Darknet: EfficientNet | Implementation ?
All 214 comments
+1
 nseidl
on 12 Jun 2019
nseidl
on 12 Jun 2019
Paper: https://arxiv.org/abs/1905.11946v2
Classifier
EfficientNet B0 (224x224) 0.9 BFLOPS - 0.45 B_FMA (16ms / RTX 2070), 4.9M params: efficientnet_b0.cfg.txt - Training 2.5 days
71.3% Top1 - 90.4% Top5 - accuracy weights file: https://drive.google.com/open?id=1nGdWz76A2EpNhWIfDeAI3hribboilux-
While (Official) EfficientNetB0 (224x224) 0.78 BFLOPS - 0.39 FMA, 5.3M params - that is trained by official code https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet with batch size equals to 256 has lower accuracy: 70.0% Top1 and 88.9% Top5
Detector - 3.7 BFLOPs, 45.0 [email protected] on COCO test-dev.
cfg-file: enet-coco.cfg.txt
weights file: https://drive.google.com/open?id=1FlHeQjWEQVJt0ay1PVsiuuMzmtNyv36m

efficientnet-lite3-leaky.cfg: top-1 73.0%, top-5 92.4%. - change relu6 to leaky: activation=leaky https://github.com/AlexeyAB/darknet/blob/master/cfg/efficientnet-lite3.cfg
Classifiers: - Can be trained on ImageNet(ILSVRC2012) by using 4 x GPU 2080 TI:
EfficientNet B0 XNOR (224x224) 0.8 BFLOPS + 25 BOPS (18ms / RTX 2070): efficientnet_b0_xnor.cfg.txt - 5 days
EfficientNet B3 (288x288) 3.5 BFLOPS - 1.8 B_FMA (28ms/RTX 2070): efficientnet_b3.cfg.txt - 11 days
EfficientNet B3 (320x320) 4.3 BFLOPS - 2.2 B_FMA (30ms/RTX 2070): efficientnet_b3_320.cfg.txt - 14 days
EfficientNet B4 (384x384) 10.2 BFLOPS - 5.1 B_FMA (46ms/RTX 2070): efficientnet_b4.cfg.txt - 26 days
Training command:
./darknet classifier train cfg/imagenet1k_c.data cfg/efficientnet_b0.cfg -topk
Continue training:
./darknet classifier train cfg/imagenet1k_c.data cfg/efficientnet_b0.cfg backup/efficientnet_b0_last.weights -topk
Content of imagenet1k_c.data:
classes=1000
train = data/imagenet1k.train_c.list
valid = data/inet.val_c.list
backup = backup
labels = data/imagenet.labels.list
names = data/imagenet.shortnames.list
top=5
Dataset - each image in imagenet1k.train_c.list and inet.val_c.list has one of 1000 labels from imagenet.labels.list, for example n01440764
- imagenet.labels.list: https://github.com/AlexeyAB/darknet/blob/master/data/imagenet.labels.list
- imagenet.shortnames.list: https://github.com/AlexeyAB/darknet/blob/master/data/imagenet.shortnames.list
ILSVRC2012 training dataset - annotated images - 138 GB: https://github.com/AlexeyAB/darknet/blob/master/scripts/get_imagenet_train.sh
ILSVRC2012 validation dataset:
- images - 6.3 GB: http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_val.tar
- annotations - 2.2 MB: http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_bbox_val_v3.tgz
Set validation labels: https://github.com/AlexeyAB/darknet/blob/master/scripts/imagenet_label.sh
read: https://pjreddie.com/darknet/imagenet/
More: http://www.image-net.org/challenges/LSVRC/2012/nonpub-downloads
# (width_coefficient, depth_coefficient, resolution, dropout_rate)
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
CLICK ME - EfficientNet B0 model details
#alpha=1.2, beta=1.1, gamma=1.15
#d=pow(alpha, fi), w=pow(beta, fi), r=pow(gamma, fi)
#fi=0, d=1.0, w=1.0, r=1.0 - theoretically
# in practice: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L28-L40
# 'efficientnet-b0': (1.0, 1.0, 224, 0.2):
# width=1.0, depth=1.0, resolution=224, dropout=0.2
BLOCKS 1 - 7:
'r1_k3_s11_e1_i32_o16_se0.25', 'r2_k3_s22_e6_i16_o24_se0.25',
'r2_k5_s22_e6_i24_o40_se0.25', 'r3_k3_s22_e6_i40_o80_se0.25',
'r3_k5_s11_e6_i80_o112_se0.25', 'r4_k5_s22_e6_i112_o192_se0.25',
'r1_k3_s11_e6_i192_o320_se0.25',
In details: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L61-L69
BLOCK-1
# r1_k3_s11_e1_i32_o16_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 1
# input_filters=int(options['i']), input_filters = 32
# output_filters=int(options['o']), output_filters = 16
# expand_ratio=int(options['e']), expand_ratio = 1
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-2
# r2_k3_s22_e6_i16_o24_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 2
# input_filters=int(options['i']), input_filters = 16
# output_filters=int(options['o']), output_filters = 24
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-3
# r2_k5_s22_e6_i24_o40_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 2
# input_filters=int(options['i']), input_filters = 24
# output_filters=int(options['o']), output_filters = 40
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-4
# r3_k3_s22_e6_i40_o80_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 3
# input_filters=int(options['i']), input_filters = 40
# output_filters=int(options['o']), output_filters = 80
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-5
# r3_k5_s11_e6_i80_o112_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 3
# input_filters=int(options['i']), input_filters = 80
# output_filters=int(options['o']), output_filters = 112
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-6
# r4_k5_s22_e6_i112_o192_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 4
# input_filters=int(options['i']), input_filters = 112
# output_filters=int(options['o']), output_filters = 192
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-7
# r1_k3_s11_e6_i192_o320_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 1
# input_filters=int(options['i']), input_filters = 192
# output_filters=int(options['o']), output_filters = 320
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1

CLICK ME - EfficientNet B3 model details
#alpha=1.2, beta=1.1, gamma=1.15
#d=pow(alpha, fi), w=pow(beta, fi), r=pow(gamma, fi)
#fi=3, d=1.73, w=1.33, r=1.52 - theoretically
# in practice: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L28-L40
# 'efficientnet-b3': (1.2, 1.4, 300, 0.3):
# width=1.2, depth=1.4, resolution=300 (320), dropout=0.3
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_model.py#L120-L125
# repeats_new = int(math.ceil(depth * repeats)) ### ceil - Rounds x upward,
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L134-L137
# width_coefficient=width_coefficient,
# depth_coefficient=depth_coefficient,
# depth_divisor=8,
# min_depth=None)
#
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_model.py#L101-L117
# multiplier = width_coefficient = 1.2
# divisor = 8
# min_depth = none
# min_depth = divisor = 8
filters = filters * 1.2
new_filters = max(8, (int(filters + 4) // 8) * 8) ## //===floor in this case
if new_filters < 0.9 * filters: new_filters += 8
16 *1.2=19,2
new_filters = max(8, int(19,2+4)//8 * 8) = 16 (>=16)
24 *1.2=28,8
new_filters = max(8, int(28,8+4)//8 * 8) = 32 (>24)
32 *1.2=38,4
new_filters = max(8, int(38,4+4)//8 * 8) = 40 (>32)
40 *1.2=48
new_filters = max(8, int(48+4)//8 * 8) = 48 (>40)
80 *1.2=96
new_filters = max(8, int(96+4)//8 * 8) = 96 (>80)
112 *1.2=134,4
new_filters = max(8, int(134,4+4)//8 * 8) = 136 (>112)
192 *1.2=230,4
new_filters = max(8, int(230,4+4)//8 * 8) = 232 (>192)
320 *1.2=384
new_filters = max(8, int(384+4)//8 * 8) = 384 (>320)
8 *1.2=9,6
new_filters = max(8, int(9,6+4)//8 * 8) = 8 (==8)
64 *1.2=76,8
new_filters = max(8, int(76,8+4)//8 * 8) = 80 (>64)
96 *1.2=115,2
new_filters = max(8, int(115,2+4)//8 * 8) = 112 (>96)
144 *1.2=172,8
new_filters = max(8, int(172,8+4)//8 * 8) = 176 (>144)
384 *1.2=460,8
new_filters = max(8, int(460,8+4)//8 * 8) = 464 (>384)
576 *1.2=691,2
new_filters = max(8, int(691,2+4)//8 * 8) = 688 (>576)
960 *1.2=1152
new_filters = max(8, int(1152+4)//8 * 8) = 1152 (>960)
1280 *1.2=1536
new_filters = max(8, int(1536+4)//8 * 8) = 1536 (>1280)
BLOCKS 1 - 7: (for b0)
'r2_k3_s11_e1_i32_o16_se0.25', 'r4_k3_s22_e6_i16_o24_se0.25',
'r4_k5_s22_e6_i24_o40_se0.25', 'r6_k3_s22_e6_i40_o80_se0.25',
'r6_k5_s11_e6_i80_o112_se0.25', 'r8_k5_s22_e6_i112_o192_se0.25',
'r2_k3_s11_e6_i192_o320_se0.25',
In details: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L61-L69
BLOCK-1
# r1_k3_s11_e1_i32_o16_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 2 //1
# input_filters=int(options['i']), input_filters = 40 //32
# output_filters=int(options['o']), output_filters = 16 //16
# expand_ratio=int(options['e']), expand_ratio = 1
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-2
# r2_k3_s22_e6_i16_o24_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 3 //2
# input_filters=int(options['i']), input_filters = 16 //16
# output_filters=int(options['o']), output_filters = 32 //24
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-3
# r2_k5_s22_e6_i24_o40_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 3 //2
# input_filters=int(options['i']), input_filters = 32 //24
# output_filters=int(options['o']), output_filters = 48 //40
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-4
# r3_k3_s22_e6_i40_o80_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 5 //3
# input_filters=int(options['i']), input_filters = 48 //40
# output_filters=int(options['o']), output_filters = 96 //80
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-5
# r3_k5_s11_e6_i80_o112_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 5 //3
# input_filters=int(options['i']), input_filters = 96 //80
# output_filters=int(options['o']), output_filters = 136 //112
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-6
# r4_k5_s22_e6_i112_o192_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 6 //4
# input_filters=int(options['i']), input_filters = 136 //112
# output_filters=int(options['o']), output_filters = 232 //192
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-7
# r1_k3_s11_e6_i192_o320_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 2 //1
# input_filters=int(options['i']), input_filters = 232 //192
# output_filters=int(options['o']), output_filters = 384 //320
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1

CLICK ME - EfficientNet B4 model details
#alpha=1.2, beta=1.1, gamma=1.15
#d=pow(alpha, fi), w=pow(beta, fi), r=pow(gamma, fi)
#fi=4, d=2.07, w=1.46, r=1.75 - theoretically
# in practice: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L28-L40
# efficientnet-b4': (1.4, 1.8, 380, 0.4):
# width=1.4, depth=1.8, resolution=380, dropout=0.4
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_model.py#L120-L125
# repeats_new = int(math.ceil(depth * repeats)) ### ceil - Rounds x upward,
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L134-L137
# width_coefficient=width_coefficient,
# depth_coefficient=depth_coefficient,
# depth_divisor=8,
# min_depth=None)
#
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_model.py#L101-L117
# multiplier = width_coefficient = 1.4
# divisor = 8
# min_depth = none
# min_depth = divisor = 8
filters = filters * 1.4
new_filters = max(8, (int(filters + 4) // 8) * 8) ## //===floor in this case
if new_filters < 0.9 * filters: new_filters += 8
16 *1.4=22.4
new_filters = max(8, int(22.4+4)//8 * 8) = 24 (>16)
24 *1.4=33.6
new_filters = max(8, int(33.6+4)//8 * 8) = 32 (>24)
32 *1.4=44.8
new_filters = max(8, int(44.8+4)//8 * 8) = 48 (>32)
40 *1.4=56
new_filters = max(8, int(56+4)//8 * 8) = 56 (>40)
80 *1.4=112
new_filters = max(8, int(112+4)//8 * 8) = 112 (>80)
112 *1.4=156,8
new_filters = max(8, int(156,8+4)//8 * 8) = 160 (>112)
192 *1.4=268,8
new_filters = max(8, int(268,8+4)//8 * 8) = 272 (>192)
320 *1.4=448
new_filters = max(8, int(448+4)//8 * 8) = 448 (>320)
8 *1.4=11,2
new_filters = max(8, int(11,2+4)//8 * 8) = 8 (==8)
64 *1.4=89,6
new_filters = max(8, int(89,6+4)//8 * 8) = 88 (>64)
96 *1.4=134,4
new_filters = max(8, int(134,4+4)//8 * 8) = 136 (>96)
144 *1.4=201,6
new_filters = max(8, int(201,6+4)//8 * 8) = 200 (>144)
384 *1.4=537,6
new_filters = max(8, int(537,6+4)//8 * 8) = 536 (>384)
576 *1.4=806,4
new_filters = max(8, int(806,4+4)//8 * 8) = 808 (>576)
960 *1.4=1344
new_filters = max(8, int(1344+4)//8 * 8) = 1344 (>960)
1280 *1.4=1792
new_filters = max(8, int(1792+4)//8 * 8) = 1792 (>1280)
BLOCKS 1 - 7:
'r2_k3_s11_e1_i32_o16_se0.25', 'r4_k3_s22_e6_i16_o24_se0.25',
'r4_k5_s22_e6_i24_o40_se0.25', 'r6_k3_s22_e6_i40_o80_se0.25',
'r6_k5_s11_e6_i80_o112_se0.25', 'r8_k5_s22_e6_i112_o192_se0.25',
'r2_k3_s11_e6_i192_o320_se0.25',
In details: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L61-L69
BLOCK-1
# r1_k3_s11_e1_i32_o16_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 2 //1
# input_filters=int(options['i']), input_filters = 48 //32
# output_filters=int(options['o']), output_filters = 24 //16
# expand_ratio=int(options['e']), expand_ratio = 1
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-2
# r2_k3_s22_e6_i16_o24_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 4 //2
# input_filters=int(options['i']), input_filters = 24 //16
# output_filters=int(options['o']), output_filters = 32 //24
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-3
# r2_k5_s22_e6_i24_o40_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 4 //2
# input_filters=int(options['i']), input_filters = 32 //24
# output_filters=int(options['o']), output_filters = 56 //40
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-4
# r3_k3_s22_e6_i40_o80_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 6 //3
# input_filters=int(options['i']), input_filters = 56 //40
# output_filters=int(options['o']), output_filters = 112 //80
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-5
# r3_k5_s11_e6_i80_o112_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 6 //3
# input_filters=int(options['i']), input_filters = 112 //80
# output_filters=int(options['o']), output_filters = 160 //112
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1
BLOCK-6
# r4_k5_s22_e6_i112_o192_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 5
# num_repeat=int(options['r']), num_repeat = 8 //4
# input_filters=int(options['i']), input_filters = 160 //112
# output_filters=int(options['o']), output_filters = 272 //192
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 2,2
BLOCK-7
# r1_k3_s11_e6_i192_o320_se0.25
# return efficientnet_model.BlockArgs(
# kernel_size=int(options['k']), kernel_size = 3
# num_repeat=int(options['r']), num_repeat = 2 //1
# input_filters=int(options['i']), input_filters = 272 //192
# output_filters=int(options['o']), output_filters = 448 //320
# expand_ratio=int(options['e']), expand_ratio = 6
# id_skip=('noskip' not in block_string),
# se_ratio=float(options['se']) if 'se' in options else None, se_ratio = 0.25
# strides=[int(options['s'][0]), int(options['s'][1])]) strides = 1,1

https://www.dlology.com/blog/transfer-learning-with-efficientnet/
https://github.com/zsef123/EfficientNets-PyTorch/tree/master/models
https://medium.com/@lessw/efficientnet-from-google-optimally-scaling-cnn-model-architectures-with-compound-scaling-e094d84d19d4
In other words, to scale up the CNN, the depth of layers should increase 20%, the width 10% and the image resolution 15% to keep things as efficient as possible while expanding the implementation and improving the CNN accuracy.
The MBConv block is nothing fancy but an Inverted Residual Block (used in MobileNetV2) with a Squeeze and Excite block injected sometimes.
MobileNetV2: Inverted Residuals and Linear Bottlenecks: https://arxiv.org/pdf/1801.04381v4.pdf
MobileNetV2 graph: http://ethereon.github.io/netscope/#/gist/d01b5b8783b4582a42fe07bd46243986
MobileNetV2 proto: https://github.com/shicai/MobileNet-Caffe/blob/master/mobilenet_v2_deploy.prototxt
MobileNetv2 Darknet-cfg: https://github.com/WePCf/darknet-mobilenet-v2/blob/master/mobilenet/test.cfg (should be trained from the begining, since the src/image.c and examples/classifier.c are modified in WePCf-repo, search for "mobilenet" to see what are changed)
|  |
|  |
|
|-|-|
| | |
MobileNet_v2:

EfficientNet_b0:



|  |
|  |
|
|-|-|
| | |


 AlexeyAB
on 12 Jun 2019
AlexeyAB
on 12 Jun 2019
EfficientNet_b0: efficientnet_b0.cfg.txt - Accuracy: Top1 = 57.6%, Top5 = 81.2% - 150 000 iterations (something goes wrong)

AlexeyAB
on 15 Jun 2019
Would like to share this link.
https://pypi.org/project/gluoncv2/
Interesting to see the imagenet-1k comparison chart.
Model | Top 1 Error | Top 5 Error | Params | Flops
DarkNet-53 | 21.41 | 5.56 | 41,609,928 | 7,133.86M
EfficientNet-B0b | 23.41 | 6.95 | 5,288,548 | 414.31M
With the difference of 2% in top 1 error with number of parameters are 1/8 and 1/17 less flops.
Would love to see the inference time and accuracy as object detection.
Also a tiny version wouldn't be bad after all.
This is like running yolov3-tiny with yolov3 accuracy.
 dexception
on 15 Jun 2019
dexception
on 15 Jun 2019
@dexception
Have you ever seen a graphic representation of EfficientNet b1 - b7 models (other than b0), or their exact text description, like Caffe proto-files?
AlexeyAB
on 15 Jun 2019
EfficientNet_b4: efficientnet_b4.cfg.txt
AlexeyAB
on 17 Jun 2019
@AlexeyAB
Keras, Pytorch and Mxnet implementation is definitely there:
https://github.com/qubvel/efficientnet
https://github.com/lukemelas/EfficientNet-PyTorch
https://github.com/titu1994/keras-efficientnets
https://github.com/zsef123/EfficientNets-PyTorch
https://github.com/DableUTeeF/keras-efficientnet
https://github.com/qubvel/efficientnet
https://github.com/mnikitin/EfficientNet/blob/master/efficientnet_model.py
The code and research paper is different. But the code is correct.
https://github.com/tensorflow/tpu/issues/383
I don't think there is any caffe implementation as of yet.
dexception
on 18 Jun 2019
Hello, I draw the model from Keras implementation: https://github.com/qubvel/efficientnet .
Here are b0 and b1.
CLICK ME - EfficientNet B0 and B1 model diagrams


I use the code:
`from efficientnet import EfficientNetB1
from keras.utils import plot_model
model = EfficientNetB1()
plot_model(model, to_file='EfficientNetB1.png')`
 WongKinYiu
on 18 Jun 2019
WongKinYiu
on 18 Jun 2019
EfficientNet_b0: efficientnet_b0.cfg.txt - Accuracy: Top1 = 19.3%, Top5 = 40.6% (something goes wrong)
Maybe squeeze and excitation blocks are missing?
WongKinYiu
on 18 Jun 2019
@WongKinYiu Thanks!
Can you also add model diagram for B4?
Maybe squeeze and excitation blocks are missing?
I think yes, there should be:
- squeeze and excitation blocks https://towardsdatascience.com/squeeze-and-excitation-networks-9ef5e71eacd7 and https://arxiv.org/abs/1709.01507v4 and https://github.com/hujie-frank/SENet
- dropout
- batch=120 and should be trained at least 1 000 000 - 1 600 000 iterations

AlexeyAB
on 19 Jun 2019
@dexception Thanks!
AlexeyAB
on 19 Jun 2019
Model diagram for EfficientNets.
CLICK ME - EfficientNet B0 model diagram
CLICK ME - EfficientNet B1 model diagram
CLICK ME - EfficientNet B2 model diagram

CLICK ME - EfficientNet B3 model diagram

CLICK ME - EfficientNet B4 model diagram

CLICK ME - EfficientNet B5 model diagram

CLICK ME - EfficientNet B6 model diagram

CLICK ME - EfficientNet B7 model diagram

WongKinYiu
on 19 Jun 2019
@WongKinYiu Thanks!
It seems now it looks like your diagram:
efficientnet_b0.cfg.txt
- top1 = 69.49%
- top5 = 89.44%
Should be used: should be trained at least 1.6 M iterations with learning_rate=0.256 policy=step scale=0.97 step=10000 (initial learning rate 0.256 that decays by 0.97 every 2.4 epochs) to achieve Top1 = 76.3%, Top5 = 93.2%
Trained weights-file, 500 000 iterations with batch=120: https://drive.google.com/open?id=1MvX0skcmg87T_jn8kDf2Oc6raIb56xq9

Just
- I use
[dropout]instead of DropConnect
On your diagrams Lambda is a [avgpool].
MBConv blocks includes:
- Squeeze-and-Excitation blocks (layers:
[avgpool]->[conv]->[conv]->[scale_channels]) - and
[dropout]-layer before each[shortcut]-residual layer
as it is done here: https://github.com/qubvel/efficientnet/blob/master/efficientnet/model.py - Swish activations

AlexeyAB
on 19 Jun 2019
@AlexeyAB Good job! And thank you for sharing the cfg file.
I will also implement SNet of ThunderNet as backbone to compare with EfficientNet.
WongKinYiu
on 19 Jun 2019
@WongKinYiu Yes, this is interesting that SNet+ThunderNet achieved the same accuracy 78.6% [email protected] as Yolo v2, but by using 2-stage-detector with 24 FPS on ARM CPU: https://paperswithcode.com/sota/object-detection-on-pascal-voc-2007

AlexeyAB
on 20 Jun 2019
@AlexeyAB I also want to implement CEM (Context Enhancement Module) and SAM (Spatial Attention Module) of ThunderNet.
CEM + YOLOv3 got 41.2% [email protected] with 2.85 BFLOPs.
CEM + SAM + YOLOv3 got 42.0% [email protected] with 2.90 BFLOPs.
CEM:

SAM:

Results:

WongKinYiu
on 20 Jun 2019
I'd be interested in running a trial with efficientnet and sharing the results - do you have a B6 or B7 version of the model? Do I use it in the same way as I would with any of the other cfg files? No need to manually calculate anchors and enter classes in the cfg?
 LukeAI
on 20 Jun 2019
LukeAI
on 20 Jun 2019
Oh I see - efficientnet is a full Object Detector? But maybe the B7 model with a Yolo head... ?
LukeAI
on 20 Jun 2019
@LukeAI
This is imagenet classification.
dexception
on 20 Jun 2019
Ok so I realise that this is image classification - I have an image classification problem with 7 classes - if necessary I could resize all my images to 32x32 - how could I train/test on my dataset with the .cfg ?
LukeAI
on 20 Jun 2019
WongKinYiu
on 20 Jun 2019
@AlexeyAB
Nice work on EfficientNet.
If implemented successfully this would give the fastest training and inference time among all implementations.
 mdv3101
on 21 Jun 2019
mdv3101
on 21 Jun 2019
@AlexeyAB
Since we are already discussing the newer models here
https://github.com/AlexeyAB/darknet/issues/3114
This issue should be merged with this.
Because eventually we will have yolo-head with EfficientNet once the niggles are sorted out.
dexception
on 22 Jun 2019
Will Swish be implemented in darknet soon?
which is based on RELU/RELU6?
 ChenCong7375
on 26 Jun 2019
ChenCong7375
on 26 Jun 2019
Do you have scale_channels layer implement?3q
 beHappy666
on 26 Jun 2019
beHappy666
on 26 Jun 2019
@WongKinYiu Thanks!
It seems now it looks like your diagram: efficientnet_b0.cfg.txt
- top1 = 68.04%
- top5 = 88.59%
Should be used: should be used Swish instead of leaky-ReLU, should be trained at least 1M iterations with
learning_rate=0.256 policy=step scale=0.97 step=10000(initial learning rate 0.256 that decays by 0.97 every 2.4 epochs)Trained weights-file, 378 000 iterations with batch=120: https://drive.google.com/open?id=1PWbM3en8mOqIbe9kIrEY-ljvvcmTR5AK
Just
- I use
[dropout]instead of DropConnect- I use
activation=leaky-relu (slope=0.1) instead of SwishOn your diagrams Lambda is a [avgpool].
MBConv blocks includes:
- Squeeze-and-Excitation blocks (layers:
[avgpool]->[conv]->[conv]->[scale_channels])- and
[dropout]-layer before each[shortcut]-residual layer
as it is done here: https://github.com/qubvel/efficientnet/blob/master/efficientnet/model.py

@AlexeyAB

Can you share other cfg files for EfficientNet ? I would like to give it a try.
dexception
on 26 Jun 2019
@ChenCong7375 @beHappy666
Do you have scale_channels layer implement?3q
Yes.
Will Swish be implemented in darknet soon?
which is based on RELU/RELU6?
There are already implemented in the last commits:
Swish is based on sigmoid,
swish = x * sigmoid(x)
later I will addh-swish = x * ReLU6(x+3) / 6from MobileNet v3: https://github.com/AlexeyAB/darknet/issues/3494Squeeze-n-excitation blocks that is based on
[scale_channels]-layer
AlexeyAB
on 26 Jun 2019
@dexception I will add b0, b4 and may be other models in 1-2 days. I just should test it.
It would be nice if you can train them about 1-1.5 million iterations (at least 100 epochs with batch=120).
AlexeyAB
on 26 Jun 2019
@dexception I will try for sure.
Just want to mention this ....so that we are on track:
EfficientNet B0 Stats:
Difference of 8.26% Top 1 Accuracy with the actual.
Difference of 4.61% Top 5 Accuracy with the actual.
Flops: 0.915 vs 0.39 with the actual. (2.34 Times)
https://github.com/AlexeyAB/darknet/files/3307881/efficientnet_b0.cfg.txt
dexception
on 26 Jun 2019
@dexception
EfficientNet B0 Stats:
Difference of 8.26% Top 1 Accuracy with the actual.
Difference of 4.61% Top 5 Accuracy with the actual.
It is just because there wasn't used Siwsh-activation - I will add. And because it was trained 360 000 iterations instead of 1 600 000 iterations with another learning rate policy - I will change.
Flops: 0.915 vs 0.39 with the actual. (2.34 Times)
This is strange, since I used absolutely the same model. Also you can compare their Flops for ResNet50 or 101 with
ResNet50:
4.1 BFlopsshown in their paper Table 2: https://arxiv.org/pdf/1905.11946v2.pdfResNet50:
9.74 BFlopsshown in Joseph's site: https://pjreddie.com/darknet/imagenet/ResNet50:
10 BFlopsshown in Darknet
So it seems they calculate two operations (ADD+MUL) as one FMA-operation (which is used in CPUs, GPUs and probably in their TPUs): https://en.wikipedia.org/wiki/FMA_instruction_set
So we use correct model, just we calculate Flops in different ways, our approach is correct: https://en.wikipedia.org/wiki/FLOPS
https://github.com/AlexeyAB/darknet/blob/88cccfcad4f9591a429c1e71c88a42e0e81a5e80/src/convolutional_layer.c#L363
https://github.com/AlexeyAB/darknet/blob/88cccfcad4f9591a429c1e71c88a42e0e81a5e80/src/convolutional_layer.c#L550
Output of ResNet50:

AlexeyAB
on 26 Jun 2019
@AlexeyAB
Thanks for the explanation. Learned alot from you.
My main objective is to use EfficientNet for Object Detection.
Can't wait to try it.
dexception
on 26 Jun 2019
@AlexeyAB 3q
beHappy666
on 28 Jun 2019
@dexception @beHappy666 @nseidl @WongKinYiu @LukeAI @mdv3101 @ChenCong7375
I added 4 cfg-files Classifier EfficientNets: B0, B3, B3_320, B4: https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-501263052
(there are used: squeeze-n-excitation, swish-sigmoid, dropout, residual-connections, grouped-convolutionals)
To get the highest Top1/Top5 results, you should train it at least 1 600 000 iterations with batch=128.
Also I added EfficientNet B0 XNOR where are replaced Depth-wise-conv-layers by XNOR-conv-layers.
You can try to train it on ImageNet (ILSVRC2012), I wrote there how to do it: https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-501263052
After you train one of them on ImageNet, it can be used as pre-trained weights-files for detection networks.
Then I will create a Detection network: EfficientNet-backend + TridentNet (or FPN as in Yolov3) + Yolo_Head
I will add GIoU, Mixup, Scale_xy, and may be new_PAN and Assisted Excitation of Activations, If I have time to make them: https://github.com/AlexeyAB/darknet/projects/1#card-22787888
Then you can train it on MS COCO and get state-of-art results.
Also you can try to train EfficientNet on Stylized-ImageNet + ImageNet and get state-of-art results:
AlexeyAB
on 28 Jun 2019
@AlexeyAB
I have always hated the idea of putting names of the categories within the name of images.
For now i have no choice but to follow it. Eventually it would better to have a single csv file for classification rather than this.
dexception
on 29 Jun 2019
@dexception This is not Darknet's idea.
This is done in default ILSVRC2012_img_train.tar (ImageNet).
Maybe in the future I will make an alternative with txt or csv file/files, but this is not a priority.
AlexeyAB
on 29 Jun 2019
@AlexeyAB
Just started training for EfficientNet b0 model.
I have a 2080 TI(only one) machine.
batch=128
subdivision=4
I guess it is going to take a week.
dexception
on 1 Jul 2019
@AlexeyAB I can train cifar with EfficientNet_b0 on my titanXp, I think there must be some error in my detection cfg. #3500
I am looking forward to your object-detection work on EfficientNet. Thank you very much.
ChenCong7375
on 1 Jul 2019
@dexception here.
efficientnet_b0_cg.cfg.txt
ChenCong7375
on 1 Jul 2019
I think maybe scale_channels_layer has cuda init problem.
When random parameter of yolo layer is set to 1, it will get CUDNN_STATUS_EXECUTION_FAILED error.
If disable cudnn, it will get illegal memory access error.
When random parameter of yolo layer is set to 0, anything is fine.
WongKinYiu
on 2 Jul 2019
@AlexeyAB I can train cifar with EfficientNet_b0 on my titanXp, I think there must be some error in my detection cfg. #3500
I am looking forward to your object-detection work on EfficientNet. Thank you very much.
@ChenCong7375
Can you try and train on efficientNet-b3 model ?
https://github.com/AlexeyAB/darknet/files/3340717/efficientnet_b3.cfg.txt
dexception
on 2 Jul 2019
@WongKinYiu
What init problem do you mean? https://github.com/AlexeyAB/darknet/blob/54e2d0b0e8909bc1da8a2d15113b4f2669ce2f4e/src/scale_channels_layer.c#L7-L40
When random parameter of yolo layer is set to 1, it will get CUDNN_STATUS_EXECUTION_FAILED error.
If disable cudnn, it will get illegal memory access error.When random parameter of yolo layer is set to 0, anything is fine.
Do you mean an error occurs during backpropagation from yolo-layer (training)?
As you can see it doesn't use cuDNN: https://github.com/AlexeyAB/darknet/blob/54e2d0b0e8909bc1da8a2d15113b4f2669ce2f4e/src/scale_channels_layer.c#L96-L116
To get correct error place, you should build Darknet with DEBUG=1
AlexeyAB
on 3 Jul 2019
@WongKinYiu
What init problem do you mean?
When random parameter of yolo layer is set to 1, it will get CUDNN_STATUS_EXECUTION_FAILED error.
If disable cudnn, it will get illegal memory access error.
When random parameter of yolo layer is set to 0, anything is fine.Do you mean an error occurs during backpropagation from yolo-layer (training)?
As you can see it doesn't use cuDNN:
To get correct error place, you should build Darknet with
DEBUG=1
I am not sure add resize_scale_channels_layer to network.c is necessary or not.
Or maybe error occurs in other layer.
I get a fever now, I will check it using 'DEBUG=1' after I feel better.
WongKinYiu
on 3 Jul 2019
@WongKinYiu
I am not sure add resize_scale_channels_layer to network.c is necessary or not.
Yes, it is there: https://github.com/AlexeyAB/darknet/blob/54e2d0b0e8909bc1da8a2d15113b4f2669ce2f4e/src/scale_channels_layer.c#L42-L58
AlexeyAB
on 3 Jul 2019
@WongKinYiu
I am not sure add resize_scale_channels_layer to network.c is necessary or not.
Yes, it is there:
I mean here.

But even though I add resize_scale_channels_layer to network.c, the error still occurs.
I have no other idea why it will get error when set random=1 now.
WongKinYiu
on 3 Jul 2019
@WongKinYiu I fixed it: https://github.com/AlexeyAB/darknet/commit/5a6afe96d3aa8aed19405577db7dba0ff173c848
I don't get an error if I set width=320 height=320 random=1
AlexeyAB
on 3 Jul 2019
@WongKinYiu I fixed it: 5a6afe9
I don't get an error if I set width=320 height=320 random=1
Hello, previous I got error at w=h=416, after training 50~80 epochs.
I will try new repo after tomorrow, thank you.
WongKinYiu
on 3 Jul 2019
@AlexeyAB The iterations are moving too slowly. They are stopping after every 20-30 iterations.
Is this normal ?
dexception
on 3 Jul 2019
@dexception
The iterations are moving too slowly. They are stopping after every 20-30 iterations.
Is this normal ?
With what message?
AlexeyAB
on 3 Jul 2019
(next TOP5 calculation at 20011 iterations) Tensor Cores are disabled until the first 3000 iterations are reached.
(next TOP5 calculation at 20011 iterations) Tensor Cores are disabled until the first 3000 iterations are reached.
(next TOP5 calculation at 20011 iterations) Tensor Cores are disabled until the first 3000 iterations are reached.
(next TOP5 calculation at 20011 iterations) Tensor Cores are disabled until the first 3000 iterations are reached.
dexception
on 3 Jul 2019
The iterations are moving too slowly. They are stopping after every 20-30 iterations.
Is this normal ?
Does the program crash completely after each 30 iterations or just pause for a while?
AlexeyAB
on 3 Jul 2019
It pauses for a min and then this line is printed.
(next TOP5 calculation at 20011 iterations) Tensor Cores are disabled until the first 3000 iterations are reached.
dexception
on 3 Jul 2019
@dexception This is very strange. I didn't meet this.
May be it calculates Top5 too often.
Try to set 1000 there: https://github.com/AlexeyAB/darknet/blame/master/src/classifier.c#L144
AlexeyAB
on 3 Jul 2019
Is it possible to use efficientnet with yolov3 for object detection, with training in Darknet here?
nseidl
on 3 Jul 2019
@nseidl
After you train one of them on ImageNet, it can be used as pre-trained weights-files for detection networks.
Then I will create a Detection network: EfficientNet-backend + TridentNet (or FPN as in Yolov3) + Yolo_HeadI will add GIoU, Mixup, Scale_xy, and may be new_PAN and Assisted Excitation of Activations, If I have time to make them: https://github.com/AlexeyAB/darknet/projects/1#card-22787888
Then you can train it on MS COCO and get state-of-art results.
 dreambit
on 3 Jul 2019
dreambit
on 3 Jul 2019
@dexception This is very strange. I didn't meet this.
May be it calculates Top5 too often.
Try to set 1000 there: https://github.com/AlexeyAB/darknet/blame/master/src/classifier.c#L144
Still Facing the same issue.
So exactly after 30 iterations it is pausing.
dexception
on 4 Jul 2019
@dexception
What batch, subdivisions and GPU do you use?
Can you show GPU-VRAM usage during training?
What CUDA, cuDNN and OS do you use?
How many GPUs do you use?
What training command do you use?
Show your
obj.datafileDo you train on Local or Remote server?
AlexeyAB
on 4 Jul 2019
What batch, subdivisions and GPU do you use?
Batch : 128
Subdivisions: 4
Can you show GPU-VRAM usage during training?
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 17652 C ./darknet 6521MiB |
+-----------------------------------------------------------------------------+
index, timestamp, utilization.gpu [%], power.draw [W], temperature.gpu
0, 2019/07/05 09:42:29.860, 0 %, 217.12 W, 58
0, 2019/07/05 09:42:30.863, 68 %, 103.37 W, 55
0, 2019/07/05 09:42:31.864, 0 %, 215.44 W, 58
0, 2019/07/05 09:42:32.869, 52 %, 103.22 W, 56
0, 2019/07/05 09:42:33.870, 16 %, 116.11 W, 56
0, 2019/07/05 09:42:34.872, 38 %, 102.11 W, 56
0, 2019/07/05 09:42:35.873, 30 %, 101.66 W, 56
0, 2019/07/05 09:42:36.875, 18 %, 189.39 W, 57
0, 2019/07/05 09:42:37.876, 50 %, 101.23 W, 56
0, 2019/07/05 09:42:38.878, 6 %, 218.42 W, 59
0, 2019/07/05 09:42:39.879, 63 %, 102.96 W, 56
0, 2019/07/05 09:42:40.881, 0 %, 213.42 W, 59
0, 2019/07/05 09:42:41.882, 68 %, 102.96 W, 56
0, 2019/07/05 09:42:42.885, 0 %, 212.70 W, 60
0, 2019/07/05 09:42:43.887, 68 %, 103.08 W, 56
0, 2019/07/05 09:42:44.889, 0 %, 212.85 W, 60
0, 2019/07/05 09:42:45.890, 69 %, 103.03 W, 57
0, 2019/07/05 09:42:46.892, 0 %, 102.55 W, 56
What CUDA, cuDNN and OS do you use?
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
Cudnn:
cudnn-10.0-linux-x64-v7.5.0.56.tgz
How many GPUs do you use?
1 GPU i.e Nvidia RTX 2080 TI
What training command do you use?
nohup ./darknet classifier train cfg/imagenet1k.data cfg/efficientnet_b0.cfg /efficientnet_b0/backup/efficientnet_b0_last.weights -topk -dont_show &
Show your obj.data file
classes=1000
train = /opt/dataset/imagenet_2012/imagenet1k.train.list
valid = /opt/dataset/imagenet_2012/inet.val.list
backup = /opt/work/project_efficientnet/darknet/efficientnet_b0/backup/
labels = /opt/work/project_efficientnet/darknet/cfg/imagenet.labels.list
names = /opt/work/project_efficientnet/darknet/cfg/imagenet.shortnames.list
top=5
Do you train on Local or Remote server?
Remote Server via ssh
With the current speed i am only able to manage 50k interations daily. So training the entire dataset for EfficientNet B0 would take a month. So something is definitely wrong here.
dexception
on 5 Jul 2019
@WongKinYiu I fixed it: 5a6afe9
I don't get an error if I set width=320 height=320 random=1
I still get same error after training 30~60 iterations.
I think maybe w & h of resize_scale_channels_layer is not correct.
In make_scale_channels_layer:
l.out_w = w2;
l.out_h = h2;
In resize_scale_channels_layer:
l->out_w = w;
l->out_h = h;
while w & h should be 1 in scale_channels_layer (assert(w == 1 & h == 1);).
But I don't know why it can run several iterations...
WongKinYiu
on 5 Jul 2019
I am waiting for replace Darknet53 with Efficient in backbone of YOLO
 hitle451997
on 5 Jul 2019
hitle451997
on 5 Jul 2019
@hitle451997
This is going to take a while.
dexception
on 5 Jul 2019
@dexception
Maybe only the display slows down, but training goes without slowing down?
It seems that your HDD or CPU is a bottleneck, because Loading time higher than 0 sec.
Try to use SSD.
AlexeyAB
on 5 Jul 2019
@AlexeyAB
Htop

iotop

I think system is quite resourceful.
Xeon cpu with 16 cores should enough for training.
dexception
on 5 Jul 2019
@dexception
So HDD is a bottleneck.
Load time should be ~0 sec - I use SSD Samsung EVO 850 Pro 1 TB:
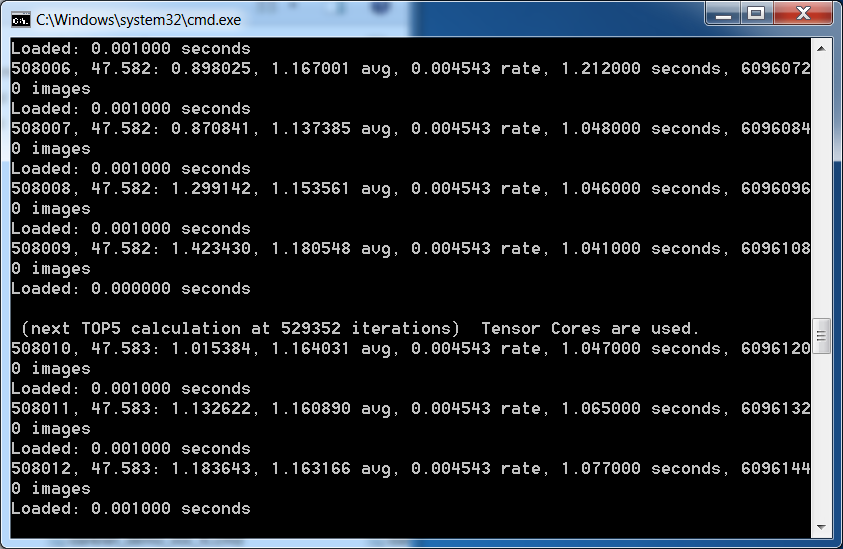
AlexeyAB
on 5 Jul 2019
@AlexeyAB
Let me put the data on SSD and start training again.
Will share you the details tomorrow.
dexception
on 5 Jul 2019
@AlexeyAB
Read Speed has increased from : 4.88 M/s to 32.84 M/s
6.7 Times increase in speed. :-)
Now if somebody wants to train on Open Images Dataset. Imagine the horror of buying 18TB SSD.

dexception
on 6 Jul 2019
@dexception About ~ $4K for 2 x 8 TB SSD: https://www.amazon.com/Intel-P4510-3-1x4-Solid-SSDPE2KX080T801/dp/B0782Q4CV9
AlexeyAB
on 6 Jul 2019
@AlexeyAB
So if we train an EfficientNet-B0 model on OpenImages and then use it as pretrained weights, would it not give better accuracy on than a pretrained model that was trained on imagenet ? There must be some difference ? Right ? What world be that difference ? Would it better or worse ?
dexception
on 7 Jul 2019
@dexception
ImageNet contains about 1.3 million images for Classification - 0.14 TB (140 GB).
Google Open Images dataset contains over 30 million images and 15 million bounding boxes for Detection - 18 TB (18 000 GB).
So yes, its better to train the model on OpenImages.
I just don't know should we immediately train the Detector, or do we need to train the Classifier for some time, and then use this pre-trained weights for the Detector training.
Do you have 18 TB SSD and want to train on OpenImages?
AlexeyAB
on 7 Jul 2019
@AlexeyAB
Google Open Images dataset contains over 30 million images and 15 million bounding boxes for Detection - 18 TB (18 000 GB).
Is it necessary to take all classes? what about extracting some of them? I extracted 2 classes from openimage and size was about 20-30 GB
dreambit
on 7 Jul 2019
@dexception
- ImageNet contains about 1.3 million images for Classification - 0.14 TB (140 GB).
- Google Open Images dataset contains over 30 million images and 15 million bounding boxes for Detection - 18 TB (18 000 GB).
So yes, its better to train the model on OpenImages.
I just don't know should we immediately train the Detector, or do we need to train the Classifier for some time, and then use this pre-trained weights for the Detector training.Do you have 18 TB SSD and want to train on OpenImages?
Well the reason why i was asking question was that we are training our current models on darknet53 which is training on mscoco/imagenet ... so it would be better to use the pre trained weights from
https://pjreddie.com/media/files/yolov3-openimages.weights
This will prove the difference in terms of accuracy(if any) that we get. Then decide whether it is worth training any models on open-images.
If there is too much difference in accuracy then why not merge both datasets and then create pretrained models ? This is a topic that i have not seen discussed anywhere.
I don't have the hardware to train OpenImages right now. Even how time it would take to train such a big dataset ..couple of years on my RTX 2080TI. This is a job only TPU's can handle.
Lets have the EfficientNet-B0 model ready as a classifier first then work on object detection.
dexception
on 7 Jul 2019
@dexception @AlexeyAB really interesting work, excited to see what comes out.
I have a couple of questions / comments:
- Is any eventual Object Detector that comes out of this project likely to be very low FPS, at least for the time being? (Like in this result that found efficientnet-B0 based network more than an order of magnitude slower than darknet-tiny using this repo.) https://github.com/AlexeyAB/darknet/issues/3580
- Would openimages be inappropriate for training a classifier like efficientnet given that it principally contains complex scenes with many different classes in, rather than just one class per scene like in imagenet?
LukeAI
on 13 Jul 2019
@LukeAI
I am quite puzzled myself. It was last year since i opened the issue:
https://github.com/AlexeyAB/darknet/issues/1232
And since then i have evaluated more than 400 open source repositories and many many research papers. Many commercial implementations.
Apart from LBP for single class detection implementation from https://github.com/ShiqiYu/libfacedetection i haven't come across any open source implementation that is remotely close to the commercial offerings from various vendors. Yolov3-Tiny is still by far the best trade-off in terms of accuracy/speed/cost.
@AlexeyAB
Please correct me if i am wrong.
dexception
on 13 Jul 2019
@LukeAI
Is any eventual Object Detector that comes out of this project likely to be very low FPS, at least for the time being? (Like in this result that found efficientnet-B0 based network more than an order of magnitude slower than darknet-tiny using this repo.) #3580
I don't unserstand, do you want to find very slow Detector? )
Would openimages be inappropriate for training a classifier like efficientnet given that it principally contains complex scenes with many different classes in, rather than just one class per scene like in imagenet?
I don't know.
I can propose, that it would be better to train Classifier EfficientNet on ImageNet (0.13 TB), and the train Detector-basedon-EfficientNet on OpenImages 18 TB.
AlexeyAB
on 13 Jul 2019
@dexception
Did you train EfficientNetB0 for 1 M - 1.6 M iterations and what Top1/5 accuracy did you get?
Yes, Yolov3 and tiny are the best models, just we should make something like v4 with new features: SPP + PAN2 + GIoU + scales_x_y + Assisted Excitation of Activations + squeeze_n_excitation + swish_activation + corner_head.
Apart from LBP for single class detection implementation from https://github.com/ShiqiYu/libfacedetection i haven't come across any open source implementation that is remotely close to the commercial offerings from various vendors. Yolov3-Tiny is still by far the best trade-off in terms of accuracy/speed/cost.
Yes, old approaches LBP, DFM, HaarCascades... are fast but can detect only 1 object only from 1 side with ~the same exposure, tilt, rotation ....
In all object detection challengaes (PascalVOC, OpenImages, MS COCO, ImageNet, Kitty, Cityscapes,...) the winners are Deep Learning models in all places, all last 4 years.
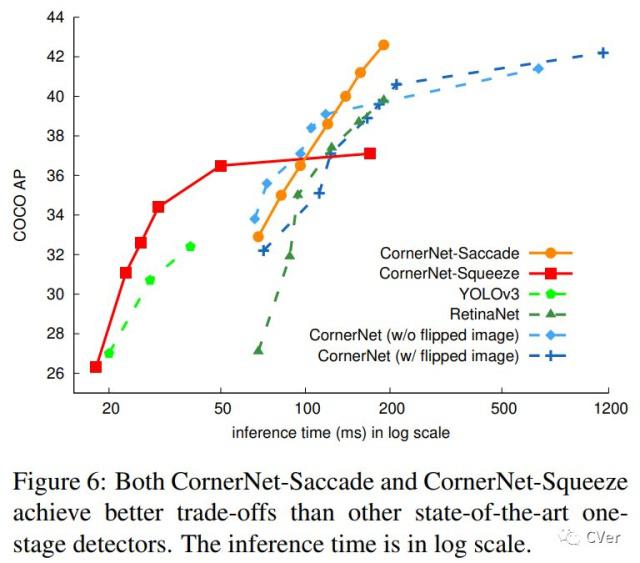
In terms of inference time, Yolov3-tiny and Yolov3 are the optimal models may be except CornerNet
(but we should compare Yolov3 + SPP + PAN2 + GIoU + scales_x_y + Assisted Excitation of Activations vs CornerNet, may be we should use [corner]-layer-head instead of [yolo]-layer-head):
In terms of BFLOPS, the best model EfficientNet, but it isn't the fastest until there will be mainstream hardware devices with very fast depthwise-convolutional layer processing:
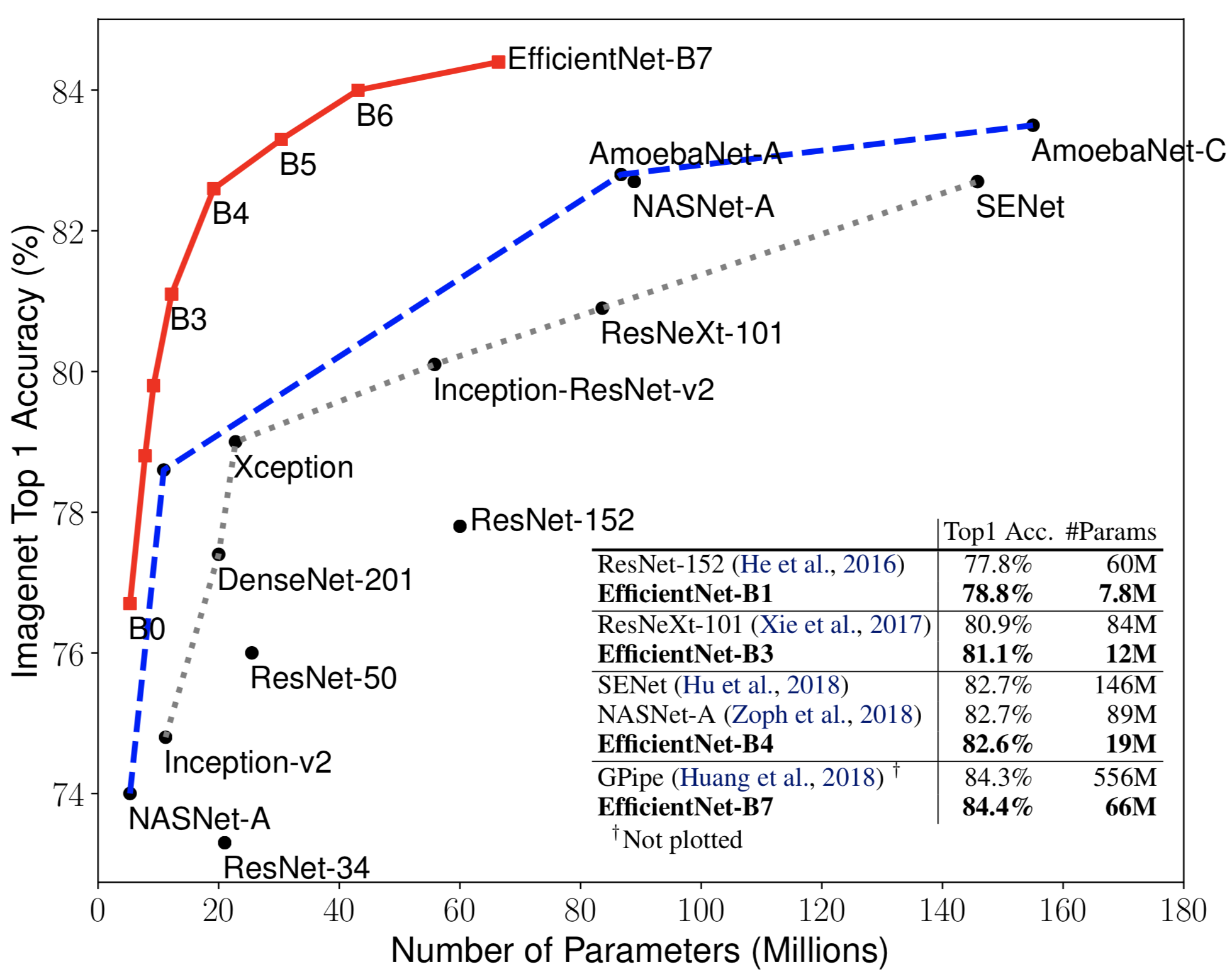
AlexeyAB
on 13 Jul 2019
I don't unserstand, do you want to find very slow Detector? )
No, of course not... I'm just wondering if this efficientnet/yolo project has any near-future potential to become a high AP realtime OD algoirithm on GPUs.
I can propose, that it would be better to train Classifier EfficientNet on ImageNet (0.13 TB), and the train Detector-basedon-EfficientNet on OpenImages 18 TB.
This sounds very sensible. Just want to point out that 18 TB is the entire dataset. Only a subset of Openimages is actually annotated with bounding boxes and that weighs in at 561 GB uncompressed (see here
Yes, Yolov3 and tiny are the best models, just we should make something like v4 with new features: SPP + PAN2 + GIoU + scales_x_y + Assisted Excitation of Activations + squeeze_n_excitation + swish_activation + corner_head.
Sounds great. I want to contribute if I can. Even if that's just running experiments. My findings on the above points seem to indicate that SPP is unambiguously better (as everybody knows by now), PAN2 helps a little (although does slow things down - difficult to say if the trade is unambiguously worth it), Swish helps a little and is essentially no cost. Don't really know about the other stuff.
I want to train a Darknet53 network with swish activations on Imagenet so that we have a starting point of pre-trained weights to run other experiments from. Efficientnet looks like it has more long term potential but perhaps not on currently existing GPUs?
- Are there any other large single class datasets that you know of that I could throw in with Imagenet to get even more breadth and diversity?
- What resolution should I train at? PJ Reddie uses 448 x 448 with letterboxing in his highest performing darknet53 but presumably higher resolution would give better weights for training higher resolution ODs? I'm also unsure if I should be cropping, letterboxing or distorting. Would appreciate any thoughts?
LukeAI
on 14 Jul 2019
I've just been checking out some of the human-verified image-level only images from openimages Here are the first five from the training set:
https://c7.staticflickr.com/6/5499/10245691204_98dce75b5a_o.jpg
https://farm1.staticflickr.com/5615/15335861457_ec2be7a54e_o.jpg
https://c7.staticflickr.com/8/7590/17048042861_97168daff8_o.jpg
https://farm5.staticflickr.com/5582/18233009494_029b52ca79_o.jpg
https://farm6.staticflickr.com/4126/5145819744_b4a7871064_o.jpg
Possibly we could download just those images that have only one kind of class label? And then train a classifier on imagenet, openimages, imagenet + openimages - and then train an OD on all three starting weights on some different dataset to see how much, if any, difference it makes?
LukeAI
on 14 Jul 2019
@AlexeyAB
I was assigned other work and since i only have one GPU to work with i had to stop training and will resume once i am finished with new assignment. I guess we all know how software industry works. :-)
Its crazy sometimes.
I am going to share my real life practical experience with you and going to be quite blunt about it :-)
Your missing the point when i am talking this repo https://github.com/ShiqiYu/libfacedetection
The default opencv implementation of LBP is not that fast. There are huge performance improvements in his code. I am just wondering whether certain C optimizations can give a boost or not.
As long as we are using fully connected layers i doubt we will have any improvements in yolov3-tiny's inference time. Activation function also needs to be replaced. Please refer to 3.1 section of this paper:
Compact Convolutional Neural Network Cascade
https://arxiv.org/pdf/1508.01292
just we should make something like v4 with new features: SPP + PAN2 + GIoU + scales_x_y + Assisted Excitation of Activations + squeeze_n_excitation + swish_activation + corner_head.
As long as it doesn't increase the computations in the network and doesn't increase the cost of the overall machine.
Int8 Quantization
Couple of months back i did a comparison between TensorRT yolo quantization vs yolov2_light repo.
https://github.com/AlexeyAB/yolo2_light/issues/51
TensorRT quantization is way better but still the accuracy that they claim in the papers is not even close.
Please refer to this issue:
https://devtalk.nvidia.com/default/topic/1050874/tensorrt/int8-calibration-is-not-accurate-see-image-diff-with-and-without/post/5354732/#5354732
I guess yolov2_light's quantization needs a calibration table, the way Nvidia is doing it.
Improvements
I would love to have the option of having an 8 point coordinate(x1,y1,x2,y2,x3,y3,x4,y4).
Increasing possibilities of using it as a text detector and on satellite images.
Also for weapon detection this would help because when your tagging images often hand is major part of the 7 shape of the gun. So when your using it it real life if somebody is sitting with his hands folded, or shaking hands or holding a mobile phone or a cup there are false alerts since hand was part of the tagging. And daily we get about 50 false alerts in production from a single camera.
Cost
Imagine my horror when somebody says you need to monitor 2 security cameras on i5 without GPU. They want everything from Person Detection to a bunch of 10 other things. But i tell them i need a GPU and the cost goes up 4 times per camera.
So the point is that, this darknet repo is the best real time object detection repo but we are missing the above points and we should focus on keeping this repo the best real time object detection repo.
@LukeAI
In theory we all agree adding more data will increase the accuracy so its just a matter of getting hardware. So its a long term thing since none of us have access to huge machines.
dexception
on 14 Jul 2019
What is the inference time for efficientnet B0 on a high end cpu?
LukeAI
on 14 Jul 2019
What is the inference time for efficientnet B0 on a high end cpu?
Took the latest clone of the repo 2 minutes ago.
Ran on my laptop with 2 GB 940 MX GPU memory
Ran this 10 times. The time is consistent.
GPU Time:
darknet.exe classifier predict cfg/imagenet1k.data cfg/efficientnet_b0.cfg efficientnet_b0_last.weights data/eagle.jpg
data/eagle.jpg: Predicted in 0.251000 seconds.
Darknet19
darknet.exe classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights data/eagle.jpg
data/eagle.jpg: Predicted in 0.025000 seconds.
Darknet53
darknet.exe classifier predict cfg/imagenet1k.data cfg/darknet53.cfg darknet53.weights data/eagle.jpg
data/eagle.jpg: Predicted in 0.054000 seconds.
Thanks! What about if you run on CPU?
LukeAI
on 14 Jul 2019
Processor used:

CPU Timings:
darknet_no_gpu.exe classifier predict cfg/imagenet1k.data cfg/efficientnet_b0.cfg efficientnet_b0_last.weights data/eagle.jpg
Used AVX
Used FMA & AVX2
data/eagle.jpg: Predicted in 0.216000 seconds.
Darknet19
darknet_no_gpu.exe classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights data/eagle.jpg
Used AVX
Used FMA & AVX2
data/eagle.jpg: Predicted in 0.162000 seconds.
Darknet53
darknet_no_gpu.exe classifier predict cfg/imagenet1k.data cfg/darknet53.cfg darknet53.weights data/eagle.jpg
Used AVX
Used FMA & AVX2
data/eagle.jpg: Predicted in 0.494000 seconds.
@dexception
As long as we are using fully connected layers i doubt we will have any improvements in yolov3-tiny's inference time. Activation function also needs to be replaced. Please refer to 3.1 section of this paper:
Compact Convolutional Neural Network Cascade
https://arxiv.org/pdf/1508.01292
What do you mean?
Yolov3-tiny, Yolov3, Yolov2-tiny, Yolov2 - don't use fully connected layers.
As long as it doesn't increase the computations in the network and doesn't increase the cost of the overall machine.
GIoU + scales_x_y + Assisted Excitation of Activations + corner_head- don't increase inference timeSPP + PAN2 + squeeze_n_excitation + swish_activation- increase inference timy slightly, but much improves accuracy. There is no point in thinking only about accuracy or only execution time. You must be on the pareto optimality curve.
For example, just assuming, even if SPP + PAN2 greatly increases the execution time, but allows you to go to a more optimal Pareto-curve, then we can simply reduce the network resolution or the number of layers and we will get better accuracy with less execution time.
Couple of months back i did a comparison between TensorRT yolo quantization vs yolov2_light repo.
AlexeyAB/yolo2_light#51
TensorRT quantization is way better but still the accuracy that they claim in the papers is not even close.
Please refer to this issue:
https://devtalk.nvidia.com/default/topic/1050874/tensorrt/int8-calibration-is-not-accurate-see-image-diff-with-and-without/post/5354732/#5354732
I guess yolov2_light's quantization needs a calibration table, the way Nvidia is doing it.
What does it mean - better? Does it have higher mAP or less inference time, or both?
I do it based on this presentation by using KL_divergence with saturation http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf there is nothing about calibration table, what do you mean?
Currently OpenCV-dnn is the fastest module to run Yolov3 and Yolov3-tiny on CPU in real-time.
I am also working on implementing Yolo v3 on a chip Intel Myriad X (NCS2), so currently it can process Yolov3-tiny 20 FPS on Intel Atom CPU + Intel Myriad X (1 watt - 100$).
AlexeyAB
on 14 Jul 2019
@LukeAI
I can try to implement Darknet53 with swish-activation + squeeze_n_excitation_blocks, so you can try to train it on ImageNet for 1 - 1.6 M iterations on ImageNet + Stylized ImageNet.
If I will have a time. You can just now try to train Darknet53 + swish-activation.
Are there any other large single class datasets that you know of that I could throw in with Imagenet to get even more breadth and diversity?
I would recommend you to train this Classifier on ImageNet + Stylized ImageNet - it gives + several % of Top1:
- how to create Stylized ImageNet: https://github.com/rgeirhos/Stylized-ImageNet
- just to know: https://github.com/rgeirhos/texture-vs-shape
Joseph Redmon trained Darknet53 on 256x256 resolution for 800K iterations https://github.com/pjreddie/darknet/blob/master/cfg/darknet53.cfg#L10-L11
And only then change network resolution to 448x448 and continue training for 100K iterations https://github.com/pjreddie/darknet/blob/master/cfg/darknet53_448.cfg#L10-L11
No, of course not... I'm just wondering if this efficientnet/yolo project has any near-future potential to become a high AP realtime OD algoirithm on GPUs.
Every two years, the performance of the GPU and the CPU increases, neurochips (Intel Myriad X) or built-in neurochips appear in smartphones. So with all these improvements, yes - Yolo-v3 will be the most accurate with the same speed and the fastest with the same accuracy of all universal detection algorithms.
AlexeyAB
on 14 Jul 2019
@AlexeyAB
https://github.com/NVIDIA-AI-IOT/deepstream_reference_apps/blob/master/yolo/README.md
Once you do calibration on a dataset a calibration table is generated and this used for inference.
This dataset can be same to one one which you have trained your model.
Please go through the app and see the inference time which is quite similar to yolo2_light but way more accurate than yolo2_light repo. Infact nearly twice as more accurate in some cases.
Fully Connected Layers
I know yolov2, yolov3 doesn't use fully connected layers. Quote from the article :
the lack of fully-connected layer gives a 50% increase in speed of a forward propagation procedure.
I was referring to the approach in the article.
https://arxiv.org/pdf/1508.01292
Yolov4-Tiny [Future Release]
A faster and more accurate version of Yolov3-Tiny.
Please share a cfg file with darknet19 + swish-activation + squeeze_n_excitation_blocks
NCS2
I have also tried the Intel Neural Computing Stick V2. Can't reveal much about it. As it is still buggy.
So waiting for the next release.
@LukeAI
EfficientNet-B0
Given the inference time tested using cudnn 7.6.1(latest as of today). I understand that the FP16 implementation of depthwise-conv is different from fp32. So the inference time would be faster with CUDNN_HALF. Nvidia has promised to improve it in future on fp32.
Efficient-NetB0 will be faster than darknet53 on CPU. Almost twice as fast.
So it is not completely useless.
dexception
on 14 Jul 2019
@dexception
Once you do calibration on a dataset a calibration table is generated and this used for inference.
This dataset can be same to one one which you have trained your model.
It seems it is something like this: https://github.com/AlexeyAB/yolo2_light/blob/master/bin/yolov3-tiny.cfg#L25
Please go through the app and see the inference time which is quite similar to yolo2_light but way more accurate than yolo2_light repo. Infact nearly twice as more accurate in some cases.
What mAP did you get in both cases?
What dataset did you use?
I have also tried the Intel Neural Computing Stick V2. Can't reveal much about it. As it is still buggy.
So waiting for the next release.
Yes, we are waiting for bug fixes.
They promise to fix several bugs and implement fast async implementation of Yolov3 on NCS2 by using OpenCV-dnn with OpenVINO backend: https://github.com/opencv/opencv/issues/15023#issuecomment-510845216
With --async=3 it should work with the highest FPS in new OpenCV and new OpenVINO libraries: https://github.com/opencv/opencv/pull/14516
AlexeyAB
on 14 Jul 2019
@AlexeyAB
Dataset : photos from social media+google images
Yolov3-Tiny mAP: 80%
I did't compare the actual mAP from TensorRT with Yolov2_light after quantization but TensorRT one was better. The case with yolo2_light quantization is quite similar to the once i also discussed with you while comparing yolov3-tiny with yolov3-tiny-xnor.
https://github.com/AlexeyAB/darknet/issues/2605
We discussed that the bounding boxes are not accurate even though they might give decent [email protected]
TensorRT quantization.
TensorRT quantization is generated for a specific dataset that results in higher mAP. Can you share how you came up with the calibration in the cfg file ? Is there a way to generate it on a dataset and then copy paste it in the cfg file ?
Waiting for your inputs regarding:
- darknet19 + swish-activation + squeeze_n_excitation_blocks.
- Rotated Rectangle with 8 point coordinate(x1,y1,x2,y2,x3,y3,x4,y4) based yolov3-tiny, yolov3
dexception
on 14 Jul 2019
@dexception
We discussed that the bounding boxes are not accurate even though they might give decent [email protected]
TensorRT quantization.
Without exact [email protected] values on the same dataset we can't say that one model is better than other, because one model can have higher mAP but can require lower confidence-threshold, so with the same
-thresh 0.25it will have lower TP, but with lower threshold-thresh 0.15it can have more TP.If you are worried about more accurate bboxes, you should compare [email protected] or @0.90 instead of @0.5
Also it is a bad practice - visual compariosn of the models just by few images. So mAP comparison is required on validation dataset with several thousand images.
TensorRT quantization is generated for a specific dataset that results in higher mAP. Can you share how you came up with the calibration in the cfg file ? Is there a way to generate it on a dataset and then copy paste it in the cfg file ?
./darknet detector calibrate obj.data tiny-yolo-voc.cfg tiny-yolo-voc.weights -input_calibration 100 it will calibrate the model on training dataset from obj.data file for the first 100 images.
and will create input_calibration.txt file with input_calibration = 15.7342, 4.41852, 9.17237, 9.70713, 13.1849, 14.9823, 15.1913, 8.62978, 15.7353, 15.6297, 15.6939, 15.4093, 15.8055, 16 params which you should copy paste to the [net] section in used cfg-file.
But default input_calibration params in yolov3.cfg/tiny seems works better. Just use lower threshold.
But I'm not sure that quantization before int8 after learning is generally a good idea. Perhaps it is required training int8. Or may be XNOR-net is better.
AlexeyAB
on 14 Jul 2019
What is this calibration?
LukeAI
on 14 Jul 2019
@dexception
EfficientNet-B0
Given the inference time tested using cudnn 7.6.1(latest as of today). I understand that the FP16 implementation of depthwise-conv is different from fp32. So the inference time would be faster with CUDNN_HALF. Nvidia has promised to improve it in future on fp32.
Efficient-NetB0 will be faster than darknet53 on CPU. Almost twice as fast.
So it is not completely useless.
@AlexeyAB
* **EfficientNet B0** (224x224) 0.9 BFLOPS - 0.45 B_FMA (16ms / RTX 2070): [efficientnet_b0.cfg.txt](https://github.com/AlexeyAB/darknet/files/3336187/efficientnet_b0.cfg.txt) - **2.5 days** * **EfficientNet B0 XNOR** (224x224) 0.8 BFLOPS + 25 BOPS (18ms / RTX 2070): [efficientnet_b0_xnor.cfg.txt](https://github.com/AlexeyAB/darknet/files/3342957/efficientnet_b0_xnor.cfg.txt) - **5 days** * **EfficientNet B3** (288x288) 3.5 BFLOPS - 1.8 B_FMA (28ms/RTX 2070): [efficientnet_b3.cfg.txt](https://github.com/AlexeyAB/darknet/files/3340717/efficientnet_b3.cfg.txt) - **11 days** * **EfficientNet B3** (320x320) 4.3 BFLOPS - 2.2 B_FMA (30ms/RTX 2070): [efficientnet_b3_320.cfg.txt](https://github.com/AlexeyAB/darknet/files/3340753/efficientnet_b3_320.cfg.txt) - **14 days** * **EfficientNet B4** (384x384) 10.2 BFLOPS - 5.1 B_FMA (46ms/RTX 2070): [efficientnet_b4.cfg.txt](https://github.com/AlexeyAB/darknet/files/3340718/efficientnet_b4.cfg.txt) - **26 days**
I'm a little confused! So efficientnet is really slow only if using fp32? Were these impressive inference times achieved using CUDNN_HALF ?
LukeAI
on 14 Jul 2019
**Output from RTX 2080 TI**
Cuda 10
CUDNN 7.5.0
CUDA allocate done!
224 224
data/eagle.jpg: Predicted in 0.003562 seconds.
**Output from GTX 1050 TI**
CUDA : 9.0
CUDNN: 7.6.1
CUDA allocate done!
224 224
data/eagle.jpg: Predicted in 0.113574 seconds.
**Output from GTX 1060**
CUDA 10.0
CUDNN 7.5.0
CUDA allocate done!
224 224
data/eagle.jpg: Predicted in 0.129041 seconds.
@AlexeyAB I used your 500k model for efficientnet-b0 weights to resume training and after the weights were saved, ran the following command the mAP dropped.
./darknet classifier valid cfg/imagenet1k.data cfg/efficientnet_b0.cfg efficientnet_b0_last.weights
top 1: 0.317949, top 5: 0.533333
dexception
on 19 Jul 2019
@AlexeyAB
Can you clarify what is going on ?
Because i have trained the model till 500k and there seems to be a huge difference your accuracy and my accuracy ? Is it because you have train a model continuously and should not resume in between ?
dexception
on 20 Jul 2019
@dexception
I resumed training several times.
It is because I used other learning rate and policy. You should train 1.6M iterations.
AlexeyAB
on 20 Jul 2019
@AlexeyAB
The model is in training mode. Its has reached 600k.
I will share the model when it reaches 1.6 million.
dexception
on 21 Jul 2019
Hello,
I have checked the code of new operations, some bugs are listed below:
avgpool layer
Originally, avgpool layer is designed for using in the last layer of classifier.
If there is an avgpool layer, resize_network will break.
https://github.com/AlexeyAB/darknet/blob/master/src/network.c#L550scale_channels layer
scale_channels layer usually has size equal to 1x1xc, but it should resize the output equal to the size of "from" layer.
https://github.com/AlexeyAB/darknet/blob/master/src/scale_channels_layer.c#L42-L58
I think it should be similar to the resize function of route layer.
https://github.com/AlexeyAB/darknet/blob/master/src/route_layer.c#L39convolutional layer with swish activation function
swish activation function is seen as a special case in convolutional layer.some code I am not sure will have problem
scale_channels layer is not listed in get_layer_string function.
https://github.com/AlexeyAB/darknet/blob/master/src/network.c#L172-L223
And above bugs may get error when training a detector.
(CUDNN_STATUS_EXECUTION_FAILED, illegal memory access, illegal instruction was encountered...)
I have tried:
- CUDA 8 + TITAN X
- CUDA 8 + 1080 ti
- CUDA 9 + 1080 ti
- CUDA 9 + TITAN X (Pascal)
- CUDA 10 + 1080
- CUDA 10 + 2080 ti
- CUDA 10 + TITAN X (Pascal)
All of these get errors.
WongKinYiu
on 24 Jul 2019
@AlexeyAB
Should i stop training ?
dexception
on 25 Jul 2019
@dexception How many iterations and TopK do you get currently?
AlexeyAB
on 25 Jul 2019
share my result.
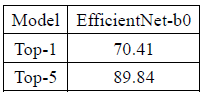
WongKinYiu
on 25 Jul 2019
@WongKinYiu How many iterations did you train?
AlexeyAB
on 25 Jul 2019
@WongKinYiu How many iterations did you train?
600k only.
WongKinYiu
on 25 Jul 2019
@WongKinYiu You should train 1M - 1.6M iterations
https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-511189891
AlexeyAB
on 25 Jul 2019
@WongKinYiu You should train 1M - 1.6M iterations
#3380 (comment)
Because currently I can not use EfficientNet_b0 as backbone of the detector, so I stop training.
(Training depthwise convolutional layer takes looooooooooooong time.)
Could you provide cfg file of EfficientNet_b0 with learning rate policy for 1.6M iterations?
I will get available GPU next Tuesday, then I can train it.
WongKinYiu
on 25 Jul 2019
@WongKinYiu
EfficientNet_b0 with learning rate policy for 1.6M iterations: https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-501263052
AlexeyAB
on 25 Jul 2019
@WongKinYiu
EfficientNet_b0 with learning rate policy for 1.6M iterations: #3380 (comment)
got it, thank you.
WongKinYiu
on 25 Jul 2019
@AlexeyAB
That is strange .. i am not getting the same accuracy as @WongKinYiu
@WongKinYiu
Can you share your cfg file which you trained for 600k iterations ?
My Results:
efficientnet_b0_729100.weights
Used https://github.com/AlexeyAB/darknet/files/3336187/efficientnet_b0.cfg.txt
top 1: 0.546160, top 5: 0.799100
dexception
on 25 Jul 2019
@dexception
I use this cfg file.
https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-503746180
WongKinYiu
on 25 Jul 2019
@WongKinYiu
Got it ..there is a policy difference.
@AlexeyAB
Are you sure 1.6 million iterations are enough ?
dexception
on 25 Jul 2019
Here is the link for the currently trained model:
Results:
efficientnet_b0_729100.weights
Used https://github.com/AlexeyAB/darknet/files/3336187/efficientnet_b0.cfg.txt
top 1: 0.546160, top 5: 0.799100
https://drive.google.com/open?id=1vYRmFjYgCMdt3f9XTebjf_kU9_qb-Z_Y
dexception
on 25 Jul 2019
@dexception
Are you sure 1.6 million iterations are enough ?
I think yes. Just try to train 1.6m.
AlexeyAB
on 25 Jul 2019
Although I can not train the detector contains conv+swish & squeeze-and-excitation layers with random=1,
I get 42.2% [email protected] with 2.6 BFLOPs on COCO test-dev (random=0).
(YOLOv3-tiny get 33.1% [email protected] with 5.6 BFLOPs)
If the bugs are fixed, I think it may get better performance than CenterNet based methods.
WongKinYiu
on 26 Jul 2019
@WongKinYiu Can you share your cfg-file for Detector (2.6 BFLOPS)?
Is it based on efficientnet_b0.cfg.txt ?
AlexeyAB
on 26 Jul 2019
@WongKinYiu Can you share your cfg-file for Detector (2.6 BFLOPS)?
Is it based on efficientnet_b0.cfg.txt ?
No, it is not based on efficientnet_b0.
I found that the performance of efficientnet_b0 with leaky ReLU and swish activation function have large gap.
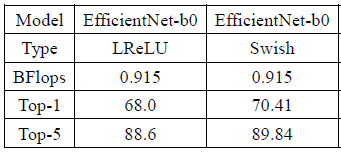
So I change the activation function of my proposed architecture.
I use image size=320*320 for testing, so the computation cost is 2.6 BFLOPs.
The network has more than 300 layers in cfg file.
Even though it only has 2.6 BFLOPs, its inference time is 2~3 times than YOLOv3-tiny on GPU. (~0.8 times on CPU)
The paper is under writing.
If you need cfg file, I can send it to you, but please do not share it before my paper is published.
If you don't need cfg file, I can share you my experiments for implementing state-of-the-art methods.
For example, https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-503780307 .
WongKinYiu
on 26 Jul 2019
@WongKinYiu Yes, please send me cfg-file: [email protected]
Did you change source coda of Darknet framework to implement CEM + SAM?
I found that the performance of efficientnet_b0 with leaky ReLU and swish activation function have large gap.
Did you train it 600k iterations?
AlexeyAB
on 26 Jul 2019
@AlexeyAB
I do not change source code for the model which get 42.2% [email protected] with 2.6 BFLOPs.
But for supporting SAM module, yes.
I change the scale channels layer from 1 * 1 * c to w * h * c.
(I am not familiar to add new layer on darknet, so I modify existed layer.)
squeeze-and-excitation = avgpool + conv + scale_channels
SAM = conv + scale_maps
Yes, both of EfficientNet-b0 with leaky ReLU and swish activation function trained 600k iterations.
Here are the stat-of-the-art methods I have implemented.
(Some of them are borrowed from your cfg files.)
- Yolov3: An incremental improvement.
- Feature pyramid networks for object detection.
- Path aggregation network for instance segmentation.
- Sparsely Aggregated Convolutional Networks.
- Spatial pyramid pooling in deep convolutional networks for visual recognition.
- ThunderNet: Towards Real-time Generic Object Detection.
- Pelee: A real-time object detection system on mobile devices.
- Tiny-DSOD: Lightweight Object Detection for Resource Restricted Usage.
- Scale-Aware Trident Networks for Object Detection.
- DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection.
- Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression.
- Bag of Freebies for Training Object Detection Neural Networks.
3, 4, 5, 6 make obvious improvement of mAP.
11 get impressive performance on [email protected]:0.95.
12 can not get good results on lightweight models.
WongKinYiu
on 27 Jul 2019
@WongKinYiu would you consider sending me your detector .cfg ? I have access to an array of GPUs and I'd been happy to train on a few standard datasets and send you the results. I'd love to study the .cfg and I'd be happy to keep secret until you are ready to release. ezekiel.incorrigible at gmail.com
LukeAI
on 30 Jul 2019
2.2 BFLOPs, 41.0 [email protected] on COCO test-dev.
WongKinYiu
on 1 Aug 2019
@AlexeyAB
Any update ?
dexception
on 3 Aug 2019
@WongKinYiu very exciting! did you do pretraining on imagenet for the feature extractor? do you have any pretrained weights?
LukeAI
on 7 Aug 2019
@hwijune u can just replace all swish to leaky.
@LukeAI i use the imagenet pretrained model from https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-503746180
WongKinYiu
on 7 Aug 2019
ah I see!
I note that there are two yolo layers and it's configured for 80 classes. How can I change it to be configured for a different number of classes in my custom dataset? (I'll share my results for comparison)
LukeAI
on 7 Aug 2019
Please follow https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
for 80 classes, the number of filters of convolutional layer before yolo layer is (classes + coordinates + confidence)masks = (80 + 4 + 1)3 = 255
WongKinYiu
on 7 Aug 2019
Thanks @WongKinYiu
Did you try with scale_x_y in the yolo layers? https://github.com/AlexeyAB/darknet/issues/3691
Did you try with 3 yolo layers on the head instead of just 2?
If not, if I have the GPU time I'll try running some experiments like that.
LukeAI
on 7 Aug 2019
@LukeAI for this model, i do not try those method.
for other lightweight models, scale_x_y improve about 0.2% mAP.
3 yolo layers improve about 1% mAP.
better head (such as panet) improve about 1% mAP.
WongKinYiu
on 7 Aug 2019
EfficientNet for edge computing.
https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu
WongKinYiu
on 8 Aug 2019
@AlexeyAB
update results.
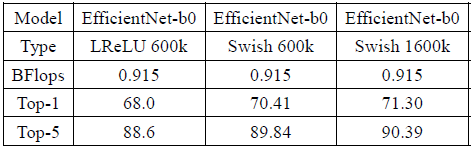
WongKinYiu
on 9 Aug 2019
@WongKinYiu Hi,
Can you share weights file for 71.3% Top1 by using Google-disk?
It seems that we miss something in Efficientnet-b0, so we get only Top1 71.3% instead of 76.3%.
At least there is one difference, we use DropOut instead of DropConnect.
AlexeyAB
on 9 Aug 2019
@AlexeyAB Hello,
I've sent the weight file to you.
You can share the weight file by Google-disk.
Thank you.
WongKinYiu
on 11 Aug 2019
@dexception Yes, with DropOut instead of DropConnect we can achieve only Top1 71.3% instead of 76.3%. Also may be there are still other differences.
71.3% Top1 accuracy:
AlexeyAB
on 14 Aug 2019
3.7 BFLOPs, 45.0 [email protected] on COCO test-dev.
cfg-file: enet-coco.cfg.txt
weights file: https://drive.google.com/open?id=1FlHeQjWEQVJt0ay1PVsiuuMzmtNyv36m
AlexeyAB
on 15 Aug 2019
can i convert enet to caffe?? this repository(https://github.com/marvis/pytorch-caffe-darknet-convert) is not support logistic activation
 Hwijune
on 16 Aug 2019
Hwijune
on 16 Aug 2019
is it possible to use Efficient-Net B0 instead of darknet53.conv74 for object detection related task?
 varghesealex90
on 21 Aug 2019
varghesealex90
on 21 Aug 2019
@AlexeyAB
I am asking a relevant question here.
If i want to use https://github.com/AlexeyAB/darknet/files/3504727/enet-coco.cfg.txt
and https://drive.google.com/open?id=1FlHeQjWEQVJt0ay1PVsiuuMzmtNyv36m
as pretrained weights. What is the command to fetch the pretrained layers and use them to train our own models ?
Please reply.
 jamessmith90
on 22 Aug 2019
jamessmith90
on 22 Aug 2019
Is it possible to have a lighter version of Efficientnet-b0 ?
Like darknet 19 is available for darknet53 but is faster ?
 suman-19
on 22 Aug 2019
suman-19
on 22 Aug 2019
@AlexeyAB
I might be wrong here but since your the expert i ran the enetb0-coco_final.weights for inference on RTX 2080 TI.
43% GPU Usage
25 FPS on 416x416 Resolution.
1167 MB GPU Memory
This is not efficient by any stretch of imagination. It is taking too many cuda cores.
Please check this.
dexception
on 22 Aug 2019
@dexception
EfficientNet only efficient on CPU.
If you want to use GPU, please check https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-519491383
They remove swish, SE, and depth-wise convolution.
WongKinYiu
on 22 Aug 2019
@jamessmith90
using "darknet.exe partial enet-coco.cfg.txt enet-coco.weights enet-coco.conv.131 131"
WongKinYiu
on 22 Aug 2019
Anybody could share some prototxt of caffe version Efficient model file?
 jinfagang
on 22 Aug 2019
jinfagang
on 22 Aug 2019
@dexception
I might be wrong here but since your the expert i ran the enetb0-coco_final.weights for inference on RTX 2080 TI.
43% GPU Usage
25 FPS on 416x416 Resolution.
1167 MB GPU MemoryThis is not efficient by any stretch of imagination. It is taking too many cuda cores.
Please check this.
Do you mean "too many" or "too few - only 43%" cuda cores?
EfficientNet is efficient only in terms FLOPS/Accuracy but not in terms FPS/Accuracy, at least on GPU.
May be it is efficient on TPU ($1M Google device).
AlexeyAB
on 22 Aug 2019
I meant too many cuda cores. I just want a scalable architecture. I had high hopes for this since it was accurate and fast. Now all hopes are on using pruning with yolov3/yolov3-tiny. No longer interested in Efficientnet. It would be too expensive in a production environment.
dexception
on 23 Aug 2019
Does there any support for caffe?
jinfagang
on 23 Aug 2019
What makes efficientnet slow on the GPU?
 gnefihs
on 6 Sep 2019
gnefihs
on 6 Sep 2019
@gnefihs
What makes efficientnet slow on the GPU?
Depth-wise convolutional
AlexeyAB
on 6 Sep 2019
@AlexeyAB
Is there a possibility where we can replace depthwise conv with something else ?
dexception
on 12 Sep 2019
this paper might be relevant:
Diagonalwise Refactorization: An Efficient Training Method for Depthwise Convolutions
https://arxiv.org/pdf/1803.09926.pdf
Our key idea is to
rearrange the weight vectors of a depthwise convolution into
a large diagonal weight matrix so as to convert the depthwise
convolution into one single standard convolution, which is well
supported by the cuDNN library that is highly-optimized for GPU
computations. We have implemented our training method in five
popular deep learning frameworks. Evaluation results show that
our proposed method gains 15.4× training speedup on Darknet,
8.4× on Caffe, 5.4× on PyTorch, 3.5× on MXNet, and 1.4×
on TensorFlow, compared to their original implementations of
depthwise convolutions.
gnefihs
on 12 Sep 2019
@gnefihs @dexception
I added separate issue: https://github.com/AlexeyAB/darknet/issues/3908
Is there a possibility where we can replace depthwise conv with something else ?
There are several ways:
- remove
gourps=...to use common conv instead of depthwise-conv, it can be faster on GPU - remove
groups...and reduce number offilters=... - remove
groups=...and addxnor=1 - wait when nVidia will accelerate depth-wise conv in cuDNN.
AlexeyAB
on 12 Sep 2019
EfficientNet for edge computing.
https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu
There's also this approach of finding / using similar non-depth-wise operations
LukeAI
on 12 Sep 2019
@LukeAI Yes, juse remove groups=... in [convolutional] layers.
The model will be larger, but the speed will be higher.
AlexeyAB
on 12 Sep 2019
@AlexeyAB EfficientNet-EdgeTPU also remove squeeze-and-excitation and swish activation function.
"In addition, removing certain operations from the search space that require modifications to the Edge TPU compiler to fully support, such swish non-linearity and squeeze-and-excitation block, naturally leads to models that are readily ported to the Edge TPU hardware. These operations tend to improve model quality slightly, so by eliminating them from the search space, we have effectively instructed AutoML to discover alternate network architectures that may compensate for any potential loss in quality."
WongKinYiu
on 12 Sep 2019
@WongKinYiu Thanks. Did you try to train EfficientNet-EdgeTPU model?
Do they just remove
- squeeze-and-excitation block
- swish activation
And keep number of filters= the same as in original EfficientNet?
AlexeyAB
on 12 Sep 2019
@AlexeyAB No, EfficientNet-EdgeTPU is too big.
WongKinYiu
on 13 Sep 2019
The method in the paper "Diagonalwise Refactorization: An Efficient Training ..." pointed out in the comment by 'gnefihs' might be the most promising way, as it seems to be fast and preserves also the low memory usage of the EfficientNet backbone.
On the GPU, I would not worry too much about the speed of the 'swish' activation function as CUDA provides a very fast (approximate) 'exp' function.
 hfassold
on 13 Sep 2019
hfassold
on 13 Sep 2019
hi @hfassold, do you have more information on CUDA's exp function? I can't seem to find anything on it.
gnefihs
on 13 Sep 2019
Yes, for GPU, speed of the 'swish' is OK.
WongKinYiu
on 13 Sep 2019
@gnefihs: See https://stackoverflow.com/questions/7257843/cuda-exp-expf-and-expf
and https://devtalk.nvidia.com/default/topic/990115/cuda-programming-and-performance/a-more-accurate-performance-competitive-implementation-of-expf-/
(if one wants to implement it for other platforms efficiently - it seems to use a polynomial approximation)
hfassold
on 13 Sep 2019
Can we list down the complexity of each activation function along with different convolution algorithms and then decide the architecture ?
dexception
on 13 Sep 2019
I think EfficientNet-architecture in its standard variant (from the paper, with swish etc.) is fine on the GPU (especially the 'B3' or 'B4' variant could be a good default for replacing YoloV3-MSCoco-608), when you have a fast implementation of the depth-wise convolution operation (via a special CUDA kernel like done in Tensorflow or via the method described in the referenced paper) - see issue opened in https://github.com/AlexeyAB/darknet/issues/3908
Sticking with the standard variant wold have also the advantage that one can take a pre-trained EfficientNet-BX standard variant model (X= 0 - 7) in ONNX format and convert it to darknet format via a model converter like the one in https://github.com/minhoolee/onnx-darknet/blob/master/doc/API.md
Pretrained efficientnet models in MXNet format can be found at https://pypi.org/project/gluoncv2/
Via MXNet one can easily convert these to ONNX format.
hfassold
on 13 Sep 2019
@hfassold
Looks good..
dexception
on 13 Sep 2019
@hfassold
Can you post B0 / B4 models converted from MXNet to Darknet format there? https://github.com/AlexeyAB/darknet/issues/3874
AlexeyAB
on 13 Sep 2019
I am currently on travel and am back in the office in the last week of September.
I will try to convert the models then (the ones pretrained on ImageNet). If it is needed earlier, someone else has to volunteer.
hfassold
on 13 Sep 2019
dexception
on 13 Sep 2019
Using TVM, u can run state-of-the-art segmentation model on TX2 and get 178 FPS inference speed.
http://fastdepth.mit.edu/
For YOLOv3, u can check https://docs.tvm.ai/tutorials/frontend/from_darknet.html
WongKinYiu
on 13 Sep 2019
@AlexeyAB I removed the "groups" from enet-coco.cfg file and used the following command:
./al/darknet/darknet detect enet-coco-std.cfg enetb0-coco_final.weights data/dog.jpg
Here are few understandings:
1) enet-coco-std is similar to enet-coco.cfg except that groups have been removed in enet-coco-std.
2) Network with depth-wise convolution comprises of 3 Billion flops while network with standard comprises of 90 Billion FLOPS.
3) On the contrary, the time taken by depth-wise convolution e-NET was 177 ms, while the network with standard convolution taken approximately 40 ms. Yolov3 takes 18 ms. (GPU Tesla P100).
4) Looking at the predictions generated by the networks, the output of network with depth-wise convolution is good. I dont see any bounding boxes when I use enet with standard convolution. This might be probably because the mismatch between the model and cfg.
Are my findings/ understandings correct. Please comment
varghesealex90
on 17 Sep 2019
@varghesealex90 If you removed groups= then you should train the model from scratch.
- standard-conv works faster than grouped-conv on GPU
- standard-conv uses more weights-params than grouped-conv
AlexeyAB
on 17 Sep 2019
Update: I tried to convert the pre-trained EfficientNet models in GluonCV model zoo from MXNet format to ONNX (and then from ONNX to darknet). Unfortunately, it seems the MXNet ONNX exporter is missing a certain operator - see https://github.com/apache/incubator-mxnet/issues/16200
Another possibility would be pytorch -> ONNX (https://github.com/lukemelas/EfficientNet-PyTorch)
Unfortunately, also the other route (Pytorch model => Caffe model => Darknet model, with scripts from https://github.com/marvis/pytorch-caffe-darknet-convert) very likely will not work, because the respective github has not been updated the last two years - so the new ops / layers will not be supported.
So, for the moment I do not see any chance to convert one of the pre-trained models (from other frameworks) to Darknet format. Any suggestions ?
hfassold
on 18 Sep 2019
@AlexeyAB @dexception @gnefihs
I think the way forward is to stick for the moment with the Efficientnet-B0 model for which already a darknet model is available. We can see then how effective the performance optimizations of the depth-wise convolution operation are.
If one gets a reasonable performance, one still can train other Efficientnet model variants (B3, B4 e.g.) from scratch - directly in darknet of course. As the more powerful training algorithms (Adam, RMSProp) are not available there, one could simply do it brute force by employing more iterations / epochs. In our research group we will get next year (Q1 2020) a powerful 4-GPU workstation where we could do such stuff.
By the way: I noticed that the efficientnet models at https://pypi.org/project/gluoncv2/ seem to be not only the original variants (B0, B1, ...) , but there are also modified variants (B0b, B1b, ...). Actually, e.g. for B3 variant only the modified variant 'B3b' is available. These modified variants seem to be even better (compare e.g. 'B0' and 'B0b' in the top-1 error). The modified variant seems to come from tensorflow - anyone knows what these modified variants are - is there some paper for it ?
hfassold
on 20 Sep 2019
My guess is that the B*b weights are the ones mentioned here: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet trained with AutoAugment. They have the same number of params so I think they are the same network, different weights.
LukeAI
on 20 Sep 2019
Thanks for pointing out - here is the paper describing 'AutoAugment': https://arxiv.org/abs/1805.09501
hfassold
on 20 Sep 2019
I watched the video in the original post and skimmed the other posts here.
So it seems this is:
- An innovation in how to add layers to neural networks in an intelligent way to gain more accuracy and efficiency than old methods of adding layers and complexity at-random.
- Is only for image classification (not object detection). At least in the officially released models?
- Extremely efficient on CPU. Not accelerated well on GPU yet due to a few layers doing complex things.
- Seems like @AlexeyAB has made a detector version of it with 416x416 input image size? https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-501263052
- Seems like the detector version is almost half the BFLOPS of Tiny-YOLOv3 but higher mAP.
- Tiny-YOLOv3: 5.56 BFLOPS, 33.1 mAP on COCO test-dev. (According to pjreddie's website).
- ENet-COCO.cfg by Alexey on COCO test-dev: 3.7 BFLOPs, 45.0 [email protected] on COCO test-dev.
I have three questions:
- Does this net use any new features that will need to be added to the darknet core? Or is it all standard darknet/yolo layer types?
- Who made the detector version? Alexey? What tweaks were done to make a detector?
- How to do transfer learning with the detector version and its pre-trained weights?
 Bananaman
on 27 Sep 2019
Bananaman
on 27 Sep 2019
@VideoPlayerCode Your profile looks like it was made by Joseph Redmon. :-)
dexception
on 27 Sep 2019
@VideoPlayerCode Your profile looks like it was made by Joseph Redmon. :-)
Hahah. :-D
Bananaman
on 28 Sep 2019
@AlexeyAB Hello sir, could you please answer https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-535874518 someday if you have time? I had 3 pretty short questions about your ENet-COCO.cfg there. :-)
Bananaman
on 11 Oct 2019
@VideoPlayerCode
Does this net use any new features that will need to be added to the darknet core? Or is it all standard darknet/yolo layer types?
All these features (swish-activation, squeeze_n_excitation_blocks, ...) are added to this Darknet repository, so you should use https://github.com/AlexeyAB/darknet for EfficientNet
Who made the detector version? Alexey? What tweaks were done to make a detector?
@WongKinYiu trained enet-coco.cfg on MS COCO.
How to do transfer learning with the detector version and its pre-trained weights?
./darknet partial cfg/enet-coco.cfg enetb0-coco_final.weights enetb0.132 132
or
./darknet partial cfg/efficientnet_b0.cfg backup/efficientnet_b0_last.weights enetb0.132 132
and train
./darknet detector train cfg/coco.data cfg/enet-coco.cfg enetb0.132
AlexeyAB
on 11 Oct 2019
@AlexeyAB Thank you so much for the answers! Very grateful to finally know what this network is. Time to try switching from Tiny-YOLOv3 to EfficientNet now. :-)
Bananaman
on 12 Oct 2019
@VideoPlayerCode Also look at the inference time: https://github.com/AlexeyAB/darknet/issues/3874
AlexeyAB
on 12 Oct 2019
@AlexeyAB Wow thank you, that's scary. I didn't know that so few BFLOPS would still be slower than Tiny-YOLOv3! I guess it's the "swish" operations of EfficientNet which I read are very slow and complicated on GPU (I think I read that "swish" in Darknet runs on the CPU and everything else runs on GPU for now). That page also tells me that I should research the PRN version YOLO, judging by your table there.
I did some Google searching for more info, and I can't find the original paper, but this page https://www.iis.sinica.edu.tw/page/researchoverview/RecentResearchResults.html?lang=zh&mobile that came up has a quote from some paper saying:
This study proposes to use the combination of gradient concept to enhance the learning capability of Deep Convolutional Networks (DCN), and four Partial Residual Networks based (PRN-based) architectures are developed to verify above concept. The purpose of designing PRN is to provide as rich information as possible for each single layer. During the training phase, we propose to propagate gradient combinations rather than feature combinations. PRN can be easily applied in many existing network architectures, such as ResNet, feature pyramid network, etc., and can effectively improve their performance. Nowadays, more advanced DCNs are designed with the hierarchical semantic information of multiple layers, so the model will continue to deepen and expand. Due to the neat design of PRN, it can benefit all models, especially for lightweight models. In the MSCOCO object detection experiments, YOLO-v3-PRN maintains the same accuracy as YOLO-v3 with a 55% reduction of parameters and 35% reduction of computation, while increasing the speed of execution by twice. For lightweight models, YOLO-v3-tiny-PRN maintains the same accuracy under the condition of 37% less parameters and 38% less computation than YOLO-v3-tiny and increases the frame rate by up to 12 fps on the NVIDIA Jetson TX2 platform. The Pelee-PRN is 6.7% [email protected] higher than Pelee, which achieves the state-of-the-art lightweight object detection. The proposed lightweight object detection model has been integrated with technologies such as multi-object tracking and license plate recognition, and is used in a commercial intelligent traffic flow analysis system as its edge computing component. There are already three countries and more than ten cities have deployed this technique into their traffic flow analysis systems.
So that's damn impressive. I'll research more about it and see if I switch to Tiny-YOLOv3-PRN instead! <3
Edit: Oh apparently the paper is not published yet, and you already knew about it since you had linked to https://github.com/WongKinYiu/PartialResidualNetworks ! :-)
Bananaman
on 15 Oct 2019
@VideoPlayerCode
(I think I read that "swish" in Darknet runs on the CPU and everything else runs on GPU for now).
No. Everything works on GPU, except [yolo] layer.
Just Grouped-convolution is very slow on GPU, that is the reason.
Also look: https://github.com/AlexeyAB/darknet/issues/3114#issuecomment-494148968
AlexeyAB
on 15 Oct 2019
@AlexeyAB Ah okay, thanks for clarifying and thanks a lot for your graceful help and links! Fantastic resources for more research! I am very excited to try the PRN versions!
Also, I found a video from just 2 weeks ago which compares YOLOv3-spp, YOLOv3-tiny, enet-coco, YOLOv3-openimages, YOLOv3-tiny-prn, and YOLOv3 all in darknet on a 1080ti:
https://www.youtube.com/watch?v=j5WstN4VWVU
Of course this video shows no difference between YOLOv3-tiny-prn and YOLOv3-tiny but I'm betting that's an error by the person testing them. It looks like both of those networks are capping the max framerate of the input video or something, since they're literally identical. But still, it's a useful video for comparing the _other_ networks!
Bananaman
on 15 Oct 2019
@VideoPlayerCode
the bottleneck of YOLOv3-tiny and YOLOv3-tiny-prn is showing the results.
WongKinYiu
on 15 Oct 2019
@WongKinYiu Oh, are you saying that the FPS bottleneck in that video is caused by the drawing of the colored boxes around the detected objects?
And thank you very much for that image you just posted! Very helpful to see them side by side like that. I am working on finishing some project right now but I will be trying Tiny-YOLOv3-PRN as soon as possible. Looks amazing!
Bananaman
on 15 Oct 2019
@VideoPlayerCode Drawing video frames and colored boxes on "screen", saving result to video won't spend much time.
WongKinYiu
on 15 Oct 2019
@WongKinYiu Ohhhhhhhhhhhh yeah that makes perfect sense! I understand what you mean now:
- First, Darknet (via CPU) loads the video image/frame from disk. This takes time.
- Then, "yolov3-tiny" and "yolov3-tiny-prn" both detect super fast. "prn" is faster. But both are super fast.
- Then, the CPU (not GPU) code in darknet takes the image, draws colored boxes (via CPU), and converts it to texture (via CPU) to show on screen/give to Windows (via CPU). All of that CPU code is what is taking time in the test, and this is what is making the FPS capped at ~67, which is the fastest that guy's CPU can do those drawing steps. The capping is not caused by the neural networks.
- After all of that CPU work is done (which is what's capping the FPS), it fetches another video frame (step 1) slowly via CPU, and does step 2 again (neural network) super fast... and then yet again goes to step 3 to slowly draw the frame via CPU.
So that's why the benchmark video fails to demonstrate those two networks properly... a proper benchmark would be to not draw results. Just looking at the output of the network and checking how long the "forward pass" took (not counting image loading from disk, and not doing any drawing on screen). Which is what your table displays. And indeed PRN is much faster.
Thanks for the explanation!
Bananaman
on 15 Oct 2019
By the way I was just looking at that benchmark video again, setting playback speed to 0.25x and pausing frames. Pretty shocking results: YOLOv3-Tiny-PRN outputs MUCH better bounding boxes than YOLOv3-Tiny. For example at 0:03 in the video. I paused, took a screenshot, enlarged to 200%, and drew blue rectangles around the bounding boxes (because the ones in the video were thin and blurred).
Top image: v3-Tiny, Bottom Image: v3-Tiny-PRN.
Much better results on PRN! Any ideas why @WongKinYiu ? Is it because of the PRN feedback to the layers? The tester is using pretrained weights + default configs, so it can't be caused by anything they did.

Bananaman
on 15 Oct 2019
@VideoPlayerCode Hello,
i ve answered u at https://github.com/WongKinYiu/PartialResidualNetworks/issues/2#issuecomment-542203456
WongKinYiu
on 15 Oct 2019
@WongKinYiu Oh you talked about that (the smaller bounding boxes) there. I missed that. Thanks, I'll reply there!
Bananaman
on 15 Oct 2019
@AlexeyAB from your quote "./darknet partial cfg/enet-coco.cfg enetb0-coco_final.weights enetb0.132 132
or
./darknet partial cfg/efficientnet_b0.cfg backup/efficientnet_b0_last.weights enetb0.132 132
and train
./darknet detector train cfg/coco.data cfg/enet-coco.cfg enetb0.132"
I trained my custom data sets, it show "segmentation fault (core dumped)". The same data sets passed when train yolov3-tiny/yolov3. What I do wrong?
Thank you for your great jobs.
 xjohnxjohn
on 17 Oct 2019
xjohnxjohn
on 17 Oct 2019
@AlexeyAB from your quote "./darknet partial cfg/enet-coco.cfg enetb0-coco_final.weights enetb0.132 132
or
./darknet partial cfg/efficientnet_b0.cfg backup/efficientnet_b0_last.weights enetb0.132 132and train
./darknet detector train cfg/coco.data cfg/enet-coco.cfg enetb0.132"I trained my custom data sets, it show "segmentation fault (core dumped)". The same data sets passed when train yolov3-tiny/yolov3. What I do wrong?
Thank you for your great jobs.
Hi, @xjohnxjohn
I use enet-coco.cfg and enetb0-coco_final.weights from this and everything is ok.
First, Update darknet repo to the latest version from https://github.com/AlexeyAB/darknet.git
Second, you should modify [yolo] classes and corresponding [convolutional] filters value of cfg/enet-coco.cfg according to your own custom dataset, refer to how-to-train-to-detect-your-custom-objects
 JohnTian
on 18 Oct 2019
JohnTian
on 18 Oct 2019
CBNet looks also like a good backbone. In a R-CNN like detector it achieves #1 (see https://paperswithcode.com/sota/object-detection-on-coco) .
"CBNet: A Novel Composite Backbone Network Architecture for Object Detection", Sep 2019,
https://arxiv.org/pdf/1909.03625.pdf
hfassold
on 18 Oct 2019
@hfassold according to the paper CBNet is about stacking multiple identical backbones in parallel (2 to 3 of them) so it directly induces drastic computational overhead and memory cost. From their experiments the Double-Backbone version decreases speed by 33 % while increasing Coco AP 1.6 %.
To me his solution seems to be sub-optimal as it only focuses on the brut performance and not on the accuracy/BFLOP ratio. It's more about winning Coco Challenge than proposing a more efficient method (like eNet does for instance).
 laclouis5
on 18 Oct 2019
laclouis5
on 18 Oct 2019
Hi, @AlexeyAB
I encounter an issue about Too many or too few labels when use EfficientnetB0 to train a Two-Classes model.
I refer Wiki-Train-Classifier-on-ImageNet-(ILSVRC2012) to set values in efficientnet_b0.cfg.txt
1 Environment
- Ubuntu18.04 LTS
➜ darknet git:(master) ✗ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.3 LTS
Release: 18.04
Codename: bionic
- GPU
➜ darknet git:(master) ✗ nvidia-smi
Sat Oct 19 14:24:24 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.26 Driver Version: 430.26 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 2070 Off | 00000000:01:00.0 On | N/A |
| N/A 37C P8 5W / N/A | 294MiB / 7979MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1182 G /usr/lib/xorg/Xorg 18MiB |
| 0 1223 G /usr/bin/gnome-shell 51MiB |
| 0 1449 G /usr/lib/xorg/Xorg 121MiB |
| 0 1726 G /usr/bin/gnome-shell 101MiB |
+-----------------------------------------------------------------------------+
- Darknet is the latest version from this repo.
- Makefile set the following values to 1
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
AVX=1
OPENMP=1
LIBSO=1
- The
efficientnet_b0.cfgandenetb0-imagenet_final.weightswork very well.
➜ darknet git:(master) ✗ ./darknet classifier predict cfg/imagenet1k.data cfg/efficientnet_b0.cfg data/darknet_pb/enetb0-imagenet_final.weights data/dog.jpg
......
......
Total BFLOPS 0.915
Allocate additional workspace_size = 5.30 MB
Loading weights from data/darknet_pb/enetb0-imagenet_final.weights...
seen 64
Done! Loaded 136 layers from weights-file
try to allocate additional workspace_size = 5.30 MB
CUDA allocate done!
224 224
data/dog.jpg: Predicted in 0.001878 seconds.
malamute: 0.335289
Eskimo dog: 0.083902
German shepherd: 0.071021
standard schnauzer: 0.045112
Tibetan mastiff: 0.043899
2 My custom structure
Project path is /home/epbox/Github/darknet/data/darknet_pb/
➜ darknet_pb git:(master) ✗ ls -hl
total 20M
drwxr-xr-x 2 epbox epbox 220K 10月 18 15:19 backofphone
-rw-rw-r-- 1 epbox epbox 13K 10月 19 10:58 efficientnet_b0.cfg
-rw-rw-r-- 1 epbox epbox 19M 10月 18 10:00 enetb0-imagenet_final.weights
drwxr-xr-x 2 epbox epbox 148K 10月 18 15:20 notphone
-rw-r--r-- 1 epbox epbox 204 10月 18 15:43 pb.data
-rw-r--r-- 1 epbox epbox 4 10月 18 15:11 pb.labels.list
-rw-r--r-- 1 epbox epbox 21 10月 18 15:11 pb.shortnames.list
-rw-r--r-- 1 epbox epbox 333K 10月 18 15:39 pb.train.list
-rw-r--r-- 1 epbox epbox 83K 10月 18 15:40 pb.val.list
- pb.labels.list
1
- pb.shornames.list
backofphone
- pb.data
classes = 2
train = data/darknet_pb/pb.train.list
valid = data/darknet_pb/pb.val.list
backup = backup
labels = data/darknet_pb/pb.labels.list
names = data/darknet_pb/pb.shornames.list
top = 1
- pb.train.list
➜ darknet_pb git:(master) ✗ cat pb.train.list | head -n 5
data/darknet_pb/backofphone/IMG_20190509_174257_crop_1.jpg
data/darknet_pb/notphone/3651_0.jpg
data/darknet_pb/notphone/9558_0.jpg
data/darknet_pb/backofphone/IMG_20190827_153432_crop_1.jpg
data/darknet_pb/backofphone/IMG_20190418_145420_302_crop_1.jpg
- pb.val.list
➜ darknet_pb git:(master) ✗ cat pb.val.list | head -n 5
data/darknet_pb/notphone/7956_0.jpg
data/darknet_pb/backofphone/IMG_20190513_105514_crop_1.jpg
data/darknet_pb/notphone/11034_0.jpg
data/darknet_pb/backofphone/274_1.jpg
data/darknet_pb/notphone/2775_0.jpg
3 The output of train
➜ darknet git:(master) ✗ pwd
/home/epbox/Github/darknet
➜ darknet git:(master) ✗ ./darknet classifier train data/darknet_pb/pb.data data/darknet_pb/efficientnet_b0.cfg data/darknet_pb/enetb0-imagenet_final.weights -topk -dont_show
...
...
Total BFLOPS 0.915
Allocate additional workspace_size = 5.30 MB
Loading weights from data/darknet_pb/enetb0-imagenet_final.weights...
seen 64
Done! Loaded 136 layers from weights-file
Learning Rate: 0.256, Momentum: 0.9, Decay: 0.0005
7984
Saving weights to backup/efficientnet_b0_final.weights
Too many or too few labels: 2, data/darknet_pb/notphone/5391_0.jpg
Too many or too few labels: 2, data/darknet_pb/notphone/10485_0.jpg
Too many or too few labels: 2, data/darknet_pb/backofphone/IMG_20190418_093428_crop_1.jpg
Too many or too few labels: 2, data/darknet_pb/backofphone/1850_1.jpg
@JohnTian Create separate issue with this question.
AlexeyAB
on 19 Oct 2019
@AlexeyAB OKay. Sorry for it.
JohnTian
on 19 Oct 2019
@laclouis5: Thanks for the comment. So
hfassold
on 24 Oct 2019
@laclouis5 - I found another Backbone, an improved Version of ResNet.
"Res2Net: A New Multi-scale Backbone Architecture" at https://arxiv.org/abs/1904.01169
https://mmcheng.net/res2net/
Maybe ist idea could be used also to improve the darknet-53 backbone
hfassold
on 24 Oct 2019
res2net seems use 10 crop test to conduct accuracy.

WongKinYiu
on 24 Oct 2019
@dexception It seems that MixNet-L can be more efficient than EfficientNetB1, and much more faster on GPU
https://github.com/AlexeyAB/darknet/issues/4203
AlexeyAB
on 1 Nov 2019
Looks good
hfassold
on 2 Nov 2019
@AlexeyAB Can you share some statistics ? So far i think ShuffleV2 seems to be the most efficient of them all.
dexception
on 7 Nov 2019
@dexception
Original MixNet uses 4 depthwise conv-layers (3x3, 5x5, 7x7, 9x9) instead of 1 depthwise conv-layer, so this has aproximately the same speed. But we can try to use uses only 4 groups for MixNet conv-layers (3x3, 5x5, 7x7, 9x9), while EfficientNet and ShuffleNetv2 uses 16-512 groups, so this modified MixNet can be faster on GPU.
Mix_net has higher Top1 accuracy and lower Flops - so Mix_net can be faster on CPU: https://github.com/AlexeyAB/darknet/issues/4203
- ShuffleNetV2 - xxxx params - 0.600 BFlops - 75.4% Top1 - xxxx Top5
- MixNet-L - 7.3M params - 0.565 BFlops - 78.9% Top1 - 94.2% Top5
- EfficientNetB1 - 7.8M params - 0.700 BFlops - 78.8% Top1 - 94.4% Top5

AlexeyAB
on 7 Nov 2019
this paper might be relevant with this issue in detection task
https://arxiv.org/pdf/1911.09070.pdf
EfficientDet: Scalable and Efficient Object Detection
 syjeon121
on 21 Nov 2019
syjeon121
on 21 Nov 2019
@syjeon121 Thanks! I added a separate issue: https://github.com/AlexeyAB/darknet/issues/4346
AlexeyAB
on 21 Nov 2019
@AlexeyAB
Q1. Can you please highlight which if these architectures use depthwise-convolution layers so that we know they are for offline usage ?
Q2. I would like to know which is the most efficient architecture that doesn't use depthwise-convoltion ?
Also,
According to this link:
https://pypi.org/project/gluoncv2/
If we set the criteria for Min Top 1 Accuracy to 75%
MobileNetV3 L/224/1.0 Seem to be better than Mixnet-S.
MobileNetV3 L/224/1.0 vs Mixnet-S
226 Flops vs 260 Flops
75.37 Top 1 Accuracy vs 75.68 Accuracy.
dexception
on 29 Nov 2019
@dexception
- All these models use grouped/depthwise-conv: ShuffleNet v1/v2, EfficientNet b0-b7, MixNet-S/M/L, MobileNet v2/v3, ...
What is the offline usage ?
- Do you have any paper with comparison MixNet vs MobileNetv3?
As I understand it, these are very close architectures. Yes, according to https://pypi.org/project/gluoncv2/ MobileNetV3 L/224/1.0 (14% lower BFLOPS, but 4% = 7.69 / 7.39 higher Top5-error) better than MixNet-S
Model | Top1 | Top5 | Params | FLOPs/2 | Remarks
-- | -- | -- | -- | -- | --
AlexNet | 40.46 | 17.70 | 62,378,344 | 1,132.33M | Training (log)
-- | -- | -- | -- | --
MixNet-S | 24.32 | 7.39 | 4,134,606 | 260.26M
-- | -- | -- | -- | --
MixNet-M | 23.31 | 6.78 | 5,014,382 | 366.05M
-- | -- | -- | -- | --
MobileNetV3 L/224/1.0 | 24.63 | 7.69 | 5,481,752 | 226.80M
-- | -- | -- | -- | --

AlexeyAB
on 29 Nov 2019
Is there a darknet implementation of MobileNetV3?
LukeAI
on 29 Nov 2019
@dexception
- All these models use grouped/depthwise-conv: ShuffleNet v1/v2, EfficientNet b0-b7, MixNet-S/M/L, MobileNet v2/v3, ...
What is the offline usage ?
- Do you have any paper with comparison MixNet vs MobileNetv3?
As I understand it, these are very close architectures. Yes, according to https://pypi.org/project/gluoncv2/
MobileNetV3 L/224/1.0(14% faster and4% = 7.69 / 7.39higher Top5-error) better than MixNet-SModel Top1 Top5 Params FLOPs/2 Remarks
AlexNet 40.46 17.70 62,378,344 1,132.33M Training (log)
-- -- -- -- --
MixNet-S 24.32 7.39 4,134,606 260.26M
-- -- -- -- --
MixNet-M 23.31 6.78 5,014,382 366.05M
-- -- -- -- --
MobileNetV3 L/224/1.0 24.63 7.69 5,481,752 226.80M
-- -- -- -- --
By offline usage i meant user can wait for the output even if it is a little late and where accuracy is more important and we can use heavy models for detection.
Can you share which architecture is the most efficient if we don't include any that use depthwise-convolution with min top 1 accuracy 75% ?
dexception
on 29 Nov 2019
@LukeAI No.
@dexception
At first, you should know that this accuracy
MobileNetv3 Top1 75,37%andMixNet-S Top1 75,68%andEfficientNetB0 Top1 76.3%can be achieved only if you train with very large mini_batch size:either you use TPU-cluster ~1M$ or DGX-2 400K$ with synchronized batch-normalization (which slows down training) https://arxiv.org/abs/1711.07240v4
or you use CPU-RAM instead of GPU-RAM which 100x time cheaper, but slows down training much more (except BM Power8-CPU with nVlink between CPU & GPUs) https://github.com/AlexeyAB/darknet/issues/4386
With small mini_batch size instead of Top1 76.3% we get: https://github.com/AlexeyAB/darknet/issues/3380#issuecomment-501263052
- Our EfficientNet B0 (224x224) 0.9 BFLOPS - 0.45 B_FMA (16ms / RTX 2070), 4.9M params - 71.3% Top1
- Official EfficientNetB0 (224x224) 0.78 BFLOPS - 0.39 FMA, 5.3M params - 70.0% Top1
- Lower BFLOPS doesn't mean a faster model
So:
- to compare apples with apples we should compare results with the same mini_batch size
- if we are talking about speed rather than BFLOPS, then the best models:
Classifiers:
- CSPDarkNet-53 77.2% Top1: https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/cfg/csdarknet53.cfg and https://drive.google.com/open?id=1dZJIxngmFpQJvsa6y7XADfSxkXCjJTzp comparison: https://github.com/WongKinYiu/CrossStagePartialNetworks#big-models
CSPPeleeNet- 70.9% Top1 andCSPPeleeNet-swish-SE- 72.4% Top1 - private networks @WongKinYiu https://github.com/WongKinYiu/CrossStagePartialNetworks#small-models
Detectors:
- for 100-400 FPS on GPU - EFM (SAM) are the best models - author @WongKinYiu cfg-file is private https://github.com/AlexeyAB/darknet/issues/4406#issue-530052808
- for ~50 FPS on GPU - CSPResNeXt50-PANet-SPP - 512x512 - 38.0%
[email protected], 60.0%[email protected]cfg/weights: https://github.com/AlexeyAB/darknet/issues/4406#issue-530052808 - for ~30 FPS on iPhone 11 - Yolov3-spp (but I think CSPResNeXt50-PANet-SPP will be better): https://github.com/AlexeyAB/darknet/issues/3702#issuecomment-518223308
AlexeyAB
on 29 Nov 2019
@AlexeyAB
Thanks for sharing the stats.
Do you have any cfg files related to PeleeNet with swish activation ? I would to train it on Imagenet.
@WongKinYiu
Amazing work. Are you planning to share CSPPeleeNet - EFM (SAM) 512x512 this model in future ?
dexception
on 30 Nov 2019
https://arxiv.org/abs/1911.11907
https://github.com/iamhankai/ghostnet
maybe better than mobilenetv3, efficientnet, ..., etc.

WongKinYiu
on 30 Nov 2019
@AlexeyAB @WongKinYiu
Its funny but i thought i should mention this. I have temporary access to 2xTesla T4 for next 10-20 days.
After that i have to return them. So i would love to train some of these new models your talking about. Can i have some cfg files for imagenet from you guys ?
dexception
on 30 Nov 2019
@dexception
While CSPPeleeNet is private.
And since GhostNet there isn't implemented yet.
There are MixNet-M and MixNet-M-GPU which are approximately have the same architecture, accuracy ~76.5% Top1 and speed ~0.38 FMA BFlops as large-MobileNet v3
- MixNet-M: mixnet_m.cfg.txt - 0.759 BFlops (0.379 FMA) - 4.6 sec per iteration training - 45ms inference
- MixNet-M-GPU (minor modification for GPU): mixnet_m_gpu.cfg.txt - 1.0 BFlops (0.500 FMA) - 2.7 sec per iteration training - 45 ms inference
Now @WongKinYiu is training MixNet-M-GPU: https://github.com/AlexeyAB/darknet/issues/4203#issuecomment-557909581
Or you can try to train with CutMix and Large mini-batch size https://github.com/WongKinYiu/CrossStagePartialNetworks#big-models
- either https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/cfg/csresnext50.cfg
- or https://github.com/WongKinYiu/CrossStagePartialNetworks/blob/master/cfg/csresnext50-elastic.cfg
For example, you can try to train https://github.com/AlexeyAB/darknet/files/3838329/mixnet_m.cfg.txt
- with CutMix: https://github.com/AlexeyAB/darknet/issues/4419
[net]
batch=120
subdivisions=2
height=224
width=224
cutmix=1
- Also you can try to train the first 1-2 days and the last 1-2 days with large mini-batch size (if you have 32-128 GB CPU RAM) https://github.com/AlexeyAB/darknet/issues/4386
[net]
batch=256 # or 512
subdivisions=1
height=224
width=224
cutmix=1
optimized_memory=3
workspace_size_limit_MB=2000 # or 4000
@AlexeyAB
What about PeleeNet ? Do you have any cfg files for this ?
dexception
on 30 Nov 2019
This paper might also Help a Bit: https://arxiv.org/pdf/1904.11486
Modification can be applied to any backbone
hfassold
on 1 Dec 2019
@hfassold
WongKinYiu
on 1 Dec 2019
@AlexeyAB Hi, about enet-coco.cfg
139 upsample 2x 13 x 13 x 128 -> 26 x 26 x 128
140 Shortcut Layer: 90
I got this tip:
139 upsample 2x 17 x 17 x 128 -> 34 x 34 x 128
140 Shortcut Layer: 90
w = 34, w2 = 34, h = 34, h2 = 34, c = 128, c2 = 576
Is there something wrong in cfg file?
 litingsjj
on 19 Dec 2019
litingsjj
on 19 Dec 2019
@AlexeyAB Hi, in enet-coco.cfg the last yolo layer:
mask = 1,2,3 should be mask = 0,1,2?
 kinglintianxia
on 9 Jan 2020
kinglintianxia
on 9 Jan 2020
Related issues
 siddharth2395
·
3Comments
siddharth2395
·
3Comments
 Cipusha
·
3Comments
Cipusha
·
3Comments
 Yumin-Sun-00
·
3Comments
Yumin-Sun-00
·
3Comments
 louisondumont
·
3Comments
louisondumont
·
3Comments
 shootingliu
·
3Comments
shootingliu
·
3Comments
Most helpful comment
Paper: https://arxiv.org/abs/1905.11946v2
Classifier
EfficientNet B0 (224x224) 0.9 BFLOPS - 0.45 B_FMA (16ms / RTX 2070), 4.9M params: efficientnet_b0.cfg.txt - Training 2.5 days
71.3% Top1 - 90.4% Top5 - accuracy weights file: https://drive.google.com/open?id=1nGdWz76A2EpNhWIfDeAI3hribboilux-
While (Official) EfficientNetB0 (224x224) 0.78 BFLOPS - 0.39 FMA, 5.3M params - that is trained by official code https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet with batch size equals to 256 has lower accuracy: 70.0% Top1 and 88.9% Top5
Detector - 3.7 BFLOPs, 45.0 [email protected] on COCO test-dev.
cfg-file: enet-coco.cfg.txt
weights file: https://drive.google.com/open?id=1FlHeQjWEQVJt0ay1PVsiuuMzmtNyv36m
efficientnet-lite3-leaky.cfg: top-1 73.0%, top-5 92.4%. - change relu6 to leaky:
activation=leakyhttps://github.com/AlexeyAB/darknet/blob/master/cfg/efficientnet-lite3.cfgClassifiers: - Can be trained on ImageNet(ILSVRC2012) by using 4 x GPU 2080 TI:
EfficientNet B0 XNOR (224x224) 0.8 BFLOPS + 25 BOPS (18ms / RTX 2070): efficientnet_b0_xnor.cfg.txt - 5 days
EfficientNet B3 (288x288) 3.5 BFLOPS - 1.8 B_FMA (28ms/RTX 2070): efficientnet_b3.cfg.txt - 11 days
EfficientNet B3 (320x320) 4.3 BFLOPS - 2.2 B_FMA (30ms/RTX 2070): efficientnet_b3_320.cfg.txt - 14 days
EfficientNet B4 (384x384) 10.2 BFLOPS - 5.1 B_FMA (46ms/RTX 2070): efficientnet_b4.cfg.txt - 26 days
Training command:
./darknet classifier train cfg/imagenet1k_c.data cfg/efficientnet_b0.cfg -topkContinue training:
./darknet classifier train cfg/imagenet1k_c.data cfg/efficientnet_b0.cfg backup/efficientnet_b0_last.weights -topkContent of
imagenet1k_c.data:Dataset - each image in
imagenet1k.train_c.listandinet.val_c.listhas one of 1000 labels fromimagenet.labels.list, for examplen01440764ILSVRC2012 training dataset - annotated images - 138 GB: https://github.com/AlexeyAB/darknet/blob/master/scripts/get_imagenet_train.sh
ILSVRC2012 validation dataset:
Set validation labels: https://github.com/AlexeyAB/darknet/blob/master/scripts/imagenet_label.sh
read: https://pjreddie.com/darknet/imagenet/
More: http://www.image-net.org/challenges/LSVRC/2012/nonpub-downloads
Models: https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_builder.py#L28-L39
CLICK ME - EfficientNet B0 model details
CLICK ME - EfficientNet B3 model details
CLICK ME - EfficientNet B4 model details
https://arxiv.org/abs/1905.11946v2
https://www.dlology.com/blog/transfer-learning-with-efficientnet/
https://github.com/zsef123/EfficientNets-PyTorch/tree/master/models
https://medium.com/@lessw/efficientnet-from-google-optimally-scaling-cnn-model-architectures-with-compound-scaling-e094d84d19d4
In other words, to scale up the CNN, the depth of layers should increase 20%, the width 10% and the image resolution 15% to keep things as efficient as possible while expanding the implementation and improving the CNN accuracy.
The MBConv block is nothing fancy but an Inverted Residual Block (used in MobileNetV2) with a Squeeze and Excite block injected sometimes.
MobileNetV2: Inverted Residuals and Linear Bottlenecks: https://arxiv.org/pdf/1801.04381v4.pdf
MobileNetV2 graph: http://ethereon.github.io/netscope/#/gist/d01b5b8783b4582a42fe07bd46243986
MobileNetV2 proto: https://github.com/shicai/MobileNet-Caffe/blob/master/mobilenet_v2_deploy.prototxt
MobileNetv2 Darknet-cfg: https://github.com/WePCf/darknet-mobilenet-v2/blob/master/mobilenet/test.cfg (should be trained from the begining, since the src/image.c and examples/classifier.c are modified in WePCf-repo, search for "mobilenet" to see what are changed)
| |
|  |
|
|-|-|
| | |
MobileNet_v2:
EfficientNet_b0:
| |
|  |
|
|-|-|
| | |