Darknet: Small object detection maxes out around 50% mAP
I have 2 classes, class 1 objects are ~50x50px class 2 objects are ~70x70px. I have a large class imbalance, 2500 class 1, 500 class 2 so using focal loss which has been working well. No matter what I do though I can't seem to get > 50% mAP. F1 is more important for me but still, most of the time can only get 60% TP with about 30-40% of detection being FP. I feel like the objects are usually very distincct and that I should be doing much better. These are photos taken from a plane, the background is generally glaciers, so lots of white, but also lots of noise, then the objects are usually a very distinct shape that is easily detectable by eye.
Anyways the main point of this is that I'm a bit confused about how input size in yolov3 works because from what I have read it scales everything down to 448x448. Currently I've been training on 640x640 input but I could likely go larger(training on single 1080ti). If yolov3 scales my 640x640 input down to 448x448 I'm likely losing a lot of information as my objects are small, no? I've set up my larger residual layer as you suggest "layer=-1, 11" w/ stride of 4 to try and save some of the information from the earlier layers, color is not very important so removed saturation, exposure, and hue augs. I'm using my own anchors(clusters 9, w/h 640), I've got a 2:1 ratio of true negatives to true positive images, lots of images have multiple truths, labels are correct(have gone through all of them manually).
Anything you can think of that I may be doing wrong or that may help me increase results? I can post a few example images if that would be helpful.
Also you mention that for small objects it is good to use:
yolov3_5l or yolov3-tiny_3l or yolov3-spp. Is there any documentation somewhere on what these models are doing different then the generic yolov3 model?
Any advice would be super helpful, thanks for everything! The tools in your fork have been incredibly useful.
Some of cfg:
batch=64
subdivisions=64
width=640
height=640
channels=3
momentum=0.9
decay=0.0005
angle=0
#saturation = 1.5
#exposure = 1.5
#hue=.1
learning_rate=0.0008
burn_in=1000
max_batches = 20000
policy=steps
steps=400000,450000
first yolo region
[yolo]
focal_loss=1
mask = 6,7,8
anchors = 44, 45, 70, 45, 46, 73, 61, 70, 85, 57, 65,115, 86, 88, 126, 75, 107,128
classes=2
num=9
jitter=.2
ignore_thresh = .7
truth_thresh = 1
random=1
 readicculus
readicculus
All 15 comments
Adding a few examples from the training set maybe useful information






readicculus
on 13 Feb 2019
@readicculus Hi,
Anyways the main point of this is that I'm a bit confused about how input size in yolov3 works because from what I have read it scales everything down to 448x448. Currently I've been training on 640x640 input but I could likely go larger(training on single 1080ti). If yolov3 scales my 640x640 input down to 448x448 I'm likely losing a lot of information as my objects are small, no?
You use width=640 height=640 in your cfg-file, so any image will be resized to the 640x640.
I've set up my larger residual layer as you suggest "layer=-1, 11" w/ stride of 4 to try and save some of the information from the earlier layers,
It isn't necessary in your case.
It is required only if there are many objects with size less than 16x16 after that image is resized to 640x640.
color is not very important so removed saturation, exposure, and hue augs.
You must use default exposure=1.5, because illumination on your test images will be different.
But you can reduce hue and saturation:
saturation = 1.1
exposure = 1.5
hue=.01
I'm using my own anchors(clusters 9, w/h 640)
anchors = 44, 45, 70, 45, 46, 73, 61, 70, 85, 57, 65,115, 86, 88, 126, 75, 107,128
- You should follow this rules https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
(also you can change indexes of anchors masks= for each [yolo]-layer, so that 1st-[yolo]-layer has anchors larger than 60x60, 2nd larger than 30x30, 3rd remaining)
Or just use default anchors
- Can you show screenshot of cloud of points?
./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 640 -height 640 -show
labels are correct(have gone through all of them manually).
Did you use Yolo_mark for this? https://github.com/AlexeyAB/Yolo_mark
yolov3_5l or yolov3-tiny_3l or yolov3-spp. Is there any documentation somewhere on what these models are doing different then the generic yolov3 model?
Yolov3-spp just better than Yolov3 in any cases
yolov3_5l better than Yolov3 if you use network resolution (width, height in cfg) 832x832 or more and want to detect both small and large objects - the best accuracy for large and small objects
yolov3-tiny_3l you can use with very high network resolution (width, height in cfg) 1024x1024 and good speed
I have 2 classes, class 1 objects are ~50x50px class 2 objects are ~70x70px. I have a large class imbalance, 2500 class 1, 500 class 2 so using focal loss which has been working well. No matter what I do though I can't seem to get > 50% mAP.
On such images your should get mAP ~= 90-95% using default settings and width=640 height=640 in cfg-file
Do you use separate validation dataset or the same as training?
 AlexeyAB
on 13 Feb 2019
AlexeyAB
on 13 Feb 2019
Thanks for the response! I did not use Yolo Mark to annotate, built my own tool to specific to this dataset but when I look at labels using Yolo mark they are the same. I'm only training to ~10k iters because beyond that it overfits a lot but I've never tried past 20k, but for 2 classes from what I've seen and what other say 5k iterations should be enough. Maybe because I only have 3,000 total labels using a network as large as yolov3 is hurting performance and over fitting? I'll post a loss / mAP graph of training when its done but essentially loss looks good but mAP is up and down and all over the place every 500 iterations when it is measured.
I'll train right now without the layer=-1,11 and with the color augmentations mentioned thanks for the tip. I'll also try the models you made and report back soon.
Attached is from running:
./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 640 -height 640 -show

readicculus
on 14 Feb 2019
I'll train right now without the
layer=-1,11and with the color augmentations mentioned thanks for the tip. I'll also try the models you made and report back soon.
Try to train ~20 000 iterations with -map flag and show Loss/mAP-chart.
AlexeyAB
on 14 Feb 2019
I've been trying to get the graph for you but my training in this fork dies every 1000 or so iterations, but not right after or during the stage that checks the mAP score every x iters. It also does not give any error message, it just stops. I can get a loss plot from the logs but the chart.png gets overwritten every time I have to restart. It could be I'm running out of ram training using yolov3-tiny-3l on 1024x1024 with 16gb ram and it's possible there is a memory leak as the process starts out using about 5gb then around the time it crashes is using 9gb. Every time it runs mAP memory use goes up by ~1gb and does not seem to get cleaned up. I'm running with -map -dont_show because when it brings up the UI the ui doesn't respond and this seems to just write the graph. Have you seen this before? Can't seem to find it in other issues
readicculus
on 15 Feb 2019
@readicculus
I've been trying to get the graph for you but my training in this fork dies every 1000 or so iterations
Can you show screenshot when it happen?
Do you get this issue if you train without -map flag?
Can you run ./darknet detector map... successfully without errors?
What parameters do you use in the Makefile?
Are there files bad.list or bad_label.list?
Can you show output of these commands?
nvcc --version
nvidia-smi
Can you show screenshot when it happen?
Do you get this issue if you train without
-mapflag?
It has died in the same way before without the -map flag, but seemed like a much rarer occurrence. Have never had this issue with Joe's repo
Can you run
./darknet detector map...successfully without errors?
Yes
What parameters do you use in the Makefile?
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=1
AVX=0
OPENMP=0
LIBSO=0
Are there files bad.list or bad_label.list?
No
Can you show output of these commands?
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Tue_Jun_12_23:07:04_CDT_2018
Cuda compilation tools, release 9.2, V9.2.148
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.93 Driver Version: 410.93 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:01:00.0 On | N/A |
| 44% 64C P2 121W / 250W | 3539MiB / 11172MiB | 72% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 960 G /usr/lib/xorg/Xorg 307MiB |
| 0 2641 G compiz 213MiB |
| 0 18880 G ...quest-channel-token=7822038591548515382 135MiB |
| 0 24295 G ...Downloads/pycharm-2018.3/jre64/bin/java 9MiB |
| 0 31211 C ./darknet 2869MiB |
+-----------------------------------------------------------------------------+
It definitely seems like its a ram thing because when it dies I only have about 500mb ram left, and its not other processes the darknet process's memory use grows as I train
readicculus
on 15 Feb 2019
@readicculus
Have never had this issue with Joe's repo
Just because Joe's repo can't train a model with higher network resolution when random=1, because there is hardcoded network size range 320x320 - 608x608: https://github.com/pjreddie/darknet/blob/61c9d02ec461e30d55762ec7669d6a1d3c356fb2/examples/detector.c#L65
So it doesn't reuqire so much CPU-RAM and GPU-RAM.
But it will give you very low accuracy when you will try to detect using width=1024 height=1024 in cfg-file.
It definitely seems like its a ram thing because when it dies I only have about 500mb ram left, and its not other processes the darknet process's memory use grows as I train
Are you about CPU or GPU ram?
Just train your model either with width=1024 height=1024 random=0
or with width=704 height=704 random=1
AlexeyAB
on 15 Feb 2019
Are you about CPU or GPU ram?
Talking about cpu-ram
Ok thanks! Still don't totally understand why memory goes up throughout training(starts at 5gb used by darknet dies when ~11gb used by darknet, other 5gb used by other processes I have running) but I'll try with random=0, and smaller images.
readicculus
on 15 Feb 2019
training now with random=0 and cpu-ram used seems to be staying around 4.1gb for the last 1,000 iters! Also mAP is improving with random=0.. wonder if its because my objects are relatively the same size within each class +-20px at most
readicculus
on 15 Feb 2019
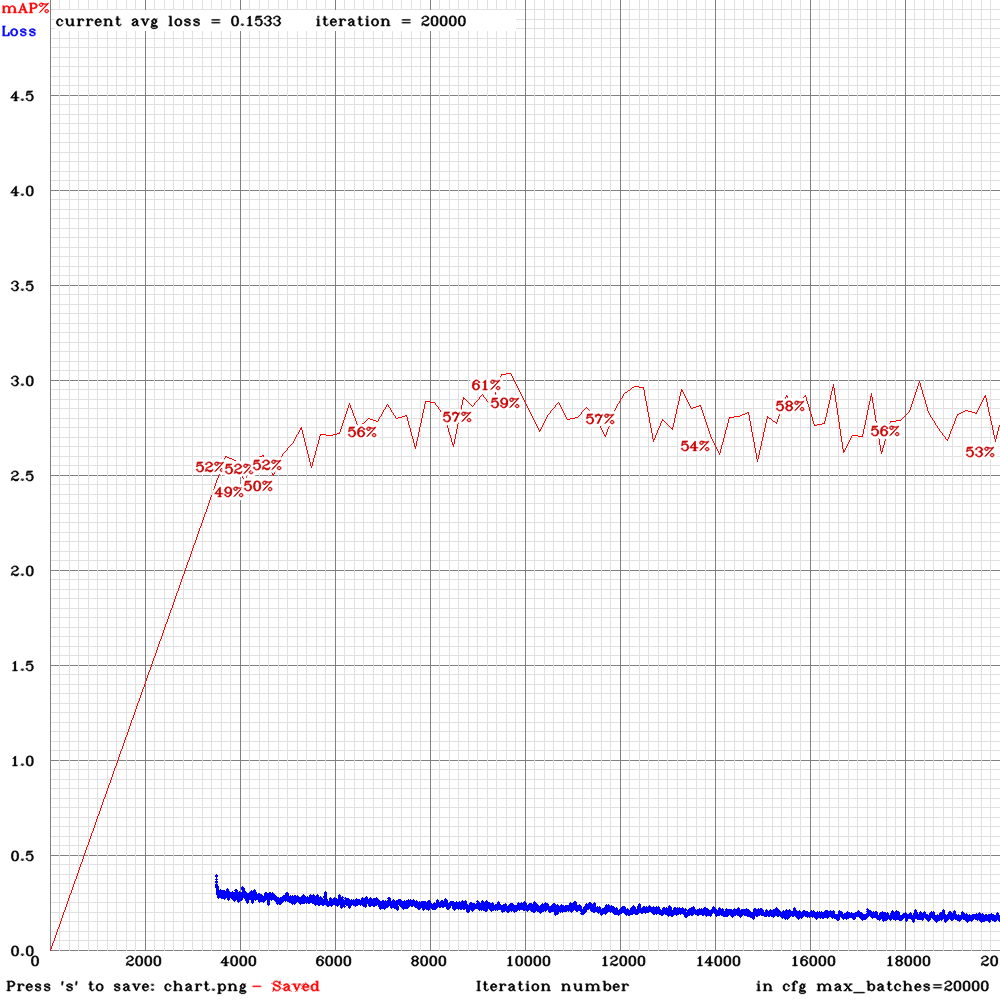
Here's my loss chart, went a bit higher than 50% using the yolov3-tiny-3l instead of yolov3 but doing the same thing it was before where it maxes out pretty early on with this dataset. Currently have about half negative training images would there be a benefit in increasing/decreasing negative examples? I get better accuracy with less negative examples but worse results in the field.
readicculus
on 15 Feb 2019
Currently have about half negative training images would there be a benefit in increasing/decreasing negative examples?
It depends on ratio of TP/FP/FN that you get by using ./darknet detector map...
Try to train yolov3-spp.cfg with batch=64 subdivisions=64 width=640 height=640 hue=.01 random=0 and all the rest default parameters.
AlexeyAB
on 15 Feb 2019
calculation mAP (mean average precision)...
1020
detections_count = 1138, unique_truth_count = 644
class_id = 0, name = Ringed, ap = 47.95 %
class_id = 1, name = Bearded, ap = 63.16 %
for thresh = 0.25, precision = 0.80, recall = 0.36, F1-score = 0.49
for thresh = 0.25, TP = 231, FP = 59, FN = 413, average IoU = 58.61 %
IoU threshold = 50 %
mean average precision ([email protected]) = 0.555555, or 55.56 %
Total Detection Time: 13.000000 Seconds
and from what I can tell F1, FP, TP, FN are calculated with IoU thresh of 0.25 so evaluating with the default map thresholds should be a good representation of what I'm going for as I don't need boxes to be great but do need them to mark the location of the objects. I'll try with the spp model now, thanks again for helping me out.
Also its odd I get higher AP on the Bearded Seal class as there are only 500 labels instead of 2500 for the Ringed. Should I try the spp model without focal loss?
readicculus
on 15 Feb 2019
Heres my run with spp model with only the changes you said, get 15pts more than before so thats something
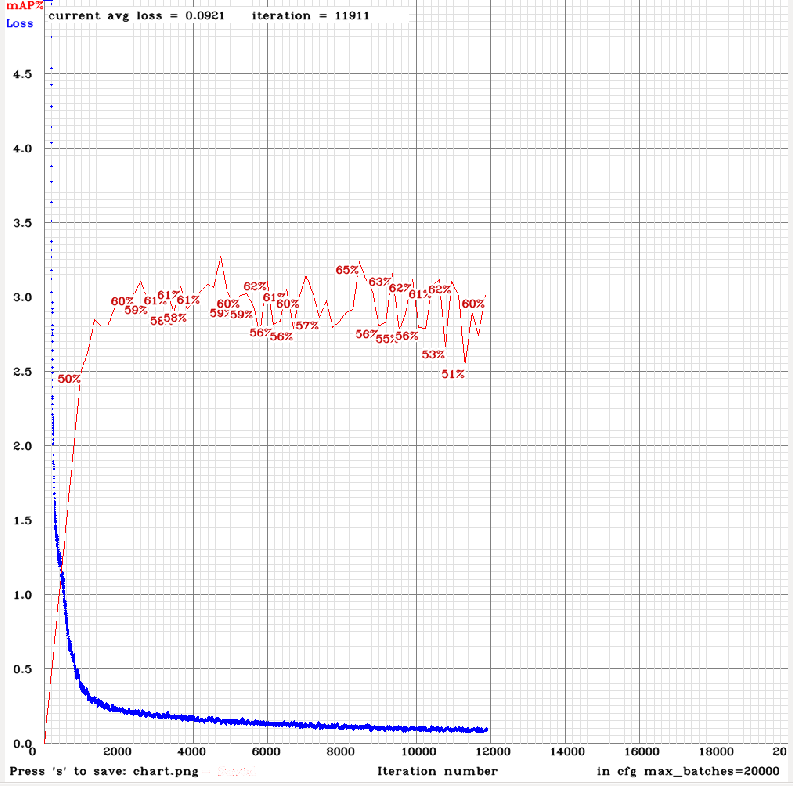
calculation mAP (mean average precision)...
868
detections_count = 1059, unique_truth_count = 657
class_id = 0, name = Ringed, ap = 58.51 %
class_id = 1, name = Bearded, ap = 66.57 %
for thresh = 0.25, precision = 0.85, recall = 0.52, F1-score = 0.65
for thresh = 0.25, TP = 342, FP = 60, FN = 315, average IoU = 63.79 %
IoU threshold = 50 %
mean average precision ([email protected]) = 0.625407, or 62.54 %
Total Detection Time: 21.000000 Seconds
I thing I need to maybe use less negatives in training but maintain the same in testing(?), the FP rate is more than acceptable, the FN rate is far higher than my goal
readicculus
on 16 Feb 2019
@readicculus
Also its odd I get higher AP on the Bearded Seal class as there are only 500 labels instead of 2500 for the Ringed. Should I try the spp model without focal loss?
Yes, try to train without focal_loss.
and from what I can tell F1, FP, TP, FN are calculated with IoU thresh of 0.25 so evaluating with the default map thresholds should be a good representation of what I'm going for as I don't need boxes to be great but do need them to mark the location of the objects. I'll try with the spp model now, thanks again for helping me out.
F1, FP, TP, FN are calculated with Confidence-thresh of 0.25.
Just try to run checking mAP with lower Confidence-threshold:
./darknet detector map... -thresh 0.15
or
./darknet detector map... -thresh 0.10
Also there is not implemented yet - rotation data augmentation for Detection (it is implemented only for Classification).
Rotation data augmentation can help in your case. So you can try to implement it by yourself.
AlexeyAB
on 16 Feb 2019
Related issues
 Mididou
·
3Comments
Mididou
·
3Comments
 Greta-A
·
3Comments
Greta-A
·
3Comments
 siddharth2395
·
3Comments
siddharth2395
·
3Comments
 jasleen137
·
3Comments
jasleen137
·
3Comments
 off99555
·
3Comments
off99555
·
3Comments