Cudf: [FEA] Port CSV writer to `cudf::column` types
Port the writer to libcudf++: use the new table/column types and follow the new scheme for IO functions.
 vuule
vuule
All 45 comments
So, I assume a valid API for the CSV writer would be the complementary of read_csv(...)'s signature:
void write_csv(table_with_metadata const& tbl_w_m,
write_csv_args const& args,
rmm::mr::device_memory_resource* mr = rmm::mr::get_default_resource())
@davidwendt, @vuule was that agreed upon already (in which case, what is the agreed-upon signature?) or what are your thoughts on the API?
Thanks in advance.
 aschaffer
on 12 Mar 2020
aschaffer
on 12 Mar 2020
I think it should be the same as write_orc or write_parquet (for consistency, if nothing else), where the table and the metadata are included in the arg struct.
vuule
on 12 Mar 2020
The porting pattern of readers / writers appears to be the following (Fig 1.):
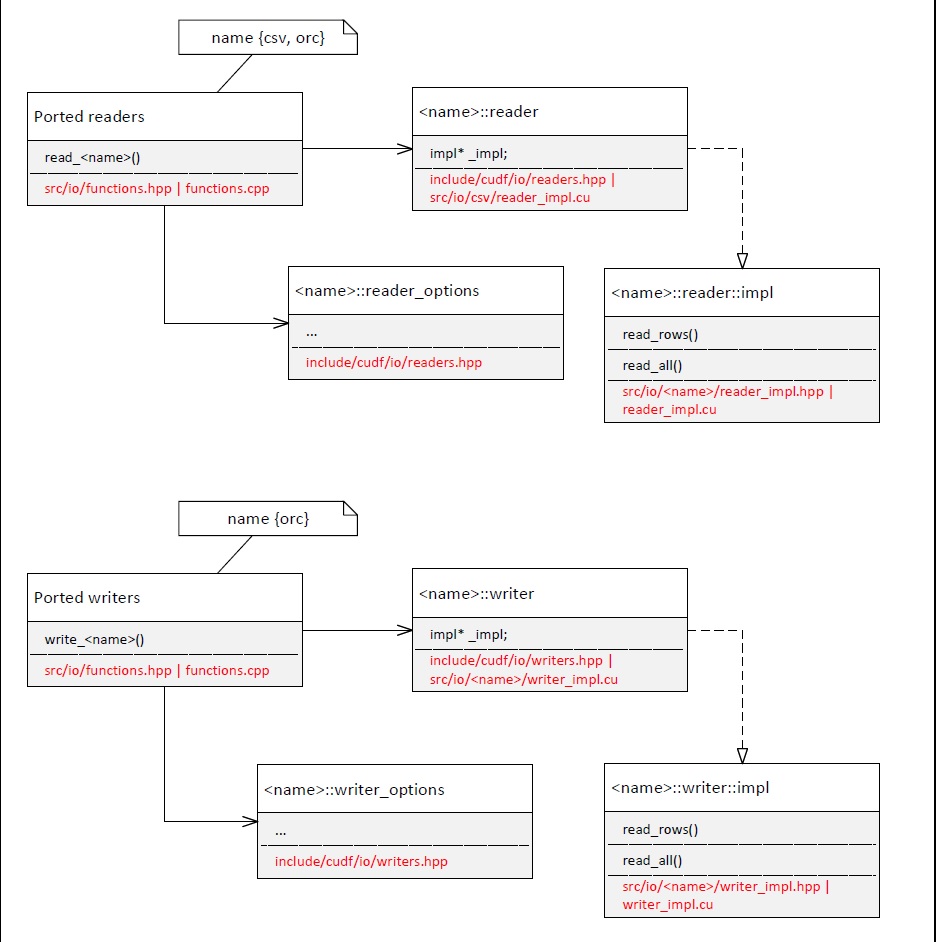
This mirrors the legacy structure (Fig 2.):
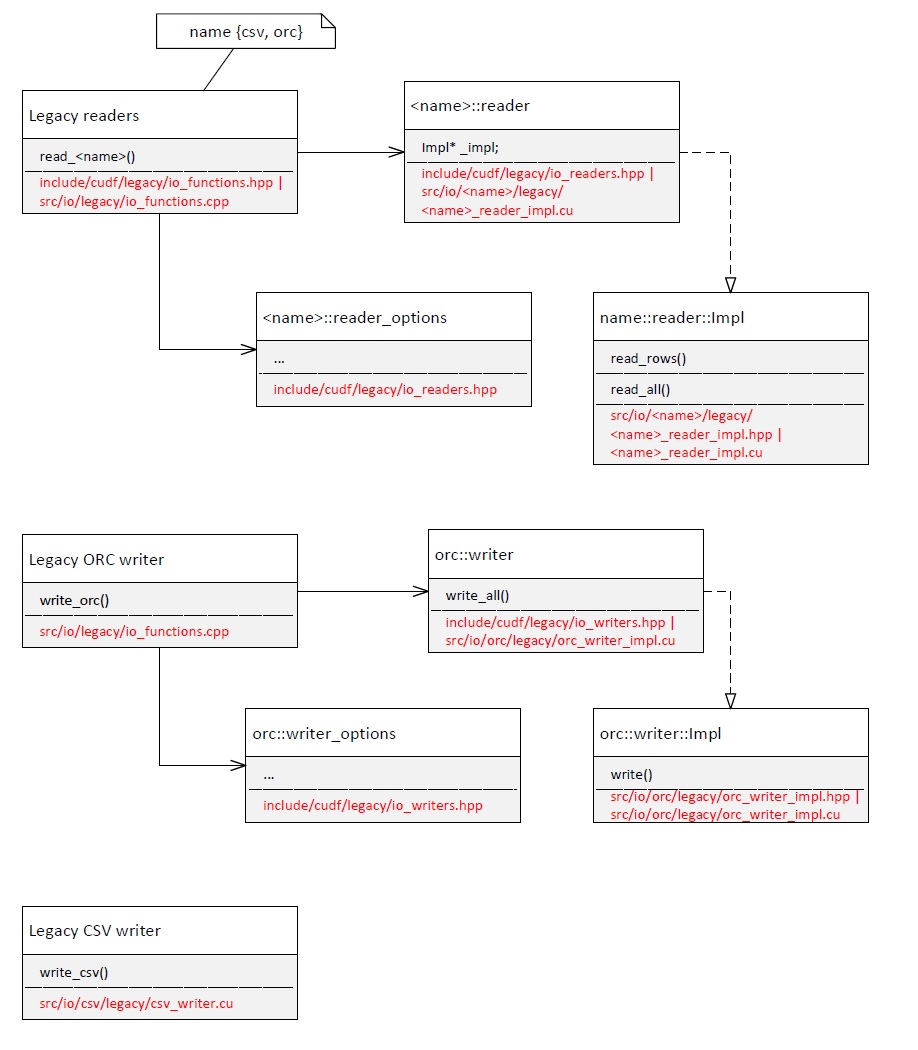
With the _exception_ of the CVS writer which is standalone. Should then the ported CVS follow the more complex structure in Fig 1. or the standalone one in Fig 2. ?
aschaffer
on 25 Mar 2020
I think it's better to make it consistent with other writers. Do you have any concerns with this option?
vuule
on 25 Mar 2020
Do you have any concerns with this option?
In general, not really. It'll be a bit more re-org work than initially expected, but probably worth it.
One issue might be which parts of the legacy code should be delegated to writer_options. I assume, just the csv_write_arg* args.
aschaffer
on 25 Mar 2020
What is the motivation behind <reader/writer>_options? It seems that they just copy data from read/write_<name>_args (where <name> is orc, csv, etc.). Why not directly use the read/write_name>_args, then?
The motivation for this question is the design model (Fig 1. above) that I'm trying to also follow for porting the CSV writer. The options just seem to be a pass-through abstraction (in which case time would be just wasted with copy ops). If there's more to their "raison d'etre" could someone please explain? Thanks in advance.
aschaffer
on 31 Mar 2020
I think it's a leftover from the time we had a C API because of the way the interop between Python and C++ was implemented. This was used for C++ <-> conversion and parameter validation.
ATM it's not always just a data copy, but I think we don't necessarily need to have two layers here.
CC @OlivierNV in case I'm missing something.
vuule
on 31 Mar 2020
Yeah. Personally, I really don't like the *_args C-style API in functions.hpp (legacy from pre-cython days afaik), but unfortunately, that is still the primary way the readers/writers are being called (though it might still have some benefits on the caller side, like reducing the read/write table op to a simple function call). The downside is that every time we have to make a minor addition in the reader/writer args, we have to basically add the same thing in 4 different places (!). Perhaps having *_args inheriting from *_options would avoid some of that duplication...
 OlivierNV
on 31 Mar 2020
OlivierNV
on 31 Mar 2020
Perhaps having *_args inheriting from *_options would avoid some of that duplication...
I was thinking the same. Perhaps, even private inheritance to not enforce an IS-A dependency between 2 abstractions that do not (or might not, in the future) have enough in common.
Another question would be: what's the deal with these statistics (compression, etc.)? I see them in the reader options/args but in the CSV writer args.
aschaffer
on 31 Mar 2020
Another question would be: what's the deal with these
statistics(compression, etc.)? I see them in the reader options/args but in the CSV writer args.
Generally, the readers have way more options than the writers, since we need to support different types of CSVs (such as compressed CSVs, various ways to specify column dtype, and/or various delimiter syntax types), whereas on the writer, we're somewhat free to choose what to support (for example, no compression for CSV) and we get dtype information from the table itself.
OlivierNV
on 31 Mar 2020
What is the purpose of <name>_chunked_state and the begin() / write() / end() call process? (orc and parquet have them) Do we need that in CSV writer? I see some "chunk" comments and a rows_per_chunk field in the legacy code.
aschaffer
on 2 Apr 2020
What is the purpose of
_chunked_state and the begin() / write() / end() call process? Do we need that in CSV writer? I see some "chunk" comments and a rows_per_chunk field in the legacy code.
I'm not familiar with this part at all. @OlivierNV ?
vuule
on 2 Apr 2020
Also, I see various constants in the orc/parquet writers, like:
(orc:)
static constexpr uint32_t DEFAULT_STRIPE_SIZE = 64 * 1024 * 1024;
static constexpr uint32_t DEFAULT_ROW_INDEX_STRIDE = 10000;
static constexpr uint32_t DEFAULT_COMPRESSION_BLOCKSIZE = 256 * 1024;
(I think we established there's no compression in CSV writer)
(parquet:)
static constexpr uint32_t DEFAULT_ROWGROUP_MAXSIZE = 128 * 1024 * 1024;
static constexpr uint32_t DEFAULT_ROWGROUP_MAXROWS = 1000000;
static constexpr uint32_t DEFAULT_TARGET_PAGE_SIZE = 512 * 1024;
Anything similar in CSV? (nothing seems to be there in the legacy code, but maybe I'm wrong).
aschaffer
on 2 Apr 2020
The more I dig the more abstraction layers seem to be involved in the ported writers. AFAIK, the diagram of a typical ported writer looks like this:
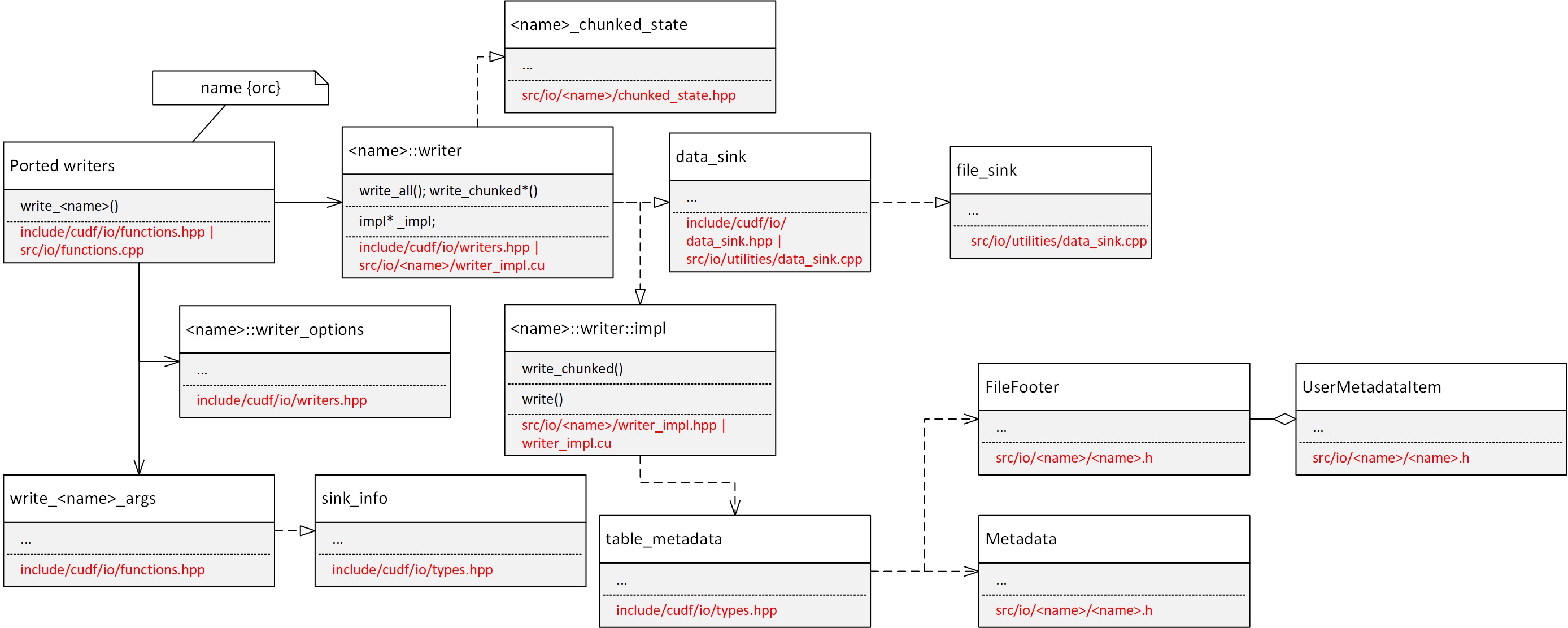
...while the legacy CSV writer is this:

So, the question is: do we really need all those layers for the CSV writer, or can we get away with a more simplified structure?
aschaffer
on 2 Apr 2020
The write_chunked support is to append to an existing file. Unlike columnar formats, for a linear text format like CSV, it essentially means to just open the file in append mode and skip writing the header line, so no need to have a very separate path for that IMO (no chunked_state needed afaict).
Similarly, rowgroups/compression/stripes/page concepts are unique to columnar formats, and do not exist in CSV.
[In the chart above, the read_rows/read_all is from the readers, not writers]
OlivierNV
on 2 Apr 2020
Can anyone explain the purpose of two different classes that seem to serve same purpose: sink_info and data_sink? (for file locations see the diagram in the 1st diagram above). And how's the data flow from one to another? Do I need to address any special piping between these 2 classes, or is that implicit in the design above?
aschaffer
on 6 Apr 2020
What flag (or other piece of info) specifies that the user wants to _append_ to existing file (hence skip the header) or write a plain new file? The filepath seems to be buried inside sink_info but there's no state specifying which is desired: append vs. write-new.
Also, looking for example at orc writer: it seems like the header is always written, in spite of additional orc_chunk_state class which is not used in the case of writing the beginning of the chunk (header). Can someone point of an example where/how the decision of append vs. write-all is done in such writers? Thanks in advance.
aschaffer
on 6 Apr 2020
Can anyone explain the purpose of two different classes that seem to serve same purpose: sink_info and data_sink?
data_sinkis an interface users can implement as a custom sink.sink_infois a part of the old C-style API, provides a way for users to specify the sink type by passing different param type (string, buffer, arrow file, etc.).sink_infocan take adata_sinkpointer and this object will then be used in the writer.
Pretty sure they can be merged and then writers can take a pointer to the base class. I think this is another left over from the C interface.
I hope this helped with the other questions above. Also, other writers show provide a good reference for the use of these types. Let me know if you have more questions.
@OlivierNV for the chunked state question.
vuule
on 6 Apr 2020
I'm assuming file_sink is what CSV writer needs (data_sink is an abstract base class for file_sink). If not file_sink is needed here, but one of the other derived classes; or, if the underlying "sink" can vary at runtime, please someone let me know. Thanks in advance.
file_sink keeps the state of the std::ofstream. I will then drop the dependency of the CSV writer on the alleged useless sink_info left-over.
However, the answer to deciding on the action, append vs. write, is still unclear.
aschaffer
on 7 Apr 2020
The sink type can vary at runtime, data_sinkprovides a virtual interface. I think the writer should use a pointer to data_sink. For consistency, the API can use the sink_info, same as other writers.
Overall, is there a reason why CSV writer cannot be implemented exactly the same as other writers?
vuule
on 7 Apr 2020
Overall, is there a reason why CSV writer cannot be implemented exactly the same as other writers?
I am trying to implement it exactly as the others (well, parquet and orc, to be specific). I'm just trying to understand _how_ they are implemented. As you can see in the above diagram, the more layers I peel off the more I find. The implementation seems to me overly complicated. I assume there's a good reason. I just need to understand it. I don't know how to mimic that implementation without a minimal understanding of how it works and justification for all those layers of abstraction (about 12 classes spread over 11 files...so far). BTW, the more I look at sink_info the more it seems it's not really being used. If it is, I'd like to understand how.
For example, the legacy code has some CUDF_EXPECTS on the CSV file handler. Do I need to do those checks, too? If so, where can I find the std::ofstream? Well, it's in the file_sink, but that varies at runtime. So, then this check could be dropped? Should I then trust the mechanism of handling the IO is taken care (checks in place, etc.) in the data_sink abstraction? Or, sink_info? Or both? Etc.
aschaffer
on 7 Apr 2020
Afaik, the sink_info struct is just the parameters needed to construct the data_sink class (only used in write_*_args). CSV writer should be able to use the same sink class as orc/parquet writers for file io. It will likely need to be modified to add support for append mode (I don't think the file sink currently has an append mode, though that could be added later on).
Unlike CSV, in the case of columnar writers, the "header" is more of a "footer" and is written at the end of the file (in write_chunked_end), so that flow will be different for CSV (header, no footer).
Besides opening the file, I'm assuming the CSV writer essentially writes bytes at some point, which could presumably just be done through out_sink->host_write() or out_sink->device_write(), which would replace anything involving std::ofstream
OlivierNV
on 7 Apr 2020
It will likely need to be modified to add support for append mode (I don't think the file sink currently has an append mode, though that could be added later on).
Okay, thanks. But, the decision of whether the operation should be an append rather than a brand new write, how is that done in orc / parquet ? There should be a flag or arg specifying that. I don't see it. Is the append functionality working for orc / parquet ?
aschaffer
on 7 Apr 2020
The use of the write_chunked_* api implies a sort of progressively writing to the file (each write_chunked appends), but it's not a true append mode, as it starts the file from scratch at write_chunked_begin().
We will likely need a true append mode (as in 'append to an existing parquet/orc file') in the future, which will require a new 'append' flag to be added to sink_info.
OlivierNV
on 7 Apr 2020
We will likely need a true append mode (as in 'append to an existing parquet/orc file') in the future, which will require a new 'append' flag to be added to sink_info.
Ah. That's a separate effort. I have been told to focus on porting _existing_ functionality. I don't mind squeezing a few things here and there, but API changes probably will _not_ be accepted for this release (not my decision).
aschaffer
on 7 Apr 2020
Correct. True append mode is afaik not supported by any of the writers (can be deferred to a separate PR in 0.15, issue #4715 exists to track this, though not entirely sure what happens on the CPP side when a file object is passed on the python side).
OlivierNV
on 7 Apr 2020
What's the logic with out_sink_->host_write()/device_write() ?
if(out_sink_->supports_device_write())
out_sink_->device_write(...);
else
out_sink_->host_write(...);
CSV column names (header): I see a table_metadata that seems to contain that kind of info. Do I use that? It's not clear from orc/parquet writers.
Also, do I have any guarantee that the table_view argument to the API and the table_metadata::column_names are in sync? Or, what's the logic here?
aschaffer
on 14 Apr 2020
Yes, table_metadata contains the column names that corresponds to the table view (unfortunately, no guarantees, as names are not part of the column or table). The ordering of names is described in the table_metadata definition, simple 1:1 mapping without nesting. In parquet/ORC writers, names will be made up on-the-fly if the column_names vector is empty (like _col0, _col1, etc).
OlivierNV
on 14 Apr 2020
device_write allows writing data in device memory, for data sinks that support it (it may be more efficient with some sinks), whereas host_write takes in a host memory pointer.
OlivierNV
on 14 Apr 2020
The ordering of names is described in the table_metadata definition, simple 1:1 mapping without nesting
So, the _actual_ column names, (for i in [0..ncols-1]), are in table_metadata::column_names[i]; or, in table_metadata::user_data[column_names[i]]? Thanks.
aschaffer
on 14 Apr 2020
device_writeallows writing data in device memory, for data sinks that support it (it may be more efficient with some sinks), whereashost_writetakes in a host memory pointer.
I guess, my question was: given the fact that out_sink_ can transparently change at runtime, I should always pair the check out_sink_->supports_device_write() with the right kind of write (device if the check passes; host otherwise). Correct?
Also, I assume a device_write(...) takes a device buffer while host_write(...) takes a host one (I don't see that stipulated in the dox). Correct?
Thanks.
aschaffer
on 14 Apr 2020
I guess, my question was: given the fact that
out_sink_can transparently change at runtime, I should always pair the checkout_sink_->supports_device_write()with the right kind of write (deviceif the check passes;hostotherwise). Correct?
Correct. device_write may not be implemented by some sinks (assumption is that the caller could implement a host-only path more efficiently than a generic default implementation of device_write).
Also, I assume a
device_write(...)takes a device buffer whilehost_write(...)takes a host one (I don't see that stipulated in the dox). Correct?
Correct.
OlivierNV
on 14 Apr 2020
For the CSV format, what is the desired handling of special characters, in a (string) column, like the delimiter itself (typically, ",") or newlines (or any other?).
Looking online I see that if a string entry has delimiters and/or newlines in it then that whole string entry must be placed between quotes.
Example:
Say delimiter is comma "," and we have a row with 3 columns:
[1, 2.01, Hello, World!]
Then the last column must be quoted, because it contains the delimiter:
[1,2.01, "Hello, World!"]
Same for newline 'n'. Is this the rule we want to follow for the CSV writer, too? If not, then what?
In the legacy code I see treatment of double quotes: <"> being doubled <"">, but, unless I'm missing something, no special treatment of newlines or delimiters present in a field.
Also, what other special characters need (what kind of) special treatment? Thanks in advance.
aschaffer
on 16 Apr 2020
The "," delimiter is handled here https://github.com/rapidsai/cudf/blob/5c67229207af9c79ba66d3866105d182db0adc37/cpp/src/io/csv/legacy/csv_writer.cu#L204
Double-quotes are handled here https://github.com/rapidsai/cudf/blob/5c67229207af9c79ba66d3866105d182db0adc37/cpp/src/io/csv/legacy/csv_writer.cu#L198
The original code did not have special code for new-lines inside strings. Mainly because the parser could not handle them. I believe the parser may be able to process new-lines inside of strings now?
 davidwendt
on 16 Apr 2020
davidwendt
on 16 Apr 2020
The reader should be able to handle newlines in strings.
Aside from these, I don't think there are other special characters you need to handle.
vuule
on 16 Apr 2020
The reader should be able to handle newlines in strings.
So, what should the writer do about newlines to make the reader happy? (looking at read_csv() is not clear what the reader _expects_ in terms of newlines).
The "standard" treatment of surrounding the whole string with double quotes (") if it contains newline(s) and/or delimiter characters in it, is that okay?
aschaffer
on 16 Apr 2020
The "standard" treatment of surrounding the whole string with double quotes (") if it contains newline(s) and/or delimiter characters in it, is that okay?
That's exactly what the reader expects.
vuule
on 16 Apr 2020
How about the presence of double quotes (") in a string? The legacy code was doubling them.
But how about the whole string that contains them? Should I also surround the whole string between double quotes, like it's done for the newlines and delimiters?
IOW, should I:
(1) _only_ double the quotes when encountered in a string?
Or,
(2) _only_ surround the whole string containing them by quotes?
Or,
(3) double the quotes _and_ surround the whole string by quotes?
aschaffer
on 16 Apr 2020
I think the option (3) is correct. I suggest adding a test for these cases to verify our assumptions, hits two birds with one stone IMO.
vuule
on 16 Apr 2020
Looks like option (1) works but will leave that up to cuIO team to answer.
Option (2) is invalid if I'm understanding it. "string with "internal" quote"
The legacy code is doing option (3) if that helps.
davidwendt
on 16 Apr 2020
The legacy code is doing option (3) if that helps.
Absolutely it helps. Thanks.
aschaffer
on 16 Apr 2020
Adding some discussion points from Slack:
Vukasin Milovanovic: 1 day ago
I think you can just replace n with linedelimiter
AFAIK the only reason n is treated in a special way is that it is usually the line delimiter (edited)
Olivier Lapicque 1 day ago
I'm not aware of a "line delimiter" in CSV, there is the "line terminator" (end-of-line character) and the column "delimiter" (separator between columns). There are two ways to deal with delimiters/terminator within string fields:
When quoting is enabled, the string field is encapsulated between quotes (delimiter/separator in quotes are ignored)
If quoting is disabled, the delimiter/separator should be preceded by the special escape character (configurable, usually \)
Note that option 2 is not currently supported by the cudf csv reader, and the support for line terminator within quotes is currently a bit sketchy when combined with the use of byte range. (edited)
Olivier Lapicque 1 day ago
Also, the limited quoting mode in pandas encapsulates string fields in quotes but not numeric fields (the full quoting mode encapsulates all fields within quotes iirc). Quotes in quote-encapsulated fields are replaced by doublequotes, but not in non-quoted fields.
Vukasin Milovanovic: 1 day ago
yeah, this param should be named lineterminator
Vukasin Milovanovic: 1 day ago
@Olivier Lapicque do we currently support QUOTE_ALL in the reader?
Olivier Lapicque 1 day ago
@Vukasin Milovanovic Yes, from what I can see, the reader will automatically remove quotes from numeric fields (trim_field_start_end) if they are present (as long as quotechar is specified in the reader args). (edited)
Andrei Schaffer 1 day ago
A lot of new fields I haven't accounted for... I'll put together another pseudocode with the logic we want here and perhaps we can sign-off on that.
Andrei Schaffer 1 day ago
So, this is different than what was discussed on the GitHub issue: https://github.com/rapidsai/cudf/issues/4342#issuecomment-614877138
vuulevuule
Comment on #4342 [FEA] Port CSV writer to cudf::column types
I think the option (3) is correct. I suggest adding a test for these cases to verify our assumptions, hits two birds with one stone IMO.
https://github.com/rapidsai/cudf|rapidsai/cudfrapidsai/cudf | Apr 16th | Added by GitHub
Andrei Schaffer 1 day ago
So, then, I scrap the logic I put in place from the GitHub conversation and implement this, instead: https://nvidia.slack.com/archives/CCWT6NJ0K/p1588212258091600?thread_ts=1588201893.089300&cid=CCWT6NJ0K ?
I'm not aware of a "line delimiter" in CSV, there is the "line terminator" (end-of-line character) and the column "delimiter" (separator between columns). There are two ways to deal with delimiters/terminator within string fields:
- When quoting is enabled, the string field is encapsulated between quotes (delimiter/separator in quotes are ignored)
- If quoting is disabled, the delimiter/separator should be preceded by the special escape character (configurable, usually )
Note that option 2 is not currently supported by the cudf csv reader, and the support for line terminator within quotes is currently a bit sketchy when combined with the use of byte range.
From a thread in #rapidsdev-io | Apr 29th | View reply
Andrei Schaffer 1 day ago
(at some point we must "freeze" the specs if we want to release...)
Andrei Schaffer 1 day ago
"Note that option 2 is not currently supported by the cudf csv reader,"...okay, so what is the desired implementation for the CSV Writer?
Andrei Schaffer 1 day ago
(I must admit I am confused, rt now about the desired functionality)
Andrei Schaffer 1 day ago
We went before off a tangent (with the append issue, which I thought was implemented and it isn't) and I wasted quite some time with that. So, avoiding "wishes" and "nice-to-haves":
what is the desired treatment of special characters?
which are the special characters?
which are runtime configurable and which are fixed?
what other flags and config variables from the reader must also be used in the writer?
Andrei Schaffer 1 day ago
Right now, the functionality is:
if str.any_of{'\"', 'n',
surround the entire string by double quotes:
str = '\"' + str + '\"'
and
double the double quotes; i.e., any '\"' encountered inside str becomes "\"\"" (except the prefix and suffix-added double quotes, obviously).
If that isn't the desired behavior, please specify what is. At least lets finally agree on the behavior (treatment of special characters), which is harder to pass at runtime (special characters can be decided at runtime). @Olivier Lapicque, @Vukasin Milovanovic, @Ayush Dattagupta please let's sign off on this. It's getting late in the process to not agree on functionality. Thanks in advance.
Olivier Lapicque 1 day ago
The option above seems reasonable (quotes around strings that contain special characters and quotes->doublequotes). It could be useful to also have the option to always surround string fields in quotes. The CSV spec isn't very well defined (hence lots of args in the reader). As I said before, though, in the writer, we're free to choose/limit what we want to implement (unlike the reader).
aschaffer
on 1 May 2020
(..cont'd from Slack)
Andrei Schaffer 18 hours ago
Hey @Olivier Lapicque, 2 things (a question and more of an FYI):
May I post this conversation :arrow_up: on the GitHub issue (#4342) ?
I had to go back to the sink-><host/device>write(...) in a loop (thrust::for_each()) rather than all rows at once. Because of the lineterminator that must be interposed between rows. There could be other solutions...but more complicated and I doubt they'd bring any performance benefits because of the additional device memory traffic.
Andrei Schaffer 18 hours ago
(essentially going back - and fixing - the implementation of commit SHA 1c4658949c847f38b3062fda903842ec334f5402 :
git checkout 1c4658949c847f38b3062fda903842ec334f5402 src/io/csv/writer_impl.cu )
Olivier Lapicque 18 hours ago
Ok with me, though I would think that writing a csv with a few column of 100 million ints or floats is going to be a big problem -> why not just append the terminator to the last column once it's in string form ?
Andrei Schaffer 18 hours ago
The columns don't get transformed to string form one-by-one. The whole row gets stringified by concatenate().
Andrei Schaffer 18 hours ago
So, I'd have to post-process that resulting 1-column of strings to append the lineterminator. Which must go through the 2 steps process of modify_strings(), namely 1 pass to create space on the device (for the original row + line terminator); 2nd pass to essentially copy the original row and then append the lineterminator. And that gets copied on the host, anyway.
Andrei Schaffer 18 hours ago
Look, you've more experience w/ cuio than me, obviously. If you think this 2nd approach (post-process) is worth the effort to avoid the loop...than I'll do that.
Andrei Schaffer 18 hours ago
Why would "100 million ints or floats is going to be a big problem"? (with the for_each approach)
Andrei Schaffer 18 hours ago
(remember, the write happens in chunks, anyway)
Olivier Lapicque 18 hours ago
Not super familiar with string functionality in cudf (the legacy reader appears to just use append a different delimiter when concatenating the last column, which I was hoping the libcudf++ strings could do as well). Maybe I'm misunderstanding something, I thought that by not transferring the contiguous character in one batch, it would result in 100 million DtoH and sink->write() calls of a dozen bytes each if there are 100 million rows for two float columns for example.
Andrei Schaffer 17 hours ago
No additional D2H because of newline. The logic is this:
if( out_sink_->supports_device_write()) ) {
d_newl = copy newline to D;
loop row_index{
out_sink_->device_write(buffer + offsets[row_index], sizes[row_index], blah...);
out_sink_->device_write(d_newl.data().get(), d_newl.size(), blah...);
} // end loop row_index
} else { similar for host...}
Andrei Schaffer 17 hours ago
Unless device_write does a D2H, which I realize it must...
Andrei Schaffer 16 hours ago
Okay, I'll investigate tomorrow the postprocessing approach.
aschaffer
on 1 May 2020
Legacy csv writer failed to update header to file if table has 0 rows, but other csv writer such as pandas writes header information. It would be nice if we can support this.
 rgsl888prabhu
on 11 May 2020
rgsl888prabhu
on 11 May 2020
Related issues
 shwina
·
3Comments
shwina
·
3Comments
 beckernick
·
3Comments
beckernick
·
3Comments
 kkraus14
·
3Comments
kkraus14
·
3Comments
 AjayThorve
·
3Comments
AjayThorve
·
3Comments
 c-jamie
·
3Comments
c-jamie
·
3Comments