Common-voice: Too many recordings per user?
Recently a change was made to the validation section to list sentences with the fewest recordings first in order to add more unique sentences for the DeepSpeech model. This has made me more aware of something that could potentially be an issue.
Some users are recording a LOT of sentences. In fact, over the past few days I have validated around 1500-2000 clips and I would estimate around 70% of them were recorded by the same user, all of which were unique sentences.
I’m sure that the DeepSpeech team makes certain that there aren’t too many recordings by a single user, so these sentences will most likely be discarded until there are more recordings available. But if the site shows sentences with the fewest recordings first, it will have to go through the thousands of unrecorded sentences to get to that point again, which may never happen if more sentences keep getting added. And if the validation site shows unique sentences first, it will take even longer to get the new sentence approved.
The DeepSpeech team said they don’t want more than a few hundred recordings from any one user. So a user with 5000 recordings may have prevented 4700 sentences from making it into the model.
So I think the solution to this is either:
Put a hard limit on the total number of recordings users can make or have a daily per-user limit.
Change the algorithm so that each sentence has, say, 3 recordings minimum before it’s given a lower priority in the record queue.
Deprioritize recordings in the validation queue by users who have x number of validated recordings. So we’re prioritizing unique users AND unique sentences.
 dabinat
dabinat
All 11 comments
I agree that there are a variety of problems here. Some more information from the team would be helpful to aid our discussions. What is the DeepSpeech team actually doing with the contributions of users who have made large numbers of recordings? Using them will bias the corpus; not using them results in a lot of volunteer time being wasted. Better guidelines to volunteers as to what is needed and what is not would help considerably.
On the question of unique sentences, it's still not clear to me which recordings are used. If a sentence is recorded three times, once in Indian English, once in American English, and once in British English, what happens? Choosing the first recording, or a recording at random, will tend to exclude those who have lower representation within the volunteers. It will particularly tend to perpetuate the low number of female voices.
 MichaelNMaggs
on 2 Apr 2019
MichaelNMaggs
on 2 Apr 2019
@dabinat I'm not sure I understand your statement of the problem. Let me start here...
- You state "...so these sentences will most likely be discarded until there are more recordings available..." what do you mean by "discarded"? I'm not sure your definition reflects what is actually occurring.
- You state "...But if the site shows sentences with the fewest recordings first, it will have to go through the thousands of unrecorded sentences to get to that point again..." What do you mean by "that point again"?
- You state "...And if the validation site shows unique sentences first, it will take even longer to get the new sentence approved." What do you mean by "unique"? I don't think you mean unique. All the sentences are unique.
There are many other question I have about your issue, but lets start there.
 kdavis-mozilla
on 3 Apr 2019
kdavis-mozilla
on 3 Apr 2019
Ok, I’ll try to explain it another way.
The recording view displays sentences with the fewest recordings first. So it will always prioritize sentences with 0 recordings first.
Let’s say I record a sentence that has no prior recordings and my recording gets approved by validators. The number of recordings for that sentence is now 1.
This is the 2000th recording I have made (we’ll assume all 2000 were approved). Obviously you’re not going to use all 2000 recordings because that would bias the model too much, so some of my recordings would not be used to train the model.
But some of those clips that are unused are the only recording of that particular sentence, so that sentence doesn’t get coverage in the model.
That’s ok - we’ll just wait for someone else to record it and use their recording instead. But the recording view prioritizes sentences with 0 recordings first and that sentence has 1 recording. So in order for it to appear again, all unrecorded sentences would need to be recorded so that there are no more sentences with 0 recordings.
English has over 30,000 sentences with more being added all the time so the chances of unrecorded sentences ever being reduced to zero seems pretty slim. So therefore that sentence will never appear again and will never get recorded again, so recordings of that sentence will never make it into the model.
This may seem hypothetical but there are people with over 15,000 recordings and I often hear the same one or two voices again and again when I validate. So my question is: are people with thousands of recordings doing more harm than good?
(Also, even if they’re not actively doing harm, they’re probably wasting their own time and the time of validators. While there may be some uses for this outside of DeepSpeech it seems like it’s not the most optimal use of volunteer time.)
dabinat
on 4 Apr 2019
Some of your assumptions are not true.
For example...
...Obviously you’re not going to use all 2000 recordings...
Is not necessarily true. This depends on the how many other people have read sentences you've read. Some of your validated recordings _may_ not be put in the train.tsv, but all will be put in validated.tsv set. Anyone is free to use the validated.tsv to train on.
But some of those clips that are unused are the only recording of that particular sentence, so that sentence doesn’t get coverage in the model.
This is also incorrect.
I think to not take too much time explaining all the details, it'd be best if you took a look at the code that actually creates the various data splits corpus.py then come back with specific questions about that code.
kdavis-mozilla
on 4 Apr 2019
If my understanding of the code is correct, it sorts by total user recordings ascending and then filters out duplicates, meaning that in the case of more than one recording of a sentence it will favor the user with the fewest total recordings.
It then sorts again, this time in descending order. I’m not really sure what the purpose of sorting again is. Maybe to make sure users with more recordings go to test/dev instead of train?
But then it loops through each individual user and makes sure their recordings that haven’t already been filtered out fit in the test/dev sets, otherwise they end up in train.
So it seems like I could make thousands and thousands of recordings and as long as the sentences had no other recordings, all of them would end up in train?
dabinat
on 4 Apr 2019
Maybe to make sure users with more recordings go to test/dev instead of train?
Basically, yes. Worded in another way, this sort is made to have users with fewer recordings in the test set.
For smaller data sets which don't have enough data to train a robust STT engine the maximal utility of the data set can be obtained by having a diverse test set, as the test set can become a standard used in research and industry. This is accomplished by having the test set contain a more diverse set of users which is accomplished by this sort.
So it seems like I could make thousands and thousands of recordings and as long as the sentences had no other recordings, all of them would end up in train?
Yes.
kdavis-mozilla
on 5 Apr 2019
So should users create thousands of recordings or just say 300 per language and focus on verification then?
If so, the leader board makes no sense since it encourages users to create more recordings.
Please communicate what helps most to reach our goal (get robust STT ASAP) on the website and build a workflow to encourage that.
 davidak
on 8 Jun 2019
davidak
on 8 Jun 2019
@kdavis-mozilla any update here? are we going in the right direction?
davidak
on 17 Jul 2020
So should users create thousands of recordings or just say 300 per language and focus on verification then?
Thousands of recordings will be useful for the train data set. Similarly, 300 per language + validation is also useful.
Both are useful, and I don't think there is one "most useful" path other than to contribute the the languages you want to support!
kdavis-mozilla
on 21 Jul 2020
@kdavis-mozilla thanks. that's a clear statement.
since 1 recording needs at least 2 verifications, it makes sense to make the goals accordingly in the web ui.
the daily goal in the statistic already reflects that
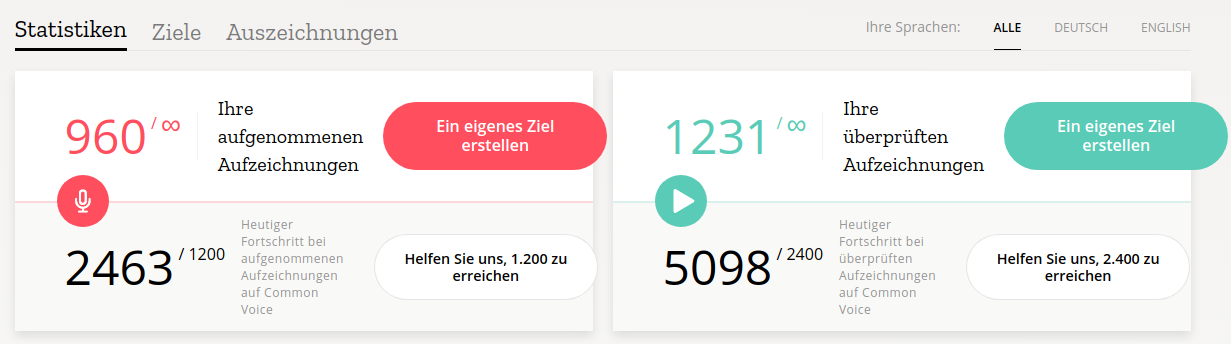
and we might want to communicate it as a common goal and it is fine if someone only records or verifies.
or we also apply it to the personal goal and achievements
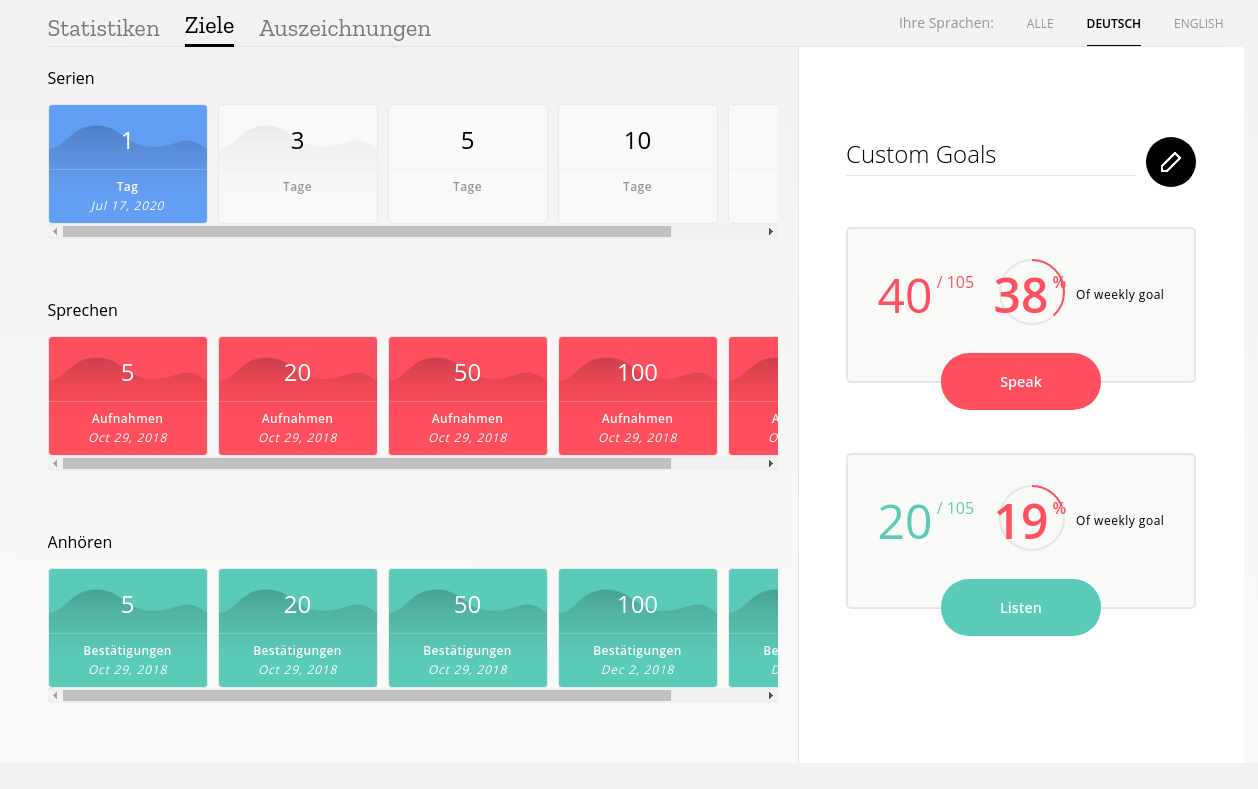
davidak
on 21 Jul 2020
Yeah I agree
kdavis-mozilla
on 21 Jul 2020
Related issues
 mbransn
·
5Comments
mbransn
·
5Comments
 mikehenrty
·
3Comments
mikehenrty
·
3Comments
 r00ster91
·
4Comments
r00ster91
·
4Comments
 psubhashish
·
5Comments
psubhashish
·
5Comments
 kenrick95
·
4Comments
kenrick95
·
4Comments