Darknet: CSPNet - New models and the most comprehensive comparison of detection models
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
The most comprehensive comparison of detection models:
- paper: https://arxiv.org/abs/1911.11929v1
- models: https://github.com/WongKinYiu/CrossStagePartialNetworks
New model - this model can be used with this Darknet repository:
CSPResNeXt50-PANet-SPP- 512x512 - 38.0%[email protected], 60.0%[email protected]- 1.5x faster than Yolov3-SPP the same [email protected] accuracy and higher [email protected] accuracy:
- cfg: https://raw.githubusercontent.com/WongKinYiu/CrossStagePartialNetworks/master/cfg/csresnext50-panet-spp.cfg
- weights: https://drive.google.com/open?id=1Y6vJQf-Vu9O0tB10IUYNttktA-DLp5T1
It's interesting, that:
- old
Yolov3 416x416 (without SPP)has higher [email protected] and faster thanResNet101-CenterNet 512x512
private model
CSPPeleeNet - EFM (SAM) 512x5122x faster with approximately the same accuracy asYolo v3 320x320our classifier
EfficientNet B0 (224x224) 0.9 BFLOPS - 0.45 B_FMA (16ms / RTX 2070), 4.9M params, 71.3% Top1 | 90.4% Top5has higher accuracy than officialEfficientNet B0(official) (224x224) 0.78 BFLOPS - 0.39 B_FMA, 5.3M params, 70.0% Top1 | 88.9% Top5https://github.com/WongKinYiu/CrossStagePartialNetworks#small-models


FPS is measured by using commands like this: classifier_bench_models.cmd.txt
./darknet classifier demo cfg/imagenet1k_c.data models/csdarknet53.cfg models/csdarknet53.weights test.mp4 -benchmark
- GPU FPS - Darknet (GPU=1 CUDNN=1 CUDNN_HALF=1) - Ge Force RTX 2070 (Tensor Cores)
- CPU FPS - Darknet (AVX=1 OPENMP=1) - Intel Core i7 6700K (4 Cores / 8 Logical-cores)
There are FPS
- for original network resolution from cfg-file
- in parentheses (FPS for network resolution 512x512)
- in square brackets [FPS for network resolution 608x608]
Conclusion:
- use
filters=256 groups=2andfilters=512 groups=8for 256x256 network resolution - use
groups=8for 512x512 network resolution - use
groups=32for 608x608 and higher network resolution
Big Models
| Model | #Parameter | BFLOPs | Top-1 | Top-5 | cfg | weight | GPU FPS orig (512) [608] | CPU FPS orig (512) [608] |
| :---- | :--------: | :----: | :---: | :---: | :-: | :----: | :--: | :--: |
| | | | | | | |
| CSPDarknet19-fast | - | 2.5 | - | - | cfg | - | 213 (149) [116] | 19..7 (4.6) [3.2] |
| Spinenet49 | - | 8.5 | - | - | cfg | - | 49 (44) [43] | 7.6 (2.0) [1.4] |
| DarkNet-53 [1] | 41.57M | 18.57 | 77.2 | 93.8 | cfg | weight | 113 (56) [38] | 4.9 (1.1) |
| CSPDarkNet-53g | - | 11.03 (-40%) | - | - | cfg | - | 122 (64) [46] | 6.6 (1.5) [1.1] |
| CSPDarkNet-53ghr | 9.74M (-76%) | 5.67 (-70%) | - | - | cfg | - | 100 (75) [57] | 8.5 (2.0) [1.5] |
| CSPDarkNet-53 | 27.61M (-34%) | 13.07 (-30%) | 77.2 (=) | 93.6 (-0.2) | cfg | weight | 101 (57) [41] | 6.0 (1.3) [1.0] |
| CSPDarkNet-53-Elastic | - | 7.74 (-58%) | 76.1 (-1.1) | 93.3 (-0.5) | cfg | weight | 66 | 7.5 |
| | | | | |
| ResNet-50 [2] | 22.73M | 9.74 | 75.8 | 92.9 | cfg | weight | 135 (73) | 8.6 (2.0) |
| CSPResNet-50 | 21.57M (-5%) | 8.97 (-8%) | 76.6 (+0.8) | 93.3 (+0.4) | cfg | weight | 131 (81) | 9.2 (2.2) |
| CSPResNet-50-Elastic | - | 9.36 (-4%) | 76.8 (+1.0) | 93.5 (+0.6) | cfg | weight | 77 | 7.8 |
| | | | | |
| ResNeXt-50 [3] | 22.19M | 10.11 | 77.8 | 94.2 | cfg | weight | 71 (60) | 6.2 (1.5) |
| CSPResNeXt-50 | 20.50M (-8%) | 7.93 (-22%) | 77.9 (+0.1) | 94.0 (-0.2) | cfg | weight | 67 (58) [50] | 6.9 (1.8) [1.28] |
| CSPResNeXt-50-gpu | 24.93M (+12%) | 9.89 (-2%) | - | - | cfg | - | 102 (66) [49] | 6.9 (1.7) [1.25] |
| CSPResNeXt-50-fast | 21.73 (-2%) | 8.81 (-13%) | - | - | cfg | - | 85 (67) [51] | 7.8 (1.9) [1.4] |
| CSPResNeXt-50-Elastic | - | 5.45 (-46%) | 77.2 (-0.6) | 93.8 (-0.4) | cfg | weight | 47 | 8.8 |
| HarDNet-138s [4] | 35.5M | 13.4 | 77.8 | - | - | - | | |
| DenseNet-264-32 [5] | 27.21M | 11.03 | 77.8 | 93.9 | - | - | | |
| ResNet-152 [2] | 60.2M | 22.6 | 77.8 | 93.6 | - | - | | |
| | | | | |
| DenseNet-201-Elastic [6] | 19.48M | 8.77 | 77.9 | 94.0 | - | - | | |
| CSPDenseNet-201-Elastic | 20.17M (+4%) | 7.13 (-19%) | 77.9 (=) | 94.0 (=) | - | - | | |
| | | | | | | |
| Res2NetLite-72 [7] | - | 5.19 | 74.7 | 92.1 | cfg | weight | 102 | 12.3 |
| | | | | | | |
Small Models
| Model | #Parameter | BFLOPs | Top-1 | Top-5 | cfg | weight | GPU FPS | CPU FPS |
| :---- | :--------: | :----: | :---: | :---: | :-: | :----: | :-: | :-: |
| | | | | | | |
| PeleeNet [8] | 2.79M | 1.017 | 70.7 | 90.0 | - | - | | |
| PeleeNet-swish | 2.79M | 1.017 | 71.5 | 90.7 | - | - | | |
| PeleeNet-swish-SE | 2.81M | 1.017 | 72.1 | 91.0 | - | - | | |
| CSPPeleeNet | 2.83M (+1%) | 0.888 (-13%) | 70.9 (+0.2) | 90.2 (+0.2) | - | - | | |
| CSPPeleeNet-swish | 2.83M (+1%) | 0.888 (-13%) | 71.7 (+0.2) | 90.8 (+0.1) | - | - | | |
| CSPPeleeNet-swish-SE | 2.85M (+1%) | 0.888 (-13%) | 72.4 (+0.3) | 91.0 (=) | - | - | | |
| SparsePeleeNet [9] | 2.39M | 0.904 | 69.6 | 89.3 | - | - | | |
| | | | | | | |
| EfficientNet-B0* [10] | 4.81M | 0.915 | 71.3 | 90.4 | cfg | weight | 143 | 6.3 |
| EfficientNet-B0 (official) [10] | - | - | 70.0 | 88.9 | - | - | | |
| | | | | | | |
| MobileNet-v2 [11] | 3.47M | 0.858 | 67.0 | 87.7 | cfg | weight | 253 | 7.4 |
| CSPMobileNet-v2 | 2.51M (-28%) | 0.764 (-11%) | 67.7 (+0.7) | 88.3 (+0.6) | cfg | weight | 218 | 7.9 |
| | | | | | | |
| Darknet Ref. [12] | 7.31M | 0.96 | 61.1 | 83.0 | cfg | weight | 511 | 51 |
| CSPDenseNet Ref. | 3.48M (-52%) | 0.886 (-8%) | 65.7 (+4.6) | 86.6 (+3.6) | - | - | | |
| CSPPeleeNet Ref. | 4.10M (-44%) | 1.103 (+15%) | 68.9 (+7.8) | 88.7 (+5.7) | - | - | | |
| CSPDenseNetb Ref. | 1.38M (-81%) | 0.631 (-34%) | 64.2 (+3.1) | 85.5 (+2.5) | - | - | | |
| CSPPeleeNetb Ref. | 2.01M (-73%) | 0.897 (-7%) | 67.8 (+6.7) | 88.1 (+5.1) | - | - | | |
| | | | | | | |
| ResNet-10 [2] | 5.24M | 2.273 | 63.5 | 85.0 | cfg | weight | 425 | 29.2 |
| CSPResNet-10 | 2.73M (-48%) | 1.905 (-16%) | 65.3 (+1.8) | 86.5 (+1.5) | - | - | | |
| | | | | | | |
| MixNet-M-GPU | - | 1.065 | 71.5 | 90.5 | cfg | - | 86 | 4.7 |
| MixNet-M | - | 0.759 | - | - | cfg | - | 87 | 3.4 |
| GhostNet-1.0 | - | 0.234 | - | - | cfg | - | 62 | 12.2 |
| | | | | | | |
cuda version is V9.0.252 and it was built on 11.19.2017, so maybe the cudnn do not support group convolution well.
| Model | GPU | 256×256 | 512×512 | 608×608 |
| :-- | :-: | :-: | :-: | :-: |
| CSPResNeXt50-GPU | Titan X Pascal | 126 | 70 | 57 |
| CSPResNeXt50 | Titan X Pascal | 103 | 65 | 55 |
| CSPResNeXt50-fast | Titan X Pascal | 117 | 70 | 57 |
| CSPDarknet19 | Titan X Pascal | 242 | 144 | 118 |
| CSPDarknet53 | Titan X Pascal | 132 | 71 | 56 |
| CSPDarknet53-G | Titan X Pascal | 123 | 69 | 56 |
| CSPDarknet53-GHR | Titan X Pascal | 126 | 76 | 61 |
| Spinenet49 | Titan X Pascal | 73 | 52 | 42 |
Detector FPS on GeForce RTX 2070 (Tensor Cores):
FPS- measured using the command:./darknet detector demo cfg/coco.data ... -benchmark
CUDNN_HALF=1 (Mixed-precision is forced for Tensor Cores (if groups==1))
512x512:
yolov3-spp- 52.0 FPS - (--ms )csresnext50-panet-spp- 36.5 FPS - (--ms )
608x608:
yolov3-spp- 38.0 FPS - (--ms )csresnext50-panet-spp- 33.9 FPS (--ms )
CUDNN_HALF=0
512x512:
yolov3-spp- 41.4 FPS - (--ms)csresnext50-panet-spp- 34.5 FPS - (--ms)
608x608:
yolov3-spp- 26.1 FPS - (--ms)csresnext50-panet-spp- 30.0 FPS (--ms)
 AlexeyAB
AlexeyAB
All 124 comments
@WongKinYiu Hi,
@pjreddie used several tricks to improve accuracy:
train
darknet53.cfgfor 800000 iterations withwidth=256 height=256, then setwidth=448 height=448and continue training with another 100000 iterations, then used this model as pre-trained weights for training Yolo v3 - it gives ~+1 mAPtrain yolov3 with
width=416 height=416 random=1, then setwidth=608 height=608 random=0and train another 200 or more iterations - it improve accuracy for 608x608 inference: https://github.com/pjreddie/darknet/blob/61c9d02ec461e30d55762ec7669d6a1d3c356fb2/examples/detector.c#L66
If you didn't use these tricks, you can try to do it.
Also:
at the start of training, and at the end of trainin (between increasing resolution from 256x256 to 448x448) you can try to train 1-2 days with the highest mini_batch size for both Classifier and Detector, by using CPU-RAM: https://github.com/AlexeyAB/darknet/issues/4386
you can try to use
[Gaussian_yolo]layers without D/C/GIoU instead of[yolo]layers inCSPResNeXt50-PANet-SPP: https://github.com/AlexeyAB/darknet/issues/4147
I think it can give +2-4% for both AP and AP50
AlexeyAB
on 28 Nov 2019
having all those result in one place is great! seems like having nms threshold around .6 is kind of a slightly sweeter spot
 HagegeR
on 28 Nov 2019
HagegeR
on 28 Nov 2019
@AlexeyAB Hello,
I have tested 1. and 2. , it not always get better results.
especially for small object, using large size to fine-tune making they can not be detected when test on small size.
I know there are some tricks for improving AP on COCO.
For example, in ICCVW 2019, a team remove all training images which contain small objects in COCO dataset.
Then it improves 7.8% AP... due to COCO dataset has only few small objects.
This kind of trick is only useful for COCO, not all of cases, so I do not use the trick.
And for Gaussian YOLO... if use default learning rate schedule of YOLOv3, it gets worse results.
I will get the result which using lr=0.0001, recommended by the authors, after 1~2 weeks.
(Gaussian YOLO + GIoU gets NaN, maybe the lr schedule have to adjust for this case.)
 WongKinYiu
on 29 Nov 2019
WongKinYiu
on 29 Nov 2019
The Swish version of this doesn't work:
CUDA Error Prev: an illegal memory access was encountered
CUDA Error Prev: an illegal memory access was encountered: File exists
darknet: ./src/utils.c:295: error: Assertion `0' failed.
./train_cs.sh: line 1: 2088 Aborted (core dumped) ./darknet/darknet detector train ./obj.data ./csresnext50-panet-spp.cfg csresnext50.conv.74 -dont_show -map -thresh 0.1
 LukeAI
on 1 Dec 2019
LukeAI
on 1 Dec 2019
@LukeAI I fixed this bug: https://github.com/AlexeyAB/darknet/commit/55cfc272fbbb63c0897a81f821cebecdb2d13362
AlexeyAB
on 1 Dec 2019
what is the right number of layers to extract from the pretrained weights in order to train a new model? How do you work that out in general? I could count the number of "[" layers before the first YOLO layer? or something else?
LukeAI
on 2 Dec 2019
@LukeAI
I could count the number of "[" layers before the first YOLO layer? or something else?
cut = "[" layers before the first YOLO layer - 1
Count the number of layers which you will not change. You will change filters= in the prevous [conv] layer before [yolo] layer.
AlexeyAB
on 2 Dec 2019
@WongKinYiu
Did you try to use new [route]-params: groups= and group_id= for CSP-models to divide channels into 2 blocks?
[route]
layers=-4
groups=2
group_id=0
@AlexeyAB Hello,
Not yet, but I use new [route]-params: groups= and group_id= in CSP-Elastic-models.
You can check CSPResNet-50 vs CSPResNet-50-Elastic
| Model | #Parameter | BFLOPs | Top-1 | Top-5 | cfg |
| :---- | :--------: | :----: | :---: | :---: | :-: |
| ResNet-50 [2] | 22.73M | 9.74 | 75.8 | 92.9 | cfg |
| CSPResNet-50 | 21.57M (-5%) | 8.97 (-8%) | 76.6 (+0.8) | 93.3 (+0.4) | cfg |
| CSPResNet-50-Elastic | - | 9.36 (-4%) | 76.8 (+1.0) | 93.5 (+0.6) | cfg |
WongKinYiu
on 3 Dec 2019
Testing on my dataset - I got about +1mAP with CSPResNext50-spp-pan-scale vs. yolov3-spp-scale-swish at the same resolution - and since it's faster as well, that's a clear win.
I tried training CSPResNext50-spp-pan-scale using swish instead of leaky and found that it hurt mAP - this is the first time I've seen swish lose to leaky-relu even when transferring from pretrained weights, trained with the original leaky on coco. Presumably if I trained on coco from scratch with swish I would get the expected 1mAP boost, but who has time for that :)
Adding iou_thresh=0.213 to CSPResNext50-spp-pan-scale gave a further +1mAP - I'm trying now with mosaic and next I'll try with Gaussian and then try with large mini-batches.
LukeAI
on 6 Dec 2019
@LukeAI
Swish is not benefit on ResNeXt.
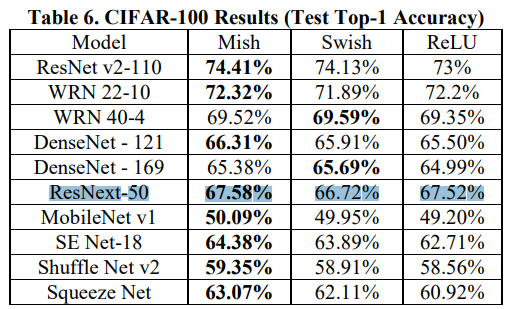
Mish paper shows the results:
WongKinYiu
on 6 Dec 2019
@WongKinYiu It seems that for ResNext-50 the best activaion is ReLU, since ~ the same accuracy as Mish, but faster and requires less memory.
Mish is noticeably better than Swish/ReLU only for DenseNet-121, SENet-18, ShuffleNetv2, and especially for SqueezeNet (+2.15 than ReLU, +0.96 than Swish)
AlexeyAB
on 6 Dec 2019
@AlexeyAB Thank you for your summary.
WongKinYiu
on 6 Dec 2019
@WongKinYiu
Did you try to use such PAN-block (with [maxpool] maxpool_depth=1 ) for MS COCO models? https://github.com/AlexeyAB/darknet/files/3805208/yolo_v3_tiny_pan3_aa_ae_mixup_scale_giou.cfg.txt
Since on some custom dataset the model Tiny Yolo V3 Pan 3 has better accuracy than Yolo V3 CSR Spp Panet https://github.com/AlexeyAB/darknet/issues/3874#issuecomment-549470673
Also it seems that iou_normalizer=0.5, uc_normalizer=0.5 is better than iou_normalizer=0.07, uc_normalizer=0.07 on some custom dataset https://github.com/AlexeyAB/darknet/issues/3874#issuecomment-561064425
AlexeyAB
on 10 Dec 2019
@AlexeyAB
Yes, for lightweight models, i apply maxpool_depth=1. it is very useful.
i do not apply it to panet-spp is becuz... i m lazy to find which layer to route.
hmm... i do not have enough gpus for test different normalizer setting.
maybe just wait my experiments finish training.
WongKinYiu
on 10 Dec 2019
@WongKinYiu
Yes, for lightweight models, i apply maxpool_depth=1. it is very useful.
Do you mean EFM(SAM) models?
AlexeyAB
on 10 Dec 2019
@AlexeyAB
yes, i find the operation of maxpool_depth=1 is same as maxout net.

WongKinYiu
on 10 Dec 2019
@WongKinYiu
Please, let me know the results of experiments with anti-aliasing and assisted-excitation when you finish tests. These are the most incomprehensible features for me in terms of improving accuracy.
AlexeyAB
on 10 Dec 2019
@AlexeyAB
now anti-aliasing model 850k epochs, totally 1600k epochs.
for assisted-excitation, could you provide two cfg files for testing? (with and w/o assisted-excitation)
it is hard to decide which layers should add assisted-excitation for me.
WongKinYiu
on 10 Dec 2019
@WongKinYiu
yolov3-tiny-prn-ae.cfg.txt only one line is changed (
conv-layer-8) compared to https://github.com/WongKinYiu/PartialResidualNetworks/blob/master/cfg/yolov3-tiny-prn.cfgcsresnext50-panet-spp-ae.cfg.txt only one line is changed (
conv-layer-38) compared to https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/cfg/csresnext50-panet-spp.cfg
Did you train csresnext50-panet-spp.cfg with width=416 height=416 random=1 and then test it with width=512 height=512 ?
AlexeyAB
on 10 Dec 2019
@AlexeyAB
yes, i train with size 416 and test on other sizes.
so if u want to get better results, just train with target size.
WongKinYiu
on 10 Dec 2019
why csresnext50-panet-spp is slower than yolov3-spp ? #4558
 syjeon121
on 20 Dec 2019
syjeon121
on 20 Dec 2019
@syjeon121 @WongKinYiu
On Windows 7 x64, MSVS 2015, OpenCV 4.1.0, CUDA 10.0, cuDNN 7.4.2, GPU Driver 417.35
Compiled with GPU, CUDNN, OPENCV
FPS- measured using the command:./darknet detector demo cfg/coco.data ...ms- measured using the command:./darknet detector test cfg/coco.data ... < train.txtfor 30 images after heating (another 30 images)
GPU GeForce RTX 2070 (Tensor Cores)
CUDNN_HALF=1 (Mixed-precision is forced for Tensor Cores)
512x512:
yolov3-spp- 41 FPS - (23.1msnetwork_predict()only)csresnext50-panet-spp- 19 FPS - (51.5msnetwork_predict()only)
608x608:
yolov3-spp- 34 FPS - (27.3msnetwork_predict()only)csresnext50-panet-spp- 19 FPS (48.1msnetwork_predict()only)
CUDNN_HALF=0
512x512:
yolov3-spp- 37 FPS - (26.5msnetwork_predict()only)csresnext50-panet-spp- 30 FPS - (31.6msnetwork_predict()only)
608x608:
yolov3-spp- 25 FPS - (40.8msnetwork_predict()only)csresnext50-panet-spp- 25 FPS (40.4msnetwork_predict()only)
AlexeyAB
on 20 Dec 2019
@syjeon121 @WongKinYiu
Differences from previous post:
Added 2 fixes: https://github.com/AlexeyAB/darknet/commit/dc7277f152cc1ef84b408872b3d774730bdca581 and https://github.com/AlexeyAB/darknet/commit/e66d3b1bdbe9cefc2dd4ede5e341afe5fa6902b4
Used
-dont_showflag for./darknet detector demo ... -dont_show
FPS- measured using the command:./darknet detector demo cfg/coco.data ... -dont_showms- measured using the command:./darknet detector test cfg/coco.data ... < train.txtfor 30 images after heating (another 30 images)
CLICK ME - before fixes
CUDNN_HALF=1 (Mixed-precision is forced for Tensor Cores (if groups==1))
512x512:
yolov3-spp- 44 FPS - (23.1msnetwork_predict()only)csresnext50-panet-spp- 32 FPS - (31.0msnetwork_predict()only)
608x608:
yolov3-spp- 36 FPS - (27.3msnetwork_predict()only)csresnext50-panet-spp- 31 FPS (31.8msnetwork_predict()only)
CUDNN_HALF=1 (Mixed-precision is forced for Tensor Cores (if groups==1))
Disabled - CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION
//CHECK_CUDNN(cudnnSetConvolutionMathType(l->convDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
512x512:
yolov3-spp- 46 FPS - (22.1msnetwork_predict()only)csresnext50-panet-spp- 32 FPS - (31.0msnetwork_predict()only)
608x608:
yolov3-spp- 38 FPS - (26.2msnetwork_predict()only)csresnext50-panet-spp- 32 FPS (30.5msnetwork_predict()only)
CLICK ME - before fixes
CUDNN_HALF=0
512x512:
yolov3-spp- 39 FPS - (26.5msnetwork_predict()only)csresnext50-panet-spp- 32 FPS - (32.4msnetwork_predict()only)
608x608:
yolov3-spp- 25 FPS - (40.8msnetwork_predict()only)csresnext50-panet-spp- 26 FPS (39.6msnetwork_predict()only)
Disabled - CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION
//CHECK_CUDNN(cudnnSetConvolutionMathType(l->convDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
CUDNN_HALF=0
512x512:
yolov3-spp- 41 FPS - (24.9msnetwork_predict()only)csresnext50-panet-spp- 34 FPS - (28.8msnetwork_predict()only)
608x608:
yolov3-spp- 26 FPS - (39.2msnetwork_predict()only)csresnext50-panet-spp- 29 FPS (38.2msnetwork_predict()only)
AlexeyAB
on 20 Dec 2019
@AlexeyAB
Hmm... It seems CUDNN_HALF=1 does not support group convolution very well.
For csresnext50-panet-spp, 512x512 gets almost same FPS as 608x608 is also strange.
WongKinYiu
on 20 Dec 2019
@WongKinYiu
CHECK_CUDNN(cudnnSetConvolutionMathType(l->convDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION)); is the reason.
I updated the table: https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-567919052
But for 512x512 the yolov3-spp is still faster than csresnext50-panet-spp I will still look for reasons
AlexeyAB
on 20 Dec 2019
@AlexeyAB Thanks,
So currently the csresnext50-panet-spp run faster than yolov3-spp when the input resolution is big.
I will also try mixed precision on pytorch when i get free gpus (expect on 12/28).
WongKinYiu
on 20 Dec 2019
@WongKinYiu So for Tensor Cores or for network resolution lower than 608x608 may be CSPDarkNet-53 is better than CSPResNeXt-50 on modern GPU
AlexeyAB
on 20 Dec 2019
@AlexeyAB
I have not tested on RTX gpus before, I can get a free RTX 2080ti around 12/28, I will update my testing results here.
And in my test, 512x512 gets 9 FPS faster than 608x608 on 1080ti (44 vs 35).
However, in your test, it only has 5 FPS difference on 2070 (34 vs 29).
Maybe more cuda cores can benefit group convolution?
CUDNN_HALF=1(Mixed-precision is forced for Tensor Cores (if groups==1))
Disabled - CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION
CHECK_CUDNN(cudnnSetConvolutionMathType(l->convDesc,CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
512x512: csresnext50-panet-spp - 32 FPS - (31.0ms network_predict() only)
608x608: csresnext50-panet-spp - 32 FPS (30.5ms network_predict() only)
But 608x608 gets faster inference speed than 512x512 is really strange.
WongKinYiu
on 20 Dec 2019
@WongKinYiu There are also 2x more blocks/warps/thread per SM on Pascal (1080ti) than on RTX (Turing). This can better hide latency and can speed up operations with a lower Compute/Memory_access ratio.
But 608x608 gets faster inference speed than 512x512 is really strange.
This is not strange, so this is the value of the error of my measurements :) +-2%
AlexeyAB
on 20 Dec 2019
@AlexeyAB Thanks for the explanation.
I will borrow a volta gpu to compare the inference speed on pascal, volta, and turing architectures.
WongKinYiu
on 20 Dec 2019
@AlexeyAB Hi,
Why didn't use GIoU instead of MSE?
they had comparison of BTW MSE and GIoU and GioU is better.
 zpmmehrdad
on 21 Dec 2019
zpmmehrdad
on 21 Dec 2019
@zpmmehrdad
There are both weights-files for MSE and GIoU: https://github.com/WongKinYiu/CrossStagePartialNetworks#gpu-real-time-models
GIoU is better for AP75 and AP50...95, but worse for AP50
AlexeyAB
on 21 Dec 2019
@AlexeyAB
The both of CFGs are the same. Could you share the GioU cfg? And is this command for pretrained true?
darknet partial csresnext50-panet-spp.cfg csresnext50-panet-spp_final.weights csresnext50.conv.80 80
zpmmehrdad
on 21 Dec 2019
@zpmmehrdad
Yes.
Add lines to each [yolo] layer:
iou_normalizer=0.5
iou_loss=giou
@zpmmehrdad
Thanks for your reminder.
I corrected the link of the cfg of csresnext50-panet-spp-giou: https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/cfg/csresnext50-panet-spp-giou.cfg
WongKinYiu
on 21 Dec 2019
@WongKinYiu Hi
I'm using csresnext50-panet-spp-giou and after about 2k or 3k iteration the avg is -nan but without it works fine.
zpmmehrdad
on 24 Dec 2019
@zpmmehrdad hello,
I'm using csresnext50-panet-spp-giou and after about 2k or 3k iteration the avg is -nan but without it works fine
do u mean without giou?
could u provide ur training command?
WongKinYiu
on 24 Dec 2019
@WongKinYiu Hi,
darknet.exe detector train obj.safaC csresnext50-panet_spp.cfg -dont_show -map
zpmmehrdad
on 24 Dec 2019
@zpmmehrdad hello,
using csresnext50.conv.80 or csresnext50-panet-spp.conv.113 as pre-trained model is recommended.
or u need more iterations for burn-in (i have not tested it).
WongKinYiu
on 24 Dec 2019
@WongKinYiu Hi,
I stopped the training at 8k because I was getting the avg nan, Should I continue the training with avg nan? I trained a model with mse before and works fine. Can I use mse weights as a pre-trained? What command is right for make a pre-trained? Is this command true?
darknet partial csresnext50-panet-spp.cfg csresnext50-panet-spp_final.weights csresnext50.conv.80 80
Thanks.
zpmmehrdad
on 24 Dec 2019
@zpmmehrdad
no, plz do not continue the training with avg nan.
for getting pretrained weights, u can use:
darknet partial csresnext50.cfg csresnext50.weights csresnext50.conv.80 80(imagenet pretrain)darknet partial csresnext50-panet-spp.cfg csresnext50-panet-spp_final.weights csresnext50.conv.80 80(coco pretrain, backbone)darknet partial csresnext50-panet-spp.cfg csresnext50-panet-spp_final.weights csresnext50.conv.113 113(coco pretrain, fpn included)
WongKinYiu
on 24 Dec 2019
@WongKinYiu
What command should I use for my own data set?
Is this command for custom data set?
darknet partial my-csresnext50-panet-spp.cfg my-csresnext50-panet-spp.weights my-csresnext50.conv.80 80
zpmmehrdad
on 24 Dec 2019
@zpmmehrdad Download this pre-trained weights file csresnext50-panet-spp.conv.112: https://drive.google.com/file/d/16yMYCLQTY_oDlCIZPfn_sab6KD3zgzGq/view?usp=sharing
AlexeyAB
on 24 Dec 2019
@AlexeyAB Thanks
zpmmehrdad
on 24 Dec 2019
@AlexeyAB @WongKinYiu Hi,
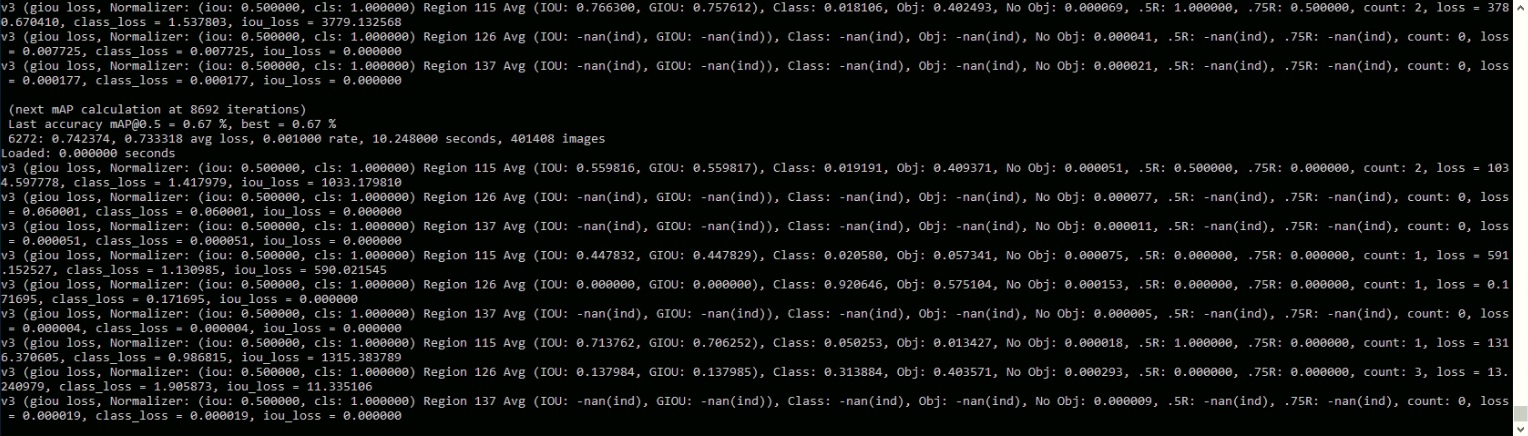
I used csresnext50-panet-spp-giou and pre-trained model that @AlexeyAB shared but after ~6k iterations the mAP is less than 1%. What should I do?
darknet.exe detector train obj.obj csresnext50-panet_spp-giou.cfg csresnext50-panet-spp.conv.112 -dont_show -map
zpmmehrdad
on 25 Dec 2019
@zpmmehrdad
from ur picture, it seems the objects in your custom dataset are very small.
u should recalculate the anchor or even add more predicted scales.
(u can take a look https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3_5l.cfg to modify cfg for more predicted scales)
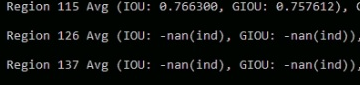
this figure shows there are no objects matching to anchors 3,4,5,6,7,8 in the ground truth.
WongKinYiu
on 25 Dec 2019
@WongKinYiu Hi,
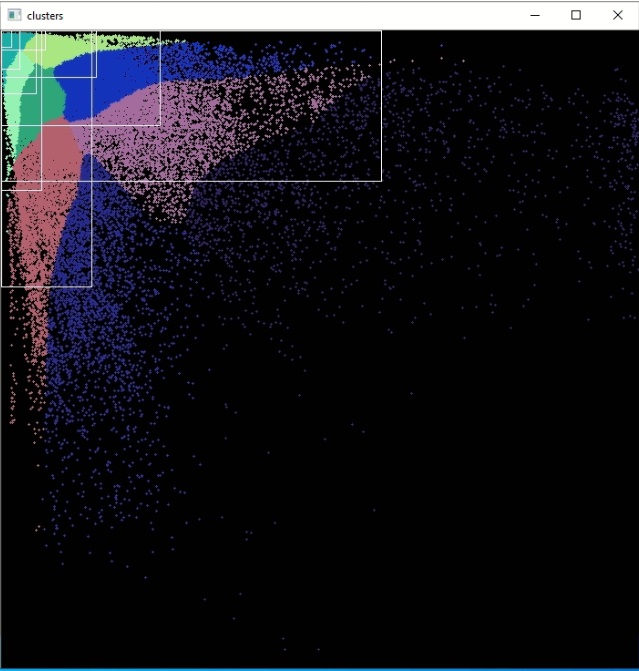
Yes, some objects are small. So, I can't use csresnext50-panet_spp-giou.cfg. Will I fix my problem if I calculate the anchor? I want to use this model
Could you please help me?
I calculated the anchor:
Thanks is advance
zpmmehrdad
on 25 Dec 2019
yes, u can fix the problem by modify the anchors.
but if ur objects r smaller than 8x8, u need increase image size or add predicted scale.
WongKinYiu
on 25 Dec 2019
@AlexeyAB Hi,
I trained a model ~200k iteration with about 200 classes and I want to train a new model with the same cfg but now I have 210 classes and added new images to old images and I'm gonna train a new model with the previous weights (fine tuning). Are these commands true? I have 2 GPUs.
- darknet partial panet_spp.cfg panet_spp_best.weights panet_spp.conv.112 112
- darknet detector train obj.obj panet_spp.cfg panet_spp.conv.112 -dont_show -map
- after 1K iteration I stop the training and use below command:
- darknet detector train obj.obj panet_spp.cfg panet_spp_1000.weights -dont_show -map -gpus 0,1
Thanks
zpmmehrdad
on 25 Dec 2019
@zpmmehrdad Yes, you are doing everything right
AlexeyAB
on 25 Dec 2019
@AlexeyAB
i do some optimization of hyper-parameter.
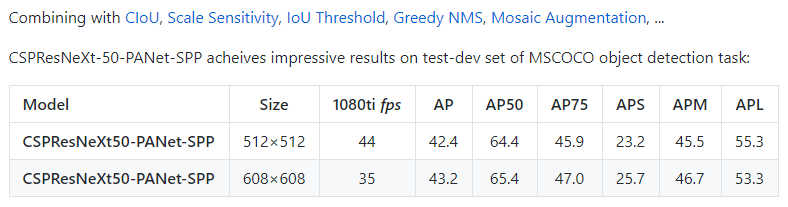
the new results are as follows:
| model | size | AP | AP50 | AP75 |
| :-- | :-: | :-: | :-: | :-: |
| CSPResNeXt50-PANet-SPP | 512x512 | 42.4 | 64.4 | 45.9 |
| CSPResNeXt50-PANet-SPP | 608x608 | 43.2 | 65.4 | 47.0 |
WongKinYiu
on 31 Dec 2019
@WongKinYiu Nice!
Will you share cfg file?
Did you use default CSPResNeXt50 or with (MISH and BoF (Label-smooth, mosaic, ...))?
It seems that it can achieve even more accuracy with ASFF+BiFPN+RFB+DropBlock+MISH https://github.com/AlexeyAB/darknet/issues/4382 , and if it is trained based on Classifier with BoF (Label-smooth, mosaic), and can be faster if will be used CSPResNeXt-50-gpu https://github.com/AlexeyAB/darknet/files/4007487/csresnext50gpu.cfg.txt as backbone with 512x512
Happy New Year!
AlexeyAB
on 31 Dec 2019
 WongKinYiu
on 31 Dec 2019
WongKinYiu
on 31 Dec 2019
@WongKinYiu Did you try to train Detector csresnext50-panet-spp-original-optimal.cfg.txt with lable_smooth_eps=0.1 ?
AlexeyAB
on 1 Jan 2020
@WongKinYiu Also how many FPS can you get with https://github.com/AlexeyAB/darknet/files/4007487/csresnext50gpu.cfg.txt
on GeForce 1080 Ti
if you set in cfg-file
width=256 height=256width=512 height=512width=608 height=608
by using this command:
./darknet classifier demo cfg/imagenet1k_c.data models/csresnext50gpu.cfg csresnext50.weights test.mp4 -benchmark
AlexeyAB
on 1 Jan 2020
@AlexeyAB hello,
not yet, i m training csresnext50-panet-spp-original-optimal with ASFF now.
i have no free 1080ti currently, i will using titan x pascal for testing inference time of csresnext50gpu in few days.
WongKinYiu
on 2 Jan 2020
fyi, nice job
| Model | [email protected] |[email protected]| precision (th=0.85)| recall(th=0.85)|precision (th=0.7)| recall(th=0.7)|
| --- | --- | --- | --- | ---| ---|---|
|darknet53,spp,mse|92.01%|60.49%|0.97|0.60|0.95|0.72|
|darknet53,spp,giou|91.79%|63.09%|0.96|0.57|0.95|0.71|
|csresnext50-panet,spp,giou| 92.80%|64.16%|0.97 |0.51 | 0.96| 0.67|
|csdarknet53-panet,spp,giou|91.13%|61.94%|0.96|0.53|0.95|0.67|
 Kyuuki93
on 2 Jan 2020
Kyuuki93
on 2 Jan 2020
@Kyuuki93 Thanks, i am trying to combine your asff and rfb into cspresnext50-panet-spp.
WongKinYiu
on 2 Jan 2020
@WongKinYiu Do you train cspresnext50-panet-spp with ASFF+RFB or with ASFF+RFB+DROPBLOCK?
AlexeyAB
on 2 Jan 2020
@AlexeyAB
I am training cspresnext50-panet-spp+ASFF.
I just fixed some bugs of my implementation when integrating ASFF into cspresnext50-panet-spp today.
After make sure everything is ok, i will train cspresnext50-panet-spp+ASFF+RFB.
The training of DROPBLOCK is too slow, so the training for cspresnext50-panet-spp+ASFF+RFB+DROPBLOCK is not in my schedule currently.
WongKinYiu
on 2 Jan 2020
@WongKinYiu After testing the droplock, I will make its accelerated implementation
AlexeyAB
on 2 Jan 2020
@AlexeyAB Thanks,
i m training classifier with dropblock, it takes more than twice time than training model without dropblock.
so it may need one more month to get the result.
by the way, local_avgpool seems not perform normally, the loss is very high when compare with the models which use maxpool (need one more week to get a result).
WongKinYiu
on 2 Jan 2020
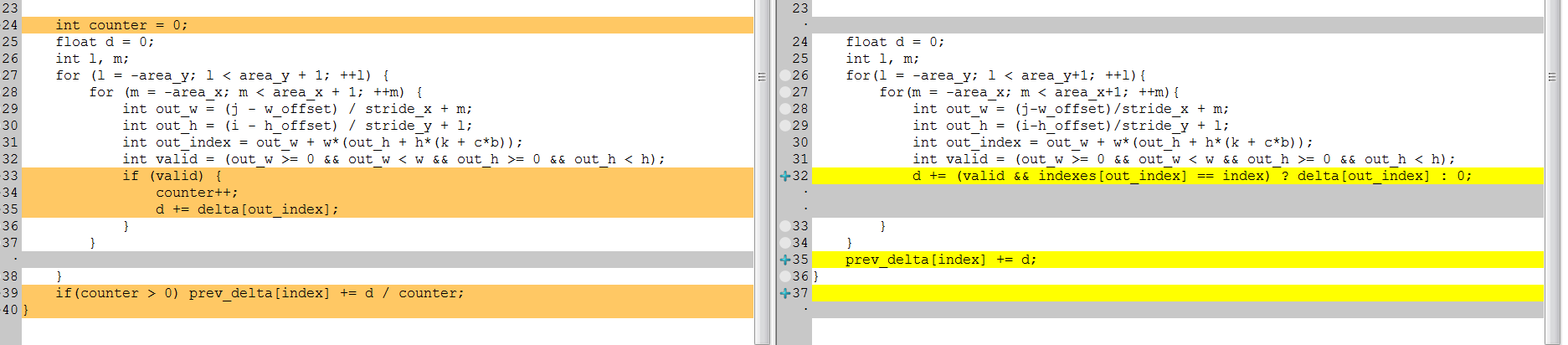
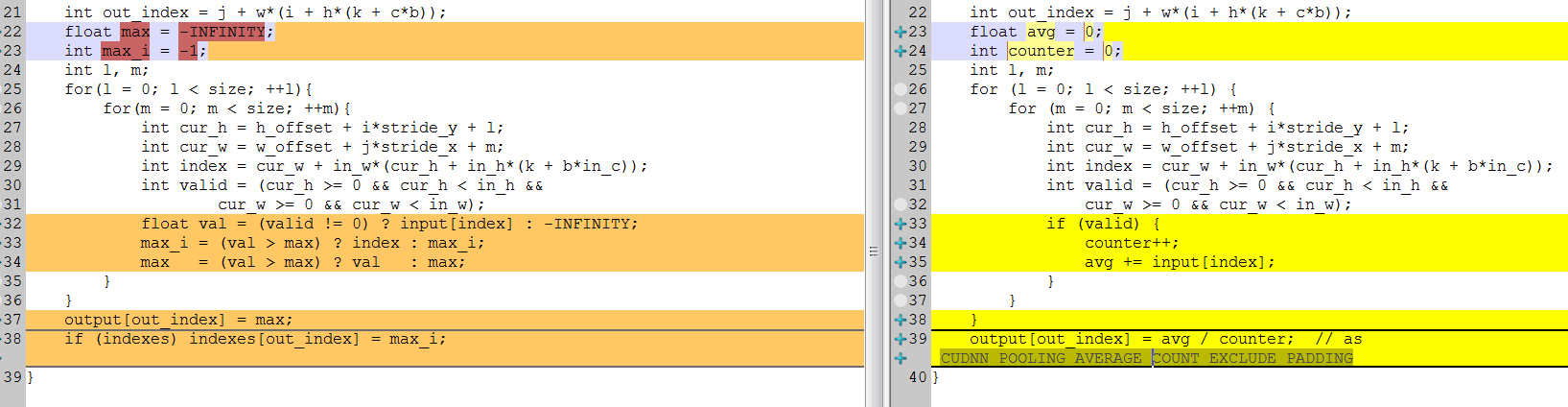
@WongKinYiu Do you train cspresnext50-Elastic-model with local_avg_pool?
There are 2 types of locav_avg_pool CUDNN_POOLING_AVERAGE_COUNT_EXCLUDE_PADDING and CUDNN_POOLING_AVERAGE_COUNT_INCLUDE_PADDING
So also you can try to put counter++; out of if() {} in these 2 places:
- https://github.com/AlexeyAB/darknet/blob/489ea7fdce771144c3ef39d870926c71a1587af5/src/maxpool_layer_kernels.cu#L262-L267
- https://github.com/AlexeyAB/darknet/blob/489ea7fdce771144c3ef39d870926c71a1587af5/src/maxpool_layer_kernels.cu#L305-L309
Tiny_3l_resize model uses local_avg_pool, and it seems that it works more or less normally: https://github.com/AlexeyAB/darknet/issues/4495#issuecomment-569824100
With normal loss: https://github.com/AlexeyAB/darknet/issues/4495#issuecomment-569046291
Diff of local_avg_pool and max_pool
forward
backward
AlexeyAB
on 2 Jan 2020
@WongKinYiu Did you have csdarknet53-panet-spp.cfg results on MS COCO which cfg you provide here , I got much worse results in this network which you can see it on previous table
I used yolov3-spp.conv.88 as pre-trained weights, or should I use your pre-trained weights on ImageNet?
Kyuuki93
on 3 Jan 2020
@Kyuuki93
Did you have csdarknet53-panet-spp.cfg results on MS COCO which cfg you provide here , I got much worse results in this network which you can see it on previous table
Do you try to train https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/in%20progress/csdarknet53-panet-spp.cfg on MS COCO?
You should use pre-trained weights file csdarknet53.conv.105 that you get by using command
./darknet partial models/csdarknet53g.cfg models/csdarknet53.weights csdarknet53.conv.105 105
csdarknet53.weights you should get from ImageNet weights file https://drive.google.com/open?id=1dZJIxngmFpQJvsa6y7XADfSxkXCjJTzp
csdarknet53g.cfg and csdarknet53.weights are there: https://github.com/WongKinYiu/CrossStagePartialNetworks#imagenet
AlexeyAB
on 3 Jan 2020
@Kyuuki93 hello,
yes you should use pre-trained weights of csdarknet53.
i have no coco pretrained model for csdarknet53-panet-spp, so u may not gets better performance when training only few epochs.
WongKinYiu
on 3 Jan 2020
@AlexeyAB
Do you try to train https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/in%20progress/csdarknet53-panet-spp.cfg on MS COCO?
No, just my custom data used before
You should use pre-trained weights file
csdarknet53.conv.105that you get by using command
Ok, I will retrain it
Kyuuki93
on 3 Jan 2020
@WongKinYiu Actually I trained this network about 60 epochs just same as other network. I will retrain it with csdarknet53.conv.105 and update later
Kyuuki93
on 3 Jan 2020
@AlexeyAB @WongKinYiu I updated table here https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570111795
csdarknet53-panet with Imagenet pre-trained which is (new) line in table was still -4%[email protected] than csresnext50-panet with MS COCO pre-trained
Could you provide csdarknet53-panet weights on MS COCO If you have free cards, also I will try to download COCO dataset but it's very slow
Kyuuki93
on 3 Jan 2020
@Kyuuki93
The model is still training.
Sorry for that I have only few gpus, so each model need 3~5 weeks for training.
WongKinYiu
on 3 Jan 2020
@AlexeyAB https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570087600
my cuda version is V9.0.252 and it was built on 11.19.2017, so maybe the cudnn do not support group convolution well.
| Model | GPU | 256×256 | 512×512 | 608×608 |
| :-- | :-: | :-: | :-: | :-: |
| CSPResNeXt50-GPU | Titan X Pascal | 126 | 70 | 57 |
| CSPResNeXt50 | Titan X Pascal | 103 | 65 | 55 |
| CSPResNeXt50-fast | Titan X Pascal | 117 | 70 | 57 |
| CSPDarknet19 | Titan X Pascal | 242 | 144 | 118 |
| CSPDarknet53 | Titan X Pascal | 132 | 71 | 56 |
| CSPDarknet53-G | Titan X Pascal | 123 | 69 | 56 |
| CSPDarknet53-GHR | Titan X Pascal | 126 | 76 | 61 |
| Spinenet49 | Titan X Pascal | 73 | 52 | 42 |
WongKinYiu
on 3 Jan 2020
@WongKinYiu Thanks!
Also test inference time of these 3 models for 256/512/608:
AlexeyAB
on 3 Jan 2020
@AlexeyAB New results, all models are tested using latest darknet(AlexeyAB).
@Kyuuki93 Pretrained weights.
| Model | Size | GPU | FPS | BFLOPs | AP | AP50 | AP75 | weight |
| :-- | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
| YOLOv3-SPP | 512×512 | TitanX Pascal | 51.5 | 100.3 | 35.7 | 60.2 | 37.5 | weight |
| CSPResNeXt50-PANet-SPP | 512×512 | TitanX Pascal | 41.3 | 71.3 | 38.0 | 60.0 | 40.8 | weight |
| CSPDarkNet53-PANet-SPP | 512×512 | TitanX Pascal | 50.5 | 91.1 | 38.7 | 61.3 | 41.7 | weight |
| CSPResNet50-PANet-SPP | 512×512 | TitanX Pascal | 54.6 | 74.7 | 38.0 | 60.5 | 40.7 | weight |
WongKinYiu
on 4 Jan 2020
@WongKinYiu Thanks!
New results, all models are tested using latest darknet(AlexeyAB).
Did you test it by using https://github.com/AlexeyAB/darknet but trained by using your own code?
Did you test it with 512x512 network resolution?
So the best model is https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/in%20progress/csdarknet53-panet-spp.cfg with this weights-file https://drive.google.com/open?id=1ezwtlTmQ1woHGZNtmKUdmyx-jqFElafA
So try to test FPS for these classification models - may be we can try to use one of these models as backbone for Detector:
- https://github.com/AlexeyAB/darknet/files/4007387/csdarknet53g.cfg.txt
- https://github.com/AlexeyAB/darknet/files/4007433/csdarknet53ghr.cfg.txt
- and these: https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570675162
AlexeyAB
on 4 Jan 2020
@AlexeyAB
- both of training and testing are using https://github.com/AlexeyAB/darknet.
- yes, they are tested with 512×512.
- yes, CSPDarknet53-PANet-SPP gets best FPS/MAP trade-off.
- OK, I will test the FPS of other models at night and update the table https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570585515.
WongKinYiu
on 4 Jan 2020
@WongKinYiu
both of training and testing are using https://github.com/AlexeyAB/darknet
Do you still get memory overflow issue with this repo, and do you use loop for restarting training?
AlexeyAB
on 4 Jan 2020
@AlexeyAB
yes, i still get memory overflow issue, and i stop and restart training by myself when memory is not enough.
i have used loop for restarting training every epochs, but it was too slow since it will resize the network every epochs.
WongKinYiu
on 4 Jan 2020
@AlexeyAB new results, ciou gets better AP and giou gets better AP50.
| Model | Size | Loss | AP | AP50 | AP75 | APS | APM | APL |
| :---- | :--: | :--: | :--: | :--: | :--: | :-: | :-: | :-: |
| CSPResNeXt50-PANet-SPP | 512×512 | MSE | 38.0 | 60.0 | 40.8 | 19.7 | 41.4 | 49.9 |
| CSPResNeXt50-PANet-SPP | 512×512 | GIoU | 39.4 | 59.4 | 42.5 | 20.4 | 42.6 | 51.4 |
| CSPResNeXt50-PANet-SPP | 512×512 | DIoU | 39.1 | 58.8 | 42.1 | 20.1 | 42.4 | 50.7 |
| CSPResNeXt50-PANet-SPP | 512×512 | CIoU | 39.6 | 59.2 | 42.6 | 20.5 | 42.9 | 51.6 |
WongKinYiu
on 4 Jan 2020
@WongKinYiu
So CIoU really improves AP (+0.2%) better than GIoU.
I added fast-random-function, so now DropBlock doesn't slowdown training, at least for csdarknet19-fast.cfg model on GPU RTX 2070 and Windows.
yes, i still get memory overflow issue, and i stop and restart training by myself when memory is not enough.
i have used loop for restarting training every epochs, but it was too slow since it will resize the network every epochs.
Do you mean you used loop for restarting training every 1 iterations?
The most difficult thing is that I have never been able to reproduce this problem.
It is very likely that the Bug is in the interaction of: OpenCV with GCC or Pthread.
So that would help me a lot if you could list the versions (OpenCV, GCC, Pthread) with which you encountered an error and with which did not.
AlexeyAB
on 4 Jan 2020
@AlexeyAB
maybe yes, they almost get same results
great, i ll move my model to use latest repo.
yes.
well, even though i reinstall whole system by same steps.
some machines have the problem, and others do not have the problem.
in above case, the version of opencv, gcc... are same.
so i also do not have idea about how to solve the problem.
WongKinYiu
on 4 Jan 2020
@WongKinYiu
in above case, the version of opencv, gcc... are same.
Are there the same OS, CPU, GPU, CUDA and cuDNN?
Can you check that you get identical output by using these commands on all these computers?
getconf GNU_LIBC_VERSION
getconf GNU_LIBPTHREAD_VERSION
gcc --version
@AlexeyAB
CPU are different, almost all of machines which do not have the problem use Xeon cpu.
WongKinYiu
on 4 Jan 2020
@WongKinYiu So may be some OpenCV-functions which use SIMD (SSE/AVX/ ...) and which have different implementations for different CPUs have a bug.
Are all your CPUs - Intel?
What command do you use for installing OpenCV?
AlexeyAB
on 4 Jan 2020
@AlexeyAB
yes, all of cpus are intel cpu.
sudo apt install libopencv-dev
by the way, https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570585515 updated.
WongKinYiu
on 4 Jan 2020
@AlexeyAB Hi,
What pre-trained should we use for csresnext50-panet-spp-original-optimal?
zpmmehrdad
on 5 Jan 2020
@zpmmehrdad
i use cspresnext50 imagenet pretrained model.
darknet.exe partial csresnext50.cfg csresnext50.weights csresnext50.conv.80 80
WongKinYiu
on 5 Jan 2020
@AlexeyAB @WongKinYiu
Updated here https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-570111795, all used MS COCO pre-trained weights
Kyuuki93
on 7 Jan 2020
@AlexeyAB Hi,
I'm using csresnext50-panet-spp-original-optimal.cfg.txt model and I have downloaded csresnext50-panet-spp-original-optimal_final.weights and get a pre-trained with this command
darknet.exe partial csresnext50.cfg csresnext50.weights csresnext50.conv.80 80. after 2k iterations the avg becomes nan. I have 226 classes and I've calculated the anchor. Does pre-trained have a problem?
zpmmehrdad
on 8 Jan 2020
@zpmmehrdad May be you something doing wrong. Try to use default anchors. And use this pre-trained weights: https://drive.google.com/file/d/16yMYCLQTY_oDlCIZPfn_sab6KD3zgzGq/view?usp=sharing
AlexeyAB
on 8 Jan 2020
@AlexeyAB I use two GPUs for training and now I'm training with 1 GPU and works fine. Can I stop the training after 10k and continue with two GPUs.
zpmmehrdad
on 8 Jan 2020
@zpmmehrdad Yes.
AlexeyAB
on 8 Jan 2020
@Kyuuki93 What pre-trained weights file did you use for training csresnext50-panet,spp,giou ?
is it
csresnext50.conv.80from Classifier model https://drive.google.com/open?id=1IxKu5lAYCo4UpzAl5pOBIDAvC843vjn1or is it
csresnext50-panet-spp.conv.112from Detector-model https://drive.google.com/file/d/16yMYCLQTY_oDlCIZPfn_sab6KD3zgzGq/view?usp=sharing
Did you use Classifier pre-trained weights files for all 4 cases in your table?
AlexeyAB
on 8 Jan 2020
@AlexeyAB is csresnext50-panet-spp.conv.112 from Detector-model, all 4 cases use MS COCO pre-trained weights.
I'm running another comparison on a bigger dataset which contains many small objects but still one-class, it's will be more illustrative, will report back when it done
Kyuuki93
on 9 Jan 2020
@Kyuuki93 If you want fair comparison of models rather than get higher AP, then you should train all models with the same type of pre-trained weights:
- or train all models with pre-trained Classifier-weights
- or train all models with pre-trained Detector-weights
AlexeyAB
on 9 Jan 2020
If you want fair comparison of models rather than get higher AP, then you should train all models with the same type of pre-trained weights:
- or train all models with pre-trained Classifier-weights
- or train all models with pre-trained Detector-weights
Yes, all cases were used pre-trained detector-weights
Kyuuki93
on 10 Jan 2020
@WongKinYiu Hi, I'am working with running well trained csresnext50-panet-spp network(from this repo) on pytorch(only for inference), I have noticed your discuss here https://github.com/ultralytics/yolov3/issues/698
I have added groups to nn.Conv2D and zeropad mentioned here https://github.com/ultralytics/yolov3/issues/698#issuecomment-563521134, now inference can be done but nothing could be detected.
I checked mean value of each layers featuremap, this value of yolov3-spp was between [0,1] but in csresnext50-panet-spp was between [-10000,100000], and after yolo-layer will get inf.
I think there could be 2 reasons
groupsin darknet and pytorch was not exactly same- the save order of
groupsweights in darknet and pytorch was not same
Do you have any progress in this issue?
Kyuuki93
on 10 Jan 2020
@Kyuuki93
groups in the darknet are the same as in nVidia cuDNN https://docs.nvidia.com/deeplearning/sdk/cudnn-developer-guide/index.html#grouped-convolutions
order of saving convolutional weights (regardless there is groups or no) https://github.com/AlexeyAB/darknet/blob/2116cba1ed123b38b432d7d8b9a2c235372fd553/src/parser.c#L1552-L1558
AlexeyAB
on 10 Jan 2020
@AlexeyAB If I wanna to save every layer's feature map when inference on darknet, what should I do?
csresnet convert to pytorch can get same result, but csresnext can not, it seems something not match in groups op
Kyuuki93
on 11 Jan 2020
@AlexeyAB Hi,
I'm using csresnext50-panet-spp-original-optimal.cfg.txt model and I have downloaded csresnext50-panet-spp-original-optimal_final.weights and get a pre-trained with this command
darknet.exe partial csresnext50.cfg csresnext50.weights csresnext50.conv.80 80. after 2k iterations the avg becomes nan. I have 226 classes and I've calculated the anchor. Does pre-trained have a problem?
I'm also facing the same issue. My loss starts with a very high value (approx 1000) and becomes nan after a few iterations. Did you manage to solve the issue? I'm training on 2080Ti for 6 classes
 Sayyam-Jain
on 12 Jan 2020
Sayyam-Jain
on 12 Jan 2020
@Sayyam-Jain Hello,
try to follow https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-572015672.
and could you show the screen shot when training?
WongKinYiu
on 12 Jan 2020
@Sayyam-Jain Hello,
try to follow #4406 (comment).
and could you show the screen shot when training?
- After a few minutes of starting the training
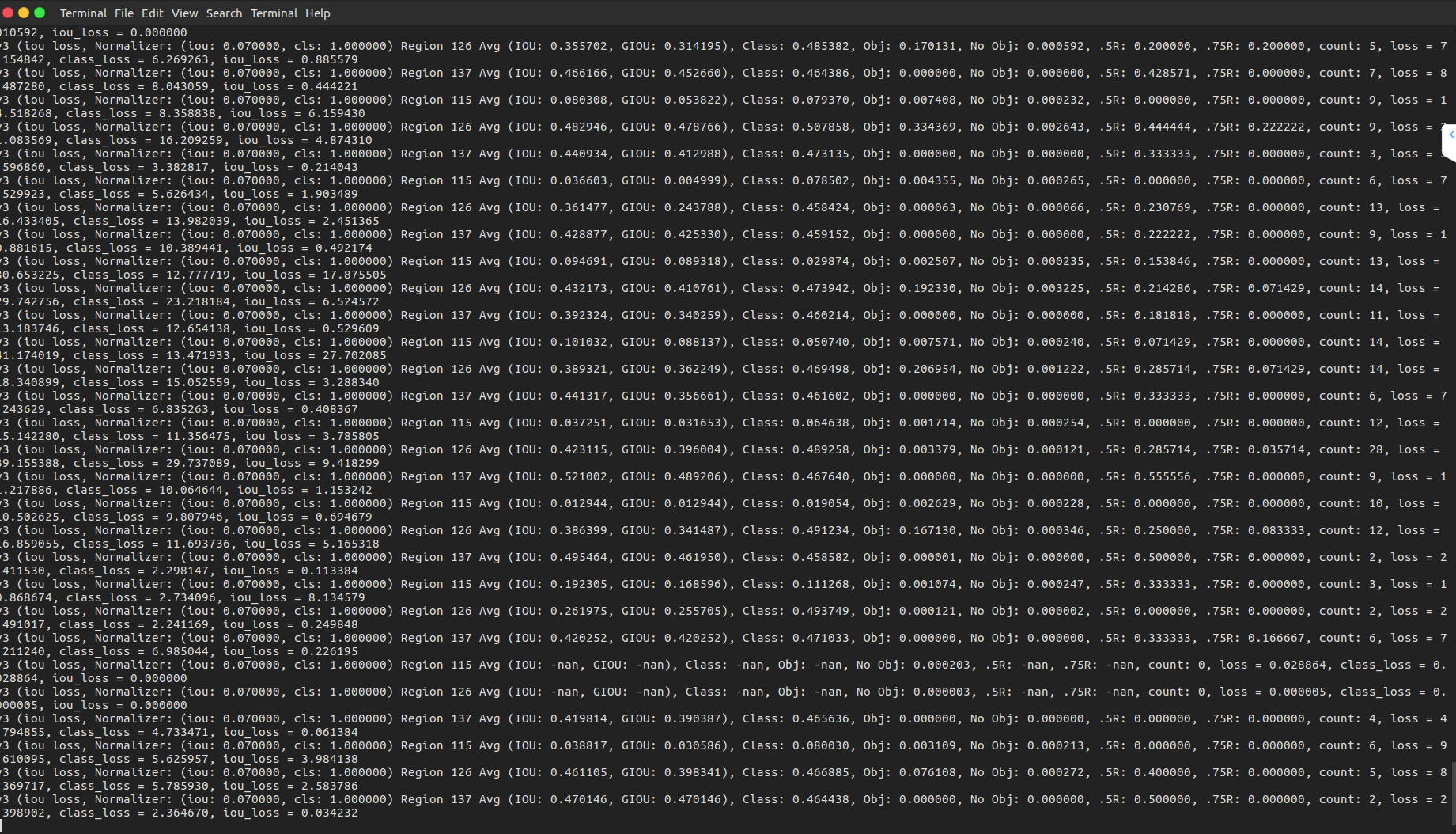
After few iterations:
Sayyam-Jain
on 12 Jan 2020
@Sayyam-Jain
it seems u directly use csresnext50-panet-spp-original-optimal_final.weights to train.
while your number of classes is different from mscoco, you will load unexpected weight.
please follow https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects.
for training on multiple gpus, please follow https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-572015672.
and set learning rate to 0.00261 is optimized for mscoco, you can set it to yolov3 default value 0.001.
WongKinYiu
on 12 Jan 2020
Hi,
I'm trying to train this CSPNet on my custom dataset. I'm slightly confused as to how to achieve that.
What is best pretrained weight file between csresnext50-panet-spp.conv.112, csdarknet53.weights, csdarknet53-panet and csdarknet53-panet-spp?
csresnext50-panet-spp.conv.112 has 115 layers (i.e. 116 "[" characters) before the first yolo layer. Is there a particular reason why it is called ".112" and not ".115"?
How many layers should I keep as initial weights for training? In this thread you suggest command lines like
./darknet partial csresnext50-panet-spp.conv.112 csresnext50-panet-spp.conv.80 80. Where does this "80" come from? Why only 80 layers and not more? Anything to do with the fact that not all layers have weights (upsample, route etc)?
 mmartin56
on 13 Jan 2020
mmartin56
on 13 Jan 2020
the backbone of csresnext50-panet-spp.conv.112 is CSPResNeXt50, and the backbone of csdarknet53.weights, csdarknet53-panet and csdarknet53-panet-spp is CSPDarkNet53.
you should choose the pre-trained model which match the backbone of your detection model.you can see there is a [route] layer just after a [yolo] layer and its parameter
fromis-4(skip [yolo] layer and additional 3 layers). those 3 layers are feature extractor of corresponding [yolo] layer, in this case, we will choose115-3which is equals to112.choose
80is because the backbone CSPResNeXt50 has 80 layers, you can take a lookcfgfiles of ImageNet pre-trained models. for the case of Darknet53, it contains74layers in the backbone, etc.
WongKinYiu
on 14 Jan 2020
That helps a lot, thank you. Do you usually recommend using CSPResNeXt50 or CSPDarkNet53? From this thread I gather that CSPResNeXt50 is faster than CSPDarkNet53 and at least as good, so it is a better choice?
mmartin56
on 14 Jan 2020
@mmartin56
CSPDarknet53-PANet-SPP performs better than CSPResNeXt50-PANet-SPP on both AP and FPS when input size is not large. https://github.com/WongKinYiu/CrossStagePartialNetworks#gpu-real-time-models
CSPResNeXt50-PANet-SPP will has better trade-off than CSPDarknet53-PANet-SPP on both FLOPs and FPS when input size is large while maintain similar AP.
So which model is better is depend on the scenario of your task.
By the way, currently there is no good COCO pre-trained model like csresnext50-panet-spp-original-optimal for CSPDarknet53.
WongKinYiu
on 14 Jan 2020
@WongKinYiu Thank you for your answer. It is clear now.
mmartin56
on 14 Jan 2020
CSPDarknet53-PANet-SPP performs better than CSPResNeXt50-PANet-SPP on both _AP_ and _FPS_ when input size is not large. https://github.com/WongKinYiu/CrossStagePartialNetworks#gpu-real-time-models
This link shows that, on COCO 512x512, CSPResNet50-PANet-SPP is faster than CSPResNeXt50-PANet-SPP, with the same AP. In this thread however, CSPResNeXt50-PANet-SPP seems to be more recommended than CSPResNet50-PANet-SPP. Why is that?
mmartin56
on 16 Jan 2020
I trained CSPResNeXt50-PANet-SPP on my custom dataset with input size 544x544. The whole network is 79.6 BFLOPS and achieves 20.4 FPS on Tesla V100.
Yolov3 with 544x544 is 112.4 BFLOPS and achieves 22.7 FPS on Tesla V100.
Why is it that CSPResNeXt50-PANet-SPP have lower flops but ends up processing images in a longer time?
mmartin56
on 16 Jan 2020
@mmartin56 ResNeXt50 uses grouped-convolutionals which are slow on Tensor Cores which are in the Tesla V100.
AlexeyAB
on 16 Jan 2020
it is becuz it suffers from the explicit tensor copy and memory access.
the implementation of group convolution also not efficient nowadays.
so you can only get higher fps with CSPResNeXt50-PANet-SPP when input size is larger.
By the way, I have tested the inference of CSPResNeXt50-PANet-SPP on GV100, it gets 67/44 fps when input size are 512/608.
WongKinYiu
on 16 Jan 2020
@mmartin56 ResNeXt50 uses grouped-convolutionals which are slow on Tensor Cores which are in the Tesla V100.
In your opinion, would yolov3 also be faster than ResNeXt50 on a jetson TX2?
mmartin56
on 16 Jan 2020
so you can only get higher fps with CSPResNeXt50-PANet-SPP when input size is larger.
You're saying CSPResNeXt50-PANet-SPP would be faster than both yolov3 and CSPDarknet53-PANet-SPP when input size is large?
How large exactly are we talking here?
mmartin56
on 16 Jan 2020
i think CSPResNeXt50 will be faster than yolov3 on jetson tx2 since the bottleneck of jetson tx2 is the bandwidth.
in our testing, 608 is large enough on gpu without tensor cores.
WongKinYiu
on 16 Jan 2020
Thank you!
mmartin56
on 16 Jan 2020
@AlexeyAB https://github.com/AlexeyAB/darknet/issues/4406#issuecomment-569924085
label_smooth_eps=0.1 gets lower AP on cspresnext50-panet-spp (37.2/59.4/39.9 vs 38.0/60.8/40.8).
WongKinYiu
on 5 Feb 2020
@WongKinYiu Thanks!
So it seems label_smooth_eps=0.1 works well for Classifier, not for Detector.
Did you solve the issue with Nan for ASFF / BiFPN?
AlexeyAB
on 5 Feb 2020
@AlexeyAB Currently ..._softmax_maxval do not get nan.
WongKinYiu
on 5 Feb 2020
Well...although it won't get nan, the loss of ASFF still going to become higher and higher slowly.
WongKinYiu
on 8 Feb 2020
@WongKinYiu Can you show generated chart.png ?
AlexeyAB
on 8 Feb 2020
loss value always greater than 5, so i can see nothing on the chart.
WongKinYiu
on 8 Feb 2020
@WongKinYiu What is the current iteration number and loss value?
AlexeyAB
on 8 Feb 2020
80k: 9.2
90k: 13.6
100k: 20.3
WongKinYiu
on 9 Feb 2020
Related issues
 shootingliu
·
3Comments
shootingliu
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 off99555
·
3Comments
off99555
·
3Comments
 Yumin-Sun-00
·
3Comments
Yumin-Sun-00
·
3Comments
 hemp110
·
3Comments
hemp110
·
3Comments
Most helpful comment
@WongKinYiu Hi,
@pjreddie used several tricks to improve accuracy:
train
darknet53.cfgfor 800000 iterations withwidth=256 height=256, then setwidth=448 height=448and continue training with another 100000 iterations, then used this model as pre-trained weights for training Yolo v3 - it gives ~+1 mAPtrain yolov3 with
width=416 height=416 random=1, then setwidth=608 height=608 random=0and train another 200 or more iterations - it improve accuracy for 608x608 inference: https://github.com/pjreddie/darknet/blob/61c9d02ec461e30d55762ec7669d6a1d3c356fb2/examples/detector.c#L66If you didn't use these tricks, you can try to do it.
Also:
at the start of training, and at the end of trainin (between increasing resolution from 256x256 to 448x448) you can try to train 1-2 days with the highest mini_batch size for both Classifier and Detector, by using CPU-RAM: https://github.com/AlexeyAB/darknet/issues/4386
you can try to use
[Gaussian_yolo]layers without D/C/GIoU instead of[yolo]layers inCSPResNeXt50-PANet-SPP: https://github.com/AlexeyAB/darknet/issues/4147I think it can give +2-4% for both AP and AP50