Consul: Error getting server health - context deadline exceeded
When filing a bug, please include the following headings if
possible. Any example text in this template can be deleted.
Overview of the Issue
We have recently upgraded our consul servers from 0.8.5 to 1.0.7 on
Ubuntu 16.04 and they immediately started to log this line
_SERVER NAME A consul[46553]: consul: error getting server health from "SERVER NAME B": context deadline exceeded_
Where SERVER NAME A and SERVER NAME B are any of 5 consul servers.
It looks like the RPC call fails to make it within the time frame allotted on the calling side.
Most commonly this is being logged on the cluster leader reaching out to other cluster servers.
The frequency of the line being logged is somewhat between 6 and 60 per hour.
Is there any serious issue behind this line we should worry about?
How can we make it go away?
Reproduction Steps
- upgrade consul servers from 0.8.5 to 1.0.7
- observe the error in logs every now and then
Consul info for both Client and Server
Client info
agent:
check_monitors = 0
check_ttls = 0
checks = 17
services = 20
build:
prerelease =
revision = fb848fc4
version = 1.0.7
consul:
known_servers = 3
server = false
runtime:
arch = amd64
cpu_count = 16
goroutines = 64
max_procs = 16
os = linux
version = go1.10
serf_lan:
coordinate_resets = 0
encrypted = true
event_queue = 0
event_time = 798
failed = 0
health_score = 0
intent_queue = 0
left = 13
member_time = 13299
members = 128
query_queue = 0
query_time = 4
Server info
agent:
check_monitors = 0
check_ttls = 0
checks = 1
services = 1
build:
prerelease =
revision = fb848fc4
version = 1.0.7
consul:
bootstrap = false
known_datacenters = 3
leader = true
leader_addr = 10.140.1.26:8300
server = true
raft:
applied_index = 881379027
commit_index = 881379027
fsm_pending = 0
last_contact = 0
last_log_index = 881379028
last_log_term = 88645
last_snapshot_index = 881376863
last_snapshot_term = 88645
latest_configuration = [{Suffrage:Voter ID:13e6f021-616b-4a22-8ae3-77481f1c957d Address:10.140.1.26:8300} {Suffrage:Voter ID:be739205-ff37-4629-97b2-06ce5f493d23 Address:10.140.1.25:8300} {Suffrage:Voter ID:45dd3826-986d-fa44-b68c-f85d21159ea2 Address:10.140.1.2
3:8300} {Suffrage:Voter ID:5cb49862-8d46-0a03-daeb-c352d2d67fd3 Address:10.140.1.53:8300} {Suffrage:Voter ID:50429a71-dfd3-6995-c13c-00b761ec76c0 Address:10.140.1.52:8300}]
latest_configuration_index = 881368980
num_peers = 4
protocol_version = 3
protocol_version_max = 3
protocol_version_min = 0
snapshot_version_max = 1
snapshot_version_min = 0
state = Leader
term = 88645
runtime:
arch = amd64
cpu_count = 2
goroutines = 12536
max_procs = 2
os = linux
version = go1.10
serf_lan:
coordinate_resets = 0
encrypted = true
event_queue = 0
event_time = 462
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 23482
members = 225
query_queue = 0
query_time = 43
serf_wan:
coordinate_resets = 0
encrypted = true
event_queue = 0
event_time = 1
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 425
members = 11
query_queue = 0
query_time = 11
Operating system and Environment details
Ubuntu 16.04 x64
Log Fragments
May 17 08:36:07 d2-gog-cnsl-cl2 consul[44416]: consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:36:07 d2-gog-cnsl-cl2 consul[44416]: 2018/05/17 08:36:07 [WARN] consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:36:06 d2-gog-cnsl-cl2 consul[44416]: consul: error getting server health from "d2-gog-cnsl-cl1": context deadline exceeded
May 17 08:36:06 d2-gog-cnsl-cl2 consul[44416]: 2018/05/17 08:36:06 [WARN] consul: error getting server health from "d2-gog-cnsl-cl1": context deadline exceeded
May 17 08:25:45 d2-gog-cnsl-cl2 consul[44416]: consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:25:45 d2-gog-cnsl-cl2 consul[44416]: 2018/05/17 08:25:45 [WARN] consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:25:43 d2-gog-cnsl-cl2 consul[44416]: consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:25:43 d2-gog-cnsl-cl2 consul[44416]: 2018/05/17 08:25:43 [WARN] consul: error getting server health from "d2-gog-cnsl-cl1": last request still outstanding
May 17 08:25:42 d2-gog-cnsl-cl2 consul[44416]: consul: error getting server health from "d2-gog-cnsl-cl1": context deadline exceeded
May 17 08:25:42 d2-gog-cnsl-cl2 consul[44416]: 2018/05/17 08:25:42 [WARN] consul: error getting server health from "d2-gog-cnsl-cl1": context deadline exceeded
The rest of the logs is passing http requests and passing checks
 mak-m
mak-m
All 11 comments
I'm pretty interested to see if this gets answered. I'm having these WARNs too when using consul exec, but in my case consul exec is indeed killing executions mid-way in what seems to be a random fashion. I would make sense that it is related to the RPC call failing to make it within the alloted time frame.
 bersalazar
on 16 Jul 2018
bersalazar
on 16 Jul 2018
I have installed 1.2.0 on five OpenBSD 6.3 based VMs all on the same hypervisor and experience the same errors in logs. happens at seemingly random intervals (every minute, sometimes with 3-5 minutes in between.
this only happens with the second server (with bootstrapped-expect=3). the other two clients have complained: Failed fallback ping: read tcp 100.64.4.3:38270->100.64.1.3:8301: i/o timeout
a few times, but only to the first server.
happy to provide more information. I'm just exploring with Consul, so this is more an odd annoyance than anything else.
 aaglenn
on 17 Jul 2018
aaglenn
on 17 Jul 2018
@bersalazar Yes the context deadline exceeded warnings are when the the RPC to the server just takes too long. The only situation I have seen this in the past was with really high cpu utilization on the server who stopped responding to the RPCs.
The second log message that says the last request is still outstanding occurs when we go to get the servers health a second time but the first request (that we emitted the error for the first time) is still ongoing. In this case we dont issue a new RPC because this would cause more RPC load on the server its trying to send the RPC to.
Are you using consul exec to execute any process that could cause high cpu utilization on the server?
@aaglenn Have you happened to look at resource utilization when one of these events occurs? Are you experimenting with consul-template or anything else which may execute many blocking queries to Consul concurrently?
 mkeeler
on 18 Jul 2018
mkeeler
on 18 Jul 2018
@mkeeler I did not at the time, but noticed the correlation between my laptop fan spinning up and the log messages shortly after writing.
aaglenn
on 18 Jul 2018
@aaglenn Yeah most likely its overloading the cpu a bit. Usually the node that is taking a long time to respond is the leader of the cluster and its doing more than the other members so its cpu utilization will be higher. Running all of this on one hypervisor may exacerbate the situation as all the nodes will be contending for the same CPU.
mkeeler
on 18 Jul 2018
Not sure if related (and happy to open a separate ticket), but we recently upgraded from 0.92 to 1.2.1 and ever since have had the context deadline exceeded messages.
Where SERVER NAME A and SERVER NAME B are any of 5 consul servers.
In our case (and unlike above), the messages only originate from the leader. We have seen 9 occurrences of that message in the last 14 days, and I have looked up the metrics for each point in time, and there is no indication that the leader or the slaves were under load / constrained.
Any advice appreciated.
 chrisdewar
on 28 Aug 2018
chrisdewar
on 28 Aug 2018
We've also run into the issue (I believe we're running 1.0.0) but we're seeing both the context deadline exceeded message and the last request outstanding message upwards of 100 times a day. We're running 5 consul servers and only see the messages on the leader, and none of the nodes appear to be under high cpu utilization.
 a-cong
on 12 Sep 2018
a-cong
on 12 Sep 2018
@mak-m : Closing this since we looked into this issue in a support ticket you opened in conjunction to this and found, after reviewing your go-routine logs, that one of your nodes was running a large number of blocking queries which lead to CPU starvation
 ChipV223
on 20 Dec 2018
ChipV223
on 20 Dec 2018
@ChipV223
We have the same issue as @a-cong , this can make occasionally requests failed.
 ccl0326
on 10 Jan 2019
ccl0326
on 10 Jan 2019
@ChipV223 @pearkes
We have the same issue as @a-cong .But our 5 consul(v1.1.0) servers run on CentOS 7.2 of 32 core CPU、 32G memory and 10 Gbps 。Cpu busy is about 10%-40%,memory used less then 10% ,and Network Out about 30MB. We only use consul http to register and discover, about 250 services and 2000 nodes.
But when we expand our service node, the consul server health will be critical.The health service api would be time out.
Should we care about the cluster autopilot health? And what the max qps of health service api? The goroutine number in our consul server is normal? What should we do if we want to add more service node?
Hope you can give me some advice.
log msg:
2019/05/11 16:50:27 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:27 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:27 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:29 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:29 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:29 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:29 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:37 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:39 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:50:39 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:51:00 [ERR] memberlist: Failed fallback ping: write tcp xxxx:36554->xxxx:8301: i/o timeout
2019/05/11 16:51:00 [INFO] memberlist: Suspect xxxx has failed, no acks received
2019/05/11 16:51:22 [WARN] memberlist: Refuting a suspect message (from: xxxx)
2019/05/11 16:51:33 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:51:39 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:51:39 [ERR] memberlist: Failed fallback ping: write tcp xxxx:38296->xxxx:8301: i/o timeout
2019/05/11 16:51:39 [INFO] memberlist: Suspect xxxx has failed, no acks received
2019/05/11 16:51:41 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:51:41 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:51:43 [ERR] memberlist: Failed fallback ping: write tcp xxxxx:42551->xxxx:8301: i/o timeout
2019/05/11 16:51:43 [INFO] memberlist: Suspect xxxx has failed, no acks received
2019/05/11 16:52:19 [WARN] memberlist: Refuting a suspect message (from: xxxx)
2019/05/11 16:52:23 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:52:23 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:52:25 [WARN] consul: error getting server health from "xxxx": context deadline exceeded
2019/05/11 16:52:25 [ERR] memberlist: Failed fallback ping: write tcp xxxx:37253->xxxx:8301: i/o timeout
2019/05/11 16:52:25 [INFO] memberlist: Suspect xxxx has failed, no acks received
2019/05/11 16:52:26 [WARN] memberlist: Refuting a suspect message (from: xxxxx)
server info:
agent:
check_monitors = 0
check_ttls = 0
checks = 0
services = 0
build:
prerelease = dev
revision =
version = 1.1.0
consul:
bootstrap = false
known_datacenters = 1
leader = false
leader_addr = xxxx:8300
server = true
raft:
applied_index = 57662938
commit_index = 57662938
fsm_pending = 0
last_contact = 706.871571ms
last_log_index = 57662940
last_log_term = 2174
last_snapshot_index = 57646465
last_snapshot_term = 2174
latest_configuration = [xxxxxxxx]
latest_configuration_index = 49626754
num_peers = 4
protocol_version = 3
protocol_version_max = 3
protocol_version_min = 0
snapshot_version_max = 1
snapshot_version_min = 0
state = Follower
term = 2174
runtime:
arch = amd64
cpu_count = 32
goroutines = 104325
max_procs = 32
os = linux
version = go1.9.4
serf_lan:
coordinate_resets = 0
encrypted = false
event_queue = 0
event_time = 772
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 36705
members = 1813
query_queue = 0
query_time = 3
serf_wan:
coordinate_resets = 0
encrypted = false
event_queue = 0
event_time = 1
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 839
members = 5
query_queue = 0
query_time = 1
some important metrics:
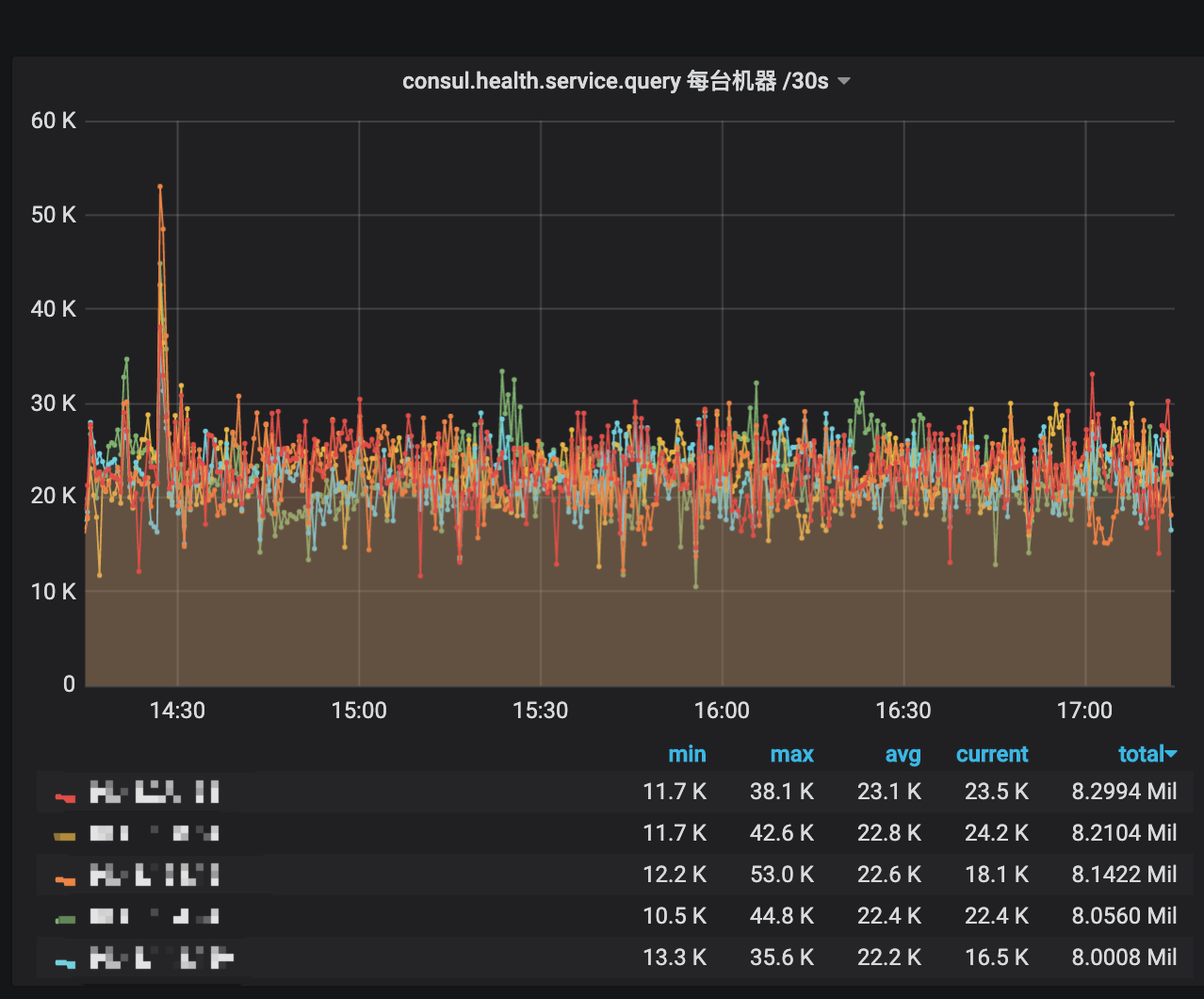
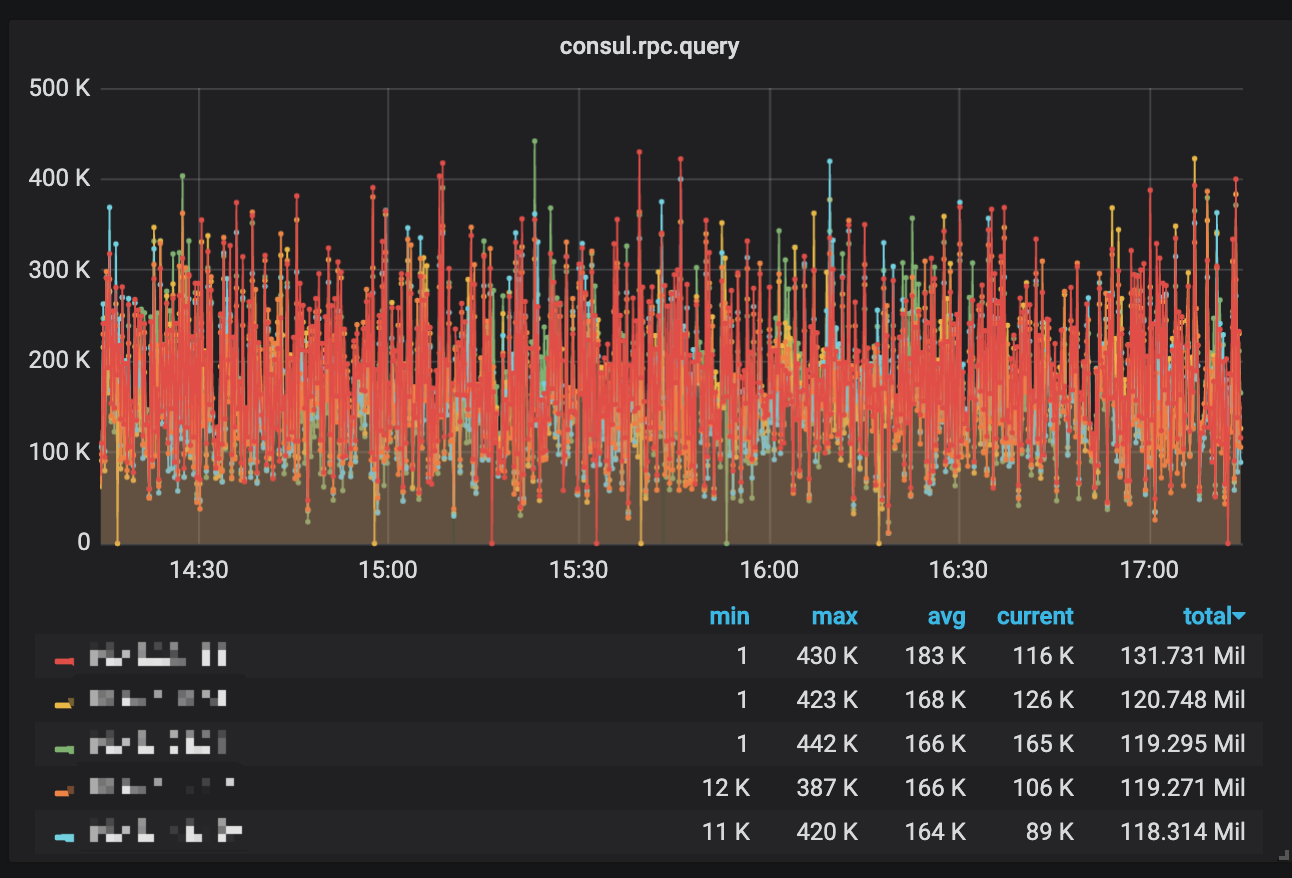
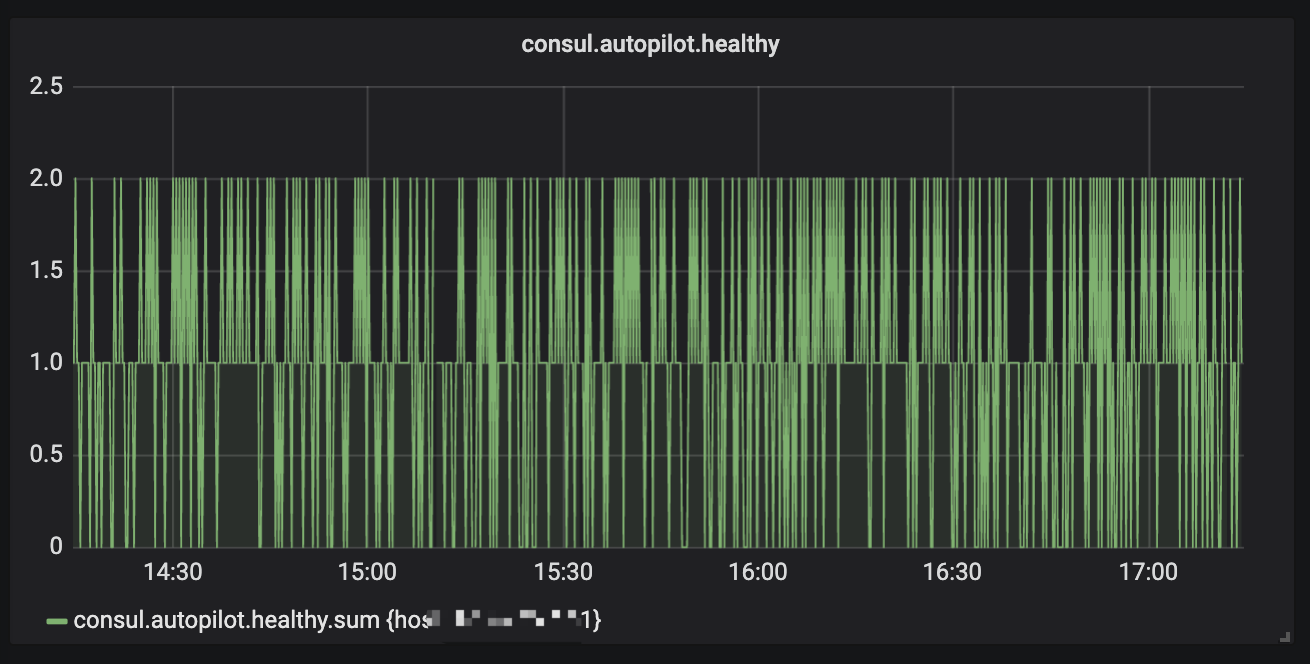
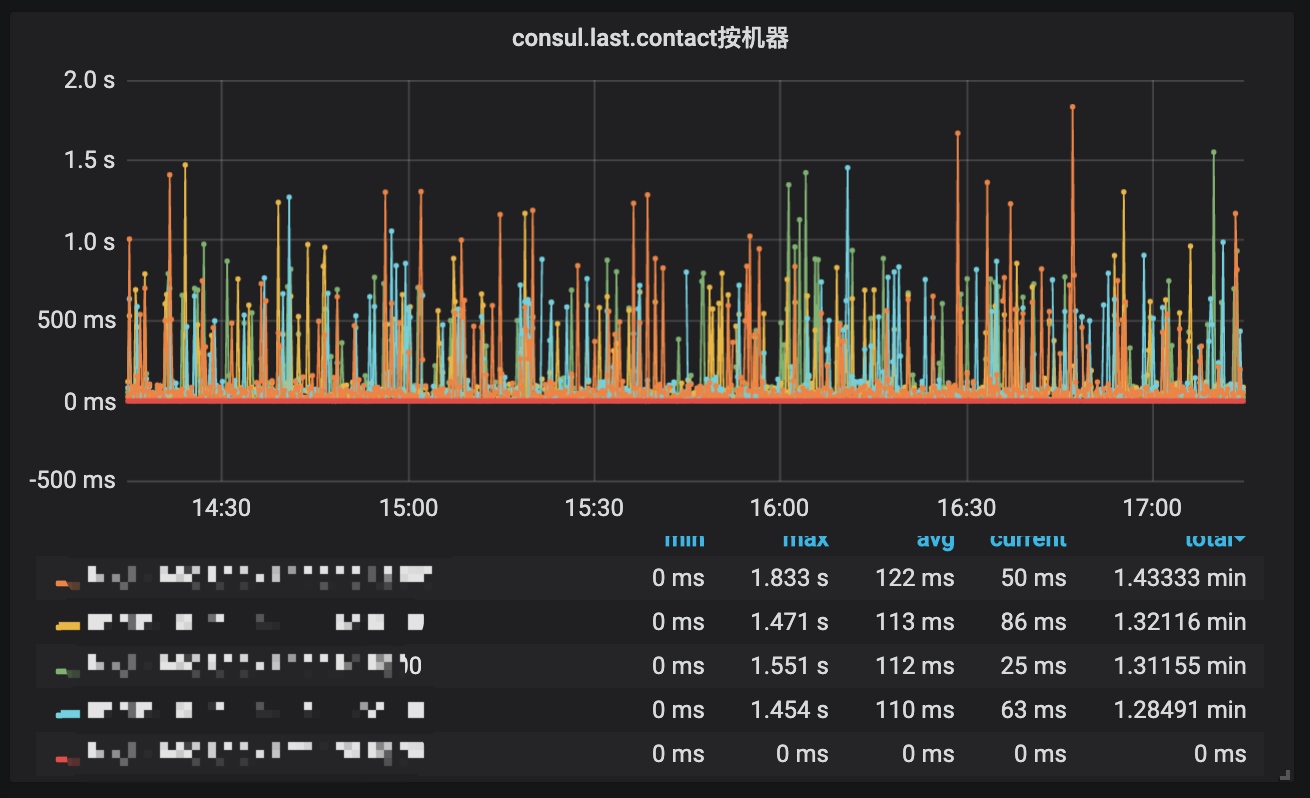
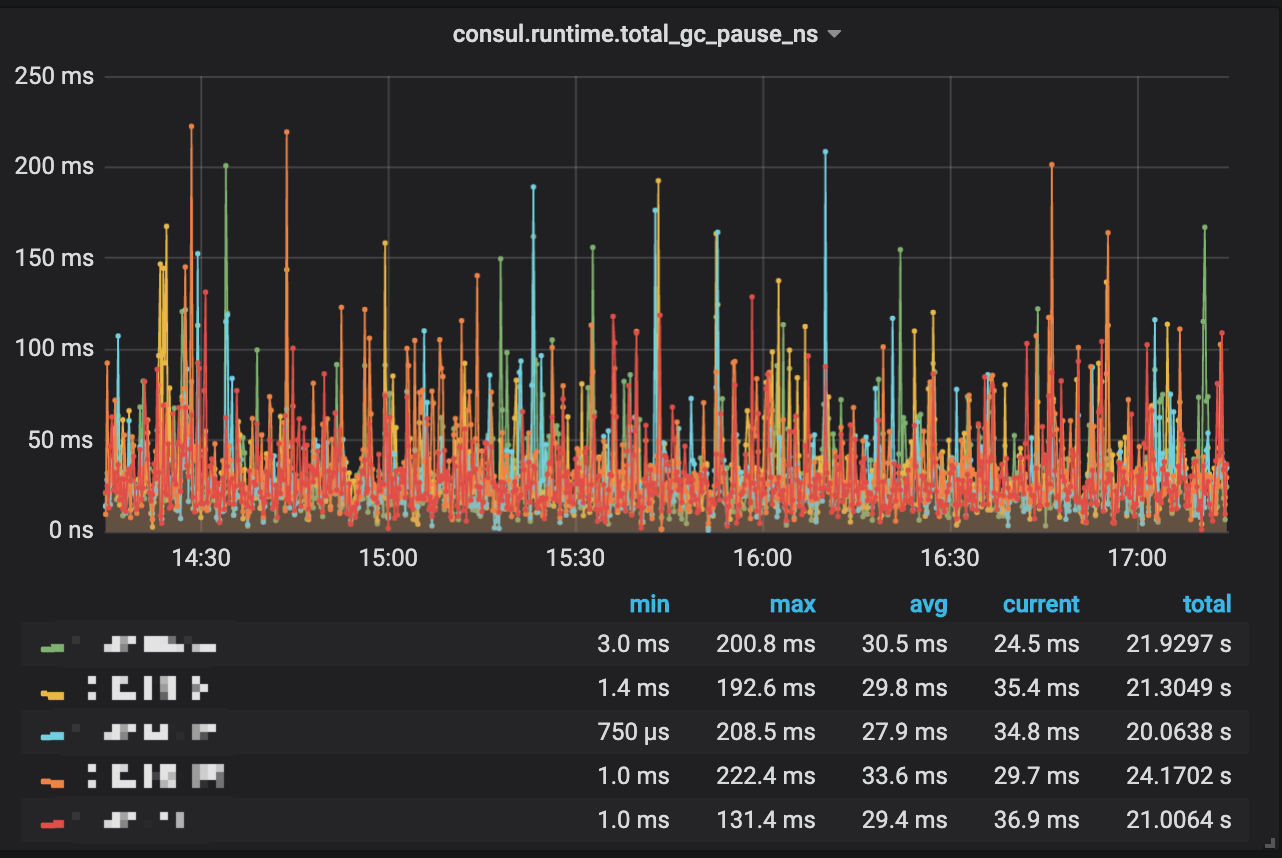

 superbool
on 11 May 2019
superbool
on 11 May 2019
I have the same issues. I deploy the Consul server cluster include 3 nodes. I check log and see:
manager: Rebalanced 3 servers, next active server is consul3_645.6 (Addr: tcp/x.x.x.x:8300) (DC:xxx-consul-dev-cluster
 phamtai97
on 11 Feb 2020
phamtai97
on 11 Feb 2020
Related issues
 nicholasjackson
·
3Comments
nicholasjackson
·
3Comments
 wing731
·
3Comments
wing731
·
3Comments
 slackpad
·
3Comments
slackpad
·
3Comments
 achille-roussel
·
4Comments
achille-roussel
·
4Comments
 nschoe
·
4Comments
nschoe
·
4Comments
Most helpful comment
We've also run into the issue (I believe we're running 1.0.0) but we're seeing both the
context deadline exceededmessage and thelast request outstandingmessage upwards of 100 times a day. We're running 5 consul servers and only see the messages on the leader, and none of the nodes appear to be under high cpu utilization.