hi~
I would like to ask about yolo2_light project
yolo2_light project is very powerful research
If I want to download 8 bit weights, how should I do it?
 DIAMONDWHILE
DIAMONDWHILE
All 17 comments
@DIAMONDWHILE Hi,
Currently yolo2_light loads Float-32 weights and convert it to the Int-8 in run-time, if you use flag -quantized: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L1427-L1445
It happens once during initialization, so I havn't added such feature to store/load INT-8 weights yet.
Why do you want to load/store INT-8 weights instead of FP32?
 AlexeyAB
on 15 Aug 2018
AlexeyAB
on 15 Aug 2018
hi~
In the hardware design required to use the int-8 weight, so could you teach me how to download INT-8 weights?
By the way,
In the darknet
Whether to convert image values from 0 ~ 255 to 0 ~1 before calculating CNN
DIAMONDWHILE
on 17 Aug 2018
Whether to convert image values from 0 ~ 255 to 0 ~1 before calculating CNN
No. Calculation should be proecessed using INT8 (weights, inputs, calculation).
Simplified convolution algorithm by using INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L670-L721
The same, but optimized convolutional algorithm by using GEMM implemented by AVX on INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L308-L381
To download INT8-weights, you should do these functions: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/main.c#L160-L170
And then use such code:
void save_weights_int8(network net, char *filename, int cutoff)
{
fprintf(stderr, "Saving weights to %s\n", filename);
FILE *fp = fopen(filename, "wb");
if(!fp) file_error(filename);
int major = 0;
int minor = 1;
int revision = 0;
fwrite(&major, sizeof(int), 1, fp);
fwrite(&minor, sizeof(int), 1, fp);
fwrite(&revision, sizeof(int), 1, fp);
fwrite(net.seen, sizeof(int), 1, fp);
int i;
for(i = 0; i < net.n && i < cutoff; ++i){
layer l = net.layers[i];
if(l.type == CONVOLUTIONAL){
//save_convolutional_weights(l, fp);
int num = l.n*l.c*l.size*l.size;
fwrite(l.biases, sizeof(float), l.n, fp);
fwrite(l.weights_int8, sizeof(uint8_t), num, fp);
fwrite(l.weights_quant_multipler, sizeof(float), 1, fp);
fwrite(l.input_quant_multipler, sizeof(float), 1, fp);
}
}
fclose(fp);
Also you should convert INPUTS from float32 to int8 too, by using such code: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L552-L558
And you should keep 1st and last layers float32, for other layers you can use int8: https://arxiv.org/abs/1603.05279v4
AlexeyAB
on 17 Aug 2018
Thank you for your answer.
Help me solve the problem, I wish you better and better.
DIAMONDWHILE
on 17 Aug 2018
@AlexeyAB @DIAMONDWHILE
When quantize float weights to INT8 weights, Why the return value of the function get_multiplier() is divided by 4? What it means?
float old_weight_mult = get_multiplier(l->weights, weights_size, 8) / 4; // good [2 - 8], best 4
float weights_multiplier_single = old_weight_mult;
l->weights_quant_multipler = weights_multiplier_single;
for (fil = 0; fil < l->n; ++fil) {
for (i = 0; i < filter_size; ++i) {
float w = l->weights[fil*filter_size + i] * l->weights_quant_multipler;// [fil];
l->weights_int8[fil*filter_size + i] = max_abs(w, W_MAX_VAL);
//l->weights_int8[fil*filter_size + i] = max_abs(lround(w), W_MAX_VAL);
}
}
 TaihuLight
on 18 Aug 2018
TaihuLight
on 18 Aug 2018
HI~
@TaihuLight Sorry, I don't know this because I want to get the results first.
@AlexeyAB I didn't get any results when I executed tiny-yolo.cfg and saved INT8.weights.
DIAMONDWHILE
on 18 Aug 2018
@TaihuLight
When quantize float weights to INT8 weights, Why the return value of the function get_multiplier() is divided by 4? What it means?
Dirty hack, magic value )
I got the best mAP for any model with it:
- For Weights -
get_multiplier() / 4;is better than get_multiplier(bins histogram) or entropy-callibration (Kullback-Leibler divergence that is used in TensorRT).
- For Inputs - the best is
entropy_calibration()- entropy-callibration (Kullback-Leibler divergence that is used in TensorRT).
AlexeyAB
on 18 Aug 2018
@AlexeyAB
When quantize float weights to INT8 weights, Why the return value of the function get_multiplier() is divided by 4? What it means?
Dirty hack, magic value )
I got the best mAP for any model with it:
- For Weights -
get_multiplier() / 4;is better than get_multiplier(bins histogram) or entropy-callibration (Kullback-Leibler divergence that is used in TensorRT).- For Inputs - the best is
entropy_calibration()- entropy-callibration (Kullback-Leibler divergence that is used in TensorRT).
I was about to give up on yolo2_light (as in this thread: https://github.com/AlexeyAB/darknet/issues/726#issuecomment-431888536, thinking that it is not working for my dataset, but then I found this thread and after several trial and error, I tuned the return value of the function get_multiplier() to be divided by 25 is giving me the best mAP closer to "without quantized" flag...The existing division by '4' was giving me way low mAP!!
Now, if I have to believe that the mAP depends on this division factor, that looks very very magical indeed!! So can I get some intuition as to why 25 worked for me rather than 4 for my dataset? Is it possible that my weights range in FP32 is very huge and by dividing that range by a bigger number like 25, helps to somehow squash this original distribution so that the linear mapping scale factor to INT8 gets optimized with little difference between INT8 and FP32 distributions? May be there are several larger values in the FP32 weight range that are getting clipped at INT8 min/max values with a smaller division factor like '4' ? Can I print the min/max values of the weight range for the FP32 distribution and validate this?
Also could you let me know if which portions of the code can I uncomment in yolov2_forward_network_quantized.c, so that I can check get_multiplier(bins histogram) or entropy-callibration.
 kmsravindra
on 23 Oct 2018
kmsravindra
on 23 Oct 2018
@kmsravindra
So did you use default input_calibration= from yolov3.cfg and just changed this line: https://github.com/AlexeyAB/yolo2_light/blob/f78f261c339eb1ed535dd9fe60a45ece68876701/src/yolov2_forward_network_quantized.c#L1427
float old_weight_mult = get_multiplier(l->weights, weights_size, 8) / 4;
to this float old_weight_mult = get_multiplier(l->weights, weights_size, 8) / 25; to get the best mAP? And what mAP did you get with -quantized?
Update your code from GitHub and uncomment some of these lines:
- https://github.com/AlexeyAB/yolo2_light/blob/f78f261c339eb1ed535dd9fe60a45ece68876701/src/yolov2_forward_network_quantized.c#L545-L546
- https://github.com/AlexeyAB/yolo2_light/blob/f78f261c339eb1ed535dd9fe60a45ece68876701/src/yolov2_forward_network_quantized.c#L616
You will see such image with distribution of values.
Red line - is the optimal multiplier (before it is divided by 4). So after applying this multiplier, this red line will be between -1 and 0 and all BINs (orange columns) will be shifted to the right. Then:
- all BINs (orange columns) higher than 7 will be merged with BIN-7
- all BINs (orange columns) lower than 0 will be merged with BIN-0
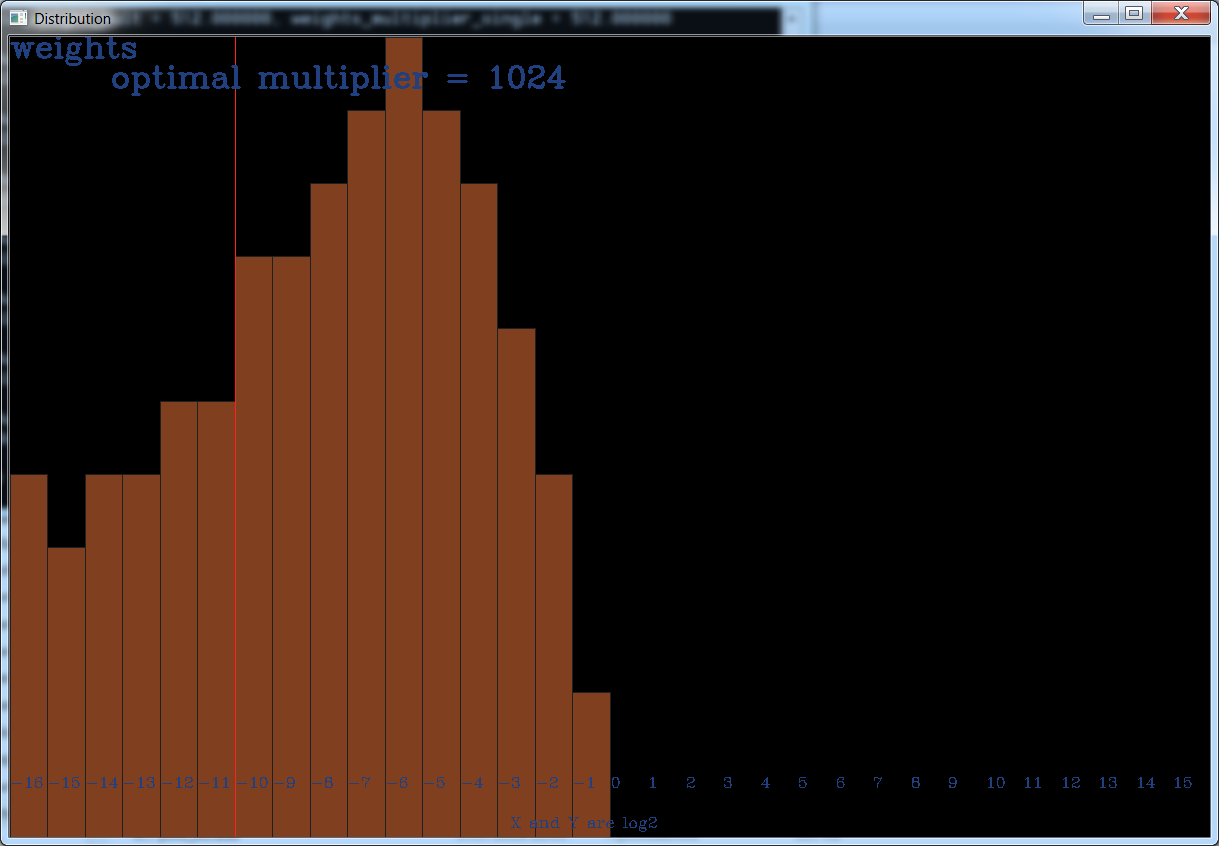
AlexeyAB
on 23 Oct 2018
@DIAMONDWHILE
I am trying to save INT8 weights and found this thread, did you figure out how to save INT8 weight yet?
 lynnw123
on 24 Oct 2018
lynnw123
on 24 Oct 2018
@AlexeyAB
So did you use default input_calibration= from yolov3.cfg
Yes
float old_weight_mult = get_multiplier(l->weights, weights_size, 8) / 25
That is correct.
And what mAP did you get with -quantized?
I got mAP = 89.57% on train dataset with -quantized. This is very near to 90.3% mAP that I got without quantized flag. With -quantized and with division factor of 4 it was giving something in higher 20% + mAP.
The only reason that I could think that mAP improved when I used division factor of 25 is may be my dataset has few weights outliers whose FP32 value is very large. So when you calculate max(weights), it picks up a very high value resulting in abnormal squashing of normal weight values when converted to INT8. Not sure if thresholding logic is working correctly...Also if you can tell me where in the code can I get the optimal multiplier using entropy calibration or an alternate technique (instead of this division by arbitrary number), may be I can try that and check my mAP values.
You will see such image with distribution of values.
Could you let me know what command do I need to run to see this image distribution? I used map and input_calibration commands but I could not get any image distribution graph.
kmsravindra
on 24 Oct 2018
@kmsravindra
Could you let me know what command do I need to run to see this image distribution? I used map and input_calibration commands but I could not get any image distribution graph.
You can use any command with -quantized flag. But you should compile on CPU. GPU=0
The only reason that I could think that mAP improved when I used division factor of 25 is may be my dataset has few weights outliers whose FP32 value is very large. So when you calculate max(weights), it picks up a very high value resulting in abnormal squashing of normal weight values when converted to INT8.
Yes. I assume that the distribution of your weights is more blurred, or higher values are more important for your data set.
You can try to comment these lines: https://github.com/AlexeyAB/yolo2_light/blob/f78f261c339eb1ed535dd9fe60a45ece68876701/src/yolov2_forward_network_quantized.c#L1427-L1428
And un-comment some of these lines - to use entropy calibration:
AlexeyAB
on 24 Oct 2018
@DIAMONDWHILE @TaihuLight @kmsravindra @lynnw123 where you guys able to save the int8 models , what was the final size of the model after conversion
 abhigoku10
on 15 Jul 2019
abhigoku10
on 15 Jul 2019
Whether to convert image values from 0 ~ 255 to 0 ~1 before calculating CNN
No. Calculation should be proecessed using INT8 (weights, inputs, calculation).
- Simplified convolution algorithm by using INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L670-L721
- The same, but optimized convolutional algorithm by using GEMM implemented by AVX on INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L308-L381
To download INT8-weights, you should do these functions: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/main.c#L160-L170
And then use such code:
void save_weights_int8(network net, char *filename, int cutoff) { fprintf(stderr, "Saving weights to %s\n", filename); FILE *fp = fopen(filename, "wb"); if(!fp) file_error(filename); int major = 0; int minor = 1; int revision = 0; fwrite(&major, sizeof(int), 1, fp); fwrite(&minor, sizeof(int), 1, fp); fwrite(&revision, sizeof(int), 1, fp); fwrite(net.seen, sizeof(int), 1, fp); int i; for(i = 0; i < net.n && i < cutoff; ++i){ layer l = net.layers[i]; if(l.type == CONVOLUTIONAL){ //save_convolutional_weights(l, fp); int num = l.n*l.c*l.size*l.size; fwrite(l.biases, sizeof(float), l.n, fp); fwrite(l.weights_int8, sizeof(uint8_t), num, fp); fwrite(l.weights_quant_multipler, sizeof(float), 1, fp); fwrite(l.input_quant_multipler, sizeof(float), 1, fp); } } fclose(fp);@AlexeyAB
How do i use those "such code"?
write in "main.c"?!
I can't compile on "yolo_cpu.sln" with Visual Studio 2017
please help me(tiro)
Thanks
 w840401
on 12 Aug 2020
w840401
on 12 Aug 2020
在計算CNN之前是否將圖像值從0〜255轉換為0〜1
不能。應使用INT8進行計算(權重,輸入,計算)。
- 使用INT8的簡化卷積算法:https : //github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L670-L721
- 使用AVX在INT8上實現的GEMM進行了相同但優化的捲積算法:https : //github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L308-L381
要下載INT8權重,您應該執行以下功能:https : //github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/main.c#L160-L170
然後使用這樣的代碼:
void save_weights_int8(網絡net,char *文件名,int截止) { fprintf(stderr,“將權重保存到%s \ n ”,文件名); FILE * fp = fopen(文件名“ wb ”); 如果(!fp)file_error(文件名); int major = 0 ; int minor = 1; int版本= 0 ; fwrite(&major,sizeof(int),1,fp); fwrite(&minor,sizeof(int),1,fp); fwrite(&revision,sizeof(int),1,fp); 的fwrite(淨看出,的sizeof(INT),1,fp的); 詮釋 I; 對於(i = 0 ; i <淨n && i <截止; ++ i){ l層=淨 層 [i]; 如果(升類型 ==卷積){ // save_convolutional_weights(1,FP); int num = l。n * l c * l。尺寸 * l。大小 ; 的fwrite(升。偏見,的sizeof(浮動),升。Ñ,FP); fwrite(l。weights_int8,sizeof(uint8_t),num,fp); fwrite(l。weights_quant_multipler,sizeof(float),1,fp); fwrite(l.input_quant_multipler,sizeof(float),1,fp); } } fclose(fp);另外,您也應該使用以下代碼將INPUTS從float32轉換為int8:https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L552-L558
並且您應該將第一層和最後一層保持為float32,對於其他層,您可以使用int8:https ://arxiv.org/abs/1603.05279v4
Please Help me!
How can I add "save_weights_int8" this function??
Add where!?
in "main.c"? or..?
Thanks!! @AlexeyAB
w840401
on 17 Sep 2020
Thank you for your answer.
Help me solve the problem, I wish you better and better.
Can you tell me how to add save_weights_int8 function??
Please and Thanks.. @DIAMONDWHILE
w840401
on 17 Sep 2020
@AlexeyAB
I am trying to save INT8 weights and found this thread, did you figure out how to save INT8 weight yet?
w840401
on 17 Sep 2020
Related issues
 Jacky3213
·
3Comments
Jacky3213
·
3Comments
 off99555
·
3Comments
off99555
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 louisondumont
·
3Comments
louisondumont
·
3Comments
 qianyunw
·
3Comments
qianyunw
·
3Comments
Most helpful comment
No. Calculation should be proecessed using INT8 (weights, inputs, calculation).
Simplified convolution algorithm by using INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L670-L721
The same, but optimized convolutional algorithm by using GEMM implemented by AVX on INT8: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L308-L381
To download INT8-weights, you should do these functions: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/main.c#L160-L170
And then use such code:
Also you should convert INPUTS from float32 to int8 too, by using such code: https://github.com/AlexeyAB/yolo2_light/blob/781983eb4186d83e473c570818e17b0110a309da/src/yolov2_forward_network_quantized.c#L552-L558
And you should keep 1st and last layers float32, for other layers you can use int8: https://arxiv.org/abs/1603.05279v4