Core: Template editor hangs Home Assistant
The problem
testing templates in editor in 115.0-115.3 very tricky -making mistake in template you are getting hanging system, only container restart via portainer helps. below you can find log at the moment of testing. I think test environment should not lead to system reboot at any case
Environment
- Home Assistant Core release with the issue: 115.3 (same on 115.0 - 115.2)
- Last working Home Assistant Core release (if known): 144.4
- Operating environment (OS/Container/Supervised/Core): Ubuntu Supervised (same on deb10 supervised)
- Integration causing this issue: ??
- Link to integration documentation on our website:
Problem-relevant configuration.yaml
evaluating this kind of templates leads to system hangs (even not able to save config files from IDE addon)
- service: notify.telegram
data_template:
message: >
{% set time_limit = as_timestamp(now())-4*60*60 %}
{% set missing = states | selectattr('attributes.last_seen', 'defined') | selectattr('attributes.linkquality', 'defined')| selectattr('attributes.last_seen','<', time_limit*1000 ) | map(attribute='attributes.device.friendlyName') | unique | list | join(', ') %}
{% set missing_count = states | selectattr('attributes.last_seen', 'defined') | selectattr('attributes.linkquality', 'defined')| selectattr('attributes.last_seen','<', time_limit*1000 ) | map(attribute='attributes.device.friendlyName') | unique | list | count %}
{% set z2m_uptime = ((states('sensor.zigbee2mqtt_bridge_uptime')|int) / 3600)|round(1) %}
{% set z2m2_uptime = ((states('sensor.zigbee2mqtt2_bridge_uptime')|int) / 3600)|round(1) %}
{% if missing_count >0 %}{{"\U0001f4f6"}} 4 часа (аптайм z2m: {{z2m_uptime}}ч, z2m2: {{z2m2_uptime}}ч) нет ответа от: {{ missing }}
{%else%}{{"\U00002705"}}Все устройства доступны!{%endif%}
Traceback/Error logs

Additional information
 to4ko
to4ko
All 34 comments
The system is likely hanging because the template is listening for all state changed events when we can't successfully evaluate a template as optimistically waiting for the template evaluation to be successful. Normally this isn't an issue but it seems like there is something on your instance that is generating more state changed events than the template engine can keep up with which leads to it being overwhelmed.
 bdraco
on 26 Sep 2020
bdraco
on 26 Sep 2020
I added functionality in #40624 to trap all the jinja2 errors which will prevent listening for all states on error. Regardless, the system should have been able to keep up with that so I suspect you have something else going on as well that might be brought to light with a py-spy recording.
bdraco
on 26 Sep 2020
As posted here https://community.home-assistant.io/t/heads-up-upcoming-breaking-change-in-the-template-integration/223715/372?u=mariusthvdb
{% set ns = namespace(domains=[]) %}
{% for d in states|groupby('domain') %}
{% set ns.domains = ns.domains + [d[0]] %}
{% endfor %}
{% set list = ns.domains|join('\n') %}
{{list if list|count < 255 else
list|replace('input','inp')|truncate(255,true)}}
115 is a bit too anxious to evaluate on state changes... no issues with these templates up to 114.
just to add to the thread here, for reference, thought it might be useful
and yes, only 'ha core restart' will do. The template testing for unavailable in that same thread, made even that impossible forcing to ha host reboot. Won't copy the thread any further
 Mariusthvdb
on 26 Sep 2020
Mariusthvdb
on 26 Sep 2020
chief, this templates were working just fine on all my instances up to 114.4. And only in 115 it cause the system to be non-responsive at all (cross tracking from other instances showing that it's offline). Only diff from "general" system that i'm having up to 2500 entities in my system.
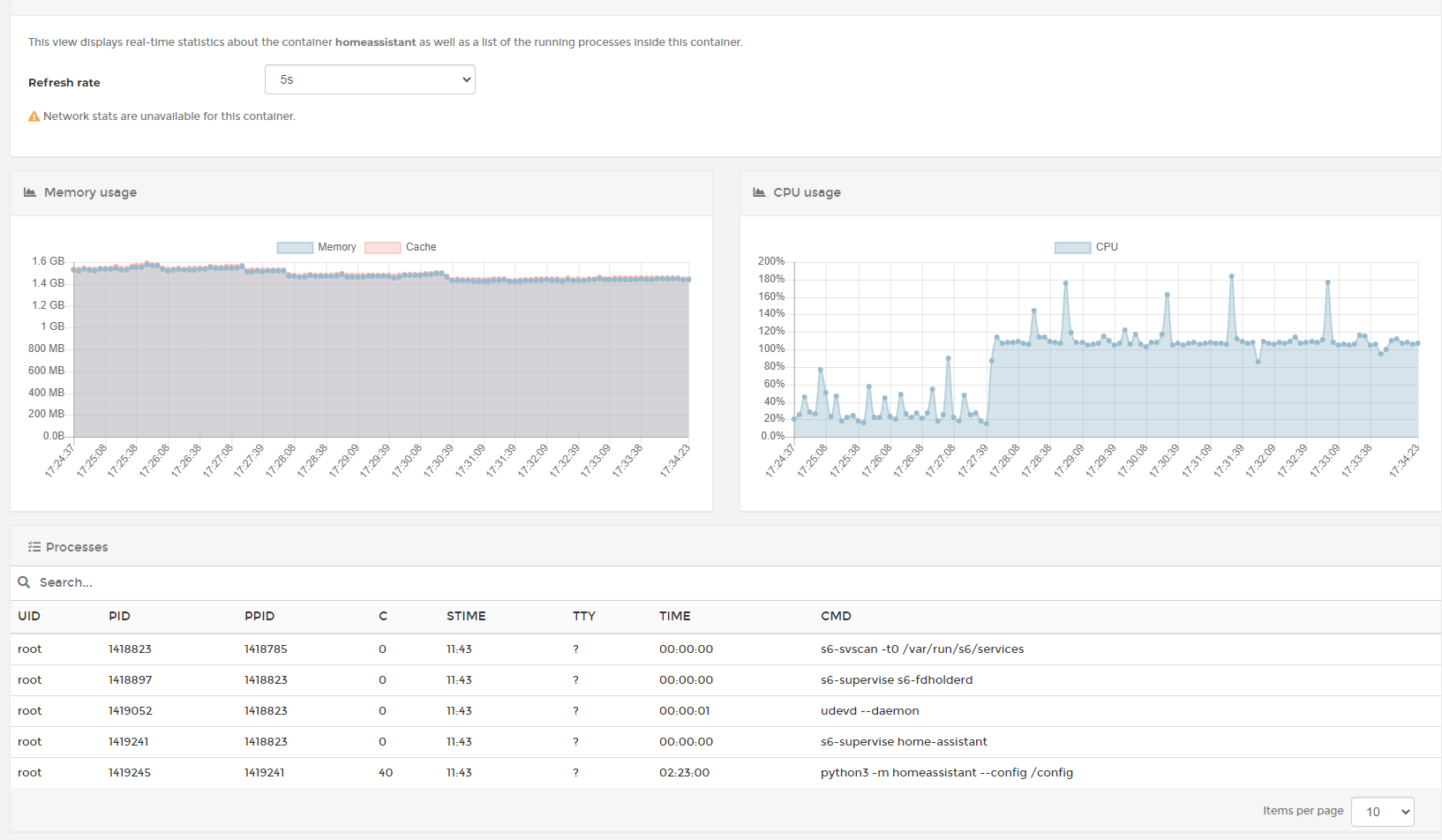
this how it looks like from portainer - and it's not dropping down when i do delete the template and press the Reset to Demo ...
it might be hat my templates not the best ones but they were working just fine even on RPI3b+ and this is happening on Xeon system as well as on i3 or celeron...my RPI simple not able to restart container - only power cycle helps...
to4ko
on 26 Sep 2020
chief, this templates were working just fine on all my instances up to 114.4. And only in 115 it cause the system to be non-responsive at all (cross tracking from other instances showing that it's offline).
In 0.114.4 we were not capable of tracking all state changed events from a template so you would not get any listeners when using states | ....
Only diff from "general" system that i'm having up to 2500 entities in my system.
How many state changed events / second does the system fire?
bdraco
on 26 Sep 2020
chief, this templates were working just fine on all my instances up to 114.4. And only in 115 it cause the system to be non-responsive at all (cross tracking from other instances showing that it's offline).
In 0.114.4 we were not capable of tracking all state changed events from a template so you would not get any listeners when using
states |....
But it were giving correct answer all the time without any problems. and adding antity_id we were able to set "update interval"
Only diff from "general" system that i'm having up to 2500 entities in my system.
How many state changed events / second does the system fire?
according to my postgre stats - like 15-20 event per seconds.
additionally once system starts evaluation template shown at the top, connection to addons got lost in couple of minutes - i was installing py-spy in terminal addon and get connection closed message. no any reaction on menubuttonstriggers whatever. only container restart.
to4ko
on 26 Sep 2020
I'm able to replicate the issue with:
{% for var in range(10000) -%}
{% for var in range(10000) -%}
{{ var }}
{%- endfor %}.
{%- endfor %}
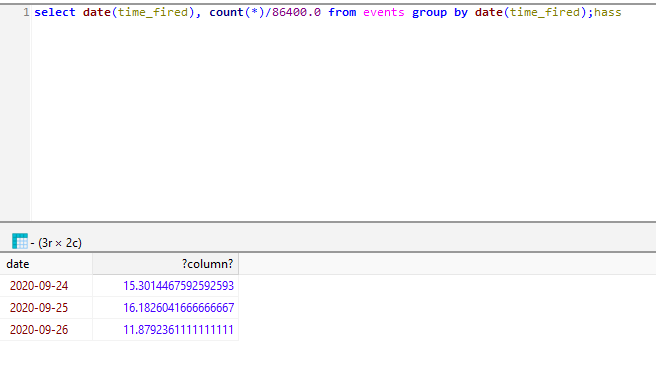
I can't replicate the issue with the template provided in the example using a system with 1200 states on the busiest system I have. The number of state changes events per second is much much lower than the reference system:
sqlite> select date(time_fired), count(*)/86400.0 from events group by date(time_fired);
2020-09-25|0.662002314814815
2020-09-26|0.821550925925926
I can't replicate the issue with the template provided in the example using a system with 1200 states on the busiest system I have. The number of state changes events per second is much much lower than the reference system:
sqlite> select date(time_fired), count(*)/86400.0 from events group by date(time_fired); 2020-09-25|0.662002314814815 2020-09-26|0.821550925925926
so what can be done?
to4ko
on 26 Sep 2020
I can't replicate the issue with the template provided in the example using a system with 1200 states on the busiest system I have. The number of state changes events per second is much much lower than the reference system:
sqlite> select date(time_fired), count(*)/86400.0 from events group by date(time_fired); 2020-09-25|0.662002314814815 2020-09-26|0.821550925925926so what can be done?
At 16.18 state changes per second that is ~1.4 million state changed events fired per day.
That's an impressive amount of state changes.
That means the template needs to check 3.5 billion states per day (in this case its actually 7 billion since its iterated twice).
Listening and iterating all states is never going to be viable on a system with those numbers no matter how much we optimize templates.
The only solution I can come up with is to revert the change that added listeners for all states but that isn't going over very well as other users rely on this.
bdraco
on 26 Sep 2020
I can't replicate the issue with the template provided in the example using a system with 1200 states on the busiest system I have. The number of state changes events per second is much much lower than the reference system:
sqlite> select date(time_fired), count(*)/86400.0 from events group by date(time_fired); 2020-09-25|0.662002314814815 2020-09-26|0.821550925925926so what can be done?
At 16.18 state changes per second that is ~1.4 million state changed events fired per day.
That's an impressive amount of state changes.
That means the template needs to check 3.5 billion states per day (in this case its actually 7 billion since its iterated twice).
Listening and iterating all states is never going to be viable on a system with those numbers no matter how much we optimize templates.
The only solution I can come up with is to revert the change that added listeners for all states but that isn't going over very well as other users rely on this.
maybe optionally add entity_id back - if it's specified use it (114 style), if not - than new 115 style
to4ko
on 26 Sep 2020
maybe optionally add entity_id back - if it's specified use it (114 style), if not - than new 115 style
The template tracking is used in bayesian sensors, template entities, automation triggers, universal media players, and the websocket api (the case you are reporting). This would handle the template entities case but it doesn't solve the issue you are reporting.
bdraco
on 26 Sep 2020
chief, this templates were working just fine on all my instances up to 114.4. And only in 115 it cause the system to be non-responsive at all (cross tracking from other instances showing that it's offline).
In 0.114.4 we were not capable of tracking all state changed events from a template so you would not get any listeners when using
states |....Only diff from "general" system that i'm having up to 2500 entities in my system.
How many state changed events / second does the system fire?
I use similar templates and they were correctly working until update to 0.115. It sounds very strange that "your instance that is generating more state changed events than the template engine can keep up with which leads to it being overwhelmed" while all previous HA versions were really capable to work with such templates. It is definitely because of non-optimized template engine code in 0.115 which is still not ready for release.
I also propose to add two features to templates engine:
1) it should have something like "template calculation timeout" inside and force stop any further calculation (with corresponding error/warning message in log) in case the engine is not capable to complete necessary updates online. It will significantly increase system stability in any case. The system behaviour when any entity can cause its hang up is not correct architectural solution.
2) HA documentation tells that any standard integration should work with some common parameters such as 'scan_interval' (https://www.home-assistant.io/docs/configuration/platform_options/). At the moment HA doesn't allow to use scan_interval in template sensor. For some 'heavy' sensors like above mentioned this option could also help to solve the problem. In case 'scan_interval' is not specified the template engine will update template by default rules.
 Spirituss
on 26 Sep 2020
Spirituss
on 26 Sep 2020
revert the change that added listeners for all states but that isn't going over very well as other users rely on this
I think that's a good compromise. Out of curiosity, who are the users relying on states getting listeners? That capability never existed prior to 0.115 so there can only be very few users who took advantage of it in the past week (since 0.115 was released). In addition, those who are relying on it might also be experiencing decreased performance (re: Marius's post above).
I think the old way of handling states (no automatically assigned listeners; use another entity, like sensor.time, to periodically update the template) was an effective (and efficient) technique. That was an unspoken advantage of entity_id, namely the ability to control the listeners assigned to a template.
 tdejneka
on 26 Sep 2020
tdejneka
on 26 Sep 2020
I think the old way of handling
states(no automatically assigned listeners; use another entity, likesensor.time, to periodically update the template) was an effective (and efficient) technique. That was an unspoken advantage ofentity_id, namely the ability to control the listeners assigned to a template.
The parameter 'entity_id' was quite simple and reliable solution to handle difficult template sensors.
Spirituss
on 26 Sep 2020
maybe optionally add entity_id back - if it's specified use it (114 style), if not - than new 115 style
The template tracking is used in bayesian sensors, template entities, automation triggers, universal media players, and the websocket api (the case you are reporting). This would handle the template entities case but it doesn't solve the issue you are reporting.
it will. my system will not hang on template testing. as of now - i need to restart container each time when i have an error. plus - to be honest - do we really need this "feature"? it was working just fine in the past. and not it's enchanted meaning broken.
to4ko
on 26 Sep 2020
chief, this templates were working just fine on all my instances up to 114.4. And only in 115 it cause the system to be non-responsive at all (cross tracking from other instances showing that it's offline).
In 0.114.4 we were not capable of tracking all state changed events from a template so you would not get any listeners when using
states |....Only diff from "general" system that i'm having up to 2500 entities in my system.
How many state changed events / second does the system fire?
I use similar templates and they were correctly working until update to 0.115. It sounds very strange that "your instance that is generating more state changed events than the template engine can keep up with which leads to it being overwhelmed" while all previous HA versions were really capable to work with such templates. It is definitely because of non-optimized template engine code in 0.115 which is still not ready for release.
I also propose to add two features to templates engine:
- it should have something like "template calculation timeout" inside and force stop any further calculation (with corresponding error/warning message in log) in case the engine is not capable to complete necessary updates online. It will significantly increase system stability in any case. The system behaviour when any entity can cause its hang up is not correct architectural solution.
jinja doesn't have a timeout capability. Since we have to render templates in async we don't have an easy way of aborting the execution without a signal which may not be safe to do.
https://github.com/pallets/jinja/issues/161
- HA documentation tells that any standard integration should work with some common parameters such as 'scan_interval' (home-assistant.io/docs/configuration/platform_options). At the moment HA doesn't allow to use scan_interval in template sensor. For some 'heavy' sensors like above mentioned this option could also help to solve the problem. In case 'scan_interval' is not specified the template engine will update template by default rules.
If we implemented that we would end up with multiple template implementations in template entities. This issue isn't about template entities though its about the template editor hanging in developer tools.
bdraco
on 26 Sep 2020
If we implemented that we would end up with multiple template implementations in template entities. This issue isn't about template entities though its about the template editor hanging in developer tools.
but it will became about template templates in general once a user will create this kind of template. dev tool is just on the top of all that
to4ko
on 26 Sep 2020
I'm come back to this once https://github.com/home-assistant/core/pull/40272 is reviewed as it will give more flexibility on how we can handle this without breaking state counting.
bdraco
on 26 Sep 2020
Assuming it solves all the cases, disabling the all states listener by default and implementing a flag allow_all_states_listener to turn it on seems a reasonable path forward after we can separate counting from iterating in #40272 as it means we don't end up with two implementations in template entities.
bdraco
on 26 Sep 2020
disabling the all states listener by default and implementing a flag
allow_all_states_listenerto turn it on seems a reasonable path forward
Instead of creating a new option, called allow_all_states_listener, which serves a single purpose, why not simply restore entity_id and allow it to accept states as a valid value? It would allow for more flexibility than a new, one-trick pony.
For example, this would, by default, _not_ assign listeners to all entities:
value_template: >
{{ states | selectattr( ... etc ...
whereas this would (because entity_id _overrides_ the default behavior for listener assignment):
entity_id: states
value_template: >
{{ states | selectattr( ... etc ...
Alternately, this would assign a listener exclusively for sensor.time and replicate the behavior of all past versions:
entity_id: sensor.time
value_template: >
{{ states | selectattr( ... etc ...
disabling the all states listener by default and implementing a flag
allow_all_states_listenerto turn it on seems a reasonable path forwardInstead of creating a new option, called
allow_all_states_listener, which serves a single purpose, why not simply restoreentity_idand allow it to acceptstatesas a valid value? It would allow for more flexibility than a new, one-trick pony.
Restoring entity_id would require the user to know about the flag in advance instead of trying to figure it out after they already have a performance issue. It also doesn't solve this issue.
bdraco
on 26 Sep 2020
@bdraco
The option @tdejneka suggests is very clear and simple solution for user.
Spirituss
on 26 Sep 2020
Restoring entity_id would require the user to know about the flag in advance instead of trying to figure it out after they already have a performance issue.
New features already require user to think about EVERY template and flags/new syntax in order not to hang up HA. Sounds unreasonable.
Spirituss
on 26 Sep 2020
Since allow_all_states_listener doesn't seem to be desired, I'm going to hold off moving forward until we can come up with a solution that accommodates the use cases without implementing two systems and solves the issue submitted here.
bdraco
on 26 Sep 2020
Restoring
entity_idrequire the user to know about the flag in advance
Users have employed entity_id all previous versions; they know its purpose. By reinstating entity_id, their templates will work just like they always have.
If entity_id is re-introduced it eliminates what was a Breaking Change (i.e. its deprecation in 0.115) and introduces it as an _enhanced_ version that now understands how to handle states (i.e. assign listeners to every entity).
In other words, the behavior remains more consistent with past versions where a value_template containing states was never automatically assigned listeners. The proposed enhancement is to allow for entity_id: states. By specifying it in their Template Sensor, the user is explicitly asking for the assignment of a boatload of listeners.
The added advantage of restoring entity_id is that the user will have, as they once did, manual control over listener assignment. For example, here I only want one listener for sensor.time and not for every binary_sensor in my system:
entity_id: sensor.time
value_template: >
{{ states.binary_sensor | selectattr( ... etc ...
Please do not spam this issue with discussion about entity_id being brought back. I've hid these comments. Next occurrence will result in a ban. This is the issue tracker, not for feature requests. The only thing you guys are achieving is that you are harassing someone who is actually trying to solve the problems. That's not something we accept in this community.
 balloob
on 26 Sep 2020
balloob
on 26 Sep 2020
Within the scope of the dev tools we need some type of safety net since users need to be able to safely experiment that covers:
- Very expensive templates
Example: massive iteration
{% for var in range(10000) -%}
{% for var in range(10000) -%}
{{ var }}
{%- endfor %}
{%- endfor %}
- Templates that re-fire too frequently
Example: iterate all states on busy systems (with the reference point being 1 million state change events per day or 3.5 billion iterates)
{{ states | list }}
- We end up with an all listener unexpectedly when we have a template error
Example: any invalid template.
[x] For 1 this is a single execution run problem where we need a way abort execution of a template that takes more than x seconds. https://github.com/home-assistant/core/pull/40647
[ ] For 2 the problem is the cumulative expense of execution where a rate limit probably makes sense. Will likely implement
rate_limitas described aslimitin https://github.com/home-assistant/architecture/issues/206. https://github.com/home-assistant/core/pull/40667[ ] We also need to tell the websocket api to use the rate limit from the dev tools (frontend change and websocket api change)
[x] For 3 https://github.com/home-assistant/core/pull/40624 addresses this issue
bdraco
on 26 Sep 2020
As posted here https://community.home-assistant.io/t/heads-up-upcoming-breaking-change-in-the-template-integration/223715/372?u=mariusthvdb
{% set ns = namespace(domains=[]) %} {% for d in states|groupby('domain') %} {% set ns.domains = ns.domains + [d[0]] %} {% endfor %} {% set list = ns.domains|join('\n') %} {{list if list|count < 255 else list|replace('input','inp')|truncate(255,true)}}115 is a bit too anxious to evaluate on state changes... no issues with these templates up to 114.
just to add to the thread here, for reference, thought it might be useful
and yes, only 'ha core restart' will do. The template testing for unavailable in that same thread, made even that impossible forcing to
ha host reboot. Won't copy the thread any further
Why was this hidden? It was on the exact issue of this issue tracker my contribution was aimed. A template killing the instance in dev template tools
Please unhide?
Mariusthvdb
on 26 Sep 2020
For 2 the problem is the cumulative expense of execution where a rate limit probably makes sense.
Penny had some thoughts on this while working on the new template engine: https://github.com/home-assistant/architecture/issues/206 – maybe it's better to continue the point 2 discussion there.
 amelchio
on 27 Sep 2020
amelchio
on 27 Sep 2020
For 2 the problem is the cumulative expense of execution where a rate limit probably makes sense.
Penny had some thoughts on this while working on the new template engine: home-assistant/architecture#206 – maybe it's better to continue the point 2 discussion there.
Fantastic 👍 🥇 💯 🚀
This is exactly the help I was looking for 😄 😄 😄
bdraco
on 27 Sep 2020
@bdraco This may be related, I've noticed that listeners are set to all states when using states.domain.object_id with an object_id that is not present on the system (i.e. a typo). Is this intended or a bug?
 Petro31
on 28 Sep 2020
Petro31
on 28 Sep 2020
@bdraco This may be related, I've noticed that listeners are set to all states when using
states.domain.object_idwith an object_id that is not present on the system (i.e. a typo). Is this intended or a bug?
@Petro31
That is intended because we don't know if the entity is about to be added. If it really is a typo it doesn't cost much since its storing a dict key/value that which has near O(1) performance and since we will never get a state changed event for an entity that doesn't exist its not really an issue.
bdraco
on 28 Sep 2020
@bdraco This may be related, I've noticed that listeners are set to all states when using
states.domain.object_idwith an object_id that is not present on the system (i.e. a typo). Is this intended or a bug?@Petro31
That is intended because we don't know if the entity is about to be added. If it really is a typo it doesn't cost much since its storing a dict key/value that which has near O(1) performance and since we will never get a state changed event for an entity that doesn't exist its not really an issue.
Great, thanks
Petro31
on 28 Sep 2020
Related issues
 MartinHjelmare
·
3Comments
MartinHjelmare
·
3Comments
 aweb-01
·
3Comments
bdraco
·
3Comments
aweb-01
·
3Comments
bdraco
·
3Comments
 piitaya
·
3Comments
piitaya
·
3Comments
 TheZoker
·
3Comments
TheZoker
·
3Comments