Cylc-flow: PoC - GraphQL endpoint Design & Implementation
Note: this is a Proof of Concept
I thought it would be a good idea to present this mock pull-request to provide insight and provoke discussion on the capability/design/implementation of GraphQL with Cylc, before the looming architectural decisions in the next workshop.
I provided an informal presentation to Bruno & Hilary a month ago, but was tied up with operations work until last week, so have found time to do this now.. It is a Work in Progress, happy to have more input.
GraphQL is agnostic to the server implementation, however, as Cherrypy does not have support (Tornado may have only recently added support via 3rd party) for GraphQL/Graphene (a python implementation of GraphQL) I chose Flask, with it's Flask-GraphQL extension (which includes the GraphiQL interface)..
I paired this with gevent for the purposes of this PoC; being at least as performant as Tornado, but easier to implement, leaving less of a footprint on Cylc's code. It also features web-socket capability, and proven to work with subscription type GraphQL queries (althoughonly HTTP is implemented in this branch (so far)).
The old REST endpoints remain in place, and I haven't migrated anything (gui or httpclient.py), to using this. I focused on the most important feature; mapping the tree to n depth with node data in one query, which will satisfy our requirement for a data driven web-gui (as @oliver-sanders outlined). The three main files where all the magic happens is GraphQL resource definition network/schema.py, the resolver filter functions scheduler.py, and the data cache created in state_summary_mgr.py.
I'll run through some examples, and encourage you to have a play ! :smiley:
The extra requirements:
Python:Flask-GraphQL (any).......................................................FOUND (?)
Python:Flask (any)...........................................................FOUND (1.0.2)
Python:Flask-HTTPAuth (any)..................................................FOUND (3.2.4)
Python:gevent (any)..........................................................FOUND (1.3.6)
Python:graphene (any)........................................................FOUND (2.1.3)
If you start a suite and visit the endpoint '/graphql' from your browser, i.e:
'https://niwa-35595lvm.niwa.local:43005/graphql' (using cylc:passphrase credentials)
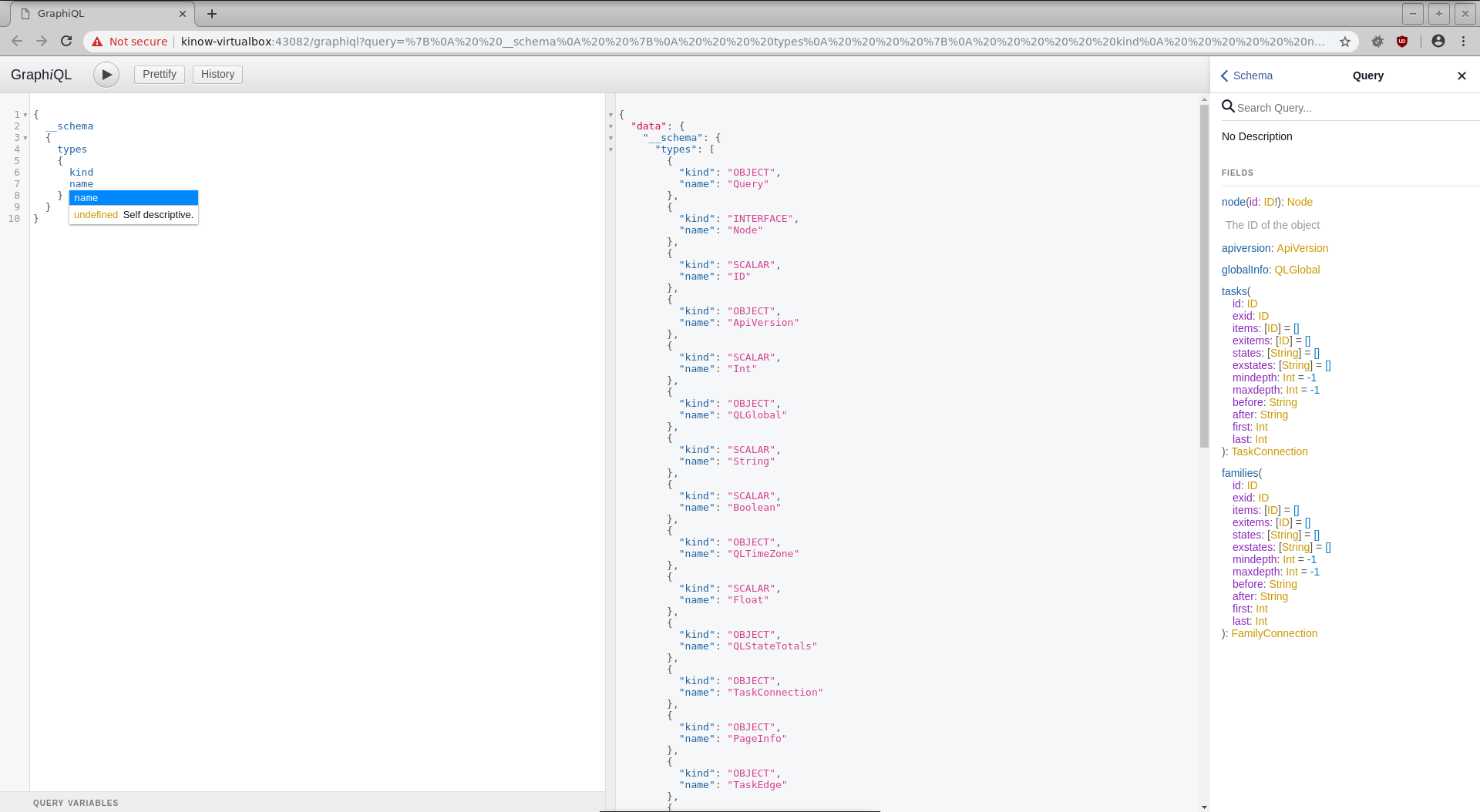
you'll be presented with an interface to discover and query your suite. Enter the following query, or even start typing it in (there's auto complete, drop down info available), but you can include or exclude as many fields as you desire;
{
globalInfo {
suite
owner
host
title
description
url
group
reloading
lastUpdated
status
runMode
newestRunaheadCyclePoint
newestCyclePoint
oldestCyclePoint
stateTotals{
held
queued
ready
waiting
submitted
submitFailed
submitRetrying
succeeded
failed
retrying
expired
running
runahead
}
treeDepth
}
}
then run it (ctrl+enter), and you'll see the result:

Although you can always use curl :wink:
curl -v -s -u cylc:$(cat /home/sutherlanddw/cylc-run/baz/.service/passphrase) --digest --cookie-jar cookietemp --anyauth --insecure --header "Content-Type: application/graphql" --data 'query{allTasks{edges{node{name label state}}}}' 'https://niwa-35595lvm.niwa.local:43005/graphql'
The documentation is very useful for discovering all the available data and filter fields.
Now, we could have a flat structure where we query all the tasks, and I've added some filters in addition to the usual task.point:state, you can include a list of these items or the converse exid & exitems, there is also states list and depth (aka node_depth, range from zero to specified):
{
allTasks(id: "[fqb]*.2017*", states: ["succeeded","waiting"], depth: 2) {
edges {
node {
id
name
label
state
title
description
URL
spawned
submittedTime
startedTime
finishedTime
meanElapsedTime
host
jobHosts{
submitNum
jobHost
}
outputs {
submitted
submitFailed
started
failed
succeeded
expired
}
nodeDepth
}
}
}
}
{
"data": {
"allTasks": {
"edges": [
{
"node": {
"id": "UUxUYXNrOmJhYS4yMDE3MDIwMVQwMDAwKzEz",
"name": "baa",
"label": "20170201T0000+13",
"state": "succeeded",
"title": "",
"description": "some task baa",
"URL": "",
"spawned": true,
"submittedTime": null,
"startedTime": null,
"finishedTime": null,
"meanElapsedTime": 10,
"host": "localhost",
"jobHosts": [
{
"submitNum": 1,
"jobHost": "niwa-35595lvm.niwa.local"
}
],
"outputs": {
"submitted": true,
"submitFailed": false,
"started": true,
"failed": false,
"succeeded": true,
"expired": false
},
"nodeDepth": 1
}
},
{
"node": {
"id": "UUxUYXNrOnF1eC4yMDE3MDEwMVQwMDAwKzEz",
"name": "qux",
"label": "20170101T0000+13",
"state": "succeeded",
"title": "Some Top family",
"description": "some task qux",
"URL": "",
"spawned": true,
"submittedTime": null,
"startedTime": null,
"finishedTime": null,
"meanElapsedTime": 20,
"host": "localhost",
"jobHosts": [
{
"submitNum": 1,
"jobHost": "niwa-35595lvm.niwa.local"
}
],
"outputs": {
"submitted": true,
"submitFailed": false,
"started": true,
"failed": false,
"succeeded": true,
"expired": false
},
"nodeDepth": 2
}
},
{
"node": {
"id": "UUxUYXNrOmJhYS4yMDE3MDEwMVQwMDAwKzEz",
"name": "baa",
"label": "20170101T0000+13",
"state": "succeeded",
"title": "",
"description": "some task baa",
"URL": "",
"spawned": true,
"submittedTime": null,
"startedTime": null,
"finishedTime": null,
"meanElapsedTime": 10,
"host": "localhost",
"jobHosts": [
{
"submitNum": 1,
"jobHost": "niwa-35595lvm.niwa.local"
}
],
"outputs": {
"submitted": true,
"submitFailed": false,
"started": true,
"failed": false,
"succeeded": true,
"expired": false
},
"nodeDepth": 1
}
}
]
}
}
}
md5-e831183700ee001042664572702adcba
{
allTasks(states: ["succeeded", "waiting"], first: 2, after: "YXJyYXljb25uZWN0aW9uOjA=") {
edges {
node {
name
label
state
title
nodeDepth
}
}
pageInfo{
hasPreviousPage
hasNextPage
startCursor
endCursor
}
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
{
"data": {
"allTasks": {
"edges": [
{
"node": {
"name": "baa",
"label": "20170201T0000+13",
"state": "succeeded",
"title": "",
"nodeDepth": 1
}
},
{
"node": {
"name": "foo",
"label": "20170101T0000+13",
"state": "succeeded",
"title": "Some Top family",
"nodeDepth": 4
}
}
],
"pageInfo": {
"hasPreviousPage": false,
"hasNextPage": true,
"startCursor": "YXJyYXljb25uZWN0aW9uOjE=",
"endCursor": "YXJyYXljb25uZWN0aW9uOjI="
}
}
}
}
md5-1ba432400751be4f40710b09f8522190
query allFamilies($vstates: [String]){
allFamilies(states: $vstates ){
edges{
node{
name
label
tasks(states: $vstates) {
edges {
node {
name
label
state
}
}
}
families(states: $vstates) {
edges {
node {
name
state
}
}
}
parents{
edges{
node{
name
}
}
}
}
}
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
{
"vstates": ["held", "succeeded"]
}
md5-4c00aa8f42908047e5cc0f7eb8f16d7a
query allFamilies($vstates: [String], $ndepth: Int){
allFamilies(states: $vstates, depth: $ndepth, items: ["root.*"]){
edges{
node{
name
label
tasks(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
}
}
}
families(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
tasks(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
}
}
}
families(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
tasks(states: $vstates) {
edges {
node {
name
state
}
}
}
families(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
tasks(states: $vstates, depth: $ndepth) {
edges {
node {
name
state
}
}
}
}
}
}
}
}
}
}
}
}
}
}
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
{
"vstates": ["held", "succeeded", "waiting"],
"ndepth": 4
}
The query could just be template'd out from the max tree depth given in the globalInfo query.. BTW it doesn't matter how deep your query is, the data will fill it out as far as it can (according to filters or w/e).
So, that's where I'm at, but there's not reason why we can't push forward with the GraphQL development.. There's still a lot I haven't tried yet, but just this alone is enough to convince me of it's utility...
 dwsutherland
dwsutherland
All 38 comments
This is a re-posting of the pull request:
https://github.com/cylc/cylc/pull/2873
dwsutherland
on 3 Dec 2018
@dwsutherland , having to learn a bit more of Relay in order to get it working with Vue. Looking at other Vue projects, looks like most devs are adopting Vue + Apollo.
Q1/ do you know if the only part that we are using of Relay is pagination?
Q2/ do you think it would be too much to implement pagination for Apollo instead?
The reasons for Q2 are for it being framework agnostic, but also due to the better integration with Vue (though the Vue + Relay might work, just need more time, but the project is maintained by 1 dev I think...).
I think Graphene offers easy support for Relay, which is nice. But if that's not too complicated to replace.... :grimacing:
 kinow
on 4 Dec 2018
kinow
on 4 Dec 2018
As we will likely use Tornado, we can combine
In the Tornado branch also had to change the scheduler.py due to the way Tornado's main loop works. So that would have to replicated (and tested) with GraphQL.
The Tornado + GraphQL seems pretty simple, and quite similar to FLask + GraphQL I think.
kinow
on 4 Dec 2018
@dwsutherland it worked! :tada:
Server with Tornado + graphene. Of course querying won't return anything as there's nothing in the scheduler.py. But I think if we go with the approach you suggested (i.e. Python3 => Tornado), then perhaps it would be just a matter of you replicating some changes from your flask branch over the new work.
Minor note; the packaging might be useful... tornado has 2 dependencies that I added manually here. But tornado-graphql has another three that would have to be added too... adding these dependencies manually is starting to look a bit weird.
kinow
on 5 Dec 2018
As we will likely use Tornado, we can combine ... the flask branch; the tornado branch; ....
@dwsutherland @kinow - just to note (for the record on this PR Issue) as discussed we don't know yet if GraphQL will be needed or used in the suite server program - as opposed the new UI Server component ... so if the aforementioned combining is done it will be to investigate the technologies further but not intended for merge. (And this PR should be closed and moved to an "exploratory" Issue with a link to the dev branch).
 hjoliver
on 5 Dec 2018
hjoliver
on 5 Dec 2018
I think that's what @dwsutherland did, @hjoliver.
kinow
on 5 Dec 2018
@kinow - you're right - apologies, my mistake! (The perils of checking in too late at night...). Amending previous comment...
hjoliver
on 5 Dec 2018
Not a problem. I did double check as I was replying in early morning too, pre coffee.
And
so if the aforementioned combining is done it will be to investigate the technologies further but not intended for merge
Well noted. And the changes that I did for Tornado's main loop in scheduler.py have not been well tested. Definitely not ready for merge.
kinow
on 5 Dec 2018
@dwsutherland , having to learn a bit more of Relay in order to get it working with Vue. Looking at other Vue projects, looks like most devs are adopting Vue + Apollo.
Q1/ do you know if the only part that we are using of Relay is pagination?
Q2/ do you think it would be too much to implement pagination for Apollo instead?The reasons for Q2 are for it being framework agnostic, but also due to the better integration with Vue (though the Vue + Relay might work, just need more time, but the project is maintained by 1 dev I think...).
I think Graphene offers easy support for Relay, which is nice. But if that's not too complicated to replace.... grimacing
Yes to both Q1 and Q2 (but proof is "in the pudding" so to speak), I guess it's just Vue that's the show stopper for the Relay compliant endpoint being used. But it appears Apollo claims to work with any endpoint:
https://github.com/apollographql/apollo-client
Universally compatible, so that Apollo works with any build setup, any GraphQL server, and any GraphQL schema.
We may need to just implement our own pagination and cursors.
Well done on the Tornado GraphQL-endpoint implement!
dwsutherland
on 5 Dec 2018
I've dropped the use of Relay;
SameBranch
for ease of use with Apollo-Vue (can be put back in place easily).
I've also tidied up the resolvers, so the Task/Family queries/Types all use the same function (at top of schema).
dwsutherland
on 18 Dec 2018
There’s one issue I’m trying to get my head around; meta data (suite/family/task) has a mix of predefined & custom/arbitrary defined fields, so you cannot specify them in general for suites in the schema definition (if it was an individual suite, then it might be possible to do it on start (but not reload, so not desirable)).. So we have a few options:
- Specify the whole meta as a JSON blob:
meta = graphene.JSON()
Which would mean you lose control of only pulling individual fields (i.e. just the title & description), and it means any query filters in the back end would need to parse the JSON. - Specify the default fields, and a custom JSON fields:
class QLMeta(graphene.ObjectType):
"""Meta data fields, and custom fields JSON blob"""
class Meta:
default_resolver = dict_resolver
title = graphene.String(default=None)
description = graphene.String(default=None)
group = graphene.String(default=None)
URL = graphene.String(default=None)
custom = graphene.JSON()
This would just mean an extra level in the data, and a json.dump of all fields that aren’t default.
- Having meta composed of key/value list:
[{“key”: “title”,”value”: “some suite”},{“key”….]
Which is worse than a JSON dump, but easier to fill.. - Having meta and custom_meta fields in the node def.
meta = graphene.Field(QLMeta)
custom_meta = graphene.JSON()
This would just reduce the depth while leaving meta more granular.
Perhaps to start 1 or 4.
I don’t think [meta]group has a corresponding [[[meta]]]group under runtime (but could include it as predefined for both I suppose).
There are other fields ([[[environment]]], [[[directives]]] ..etc) that more easily fit into the JSON blob category, if they are desired at the gui.
BTW - WRT the QL in front of the schema types; I can drop them and just use schema.Task externally for the sake of namespace (it was just an easy way to recognize what they were at a glance).
dwsutherland
on 18 Dec 2018
Some quick comments (with an old dinosaur hat on):
[meta]group should probably be retired? It was used to group suites in gscan but is not widely used. These days, suites can be registered with a directory hierarchy, so the functionality of group is less obvious.
[[[environment]]] and [[[directives]]] both need to be ordered. (E.g. an environment variable setting may reference another environment variable defined earlier. If our configuration file format has native support for list, these settings should probably be defined as lists.)
 matthewrmshin
on 18 Dec 2018
matthewrmshin
on 18 Dec 2018
So we have a few options
If I understand it correctly option 2 looks superior to me.
We aught to be able to pull the default fields individually (as we are likely to want to use this data in the GUI), if users want custom fields I see no harm in giving them the whole dictionary. I doubt anyone is likely to use the API for this anyway.
[meta]groupshould probably be retired?
 oliver-sanders
on 2 Jan 2019
oliver-sanders
on 2 Jan 2019
Been a long time coming, but I've made a lot of data structure changes (most satisfy recommendations), and now need more feedback/review:
(Note: all the nomenclature is up for change/review, i.e. if you don't like the use of proxy for task cycle point instance)
Task-Job Separation
This is actually a pseudo separation, although a true separation may be desirable in the future, and it involved:
- Creating a job type, stripping job specific fields from graphql task [proxy] type, and adding new job conf fields.
- Creating a new job pool
job_pool.py, to store and manage job data objects. - Populate the job objects on the back of job config and task proxy state/message management.
The full field query result being
{
"data": {
"jobs": [
{
"id": "20170101T0000+13/baa/01",
"batchSysJobId": "3338",
"batchSysName": "background",
"batchSysConf": {},
"directives": {},
"environment": {
"GREETING": "Hello from baa!"
},
"envScript": "echo \"Hi first, I'm second\"",
"errScript": "echo 'Boo!'",
"exitScript": "echo 'Yay!'",
"extraLogs": [
"/home/sutherlander/startrek/captains.log"
],
"executionTimeLimit": null,
"finishedTime": 1551516906,
"finishedTimeString": "2019-03-02T21:55:06+13:00",
"host": "localhost",
"initScript": "echo 'Me first'",
"jobLogDir": "/home/sutherlander/cylc-run/baz/log/job/20170101T0000+13/baa/01",
"owner": null,
"paramEnvTmpl": {},
"paramVar": {},
"postScript": "sleep 10",
"preScript": "sleep 10",
"script": "sleep 10; echo \"$GREETING\"",
"shell": "/bin/bash",
"startedTime": 1551516876,
"startedTimeString": "2019-03-02T21:54:36+13:00",
"state": "succeeded",
"submitNum": 1,
"submittedTime": 1551516876,
"submittedTimeString": "2019-03-02T21:54:36+13:00",
"workSubDir": null,
"taskProxy": {
"id": "baa.20170101T0000+13"
}
}
]
}
}
Of course you'd query from the task:
{
taskProxies(id: "baa.*") {
id
jobs {
id
state
submitNum
}
}
}
Result:
{
"data": {
"taskProxies": [
{
"id": "baa.20170201T0000+13",
"jobs": []
},
{
"id": "baa.20170101T0000+13",
"jobs": [
{
"id": "20170101T0000+13/baa/01",
"state": "succeeded",
"submitNum": 1
},
{
"id": "20170101T0000+13/baa/02",
"state": "failed",
"submitNum": 2
},
{
"id": "20170101T0000+13/baa/03",
"state": "running",
"submitNum": 3
}
]
}
]
}
}
Perhaps if the job objects were created prior to run, then they could be directly modified via the web gui (say for trigger-edit), and job script created from the object (perhaps with a true job-task separation).
Separation of Task/Family to definition & proxy/instance
This is to reduce the duplication of information, and distinguish between the abstract task/family and it's cycle point instance/proxy...
- The task/family types were split into def and proxy types and populated
state_summary_mgr.py.. - Meta type created and expanded on task def.
- Prerequisite type granulated/expanded on the task proxy
- Queries, arguments and resolver filter funtions added.
Query
{
tasks(id: "bar") {
meta {
title
description
URL
userDefined
}
proxies{
id
jobs {
id
state
submitNum
}
prerequisites {
expression
conditions{
taskId
exprAlias
reqState
satisfied
message
taskProxy{
state
}
}
satisfied
cyclePoints
}
}
}
}
Result
{
"data": {
"tasks": [
{
"meta": {
"title": "Some Top family",
"description": "some task bar",
"URL": "https://github.com/dwsutherland/cylc",
"userDefined": {
"importance": "Critical",
"alerts": "none"
}
},
"proxies": [
{
"id": "bar.20180101T0000+13",
"jobs": [
{
"id": "20180101T0000+13/bar/01",
"state": null,
"submitNum": 1
}
],
"prerequisites": [
{
"expression": "c0 | c1",
"conditions": [
{
"taskId": "foo.20180101T0000+13",
"exprAlias": "c0",
"reqState": "succeeded",
"satisfied": true,
"message": "unsatisfied",
"taskProxy": {
"state": "running"
}
},
{
"taskId": "qux.20180101T0000+13",
"exprAlias": "c1",
"reqState": "succeeded",
"satisfied": true,
"message": "satisfied naturally",
"taskProxy": {
"state": "succeeded"
}
}
],
"satisfied": true,
"cyclePoints": [
"20180101T0000+13"
]
},
{
"expression": "c0",
"conditions": [
{
"taskId": "bar.20171201T0000+13",
"exprAlias": "c0",
"reqState": "succeeded",
"satisfied": true,
"message": "satisfied naturally",
"taskProxy": {
"state": "succeeded"
}
}
],
"satisfied": true,
"cyclePoints": [
"20171201T0000+13"
]
}
]
},
{
"id": "bar.20171201T0000+13",
"jobs": [
.
.
.
So a query like:
{
taskProxies {
id
state
namespace
prerequisites {
conditions {
taskId
}
}
}
}
Would give you all the information required for the dependency graph.
The previously-mentioned/initial capabilities are still in place for the most part. And there are other optimisations I've made, and obviously more to come.. But next, and while waiting for review, I'll be working on:
- Pagination
- Mutations. And, as a sneak peak, I've added the all-in-one stop suite mutation:
class StopSuite(graphene.Mutation):
"""Stop the suite."""
class Arguments:
stop_type = graphene.String(required=True)
stop_item = graphene.String()
stop_args = graphene.List(graphene.String)
command_queued = graphene.Boolean()
def mutate(self, info, stop_type, stop_item=None, stop_args=[]):
if stop_type in ['now']:
stop_cmd = 'stop_now'
else:
stop_cmd = 'set_stop_' + stop_type
action = {}
for key in stop_args:
action[key] = True
item = ()
if stop_item:
item = (stop_item,)
schd = info.context.get('schd_obj')
schd.command_queue.put((stop_cmd,item,action))
return StopSuite(command_queued=True)
class Mutation(graphene.ObjectType):
stop_suite = StopSuite.Field()
mutation {
stopSuite(stopType: "after_task", stopItem: "baa.20170101T0000+13"){
commandQueued
}
}
- Websockets & Subscriptions (probably with a Tornado implementation)
- Authorisation/Privilege-Checking
I'll make general improvements along they way including; documentation/descriptions on the objects (which are available via the endpoint), functionality, sophistication/features and approach.. (perhaps protobuf objects instead of GraphQL objects to hold the data)
The repo will shift to cylc/wip-graphql at some point soon, but it's still here.
dwsutherland
on 1 Mar 2019
@dwsutherland Cool! I'm going to have to read your comment in detail.
A first minor suggestion. Perhaps change submitMethodId to batchSysJobId? (To align with fields in job.status.)
matthewrmshin
on 1 Mar 2019
@dwsutherland Cool! I'm going to have to read your comment in detail.
A first minor suggestion. Perhaps change
submitMethodIdtobatchSysJobId? (To align with fields injob.status.)
Done. (updated above)
dwsutherland
on 2 Mar 2019
Hi @dwsutherland , I'm trying your branch flask-gevent-graphql, and as always I'm trying to run my all-time favourite etc/examples/tutorial/cycling/five/suite.rc.
I am running it with cylc run --no-detach --verbose --debug five as I normally do, but it failed due to a local variable temp used before assignment.
kinow@kinow-VirtualBox:~/Development/python/workspace/cylc$ cylc run --no-detach five
._.
| | The Cylc Suite Engine [7.8.1-25-gb22c27b]
._____._. ._| |_____. Copyright (C) 2008-2019 NIWA
| .___| | | | | .___| & British Crown (Met Office) & Contributors.
| !___| !_! | | !___. _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
!_____!___. |_!_____! This program comes with ABSOLUTELY NO WARRANTY;
.___! | see `cylc warranty`. It is free software, you
!_____! are welcome to redistribute it under certain
2019-03-04T00:31:11Z INFO - Suite server: url=http://kinow-VirtualBox:43082/ pid=29417
2019-03-04T00:31:11Z INFO - Run: (re)start=0 log=1
2019-03-04T00:31:11Z INFO - Cylc version: 7.8.1-25-gb22c27b
2019-03-04T00:31:11Z INFO - Run mode: live
2019-03-04T00:31:11Z INFO - Initial point: 20130808T0000Z
2019-03-04T00:31:11Z INFO - Final point: 20130812T0000Z
2019-03-04T00:31:11Z INFO - Cold Start 20130808T0000Z
2019-03-04T00:31:11Z INFO - [prep.20130808T0000Z] -submit-num=1, owner@host=kinow-VirtualBox
2019-03-04T00:31:11Z ERROR - local variable 'temp' referenced before assignment
Traceback (most recent call last):
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/scheduler.py", line 269, in start
self.run()
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/scheduler.py", line 1783, in run
has_updated = self.update_state_summary()
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/scheduler.py", line 1826, in update_state_summary
self.state_summary_mgr.update(self)
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/state_summary_mgr.py", line 79, in update
self._get_tasks_info(schd, parents_dict, ancestors_dict))
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/state_summary_mgr.py", line 332, in _get_tasks_info
prereq_list.append(prereq.api_dump())
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/prerequisite.py", line 261, in api_dump
expression = temp,
UnboundLocalError: local variable 'temp' referenced before assignment
2019-03-04T00:31:11Z ERROR - error caught: cleaning up before exit
2019-03-04T00:31:11Z INFO - Suite shutting down - ERROR: local variable 'temp' referenced before assignment
2019-03-04T00:31:11Z INFO - DONE
Traceback (most recent call last):
File "/home/kinow/Development/python/workspace/cylc/bin/cylc-run", line 25, in <module>
main(is_restart=False)
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/scheduler_cli.py", line 134, in main
scheduler.start()
File "/home/kinow/Development/python/workspace/cylc/lib/cylc/scheduler.py", line 300, in start
raise exc
UnboundLocalError: local variable 'temp' referenced before assignment
Mutations. And, as a sneak peak, I've added the all-in-one stop suite mutation:
Cool!
I've separated the network implementation and interface in the python3 branch so (with a small change) you could write a simple adapter to map the network endpoints onto your GraphQL layer which would save having to duplicate the schd.command_queue.put((stop_cmd,item,action)) type logic.
Something along the lines of:
-class SuiteRuntimeServer(ZMQServer):
- """Suite runtime service API facade exposed via zmq."""
+class SuiteRuntimeInterface:
+ """Suite runtime service API facade."""
API = 4 # cylc API version
@@ -652,7 +652,7 @@ class SuiteRuntimeServer(ZMQServer):
return (True, 'Command queued')
@authorise(Priv.CONTROL)
- @ZMQServer.expose
+ @expose # and so on for all the others
def trigger_tasks(self, items, back_out=False):
"""Trigger submission of task jobs where possible.
@@ -664,3 +664,17 @@ class SuiteRuntimeServer(ZMQServer):
self.schd.command_queue.put(
("trigger_tasks", (items,), {"back_out": back_out}))
return (True, 'Command queued')
+
+
+class SuiteRuntimeServer(ZMQServer, SuiteRuntimeInterface):
+
+ @staticmethod
+ def expose(fcn):
+ return ZMQServer.expose(fcn)
+
+
+class GraphQLAdapter(GraphQLServer, SuiteRuntimeInterface):
+
+ @staticmethod
+ def expose(fcn):
+ return GraphQLServer.expose(fcn)
+
+ # ...
Something to keep in mind over the whole "commandQueued" thing.
This is legacy from our old REST interface where we were restricted to a simple REQ-REP model.
Now that we are looking at using sockets for the HTTP and TCP interfaces we can keep the socket open and trickle back data until the client looses interest i.e:
REQ - stop_suite, kill=True
REP - commandQueued
REP - commandSucceeded
I guess that's really more of SUB-PUB model but anyway this functionality would be really useful for the GUI (could display a waiting symbol). The lack of this at present trips a lot of users up.
It's especially useful when commands fail, at present users are not informed of command failure (from where they issued the command) and have to look in the suite log to find out why it failed.
oliver-sanders
on 4 Mar 2019
Hi @dwsutherland , I'm trying your branch
flask-gevent-graphql, and as always I'm trying to run my all-time favouriteetc/examples/tutorial/cycling/five/suite.rc.I am running it with
cylc run --no-detach --verbose --debug fiveas I normally do, but it failed due to a local variabletempused before assignment.
@kinow - Ok, I see the issue (didn't fail for me), needed to only include satisfied (like how it currently is).. just put a fix in.. that "should" fix it..
dwsutherland
on 5 Mar 2019
Something to keep in mind over the whole "commandQueued" thing.
This is legacy from our old REST interface where we were restricted to a simple REQ-REP model.
Now that we are looking at using sockets for the HTTP and TCP interfaces we can keep the socket open and trickle back data until the client looses interest i.e:
REQ - stop_suite, kill=True REP - commandQueued REP - commandSucceededI guess that's really more of SUB-PUB model but anyway this functionality would be really useful for the GUI (could display a waiting symbol). The lack of this at present trips a lot of users up.
It's especially useful when commands fail, at present users are not informed of command failure (from where they issued the command) and have to look in the suite log to find out why it failed.
Yes, I thought about that while writing the mutations - but for the time being stuck with how REST/http was interacting with the suite..
With acync and websockets it should be doable I think (?)... Will wait until I re-implement with Tornado after your python3 merge. I may have to create/modify your ZeroMQ feed, if I'm going to divorce it completely. But I might start with Tornado served alongside ZeroMQ, and divorce it later, have to think about it...
dwsutherland
on 5 Mar 2019
Modified the stopSuite mutation args and added some meta:
mutation {
stopSuite(stopType: "after_task", items: ["baa.20170201T0000+13"]){
commandQueued
}
}
mutation {
stopSuite(stopType: "cleanly", actions: {kill_active_tasks: False}) {
commandQueued
}
}
md5-5338d82bd9dab1562d4c83a9fcc8231b
mutation {
putBroadcast(points: ["20170401T0000+13","20170301T0000+13"], namespaces: ["foo"],settings: [{environment: {GAME: "dangerous dave"}}]) {
modifiedSettings
badOptions
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
mutation {
clearBroadcast (points: ["20170401T0000+13"], namespaces: ["foo"],settings: [{environment: {GAME: "dangerous dave"}}]) {
modifiedSettings
badOptions
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
mutation {
expireBroadcast(cutoff: "20170301T0000+13") {
modifiedSettings
badOptions
}
}
md5-711d5c8e62833db9210ec9cade07aec0
query {
taskProxies(id: "foo"){
broadcasts
cyclePoint
}
}
md5-7cd4c0ff76ac2fb9cfcb4385b6d25782
{
"data": {
"taskProxies": [
{
"broadcasts": {
"environment": {
"GAME": "dangerous dave",
"GAME2": "dangerous dave2"
}
},
"cyclePoint": "20170301T0000+13"
},
{
"broadcasts": {
"environment": {
"GAME": "dangerous dave"
}
},
"cyclePoint": "20170201T0000+13"
},
{
"broadcasts": {
"environment": {
"GAME": "dangerous dave"
}
},
"cyclePoint": "20170101T0000+13"
}
]
}
}
At the moment the task proxy only updates when the state summary does (in the main loop when state or w/e changes), but that will change once I pull that proxy item out..
dwsutherland
on 5 Mar 2019
BTW - The cycle point arg in broadcast needs revisited in another ticket, although it may be intentional for "*" to be all current and future cycle points, it would be nice if we could use actual globs in putting and clearing them on a respective set of points.. At the moment you have to use exact (glob in expire would be the largest/furthermost point) ..
dwsutherland
on 5 Mar 2019
Mutations. And, as a sneak peak, I've added the all-in-one stop suite mutation:
Cool!
I've separated the network implementation and interface in the python3 branch so (with a small change) you could write a simple adapter to map the network endpoints onto your GraphQL layer which would save having to duplicate the
schd.command_queue.put((stop_cmd,item,action))type logic.
@oliver-sanders - Nice! will force homogeneity also, to ensure they stay in sync (during dev at least).
dwsutherland
on 5 Mar 2019
@dwsutherland The broadcast API is quite different. It populates a data structure, but does not apply the settings right away. (The settings in the data structure are normally looked up on job submission. So, yes a * for cycle applies to all cycles, and a * for task applies to all tasks.)
The other commands such as hold, release, trigger, reset, poll, kill, remove etc all search for tasks in the pool to apply action. (Note: insert is also an odd one...)
matthewrmshin
on 5 Mar 2019
@dwsutherland I might have something else weird in my environment. Synced the repo, confirmed my branch is up to date, then a cylc run --no-detach --verbose --debug five starts and has a few errors
kinow@kinow-VirtualBox:~/Development/python/workspace/cylc$ cylc run --no-detach --verbose --debug five
2019-03-06T09:09:23+13:00 DEBUG - Loading site/user global config files
2019-03-06T09:09:23+13:00 DEBUG - Reading file /home/kinow/.cylc/global.rc
._.
| | The Cylc Suite Engine [7.8.1-26-g9b9b9]
._____._. ._| |_____. Copyright (C) 2008-2019 NIWA
| .___| | | | | .___| & British Crown (Met Office) & Contributors.
| !___| !_! | | !___. _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
!_____!___. |_!_____! This program comes with ABSOLUTELY NO WARRANTY;
.___! | see `cylc warranty`. It is free software, you
!_____! are welcome to redistribute it under certain
2019-03-06T09:09:23+13:00 DEBUG - creating suite run directory: /home/kinow/cylc-run/five
2019-03-06T09:09:23+13:00 DEBUG - creating suite log directory: /home/kinow/cylc-run/five/log/suite
2019-03-06T09:09:23+13:00 DEBUG - creating suite job log directory: /home/kinow/cylc-run/five/log/job
2019-03-06T09:09:23+13:00 DEBUG - creating suite config log directory: /home/kinow/cylc-run/five/log/suiterc
2019-03-06T09:09:23+13:00 DEBUG - creating suite work directory: /home/kinow/cylc-run/five/work
...
...
2019-03-05T20:09:24Z DEBUG - ['cylc', 'jobs-submit', '--debug', '--utc-mode', '--', '/home/kinow/cylc-run/five/log/job', '20130808T0000Z/prep/01']
2019-03-05T20:09:24Z DEBUG - Performing suite health check
[2019-03-06 09:09:24,423] ERROR in app: Exception on /put_messages [POST]
Traceback (most recent call last):
File "/home/kinow/.local/lib/python2.7/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/kinow/.local/lib/python2.7/site-packages/flask/app.py", line 1816, in full_dispatch_request
return self.finalize_request(rv)
File "/home/kinow/.local/lib/python2.7/site-packages/flask/app.py", line 1833, in finalize_request
response = self.process_response(response)
File "/home/kinow/.local/lib/python2.7/site-packages/flask/app.py", line 2114, in process_response
self.session_interface.save_session(self, ctx.session, response)
File "/home/kinow/.local/lib/python2.7/site-packages/flask/sessions.py", line 384, in save_session
samesite=samesite
TypeError: set_cookie() got an unexpected keyword argument 'samesite'
127.0.0.1 - - [2019-03-06 09:09:24] "POST /put_messages HTTP/1.1" 500 412 0.003503
2019-03-05T20:09:24Z DEBUG - [jobs-submit cmd] cylc jobs-submit --debug --utc-mode -- /home/kinow/cylc-run/five/log/job 20130808T0000Z/prep/01
[jobs-submit ret_code] 0
[jobs-submit out]
[TASK JOB SUMMARY]2019-03-05T20:09:24Z|20130808T0000Z/prep/01|0|6608
[TASK JOB COMMAND]2019-03-05T20:09:24Z|20130808T0000Z/prep/01|[STDOUT] 6608
2019-03-05T20:09:24Z INFO - [prep.20130808T0000Z] -(current:ready) submitted at 2019-03-05T20:09:24Z
2019-03-05T20:09:24Z DEBUG - [prep.20130808T0000Z] -ready => submitted
...
...
(same error happens multiple times)
...
...
127.0.0.1 - - [2019-03-06 09:43:42] "POST /put_messages HTTP/1.1" 500 412 0.001593
2019-03-05T20:43:43Z DEBUG - Performing suite health check
2019-03-05T20:43:44Z DEBUG - Performing suite health check
2019-03-05T20:43:45Z DEBUG - Performing suite health check
2019-03-05T20:43:46Z DEBUG - Performing suite health check
2019-03-05T20:43:47Z DEBUG - Performing suite health check
2019-03-05T20:43:48Z DEBUG - Performing suite health check
2019-03-05T20:43:49Z DEBUG - Performing suite health check
2019-03-05T20:43:50Z DEBUG - Performing suite health check
2019-03-05T20:43:51Z DEBUG - Performing suite health check
2019-03-05T20:43:52Z DEBUG - Performing suite health check
2019-03-05T20:43:53Z DEBUG - Performing suite health check
(only this printed for a long time, till I kill the suite)
Could you have another look, please?
kinow
on 5 Mar 2019
@dwsutherland helped me in Riot, and now it's working. For the record, I upgraded my libraries, until they looked as
==========================================================================================
Package (version requirements) Outcome (version found)
==========================================================================================
*REQUIRED SOFTWARE*
Python (2.6+, <3)............................FOUND & min. version MET (2.7.15.candidate.1)
*OPTIONAL SOFTWARE for the GUI & dependency graph visualisation*
Python:pygtk (2.0+)......................................FOUND & min. version MET (2.24.0)
graphviz (any)..............................................................FOUND (2.40.1)
Python:pygraphviz (any).....................................................FOUND (1.4rc1)
*OPTIONAL SOFTWARE for the HTTPS communications layer*
Python:Flask (any)...........................................................FOUND (1.0.2)
Python:graphene (any)........................................................FOUND (2.1.3)
Python:urllib3 (any)........................................................FOUND (1.24.1)
Python:gevent (any)..........................................................FOUND (1.3.7)
Python:Flask-GraphQL (any).......................................................FOUND (?)
Python:Flask-HTTPAuth (any)..................................................FOUND (3.2.4)
Python:OpenSSL (any)........................................................FOUND (19.0.0)
Python:requests (2.4.2+).................................FOUND & min. version MET (2.21.0)
*OPTIONAL SOFTWARE for the configuration templating*
Python:EmPy (any)............................................................NOT FOUND (-)
*OPTIONAL SOFTWARE for the HTML documentation*
Python:sphinx (1.5.3+)....................................FOUND & min. version MET (1.8.4)
==========================================================================================
But the issue persisted. It went away after a pip install --upgrade flask-graphql
DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7.
Requirement already up-to-date: flask-graphql in /home/kinow/.local/lib/python2.7/site-packages (2.0.0)
Requirement already satisfied, skipping upgrade: graphql-core>=2.1 in /home/kinow/.local/lib/python2.7/site-packages (from flask-graphql) (2.1)
Requirement already satisfied, skipping upgrade: graphql-server-core>=1.1 in /home/kinow/.local/lib/python2.7/site-packages (from flask-graphql) (1.1.1)
Requirement already satisfied, skipping upgrade: flask>=0.7.0 in /home/kinow/.local/lib/python2.7/site-packages (from flask-graphql) (1.0.2)
Requirement already satisfied, skipping upgrade: six>=1.10.0 in /usr/lib/python2.7/dist-packages (from graphql-core>=2.1->flask-graphql) (1.11.0)
Requirement already satisfied, skipping upgrade: rx>=1.6.0 in /home/kinow/.local/lib/python2.7/site-packages (from graphql-core>=2.1->flask-graphql) (1.6.1)
Requirement already satisfied, skipping upgrade: promise>=2.1 in /home/kinow/.local/lib/python2.7/site-packages (from graphql-core>=2.1->flask-graphql) (2.2.1)
Collecting Werkzeug>=0.14 (from flask>=0.7.0->flask-graphql)
Using cached https://files.pythonhosted.org/packages/20/c4/12e3e56473e52375aa29c4764e70d1b8f3efa6682bef8d0aae04fe335243/Werkzeug-0.14.1-py2.py3-none-any.whl
Requirement already satisfied, skipping upgrade: click>=5.1 in /usr/lib/python2.7/dist-packages (from flask>=0.7.0->flask-graphql) (6.7)
Collecting Jinja2>=2.10 (from flask>=0.7.0->flask-graphql)
Using cached https://files.pythonhosted.org/packages/7f/ff/ae64bacdfc95f27a016a7bed8e8686763ba4d277a78ca76f32659220a731/Jinja2-2.10-py2.py3-none-any.whl
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /home/kinow/.local/lib/python2.7/site-packages (from flask>=0.7.0->flask-graphql) (1.1.0)
Requirement already satisfied, skipping upgrade: typing>=3.6.4; python_version < "3.5" in /home/kinow/.local/lib/python2.7/site-packages (from promise>=2.1->graphql-core>=2.1->flask-graphql) (3.6.6)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /usr/lib/python2.7/dist-packages (from Jinja2>=2.10->flask>=0.7.0->flask-graphql) (1.0)
graphene-tornado 2.0.1 has requirement Jinja2==2.9.6, but you'll have jinja2 2.10 which is incompatible.
graphene-tornado 2.0.1 has requirement werkzeug==0.12.2, but you'll have werkzeug 0.14.1 which is incompatible.
Installing collected packages: Werkzeug, Jinja2
Found existing installation: Werkzeug 0.12.2
Uninstalling Werkzeug-0.12.2:
Successfully uninstalled Werkzeug-0.12.2
Found existing installation: Jinja2 2.9.6
Uninstalling Jinja2-2.9.6:
Successfully uninstalled Jinja2-2.9.6
Successfully installed Jinja2-2.10 Werkzeug-0.14.1
Thanks @dwsutherland ! Continuing with the tests now.
kinow
on 6 Mar 2019
@kinow - BTW I know a while back you requested that the fields be "non-null" so you didn't have to check if they were (presumably so they just aren't present when null?)...
That option (required=True or NonNull) works a little different; it just means the field has to be populated/not-null on the server end, so if such a field is requested (even amongst others) but the resolving data object doesn't have it then the response will be an error...
https://docs.graphene-python.org/en/latest/types/list-and-nonnull/#nonnull
dwsutherland
on 6 Mar 2019
So if we have that in fields like meta, proxies, families; does that guarantee that they will be at least an empty list/dictionary? i.e. is there any chance that the elements that have children elements to be null?
Right now when we display values to the UI, vue.js takes care of escaping characters and handling null. So so far I haven't had any issues. But if I start accessing the objects returned, and eventually one of them becomes null, then accessing something like taskA.namespace[0] would crash the app if .namespace was null.
Or is it guaranteed by GraphQL that they will always be empty data structures?
kinow
on 6 Mar 2019
@kinow - We can set default_value for a graphene.List or GeneralScalar, but it's probably better to add in this validation (non-null for both) so the data provision always returns the desired empty type ([] and {} resp.) and error otherwise... Which puts the responsibility on the API developer to be consistent, instead of the client developer to jump through hoops.
https://graphql.org/learn/schema/#lists-and-non-null
dwsutherland
on 6 Mar 2019
That's perfect @dwsutherland
Lists work in a similar way: We can use a type modifier to mark a type as a List, which indicates that this field will return an array of that type. In the schema language, this is denoted by wrapping the type in square brackets, [ and ]. It works the same for arguments, where the validation step will expect an array for that value.
The Non-Null and List modifiers can be combined. For example, you can have a List of Non-Null Strings:
So at least for the fields that are lists... having a guarantee that they will be a list, and never null, would already be extremely helpful.
Which puts the responsibility on the API developer to be consistent, instead of the client developer to jump through hoops.
Nicely said! And in the end makes the app less likely to crash while used.
kinow
on 6 Mar 2019
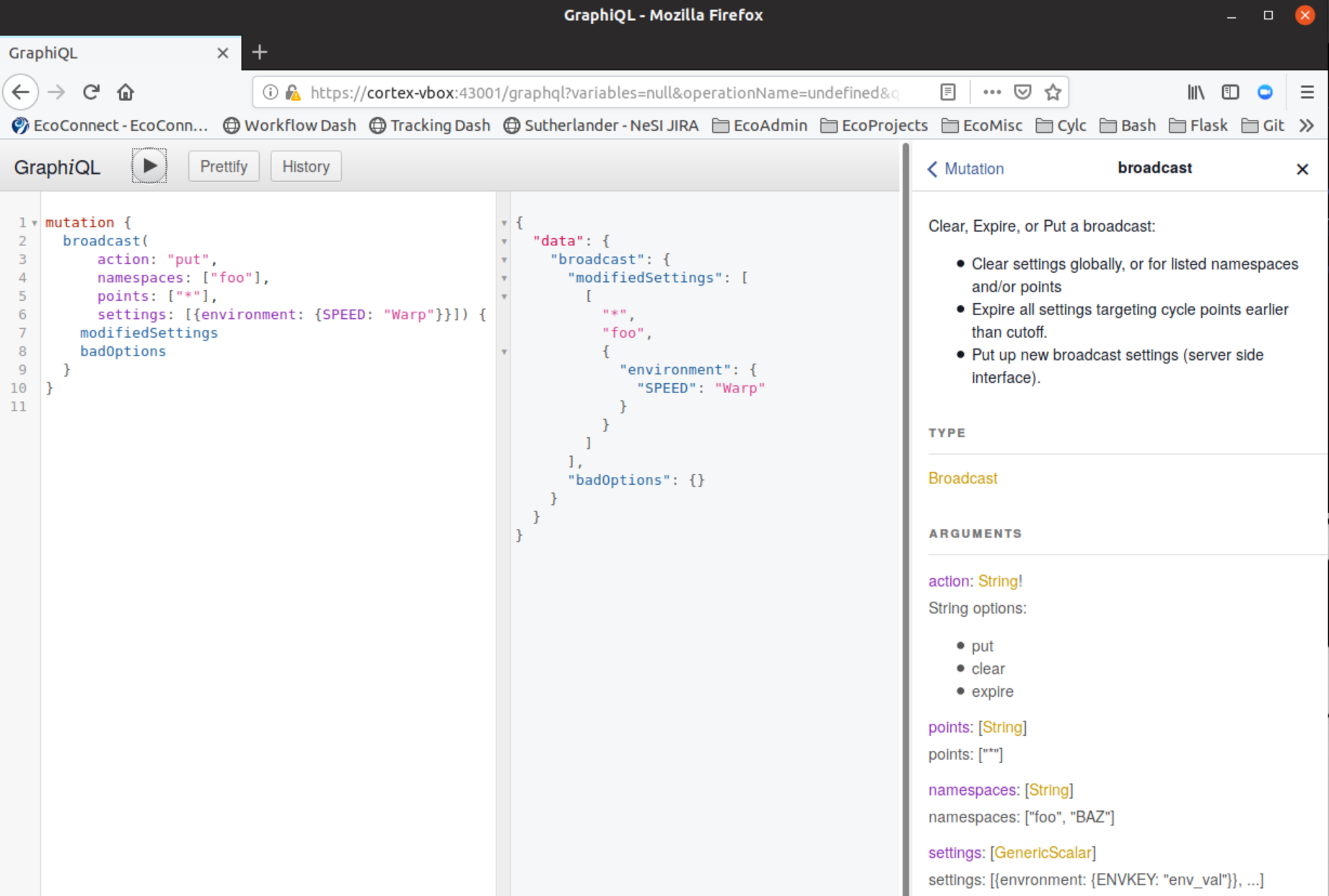
Just tidied up the schema; centralised the query arguments, changed globalInfo to suiteInfo, added metadata to mutations and consolidated broadcast:
dwsutherland
on 8 Mar 2019
Update: I've added all the Mutations.
Some of the commands are redundant for the gui:
ping task - information available in taskProxies query (exists and running)
ping suite - information available in suiteInfo query.
remove_cycle - just remove task proxies with glob for name (taskActions).
put_message - put_messages does the same and more (no need for the back compat).
The task actions have been collated into on mutation, i.e.:
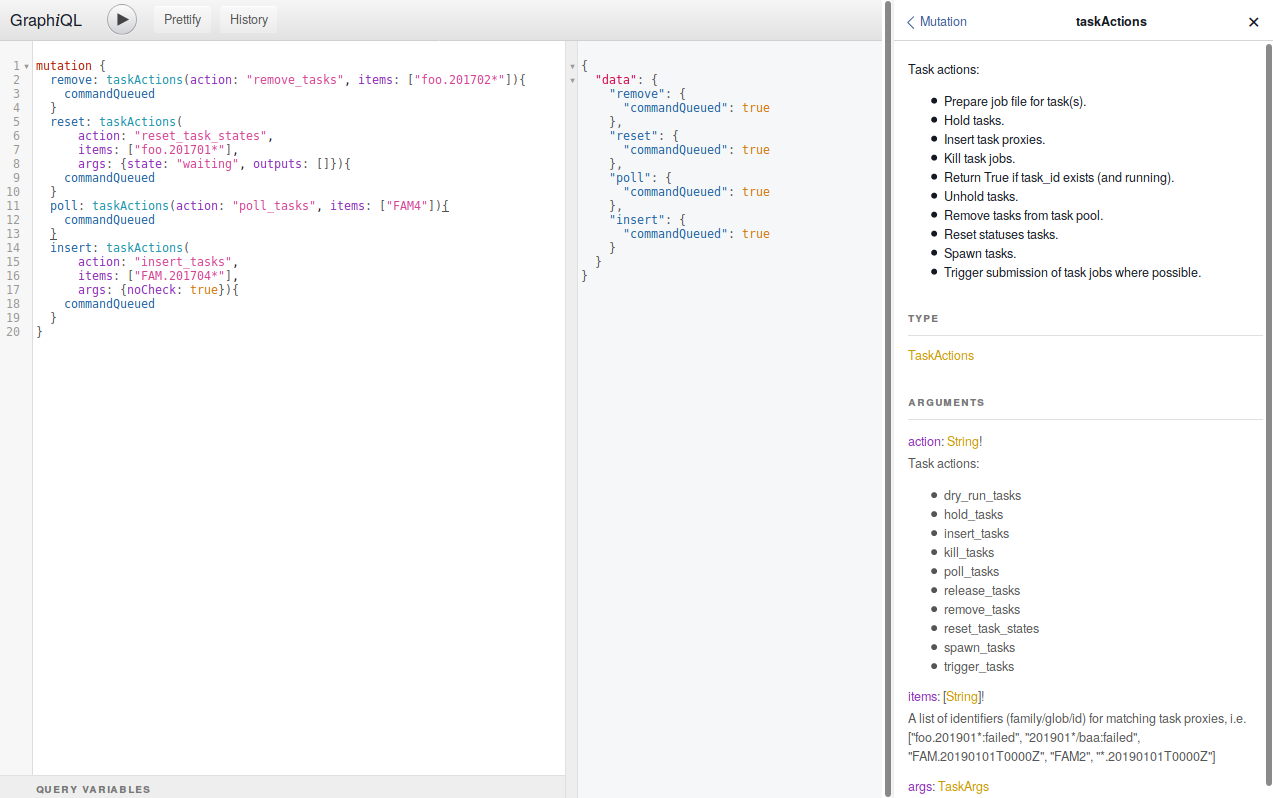
(note the use of aliases to use the same mutation multiple times in one request)
TODO for mutation & queries:
- Revert task outputs, as the messages may be bespoke
- Revisit the dependency graph data-provision/query
- Pagination
NEXT: Implementing for Cylc8 using Tornado web sockets, and add subscriptions.
dwsutherland
on 13 Mar 2019
This is very impressive & promising @dwsutherland, great work.
There is a point I feel compelled to raise, & will pre-register here but mainly hope to initiate some discussion on in today's video conference. Namely, we need to investigate the performance of the suggested data structure for a range of data-fetching instances that are realistic (or at least as realistic as we can mock at this stage) relative to real-life Cylc usage.
I think it is crucial we invest in optimising, with respect to what we foresee to be the most important scaling aspects, the query performance. If we otherwise decide upon & go ahead using a certain structure, & realise further down the line that response times are overly large for certain scenarios & therefore that amendments are needed, it will be a lot more difficult & expensive to change, given this will heavily influence development of both the back- & front-end. Also the GraphQL schema is intrinsically tied to the suite (or "workflow" as we now call it) status summary data, so this structure is central to our whole application. So, while what you have created here seems to work & looks very positive, & I imagine there is little to debate on the fields themselves, I think we need to be very careful to check the details of the design of the structuring i.e. the nesting, levels & grouping etc. of fields.
In particular, having done some initial research into GraphQL API performance considerations, I have observed that there are at least two key problems that can be run into & we need to ensure we avoid:
1) N+1 queries: a problem not occurring for REST, as outlined very well in numerous resources, but my favourites are blog posts: here & here.
2) Exponential query scaling cases: as outlined in a recent research paper which is summarised here & particularly in a less maths-heavy way here.
You or someone else may have already looked into performance, & if so can we hear more about your methodology & findings (via another comms channel if more appropriate)? If not, can we get started on some performance profiling/tracing? There seem to be a number of free load testing tools we can try, for example, but we should have some way to gather quantitative results for:
- response time (latency): server response speed per request;
- throughput: how many requests the server can handle in a set time interval.
Relating to the latter, we could consider using the utility DataLoader to reduce the number of requests & improve performance.
 sadielbartholomew
on 18 Mar 2019
sadielbartholomew
on 18 Mar 2019
@sadielbartholomew - This does need to be looked at, and excuse the brevity in my response (I'll read through more thoroughly tomorrow)..
There is a point I feel compelled to raise, & will pre-register here but mainly hope to initiate some discussion on in today's video conference. Namely, we need to investigate the performance of the suggested data structure for a range of data-fetching instances that are realistic (or at least as realistic as we can mock at this stage) relative to real-life Cylc usage.
Also the GraphQL schema is intrinsically tied to the suite (or "_workflow_" as we now call it) status summary data, so this structure is central to our whole application. So, while what you have created here seems to work & looks very positive, & I imagine there is little to debate on the fields themselves, I think we need to be very careful to check the details of the design of the structuring i.e. the nesting, levels & grouping etc. of fields.
In particular, having done some initial research into GraphQL API performance considerations, I have observed that there are at least two key problems that can be run into & we need to ensure we avoid:
- N+1 queries: a problem not occurring for REST, as outlined very well in numerous resources, but my favourites are blog posts: here & here.
- Exponential query scaling cases: as outlined in a recent research paper which is summarised here & particularly in a less maths-heavy way here.
There's no actual _suggested data structure_. What I've done is define the relationships between data objects, and then show cased what can be done with these relationships.
The relationship is defined by adding a IDs to a field in the parent object type, and fields are only resolved when asked for. Hence, the level of nesting being calculated in the server is decided not by the code, but by the query; if you you want a completely flat structure, you can! if you want nesting to the extreme, that's possible! if you want to combine multiple queries to save on requests, easy!
So the need for us now, is to find out the most efficient query structure for both the server and the front end. And of course a thorough review of code/data-access efficiency in my resolvers.
I think it is crucial we invest in optimising, with respect to what we foresee to be the most important scaling aspects, the query performance.
- Agreed
If we otherwise decide upon & go ahead using a certain structure, & realise further down the line that response times are overly large for certain scenarios & therefore that amendments are needed, it will be a lot more difficult & expensive to change, given this will heavily influence development of both the back- & front-end.
- kind-of As in the above response, there is no set data structure only the modelling of suite objects. Fields can be added and removed, and the resolvers can be changed to provision the objects in a different way without much impact. However, we do want to make sure that the data objects are modelled correctly (i.e. proxy objects, def objects, job objects..), I've taken on and implemented all/most of @oliver-sanders advice so far and welcome any more. You are right, that this will effect both front and back end, and we need to get it right.
You or someone else may have already looked into performance, & if so can we hear more about your methodology & findings (via another comms channel if more appropriate)? If not, can we get started on some performance profiling/tracing? There seem to be a number of free load testing tools we can try, for example, but we should have some way to gather quantitative results for:
- response time (latency): server response speed per request;
- throughput: how many requests the server can handle in a set time interval.
Relating to the latter, we could consider using the utility DataLoader to reduce the number of requests & improve performance.
I wasn't going to look into this until the schema model and design was settled (i.e. what we want from it), but your more than welcome to start.. We also need to add tests in after the dust settles, as the integration into the UI server is next..
Thanks!
dwsutherland
on 18 Mar 2019
(updated)
I've added in single node ID queries:
{
job(id: "20170101T0000+13/foo/01"){
id
startedTime
jobLogDir
}
task(id: "foo"){
id
}
taskProxy(id: "foo.20170101T0000+13") {
id
}
family(id: "FAM3") {
id
}
familyProxy(id: "FAM4.20170101T0000+13") {
id
}
}
And dependency graph edges (much like the current feed):
fragment tProxy on QLTaskProxy {
id
state
}
fragment fProxy on QLFamilyProxy {
id
state
}
query{
edges(startPoint: "20170101T0000+13", endPoint: "20170101T0000+13", groupAll: true) {
edges {
tailNode{
... tProxy
... fProxy
}
headNode{
... tProxy
... fProxy
}
cond
suicide
}
suitePollingTasks
leaves
feet
}
}
{
"data": {
"edges": {
"edges": [
{
"tailNode": {
"id": "FAM.20170101T0000+13",
"state": "succeeded"
},
"headNode": null,
"cond": false,
"suicide": false
},
{
"tailNode": {
"id": "FAM.20170101T0000+13",
"state": "succeeded"
},
.
.
.
{
"tailNode": {
"id": "baa.20170101T0000+13",
"state": "waiting"
},
"headNode": {
"id": "FAM4.20170101T0000+13",
"state": "waiting"
},
"cond": false,
"suicide": false
},
{
"tailNode": {
"id": "poll_jin.20170101T0000+13",
"state": "running"
},
"headNode": null,
"cond": false,
"suicide": false
},
{
"tailNode": {
"id": "poll_jin.20170101T0000+13",
"state": "running"
},
"headNode": {
"id": "baa.20170101T0000+13",
"state": "waiting"
},
"cond": false,
"suicide": false
}
],
"suitePollingTasks": {
"poll_jin": [
"jin",
"baz",
"succeed",
"<jin::baz>"
]
},
"leaves": [
"poll_jin",
"bar",
"qux",
"qaz",
"baa",
"foo"
],
"feet": [
"poll_jin",
"FAM",
"FAM4",
"baa"
]
}
}
}
(obviously this may change with employed graphing technology)
Last Commit to Flask PoC branch
https://github.com/dwsutherland/cylc/tree/flask-gevent-graphql
Next step UI Server!
dwsutherland
on 18 Mar 2019
Looks like federated GraphQL is a thing: https://medium.com/@aaivazis/a-guide-to-graphql-schema-federation-part-1-995b639ac035
Understandable as some people may have microservice architectures, with multiple GraphQL endpoints. It may be useful in case it provides links to tools that handle merging schema, caching, etc. And I agree on the performance penalty, but just looking at all possible alternatives 😬
kinow
on 23 May 2019
closed by https://github.com/cylc/cylc-flow/pull/3122
closed by https://github.com/cylc/cylc-uiserver/pull/34
dwsutherland
on 28 Jun 2019
Related issues
oliver-sanders
·
3Comments
kinow
·
3Comments
oliver-sanders
·
5Comments
kinow
·
3Comments
hjoliver
·
5Comments
Most helpful comment
Update: I've added all the Mutations.
Some of the commands are redundant for the gui:
ping task- information available in taskProxies query (exists and running)ping suite- information available in suiteInfo query.remove_cycle- just remove task proxies with glob for name (taskActions).put_message- put_messages does the same and more (no need for the back compat).The task actions have been collated into on mutation, i.e.:

(note the use of aliases to use the same mutation multiple times in one request)
TODO for mutation & queries:
NEXT: Implementing for Cylc8 using Tornado web sockets, and add subscriptions.