Darknet: Several dificults to train yolov3 with pascal voc
Hi! I'm trying to train yolov3 with pascal voc dataset (just like this tutorial do).
To start train:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
An output while the network is training

As you can see, there is some NAN. Is that right?
Anyway, the action generate some weights and i use the following comand:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
And no detentions are made. What can be wrong?
I'm running in a gtx 2080, i7-9, 32 GB Ram and 2 TB Mem.
Cuda 10.0 actually
 joaolcaas
joaolcaas
All 16 comments
An output example

joaolcaas
on 27 Mar 2019
@joaolcaas Hi,
As you can see, there is some NAN. Is that right?
There is no NAN in avg loss.
This is normal: https://github.com/AlexeyAB/darknet#how-to-train-pascal-voc-data
Note: If during training you see
nanvalues foravg (loss)field - then training goes wrong, but if nan is in some other lines - then training goes well.
You should train at least 4000 iterations to get any detections: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
And if you train for 20 classes, then you should train more than 20*2000 = 40 000 iterations.
Usually sufficient 2000 iterations for each class(object), but not less than 4000 iterations in total. But for a more precise definition when you should stop training, use the following manual:
As you can see for Detection you should use: https://github.com/AlexeyAB/darknet#how-to-use-on-the-command-line
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_4000.weights
instead of
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
 AlexeyAB
on 27 Mar 2019
AlexeyAB
on 27 Mar 2019
Thanks for your reply, @AlexeyAB!
My mistake on Detection comand. I just copy from the yolov3 website. I alredy use the weights that darknet create.
This results that you showed up works for batch=1 and subdivision=1? I'm using batch = 64 and subdivision=16 (on interation 982 rigth now). I dont know if this cfg above is the best.
joaolcaas
on 27 Mar 2019
@joaolcaas You shouldn't try detect anything until 2000-4000 iterations reached.
In my repository it works for both batch=1 and subdivision=1 and batch = 64 and subdivision=16.
In this repository you should use for Detection batch=1 and subdivision=1 and for Training batch = 64 and subdivision=16.
AlexeyAB
on 27 Mar 2019
I see! Thanks for your answer, it was rly rly helpful!
At this moment, the network is being trained. Tomorrow i can give a stronger feedback!
joaolcaas
on 27 Mar 2019
Hi! I'm trying to train yolov3 with pascal voc dataset (just like this tutorial do).
To start train:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74An output while the network is training
As you can see, there is some NAN. Is that right?
Anyway, the action generate some weights and i use the following comand:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpgAnd no detentions are made. What can be wrong?
I'm running in a gtx 2080, i7-9, 32 GB Ram and 2 TB Mem.
Cuda 10.0 actually
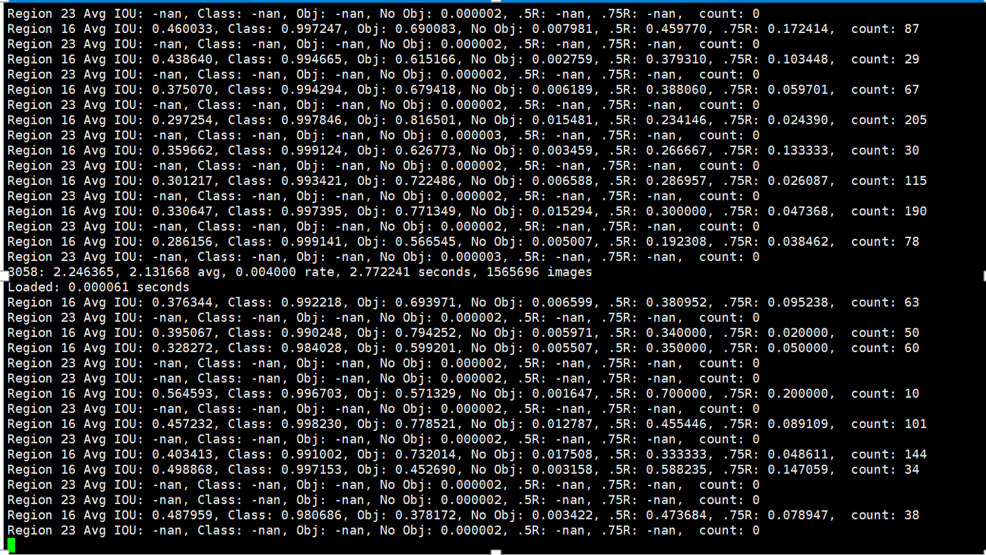
I also come across this problems .
After over 3000 iterations ,there are still so many nan, is it normal? I don't know why nan and not nan appeared alternately.
I'm running in Tesla K80,
Cuda 9.0 actually.
 ljh14
on 29 Mar 2019
ljh14
on 29 Mar 2019
@ljh14 i don't have my results on moment (training about 30000 interactions) but i do believe that is normal, as @AlexeyAB said.
I tested it on 20000 interactions backup and it was good. I gonna finish the training about 40000 interactions and use it as my own weights.
joaolcaas
on 29 Mar 2019
@ljh14 i don't have my results on moment (training about 30000 interactions) but i do believe that is normal, as @AlexeyAB said.
I tested it on 20000 interactions backup and it was good. I gonna finish the training about 40000 interactions and use it as my own weights.
Do you still have nan in your training logs now ?
ljh14
on 29 Mar 2019
Do you still have nan in your training logs now ?
I'm away from computer that is training right now, but i can give your a feedback in 12 hours, maybe. But i believe Nan values still there.
joaolcaas
on 29 Mar 2019
Do you still have nan in your training logs now ?
I'm away from computer that is training right now, but i can give your a feedback in 12 hours, maybe. But i believe Nan values still there.
Ok, thank you so much !
ljh14
on 29 Mar 2019
So, my teammates just stopped the training process at 40000 interactions and delete the console. But i believe there were some NaN in some values. If your predctions get wrong, check the labels name file. I was using the coco.names and, for a dog, the result was a stop sign
joaolcaas
on 29 Mar 2019
So, my teammates just stopped the training process at 40000 interactions and delete the console. But i believe there were some NaN in some values. If your predctions get wrong, check the labels name file. I was using the coco.names and, for a dog, the result was a stop sign
I have trained the yolov3-tiny for 50200 times using my own dataset, the mAP reached 70% according to one testing python file, I cannot believe it, because the mAP of tiny is only about 33% in COCO dataset in the official website. And there are always Nans when it comes to the second yolo layer in my training process. I don't know why it happened. But anyway my detection results are acceptable. Thank u for your attention!
ljh14
on 30 Mar 2019
I have the same problem now.
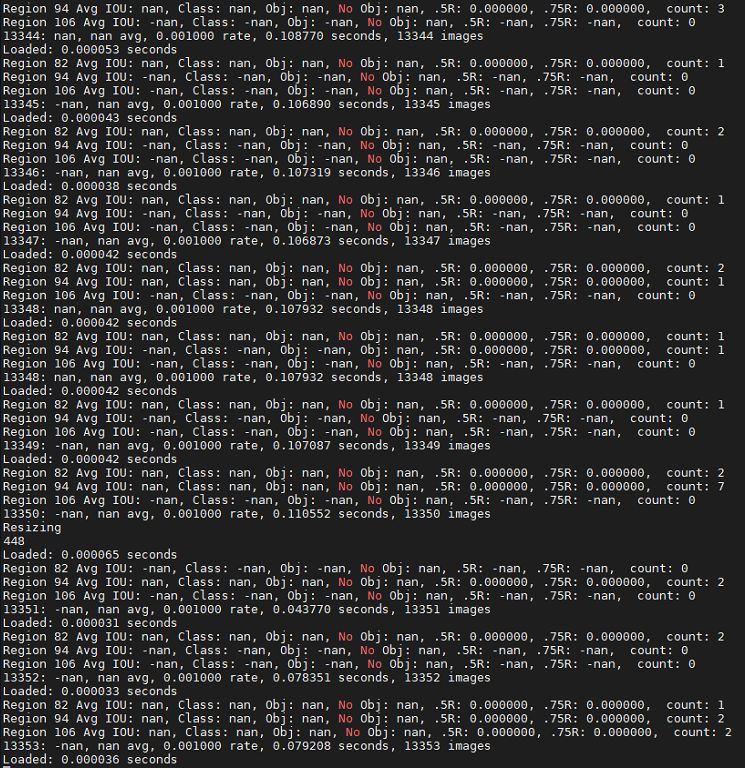
I was following instructions on https://pjreddie.com/darknet/yolo/ while this problem occurred.
My partner told me he had tried iterations from 10k to 40k, nan remained.
What change else shall I make ?
Thanks :)
 JiayiXie11
on 8 Jun 2020
JiayiXie11
on 8 Jun 2020
@joaolcaas Hi,
As you can see, there is some NAN. Is that right?
There is no NAN in avg loss.
This is normal: https://github.com/AlexeyAB/darknet#how-to-train-pascal-voc-dataNote: If during training you see nan values for avg (loss) field - then training goes wrong, but if nan is in some other lines - then training goes well.
You should train at least 4000 iterations to get any detections: https://github.com/AlexeyAB/darknet#when-should-i-stop-training
And if you train for 20 classes, then you should train more than 20*2000 = 40 000 iterations.Usually sufficient 2000 iterations for each class(object), but not less than 4000 iterations in total. But for a more precise definition when you should stop training, use the following manual:
As you can see for Detection you should use: https://github.com/AlexeyAB/darknet#how-to-use-on-the-command-line
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_4000.weights
instead of
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
Dear @AlexeyAB ,
Can you please state the exact reason behind getting "nan" in Avg_loss. It is clear and understood as mentioned by you that "Training goes wrong", but it would be nice to know the reason why the Training is going wrong. Assumptions that Data + cfg are correct and no mistakes made.
Thankyou
 deeplearner93
on 27 Aug 2020
deeplearner93
on 27 Aug 2020
@joaolcaas You shouldn't try detect anything until 2000-4000 iterations reached.
In my repository it works for both
batch=1 and subdivision=1andbatch = 64 and subdivision=16.
In this repository you should use for Detectionbatch=1 and subdivision=1and for Trainingbatch = 64 and subdivision=16.
I was looking for this answer
 martianvenusian
on 14 Sep 2020
martianvenusian
on 14 Sep 2020
I was training with batch=1 and subdivision=1 and got some nans. I stopped training after iteration 500. And changed to batch = 64 and subdivision=16 and loaded yolov3-voc_500.weights from backup where I stopped. And nans suddenly decreased. I wonder if this is the right way.
martianvenusian
on 14 Sep 2020
Related issues
 abeyang00
·
31Comments
abeyang00
·
31Comments
 sonalambwani
·
218Comments
sonalambwani
·
218Comments
 clockworkkiwi
·
29Comments
clockworkkiwi
·
29Comments
 MansourTrabelsi
·
44Comments
MansourTrabelsi
·
44Comments
 AurusHuang
·
39Comments
AurusHuang
·
39Comments
Most helpful comment
@joaolcaas You shouldn't try detect anything until 2000-4000 iterations reached.
In my repository it works for both
batch=1 and subdivision=1andbatch = 64 and subdivision=16.In this repository you should use for Detection
batch=1 and subdivision=1and for Trainingbatch = 64 and subdivision=16.