Cudf: Execution hangs when multiple ThreadPoolExecutor threads concurrently manipulate DataFrames.
- [x] I am using the latest version of cuDF from conda, built from
master, or
built from the latest tagged release. - [x] I have included the version or commit hash I am using for reference. (I'm on 0.4)
- [ ] I have included the following environment details:
Linux Distro, Linux Kernel, GPU Model - [ ] I have included the following version information for:
Arrow, cmake, CUDA, gcc/g++, Numpy, Pandas, Python - [x] I have included below a minimal working reproducer (if you are unsure how
to write one see http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports).
When I run a combination of addition and sum operations in concurrent threads the cudf library seems to hang. Here is a minimal reproducible example.
from concurrent.futures import ThreadPoolExecutor
import cudf
import numpy as np
e = ThreadPoolExecutor(10)
gfs = [cudf.DataFrame({'x': np.random.random(10000)}) for _ in range(1)]
def f(gf):
print('.', end="", flush=True)
return (gf.x + 1).sum()
list(e.map(f, gfs * 1000))
print()
As written this computation will process through a few iterations and then hang. Top shows that the python interpreter isn't doing much. I also can't break out of this with a Keyboard Interrupt / Ctrl-C.
If I remove either the + 1 or the .sum() operations then it flows through smoothly. If I increase the number of gfs from 1 to 20 (to avoid having two threads operating on the same dataframe) then it still fails.
 mrocklin
mrocklin
All 13 comments
cc @williamBlazing I believe your team implemented the current binaryops and reduction functions, do you know if they're thread safe or what it would take to make them thread safe?
 kkraus14
on 18 Dec 2018
kkraus14
on 18 Dec 2018
cc @harrism since he poked at this recently in updating to use the type dispatcher.
kkraus14
on 18 Dec 2018
To be clear, I wouldn't be surprised if this failed also with other operations. These were just the simplest things that I could try. The fact that we need both leads me to think that the issue is deeper. I don't know much about the internals here though.
mrocklin
on 19 Dec 2018
@mrocklin what does the * 1000 do here?
 harrism
on 21 Dec 2018
harrism
on 21 Dec 2018
@harrism Multiplying a list duplicates the elements in the list that many times in a new list. So given we have a list with one cudf.DataFrame object it will return a list with 1000 cudf.DataFrame objects.
kkraus14
on 21 Dec 2018
I made the title more specific to the problem experienced, since we don't know the root cause of this hang yet.
harrism
on 21 Dec 2018
This does not look like a cuDF specific issue and seems to affect CUDA in multithreading.
I tried getting the backtrace of the given example and every time, one thread seems to be stuck at a sys call called accept4.
#0 0x00007fbed4f9e8c8 in accept4 (fd=9, addr=..., addr_len=0x7fbeaac13e58, flags=524288) at ../sysdeps/unix/sysv/linux/accept4.c:40
A quick google search for this frame showed more issues where the user was using CUDA multithreaded and experienced a hang. Not all of them experienced it in python.
OpenMP
ResNet (Torch, Python)
TensorFlow
and more...
Actually, a common subset of all those traces (and I looked at all google results, including ones not listed) is three threads stuck at accept4, poll and pthread_cond_wait, all originating in libcuda.so, apart from one parent thread.
Thread 4 (Thread 0x7f5093fff700 (LWP 16341)):
#0 pthread_cond_wait@@GLIBC_2.3.2 () at ../sysdeps/unix/sysv/linux/x86_64/pthread_cond_wait.S:185
#1 0x00007f50ac5c046d in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#2 0x00007f50ac56fed4 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#3 0x00007f50ac5bf6a8 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#4 0x00007f50c256b6ba in start_thread (arg=0x7f5093fff700) at pthread_create.c:333
#5 0x00007f50c198941d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:109
Thread 3 (Thread 0x7f5096e13700 (LWP 16340)):
#0 0x00007f50c197d74d in poll () at ../sysdeps/unix/syscall-template.S:84
#1 0x00007f50ac5bd633 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#2 0x00007f50ac62684d in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#3 0x00007f50ac5bf6a8 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#4 0x00007f50c256b6ba in start_thread (arg=0x7f5096e13700) at pthread_create.c:333
#5 0x00007f50c198941d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:109
Thread 2 (Thread 0x7f5097614700 (LWP 16339)):
#0 0x00007f50c198a8c8 in accept4 (fd=9, addr=..., addr_len=0x7f5097613e58, flags=524288) at ../sysdeps/unix/sysv/linux/accept4.c:40
#1 0x00007f50ac5be57a in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#2 0x00007f50ac5b0abd in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#3 0x00007f50ac5bf6a8 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#4 0x00007f50c256b6ba in start_thread (arg=0x7f5097614700) at pthread_create.c:333
#5 0x00007f50c198941d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:109
Two of those three threads don't show any cpu time, meaning they probably never got to the point of entering libcudf.
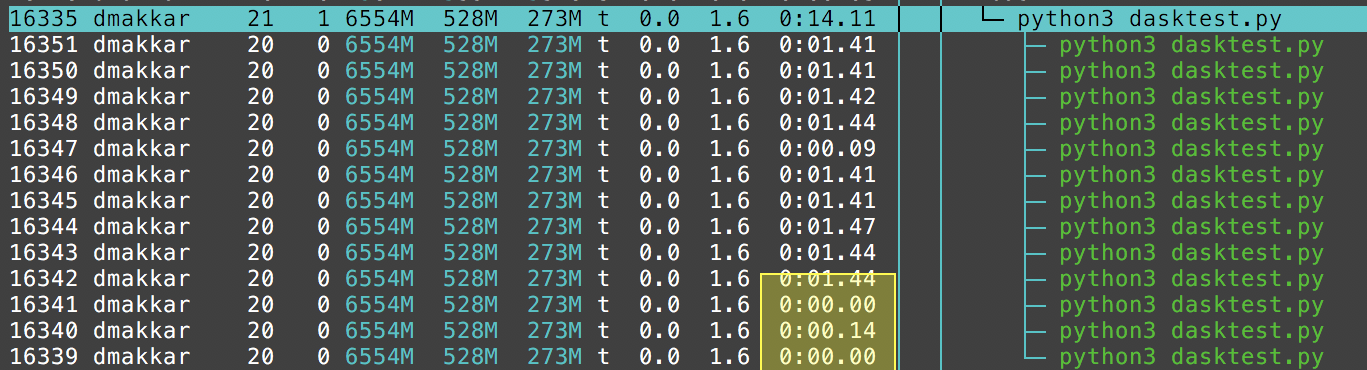
Where do I report it now?
 devavret
on 28 Dec 2018
devavret
on 28 Dec 2018
Actually, now I think that the accept4 might be for purposes of attaching some tools to the process, for debugging or otherwise.
devavret
on 28 Dec 2018
After further digging, I've narrowed down the hang to these 2 thread backtraces. 2thread_bt.txt
Basically there is a gdf_sum kernel launch and a query cuOccupancyMaxPotentialBlockSize that need to happen at the same time or something, for this to hang.
Will try to get a debug build of python and also try to get nsight systems to show more info.
devavret
on 7 Jan 2019
Good work. Keep going!
harrism
on 8 Jan 2019
Ok so making a debug python build inside conda env proving to be quite tricky but analyzing the stack traces while reading CPython code from GitHub seems to give some idea:
- Of the two locked threads, one of them is stuck in a CUDA kernel launch (_thread_C_) and the other is stuck in getting python's Global Interpreter Lock (thread_G).
- Now I can see that the _thread_C_ holds the GIL and won't return to python land until it's done it's work in C land (ffi call)
- I can't seem to understand what it is that _thread_G_ holds but _thread_C_ is waiting on.
devavret
on 8 Jan 2019
I still didn't understand what lock _thread_G_ held but it was clear that one of them needed to let go of a lock. After some research on the purpose of the GIL, it seemed safe to let go of the interpreter lock before entering a C function. Tried the following and it worked:
with nogil:
result = gdf_sum(<gdf_column*>c_col, <void*>out_ptr, outsz)
Why didn't this affect us before?
Because in CFFI, C function calls are done with the GIL released.
Now that we are using Cython, we need to manually specify this requirement.
What's funny is that after figuring this out and while checking if it's something that most people do, I found this GitHub thread by none other than @mrocklin suggesting the same on a different project.
Now I can go ahead and work on adding this to all libcuDF calls made from Cython.
devavret
on 9 Jan 2019
Closed by #669
 randerzander
on 16 Jan 2019
randerzander
on 16 Jan 2019
Related issues
kkraus14
·
3Comments
 c-jamie
·
3Comments
randerzander
·
3Comments
c-jamie
·
3Comments
randerzander
·
3Comments
 saifrahmed
·
3Comments
saifrahmed
·
3Comments
 galipremsagar
·
3Comments
galipremsagar
·
3Comments
Most helpful comment
I still didn't understand what lock _thread_G_ held but it was clear that one of them needed to let go of a lock. After some research on the purpose of the GIL, it seemed safe to let go of the interpreter lock before entering a C function. Tried the following and it worked:
Why didn't this affect us before?
Because in CFFI, C function calls are done with the GIL released.
Now that we are using Cython, we need to manually specify this requirement.
What's funny is that after figuring this out and while checking if it's something that most people do, I found this GitHub thread by none other than @mrocklin suggesting the same on a different project.
Now I can go ahead and work on adding this to all libcuDF calls made from Cython.