while doing adventofcode i noticed rotate method a bit slow. checked implementation, does copy of array, allocates memory, not very good. implementation in ruby (copied from perl) does reverse three times:
https://github.com/ruby/ruby/blob/027b576b31cd12bad575b3a39476726273f58c41/array.c#L2296-L2315
i did benchmark with different sizes, seem after size 100 faster to allocate memory, otherwise do in place. or maybe always do in place?
class Array
def new_rotate!(n = 1)
return self if size == 0
n %= size
return self if n == 0
Slice.new(@buffer, n).reverse! if n > 1
Slice.new(@buffer + n, size - n).reverse! if n < size - 1
reverse!
end
end
def bench
Time.measure do
1_000_000.times do
yield
end
end
end
sizes = [10, 20, 50, 100, 110, 200, 500, 1000, 5000]
rotate_counts = (1..9).to_a
puts "size, rotate, time old, time new"
sizes.each do |size|
ary = Array.new(size, &.itself)
rotate_counts.each do |rotate_count|
time_old = bench { ary.rotate!(rotate_count) }
time_new = bench { ary.new_rotate!(rotate_count) }
puts "#{size}, #{rotate_count}, #{time_old}, #{time_new}"
end
end
Output:
size, rotate, time old, time new
10, 1, 00:00:00.120928263, 00:00:00.016859090
10, 2, 00:00:00.101144279, 00:00:00.020961746
10, 3, 00:00:00.123458672, 00:00:00.017167817
10, 4, 00:00:00.122454864, 00:00:00.020344335
10, 5, 00:00:00.122315772, 00:00:00.017891776
10, 6, 00:00:00.123336572, 00:00:00.020212703
10, 7, 00:00:00.105817244, 00:00:00.018086583
10, 8, 00:00:00.100856720, 00:00:00.018376816
10, 9, 00:00:00.104535931, 00:00:00.018839083
20, 1, 00:00:00.100450762, 00:00:00.031587526
20, 2, 00:00:00.099028190, 00:00:00.031607453
20, 3, 00:00:00.116294172, 00:00:00.029703566
20, 4, 00:00:00.119623513, 00:00:00.030364195
20, 5, 00:00:00.116714344, 00:00:00.029344444
20, 6, 00:00:00.117427029, 00:00:00.034127133
20, 7, 00:00:00.134617673, 00:00:00.030561268
20, 8, 00:00:00.136022428, 00:00:00.030929011
20, 9, 00:00:00.129268385, 00:00:00.031708755
50, 1, 00:00:00.102764069, 00:00:00.067362985
50, 2, 00:00:00.106949262, 00:00:00.070628290
50, 3, 00:00:00.126886781, 00:00:00.072188116
50, 4, 00:00:00.128371287, 00:00:00.072219045
50, 5, 00:00:00.128669877, 00:00:00.070250427
50, 6, 00:00:00.128479294, 00:00:00.075750366
50, 7, 00:00:00.135220582, 00:00:00.069463664
50, 8, 00:00:00.137785256, 00:00:00.067685157
50, 9, 00:00:00.136315260, 00:00:00.071669669
100, 1, 00:00:00.099206141, 00:00:00.148144148
100, 2, 00:00:00.101125638, 00:00:00.147913928
100, 3, 00:00:00.131678238, 00:00:00.146786222
100, 4, 00:00:00.130791922, 00:00:00.156125615
100, 5, 00:00:00.128752702, 00:00:00.147817690
100, 6, 00:00:00.127315555, 00:00:00.148849068
100, 7, 00:00:00.137780093, 00:00:00.144140311
100, 8, 00:00:00.138602604, 00:00:00.149558444
100, 9, 00:00:00.140234268, 00:00:00.145874548
110, 1, 00:00:00.099337242, 00:00:00.153697442
110, 2, 00:00:00.099129942, 00:00:00.155149370
110, 3, 00:00:00.130136229, 00:00:00.160515708
110, 4, 00:00:00.131667602, 00:00:00.168184856
110, 5, 00:00:00.131960925, 00:00:00.158351375
110, 6, 00:00:00.131936713, 00:00:00.154146729
110, 7, 00:00:00.135346357, 00:00:00.153732246
110, 8, 00:00:00.137149644, 00:00:00.157924828
110, 9, 00:00:00.137761492, 00:00:00.162084057
200, 1, 00:00:00.114391576, 00:00:00.251576523
200, 2, 00:00:00.117437000, 00:00:00.269928936
200, 3, 00:00:00.138339056, 00:00:00.259907637
200, 4, 00:00:00.134251915, 00:00:00.251692345
200, 5, 00:00:00.134088314, 00:00:00.260822818
200, 6, 00:00:00.135678999, 00:00:00.263625594
200, 7, 00:00:00.141953332, 00:00:00.262330444
200, 8, 00:00:00.146124534, 00:00:00.267452469
200, 9, 00:00:00.147708968, 00:00:00.264784848
500, 1, 00:00:00.132368178, 00:00:00.615199123
500, 2, 00:00:00.127191336, 00:00:00.601483802
500, 3, 00:00:00.142068062, 00:00:00.594493267
500, 4, 00:00:00.142437275, 00:00:00.611995902
500, 5, 00:00:00.142401548, 00:00:00.587588649
500, 6, 00:00:00.144097188, 00:00:00.620041256
500, 7, 00:00:00.159433517, 00:00:00.608937110
500, 8, 00:00:00.165959937, 00:00:00.610409642
500, 9, 00:00:00.157916469, 00:00:00.613097371
1000, 1, 00:00:00.158271143, 00:00:01.176496980
1000, 2, 00:00:00.158373790, 00:00:01.181245065
1000, 3, 00:00:00.178311050, 00:00:01.150156520
1000, 4, 00:00:00.177887367, 00:00:01.215450674
1000, 5, 00:00:00.182622815, 00:00:01.233552764
1000, 6, 00:00:00.210927084, 00:00:01.241661947
1000, 7, 00:00:00.196003425, 00:00:01.189561179
1000, 8, 00:00:00.194813398, 00:00:01.193315692
1000, 9, 00:00:00.196365969, 00:00:01.203671327
5000, 1, 00:00:00.431793514, 00:00:06.029244231
5000, 2, 00:00:00.437870275, 00:00:05.902887141
5000, 3, 00:00:00.451904861, 00:00:06.663213585
5000, 4, 00:00:00.649389702, 00:00:06.158866684
5000, 5, 00:00:00.456520997, 00:00:06.533285982
5000, 6, 00:00:00.534730195, 00:00:07.382842737
5000, 7, 00:00:00.477839905, 00:00:05.966309350
5000, 8, 00:00:00.447289937, 00:00:06.108911938
5000, 9, 00:00:00.509821664, 00:00:05.920721640
 larubujo
larubujo
All 12 comments
it would also be helpful to make rotate work on a part of an array
 ghost
on 18 Dec 2017
ghost
on 18 Dec 2017
size, rotate, time old, time new
...
5000, 9, 00:00:00.509821664, 00:00:05.920721640
new version is 10x slower here, ouch.
 Sija
on 18 Dec 2017
Sija
on 18 Dec 2017
Please use Bechmark.ips for comparing performance. This makes it easier to recognize the differences.
require "benchmark"
sizes = [10, 20, 50, 100, 110, 200, 500, 1000, 5000]
rotate_counts = {1, 1000, 1001}
rotate_counts.each do |rotate_count|
puts " == #{rotate_count} =="
sizes.each do |size|
ary = Array.new(size, &.itself)
puts " === #{size} rotate #{rotate_count} ==="
Benchmark.ips do |bm|
bm.report "current" { ary.rotate!(rotate_count) }
bm.report "new" { ary.new_rotate!(rotate_count) }
end
end
end
Results for rotate 1:
=== 10 rotate 1 ===
current 4.17M (239.98ns) (± 9.58%) 3.71× slower
new 15.47M ( 64.64ns) (±17.91%) fastest
=== 20 rotate 1 ===
current 4.4M (227.26ns) (± 9.80%) 2.43× slower
new 10.68M ( 93.66ns) (±16.00%) fastest
=== 50 rotate 1 ===
current 4.56M (219.45ns) (± 8.03%) 1.19× slower
new 5.41M (184.86ns) (±10.07%) fastest
=== 100 rotate 1 ===
current 4.23M (236.29ns) (± 8.35%) fastest
new 2.79M ( 358.3ns) (± 8.40%) 1.52× slower
=== 110 rotate 1 ===
current 4.3M (232.33ns) (± 7.11%) fastest
new 2.55M (391.62ns) (± 7.36%) 1.69× slower
=== 200 rotate 1 ===
current 3.74M (267.58ns) (±11.03%) fastest
new 1.28M (779.94ns) (± 9.78%) 2.91× slower
=== 500 rotate 1 ===
current 2.84M (352.02ns) (±11.73%) fastest
new 525.97k ( 1.9µs) (± 7.87%) 5.40× slower
=== 1000 rotate 1 ===
current 2.05M (487.14ns) (±13.81%) fastest
new 270.51k ( 3.7µs) (± 6.18%) 7.59× slower
=== 5000 rotate 1 ===
current 650.87k ( 1.54µs) (± 8.68%) fastest
new 52.4k ( 19.09µs) (± 9.07%) 12.42× slower
On my machine, the performance lead switches somewhere between 50 and 100.
However, this is only for rotating by 1. Testing for rotation steps 1..9 does not really make any difference, the values are very similar. There are more significant differences with higher values.
If you rotate by a multiple of size (e.g. 1000), the new algorithm is slightly faster:
=== 10 rotate 1000 ===
current 59.06M ( 16.93ns) (±16.34%) 1.01× slower
new 59.9M ( 16.69ns) (±20.17%) fastest
=== 20 rotate 1000 ===
current 57.35M ( 17.44ns) (±20.04%) 1.07× slower
new 61.49M ( 16.26ns) (±18.03%) fastest
=== 50 rotate 1000 ===
current 59.07M ( 16.93ns) (±17.63%) 1.09× slower
new 64.62M ( 15.48ns) (±14.13%) fastest
=== 100 rotate 1000 ===
current 57.71M ( 17.33ns) (±19.60%) 1.09× slower
new 63.09M ( 15.85ns) (±15.87%) fastest
=== 110 rotate 1000 ===
current 3.16M (316.91ns) (± 8.68%) fastest
new 2.55M (392.79ns) (±10.53%) 1.24× slower
=== 200 rotate 1000 ===
current 60.53M ( 16.52ns) (±14.50%) 1.05× slower
new 63.28M ( 15.8ns) (±15.76%) fastest
=== 500 rotate 1000 ===
current 56.82M ( 17.6ns) (±20.58%) 1.11× slower
new 63.3M ( 15.8ns) (±16.25%) fastest
=== 1000 rotate 1000 ===
current 58.74M ( 17.02ns) (±20.01%) 1.04× slower
new 61.06M ( 16.38ns) (±19.83%) fastest
=== 5000 rotate 1000 ===
current 113.33k ( 8.82µs) (± 4.59%) fastest
new 58.88k ( 16.98µs) (± 7.51%) 1.92× slower
Now, lets take some higher and odd numbers that will require a good amount of rotating for most sizes. It looks like at size / 2 - 1 the current implementation has very bad performance:
=== 10 rotate 4 ===
current 3.93M ( 254.7ns) (±13.38%) 4.05× slower
new 15.88M ( 62.97ns) (±15.50%) fastest
=== 20 rotate 9 ===
current 3.77M (265.03ns) (± 7.08%) 3.00× slower
new 11.31M ( 88.4ns) (±14.33%) fastest
=== 50 rotate 24 ===
current 2.51M (398.78ns) (± 9.03%) 2.12× slower
new 5.32M (187.87ns) (±11.11%) fastest
=== 100 rotate 49 ===
current 1.82M (549.46ns) (± 4.28%) 1.60× slower
new 2.91M (344.23ns) (± 8.20%) fastest
=== 110 rotate 54 ===
current 1.73M (579.47ns) (± 4.12%) 1.54× slower
new 2.65M ( 376.9ns) (± 8.21%) fastest
=== 200 rotate 99 ===
current 1.05M (955.07ns) (± 3.26%) 1.35× slower
new 1.41M (709.23ns) (± 7.28%) fastest
=== 500 rotate 249 ===
current 402.88k ( 2.48µs) (± 3.95%) 1.33× slower
new 535.31k ( 1.87µs) (± 8.02%) fastest
=== 1000 rotate 499 ===
current 268.91k ( 3.72µs) (± 2.65%) fastest
new 267.07k ( 3.74µs) (±10.40%) 1.01× slower
=== 5000 rotate 2499 ===
current 72.11k ( 13.87µs) (± 4.99%) fastest
new 54.65k ( 18.3µs) (±11.35%) 1.32× slower
Here, the threshold is at about size 1000 instead of 100.
These numbers also show that the proposed algorithm has a very stable performance while the current implementation varies a lot depending on the rotation step. For example, with a size of 5000 elements, the current implementation reaches 650k IPS for rotate 1 but only 72k IPS for rotate 2499 while the propsed new algorithm has roughly the same value for both.
 straight-shoota
on 18 Dec 2017
straight-shoota
on 18 Dec 2017
I wrote optimized (non-allocation version) rotate four months ago and I remember this is same or a bit slower than current implementation, but I forgot this until now (due to #4837 works). I'll create a new pull request. Thank you.
 MakeNowJust
on 18 Dec 2017
MakeNowJust
on 18 Dec 2017
Here is benchmark of some algorithms and result plot is this:
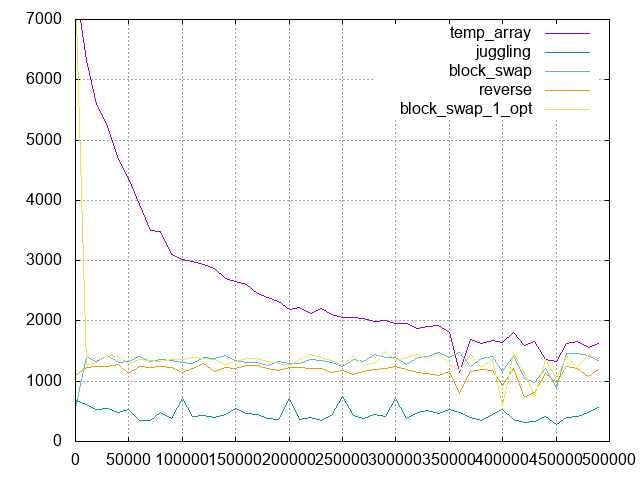
temp_array algorithm is current Crystal implementation. It looks fastest if rotation size is small, however it is slow and slow as rotation size gets close to the half of array size. Finally, the worst IPS of temp_array is the same as other non-allocation algorithms.
block_swap algorithm looks the fastest of non-allocation algorithms, but it is slower than temp_array totally :cry: So I optimize block_swap by n = 1 rotation boosting, this is named block_swap_1_opt in the above plot. It is known that n = 1 and also n = array size - 1 rotation can be ran efficiently on stack. In real, it is faster than temp_array on n = 1 (see the leftmost of plot and here). I think it is useful, based on this observation:
- If
n = 1rotation is used, speed is important because it is known thatn = 1rotation can be ran efficiently. - If
n > 1rotation is used, memory efficient is more important than speed because memory usage invokes unintentional performance issues. For example, the memory is crowded byrotateallocated memory and other memory is moved to swap, then it causes serious performance issue.
I'll create a new pull request with block_swap_1_opt algorithm.
MakeNowJust
on 18 Dec 2017
Additionally I remember libc++ uses this approach also.
MakeNowJust
on 18 Dec 2017
btw, what the real use case for rotate? i never use it.
 kostya
on 18 Dec 2017
kostya
on 18 Dec 2017
It would be nice to have some context about what the diagram shows.
If I understand correctly, the x axis shows the number of rotation steps (from 0 to 500k in steps of 50k) and y axis the numer of instructions per second each algorithm achieves (higher = better). All operations where done on an array of size 1M.
straight-shoota
on 18 Dec 2017
Yes, some algorithms uses rotate and it is very very popular operation. You have never used rotate yet, however you may use rotate tomorrow.
MakeNowJust
on 18 Dec 2017
@MakeNowJust would be great to get benchmarks of those algorithms on small arrays.
 RX14
on 18 Dec 2017
RX14
on 18 Dec 2017
Small array (array.size == 100) result plot and sources codes:
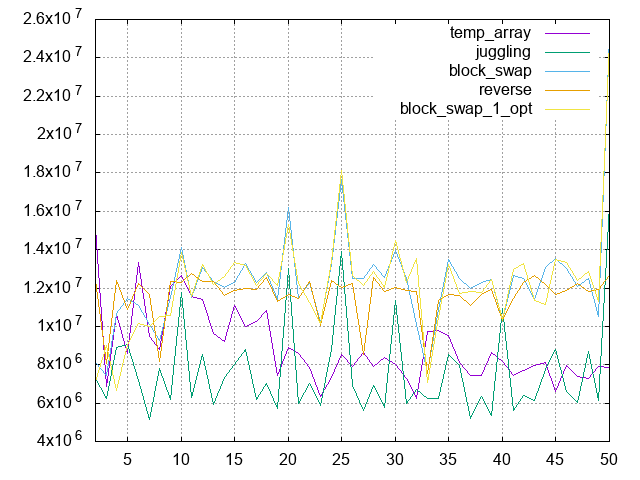
It shows better result than current on small array.
MakeNowJust
on 19 Dec 2017
Hello. How about reusing capacity?
class Array
def rotate_reusing_capacity!(n)
return self if size == 0
n %= size
return self if n == 0
if n <= size / 2
if n < @capacity - size
@buffer.move_to(@buffer + size, n)
@buffer.move_from(@buffer + n, size)
(@buffer + size).clear(n)
else
tmp = self[0..n]
@buffer.move_from(@buffer + n, size - n)
(@buffer + size - n).copy_from(tmp.to_unsafe, n)
end
else
m = size - n
if m < @capacity - size
@buffer.move_to(@buffer + m, size)
@buffer.move_from(@buffer + size, m)
(@buffer + size).clear(m)
else
tmp = self[n..-1]
(@buffer + size - n).move_from(@buffer, n)
@buffer.copy_from(tmp.to_unsafe, size - n)
end
end
self
end
end
 irxground
on 19 Dec 2017
irxground
on 19 Dec 2017
Related issues
RX14
·
3Comments
Sija
·
3Comments
 Papierkorb
·
3Comments
Papierkorb
·
3Comments
 lgphp
·
3Comments
lgphp
·
3Comments
 pbrusco
·
3Comments
pbrusco
·
3Comments
Most helpful comment
I wrote optimized (non-allocation version) rotate four months ago and I remember this is same or a bit slower than current implementation, but I forgot this until now (due to #4837 works). I'll create a new pull request. Thank you.