Conan: Jenkins-Artifactory | Gather information about CI use-cases
I'm opening this issue to gather use-cases related to CI that you are using (or trying to use) with the help of the Artifactory-Jenkins plugin (repo here). As you may know it has some integration with the Conan client (docs) but there is still a long path ahead.
We know that many of you are actually using the plugin and have open some issues because you need more functionalities. That's great! We want to improve it, but before implementing minor details we would like to gather feedback from the community so we can design a clear and robust set of commands that will fit most use-cases. Also, we think that sharing this kind of information can be very valuable for everyone.
I'm leaving this issue open here, I will collect and link all the use-cases you want to share with us, and I will try to reproduce the commands needed from the plugin to run those scenarios. Also, if you don't feel comfortable describing your CI publicly, you can reach to us by email [email protected] or find us in Slack/Cpplang.
 jgsogo
jgsogo
All 17 comments
I'm sharing a Google Docs with you all to document some scenarios (Jenkinsfile associated), the idea is to design the roadmap for the plugin and share _best practices_ for common scenarios. Feel free to comment there (probably you have a better knowledge of Jenkins capabilities)
📝 https://docs.google.com/document/d/1dkwPA1t5_wrEzsv4Gl-W13LiO6TYCx-xEJ_t40Q2eUo/edit?usp=sharing
jgsogo
on 30 Jul 2019
Thanks for gathering all this information, I am sure that a good CI support for Conan will be helpful for many!
Let me try and gather usecases which will be relevant for our company.
But to do this, I would like to differentiate two cases:
- Build of third party libraries
- Build of internal libraries (recipes in source)
For all usecases:
- Installing Conan Configurations:
This will be very important as we will provide all common profiles in a gerenic configurations repository
It might also make sense that you can set a (default?) profile for the ConanClient
Rebuilding for a new profile:
I think this will be very important for us potentially. Switching compilers (e.g. VS 2012 -> VS 2015) was a HUGE paint because we had to rebuild all our dependencies. Doing this in the future with Conan should be a blast, but we need to have the possibility to iterate over (all?) published recipes and rebuild / publish them with a given profile.Managing the Conan Cache:
I think it does not make so much sense to have the Conan cache in the workspace. Downloading all dependencies on every build may potentially take a long time, plus disk space may fill up quickly when building many packages.
On the other hand, produced artefacts should not be located in the shared cache (unless a package is published).
Maybe it does make sense to give an option toconan create(just like you have withconan source,conan build, ...) that lets set an output directory of all build stuff (source, export, build folders). This way you could have all produced data in your workspace, but all requirements inside the conan cache.
For out of source recipes:
- Comparing local vs published recipes:
It would be helpful to have an easy way to check if:
a) The current recipe on the server is the same as the local one (think package revisions)
-> Outdated: I need to rebuild
-> not outdated: don't need to rebuild
b) The current recipe is already packaged for the given profile.
If a) and b), then the job does not need to rebuild the package
For internal libraries:
- Creating but not publishing recipes
I want to always check in my CI that a package builds and the test_package can consume it correctly, but I don't want it published (locally or remotely)
Another point, where I can't quite wrap my head around is to distinguish between using conan for just getting the requirements (e.g. conan install) vs actually creating a package (conan create) regarding the CI usage.
E.g. when I actively develop libA, will my CI jobs just use conan install on a regular basis and I build from there (including tests) and only on a library release will my CI job call (conan create)? Or instead, will my CI job always call conan create?
I am not quite sure what of these points can be realized today (with the current API) and what can't, but these are the points that would make my life easier for a CI integration.
 KerstinKeller
on 2 Aug 2019
KerstinKeller
on 2 Aug 2019
One of the biggest issues is caching of stable packages. For example, we are using a Qt package.
Every build on CI is isolated so Qt is downloaded from Artifactory and is extracted from the package. It slows down build so much.
 wizardsd
on 2 Aug 2019
wizardsd
on 2 Aug 2019
It would be nice to provide an example of Jenkinsfile(s) for the following case: libraries A and B depends on library C, when new version of library C is built Jenkins somehow should consume dependency graph from Artifactory and rebuild all libraries that depend on C (with fresh version of library C).
wizardsd
on 2 Aug 2019
Hi. I updated one of the examples in the document with the Jenkinsfile I'm using in the core-messages project. This is a POC on how to use lockfiles to generate one single BuildInfo for many package configurations and publish it to Artifactory.
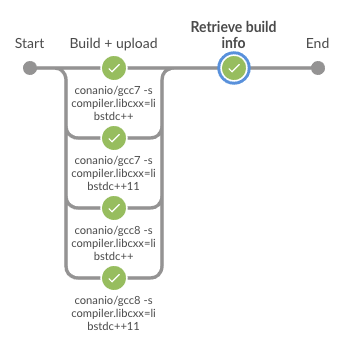
It is far from ideal as it requires the usage of external scripts, but it will serve as a POC of what we want to do and we will try to push it probably into the Artifactory-Jenkins plugin.
jgsogo
on 28 Aug 2019
About caching external dependencies.
Up to now, Conan can only work with a single cache, so it is not possible to persist some packages in the cache and forget about other ones. We are trying to relax this condition, to make a more flexible package layout so they can be relocatable, but it is not something planned for the near future.
The best I can imagine is to implement a post/finally stage where the packages created during the job are deleted from the cache, but not the external requirements. It will be fast and it will avoid downloading those dependencies again and again, but I'm not sure if it may have some collateral effect. Of course, the CONAN_USER_HOME must be set to a known persisted directory.
There's a huge problem with this approach: if using revisions, there can only be one revision in the cache at the same time ⚠️
I think this is something I can POC in one of my small projects 🚂 🚋 🚋 🚋
jgsogo
on 28 Aug 2019
About building dependencies of the modified library (ping @wizardsd)
It would be nice to provide an example of Jenkinsfile(s) for the following case: libraries A and B depends on library C, when new version of library C is built Jenkins somehow should consume dependency graph from Artifactory and rebuild all libraries that depend on C (with fresh version of library C).
Yes, sure, totally agree. We are working on the idea and the main objective of the C++ project I'm developing on the sword_and_sorcery is to provide examples of that kind of workflow. Just a little bit of patience 👍
jgsogo
on 28 Aug 2019
@KerstinKeller , you proposed a lot of things in your comment, I'll try to comment about them in order to make up my mind and see if I can provide an example...
Installing Conan Configurations:
This is something easy using conan config install <git repo>. I need to add this step to my Jenkinsfiles examples. Nevertheless I need this PR (https://github.com/jfrog/jenkins-artifactory-plugin/pull/179) to be merged in order to be able to authenticate to the remote using the Artifactory credentials.
Rebuilding for a new profile
When a new profile is introduced, usually a new docker image should be provided or new machines provisioned... but I think that it is always required some kind of change in the CI scripts... and if the CI script changes, then there is a commit in the repo and a job will be triggered. Introducing a new compiler would be as easy as modifying CI scripts to add the corresponding profile/node/machine and committing it.
Another approach I can think about is iterating all existing profiles and running nodes matching profile name:
def profile_list = ???? retrieve it from `conan config install ...` repository
profile_list.each { profile ->
node {
// profile matches a docker image
docker.image(profile).inside() {
...
conan.run(command: "create . <ref> --profile ${profile}")
}
}
}
This is quite interesting and maybe it is worth an example 🚂 🚋 🚋 🚋 . Right now I don't know how to create jobs dynamically, but it should be possible.
Comparing local vs published recipes
To guarantee that the package to generate is the same as one already in the remote you should use full_version_mode for package_id (it will compute a different ID for any change in the dependencies) and trust your environment. You can't rely on the package revision as it is computed as hash of the binaries and it is really hard (impossible?) to get full binary reproducibility in C++ (we are doing some research on it: https://github.com/conan-io/conan-io.github.io/pull/84).
Without building the package, the _package ID_ can be computed using conan info <cnanfile.py> [--profile] and then you can query your server to know if it is available.
Creating but not publishing recipes
I think this is just a matter of not running conan upload if the user/channel matches some pattern. Am I missing something?
About your last question, I think that the CI always needs to use conan create for the library being modified (it is cloning the repo and using the versioned conanfile.py). Also, conan create tests that the generated package is a valid Conan package (if there are tests in the test_package folder)
conan install <ref> --build will just retrieve the conanfile.py from the server (it is not using the one in the cloned repository).
jgsogo
on 28 Aug 2019
To chime in, we've been using conan+Jenkins+Artifactory for about two years without using the Jenkins-Artifactory plugin (we do use it, but not for conan). Basically, we are simply invoking conan from the command line. The remote configurations and profiles are fetched by a custom script (which predates conan config). Overall, I'm a bit confused about the utility of a more fleshed out conan plugin. What makes it better compared to simply calling conan?
 sztomi
on 29 Aug 2019
sztomi
on 29 Aug 2019
What makes it better compared to simply calling conan?
For our use case:
- The plugin captures environment variables and buildinfo and uploads them to artifactory
- The plugin does authentication using Jenkins credentials, so no need to hard code them in the pipeline. I think this would be achievable without the plugin though.
 tmwa
on 29 Aug 2019
tmwa
on 29 Aug 2019
About caching external dependencies.
The best I can imagine is to implement a
post/finallystage where the packages created during the job are deleted from the cache, but not the external requirements. It will be fast and it will avoid downloading those dependencies again and again, but I'm not sure if it may have some collateral effect. Of course, theCONAN_USER_HOMEmust be set to a known persisted directory.
I'm using almost the same implementation. For every build I'm creating a new conan home and conan cache directories, but at some point before conan create I create symlinks from current conan cache to the stable conan cache. When build finishes, I'm just removing both conan directories but not stable cache directory.
There could be a problem with populating stable cache by parallel builds, but I'm not sure.
wizardsd
on 29 Aug 2019
Yes, @wizardsd , parallel builds might be a problem and also take into account (if you are using revisions) that Conan cache stores only one revision at a time. You will have a problem if you try to consume different revisions of the same recipe/package from two jobs at the same time.
jgsogo
on 30 Aug 2019
I think that the CI always needs to use conan create for the library being modified (it is cloning the repo and using the versioned conanfile.py).
Our CI has built in support for checking out sources. This shows us what changes went into the build, and it's not a feature we're keen to drop. Therefore we _don't_ use conan create but instead use conan install, conan build and conan export-pkg.
 mplatings
on 22 Oct 2019
mplatings
on 22 Oct 2019
Hi. I updated one of the examples in the document with the
JenkinsfileI'm using in thecore-messagesproject. This is a POC on how to uselockfilesto generate one single BuildInfo for many package configurations and publish it to Artifactory.[...]
It is far from ideal as it requires the usage of external scripts, but it will serve as a POC of what we want to do and we will try to push it probably into the Artifactory-Jenkins plugin.
Collecting a BuildInfo over multiple stages and nodes is something we also need here. As written here we use a global BuildInfo instance and append the info generated by each Conan command execution to it which is then published to the Artifactory in a dedicated stage at the end of the build.
Its not elegant and i guess many others will also stumble over this so it would be good to improve here.
Unfortunately the Artifactory does not link the respective Artifacts listed in a "Build" to the actual Artifacts in the Conan repository though the filenames and checksums shown in the Build Info JSON are correct. For regular files (e.g. .zip) uploaded to generic Artifactory repos this works as expected though. Did i miss something there or is this a known issues for Conan packages?
 petermbauer
on 23 Oct 2019
petermbauer
on 23 Oct 2019
@mplatings, using conan create is a recommendation that should work for most cases, but custom CIs could perform custom steps. If you feel like we are going to break your workflow with any incoming change, let us know asap so we can reconsider the feature/fix/refactor and think twice before implementing it.
@petermbauer I've experimented an similar issue: Artifactory generates the links from the packages to the build-info, but no the other way around. @czoido reported today that he was getting the proper links, maybe he can confirm and he knows what are we missing with our build-info.
jgsogo
on 23 Oct 2019
@jgsogo thanks a lot for caring, would be great to have this solved. The links from the packages to the Build also worked here but since the last update of our Artifactory (incl. revision support) those links are gone too.
Update: you are right, i found that the links from the individual files of a package (e.g. conan_package.tgz) to the respective build are there so Artifactory correctly associates them but still there is no link available from the build to the files (No path found (externally resolved or deleted/overwritten)).
Update: Fix should be available with Artifactory plugin 3.5.0, (see jfrog/jenkins-artifactory-plugin#222 and https://www.jfrog.com/jira/browse/HAP-1265)
petermbauer
on 23 Oct 2019
I came across another use-case which is mainly relevant for CI but also for local development.
For doing "non-standard" builds like generating documentation output or running a static code analysis people usually create optional build targets in the used build system, e.g. CMake.
As there is most probably no need to include the generated files in the Conan packages, the build needs to be done with "conan install+build" in the userspace to be able to access them. To avoid having to call the underlying build system directly in the CI builds, it would be best to pass the actual build target via conan build to the build() method, similar to the --configure flags and the respective attributes.
This would avoid having to add dedicated options for all these "non-standard" builds in the conanfile.py which are not used for package creation anyway.
petermbauer
on 19 Dec 2019
Related issues
 mpdelbuono
·
3Comments
mpdelbuono
·
3Comments
 uilianries
·
3Comments
uilianries
·
3Comments
 niosHD
·
3Comments
niosHD
·
3Comments
 rconde01
·
3Comments
rconde01
·
3Comments
 Adnn
·
3Comments
Adnn
·
3Comments
Most helpful comment
For our use case: