Couchdb: How to make mango $or/$elemMatch/$allMatch queries fast?
$or $elemMatch $allMatch can't use index... i'm shocking. search is impossible... selector with that operators take more that 2 minutes on 50k simplied docs.
create test data base "test_bulk" with 50k docs with test field like "arr_test": ["Sdf3Kjew34"] (random value),
curl -X POST http://localhost:5984/test_bulk/_bulk_docs -H "Content-type: application/json" -d @docs.json
(by the way in result this curl i get 'badarg' error , but if i bulk 1000 docs after that i see in db 51000 docs. should i make separate issue for that?)
make index on field "arr_test" then run query with selector {"arr_test":{"$elemMatch":{"$eq":"Sdf3Kjew34"}}}
it takes more than 120 sec.... in explain i can see that querie using index on test field
Expected Behaviour
queries result in less than 1 sec
Your Environment
- CouchDB Version used: 2.3.1 in docker configured in single node
- Browser name and version: Chrome
- Operating System and version: Win 10x64
Additional context
 pavellzubkov
pavellzubkov
All 19 comments
Before I actually answer this ticket, I need to say that this is not how to open a ticket and request help. I can hear you are frustrated, but you don't need to write an angry ticket like this. It is poor form, insulting and honestly I still can't believe I'm going to offer some help. In all likely hood, you are using CouchDB for free. It costs you nothing. It would also cost you nothing to ask for some help politely.
Ok now to your problem, firstly you need to think about how mango works. Internally it is using a map/reduce index. So it builds up a view using your specified arr_test. So if you had multiple fields in the array the index would look like roughly like this:
[a, b, c]
[a, b, c, d],
[b, c, d]
[c, d]
So now, when you create a selector with $elemMatch to query the index. The mango query runner needs to find a way to query the index. The way to make a query fast is to have a startkey/endkey or an equal. Then it can reduce the number of documents it needs to fetch from an index. In your case, $elemMatch means any item in the array that matches. So if we had a selector like $elemMatch: c. We cannot build a startkey/endkey out of it because we don't know where in the array c for each item. So CouchDB needs to fetch every document in the index, check if it has the element in the array and then return it if it matches.
Secondly, you state your environment is Docker on windows. Saying it takes 2 minutes in that setup is not a good way to benchmark. That environment will always be a fair bit slower than a production machine. Also was it 2 minutes the first time or after every time you queried it? The first time you run a query with an index, it will build the index which could explain for it being a little slow.
Hope that helps.
 garrensmith
on 7 Oct 2019
garrensmith
on 7 Oct 2019
garrensmith, thank you for answer! I'm sorry if my issue have some angry tone. I only learn couchdb and can't find way to get several docs in one request. For your question - yes it has 2 minutes every time when i request it. Yes my test evironment slower than production mashine but in production i can have much more docs than 50k.(or not?). I can't understand why couchdb examined thousands docs when i want get several particular docs by _id field (for example) by using $or operator (for example). For what
CouchDB needs to fetch every document in the index, check if it has the element in the array and then return it if it matches.
if index have this array?
I will try to read docs again and again for understanding this. honestly)
Thank you for great project!
pavellzubkov
on 7 Oct 2019
Great, thank you for understanding.
An $or operator also can't always use an index unless both sides of the $or have the same fields.
This can be a little confusing initially. Start simpler by using $gt, $eq etc and then start building our your queries as you understand the syntax.
garrensmith
on 9 Oct 2019
I have similar issue with $all
I have db with 2 million records, one of them have value [1,2,3,4,5] in the field with index
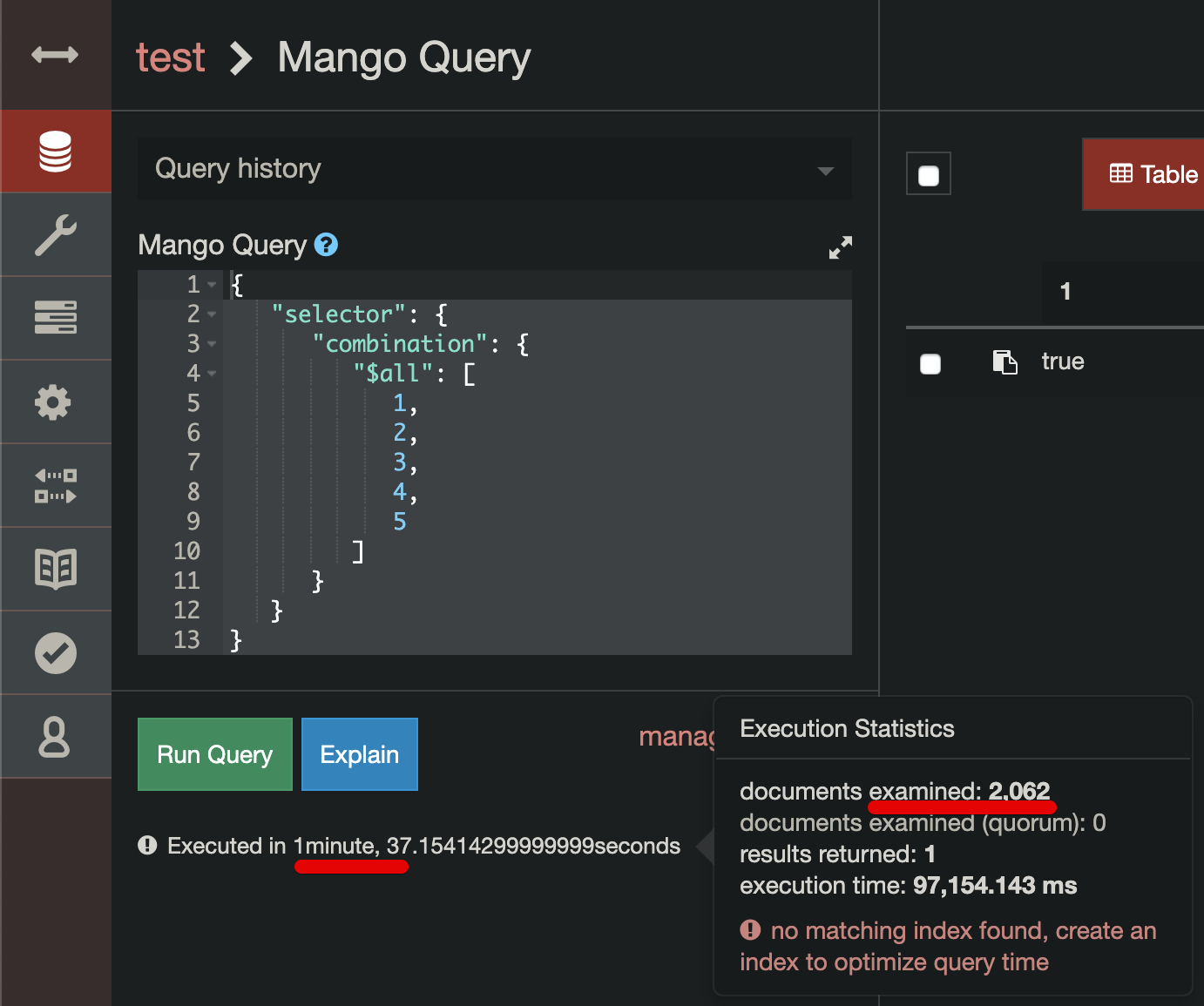
Indexer have finished all jobs, 8 cores of cpu shows no activity on graph
Explain for the following query shows that specified index will be used
{
"selector": {
"combination": {
"$all": [
1,
2,
3,
4,
5
]
}
}
}
The question is why it takes 7 minutes of 800% cpu load if it says in execution statistics that just 1 document was examined?
PS. I loaded 2 million of documents (30 mb in total) to the nodejs variable and made search obviously without any indexes just by looping through all the items and it took less than second.
 melnikaite
on 28 Oct 2019
melnikaite
on 28 Oct 2019
@melnikaite can you show the output of _explain and the execution stats? As far as I'm aware, indexes are not able to be used against an '$all' operator directly which would lead to a full index scan.
 willholley
on 28 Oct 2019
willholley
on 28 Oct 2019
{
"dbname": "test",
"index": {
"ddoc": "_design/f96e466b1579e8b7d09e9c8827cdbc8e75b14f93",
"name": "combination-json-index",
"type": "json",
"def": {
"fields": [
{
"combination": "asc"
}
]
}
},
"selector": {
"combination": {
"$all": [
1,
2,
3,
4,
5
]
}
},
"opts": {
"use_index": [],
"bookmark": "nil",
"limit": 25,
"skip": 0,
"sort": {},
"fields": "all_fields",
"r": [
49
],
"conflicts": false,
"stale": false,
"update": true,
"stable": false,
"execution_stats": false
},
"limit": 25,
"skip": 0,
"fields": "all_fields",
"mrargs": {
"include_docs": true,
"view_type": "map",
"reduce": false,
"start_key": [],
"end_key": [
"<MAX>"
],
"direction": "fwd",
"stable": false,
"update": true,
"conflicts": "undefined"
}
}
thanks @melnikaite. From that output we can see:
"start_key": [],
"end_key": [
"<MAX>"
],
which indicates a full index scan. The query engine will iterate through the index with include_docs=true and evaluate each document individually against the query selector in series. As you might expect, this isn't very efficient.
I can't think of a good ay to accelerate this kind of disjoint query in CouchDB natively; naively it would require querying the index multiple times (once for each entry in the $all predicate) and joining the results.
You could try looking at the clouseau addon which provides Lucene-based indexes. Support for this can be manually patched into CouchDB 2 and is available natively in CouchDB master.
willholley
on 28 Oct 2019
I'm not sure text search will help me, I have an array
Why without index it takes less time than with index?

melnikaite
on 28 Oct 2019
@melnikaite I think the timing difference is explained by the efficiency of iterating the entire database in it's "natural" order (i.e. no index) vs index order, which requires an additional random access to fetch each document.
Bear in mind that text indexes can be useful for all kinds of data because Lucene has a richer/more sophisticated indexing and query engine than CouchDB has natively.
willholley
on 28 Oct 2019
Best way to make mango $or/$elemMatch/$allMatch queries fast - using views for that queries if docs count more than 50.
pavellzubkov
on 2 Nov 2019
As I understand view is the same data but formatted a bit differently, like subquery in sql
@pavellzubkov How to modify array to make $or/$elemMatch/$allMatch/$all fast?
I tried to create 5 fields with boolean values but it didn't help.
Also it'd nice to understand why looping over all records in 30 mb database take so much time?
melnikaite
on 2 Nov 2019
@melnikaite
Also it'd nice to understand why looping over all records in 30 mb database take so much time?
i think it is just time for relax)) because couchdb - relax.
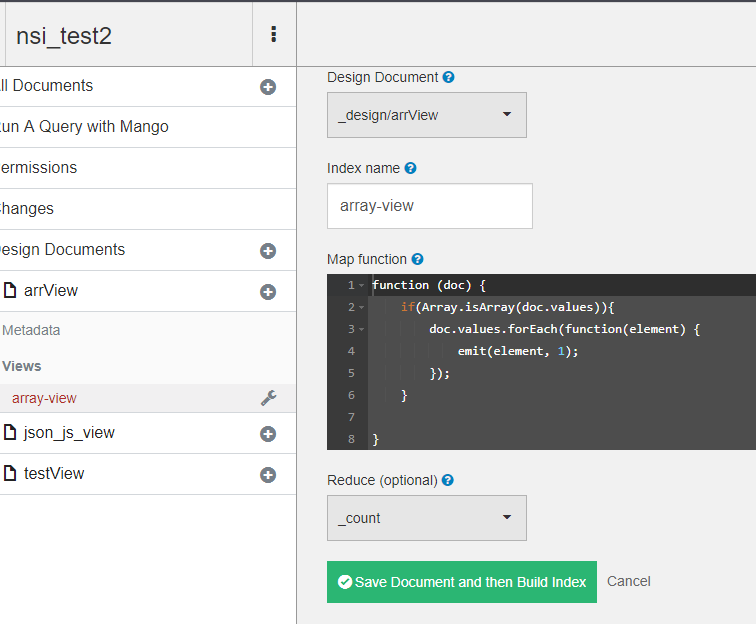
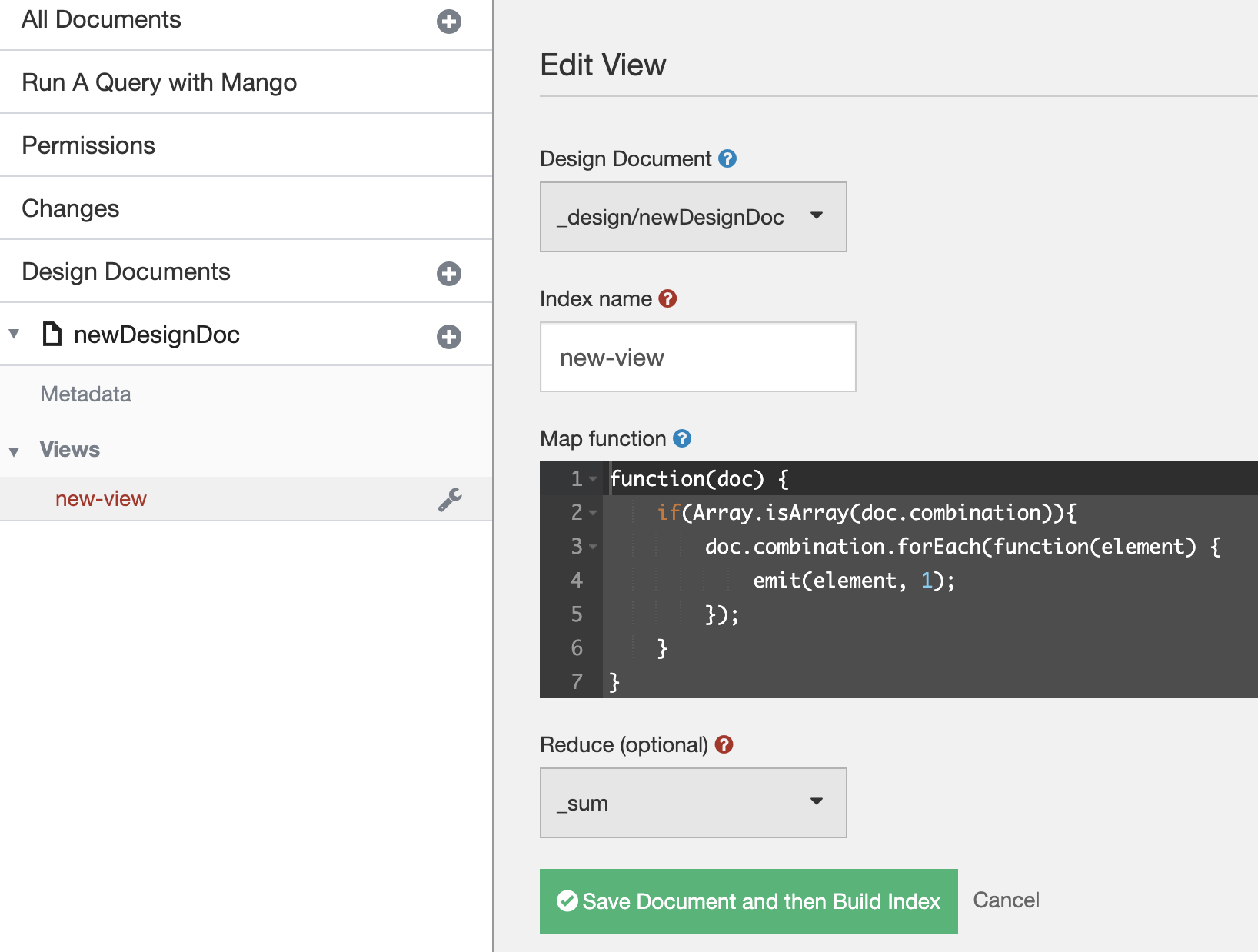
i suggest use view - for example map function for array -
function(doc) {
if(Array.isArray(doc.values)){
doc.values.forEach(function(element) {
emit(element, 1);
});
}
}
for example doc looks like this:
{
"_id": "'AGR'_00EAerqP",
"_rev": "1-a2eebcced03635c1fcd8e3eabb43f8ff",
"junk": "00EAerqP",
"arr_test": [
"gM8jkuDP"
],
"doc_type": "AGR",
"model_group": "MOD_GR_4",
"model_type": "MOD_T_2",
"model": "MOD_4",
"values": [
"MOD_2",
"MOD_3",
"MOD_2",
"MOD_4",
"MOD_2",
"MOD_2",
"MOD_1"
]
}
after build view it would be useful for queries like $or or $elemMatch run queries with params 'key' or 'keys'
if you want query $allMatch you might emit full array to view index
index look like

you can use reduce for example
after view index build it would be rebuilding incrementally or you get some time for relax again))
pavellzubkov
on 2 Nov 2019
@pavellzubkov thanks for explanations
I added view like you described, but I didn't get how to run queries with $or using view
I tried to specify keys in options dropdown, but it returns empty array
melnikaite
on 4 Nov 2019
@melnikaite i create view index on test db with map function i write above. Then i make query for get all docs id witch value field contain key "MOD_1" or 'MOD_2". it would be better to explain with screenshots from Insomnia REST tool:
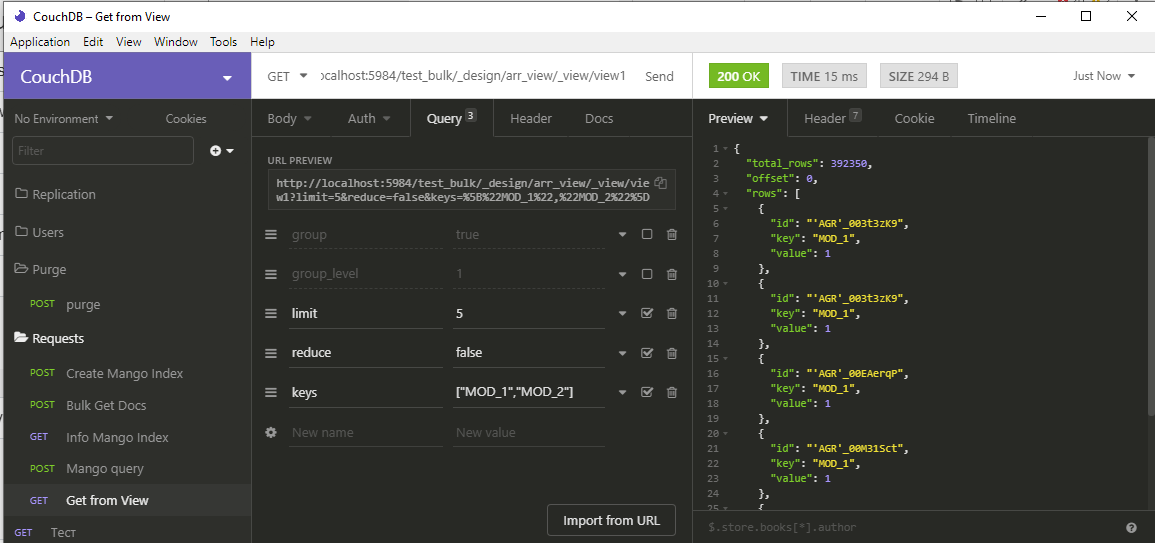
how you can see - view index contain 392350 rows. (database contains 56056 docs with "value" field contain array with 7 values ["MOD_1","MOD_2"....] . some docs contain array with only "MOD_1" or "MOD_2" values. Doc example above)
then if turn on group and reduce params we can get docs count contains specified keys:

pavellzubkov
on 4 Nov 2019
I'm using embedded to 2.3.1 utils ui with a bit different names
But anyways get request from your first screenshot http://localhost:5984/test/_design/newDesignDoc/_view/new-view?limit=5&reduce=false&keys=%5B%221%22%2C%20%222%22%5D results to 0 rows
{"total_rows":10593800,"offset":10593800,"rows":[
]}

melnikaite
on 4 Nov 2019
your (element) string or number? try req
http://localhost:5984/test/_design/newDesignDoc/_view/new-view?limit=5&reduce=false&keys=[2,3,8]
pavellzubkov
on 4 Nov 2019
Ah, you are right, it's numbers
Shame on me)
So now it's clear how to use keys in views
When I specify array of keys they are considered as OR
However I want to reduce number of returned values, the only way I see is setting as a key array of values and in request list all possible values
But it will extremely big request
I found that List, Update and Filter functions accept Request object https://docs.couchdb.org/en/2.2.0/ddocs/ddocs.html but unfortunately Reduce function doesn't acccept
melnikaite
on 5 Nov 2019
This doesn't look like something we can improve per comments above. Closing for now.
 wohali
on 30 Apr 2020
wohali
on 30 Apr 2020
Why isn't there an ability to index array entries?
If the index target is myArr: [] then create a map where the key is the array value and the value is a set of IDs. When items are inserted/deleted, updating the map and set will be fast.
Now you can compare the map keys to the query and for each match return the sets. These document IDs can then be unioned with the rest of the query for final results.
This seems like a simple, but effective performance enhancement.
 elijahdorman
on 12 Dec 2020
elijahdorman
on 12 Dec 2020
Related issues
 sploders101
·
3Comments
sploders101
·
3Comments
 mtabb13
·
5Comments
mtabb13
·
5Comments
 denyeart
·
3Comments
wohali
·
3Comments
denyeart
·
3Comments
wohali
·
3Comments
 col-panic
·
5Comments
col-panic
·
5Comments
Most helpful comment
Before I actually answer this ticket, I need to say that this is not how to open a ticket and request help. I can hear you are frustrated, but you don't need to write an angry ticket like this. It is poor form, insulting and honestly I still can't believe I'm going to offer some help. In all likely hood, you are using CouchDB for free. It costs you nothing. It would also cost you nothing to ask for some help politely.
Ok now to your problem, firstly you need to think about how mango works. Internally it is using a map/reduce index. So it builds up a view using your specified
arr_test. So if you had multiple fields in the array the index would look like roughly like this:So now, when you create a selector with
$elemMatchto query the index. The mango query runner needs to find a way to query the index. The way to make a query fast is to have a startkey/endkey or an equal. Then it can reduce the number of documents it needs to fetch from an index. In your case,$elemMatchmeans any item in the array that matches. So if we had a selector like$elemMatch: c. We cannot build a startkey/endkey out of it because we don't know where in the arraycfor each item. So CouchDB needs to fetch every document in the index, check if it has the element in the array and then return it if it matches.Secondly, you state your environment is Docker on windows. Saying it takes 2 minutes in that setup is not a good way to benchmark. That environment will always be a fair bit slower than a production machine. Also was it 2 minutes the first time or after every time you queried it? The first time you run a query with an index, it will build the index which could explain for it being a little slow.
Hope that helps.