Cudf: [BUG] Dask_cudf creates duplicate tasks during compute and transfers causing memory issues
Describe the bug
Dask_cudf creates duplicate tasks during compute and transfers causing memory issues.
This behavior is really worse when workstealing=on and with rmm on (possibly because of more transfers)
Example Workflow:
Gist: https://gist.github.com/VibhuJawa/5e0be2b8d754db9612b15c476ec4b7af
Steps/Code to reproduce bug
Helper Code:
import os
work_stealing = False
os.environ['distributed.scheduler.work-stealing']='False'
import dask
dask.config.set({"distributed.scheduler.work-stealing": work_stealing})
import dask_cudf
import cudf
import cupy as cp
import rmm
import collections
import dask.dataframe as dd
from dask import delayed
import dask.array as da
from dask_cuda import LocalCUDACluster
from dask.distributed import Client,wait
from dask.utils import parse_bytes
def create_random_data(n_rows=1_000,n_parts = 10, n_keys_index_1=1_000):
chunks = n_rows//n_parts
df = dd.concat([
da.random.random(n_rows, chunks = chunks).to_dask_dataframe(columns= '_non_merge_1'),
da.random.random(n_rows, chunks = chunks).to_dask_dataframe(columns= '_non_merge_2'),
da.random.random(n_rows, chunks = chunks).to_dask_dataframe(columns= '_non_merge_3'),
da.random.random(n_rows, chunks = chunks).to_dask_dataframe(columns= '_non_merge_4'),
da.random.randint(0, n_keys_index_1, size=n_rows,chunks = chunks ).to_dask_dataframe(columns= 'key'),
], axis=1).persist()
gdf = df.map_partitions(cudf.from_pandas)
gdf = gdf.persist()
_ = wait(gdf)
return gdf
protocol = "ucx"
enable_nvlink = True
cluster = LocalCUDACluster(
protocol=protocol,
enable_nvlink=enable_nvlink,
device_memory_limit = '31 GB',
)
client = Client(cluster)
# def setup_rmm_pool(client):
# client.run(
# cudf.set_allocator,
# pool=True,
# initial_pool_size= parse_bytes("30 GB"),
# allocator="default"
# )
# return None
# setup_rmm_pool(client)
# client.run(cp.cuda.set_allocator, rmm.rmm_cupy_allocator)
def get_total_tasks_held_by_dask(client):
"""
Util function to get total tasks held in memory by dask
"""
client_dict = client.has_what()
total_tasks_held = 0
for key,value in client_dict.items():
total_tasks_held+=len(value)
del client_dict
print("Total tasks held by client= {}".format(total_tasks_held))
def get_dup_tasks_count(client,df,print_dups = False):
'''
Find duplicate tasks held by dask for that dataframe
'''
dataframe_dask_keys = [str(key) for key in df.__dask_keys__() ]
client_dict = client.has_what()
### this creates a key map
## where key is worker_ip
## and values are the dataframe objects at that key
worker_key_map = {}
for worker_ip,worker_tasks in client_dict.items():
worker_key_map[worker_ip] = [dask_key for dask_key in worker_tasks if dask_key in dataframe_dask_keys]
all_task_list = []
for key,task_ls in worker_key_map.items():
all_task_list+=task_ls
dup_list = [item for item, count in collections.Counter(all_task_list).items() if count > 1]
total_dup_tasks = len(dup_list)
for dup_task in dup_list:
for key,task_ls in worker_key_map.items():
if dup_task in task_ls:
if print_dups:
print(f"key {key} dup_task = {dup_task}")
if print_dups:
print("-"*50)
return total_dup_tasks
rows_1, parts_1 = 3_000_176_770, 400
### create random dataframe
df_1 = create_random_data(n_rows= rows_1, n_parts = parts_1)
key_df = df_1['key'].drop_duplicates(split_out=230).to_frame().persist()
_ = wait(key_df)
key_df.to_parquet('test_key')
del _
del key_df
key_df = dask_cudf.read_parquet('test_key')
Main Reproducer
batch_size = 10
for start_index in range(0,key_df.npartitions,batch_size):
task_ls = []
for i in range(start_index,min(start_index+batch_size,key_df.npartitions)):
task = key_df.get_partition(i).merge(df_1,how='inner').repartition(npartitions=1).to_delayed()[0]
task_ls.append(task)
compute_task = client.compute(task_ls)
_ = wait(compute_task)
del _
del compute_task
del task_ls
print("completed = {}/{}".format(start_index+batch_size,key_df.npartitions))
get_total_tasks_held_by_dask(client)
Task Output
completed = 10/230
Total tasks held by client= 744
completed = 20/230
Total tasks held by client= 800
completed = 30/230
Total tasks held by client= 911
completed = 40/230
Total tasks held by client= 997
completed = 50/230
Total tasks held by client= 1032
completed = 60/230
Total tasks held by client= 1099
completed = 70/230
Total tasks held by client= 1102
completed = 80/230
Total tasks held by client= 1109
completed = 90/230
Total tasks held by client= 1100
completed = 100/230
Total tasks held by client= 1108
completed = 110/230
Total tasks held by client= 1100
completed = 120/230
Total tasks held by client= 1095
completed = 130/230
Total tasks held by client= 1099
completed = 140/230
Total tasks held by client= 1102
Duplicate Tasks being held across workers
All of these come from df_1.
key tcp://127.0.0.1:32815 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 86)
key tcp://127.0.0.1:33885 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 86)
----------------------------------------------------------------------------------------------------
key tcp://127.0.0.1:32815 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 115)
key tcp://127.0.0.1:33885 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 115)
----------------------------------------------------------------------------------------------------
key tcp://127.0.0.1:32815 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 199)
key tcp://127.0.0.1:32825 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 199)
----------------------------------------------------------------------------------------------------
key tcp://127.0.0.1:32825 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
key tcp://127.0.0.1:33885 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
key tcp://127.0.0.1:36155 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
key tcp://127.0.0.1:38089 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
key tcp://127.0.0.1:38697 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
key tcp://127.0.0.1:46791 dup_task = ('from_pandas-4a5906d9209a780059dbc7d2e9442050', 200)
--------------------------------------------------------------------------------------------------
All of these tasks are duplicates task of the df_1 being shared across workers. You can run the get_dup_tasks_count helper in the script to confirm that.
Expected Behaviour
I would expect that number of total dasks held by dask remain constant rather than linearly increasing.
Additional context
This is an example workflow, in the real workflow i am doing a batched inner join and see both duplicate tasks and memory increase with each batch.
With workstealing=False and rmm=off and ucx=False, i can more safely repro this.
The tasks held by dask keep on increasing after each batch, see below:
Memory increase screen shots
For initial batches
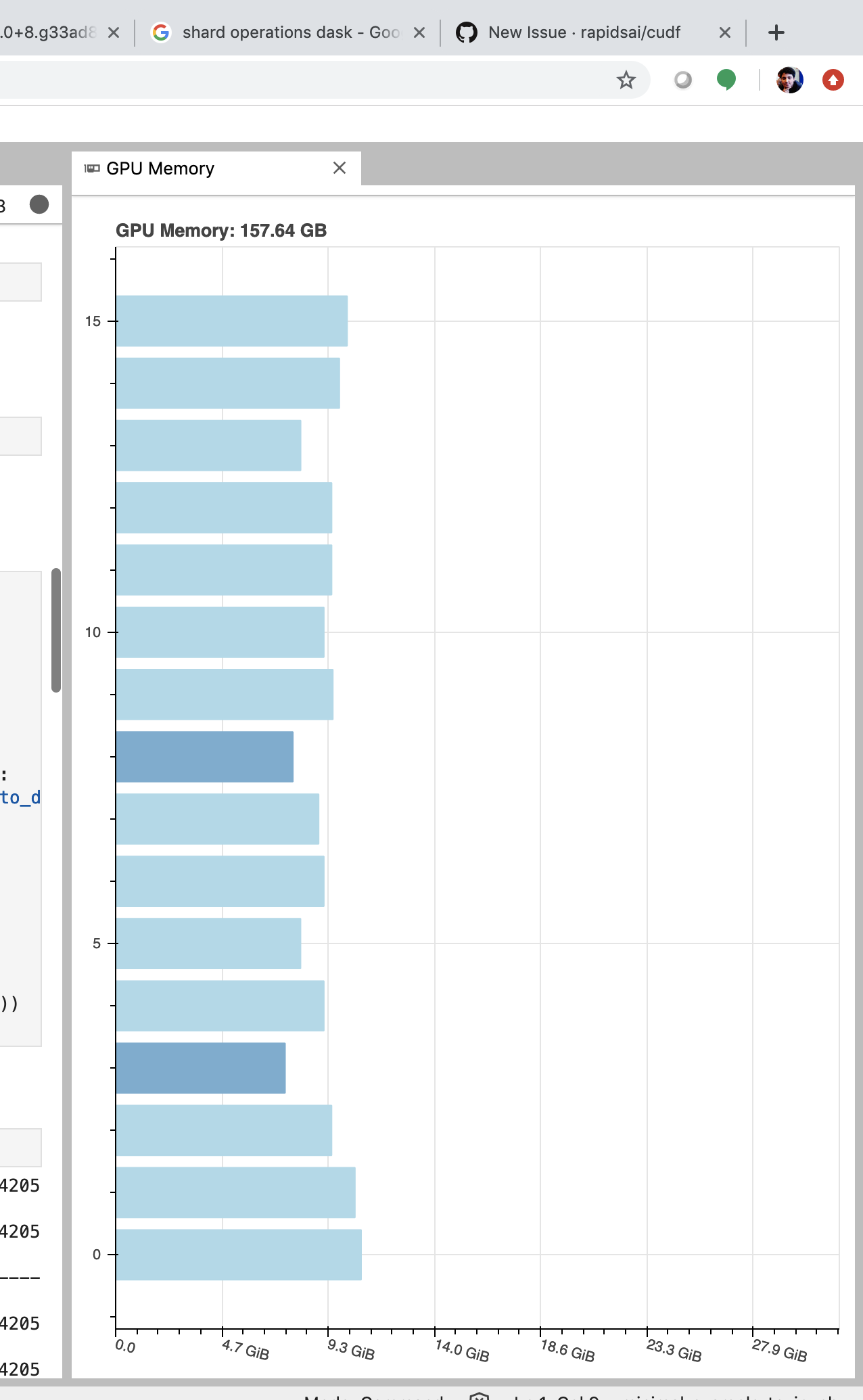
As we progress
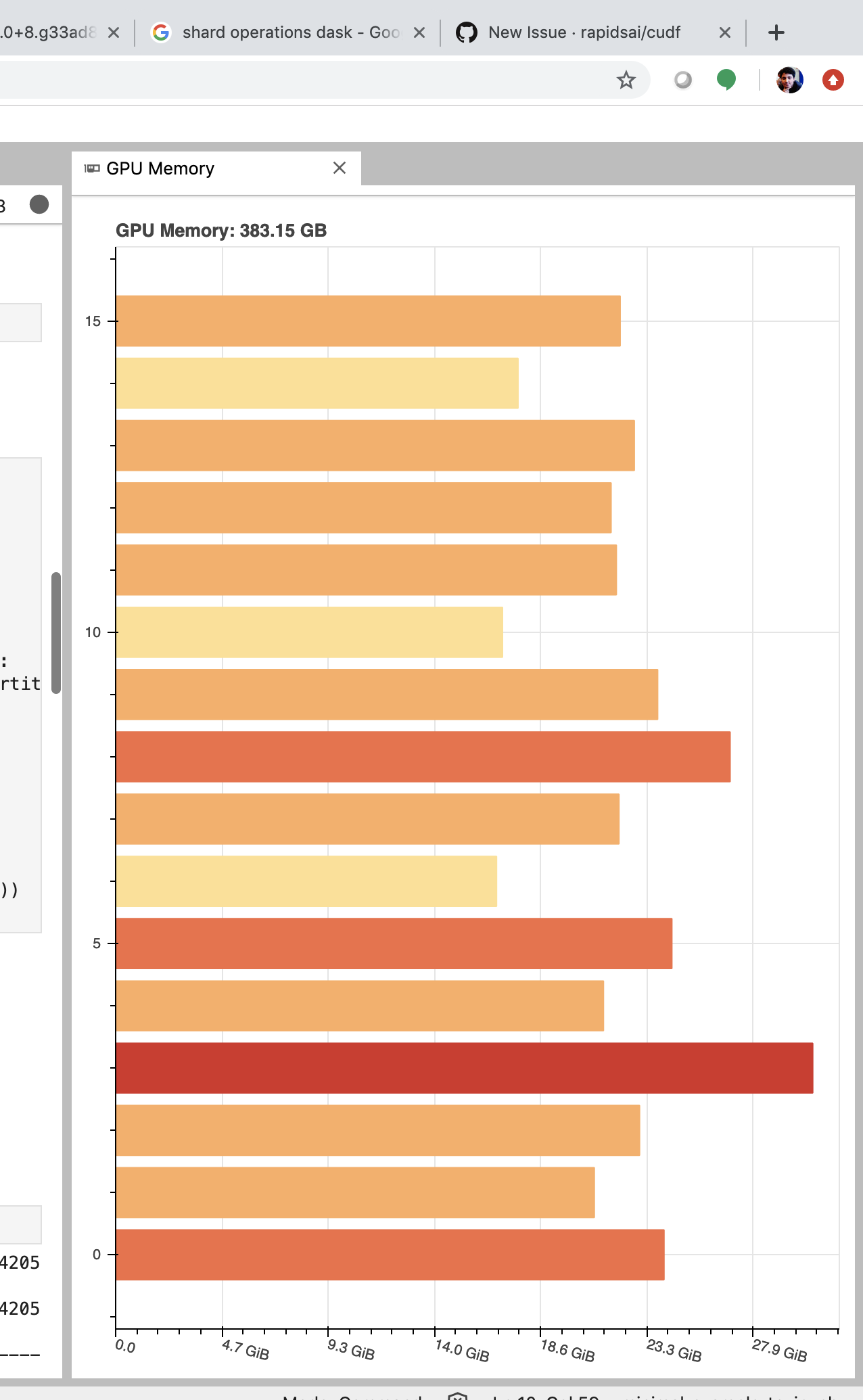
OOM
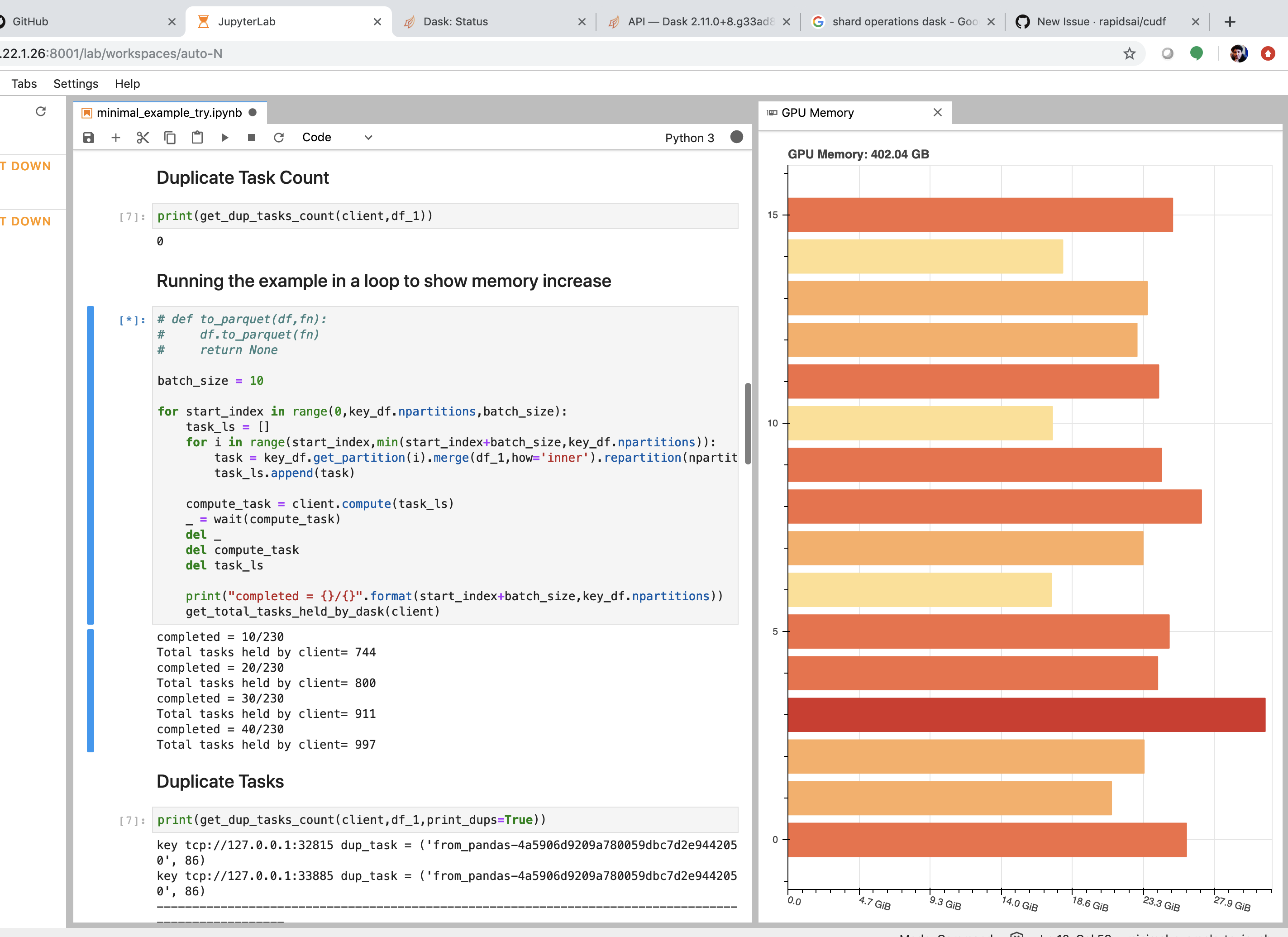
Work stealing = False works more reliably.
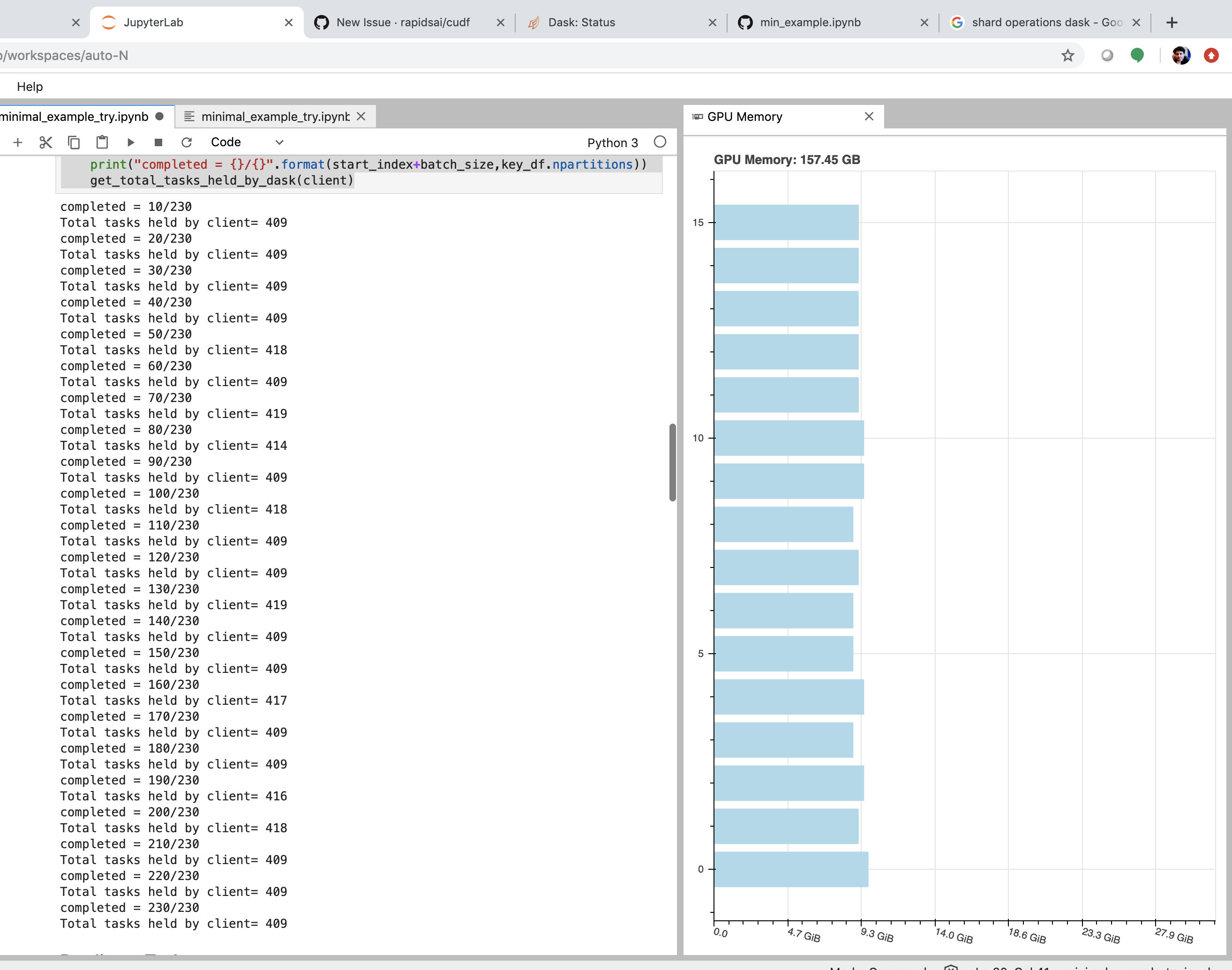
Edit: Changed shuffle to transfers
 VibhuJawa
VibhuJawa
All 10 comments
cc @quasiben @mrocklin
 jakirkham
on 27 Feb 2020
jakirkham
on 27 Feb 2020
So my best guess is this is coming from replicate-popular-data (https://distributed.dask.org/en/latest/work-stealing.html#replicate-popular-data)
Is there a way to switch off below ( replicate-popular-data) with work-stealing ?
VibhuJawa
on 27 Feb 2020
Also, I can confirm that the duplication happens with work-stealing off but is much much less.
Why, i have no clue . .
Another helpful thing here will be to force removal to remove these extra copies after each iteration, would be amazing if we can figure out a way to do that.
VibhuJawa
on 27 Feb 2020
I think we might be able to delete the extra copies by something like below:
May be worth trying.
VibhuJawa
on 28 Feb 2020
The replication of data during work stealing is currently not a tunable configuration but a policy choice made by dask. There is some good documentation on memory management here: https://distributed.dask.org/en/latest/memory.html#advanced-techniques. The TLDR is that this intended behavior of work stealing and dask promoted this kind of behavior where memory was plentiful and computation was scarce.
Also, on that page you will find more aggressive techniques for instructing dask on how to release tasks: client.cancel(fut) . Looking into changing the policy or at least a configurable policy would make sense to be but I am not clear on the timing of such a change. Typically scheduler changes move a little more slowly as they effect _all_ dask users.
With work stealing off we still see duplication because we will often (especially in joins) need to bring data together to perform some operation. I _think_ the graph and explanation below captures the idea of why duplication can be helpful and i really hope i don't confusing things -- my apologies if I do (not as familiar with the scheduler as i would like to be)
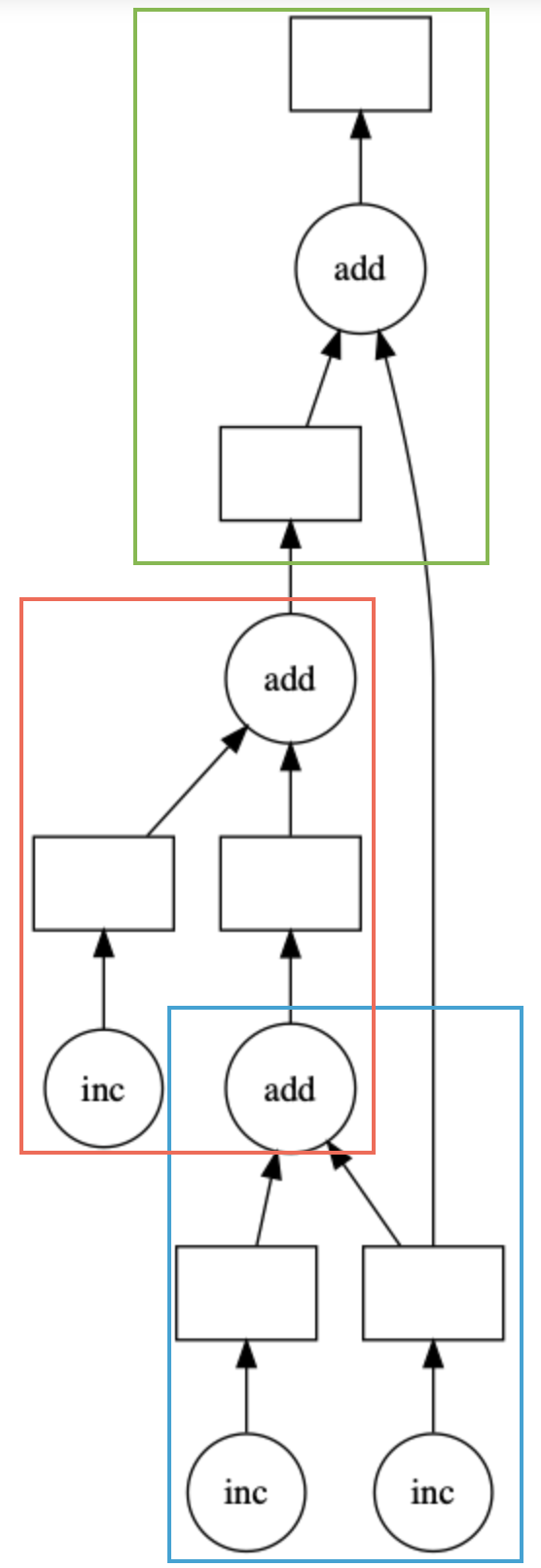
Assume the three inc boxes are data which live on different workers. To perform the add we need to bring the data together but we also see that we are going to do a final add at the end. The boxes are colored to represent the possibility of running on three different workers. Optimally, we should operate on worker and we could delete one of the incs after moving but what if we now add another operation (add another box) which also relies on an original inc need by yet another worker and we are now memory constrained. What should the policy be ?This is all to say dask wants to keep the duplicates around because high availably of data is great when we need it, we already paid the price to move and we may need the data on the original worker again -- win! Again, the policy maybe should be changed -- with UCX data movement becomes a lot cheaper.
 quasiben
on 28 Feb 2020
quasiben
on 28 Feb 2020
First, a naming clarification:
- I think that when you say "shuffle" you mean data transfer. Shuffle is actually a term that means a very specific type of data transfer that is like an all-to-all.
To the actual point here though, yes, if a computation causes a piece of data to be replicated, perhaps because many workers need it to do different computations then Dask currently will not delete the extra copies today. This policy ends up being useful when data that is frequently accessed is likely to be needed in the future, which is common. Obviously it also has downsides though.
Ideally Dask would have some more active memory management that kept track of expected use in the future, active memory transfer, and so on, and would make more intelligent decisions. This sort of active memory mangement would be great, but would also take a non-trivial amount of time to accomplish (perhaps a developer-month or two). If anyone is interested in doing or funding this work then please let me know.
 mrocklin
on 28 Feb 2020
mrocklin
on 28 Feb 2020
Thanks all for the detailed context.
@VibhuJawa I wonder if this is a situation where a more aggressive spilling configuration would help us. Or does that run into a different set of issues?
jakirkham
on 28 Feb 2020
Thanks a lot all for the detailed context and the diagrams , really helps me understand the issue more.
- I think that when you say "shuffle" you mean data transfer. Shuffle is actually a term that means a very specific type of data transfer that is like an all-to-all.
Thanks for the clarification, fixed it in the issue title and name.
To the actual point here though, yes, if a computation causes a piece of data to be replicated, perhaps because many workers need it to do different computations then Dask currently will not delete the extra copies today. This policy ends up being useful when data that is frequently accessed is likely to be needed in the future, which is common. Obviously it also has downsides though.
Got it , this helps me to clear stuff up that this in-fact is by design.
Ideally Dask would have some more active memory management that kept track of expected use in the future, active memory transfer, and so on, and would make more intelligent decisions. This sort of active memory mangement would be great, but would also take a non-trivial amount of time to accomplish (perhaps a developer-month or two). If anyone is interested in doing or funding this work then please let me know.
FWIW, I think this will be great to have especially in memory constrained workflows but i would let others take a call on this.
Follow ups:
Q1. Does exploring using the _delete_worker_data defined below for the time being for deleting the duplicated tasks make sense especially now with ucx (as ben pointed out) the transfer cost are minimized or is there a cleaner way to remove a future from just 1 particular worker while keeping it on the other ?
Q2. Is there an easy way to turn work_stealing off and then back on after starting the cluster, as i just want it off for some part of my workflow and want to keep the advantages that it has to offer us .
For context i tried doing below after starting the cluster but it did not change if i have started the cluster all ready.
dask.config.set({"distributed.scheduler.work-stealing": work_stealing})
VibhuJawa
on 28 Feb 2020
Thanks all for the detailed context.
@VibhuJawa I wonder if this is a situation where a more aggressive spilling configuration would help us. Or does that run into a different set of issues?
I don't think this is really an option right now as this whole thing stemmed from trying to achieve a work around for set-index for which we have to do aggressive spilling to make it work .
VibhuJawa
on 28 Feb 2020
Closing as this is not a bug. If there's further discussions on this topic would recommend opening an issue on the dask repo.
 kkraus14
on 2 Mar 2020
kkraus14
on 2 Mar 2020
Related issues
 Polarbeargo
·
3Comments
Polarbeargo
·
3Comments
 galipremsagar
·
3Comments
galipremsagar
·
3Comments
 henningpeters
·
3Comments
henningpeters
·
3Comments
 c-jamie
·
3Comments
c-jamie
·
3Comments
 jrhemstad
·
3Comments
jrhemstad
·
3Comments