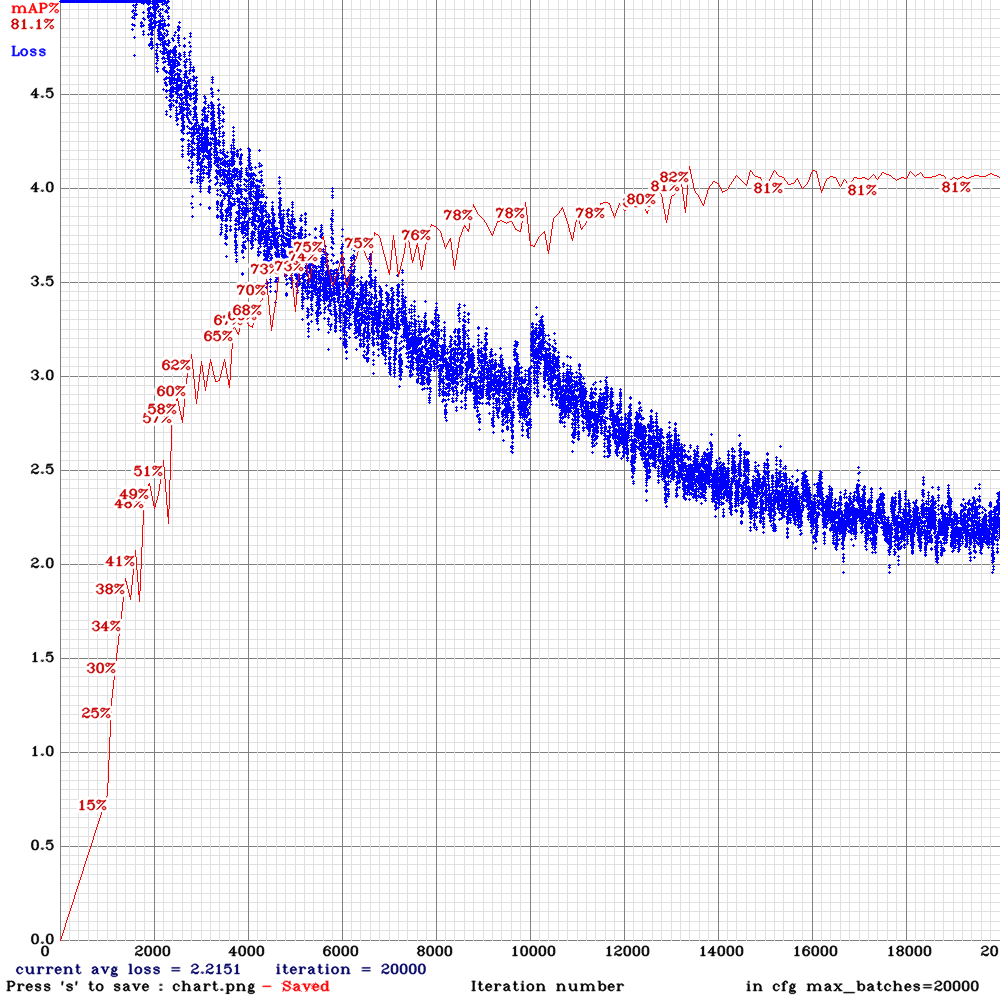
New training results:
Tiny_3l_resize:
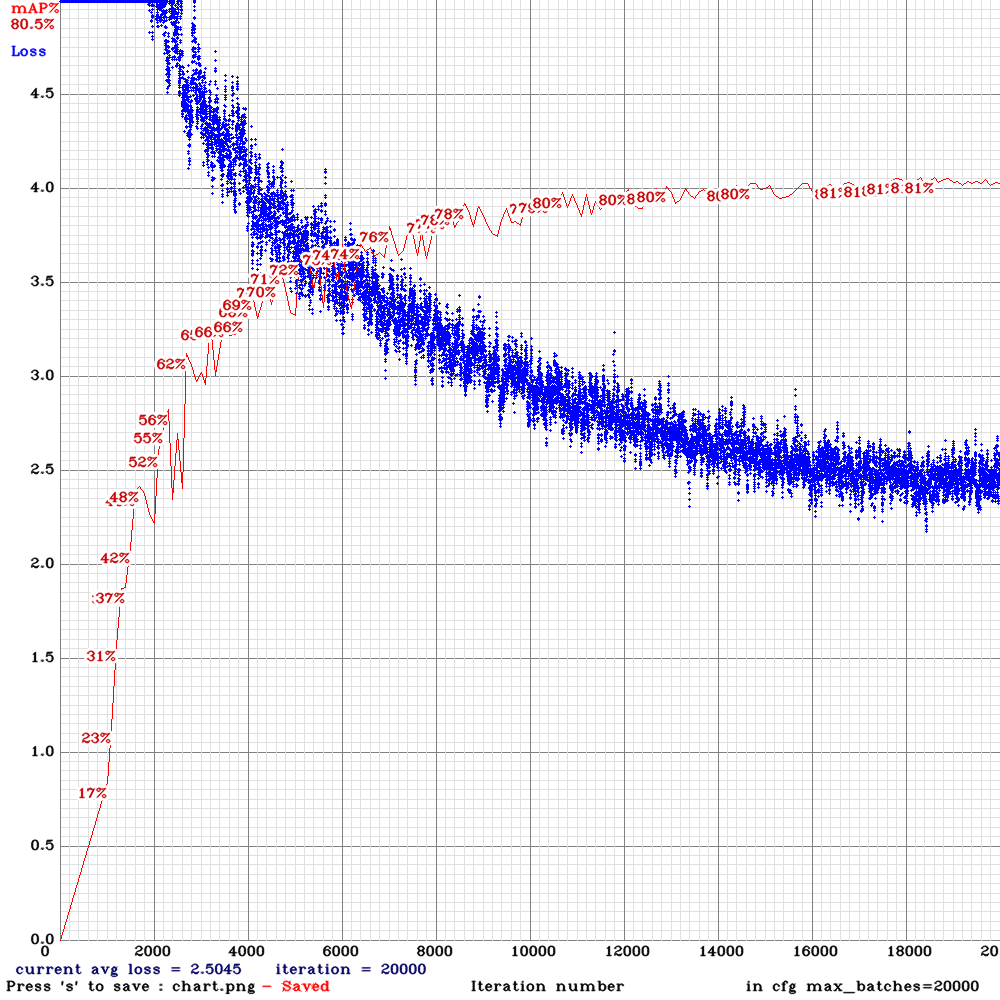
Tiny_3l_sway_5x5_maxout:
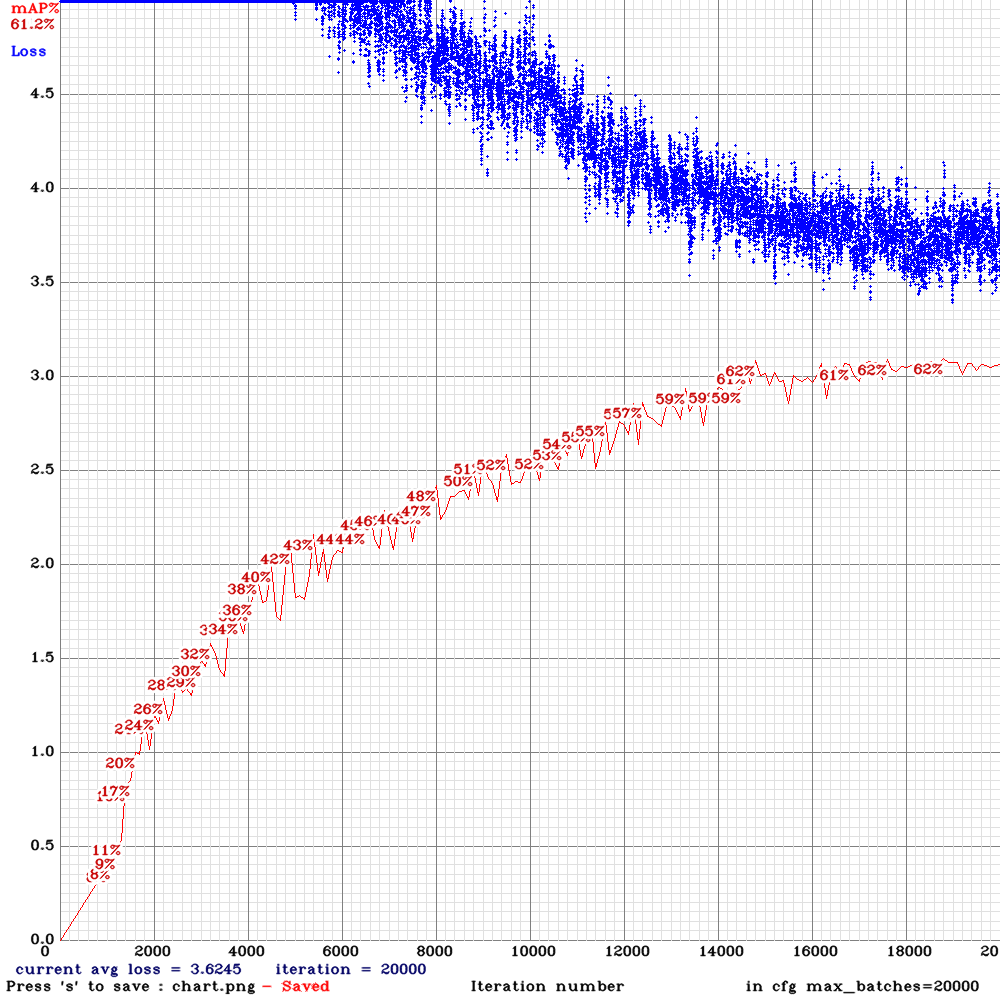
Tiny_3l_roatate_whole_maxout:
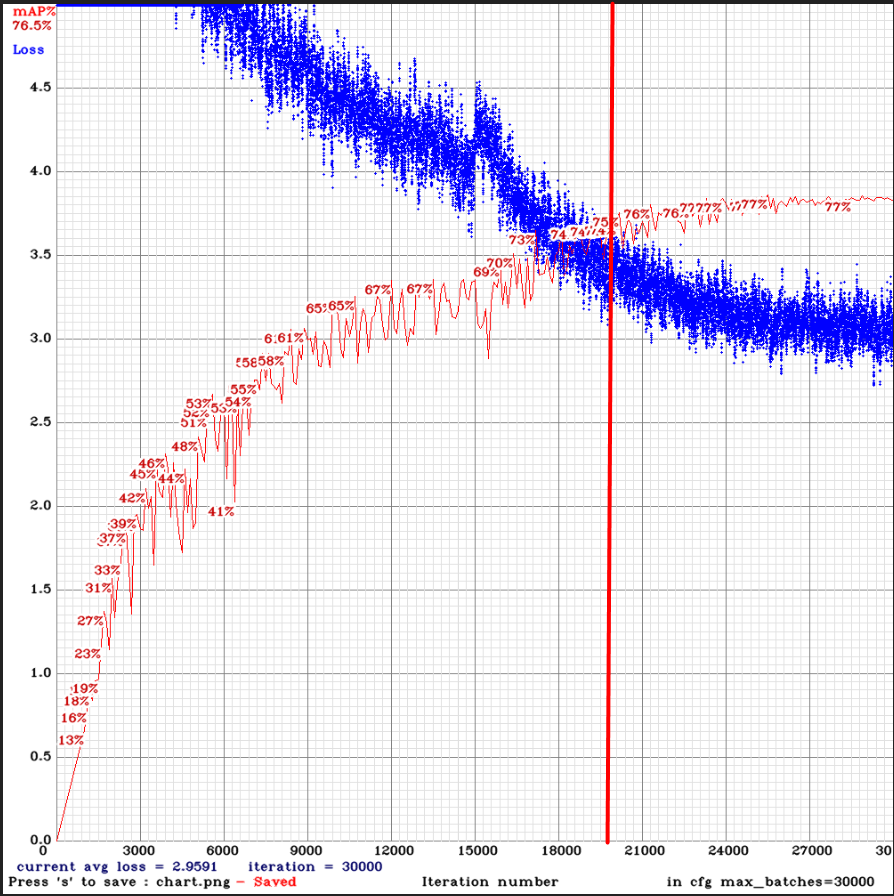
Tiny_3l_stretch_concat_maxout:
Could you give me a short description of how your changes influence network work? I will be very grateful.
Andropogon
on 26 Dec 2019
@Andropogon Thanks!
Are these mAP values for Training or Validation dataset?
What is the mAP for Validation dataset?
AlexeyAB
on 26 Dec 2019
@Andropogon Thanks!
Are these mAP values for Training or Validation dataset?
What is the mAP for Validation dataset?
@AlexeyAB
As previously it is mAP for this "test-set" (probably this name convection is not the best) that is created from other images than in training set but from the same videos (so very similar).
For validation dataset (the set that contains only images (frames) from other videos than this from the training set) mAP (for best weights) is like below:
Tiny_3l_resize:
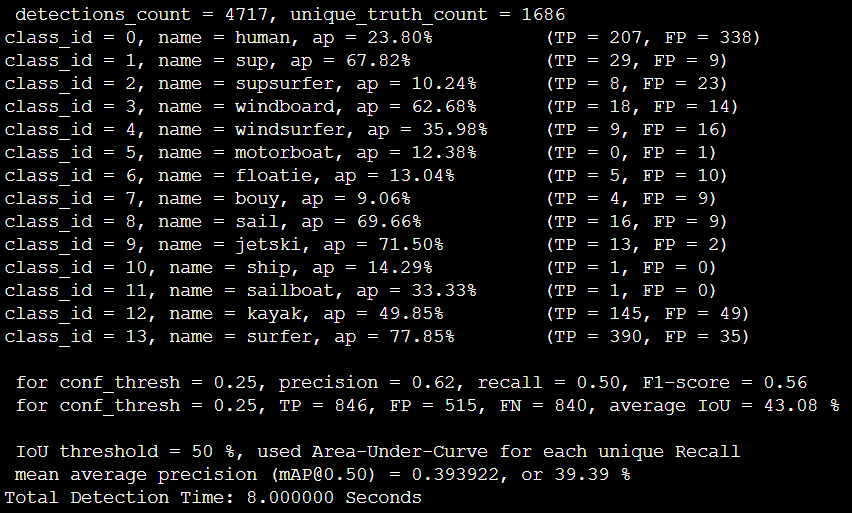
Tiny_3l_sway_5x5_maxout:
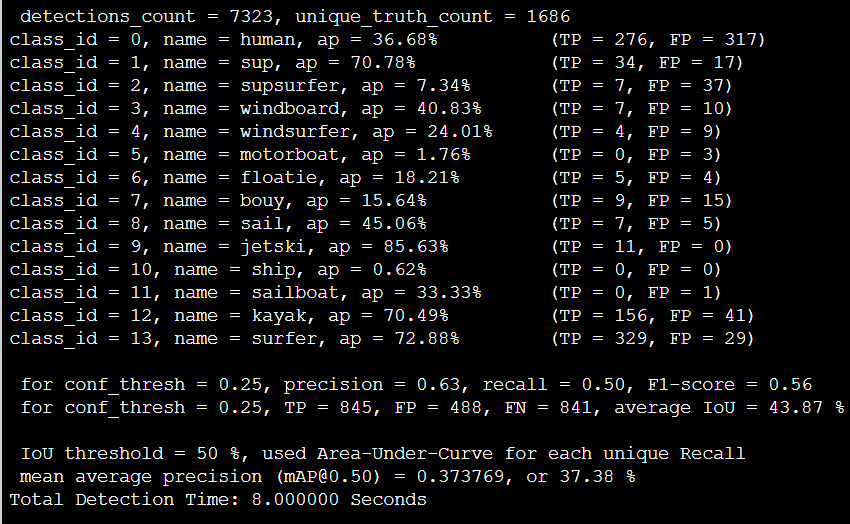
Tiny_3l_roatate_whole_maxout: (20000 weigths)
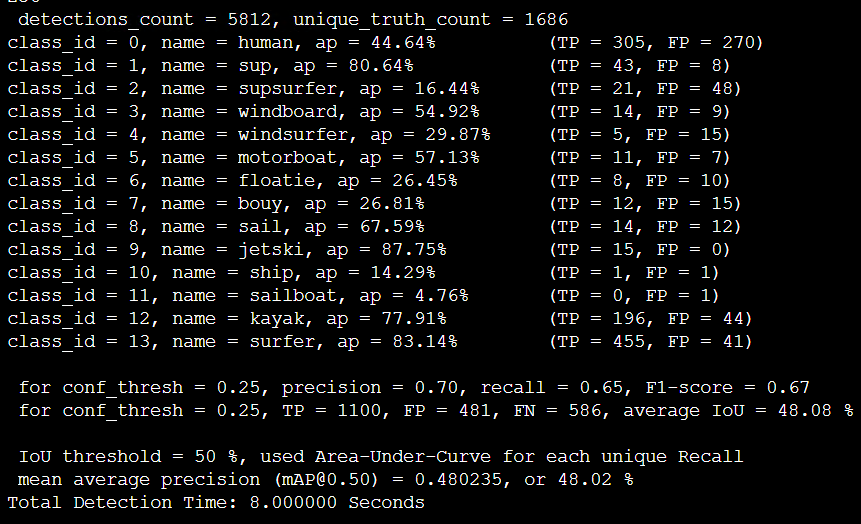
Tiny_3l_stretch_concat_maxout:
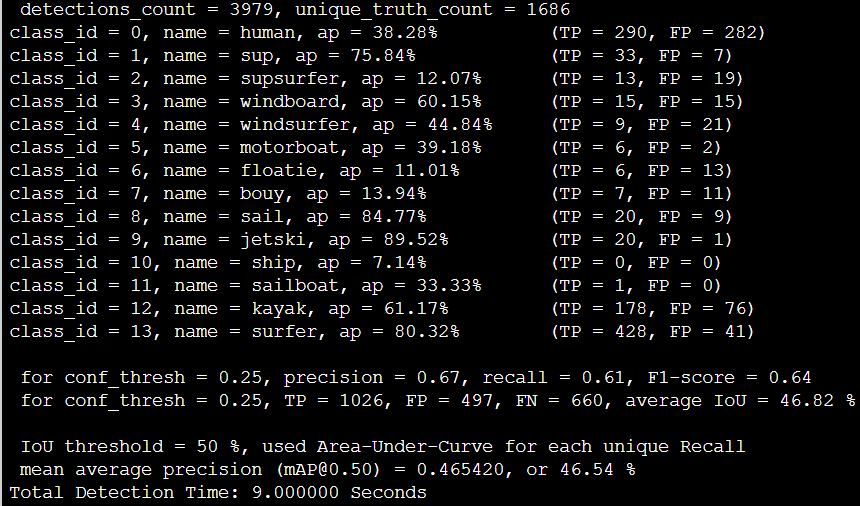
Andropogon
on 26 Dec 2019
@Andropogon Thanks!
- Did I understand correctly that the results are as follows?
- How many images in each of 3: train-set, valid-set (the same videos), valid-set (other videos)?
- Can you also measure mAP for
train-setfor all (or some of) these models?
| Model | RTX 2070 Inference time, ms | [email protected] train-set | [email protected] valid-set (the same videos) | [email protected] valid-set (other videos) |
|---|---|---|---|---|
| Tiny 3l | 6.3 ms | - | 81% | 42.79% |
| Rotate_maxout| 5.1 ms | - | 63% | 40.37% |
| Strech_maxout| 5.1 ms | - | 64% | 38.68% |
| Sway_maxout| 5.1 ms | - | 70% | 43.91% |
|---|---|---|---|---|
| Tiny_3l_resize | 6.3 ms | - | 81% | 39.39% |
| Tiny_3l_sway_5x5_maxout | 9.0 ms | - | 62% | 37.38% |
| Tiny_3l_roatate_whole_maxout | 8.9 ms | - | 77% | 48.02% |
| Tiny_3l_stretch_concat_maxout | 9.4 ms | - | 82% | 46.54% |
AlexeyAB
on 26 Dec 2019
@Andropogon
Could you give me a short description of how your changes influence network work? I will be very grateful.
This is a Hardcoded deformable kernel.
An object in one image is mapped to the same object in another image:
- in more than 90 percent of cases, using - affine deformations
- much less likely using perspective deformations
- and very rarely they are elastic deformations
So in 90% hardcoded (scale, flip, rotate) deformations should work faster and can be more accurate than the free (elastic) deformation kernel - https://arxiv.org/abs/1910.02940v1
There are:
- deformable convolution - https://arxiv.org/abs/1703.06211v3 and https://towardsdatascience.com/review-dcn-deformable-convolutional-networks-2nd-runner-up-in-2017-coco-detection-object-14e488efce44
- deformable kernel - https://arxiv.org/abs/1910.02940v1
- hardcoded deformable kernel - these models, where are hardcoded several deformations in 1 conv-layer, (4 deformations), and Maxout selects the most suitable deformation
- rotation (rotation angle = 0, 90, 180, 270 degree)
- sway (flip, and rotation angle -15, 0, -15)
- stretch (scale 0.65, 0.8, 1, 1.3)
As you can see Sway_maxout has higher [email protected] valid-set (other videos) with lower Inference-time than Tiny 3l
Try another 5 new models, which should be better:
And show:
- [email protected] valid-set (the same videos)
- [email protected] valid-set (other videos)
AlexeyAB
on 27 Dec 2019
@AlexeyAB
First of all, thank you for the description of hardcoded deformable kernel and links to the papers.
Did I understand correctly that the results are as follows?
Yes :)
How many images in each of 3: train-set, valid-set (the same videos), valid-set (other videos)?
Train -> 1445
Test -> 403
Validation -> 236
Can you also measure mAP for train-set for all (or some of) these models?
Yes, here is the updated table:
| Model | RTX 2070 Inference time, ms | [email protected] train-set | [email protected] valid-set (the same videos) | [email protected] valid-set (other videos) |
| ------------- | ------------- | ------------- | ------------- | ------------- |
| Tiny 3l | 6.3 ms | 86.01% | 81% | 42.79% |
| Rotate_maxout | 5.1 ms | 79.06% | 63% | 40.37% |
| Strech_maxout | 5.1 ms | 81.51% | 64% | 38.68% |
| Sway_maxout | 5.1 ms | 82.78% | 70% | 43.91% |
| --- | --- | --- | --- | --- |
| Tiny_3l_resize | 6.3 ms | 88.40% | 81% | 39.39% |
| Tiny_3l_sway_5x5_maxout | 9.0 ms | 70.05% | 62% | 37.38% |
| Tiny_3l_roatate_whole_maxout | 8.9 ms | 81.95% | 77% | 48.02% |
| Tiny_3l_stretch_concat_maxout | 9.4 ms | 87.56 | 82% | 46.54% |
Try another 5 new models, which should be better:
yolov3-tiny_3l_rotate_whole_concat_maxout.cfg.txt
yolov3-tiny_3l_stretch_whole_concat_maxout.cfg.txt
yolov3-tiny_3l_sway_whole_concat_maxout.cfg.txt
yolov3-tiny_3l_stretch_sway_whole_concat_maxout.cfg.txt
yolov3-tiny_3l_ref_concat_maxout.cfg.txtAnd show:
[email protected] valid-set (the same videos)
[email protected] valid-set (other videos)
Training is running now, I am going to paste results tomorrow.
Andropogon
on 30 Dec 2019
Edit: "Rest of results added"
@AlexeyAB
Here are the results:
yolov3-tiny_3l_rotate_whole_concat_maxout.cfg.txt
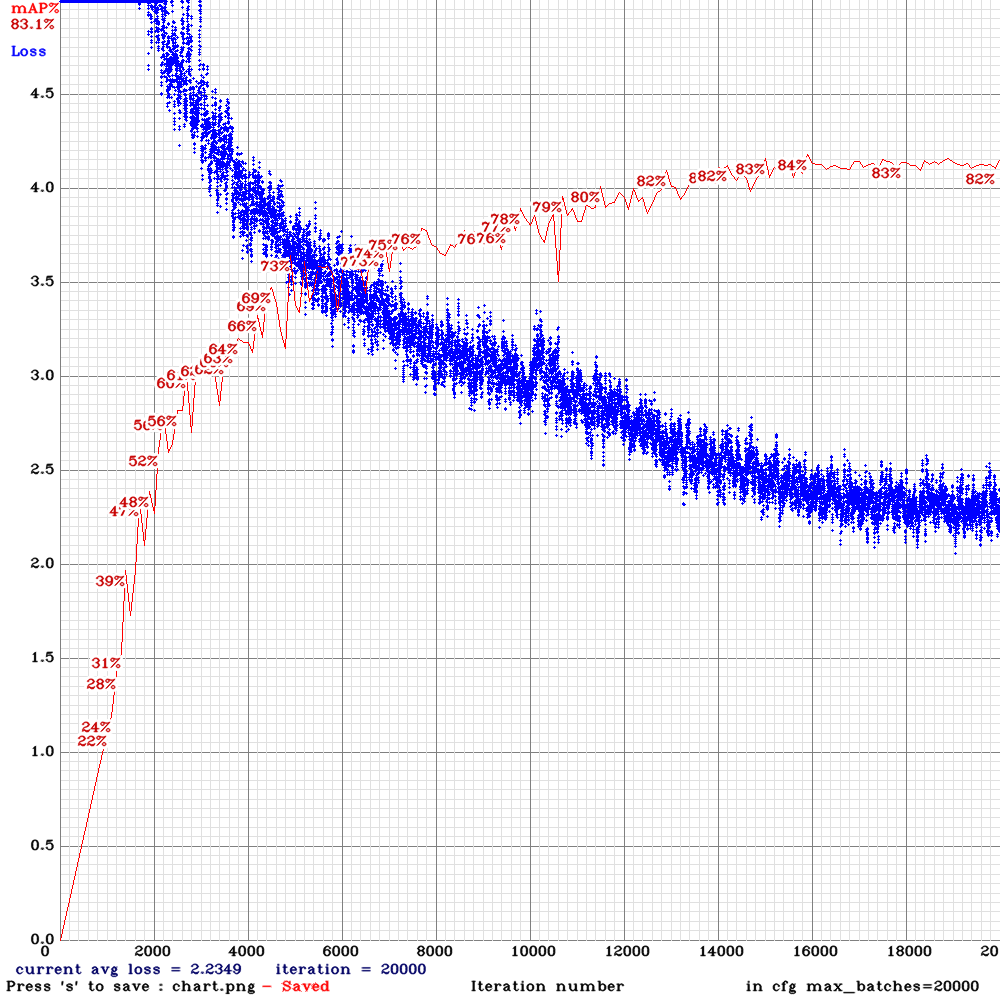
yolov3-tiny_3l_stretch_whole_concat_maxout.cfg.txt ( I need to stop and resume training, because of some problem with GPU):
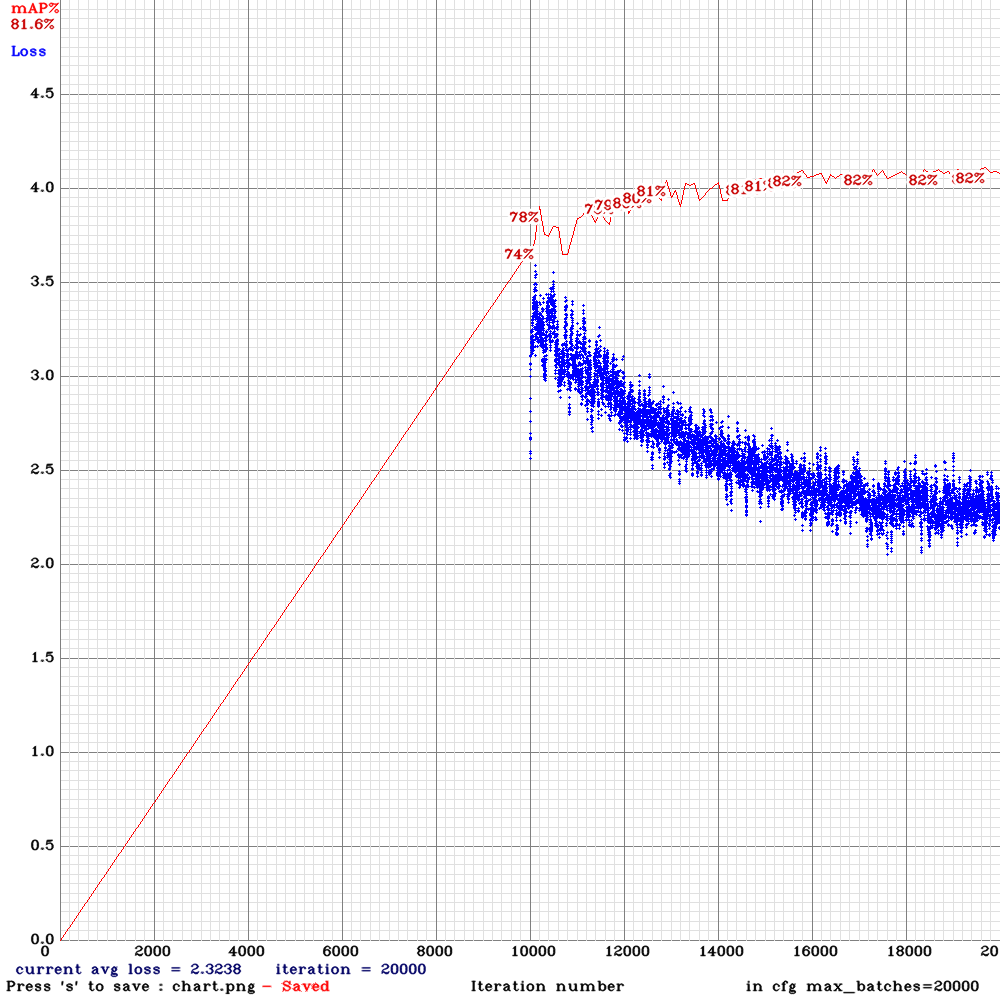
yolov3-tiny_3l_sway_whole_concat_maxout.cfg.txt
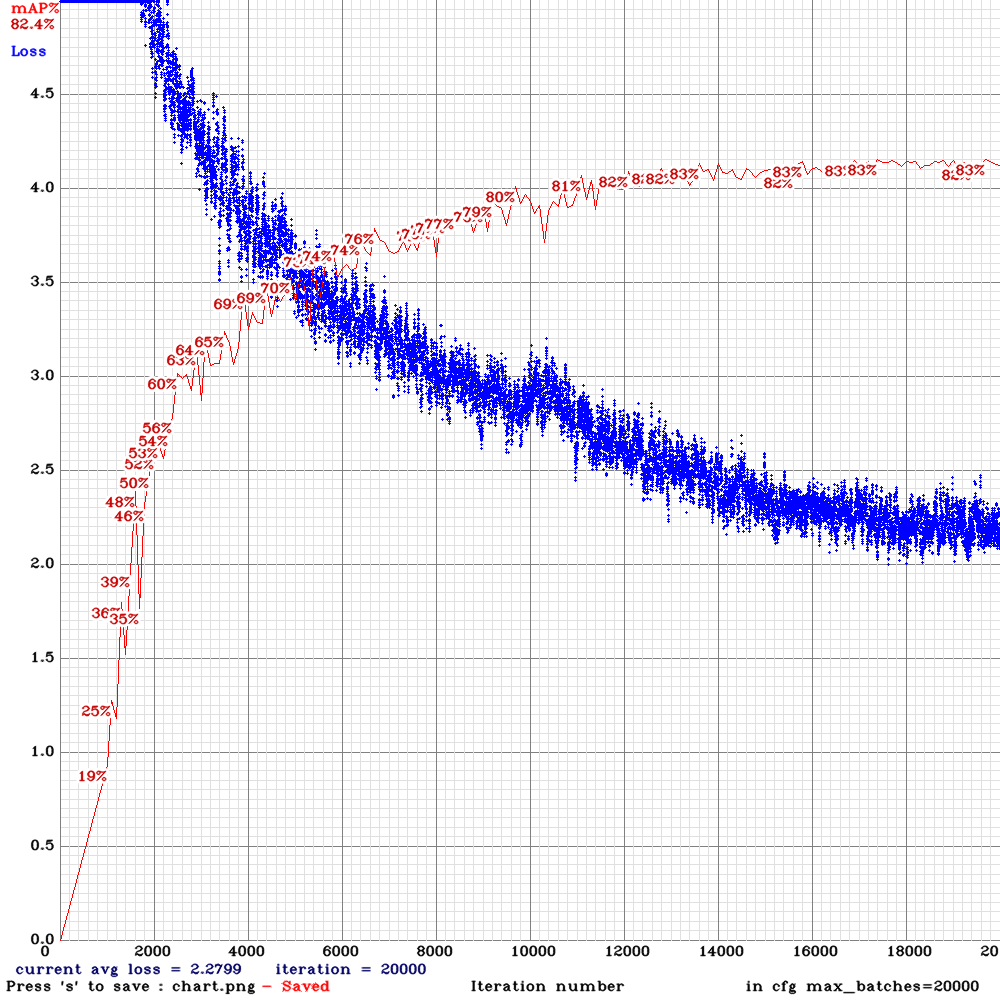
yolov3-tiny_3l_stretch_sway_whole_concat_maxout.cfg.txt
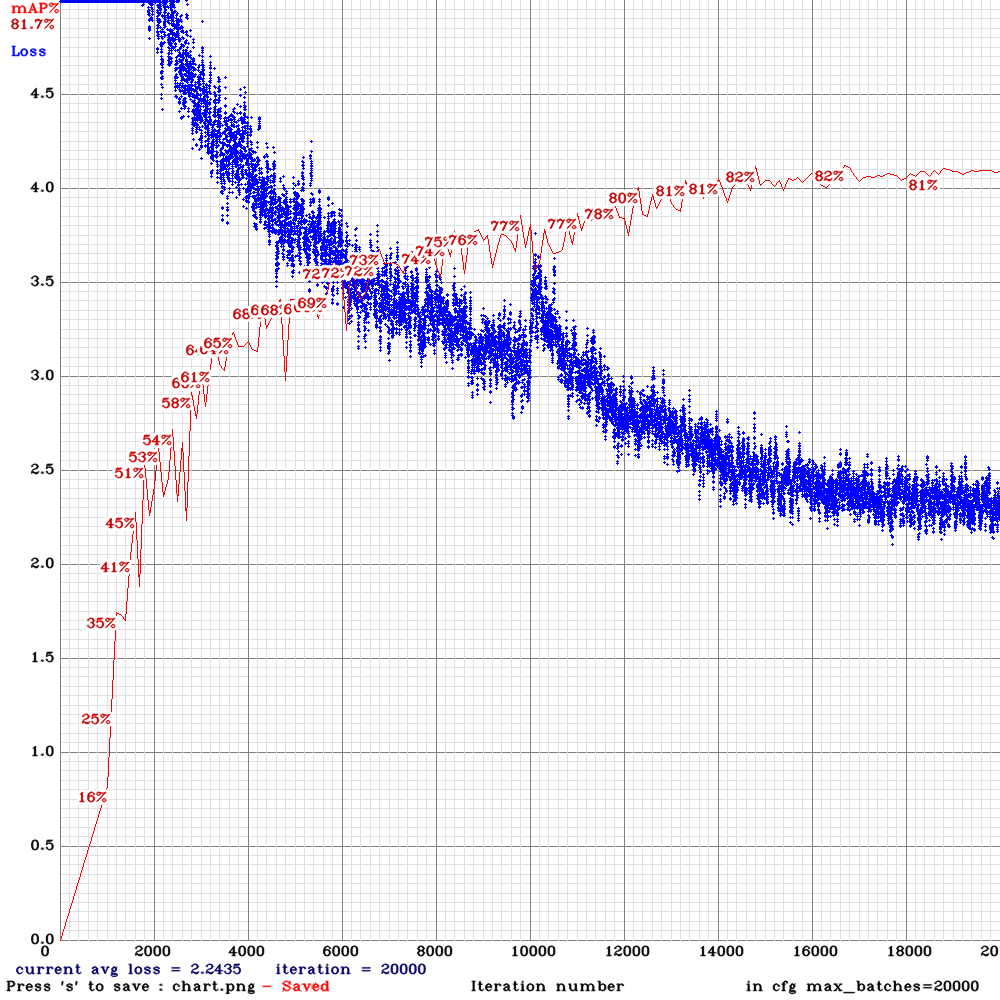
yolov3-tiny_3l_ref_concat_maxout.cfg.txt
Updated table:
| Model | RTX 2070 Inference time, ms | [email protected] train-set | [email protected] valid-set (the same videos) | [email protected] valid-set (other videos) |
| ------------- | ------------- | ------------- | ------------- | ------------- |
| Tiny 3l | 6.3 ms | 86.01% | 81% | 42.79% |
| Rotate_maxout | 5.1 ms | 79.06% | 63% | 40.37% |
| Strech_maxout | 5.1 ms | 81.51% | 64% | 38.68% |
| Sway_maxout | 5.1 ms | 82.78% | 70% | 43.91% |
| tiny_3l_ref_maxout | - ms | - | - | - |
| tiny_3l_ref_same_filters | - ms | - | - | - |
| --- | --- | --- | --- | --- |
| Tiny_3l_resize | 6.3 ms | 88.40% | 81% | 39.39% |
| Tiny_3l_sway_5x5_maxout | 9.0 ms | 70.05% | 62% | 37.38% |
| Tiny_3l_roatate_whole_maxout | 8.9 ms | 81.95% | 77% | 48.02% |
| tiny_3l_sway_whole_maxout | - ms | - | - | - |
| tiny_3l_stretch_whole_maxout | - ms | - | - | - |
| tiny_3l_stretch_sway_whole_maxout | - ms | - | - | - |
| tiny_3l_stretch_sway_reduce_whole_maxout | - ms | - | - | - |
| Tiny_3l_stretch_concat_maxout | 9.4 ms | 87.56 | 82% | 46.54% |
| --- | --- | --- | --- | --- |
| Tiny_3l_rotate_whole_concat_maxout | 12.6 ms | 87.98% | 83.61% | 45.20% |
| Tiny_3l_stretch_whole_concat_maxout | 12.6 ms | 88.62% | 82.17% | 45.70% |
| Tiny_3l_sway_whole_concat_maxout | 12.6 ms | 89.76% | 83.05% | 47.90% |
| Tiny_3l_stretch_sway_whole_concat_maxout | 12.0 ms | 88.30% | 82.41% | 48.09% |
| Tiny_3l_ref_concat_maxout | 12.6 ms | 91.10% | 85.17% | 46.25% |
| - | - ms | - | - | - |
Andropogon
on 31 Dec 2019
@Andropogon Thanks! Happy New Year!
Latter I will add new better models.
AlexeyAB
on 31 Dec 2019
@AlexeyAB Ok, you can add also "RTX 2070 Inference time" for these new models, because I have other GPU so I cant check it. I am making now training using the best models created by you for the datasets with other class divisions (like combined "human" and "surfer" class etc.) to check how this influences on accuracy.
Happy New Year :) !
Andropogon
on 31 Dec 2019
@Andropogon Hi, good job and interesting dateset!
I think the detection object of your dataset belong to tiny object detection problem, so is it necessary to recalc anchors and train again to see MAP values on your test dataset? Because I see your current cfg' anchors are as same as MS CoCo. :) @AlexeyAB
 lq0104
on 3 Jan 2020
lq0104
on 3 Jan 2020
@Andropogon Hi,
I added "RTX 2070 Inference time" for last models in your table.
There are another 6 new models:
AlexeyAB
on 3 Jan 2020
@lq0104 Thank you for nice words about my dataset - it will be available for free download I think in one or two months. About "recalc of anchors", honestly speaking I know nothing about it :) It is my first deep-learning / object-detection project and I have a lot to teach :). I will read about it when I will have some free time.
EDIT
I find this information in Alexey Darknet README:

Because I am not an expert I wasn't doing anything with anchors :)
@AlexeyAB
Thanks, I will train them as soon I will be able, but there could be some delay because now other people for my university have to use the same computer that I am using for this trainings :D.
Andropogon
on 4 Jan 2020
@Andropogon Yes, you shouldn't recalc anchors.
Do you have any progress?
AlexeyAB
on 13 Jan 2020
@AlexeyAB Hi, unfortonately not yet. I don't have computer for deep learnig right now (because other people are using mine one), so I am not able now to train these models.
By the way in next week I have engineering work defence, my engineer's thesis is about object detection of floating objects, so I used some your tips and our two models in comparison (Tiny_3l_resize and Tiny_3l_roatate_whole_maxout). So I want to say "thank you" for whole your help.
Next models I will train as soon as it will be possible.
Andropogon
on 14 Jan 2020
@AlexeyAB I started trainings for the first 3 models - I hope that I will be able to paste all results here on the weekend.
Andropogon
on 24 Jan 2020
@AlexeyAB
Finally, I have results for new config files:
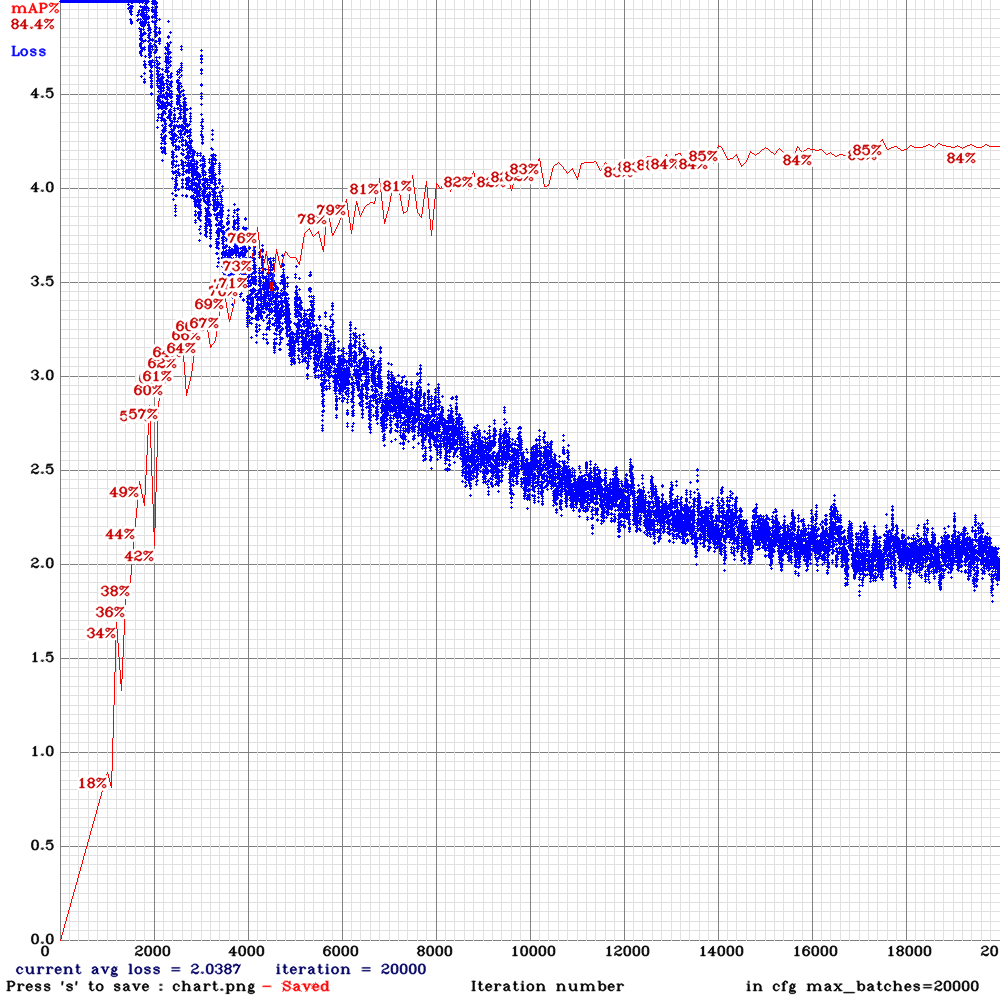
yolov3-tiny_3l_ref_maxout.cfg.txt
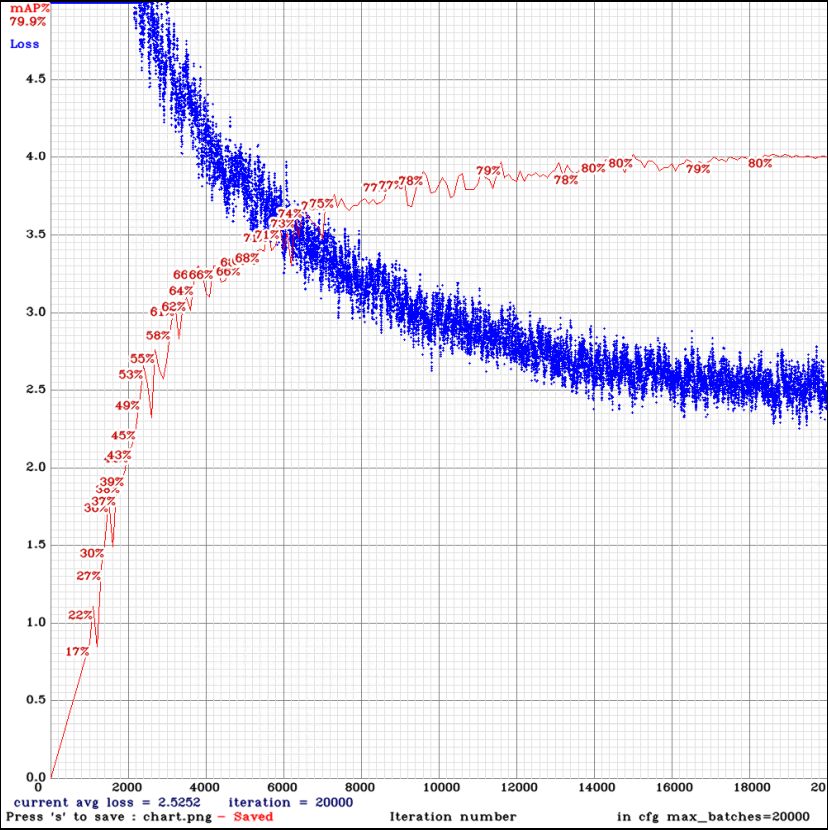
yolov3-tiny_3l_ref_same_filters.cfg.txt
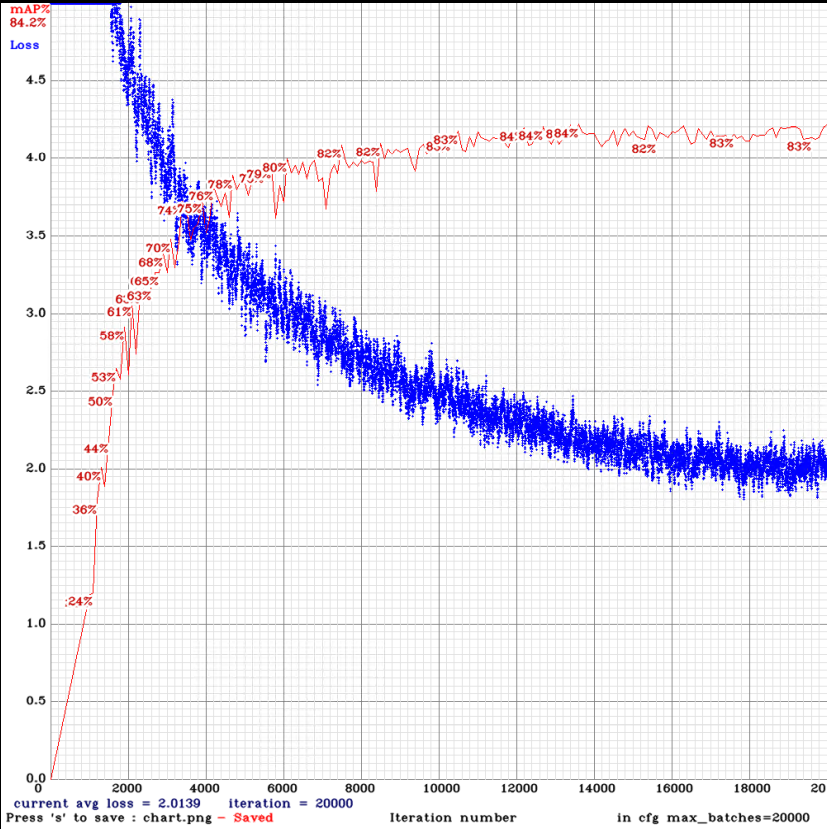
yolov3-tiny_3l_stretch_sway_reduce_whole_maxout.cfg.txt
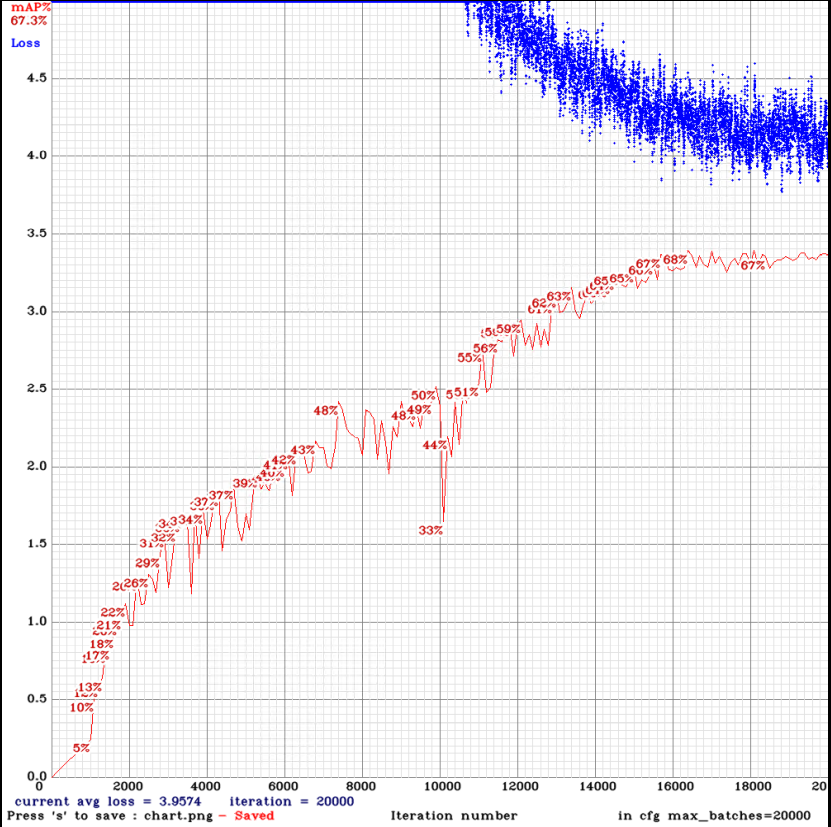
yolov3-tiny_3l_stretch_sway_whole_maxout.cfg.txt
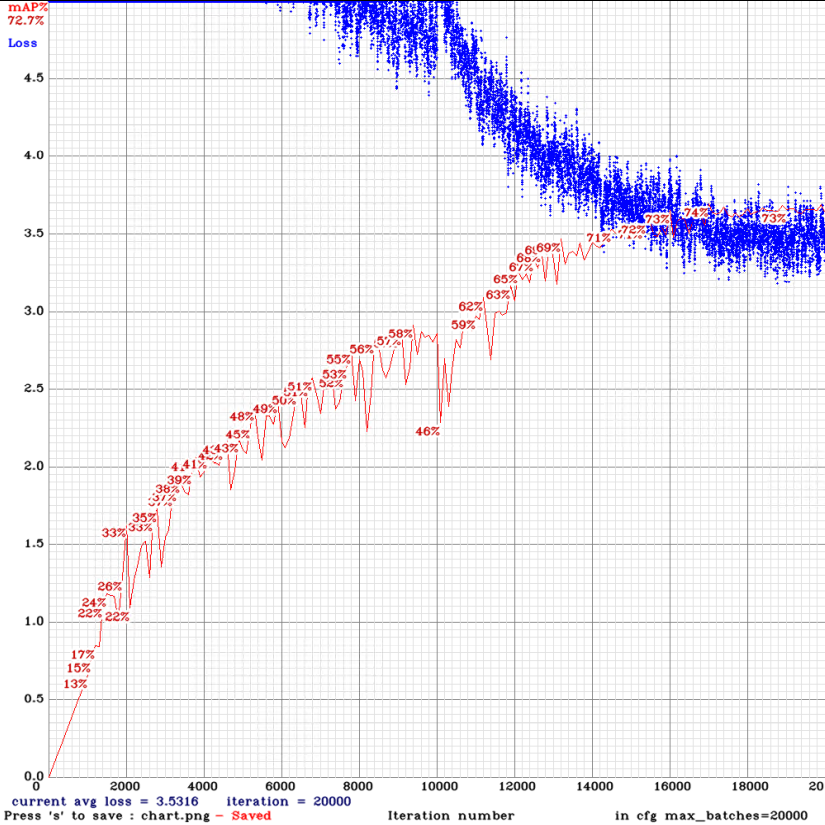
yolov3-tiny_3l_stretch_whole_maxout.cfg.txt
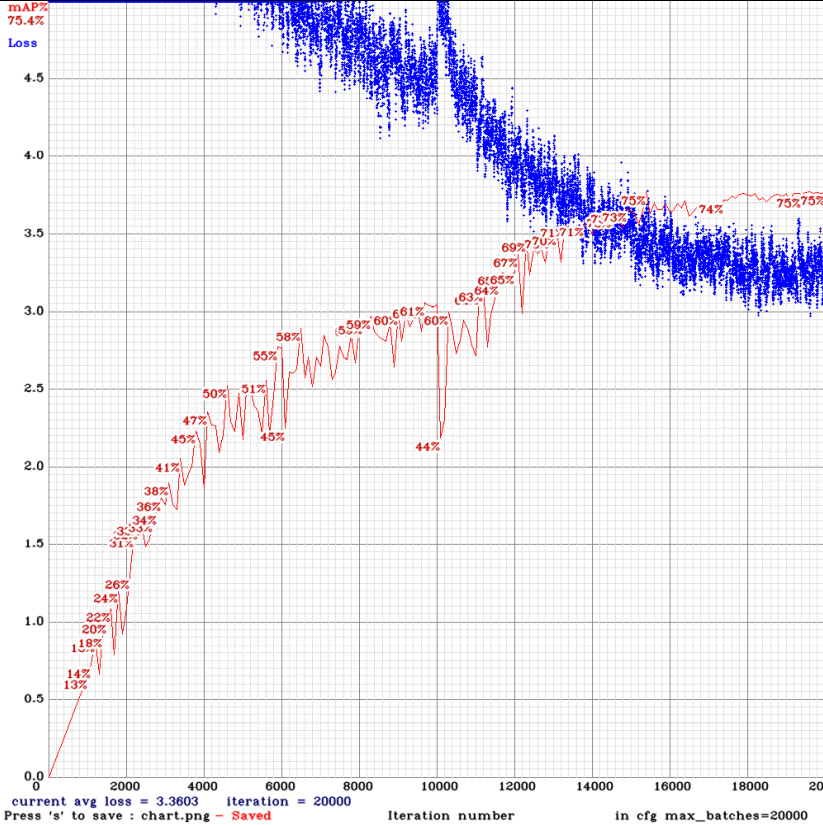
yolov3-tiny_3l_sway_whole_maxout.cfg.txt
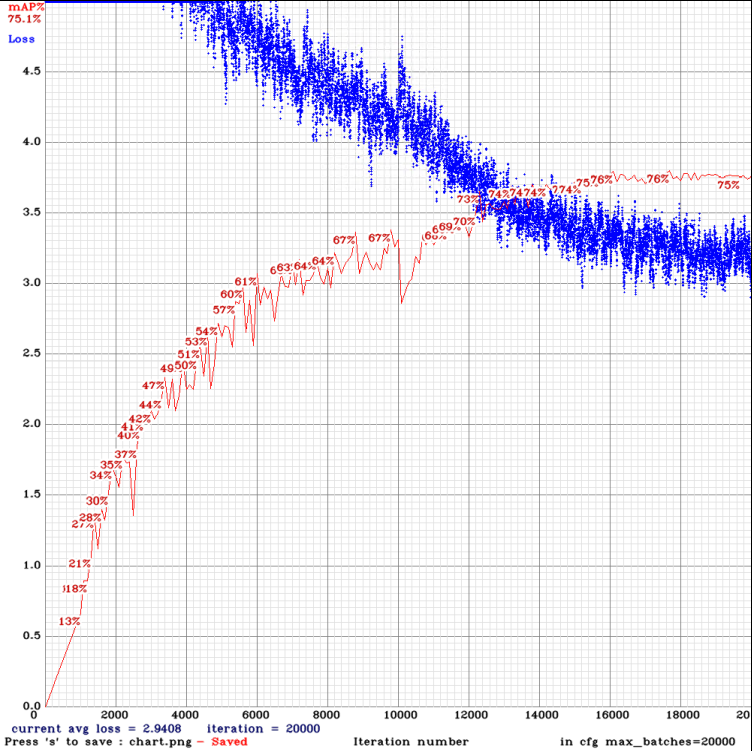
Updated table:
| Model | RTX 2070 Inference time, ms | [email protected] train-set | [email protected] valid-set (the same videos) | [email protected] valid-set (other videos) |
| ------------- | ------------- | ------------- | ------------- | ------------- |
| Tiny 3l | 6.3 ms | 86.01% | 81% | 42.79% |
| Rotate_maxout | 5.1 ms | 79.06% | 63% | 40.37% |
| Strech_maxout | 5.1 ms | 81.51% | 64% | 38.68% |
| Sway_maxout | 5.1 ms | 82.78% | 70% | 43.91% |
| tiny_3l_ref_maxout | - ms | 87.25% | 80.25% | 43.25% |
| tiny_3l_ref_same_filters | - ms | 90.55% | 84.29% | 47.17% |
| --- | --- | --- | --- | --- |
| Tiny_3l_resize | 6.3 ms | 88.40% | 81% | 39.39% |
| Tiny_3l_sway_5x5_maxout | 9.0 ms | 70.05% | 62% | 37.38% |
| Tiny_3l_roatate_whole_maxout | 8.9 ms | 81.95% | 77% | 48.02% |
| tiny_3l_sway_whole_maxout | - ms | 81.31%| 75.90% | 43.17% |
| tiny_3l_stretch_whole_maxout | - ms | 80.86% | 75.41% | 40.80% |
| tiny_3l_stretch_sway_whole_maxout | - ms | 78.76% | 73.84% | 43.44% |
| tiny_3l_stretch_sway_reduce_whole_maxout | - ms | 71.48% | 67.85% | 37.75% |
| Tiny_3l_stretch_concat_maxout | 9.4 ms | 87.56 | 82% | 46.54% |
| --- | --- | --- | --- | --- |
| Tiny_3l_rotate_whole_concat_maxout | 12.6 ms | 87.98% | 83.61% | 45.20% |
| Tiny_3l_stretch_whole_concat_maxout | 12.6 ms | 88.62% | 82.17% | 45.70% |
| Tiny_3l_sway_whole_concat_maxout | 12.6 ms | 89.76% | 83.05% | 47.90% |
| Tiny_3l_stretch_sway_whole_concat_maxout | 12.0 ms | 88.30% | 82.41% | 48.09% |
| Tiny_3l_ref_concat_maxout | 12.6 ms | 91.10% | 85.17% | 46.25% |
| - | - ms | - | - | - |
Andropogon
on 26 Jan 2020
Related issues
 yongcong1415
·
3Comments
yongcong1415
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 Cipusha
·
3Comments
Cipusha
·
3Comments
 PROGRAMMINGENGINEER-NIKI
·
3Comments
PROGRAMMINGENGINEER-NIKI
·
3Comments
 Jacky3213
·
3Comments
Jacky3213
·
3Comments
Most helpful comment
@AlexeyAB

Finally, I have results for new config files:
yolov3-tiny_3l_ref_maxout.cfg.txt
yolov3-tiny_3l_ref_same_filters.cfg.txt

yolov3-tiny_3l_stretch_sway_reduce_whole_maxout.cfg.txt

yolov3-tiny_3l_stretch_sway_whole_maxout.cfg.txt

yolov3-tiny_3l_stretch_whole_maxout.cfg.txt

yolov3-tiny_3l_sway_whole_maxout.cfg.txt

Updated table:
| Model | RTX 2070 Inference time, ms | [email protected] train-set | [email protected] valid-set (the same videos) | [email protected] valid-set (other videos) |
| ------------- | ------------- | ------------- | ------------- | ------------- |
| Tiny 3l | 6.3 ms | 86.01% | 81% | 42.79% |
| Rotate_maxout | 5.1 ms | 79.06% | 63% | 40.37% |
| Strech_maxout | 5.1 ms | 81.51% | 64% | 38.68% |
| Sway_maxout | 5.1 ms | 82.78% | 70% | 43.91% |
| tiny_3l_ref_maxout | - ms | 87.25% | 80.25% | 43.25% |
| tiny_3l_ref_same_filters | - ms | 90.55% | 84.29% | 47.17% |
| --- | --- | --- | --- | --- |
| Tiny_3l_resize | 6.3 ms | 88.40% | 81% | 39.39% |
| Tiny_3l_sway_5x5_maxout | 9.0 ms | 70.05% | 62% | 37.38% |
| Tiny_3l_roatate_whole_maxout | 8.9 ms | 81.95% | 77% | 48.02% |
| tiny_3l_sway_whole_maxout | - ms | 81.31%| 75.90% | 43.17% |
| tiny_3l_stretch_whole_maxout | - ms | 80.86% | 75.41% | 40.80% |
| tiny_3l_stretch_sway_whole_maxout | - ms | 78.76% | 73.84% | 43.44% |
| tiny_3l_stretch_sway_reduce_whole_maxout | - ms | 71.48% | 67.85% | 37.75% |
| Tiny_3l_stretch_concat_maxout | 9.4 ms | 87.56 | 82% | 46.54% |
| --- | --- | --- | --- | --- |
| Tiny_3l_rotate_whole_concat_maxout | 12.6 ms | 87.98% | 83.61% | 45.20% |
| Tiny_3l_stretch_whole_concat_maxout | 12.6 ms | 88.62% | 82.17% | 45.70% |
| Tiny_3l_sway_whole_concat_maxout | 12.6 ms | 89.76% | 83.05% | 47.90% |
| Tiny_3l_stretch_sway_whole_concat_maxout | 12.0 ms | 88.30% | 82.41% | 48.09% |
| Tiny_3l_ref_concat_maxout | 12.6 ms | 91.10% | 85.17% | 46.25% |
| - | - ms | - | - | - |