Darknet: How to train my data with densnet201?
 ChuckGithub
ChuckGithub
All 11 comments
the same question, how to use the densnet201 weights and how to train
 wangqiqi
on 14 Sep 2017
wangqiqi
on 14 Sep 2017
To use densenet201:
- Update code from this repo
- download: https://pjreddie.com/media/files/densenet201.weights
- and run:
build\darknet\x64\classifier_densenet201.cmd
or use this command:darknet.exe classifier predict cfg/imagenet1k.data cfg/densenet201.cfg densenet201.weights - enter image filename:
dog.jpg

 AlexeyAB
on 14 Sep 2017
AlexeyAB
on 14 Sep 2017
@ChuckGithub @wangqiqi
So, if you want to train Densenet201 for object detection as Yolo (not for classify) then:
Download pre-trained weights
densenet201.300https://drive.google.com/open?id=0BwRgzHpNbsWBOFpORVB4UUtfT0UDownload cfg-file
densenet201_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBMXJLX3hHZllFdzQ
Or largerdensenet201_yolo2.cfg(+3 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBeTlpajNWc21jZ0kMake changes in
densenet201_yolo.cfgthe same as described here for yolo-voc.2.0.cfg: https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objectsi.e. change
filters=125in the last convolutional layer: https://github.com/AlexeyAB/darknet/blob/c48f8c157361e8d2edbf9af00a587ceb3be37059/build/darknet/x64/densenet201_yolo.cfg#L1944change
classes=20: https://github.com/AlexeyAB/darknet/blob/c48f8c157361e8d2edbf9af00a587ceb3be37059/build/darknet/x64/densenet201_yolo.cfg#L1951
Prepare your images dataset and launch training:
darknet.exe detector train data/obj.data densenet201_yolo.cfg densenet201.300When training iterations is equal to
~2000*number_of_objectsor more, then stop training: https://github.com/AlexeyAB/darknet#when-should-i-stop-trainingAnd run detection:
darknet.exe detector test data/obj.data densenet201_yolo.cfg backup/densenet201_yolo_300.weights -thresh 0.24
For classification task the network Densenet201 has higher precision than Darknet_448 (on which Yolo v2 is based), so probably you can achive more precision using densenet201_yolo.cfg instead of yolo-voc.cfg/yolo-voc.2.0.cfg: https://pjreddie.com/darknet/imagenet/
Probably Densenet201 should be a good solution for small and big objects - this network concatinate unchanged features from many scales using [route]-layers, so Densenet201 at the end has information about ~100 different scales.
But densenet201_yolo.cfg ~2x slower than yolo-voc.cfg.
(if you want more speed, try to decrease width=416 and height=416 in cfg to lower value multiple of 32)

https://arxiv.org/abs/1707.06990
On the ImageNet ILSVRC classification dataset, this large DenseNet obtains a state-of-the-art single-crop top-1 error of 20.26%.
Whereas traditional convolutional networks with L layers have L connections - one between each layer and its subsequent layer - our network has L(L+1)/2 direct connections. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers. DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters. We evaluate our proposed architecture on four highly competitive object recognition benchmark tasks (CIFAR-10, CIFAR-100, SVHN, and ImageNet). DenseNets obtain significant improvements over the state-of-the-art on most of them, whilst requiring less memory and computation to achieve high performance. Code and models are available at this https URL - CVPR 2017 (Best Paper Award): https://github.com/liuzhuang13/DenseNet
The idea of DenseNets is based on the observation that if each layer is directly connected to every other layer in a feed-forward fashion then the network will be more accurate and easier to train.
In this paper, we extend DenseNets to deal with the problem of semantic segmentation. We achieve state-of-the-art results on urban scene benchmark datasets such as CamVid and Gatech, without any further post-processing module nor pretraining. Moreover, due to smart construction of the model, our approach has much less parameters than currently published best entries for these datasets.
Code to reproduce the experiments is available here : https://github.com/SimJeg/FC-DenseNet/blob/master/train.py
AlexeyAB
on 15 Sep 2017
Thank you, @AlexeyAB , I will try DenseNet.
I have another question, have you ever heard or used mask image to speed the inference? The mask image maybe a white-black image, the black pixels needn't do conv ?
wangqiqi
on 16 Sep 2017
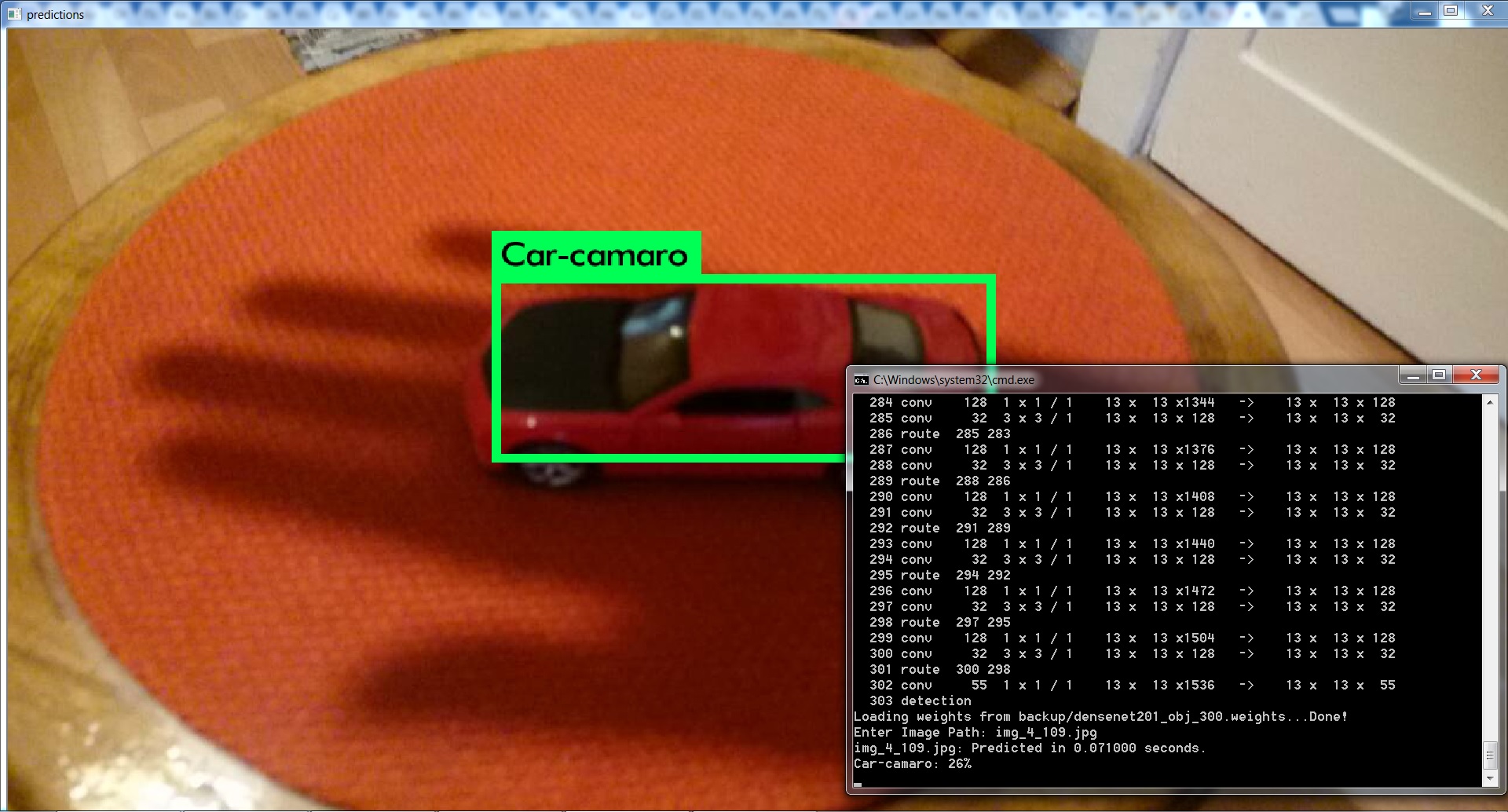
hello, @AlexeyAB, the densenet201_yolo_300.weights seems to be not good as the image below, because the iter is only 300, right?
wangqiqi
on 16 Sep 2017
@wangqiqi Hi,
Yes, you should train about ~2000 * number_of_classes iterations.
Also read: https://github.com/AlexeyAB/darknet/issues/196#issuecomment-329914554
You can use one of these cfg-files:
- cfg-file
densenet201_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBMXJLX3hHZllFdzQ - Or larger
densenet201_yolo2.cfg(+3 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBeTlpajNWc21jZ0k
I have another question, have you ever heard or used mask image to speed the inference? The mask image maybe a white-black image, the black pixels needn't do conv ?
Yes, I heared it. Darknet doesn't support it, but maybe someday I'll add this.
AlexeyAB
on 16 Sep 2017
I updated links to densenet201_yolo.cfg above.
Now for DenseNet201:
- pre-trained weights
densenet201.300https://drive.google.com/open?id=0BwRgzHpNbsWBOFpORVB4UUtfT0U - cfg file - use on of:
- cfg-file
densenet201_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBMXJLX3hHZllFdzQ - larger
densenet201_yolo2.cfg(+3 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBeTlpajNWc21jZ0k
- cfg-file
For ResNet50:
- pre-trained weights
resnet50.65https://drive.google.com/open?id=0BwRgzHpNbsWBemRnNTRJWjNIc28 - cfg file - use on of:
- cfg-file
resnet50_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBc2MtQXcxV29hTFU
- cfg-file
Comparison of the field of view for various networks:
receptive_field.xlsx
| Network name | receptive field of a single activation of the last layer, pixels |
|---|---|
| yolo-voc.cfg | 566 x 566 |
| tiny-yolo-voc.cfg | 318 x 318 |
| yolo9000.cfg | 545 x 545 |
| densenet201.cfg | 1934 x 1934 |
| densenet201-yolo.cfg | ~1934 x 1934 |
| densenet201-yolo2.cfg | ~1934 x 1934 |
| resnet50-yolo.cfg | 76 x 76 |
| resnet50.cfg | 72 x 72 |
| resnet101.cfg | 140 x 140 |
| resnet152.cfg | 208 x 208 |
resnet50-yolo.cfgcan be used only for small objects.densenet201-yolo.cfgcan be used for small and big objects.
Also DenseNet201 can be used for very big and very small objects using high resolution detector, for train and detect set in cfg-file:width=832 height=832, orwidth=1080 height=1080orwidth=1920 height=1920- if you have enough GPU-RAM.
AlexeyAB
on 17 Sep 2017
@AlexeyAB I have a question, how did you calculate the receptive field of a single activation of the last layer in the table above ?
 phongnhhn92
on 22 Sep 2017
phongnhhn92
on 22 Sep 2017
@AlexeyAB , I have the same question than @phongnhhn92
 iraadit
on 11 Oct 2017
iraadit
on 11 Oct 2017
How much gpu memeory dose densenet201-yolo need during trainning for input size 416? @AlexeyAB
I change the bese network to densenet201 for yolov3,but I can't train it for limited gpu memory.
 wait1988
on 3 Dec 2018
wait1988
on 3 Dec 2018
@AlexeyAB
On Windows I compile build\darknet\yolo_cpp_dll.sln to generate C++ DLL-file yolo_cpp_dll.dll.
Now I want to use darknet classifier predict function rather than detector.
Is there an API that I can use?
It seems that https://github.com/AlexeyAB/darknet/blob/master/include/yolo_v2_class.hpp and https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp only support detector.
Thanks.
 JamesChenChina
on 20 Apr 2019
JamesChenChina
on 20 Apr 2019
Related issues
 Cipusha
·
3Comments
Cipusha
·
3Comments
 siddharth2395
·
3Comments
siddharth2395
·
3Comments
 zihaozhang9
·
3Comments
zihaozhang9
·
3Comments
 rezaabdullah
·
3Comments
rezaabdullah
·
3Comments
 kebundsc
·
3Comments
kebundsc
·
3Comments
Most helpful comment
I updated links to
densenet201_yolo.cfgabove.Now for DenseNet201:
densenet201.300https://drive.google.com/open?id=0BwRgzHpNbsWBOFpORVB4UUtfT0Udensenet201_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBMXJLX3hHZllFdzQdensenet201_yolo2.cfg(+3 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBeTlpajNWc21jZ0kFor ResNet50:
resnet50.65https://drive.google.com/open?id=0BwRgzHpNbsWBemRnNTRJWjNIc28resnet50_yolo.cfg(+2 conv-layers): https://drive.google.com/open?id=0BwRgzHpNbsWBc2MtQXcxV29hTFUComparison of the field of view for various networks:
receptive_field.xlsx
| Network name | receptive field of a single activation of the last layer, pixels |
|---|---|
| yolo-voc.cfg | 566 x 566 |
| tiny-yolo-voc.cfg | 318 x 318 |
| yolo9000.cfg | 545 x 545 |
| densenet201.cfg | 1934 x 1934 |
| densenet201-yolo.cfg | ~1934 x 1934 |
| densenet201-yolo2.cfg | ~1934 x 1934 |
| resnet50-yolo.cfg | 76 x 76 |
| resnet50.cfg | 72 x 72 |
| resnet101.cfg | 140 x 140 |
| resnet152.cfg | 208 x 208 |
resnet50-yolo.cfgcan be used only for small objects.densenet201-yolo.cfgcan be used for small and big objects.Also DenseNet201 can be used for very big and very small objects using high resolution detector, for train and detect set in cfg-file:
width=832 height=832, orwidth=1080 height=1080orwidth=1920 height=1920- if you have enough GPU-RAM.