Consul: [Performance] Limit impact of Cache on Consul Servers
We are using SDKs for a long time (as described here: https://medium.com/criteo-labs/be-a-good-consul-client-5b55160cff7d ) with stale requests and limitation of calls per seconds, almost exclusively on health/service endpoint on some very large services (several hundreds of instances).
Starting a few months ago, we started using ?cache calls to Consul, this allows the agent to reduce the number of calls per second on machines running containers assuming applications will often use the same services (eg: databases, logs...)
This works quite well, but we recently had an incident: we were disabling our old GRPC patches that improve quite a lot the performance, while one of our major applications with a very large pool got unstable. The result was that this large application (up to 1.5k instances on a single DC) tests got red on many instances (lost connectivity) and green again once restarted, resulting in several updates/second on health/service. This service is being watched by another very large application (up to 600 instances).
Usually, our SDKs did throttle quickly their calls to Consul and when things get very unstable, the SDKs do throttle to something like 1 call every 10s, which reduces quite a lot the load on Consul server. But with the cache, throttling the number of calls/sec is without effect as the cache is updated even without any request from our SDK.
We almost lost the cluster for a long time and many operations usually completing in 10's of milliseconds took up to 3 minutes to complete (example: registering service for monitoring)
Could it be possible to add configuration options or default behavior to Consul clients to be able to add similar behavior to cache, so the cache can throttle itself when too many updates are being seen on a pool?
 pierresouchay
pierresouchay
All 10 comments
cc @i0rek
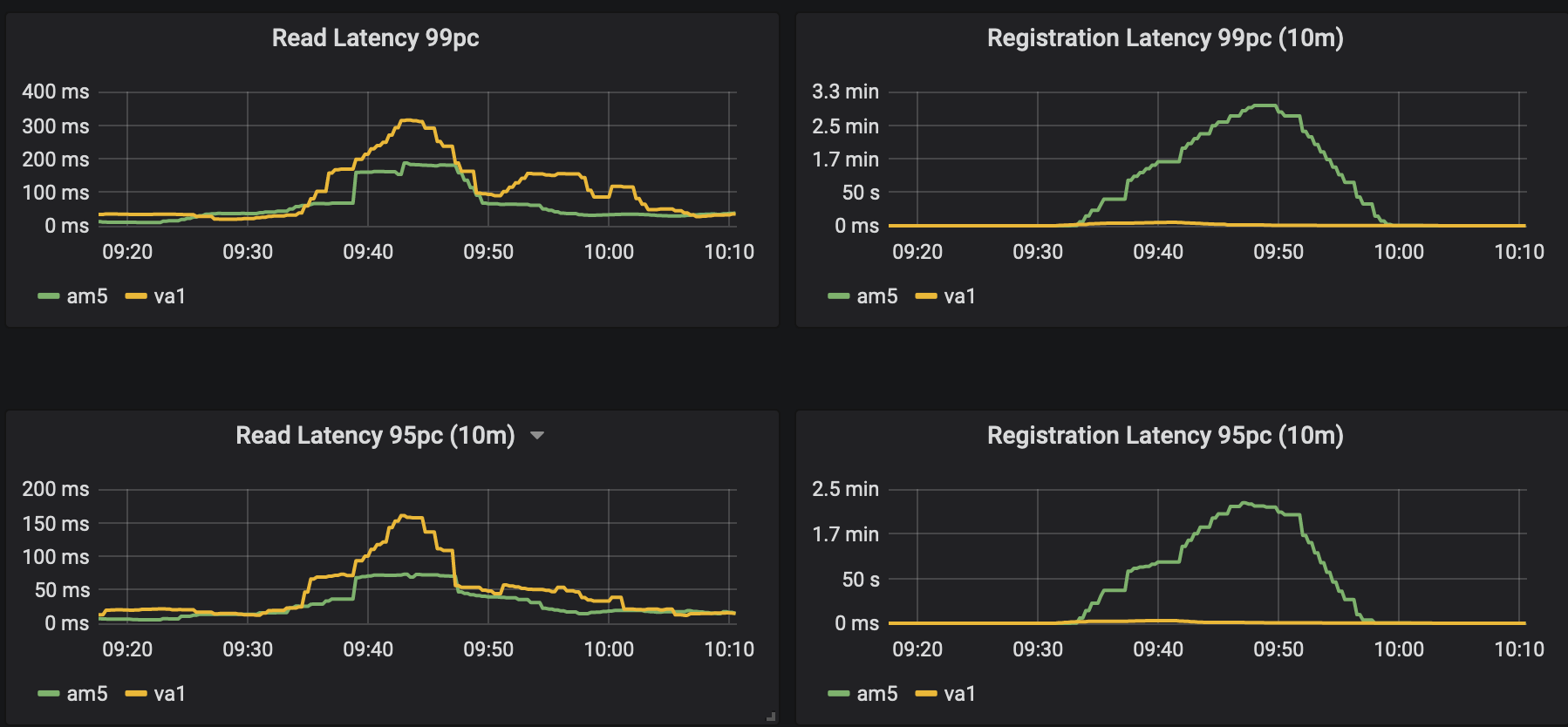
Here is the impact of this behavior during the incident (all CPUs of Consul server were at that time at 100%)
pierresouchay
on 13 May 2020
Thanks Pierre for the great report.
Just some broader context to share here:
We have an internal research project ongoing which is aiming to work towards a principled solution to this which is having servers more resilient to failures and able to shed load proactively before they are overwhelmed. This helps because it will allow clients to intelligently back off.
It's unknown when that will be something we get into a Consul release though as it's surprising subtle to get right in a way that doesn't remove all the benefits of Golang concurrency or require operators to be constantly tweaking tuning parameters to find the optimal balance between safety/stability and not limiting throughput way below what the hardware is capable of.
Of course streaming efficiency gains will eventually also help here in the sense that servers will have much more capacity again to copy with spikes like this.
Finally, I think the request here is to be able to configure a per-client rate limit that impacts the cache background refresh. Is that right? Some questions:
- Did you have regular client rate limiting enabled? If not, doesn't that already do what you need?
- Would you have this turned off in normal operation and only configure it during an incident to help resolve it quicker?
- If you'd leave it limited permanently, how would you capacity plan for genuine growth that is stable, vs abuse or unusual incidents where the churn rate in the cluster spikes much higher?
 banks
on 13 May 2020
banks
on 13 May 2020
We have been rate limiting in our SDKs for ages, basically, on a given endpoint, we use all the time a bucket algorithm to ensure we do not fetch more than 2/3 times per 10s changes (I don't really remind the exact limit, I can dive), so a stable service get updates.
There is also a security to avoid overwhelming the server(s) when we receive timeouts or HTTP 500: we do apply penalties and backoff (so, the more errors you get, the less calls you are performing up to some configurable limit (something like 3/5 minutes IIRC)
On some of our health endpoints, during massive deployments, we had up to 3k servers per pool, meaning more than 1qps/s (sometimes 5/6 ops to get the updates), with the cardinality of clients (sometimes up to 3k clients), those protections were really helpful and mitigated quite a lot the incidents (especially the backoff in case of timeouts/errors server side).
We do not implement rate limit per agent, we want to apply penalty on large services, on some of our machines, we have something like 20 applications, all of them using Consul. If 1 is using an unstable service, we want the apps watching a massive unstable service to be notified less, while other apps get their notification as it used to be.
In our experience, just 2/3 unstable services with many clients (4/5k clients) can put the leader down to its knees, especially without our GRPC patches.
Using cache is very helpful, because amongst those 20 apps running on a machines, all shared services (there are a lot of them), will consume a single request to Consul servers instead of let's say 20. But when those health endpoints get unstable. Stopping to request on the SDK side does not stop the cache to be refreshed as fast as it can, so it breaks.
For us, we don't care about being notified in 1/12 of second about service changes, the granularity of updates is around 10s (that how most of our healthchecks are configured), so do not take 40 changes in 10s is fine and just getting 1 is fine for us, we would really use it all the time.
Having a hot reload mechanism (so we can change it dynamically) would be even better, but definitely not a MUST have for us.
pierresouchay
on 13 May 2020
@banks I was thinking about implementing somethink like this with simple hashes:
"blocking-cache-configuration": {
"*": "1s",
"health": {
"service": {
"*": "3s",
"my-database": "2s",
"my-large-service": "15s"
}
},
"catalog": {
"services": "10s",
"service": {
"*": "2s",
"my-database": "3s",
"my-large-service": "10s"
}
}
}
Meaning (in this example):
- By default, all cached blocking queries with 1s of timer
- /v1/health/service/* => 3s (all health req by default)
- /v1/health/service/my-database => 2s
- /v1/health/service/my-large-service => 15s
- /v1/catalog/services =>10s
- /v1/catalog/service/* => 2s by default (we don't care with updates more frequent than every 2s)
- /v1/catalog/service/my-database => 3s
- /v1/catalog/service/my-large-service => 10s
On the long run, you'd be free to implement /v1/catalog/service/my-database* using radix or advanced regexp
From what I see, it would be not that hard to implement and would definitly solve all of our ssiues.
Possible issue:
This would of course not only apply to HTTP, but also to DNS of course, where the path /v1/health/service/my-large-service is a bit less trivial for the administrator (but we could assume it could be documented)
pierresouchay
on 20 May 2020
I think I understand, if I rephrase can you confirm the issue:
Client rate limiting today doesn't do what you need because you don't want to have one single rate for the whole client but want to limit request rate per service/RPC type separately.
I don't like the idea of configuring "sleeps" in between requests - it makes it much easier to reason about if you instead configure maximum request rates which means in the normal case where things aren't changing fast there are no extra sleeps. It seems easier to reason about "rate limit" for an operator rather than "how long to sleep during each iteration of requests" which is very implementation specific.
Your proposal strikes me as pretty complicated to maintain - this new config block will need to be kept in sync with every new API we enable via cache and like you mentioned once we use cache for DNS or other things it gets even more complicated.
Would it solve your issue if you could set a single maximum cache refresh rate per cache entry? (i.e. not a global rate limit on all RPCs like we have now, but a limit so no one cache entry can request more than X times a second/minute?) Because it's a rate limit and not a sleep it won't affect performance in normal cases or for other services if you set it quite low, will only kick in during igh churn and then only will limit the service that is churning etc.
That seems like it would solve the issue for more folks without creating complicated tuning knobs that almost no-one will ever likely use! Also much less to maintain as it will jsut work regardless of new types added etc.
banks
on 20 May 2020
Client rate limiting today doesn't do what you need because you don't want to have one single rate for the whole client but want to limit request rate per service/RPC type separately.
Yes
Would it solve your issue if you could set a single maximum cache refresh rate per cache entry? (i.e. not a global rate limit on all RPCs like we have now, but a limit so no one cache entry can request more than X times a second/minute?) Because it's a rate limit and not a sleep it won't affect performance in normal cases or for other services if you set it quite low, will only kick in during igh churn and then only will limit the service that is churning etc.
Yes
pierresouchay
on 25 May 2020
Watching
 orarnon
on 18 Jun 2020
orarnon
on 18 Jun 2020
Implemented a basic solution (without per service) that is probably good enough: https://github.com/hashicorp/consul/pull/8226
pierresouchay
on 2 Jul 2020
@banks @jsosulska Do you think you might consider #8226?
I would solve our scalability issues very easily (we would, for instance, allow only 2 queries per 10s on a given service, thus limiting the impact on servers)
pierresouchay
on 17 Jul 2020
We tested this PR in the real world today (16k agents being upgraded very quickly) and the metrics were something 10x better (full registration delay during such events was around 2s+, was 250ms max), tested with:
{
"cache": {
"entry_fetch_rate": 0.333,
"entry_fetch_max_burst": 3
}
}
=> really fix our issue
pierresouchay
on 24 Aug 2020
Related issues
 hooksie1
·
3Comments
hooksie1
·
3Comments
 matteoturra
·
4Comments
matteoturra
·
4Comments
 eshujiushiwo
·
3Comments
eshujiushiwo
·
3Comments
 achille-roussel
·
4Comments
achille-roussel
·
4Comments
 deadjoe
·
4Comments
deadjoe
·
4Comments
Most helpful comment
We tested this PR in the real world today (16k agents being upgraded very quickly) and the metrics were something 10x better (full registration delay during such events was around 2s+, was 250ms max), tested with:
=> really fix our issue