Darknet: What is yolo-spp? ~+2.7 AP@[.5, .95]
Is there any paper/blog where I can find an explanation for yolo-spp?
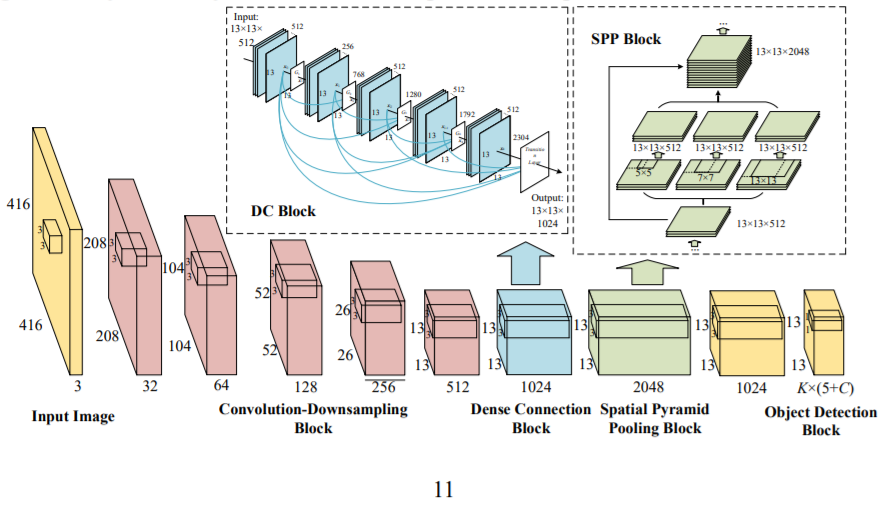
Is it the same that the spp block used here DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection?
 drapado
drapado
All 10 comments
@AlexeyAB Hi there i would also like to ask the same question. Any explanation of what exactly the differences are between the different versions (YOLOv3-Tiny, YOLOv3 and yolov3-spp) would be really helpful. A description of the changes and what exactly those changes do would be very helpful.
Thanks in advance
 HamzahNizami
on 7 Apr 2019
HamzahNizami
on 7 Apr 2019
@drapado @HamzahNizami Hi,
The difference between yolov3.cfg and yolov3-spp.cfg just this SPP-block: https://github.com/AlexeyAB/darknet/blob/b6a824df39d1a79f15916d2c11133ce27bc0ab06/cfg/yolov3-spp.cfg#L575-L597
- yolov3-tiny.cfg uses downsampling (stride=2) in Max-Pooling layers
- yolov3.cfg uses downsampling (stride=2) in Convolutional layers
- yolov3-spp.cfg uses downsampling (stride=2) in Convolutional layers + gets the best features in Max-Pooling layers
Yes, this is described in this artice, just yolov3-spp.cfg uses 5x5 9x9 13x13, while in the artice 5x5 7x7 13x13: https://arxiv.org/abs/1903.08589
They got only mAP = 79.6% on Pascal VOC 2007 test with using Yolov3SPP-model.
But you can achive higher accuracy mAP = 82.1% even with yolov3.cfg model by using this repository: https://github.com/AlexeyAB/darknet/issues/2557#issuecomment-474187706
And even higher mAP with yolov3-spp.cfg and this repository.
 AlexeyAB
on 8 Apr 2019
AlexeyAB
on 8 Apr 2019
@AlexeyAb thanks for your answers!
How the spp block makes yolov3-spp suitable for small and large object detection?
drapado
on 8 Apr 2019
@AlexeyAB I was under the impression that YOLOv3 removed max pooling layers?
HamzahNizami
on 10 Apr 2019
@AlexeyAB thanks for your answers!
How the spp block makes yolov3-spp suitable for small and large object detection?
My understanding -
Both convolution subsampling and max pooling have distinct advantages. Convolution subsampling can be better reversed probably in the subsequent upsampling layers. Max pooling somewhat acts to remove some high frequency noise from the image by selecting only max values from the adjacent regions.
By combining both, spp seems to be leveraging the benefits of both.
@AlexeyAB , Would be good to know your thoughts if the above is valid comment.
Thanks!
 kmsravindra
on 16 Apr 2019
kmsravindra
on 16 Apr 2019
@AlexeyAB , Want to know if the concept of "Dense connection block" also implemented as part of yolov3-spp here in this repository? Or this was not needed?
kmsravindra
on 16 Apr 2019
@kmsravindra
Want to know if the concept of "Dense connection block" also implemented as part of yolov3-spp here in this repository?
No.
You can try to add it there: https://github.com/AlexeyAB/darknet/blob/8c970498a296ed129ffef7d872ccc25d42d1afda/cfg/yolov3-spp.cfg#L574
For example, you can use Dense-Connection block like this (just set filters=512 in [convolutional] layers) : https://github.com/AlexeyAB/darknet/blob/8c970498a296ed129ffef7d872ccc25d42d1afda/cfg/densenet201.cfg#L1224-L1317
AlexeyAB
on 16 Apr 2019
@kmsravindra
My understanding -
Both convolution subsampling and max pooling have distinct advantages. Convolution subsampling can be better reversed probably in the subsequent upsampling layers. Max pooling somewhat acts to remove some high frequency noise from the image by selecting only max values from the adjacent regions.
By combining both, spp seems to be leveraging the benefits of both.@AlexeyAB , Would be good to know your thoughts if the above is valid comment.
Thanks!
Convolution subsampling can be better reversed probably in the subsequent upsampling layers.
What do you mean?
Convolution subsampling (with
kernel_size >= stride) uses all input data (weighted), while max-pooling uses only the maximum inputs.Convolution subsampling can be end-to-end optimized for XNOR-model (bit1-input & bit1-output), while max-pooling requires INT16/32 or FP16/32 inputs even for XNOR-model (so conversion BIT1->FP32->BIT1(transpose) - it brings a big overhead) .
AlexeyAB
on 16 Apr 2019
@AlexeyAB Can you please tell me how the concatenation of the max pooling layers is carried out if they are different dimensions? Are they simply padded to the correct size?
 mcguile
on 14 Jun 2019
mcguile
on 14 Jun 2019
@mcguile
They have different sizes but the same stride=1, so output WxH == input WxH, therefore all these maxpool-layers have the same output.
Yes it automatically uses padding size-1: https://github.com/AlexeyAB/darknet/blob/a1abd07e23fc5b143a6197de9908fe4f33791c6a/src/parser.c#L533
AlexeyAB
on 14 Jun 2019
Related issues
 Mididou
·
3Comments
Mididou
·
3Comments
 yongcong1415
·
3Comments
yongcong1415
·
3Comments
 PROGRAMMINGENGINEER-NIKI
·
3Comments
PROGRAMMINGENGINEER-NIKI
·
3Comments
 Yumin-Sun-00
·
3Comments
Yumin-Sun-00
·
3Comments
 zihaozhang9
·
3Comments
zihaozhang9
·
3Comments
Most helpful comment
@drapado @HamzahNizami Hi,
The difference between yolov3.cfg and yolov3-spp.cfg just this SPP-block: https://github.com/AlexeyAB/darknet/blob/b6a824df39d1a79f15916d2c11133ce27bc0ab06/cfg/yolov3-spp.cfg#L575-L597
Yes, this is described in this artice, just yolov3-spp.cfg uses 5x5 9x9 13x13, while in the artice 5x5 7x7 13x13: https://arxiv.org/abs/1903.08589
They got only
mAP = 79.6%on Pascal VOC 2007 test with using Yolov3SPP-model.But you can achive higher accuracy
mAP = 82.1%even with yolov3.cfg model by using this repository: https://github.com/AlexeyAB/darknet/issues/2557#issuecomment-474187706And even higher mAP with yolov3-spp.cfg and this repository.