Darknet: Improving only certain classes of existing model?
Hello everyone.
What happens if you take a model and train it with images of only some of the classes?
So for instance, lets say i want to improve the detection of persons on the VOC model. If I take the VOC weights file and train it with images of persons, will the network forget how to detect the other classes?
If not, do I have to mark all objects in the new images? So if there are cars and persons, but i'm only interested in improving person detection, will not marking cars have a negative impact on car detection?
Thank you very much for your time.
 ykangpark
ykangpark
All 6 comments
I'm waiting for exactly the same answer, partially.. though your questions adds a perspective.
Two posts ago, right here: #385
If I figure it out I will reach back and answer.
 SJRogue
on 12 Feb 2018
SJRogue
on 12 Feb 2018
@ykangpark Current VOC network is trained for 20 classes, with 125 filters in the final convolution layer. So as long as the you keep these 125 filters and try to improve for only 1 class (ex: person class in your case), the model will get biased towards person class. The detection performace of other classes will degrade but it will not be completely forgotten.
If you do not want to detect other classes, you can do the following:
- Modify the last conv layer
filters=30(for 1 class) in your cfg file. - Load the current VOC weights upto the n-1 layer (where n is the total number of layers).
- Train the network, this will fine tune only the last convolution layer to detect the required objects
 sivagnanamn
on 13 Feb 2018
sivagnanamn
on 13 Feb 2018
Adding an example to @sivagnanamn excellent answer:
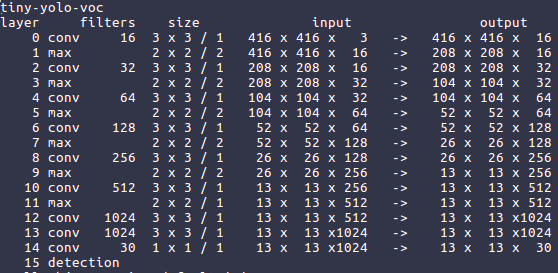
darknet.exe partial cfg-file.cfg weight-file-to-cut.weights output-name.conv.X Xwhere x is the n-1 layer, when loading network you can see the amount of layers. You want to cut before the finale layer, In the screenshot I'm detecting one class, so my finale layer is 30 filters. If I want to get a partial cut from this cfg I would do thisdarknet.exe partial tiny-yolo-voc.cfg tiny-yolo-voc.weights tiny-yolo-voc.conv.13 13
 TheMikeyR
on 13 Feb 2018
TheMikeyR
on 13 Feb 2018
@TheMikeyR @sivagnanamn Thank you for your time.
If you could clarify a bit more, i'd be grateful.
For simplicity, let's say I have a model trained with 3 classes: monitor, keyboard, mouse.
I want to improve mouse detection and I have a new set of images i'll mark and feed into the network.
I could do 2 things here:
- Mark only mice in all images.
- Mark the mice, but also the other classes.
Let's say that, coincidentally, the new image set turned out to contain mice and keyboards, but not monitors.
I can see how number 1 would lead to degradation. In an image with a mouse and a keyboard, the NN would predict there is a keyboard, but since the training data says there is no keyboard, the NN would be adjusted accordingly.
But I can't see how the second case would lead to degradation. If the NN is trained with an image that has a mouse and keyboard marked properly, those two classes should be improved, and the monitor class should at least stay the same or improve towards avoiding false positives.
Or maybe the interconnected nature of a NN makes it this way?...
ykangpark
on 13 Feb 2018
For simpler understanding, let's assume that the NN has just 3 sets of filters.
Ex: Set A ==> Learns only Mouse features
Set B ==> Learns only Keyboard features
Set C ==> Learns only Monitor features
Now you've already trained your network with 3 classes and the above mentioned 3 sets of filters are fully learnt.
Consider Case 2 scenario, the already trained NN will be re-trained with images that contain only mouse & keyboard (not monitor).
Remember the aim of the NN training is to reduce the loss. So the NN will tend to modify the already learnt Set C filters in-order to learn more Mouse/Keyboard features (in-turn reducing the training loss).
This will make the NN biased towards only Mouse,keyboard and degrade the performance for Monitors.
sivagnanamn
on 14 Feb 2018
@sivagnanamn @TheMikeyR @SJRogue Thank you for your time..
ykangpark
on 15 Feb 2018
Related issues
 Jacky3213
·
3Comments
Jacky3213
·
3Comments
 yongcong1415
·
3Comments
yongcong1415
·
3Comments
 Greta-A
·
3Comments
Greta-A
·
3Comments
 off99555
·
3Comments
off99555
·
3Comments
 shootingliu
·
3Comments
shootingliu
·
3Comments
Most helpful comment
For simpler understanding, let's assume that the NN has just 3 sets of filters.
Ex: Set A ==> Learns only Mouse features
Set B ==> Learns only Keyboard features
Set C ==> Learns only Monitor features
Now you've already trained your network with 3 classes and the above mentioned 3 sets of filters are fully learnt.
Consider Case 2 scenario, the already trained NN will be re-trained with images that contain only mouse & keyboard (not monitor).
Remember the aim of the NN training is to reduce the loss. So the NN will tend to modify the already learnt Set C filters in-order to learn more Mouse/Keyboard features (in-turn reducing the training loss).
This will make the NN biased towards only Mouse,keyboard and degrade the performance for Monitors.