Darknet: Changing input size from 416x416 to 104x104
I want to change tiny yolo v3 input size from 416x416 to 104x104 because I have small images and I want it to train faster. What parts of this file do I need to change?
Usually, in the yolo v2 model, I would just remove some max pooling layers and it would be fine. Now, this cfg file is complicated and I don't know where to start.
So if possible, please help me comment some maxpool layers or make it appropriately correct for the input size I described.
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=2
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=414
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=133
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=414
activation=linear
[yolo]
mask = 1,2,3
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=133
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
 off99555
off99555
All 13 comments
use
width=128 height=128without removing layers (width and height should be multiple of 32): https://github.com/AlexeyAB/darknet/blob/e29fcb703f8d936e17507bf78043a8b8bc6279b0/cfg/yolov3-tiny.cfg#L8-L9also you can decrease
filters=512or256in this layer: https://github.com/AlexeyAB/darknet/blob/e29fcb703f8d936e17507bf78043a8b8bc6279b0/cfg/yolov3-tiny.cfg#L99and you should fix it: https://github.com/AlexeyAB/darknet/blob/e29fcb703f8d936e17507bf78043a8b8bc6279b0/cfg/yolov3-tiny.cfg#L175
tomask = 0,1,2
If you will remove downsampling layers such as max-pool layers with stride=2 - it will increase resulotion of the subsequent layers and it will be decrease performance.
 AlexeyAB
on 17 May 2018
AlexeyAB
on 17 May 2018
What does the mask do? When do I need to change it?
Do I need to change it if I didn't change width and height to 128?
off99555
on 17 May 2018
What does the mask do? When do I need to change it?
There is a bug, it should be: mask = 0,1,2 - this is indecies of anchors that will be used for this [yolo] layer
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
So will be used bolded anchors in this yolo-layer.
AlexeyAB
on 17 May 2018
Yeah, so if it's a bug then it should be 0,1,2 always regardless of input size right?
And if it's a bug why don't we change it for everyone inside the repo by committing it?
off99555
on 17 May 2018
@off99555 not so simple) File https://pjreddie.com/media/files/yolov3-tiny.weights trained for mask = 1,2,3 so it will work incorrect with mask = 0,1,2. We are waiting for the new yolov3-tiny.weights
AlexeyAB
on 17 May 2018
Ah, I see. So if I am training from scratch without any pre-trained weights, I should use mask=0,1,2. But if I use the pre-trained weights provided by darknet as of now, I need to use mask=1,2,3.
All of these are regardless of input size. Am I right?
off99555
on 17 May 2018
If you train your own network (regardless of with or without any pre-trained weights) then use mask=0,1,2
If you use exactly yolov3-tiny.weights and exactly for Detection, then use mask=1,2,3
AlexeyAB
on 17 May 2018
Thank you. I have another error. It's when I train the model 128x128 to detect 133 classes.
Command:
./darknet detector train data/ch.data ./cfg/yolov3-tiny-ch.cfg -dont_show
Head of the output:
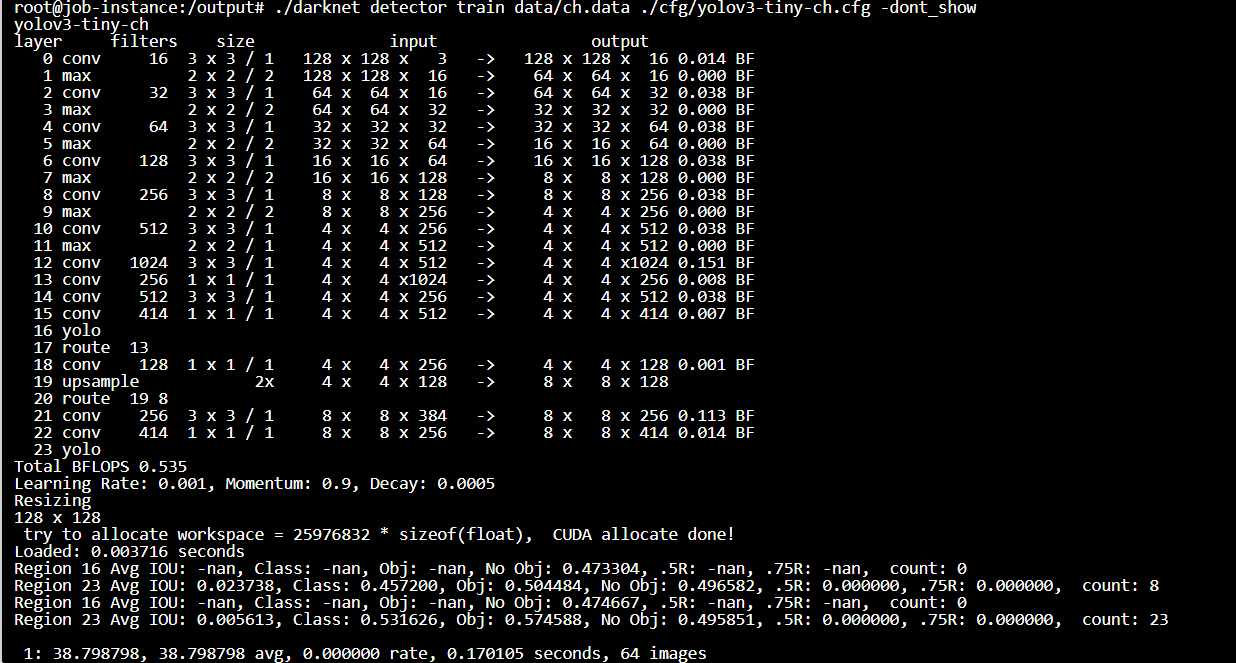
Tail of the output:
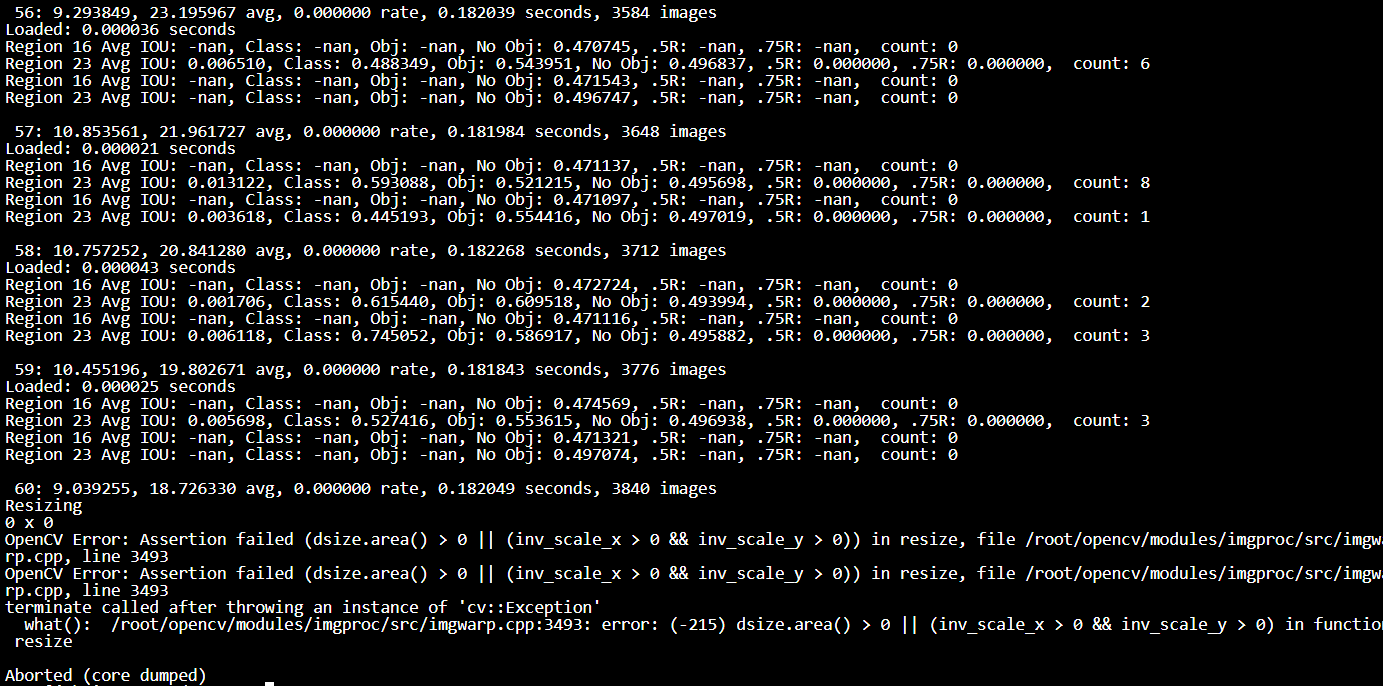
Cfg file:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=2
width=128
height=128
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=414
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=133
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=414
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=133
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
What does resizing mean? I saw the number changes randomly. E.g. for the model 416x416, sometimes I saw it say resizing 500x500 something.
off99555
on 17 May 2018
I fixed it. Update your code from this GitHub repository.
When you set random=1 then for each 10 iterations the network will be resized randomly +-160 pixels. It allows to train such that it can detect object with different sizes.
AlexeyAB
on 17 May 2018
Thanks. My image is already difficult enough to recognize, so if I don't want it to decrease my image size then I change random=0 on those 2 random variables right?
off99555
on 17 May 2018
Yes, you can set random=0 in each yolo-layers.
AlexeyAB
on 17 May 2018
OK. Resolved.
off99555
on 18 May 2018
Related issues
 kebundsc
·
3Comments
kebundsc
·
3Comments
 zihaozhang9
·
3Comments
zihaozhang9
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 bit-scientist
·
3Comments
bit-scientist
·
3Comments
 Cipusha
·
3Comments
Cipusha
·
3Comments
Most helpful comment
@off99555 not so simple) File https://pjreddie.com/media/files/yolov3-tiny.weights trained for
mask = 1,2,3so it will work incorrect withmask = 0,1,2. We are waiting for the newyolov3-tiny.weights