Cylc-flow: suite http(s) server improvements
- [ ] Find a replacement for cherrypy:
- See https://github.com/cylc/cylc/issues/2113#issuecomment-275082942 for reason. Situation does not appear to have improved.
- Tornado looks like the way forward.
- [ ] Support running multiple suites on a single http(s) server.E.g.: one server per user@host or even one server per host. (Imagine talking to your suites and launching new ones via a single URL in your browser.)
- [ ] Authentication and authorization improvements. #1901
 matthewrmshin
matthewrmshin
All 54 comments
(Could point 2 go so far as to support running all suites (for all users) on a single https server - so only one port needs to be open?)
 hjoliver
on 28 Jan 2018
hjoliver
on 28 Jan 2018
That's the intention of the bullet point - provided that the site permits it and that we are able to find a suitable authentication method.
matthewrmshin
on 28 Jan 2018
Add one more vote for Flask. Multiple suites on a single server is also something that's intriguing - although depending on how it's configured, this could be set up now with a reverse proxy.
 trwhitcomb
on 8 Feb 2018
trwhitcomb
on 8 Feb 2018
Hi @trwhitcomb Flask was my original choice as well. And then I saw the statement here: http://flask.pocoo.org/docs/0.12/deploying/#self-hosted-options Flask’s built-in server is not suitable for production - which will make it harder if we are to use it like we are using CherryPy.
matthewrmshin
on 8 Feb 2018
More on why Flask's built-in server is not for production: https://vsupalov.com/flask-web-server-in-production/
hjoliver
on 10 Jun 2018
(Presumably we could still make the application with Flask, and run it via mod_wsgi in Apache though?)
hjoliver
on 10 Jun 2018
(I guess it would be good to have a performant standalone option too?)
hjoliver
on 10 Jun 2018
Yes and yes. (Obviously, we can run Flask under any WSGI server. If we are going down this route, I am keen to look at alternatives to Apache.)
matthewrmshin
on 10 Jun 2018
Used Graphite for metrics monitoring some time ago. It is (or was, haven't used it in some years) deployed normally with Apache and WSGI. Had a few issues, especially performance issues when we had too many clients sending/reading metrics (had to scale with statsd & more servers). We ended up adding an extra server behind the load balancer for the just-in-case.
At my previous job I worked for a few months on a Flask + Injector PoC project. We managed to port most of what we used in Java + SpringBoot to that project, building everything around YAML configuration and dependency injection of services. But we never worried how to deploy it as it was a PoC. I think Flask is the simpler/easier web framework I've tried in Python, and injector is a must (-: or another DI library.
At NIWA we have a code that runs at Lauder's bruker (I think it's still in use) and on the Arduino air quality monitoring tools (Dusty Acorn), built with Tornado and uses WebSockets as well - https://github.com/niwa/dusty-acorn/blob/master/air1/web_server.py. But both run as service on Linux, without Apache httpd or Nginx. (code is old, probably needs revisit for threading correction, and whatanot, but has been running fine so far)
My favourite option would be Tornado. I had a look at CherryPy and it's not too different. Though I think Tornado is more robust, and has more examples, docs, support. I heard about people using Flask + Tornado, but never used myself, and think it would only increase complexity (https://stackoverflow.com/a/13169217).
Apache Software Foundation accepted a project into incubation similar to Tableau BI. It's built in Python, and uses Flask. Quite large project - https://github.com/apache/incubator-superset. The documentation suggests to deploy the Flask app with WSGI, using Gunicorn (which I never used). Perhaps Gunicorn would be interesting, and perhaps Superset has some code that could be adapted to cylc (AL is permissive): https://superset.incubator.apache.org/installation.html#a-proper-wsgi-http-server
 kinow
on 12 Jun 2018
kinow
on 12 Jun 2018
Thanks for the info above @kinow, useful - I somehow missed that when you posted it (I was overseas...)
hjoliver
on 25 Jun 2018
Hi All - I would echo @kinow's comments on the pairing of Flask; but add that the pairing of Flask with other WSGI servers is quite straight forward, and there are many options available (
even the self issue-defeating Flask+Cherrypy pairing is possible: Flask-Cherrypy). We have to be aware that Flask aims not to be an all-in-one bloat, but minimalist and very extensible.
Reasonably new at this; over the last several months I've been learning some Python web-frameworks (was playing about with Pyramid for a bit). I've rewritten Cylc's API in Flask:
Cylc-Flask
It uses gevent's WSGI server (which makes up ~10 lines of code), It rates at least as fast as Tornado (or faster) on some benchmarks. In another benchmark of wsgi-servers it appears bjoern is ridiculously faster than all others; so I think I'll try that one.
Flasks code structure is quite different than Tornado's or Cherrypy; as opposed to class objects containing exposed methods, it registers functions/methods (via a decorator) against the Flask application or Blueprint object(s) (which I used with Cylc). Of course, Flask has extensions for this (Flask-Classful) if it's so desired.
I've tested all the end-points, and they appeared to be working (also tested running and interacting with a simple suite), but am yet to run the full test battery on it. The packages installed via pip are flask, Flask-HTTPAuth, and gevent; so including the dependencies this comes to:
click==6.7
Flask==1.0.2
Flask-HTTPAuth==3.2.4
gevent==1.3.4
greenlet==0.4.13
itsdangerous==0.24
Jinja2==2.10
MarkupSafe==1.0
Werkzeug==0.14.1
Now; I've tested it without Jinja2==2.10 and MarkupSafe==1.0 (as these are already packaged with Cylc) and it appears to work. Although, I don't think I used the respective flask resources as both are used on the front-end HTML rendering etc.
I've also made some changes:
- The privilege checking is now done via a decorator (with required level and logging option as args)
- I've added the option to use Basic or Digest (default) authentication scheme
glbl_cfg().get(['communication', 'authentication scheme'])(set as basic or digest). Basic will be faster and sending clear-text credentials is not such an issue if HTTPS is used.
There is of course a lot of work we could do around user management/authorization (including user DB etc). But that can be addressed going forward.
Let me know what you think, and what I should change. If we still want to go with Tornado, I'm willing to look into it, although, apart from not having to install a server, I'm not sure what other advantages it has.
If we want to move forward with Flask, then I'll work on tidying up the Docs and run more tests, else I'll treat this as a learning experience. As I understand from Hilary, that there may be more to consider in the bigger picture (i.e. GraphQL etc).
 dwsutherland
on 14 Jul 2018
dwsutherland
on 14 Jul 2018
@dwsutherland - thanks, interesting! We need to understand what you've done and consider it in light of our plans (some of which you've mentioned) - but note we have quite a lot on our plates right now including a couple of large PRs to review (one very large) ... so maybe don't expect immediate action on this.
hjoliver
on 15 Jul 2018
@dwsutherland tested your branch, and it worked with no issues for the one-off suite from the tutorial, and with another simple test suite I have configured in my workstation! :tada:
Some time ago I realized that as I had cylc using HTTP Digest in my local environment, I would have its extra challenge requests, resulting in twice the expected number of HTTP requests.
But comparing the HTTP Digest packets of the current CherryPy server, with your Flask+Gevent, I noticed the CherryPy are much bigger, as the CherryPy response is including some HTML. (this sounds like a quick improvement for the current installations to get less traffic/congestion at the network level).
Here's a quick Wireshark screenshot with the latest code running the one-off suite, and with some extra packets due to the HTTP Digest auth.
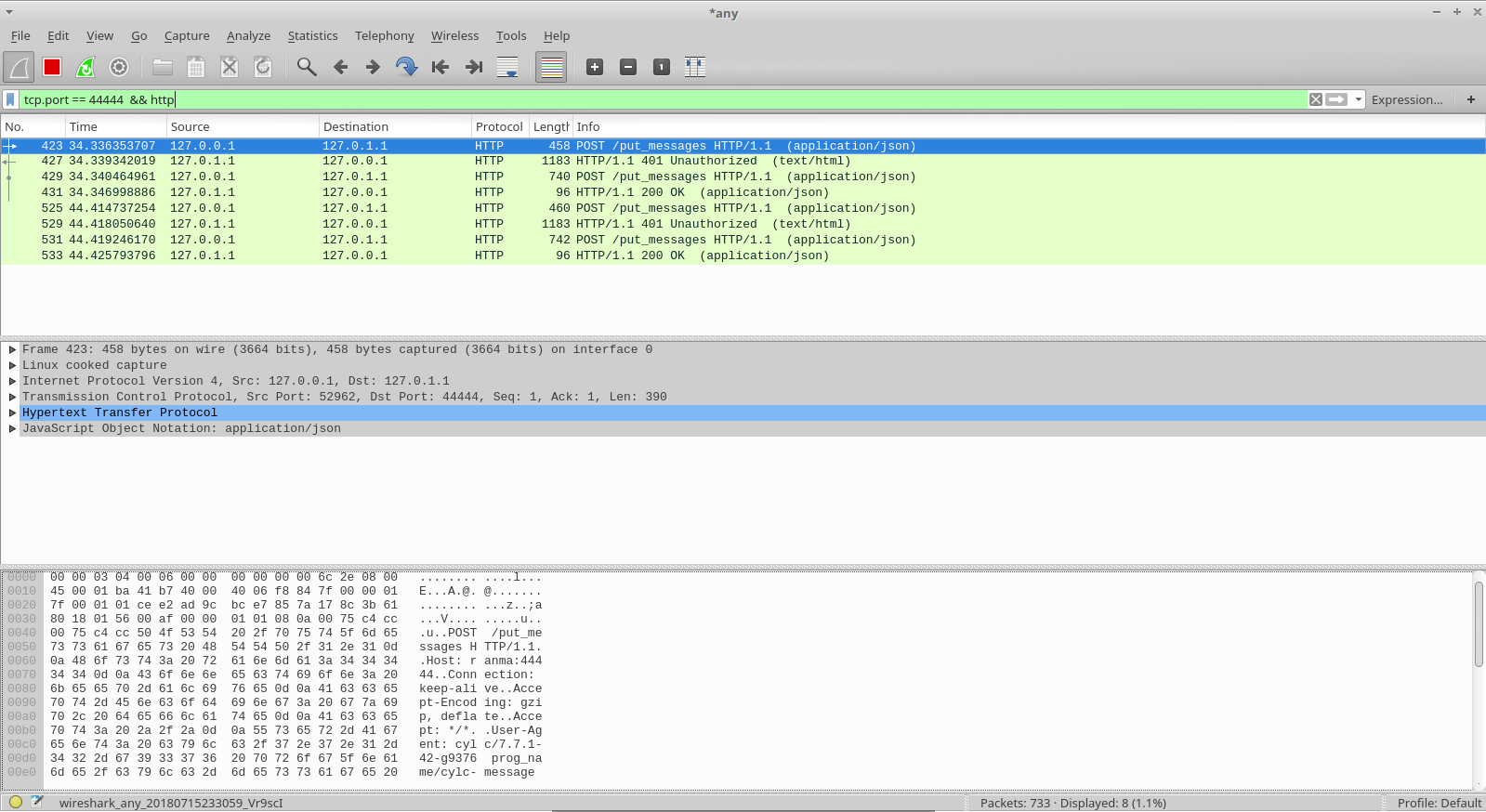
Here's your Flask+Gevent with HTTP Digest, with request almost the exact same size, but note the 1183 bytes HTTP challenge response. Also important to note that the intended response is only 96 bytes, but instead we are getting packets ~12 times bigger than that.
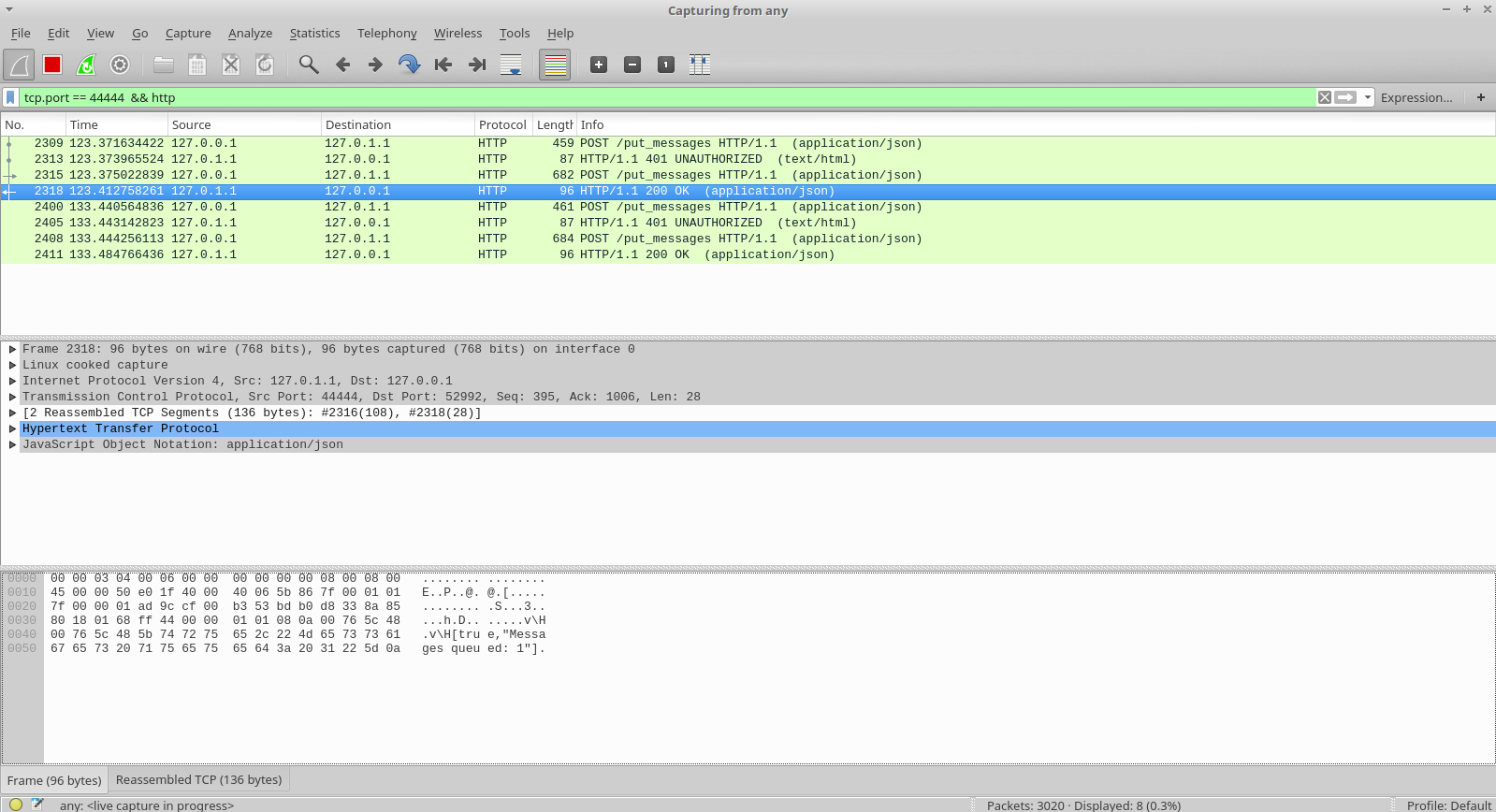
And finally your Flask+Gevent but now with HTTP Basic. Really slim!
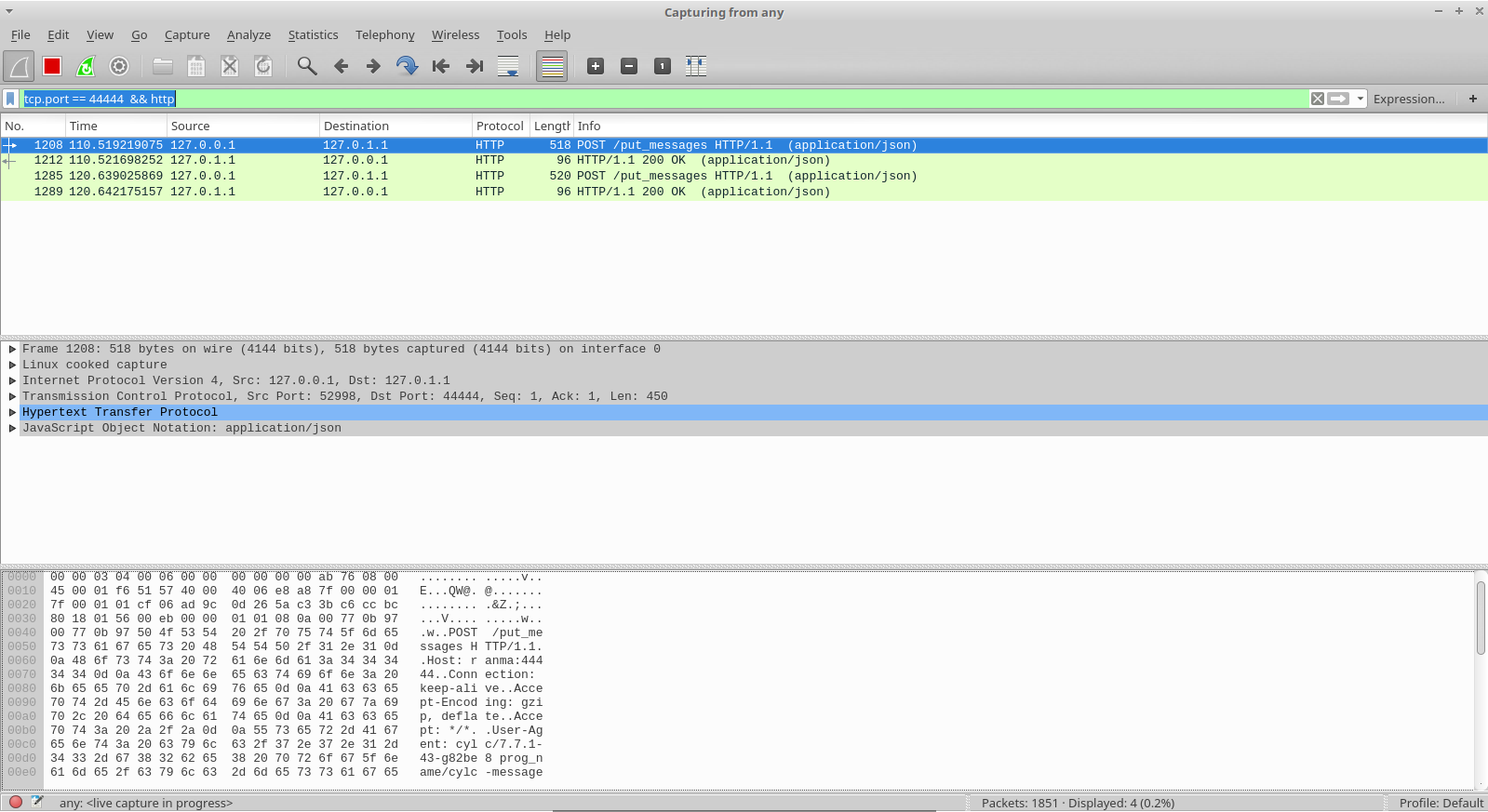
I think if HTTP Digest is not a hard requirement, even HTTP Basic can be dropped (as anyone who passed through the SSL layer could easily Base64 decode the credentials anyway).
Since I started understanding more of Cylc's internals, I have been imagining a solution for the "reverse proxy" with either Flask or Tornado. But for the communication between computers, assuming we won't be using a browser to interact directly with suites/tasks, I think we could drop HTTP and adopt a protocol like protobuf.
The rationale is that we are not using HTTP verbs (we don't really care whether it's POST or GET, except for the message size, but we wouldn't be using browsers here I think, only when connecting to the "reverse proxy"). Also not using HTTP redirect, nor URL parameters, nor most of what HTTP offers.
So for the suite/tasks communication we could reduce the network traffic (reducing memory/CPU/IO/switch congestion/etc) and also speed up the time serializing objects (I remember seeing reports from ~2015, but this one from 2017 seems pretty accurate).
I haven't started a new issue yet, but once I have time, will finish setting up a distributed Cylc lab, to experiment and come back with some numbers, though this could be done after replacing CherryPy.
I still prefer Tornado for being more familiar with and for having one single piece (though I did not find any major issue in gevent related to breaking existing flask applications), but I think either Flask+Gevent or Tornado would be better than CherryPy.
kinow
on 15 Jul 2018
@kinow - nice work.
I think if HTTP Digest is not a hard requirement,...
I'm certainly interested to explore this. What I don't really understand at this stage is, we typically have real users where the suite server programs are running, so how do we trust all incoming connections? Does an SSL Client Certificate held by the reverse proxy mean (as per the speculation in my document) that we can dispense with any authentication at the the suite server program?
But for the communication between computers, assuming we won't be using a browser to interact directly with suites/tasks, I think we could drop HTTP and adopt a protocol like protobuf.
I presume you mean task job status messages etc.? The trouble is, the "etc." here hides a lot - task jobs can (and sometimes do) usefully run any Cylc command line client. Which is why it was convenient to do the same as for user-invoked clients under the current system. Is it feasible to do what you're suggesting in light of this? Or could we use protobuf (e.g.) for all comms with the suite server programs, and the reverse proxy would translate user client requests appropriately? But then what about the trust issue in suite server programs? And where does (can?) graphql fit in? (I have a tenuous grip on all this, at this stage - email or VC might be a better medium to discuss, if my questions are too open-ended, or silly!)
hjoliver
on 16 Jul 2018
P.s. I have actually been wondering, since it became apparent that our web era clients are unlikely to connect directly to the suite server programs, if they - the server programs - really need to talk HTTPS. When we swapped the old Pyro comms layer out for HTTPS, we assumed (at least I did) that our future web GUIs would (or at least might, in some set ups) talk directly to the suite servers.
hjoliver
on 16 Jul 2018
Hi @hjoliver 👋 !
Does an SSL Client Certificate held by the reverse proxy mean (as per the speculation in my document) that we can dispense with any authentication at the the suite server program?
I think it's a good option to be explored more, possibly with some feedback from users using Cylc. From what I recall, that's more or less how Puppet master/slave communication works.
Is it feasible to do what you're suggesting in light of this? Or could we use protobuf (e.g.) for all comms with the suite server programs, and the reverse proxy would translate user client requests appropriately?
That's the way I'm thinking, the reverse proxy would be the place to look at everything, and would be responsible for translating commands to the suite server programs.
But then what about the trust issue in suite server programs?
Good question. If we adopted Google's grpc, it uses protobuf, and supports channel & communication security (SSL, or a custom token respectively). But I haven't had time to look through how a complete implementation would look like.
I got this idea from the way Hadoop/YARN server & client communication works.
And where does (can?) graphql fit in? (I have a tenuous grip on all this, at this stage - email or VC might be a better medium to discuss, if my questions are too open-ended, or silly!)
Another excellent question, which I do not have an answer yet. GraphQL is pretty new compared to protocol buffers & other binary formats, so I haven't heard of anybody using both... but in theory it's still doable.
The reverse proxy could expose the API, accept GraphQL requests, translate into the necessary messages to server suite programs, and submit requests with protobuf payloads. Not sure if it'd be doable to have graphql in the server program though.
I think this approach would be more interesting if we could benchmark a suite with high network & IO load levels, to compare the performance of a Cylc + CherryPy, with Cylc + Protobuf.
kinow
on 16 Jul 2018
@hjoliver - Thanks for the reply and understood. I'm not sure what's meant by
"understand what you've done"
aside from the above description and the diff, but a summary of the file changes would be:
Major rewrite:
lib/cylc/network/httpserver.py(essentially completely changed, but interacts-with/references the scheduler object in the same way)
Minor changes (like <~10 lines):
lib/cylc/network/httpclient.py(authentication scheme option)lib/cylc/scheduler.py(server object instantiated, start, stop, and associated object references)lib/cylc/cfgspec/globalcfg.py(authentication scheme option)README.md
Deletion:
lib/cherrypylicences/LICENSE-BSD-CHERRYPY
I guess you mean at the code level of detail. I've got plenty to learn! so it's possible I've broken some of the code style/convention, so please pull me up on it!
@kinow - Thanks for testing the branch!
Really not sure what the extra data in the Cherrypy response is for, but it's clearly not needed.
BTW I think we do need some way to secure the suite server program, if only for avoiding human error on an open network (someone stops someone else's suite inadvertently? if that's possible)..
From the little I know about GraphQL; I think we have three main ways to make it work for us:
- You could actually replace Cherrypy (or Flask) rest API with it; you essentially create the schema (SDL) for the Cylc API and then you write the resolver functions to interact with the scheduler object. So in the same way the endpoint functions of Cylc's Cherrypy API interact with the scheduler object the resolver functions can also (in the form of queries and mutations (as the language describes them)).
- You could have a Rest API as it currently exists (or protobuf) and have GraphQL at the reverse proxy end with a schema that encompasses many suites (which might be a single endpoint for all suites (I think could work!)), and the resolvers would be essentially be making requests to the rest API .
- You could have a double layer of GraphQL (both above 1 & 2), so the Suite API as a GraphQL endpoint and the reverse-proxy level a GraphQL endpoint whos resolver functions would essentially make a request to one or many suite GraphQL endpoints).
dwsutherland
on 16 Jul 2018
@dwsutherland -
. I'm not sure what's meant by "understand what you've done" ...
Sorry, just poorly phrased on my part (I was in a hurry when I wrote that) - it is more about the second part of my sentence, i.e. understanding the implications of what you've done in light of our various half-formed and rapidly evolving (as of very recently) plans. I also tested your branch and it ran fine on a test suite - so, well done :grin: - however, we obviously can't say yet whether we will go with Flask or not. And now @kinow has opened up a new can of worms (maybe no http in the suite server programs...)!
BTW I think we do need some way to secure the suite server program, ...
Yes that's probably essential, but hopefully we can use some more or less automatic method (e.g. SSL client certificates) so that actual user authentication does not have to be done by the suite server programs.
hjoliver
on 16 Jul 2018
From the little I know about GraphQL; I think we have three main ways to make it work for us:
I'd envisaged something closer to option 1 for GUI communication with GraphQL providing the "suite interface". The real motive behind GraphQL was to improve the efficiency and capability of the GUI (see notes below).
To realise this the client would have to be able to communicate to either the suite or some form of GUI server (running alongside the suite) using the GraphQL interface so I don't think we could get away with absorbing GraphQL at the reverse proxy and then using the REST interface thereafter, unless the reverse proxy is also the GUI server.
To try and clarify why we are interested in using GraphQL in the GUI (#1873):
Provide a bit more flexibility for the future GUI
- GUI components need only request the data they need without having to worry about where that data is coming from.
- For example in the GUI graph view we require information about the suite's graph, task states, inheritance hierarchy, ... all of which, in a REST api, could potentially sit behind different endpoints.
- As making multiple requests to get this data is waaayyyy too inefficient we end up creating a composite endpoint, in this case
get_graph_raw. - The problems with this are:
- The approach is not dynamic, if we want to change the view in some way, say we want to group/ungroup nodes, we have to add the functionality to the
get_graph_rawinterface, in this case through thegroup_nodesargument. Ideally the GUI would just request the information it needs rather than requiring every possible case handled by an endpoint interface. - Changes to the GUI must be associated with changes to the composite endpoint breaking inter-version compatibility.
- The approach is not dynamic, if we want to change the view in some way, say we want to group/ungroup nodes, we have to add the functionality to the
- The future GUI is likely to have more dynamic data needs, e.g. viewing part of a suite's graph so we want to keep as much control over the interface with the GUI as possible.
Cut down on the number of network requests.
- In the future GUI there would be a suite list down the left hand side much like the current
gscan. This "sidebar" would require suite status information (just like the currentgscandoes). - If you have say the tree view open for a suite you already posses the information required to populate this
gscanview so do not need to perform a second request. - Rather than having each component (the
gscansidebar, graph view, tree view, dot view, rose bush?, suite analytics?) performing individual requests GraphQL enables us to pool these data requests, potentially into a single API call. - Is this such a big deal? If we could keep a websocket open then it wouldn't matter.
- In the future GUI there would be a suite list down the left hand side much like the current
Upgrading / Deprecating.
- GraphQL provides a simple system for upgrading / deprecating syntax gracefully.
- This is particularly useful for a system which is likely to see very rapid development and potentially large changes to its broader implementation (e.g. Spawn On Demand, Change to different network protocols?, API On The Fly, ...)
 oliver-sanders
on 16 Jul 2018
oliver-sanders
on 16 Jul 2018
@oliver-sanders great explanation! I think now I understand a bit more why graphql would have to go over the reverse proxy web application. But maybe we could move the GraphQL could be a task to be done after the reverse-proxy is implemented (and maybe new suite serve program communication model?)?
This way we would be minimizing the changes and doing it through a few iterations. This would also gives up time to compare each step with the previous, taking notes of what improvements we had from the new reverse proxy web application, of a different suite serve program communication model, and of graphql. As well as allows us to more easily revert any changes.
Maybe we could split this task into three separate tasks later.
- implement reverse proxy web application
- review suite server program communication model
- add support to graphql
kinow
on 16 Jul 2018
https://www.howtographql.com/basics/3-big-picture/
It’s important to note that GraphQL is actually transport-layer agnostic. This means it can potentially be used with any available network protocol. So, it is potentially possible to implement a GraphQL server based on TCP, WebSockets, etc.
hjoliver
on 17 Jul 2018
@kinow's suggestion above could be a good way to proceed:
- implement reverse proxy web application
- review suite server program communication model
- add support to graphql
Having the reverse proxy would enable us to start on other parts of the system concurrently as well, around it:
- authentication
- suite discovery service
- and the GUI application itself
hjoliver
on 17 Jul 2018
(updating a previous post, deleted)
WebSocket sounds good. Connections are established by HTTP handshake, then full duplex comms with tiny (2-byte) frame headers and low latency. https://www.websocket.org/quantum.html Hence, no GUI polling required.
WebSocket and GraphQL are compatible ("GraphQL is transport layer agnostic"). E.g. here WebSocket is used to implement GraphQL subscriptions? https://github.com/apollographql/subscriptions-transport-ws.
Maybe we could use a GraphQL API over the WebSocket protocol...
hjoliver
on 18 Jul 2018
@hjoliver - Agreed GraphQL+WebSocket for the suite API. Then I would think a gui could connect locally to the suite GraphQL endpoint, or to the reverse-proxy endpoint while speaking the same request language (query/mutation/subscription).
dwsutherland
on 18 Jul 2018
The arguments above for GraphQL are compelling. I'm slightly concerned that the different kinds of data needed by the GUI - summary states, tree (inheritance), DAG (dependencies), and incremental updates to all? ... are not compatible with a single coherent data structure that the GraphQL resolver function(s?) can simply "index into" to get exactly what's requested. But I suppose even if that takes significant server-side computation in response to requests, it would still be simpler (and at least no more computation) than having many complex and inflexible REST endpoints.
hjoliver
on 18 Jul 2018
@dwsutherland - yes, if the GraphQL API is exposed at the reverse proxy and the suite server programs, then in principle a single-suite GUI could talk directly to the suite. However in practice I think the reverse proxy is going to be needed even in the most minimal setup (one user on a personal laptop...) because of the fact that a GUI (running in a web browser) cannot do "suite discovery".
hjoliver
on 18 Jul 2018
I'm slightly concerned that the different kinds of data needed by the GUI - summary states, tree (inheritance), DAG (dependencies), and incremental updates to all? ... are not compatible with a single coherent data structure that the GraphQL resolver function(s?) can simply "index into" to get exactly what's requested.
I definitely would like to research this more. It may not be feasible to split up the items like the tree (inheritance), because of the arbitrary depth and size, in order to make the GraphQL request specific to part of the tree. You could perhaps request a level of tree depth. The gui can query the API schema via introspection, so definitely needs more thought.
In GraphQL subscription requests are used for updating information (incremental updates) with connections kept open, perhaps we could utilize that.
And, yes, for "suite discovery" you would need the reverse proxy.
dwsutherland
on 18 Jul 2018
Finally manage to have time to put some comments here!
The proposed reverse proxy has these purposes:
- It allows a single point of access for users on a given site. It will typically be started up using a good set of SSL certificate pair that will allow browsers to trust it without users having to fiddle with browser trust settings.
- It can manage authentication.
- It can manage or spin up services to manage some levels of authorisation.
- It can spin up services to discover suites (running or not), start up new suites, and handle other services that do not involve a suite server program. E.g.
cylc graph,cylc review(son of Rose Bush), and/or currentcylc guiservices that only really require access to the file system. - It can also be extended for related web services that will replace
rose config-editand Rosie suite discovery service. - It can be a single access point for other services. E.g. task job messaging (for all or just for those submitted to run on external platforms).
- It is worth noting that the current GUIs can call very much every API points of the suite server program. There is no reason why we cannot handle task job messaging via the reverse proxy the same way as the rest of the API points. However, we may choose to handle task job messaging from local jobs differently to improve performance.
- (It may or may not end up doing all of the above, but we should explore the potentials.)
matthewrmshin
on 18 Jul 2018
@matthewrmshin - agreed (although I hadn't really thought of 6 when I wrote up my document on the proposed architecture...)
hjoliver
on 18 Jul 2018
On 6. again - "suite discovery" isn't really necessary for client commands executed by jobs, because the suite can tell its jobs its own location, so unlike user clients, job clients could talk directly to suites. On the other hand, I suppose it could be possible for the reverse proxy, but not the suite, to be visible from job hosts. [UPDATE] And it may be more convenient to go via the proxy anyway (e.g. if the client API looks different at the proxy).
hjoliver
on 18 Jul 2018
For point 6. The emphasis is single point of access, not suite discovery. This is a good solution for jobs running on platforms that may not have full access to the suite platform, but is able to punch through the single access point. Of course, this is not necessary for local jobs or for jobs running on platforms that are able to fully access the suite platform.
matthewrmshin
on 18 Jul 2018
Yes, I think we agree; I just meant that going through the proxy is a necessity for user clients because of the suite discovery requirement, but not necessarily for job clients ... although it may still be very convenient for other reasons as you point out.
hjoliver
on 18 Jul 2018
Agreed GraphQL+WebSocket for the suite API
Hmmm, for the GUI this makes sense, for the suite API less so. I think we're probably just clashing terminology here but just to make sure.
Suite API:
- Simple call response model
- One off bursts of data -> nothing to gain from WebSockets?
- Examples:
broadcaststophold
GUI Interface (Suite State API?):
- Interface to suite data model for retrieving suite state information.
- Could be used for one off purposes e.g.
cylc ping. - Could be used for long running communication e.g. the future version of
get_graph_raw.
As regards GraphQL, I guess in theory we could use it for the suite API, (e.g. cylc stop would become a mutate request involving the suite status) could be a bit of a stretch though.
oliver-sanders
on 18 Jul 2018
@oliver-sanders - clarification needed!
I think of "the suite API" as being the complete suite server API available to all clients.
You are making a distinction between "suite API" vs "GUI Interface (Suite State API)". Do you mean:
- (a) two parts of the complete suite server API (in my sense): the API subset that returns suite status for the GUI vs the subset used for all other queries and control commands; OR
- (b) the API the GUI sees at the reverse proxy vs the API the reverse proxy sees at the suite?? (which may or may not differ, depending?)
I think you mean (a) but I'm not sure. If so, I agree those two aspects of the complete suite server API are very different. I have been assuming we might cater to that with two GraphQL endpoints, or one GraphQL endpoint (for the GUI) and multiple REST endpoints for the rest - but I have no idea if that is a reasonable thing to do. Also, yes WebSocket probably has little advantage for the non-GUI stuff, but maybe there's no disadvantage either, if using it for everything for simplicity/consistency (I don't know though, at this stage).
If you mean (b), note WebSocket can apparently go straight through proxy servers, automatically.
hjoliver
on 18 Jul 2018
clarification needed!
Short answer, I don't know, it depends what approach we go down with the One Cylc GUI. If the suite is serving its own status as with the current model then (a), if a "GUI server" is serving the status of many suites (i.e. scraping the database rose bush style) then (b)?
one GraphQL endpoint (for the GUI) and multiple REST endpoints for the rest
Probably the easiest way to get a proof of concept working.
If you mean (b), note WebSocket can apparently go straight through proxy servers, automatically.
Brilliant
oliver-sanders
on 18 Jul 2018
if a "GUI server" is serving the status of many suites (i.e. scraping the database rose bush style)
Interesting. Do you mean literally the database - i.e. the suite server program has no API at all for suite status? Did this come up in June meetings? (I might have missed it).
hjoliver
on 18 Jul 2018
Architecturally, such a GUI server would be another service under the reverse proxy?
hjoliver
on 18 Jul 2018
Did this come up in June meetings
It did, though by that point we were so well entrenched in the future architecture discussions that it was easily missed!
It's not something we have any sort of agreement on at this end but is worth noting as an option. This would keep the suite server process free from the load of GUI requests. What information do we actually need to bother the suite for?
If we are going to open up the opportunity for viewing other peoples suites this is definitely something we need to think about. This way the load is put on the users own GUI server? rather than the other users suite. As it stands at the moment we couldn't possibly open up read-only viewing of operational suites with the current architecture as the suite would be completely inundated.
the suite server program has no API at all for suite status
In that model probably not!
oliver-sanders
on 18 Jul 2018
This would keep the suite server process free from the load of GUI requests
(That does ring a bell, now that you mention it!)
hjoliver
on 18 Jul 2018
Dave has raised concerns that file system latency might mean this approach isn't compatible with a responsive GUI. The current reaction time is ~1s so we wouldn't want anything much worse than this. Sqlite3 uses fsync so this shouldn't be mush of a problem?
Barriers to overcome with this approach would be coming up with an efficient way of polling for changes in the DB and avoiding locking issues.
oliver-sanders
on 18 Jul 2018
Under heavy load that might require a proper client/server database.
hjoliver
on 20 Jul 2018
... WebSocket probably has little advantage for the non-GUI stuff,
Maybe I was wrong there. WebSocket, being two-way, could allow quick real response to client commands, rather than the current "command queued" response.
hjoliver
on 20 Jul 2018
Yes, a bidirectional socket is very advantageous for the GUI - it reduces the need to the client to poll the suite for status, so the suite can update its client when it needs (or chooses) to do so.
matthewrmshin
on 20 Jul 2018
https://www.fullstackpython.com/websockets.html
A multi-threaded or multi-process based server cannot scale appropriately for WebSockets because it is designed to open a connection, handle a request as quickly as possible and then close the connection. An asynchronous server such as Tornado or Green Unicorn monkey patched with gevent is necessary for any practical WebSockets server-side implementation.
hjoliver
on 30 Jul 2018
Yes I've heard of GraphQL used in conjunction with gevent to obtain an asynchronous server (was mentioned in a presentation on GraphQL (on YouTube)). I had to do the monkey patching when I implemented gevent's pyWSGI server in that Flask+gevent branch.
dwsutherland
on 31 Jul 2018
Here's a good/typical explanation of the pros and cons of Websocket vs HTTP: https://stackoverflow.com/a/29933428
It seems to me that Websocket is a clear winner for Cylc purposes. None of the HTTP pros seem particularly relevant to our use cases.
Do we know enough at this stage to agree on Websocket, short of unforeseen problems?
hjoliver
on 6 Aug 2018
Agree that Websocket is a clear winner. Most major browsers have client support, so we only need to find a good way to support the protocol at the server end (and ensure that the reverse proxy can redirect the (initial) request correctly).
matthewrmshin
on 6 Aug 2018
@hjoliver - Matt Makai did a really thorough job on that fullstack article;
https://www.fullstackpython.com/websockets.html
it has some really good resources and examples referenced, i.e. flask websockets implementation (which required gevent):
https://flask-socketio.readthedocs.io/en/latest/
@matthewrmshin - He also details/references Nginx support for websocket proxying:
http://nginx.org/en/docs/http/websocket.html
With his presentation/tutorial on YouTube:
https://youtu.be/L5YQbNrFfyw
I followed along and wrote the code out as he went (couldn't find his github resource):
https://github.com/dwsutherland/flask-gevent-websockets
(if you want to play around)
Which could be paired with flask-graphql;
https://github.com/graphql-python/flask-graphql
and perhaps/probably graphene:
http://docs.graphene-python.org/projects/sqlalchemy/en/latest/tutorial/
(On a seperate note - GraphQL has many advantages, one downside is it will put more load on the server in resolving objectTypes (may have been mentioned above)... Perhaps dwarfed by the alleviation on network traffic.)
I've been thinking a bit about how to elegantly represent the scheduler's data structure in GraphQL, I was thinking of a flat structure of 'task' and 'family' type objects;
type task {
name = String!
state = String!
parent(s?) = family([family]?)
title = String
description = String
. . . etc
}
type family {
name = String!
title = String
description = String
tasks = [task]
parent(s?) = family([family]?)
}
([] indicates a list, and assuming the name has the cycle in it ... )
Then to obtain a picture of the tree you'd need to create a query like;
type Query {
allTasks(cycle: CyclePoint): [task]
}
Then your request sent to the server might look like;
query alltasks{
name
state
. . . etc
parent {
name
}
}
(perhaps a family equivalent, or represent task and family as the same type)
There's obviously a number of ways to conceptualize it (and hence write the GraphQL schema), and we need to work out the resolver methods (which would call new functions in the scheduler object).. But I'll test the above once I've learned/played-around enough.. The load on the server may be reduced with the use of dataloaders;
http://docs.graphene-python.org/en/latest/execution/dataloader/
It will be a more extensive rewrite of schedular, network, gui (current) code.. But doable.
Heck, it could even be incrementally done:
- Design the GraphQL schema (in graphene).
- Start from the flask-gevent implementation of Cylc's API, leave the current end-points in place, then implement changes and expose a new graphql endpoint.
- Then incrementally switch the downstream to it (perhaps deprecating the old).
- Switch to a Websocket protocol (or possibly have both while dev?!), work on downstream changes (i.e. network/httpclient.py).
- Create subscription type GraphQL queries.
- Deprecate REST endpoints etc.
Thoughts? :-)
dwsutherland
on 8 Aug 2018
@dwsutherland - thanks for the excellent references and thoughts, will digest as soon as possible...
hjoliver
on 8 Aug 2018
BTW - Tornado may still a possible candidate, since the inbuilt asynchronous server is ideal for websockets too;
http://www.tornadoweb.org/en/stable/guide/intro.html
http://www.tornadoweb.org/en/stable/websocket.html
however, it doesn't appear to have the equivalent support for graphql/graphene as Flask with it's extension flask-graphql (or Django...)...
dwsutherland
on 8 Aug 2018
Deciding on the GraphQL schema is going to require a lot of thought as these interfaces [1] define Cylc itself. The GraphQL endpoint needs to be compatible with future plans for both the scheduler (e.g. divorcing from the task pool implementation) and GUI (e.g. better filtering). We should probably spin this off into a separate discussion when we are ready to get into it.
[off the top of my head] Some considerations:
- Graph structure
- Model for representing graph structure
- Node and edges (aka graphviz, see also GitHub GraphQL interface which uses these terms throughout)
- Heavyweight for large graphs (particularly diamond patterns)?
- Pattern + State (the GUI holds the pattern of the graph and fills it in with task states as they arrive)
- Tasks can occur on multiple recurrences, how could the GUI determine which one it belongs to? We cannot
import isodatetimeorcylc.cyclingas the GUI will be implemented in JavaScript.
- Tasks can occur on multiple recurrences, how could the GUI determine which one it belongs to? We cannot
- How do we minimise traffic when graph nodes are collapsed?
- Querying
- Family collapsing
- Filtering by task/job state (e.g. by default we filter out runahead tasks)
- Filter by graph distance https://github.com/cylc/cylc/issues/1873#issuecomment-330254260
- Suicide triggers and optional branching (https://github.com/cylc/cylc/issues/1903)
- Ghost nodes (now need to be computed suite side)
- Task-Job relationship
- We are working towards decoupling this in Cylc, the GUI should be similar. Jobs nested within tasks?
- Task structures beyond families
- We shouldn't lock ourselves into a family model, we already have other ways of defining task groups e.g. parameterisations and queues. These groupings don't change in the same manner that task/job's do?
- Migration
rose_bunchtype functionality into Cylc
- Any implications on this model of Cylc moving from the task pool to an event driven architecture?
- No more task pool, we need to be more explicit about what tasks we want to request.
- The graph could potentially become more dynamic
[1] user suite definition (rc), internal suite definition (cylc.config), runtime datastructure (suite db), ...
oliver-sanders
on 8 Aug 2018
@oliver-sanders - Yes, we will need to approach this with a level of sophistication; I was simply trying to layout (in GraphQL pseudo-like code) a way of describing one aspect; the inheritance tree (arguably the hardest, due to it's arbitrary, and dynamic, breadth and depth (across suites)).
With respect to:
- Model
- for representing graph structure
- Node and edges (aka graphviz, see also GitHub GraphQL interface which uses these terms throughout)
- Heavyweight for large graphs (particularly diamond patterns)?
Graphene has support for relay:
http://docs.graphene-python.org/en/latest/relay/
which works in that context of nodes and edges.
Also, I'm not sure what we can do about;
- Pattern + State (the GUI holds the pattern of the graph and fills it in with task states as they arrive)
- Tasks can occur on multiple recurrences, how could the GUI determine which one it belongs to? We cannot import isodatetime or cylc.cycling as the GUI will be implemented in JavaScript.
Because the "pattern" may not be exactly static (or symmetric across occurrences), and if the schema mapped it out exactly we would need to rewrite the schema on suite definition reload and the gui would have to pick this up by introspection or something (? I could be wrong on this, there's still a lot I don't understand, but I gain understanding partly by having the conversation (^.^) )..
I think we do need a level of abstraction; but the appropriate level of analysis might be the task, because we can build the "big picture" up from the [GraphQL objectType] fields of a task;
- What occurrence/cycle it belongs to
- What family/families it belongs to.
- What queue it belongs to.
- What parameterisation it's constructed from.
- State. . . etc
Because the occurrence (cycle_point) is the only information that separates the same named task in an exclusive way, then ideally this information would also be included as an identifier: Perhaps have the name include the occurrence information task.cycle_point And/Or perhaps construct an id (node id) out of task.cycle_point, at least that would be unique..
We have the ability to query all tasks, scope down to the individual task, and/or filter on a field (queries can take args, and nodes take id args). Also there is a way of applying filters on query results also (first, last, range ...etc).
If we are to split the GraphQL schema into a different issue, then in this issue we need to decide on the vehicle that will accommodate GraphQL&websockets, as well as the existing REST end points (unless we do it in one big bang). I've shown that Flask is a good fit, but will add a simple GraphQL endpoint as proof of concept.
dwsutherland
on 9 Aug 2018
+1 for websockets then! :raised_hands:
@dwsutherland
however, it doesn't appear to have the equivalent support for graphql/graphene as Flask with it's extension flask-graphql (or Django...)...
True! Found an open ticket for tornado, with some existing code that could work (and they wanted to donate to graphene as reference impl) https://github.com/graphql-python/graphene/issues/718 will check over there what needs to be done to get the code working, so that we can at least compare Flask & Tornado, and maybe even look at Django and CherryPy (maybe just to point differences, peculiarities, etc).
@oliver-sanders
Deciding on the GraphQL schema is going to require a lot of thought as these interfaces [1] define Cylc itself. The GraphQL endpoint needs to be compatible with future plans for both the scheduler (e.g. divorcing from the task pool implementation) and GUI (e.g. better filtering). We should probably spin this off into a separate discussion when we are ready to get into it.
:+1: maybe another discussion/issue for the authentication improvements as well. It was mentioned in the issue description, but most of the recent discussion has been mainly around the first two items, but I think there will be a lot to be discussed about security/authentication/groups/roles/etc.
kinow
on 9 Aug 2018
Superseded by Cylc-8 Architecture.
matthewrmshin
on 28 Jan 2019
Related issues
oliver-sanders
·
3Comments
kinow
·
4Comments
hjoliver
·
5Comments
oliver-sanders
·
3Comments
kinow
·
4Comments
Most helpful comment
Finally manage to have time to put some comments here!
The proposed reverse proxy has these purposes:
cylc graph,cylc review(son of Rose Bush), and/or currentcylc guiservices that only really require access to the file system.rose config-editand Rosie suite discovery service.