Darknet: Weight Model size reduction / optimization
@pjreddie @lilohuang @tjluyao The model size which i trained for the custom dataset is around 63.5Mb for 6 class , i need to reduce the model size as much as possible . Can you suggest a way where i can reduce the model size either by changing the network or by using some compressor???? from my survey i came across SqueezeDet, do u have the cfg file and weight file for it so tat i can train on it .
Pls suggest, thankyou in advance
 abhigoku10
abhigoku10
All 26 comments
The easiest thing to do is simply use a smaller network with less parameters. See this page for an explanation how to make sure your network doesn't have as much parameters.
If you're knowledgeable about programming, you could try to alter the Darknet source so it stores the weights with less digits after the decimal point; I read some time ago it hardly affects the prediction accuracy, and it makes it easier to compress the weights, because there will be more parameters with exactly the same value.
 Fred-Erik
on 8 Dec 2017
Fred-Erik
on 8 Dec 2017
The model size which i trained for the custom dataset is around 63.5Mb for 6 class
It looks like you are using a model Tiny-Yolo: https://github.com/pjreddie/darknet/blob/80d9bec20f0a44ab07616215c6eadb2d633492fe/cfg/tiny-yolo-voc.cfg
i need to reduce the model size as much as possible
Just try to remove these 3 layers: https://github.com/pjreddie/darknet/blob/80d9bec20f0a44ab07616215c6eadb2d633492fe/cfg/tiny-yolo-voc.cfg#L88-L108
and you will get cfg-file for 6 MB model (instead of 60 MB model) like this: https://drive.google.com/file/d/1u5KaBgjfWjRxPk1-ZV1qfLBKnBa6Ojsn/view
 AlexeyAB
on 8 Dec 2017
AlexeyAB
on 8 Dec 2017
@AlexeyAB i have done this and currently put it on training thanks for the suggestion . With this would the accuracy come down ????
abhigoku10
on 11 Dec 2017
@Fred-Erik the page u suggested are the architectures for the classification . i need the architecture model for detection . can u suggest some other solution?
abhigoku10
on 11 Dec 2017
So basically the architecture I'm proposing is similar to tiny-yolo, but with 1x1 convolutions in between like tiny-darknet uses. This reduces the overall dimensionality of the model drastically, and its the same technique SqueezeNet (and SqueezeDet) use. You can easily use the architecture of tiny.cfg and make it a detection network by copying the [convolutional] parts of tiny.cfg and the rest of tiny-yolo.cfg. Make sure to also use the very last [convolutional] layer from tiny-yolo.cfg, because that determines your classes (but you already must have altered that one if you altered the number of classes, see AlexeyAB's excellent guide.
Fred-Erik
on 11 Dec 2017
@Fred-Erik Thanks for the suggesting the method . I am not able to find the squeezeNet/ SqueezeDet.cfg file can you pls share it / or the location where it is available??
abhigoku10
on 11 Dec 2017
I can be a little clearer, sorry. I mean this tiny.cfg, which uses the same squeeze-excite setup as squeezenet. Combine it with tiny-yolo.cfg.
Fred-Erik
on 11 Dec 2017
@Fred-Erik as suggested i combine tiny.cfg and tiny-yolo.cfg by replacing all the convolution layers besides the last one so now i am putting it for training , but squeezenet has different architecture like fire layer and all , i donot have have the cfg file for that , so was asking if you knw which one to use
abhigoku10
on 11 Dec 2017
Squeezenet's fire layers are just 1x1 convolutions followed by 3x3 convolutions.
Fred-Erik
on 11 Dec 2017
@Fred-Erik yes, do u have tat cfg files or should we code from scratch can you please let me know , if you have it , it would be really helpfull
abhigoku10
on 11 Dec 2017
I'm sorry, I don't have it. The configuration you now have should perform similarly to SqueezeDet, but if you really want the exact same network (in what I can only assume to be for benchmarking purposes), you'll have to make the .cfg yourself. Take a look at an existing implementation in for example Tensorflow and I'm sure you'll figure it out. :)
Fred-Erik
on 11 Dec 2017
@Fred-Erik tq fred i shall try it and get back to u if i have some issues
abhigoku10
on 11 Dec 2017
@Fred-Erik i converted the squeezedet from tensor flow to the .cfg file similar to tiny.cfg i have couple of questions during conversion .
- should retain the inputs like
[net]
batch=64
subdivisions=8
width=416
height=416
channels=3
2.Should i regenerate the anchors
- The expand layer is 1x1 filters sequential followed by 3x3 filters convolutional filter?
- The layers
[avgpool]
[softmax]
groups=1
[cost]
type=sse
[region]
should be added after the last layer, in the cfg file similar to tiny.cfg???
abhigoku10
on 12 Dec 2017
- Yeah that's fine. If you want an even smaller (faster) model you can also reduce the width and height
- I think it depends on the sort of model you're training how much it will improve performance, but it definitely won't hurt.
- The original paper has 1x1 filters followed by 1x1 and 3x3 filters together. I don't think it will improve it much, but if you want to do it like that, you need to make a 1x1 layer (the squeeze part), then a 1x1 layer (part of the expand part), then bypass that layer, do a 3x3 conv on that, and then add the 2 layers together (one with 3x3 convs on the 1x1 output and one with 1x1 convs on the 1x1 output). You can read a bit more about how to do that here.
- No definently not. You should use the part from tiny.cfg up to line 160 and then add the last bit of tiny-yolo.cfg starting with line 115, and then alter it to match your number of classes as explained here.
Fred-Erik
on 13 Dec 2017
@Fred-Erik i created a squeezedet.cfg file based on the link suggested, the size of the model is 20Mb, i thought it will be around ~4Mb . Should i decrease the image input width and height will tat decrease the model size
abhigoku10
on 13 Dec 2017
No, that won't help, the number of weights needed to be stored will be the same. The increased file size is could be due to the way Darknet works, I'm not sure.
Fred-Erik
on 13 Dec 2017
@abhigoku10 Hi, were you able to get the model to fit your training data? I tried the option mentioned by @Fred-Erik by combining tiny.cfg & tiny-yolo.cfg (as explained in his previous comment - point 4). But model isn't converging. I'm training on a custom dataset with 10 classes & the avg loss if fluctuating around ~11.
[net]
# Train
batch=64
subdivisions=2
height=416
width=416
channels=3
momentum=0.9
decay=0.0005
max_crop=320
learning_rate=0.001
policy=poly
power=4
max_batches=1600000
angle=7
hue=.1
saturation=.75
exposure=.75
aspect=.75
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=16
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=16
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear
[region]
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
bias_match=1
classes=10
coords=4
num=5
softmax=1
jitter=.2
rescore=0
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .6
random=0
 sivagnanamn
on 23 Jan 2018
sivagnanamn
on 23 Jan 2018
@sivagnanamn i tried with the option suggested my model was converging but there were not detection where happening at all even after changing the thresholds and other parameters. After tat i didnot pursue it too deep .Pls let me knwo if ur successful in this
abhigoku10
on 24 Jan 2018
I am looking into model compression of tiny-yolo as well. Thanks all and I will try it out and let you know the results.
 patrick-ucr
on 25 Jan 2018
patrick-ucr
on 25 Jan 2018
Hi, I removed the last three layers of TinyYolo as @AlexeyAB suggested. Good news is that the file size of weights reduce 10x but unfortunately, this compressed network does not detect any object in data/ like horse.jpg, dog.jpg, etc. Any suggestion?
I will try tiny-darknet version tomorrow.
patrick-ucr
on 26 Jan 2018
Before compression,
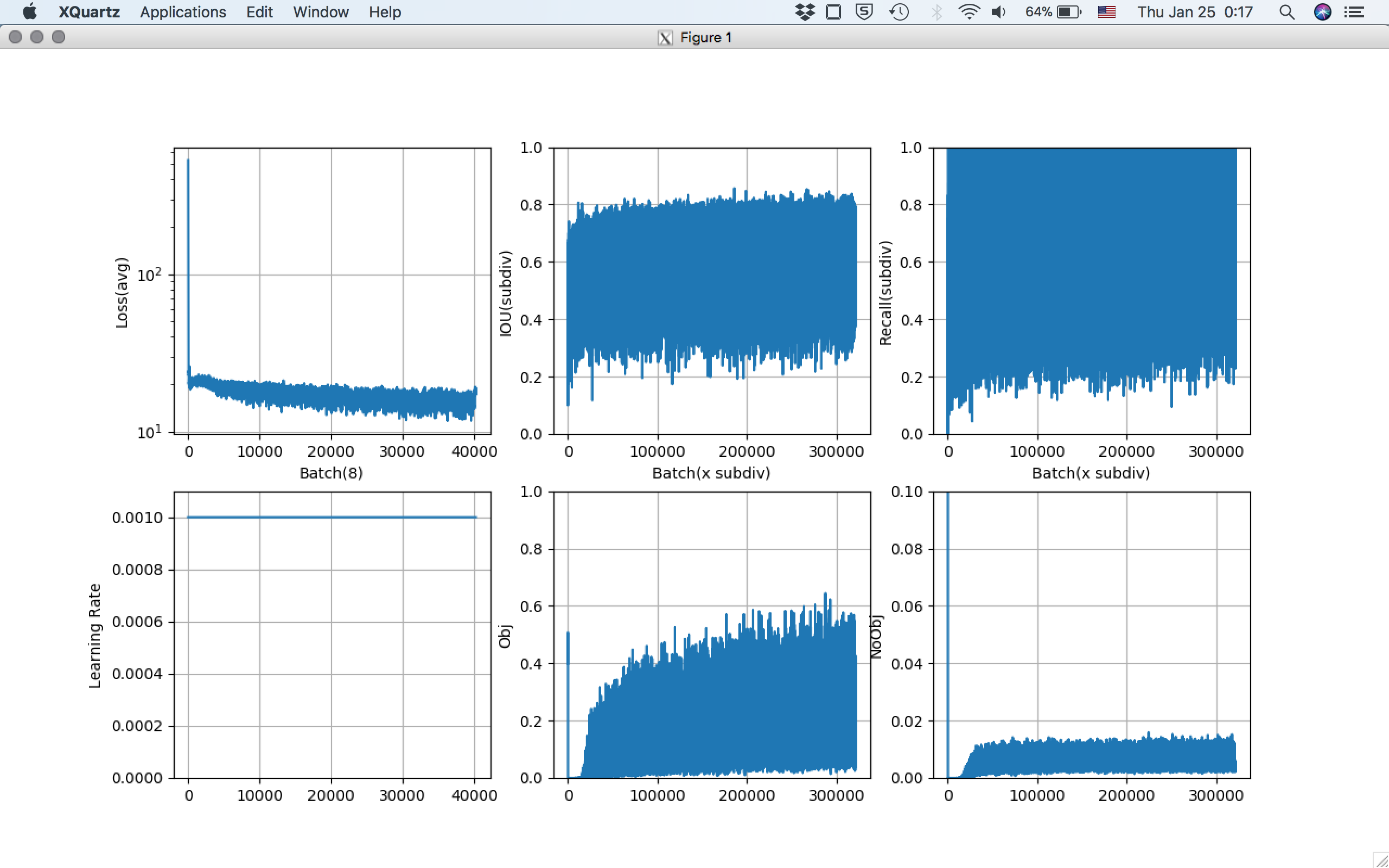
After compression,
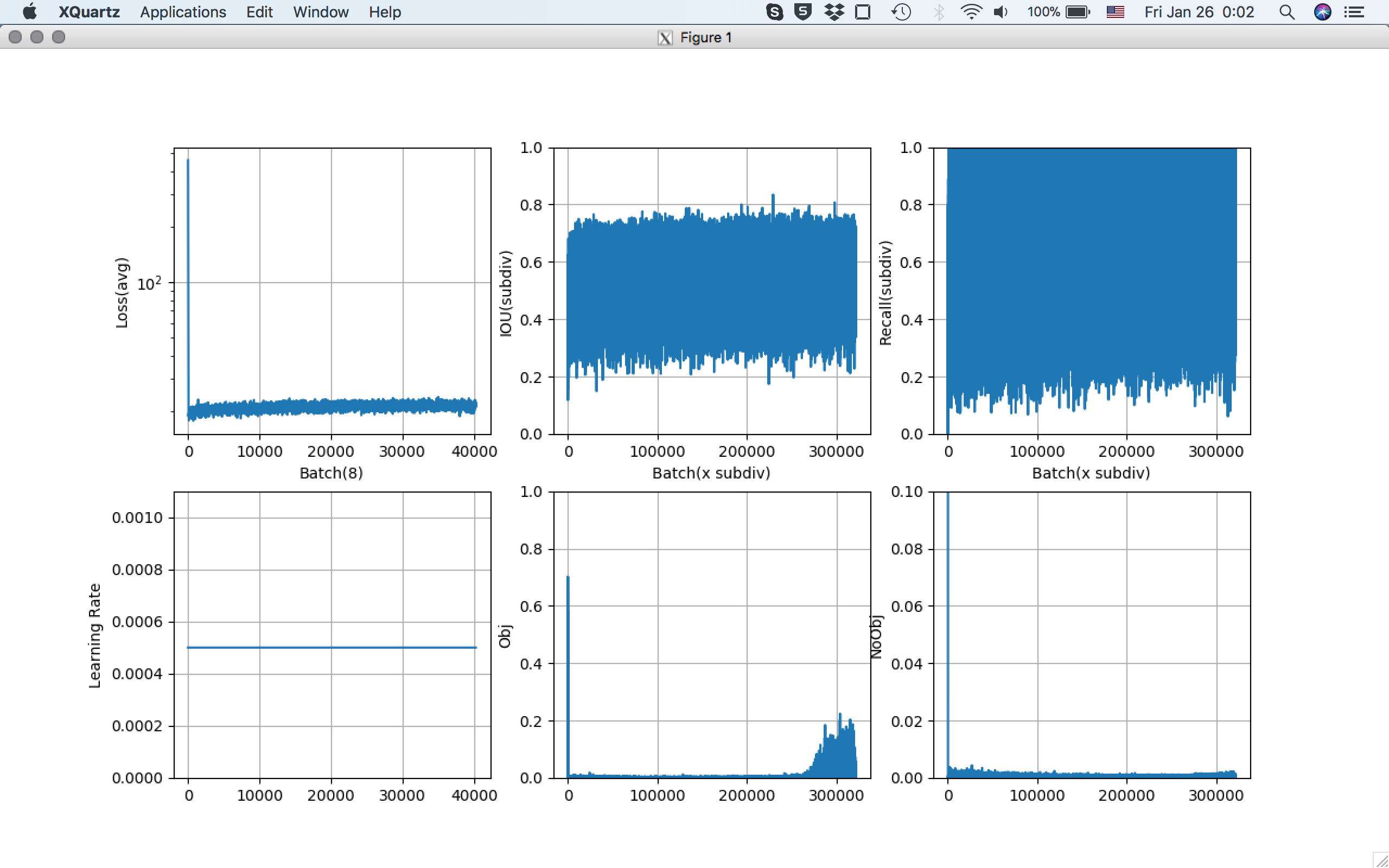
Object detection rate seems to be very very low.
patrick-ucr
on 26 Jan 2018
@patrick-ucr
Guessing you have to training the model again after remove those 3 layers, so, when you train the model, do you have the horse and dog classes in your training data? If not, the model won't label these classes for you.
Sorry if I this is too obvious and not helpful, just trying to help.
 xzhub
on 14 Jun 2018
xzhub
on 14 Jun 2018
Why would you bother reducing the model size (in MB) when as far as I understand what matters is the amount of parameters. Based on this, the darknet reference model does better than tiny darknet, that is not tiny yolo! More details here.
 martinbel
on 27 Nov 2018
martinbel
on 27 Nov 2018
@martinbel we wanted to reduce the model since the size of the model is directly proportional to the time consumed for prediction . When our use case has priority of high prediction time we use this tiny yolo
abhigoku10
on 27 Nov 2018
The problem is "the model size" is too vague. The network architecture, the amount of parameters, the model size regarding the amount of FLOPS is what determines the inference time.
For my applications tiny yolo is just too large, I even train a model with less parameters. As someone already mentioned above, you are better off training a different network with less parameters. Squeeze net, has a smaller model size in MB but this doesn't affect the amount of parameters. It's explained in the link above.
martinbel
on 28 Nov 2018
@AlexeyAB,@Fred-Erik
I am running my own object detection using tiny yolov2.I want to reduce weight file size as much as possible.Is there any way to do that without compromising the accuracy at all ?. Can somebody please tell me how to do that?
I used your solution of reducing three layers in tiny-yolo-voc.cfg file.My data is 2200+image with
their .txt files.Its only half of my data.Actually I want to train 5000 images.I am getting 60.5MB for each weight file for max_batch_size=4000.
 YadneshHande
on 24 Jul 2019
YadneshHande
on 24 Jul 2019
Related issues
 abeyang00
·
31Comments
abeyang00
·
31Comments
 AurusHuang
·
47Comments
AurusHuang
·
47Comments
 zsjerongdu
·
35Comments
zsjerongdu
·
35Comments
 MansourTrabelsi
·
44Comments
MansourTrabelsi
·
44Comments
 ssanzr
·
43Comments
ssanzr
·
43Comments
Most helpful comment
It looks like you are using a model Tiny-Yolo: https://github.com/pjreddie/darknet/blob/80d9bec20f0a44ab07616215c6eadb2d633492fe/cfg/tiny-yolo-voc.cfg
Just try to remove these 3 layers: https://github.com/pjreddie/darknet/blob/80d9bec20f0a44ab07616215c6eadb2d633492fe/cfg/tiny-yolo-voc.cfg#L88-L108
and you will get cfg-file for 6 MB model (instead of 60 MB model) like this: https://drive.google.com/file/d/1u5KaBgjfWjRxPk1-ZV1qfLBKnBa6Ojsn/view