Darknet: How the YOLO training works internally?
I was wondering what would happen if I forgot to label some instances of class objects in the training images. This, of course, depends on how the training is done.
Does YOLO train:
- using only the labeled objects (training only with the regions of images with objects);
- using the whole image itself as its training data.
My idea:
Case (1) - If YOLO trains using only the cells (in the S * S grid) containing a labeled object, then it would not be a problem if I forget to label some instances of objects.
Case (2) - In this case, all the objects must be labeled for it to learn properly. During training, if the network predicted that class correctly it would still get penalized for it since that class is not in the ground-truth.
 Cartucho
Cartucho
All 9 comments
As @AlexeyAB said in many different issues
(For instance: https://github.com/AlexeyAB/darknet/issues/615)
"It is very bad if there are unlabelled objects (which you want to detect)."
So I think case 2 is the right scenario.
 frvalentini
on 19 Apr 2018
frvalentini
on 19 Apr 2018
@Cartucho @ralek67
Case 2:
Look at this code - Yolo iterates across whole final feature map (width, height, anchors):
for (j = 0; j < l.h; ++j) {
for (i = 0; i < l.w; ++i) {
for (n = 0; n < l.n; ++n) {
//...
int obj_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 4);
avg_anyobj += l.output[obj_index]; // l.output[obj_index] is objectness T0
l.delta[obj_index] = 0 - l.output[obj_index];
if (best_iou > l.ignore_thresh) {
l.delta[obj_index] = 0;
}
I.e.:
- if (iou > ignore_thresh) then
delta = 0 - if (iou <= ignore_thresh) then
delta = -objectness (T0)
So if there isn't object, then iou = 0 and iou < ignore_thresh then delta = -objectness (T0), i.e. objectness is decreased - i.e. Yolo learns to don't detect this not-labled object.
So all objects should be labled for good training.
Source code: https://github.com/AlexeyAB/darknet/blob/c2c8595b083ec3586a99bb913b8a986e81e3a42a/src/yolo_layer.c#L194-L215
 AlexeyAB
on 19 Apr 2018
AlexeyAB
on 19 Apr 2018
@AlexeyAB
Thank you for the quick and detailed response!
Btw, this video also helps understanding the training:
Cartucho
on 19 Apr 2018
@AlexeyAB so I think the training works this way:
1) YOLO was previously trained on ImageNet at different scales, so that's why we download the pre-trained convolutional weights.
2) When trained on ImageNet it learns to predict objects in an image (independently of their specific classes).
3) Then (when we train) YOLO uses these predictions and fine tunes the detection of objects: changing the class probabilities and adjusting the bounding boxes.
Cartucho
on 12 May 2018
@Cartucho
If absolutely to simplify then you are right. But to be more precise:
ImageNet the biggest dataset that has millions of images, so neural network learns to know all possible shapes of objects in its feature maps (convolutional weights). Therefore we get only first N-layers that knows shapes of objects rather than whole objects.
So we get only first 23 layers, without the last convolutional layer: https://pjreddie.com/darknet/yolov2/
./darknet partial cfg/darknet19_448.cfg darknet19_448.weights darknet19_448.conv.23 23By default Yolo does Transfer-learning rather than Fine-tuning (if we doesn't use
stopbackward=1)Fine-tuning - if we train only last convolutional layer (usually is used validation dataset that has the same distribution and the same classes as training dataset that was used to get pre-trained weights)
Transfer-learning / Domain-Adaptation - if we train whole neural network (all layers) and uses for this such dataset that has different distribution and different classes than in dataset that was used to get pre-trained weights.
AlexeyAB
on 12 May 2018
@AlexeyAB Thank you!
I made a summary of how YOLO training works. Would you like me to share it?
Cartucho
on 12 May 2018
@Cartucho Yes
AlexeyAB
on 12 May 2018
ImageNet is currently the biggest dataset for Computer Vision tasks like object detection. It includes millions of images capturing 1000 different object classes in their natural scenes. When we train YOLO to detect our own custom object classes we usually have a small training set. Remarkably, YOLO was pre-trained on the ImageNet dataset. During this pre-train, YOLO learned to convert the objects in millions of images into a feature map (convolutional weights). Therefore, when YOLO trains it adapts these convolutional weights to detect our custom object classes in the training set images. Specifically, it applies a technique called Transfer-Learning (also known as Domain-Adaptation). This allows us to get a good performance even with a small training set.
Since YOLO predicts all the existing instances of objects from a single full image it also has to train on full images. First, given a training image coupled with the ground-truth labels, YOLO matches these labels with the appropriate grid cells. This is done by calculating the center of each bounding box and wherever grid cell that center falls in that will be the one responsible for predicting that detection. Then YOLO adjusts that cell's class predictions (e.g. in Figure 1 we want it to predict ``dog") and its bounding box proposals. The bounding box overlapping the most with the ground-truth label will have its confidence score increased (e.g. the one with the green arrow in Figure 1) and its coordinates adjusted while the remaining boxes will simply get their confidence score decreased (e.g. the one with the red arrow in Figure 1) since they don't properly overlap the object.
Figure 1:
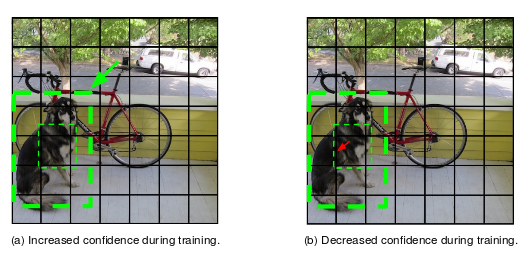
Some remaining cells do not have any ground-truth detections assigned to them. In this case, all the predicted bounding boxes' confidence is decreased, since they are not responsible for predicting any object. One important thing to note is that in this case, YOLO does not adjust the class probabilities or coordinates for the proposed bounding boxes since there are not any actual ground-truth objects assigned to that cell.
Overall the training of this network is pretty straightforward and corresponds to a lot of standards in the Computer Vision community: YOLO pre-trains on ImageNet; uses stochastic gradient descent; and uses data augmentation. For the data augmentation, YOLO randomly scales and translates of up to 20\% of the original image size and also randomly adjusts the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
Cartucho
on 12 May 2018
On a simple, everything is written correctly.
Some additions:
ImageNet is currently the biggest dataset for Computer Vision tasks like object classification. We pre-train Darknet53-classification-network on Imagenet, and use this pre-trained weights except for the last layer to train YoloV3-detection-network.
also randomly adjusts the exposure and saturation of the image by up to a factor of 1.5 and hue by up to a factor 0.1 in the HSV color space.
AlexeyAB
on 12 May 2018
Related issues
 HanSeYeong
·
3Comments
HanSeYeong
·
3Comments
 Greta-A
·
3Comments
Greta-A
·
3Comments
 Cipusha
·
3Comments
Cipusha
·
3Comments
 kebundsc
·
3Comments
kebundsc
·
3Comments
 Mididou
·
3Comments
Mididou
·
3Comments
Most helpful comment
ImageNet is currently the biggest dataset for Computer Vision tasks like object detection. It includes millions of images capturing 1000 different object classes in their natural scenes. When we train YOLO to detect our own custom object classes we usually have a small training set. Remarkably, YOLO was pre-trained on the ImageNet dataset. During this pre-train, YOLO learned to convert the objects in millions of images into a feature map (convolutional weights). Therefore, when YOLO trains it adapts these convolutional weights to detect our custom object classes in the training set images. Specifically, it applies a technique called Transfer-Learning (also known as Domain-Adaptation). This allows us to get a good performance even with a small training set.
Since YOLO predicts all the existing instances of objects from a single full image it also has to train on full images. First, given a training image coupled with the ground-truth labels, YOLO matches these labels with the appropriate grid cells. This is done by calculating the center of each bounding box and wherever grid cell that center falls in that will be the one responsible for predicting that detection. Then YOLO adjusts that cell's class predictions (e.g. in Figure 1 we want it to predict ``dog") and its bounding box proposals. The bounding box overlapping the most with the ground-truth label will have its confidence score increased (e.g. the one with the green arrow in Figure 1) and its coordinates adjusted while the remaining boxes will simply get their confidence score decreased (e.g. the one with the red arrow in Figure 1) since they don't properly overlap the object.
Figure 1:
Some remaining cells do not have any ground-truth detections assigned to them. In this case, all the predicted bounding boxes' confidence is decreased, since they are not responsible for predicting any object. One important thing to note is that in this case, YOLO does not adjust the class probabilities or coordinates for the proposed bounding boxes since there are not any actual ground-truth objects assigned to that cell.
Overall the training of this network is pretty straightforward and corresponds to a lot of standards in the Computer Vision community: YOLO pre-trains on ImageNet; uses stochastic gradient descent; and uses data augmentation. For the data augmentation, YOLO randomly scales and translates of up to 20\% of the original image size and also randomly adjusts the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.