Cockroach: storage: MVCCStats divergence
Run the following script (tested at master @ 7ccc197b2751098c9945d6b46da6238ae5a195a4)
#!/bin/bash
set -euxo pipefail
export COCKROACH_FATAL_ON_STATS_MISMATCH=true
killall -9 cockroach || true
killall -9 workload || true
sleep 1
rm -rf cockroach-data || true
mkdir -p cockroach-data
./cockroach start --insecure --host=localhost --port=26257 --http-port=26258 --store=cockroach-data/1 --cache=256MiB --background
./cockroach start --insecure --host=localhost --port=26259 --http-port=26260 --store=cockroach-data/2 --cache=256MiB --join=localhost:26257 --background
./cockroach start --insecure --host=localhost --port=26261 --http-port=26262 --store=cockroach-data/3 --cache=256MiB --join=localhost:26257 --background
sleep 5
./cockroach sql --insecure -e 'alter range default configure zone using range_max_bytes = 1048471142400;'
for i in $(seq 0 5); do
./bin/workload run kv --cycle-length 100 --concurrency 4 --init --max-rate 10 --max-ops 1000 --min-block-bytes $((1024)) --max-block-bytes $((1 << 20)) --sequential &
done
tail -Fq cockroach-data/*/logs/cockroach.log
(if it doesn't repro within ~2min, run it again - this happens every other time at the time of writing).
A repro is a node crashing with a stack trace like this:
F181025 11:58:07.035045 2143 storage/replica_consistency.go:119 [n1,consistencyChecker,s1,r21/1:/{Table/58-Max}] found a delta of {false 0 0 251916452 33177250 0 1128 0 71487294 94 0 0 0 0}
goroutine 2143 [running]:
github.com/cockroachdb/cockroach/pkg/util/log.getStacks(0xc0000c4601, 0xc0000c46c0, 0x835e100, 0x1e)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/log/clog.go:997 +0xd4
github.com/cockroachdb/cockroach/pkg/util/log.(*loggingT).outputLogEntry(0x8a99f60, 0xc000000004, 0x835e152, 0x1e, 0x77, 0xc00d13a200, 0x7d)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/log/clog.go:866 +0x8e8
github.com/cockroachdb/cockroach/pkg/util/log.addStructured(0x6e5f6c0, 0xc0095c6000, 0x4, 0x2, 0x675e62c, 0x14, 0xc009bf59e0, 0x1, 0x1)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/log/structured.go:85 +0x2d5
github.com/cockroachdb/cockroach/pkg/util/log.logDepth(0x6e5f6c0, 0xc0095c6000, 0x1, 0x4, 0x675e62c, 0x14, 0xc009bf59e0, 0x1, 0x1)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/log/log.go:69 +0x8c
github.com/cockroachdb/cockroach/pkg/util/log.Fatalf(0x6e5f6c0, 0xc0095c6000, 0x675e62c, 0x14, 0xc009bf59e0, 0x1, 0x1)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/log/log.go:172 +0x7e
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).CheckConsistency(0xc00cfd2e00, 0x6e5f6c0, 0xc0095c6000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica_consistency.go:119 +0x6e6
github.com/cockroachdb/cockroach/pkg/storage.(*consistencyQueue).process(0xc0003382e0, 0x6e5f6c0, 0xc0095c6000, 0xc00cfd2e00, 0x0, 0x0, 0x100000001)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/consistency_queue.go:117 +0x1d0
github.com/cockroachdb/cockroach/pkg/storage.(*baseQueue).processReplica(0xc00074e800, 0x6e5f700, 0xc00cb1c000, 0xc00cfd2e00, 0x0, 0x0)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/queue.go:747 +0x339
github.com/cockroachdb/cockroach/pkg/storage.(*baseQueue).processLoop.func1.2(0x6e5f700, 0xc00cb1c000)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/queue.go:626 +0xb8
github.com/cockroachdb/cockroach/pkg/util/stop.(*Stopper).RunAsyncTask.func1(0xc0001d8bd0, 0x6e5f700, 0xc00cb1c000, 0xc00e534040, 0x36, 0x0, 0x0, 0xc000338060)
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/stop/stopper.go:324 +0xe6
created by github.com/cockroachdb/cockroach/pkg/util/stop.(*Stopper).RunAsyncTask
/Users/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/stop/stopper.go:319 +0x134
 tbg
tbg
All 5 comments
https://github.com/cockroachdb/cockroach/issues/37815#issuecomment-545650087 has the updated script (it's just replacing the env var).
tbg
on 28 Oct 2019
As you'd expect from the kind of failure, the replication isn't necessary, so the second and third ./cockroach start invocation can simply be removed.
tbg
on 28 Oct 2019
I tried to reduce a bit further, but it really seems that it does need at least two overlapping kv instances; I haven't gotten the crash once with just one, despite "scaling" the other parameters to fit. And when I point the clients at different db names, I also don't get the crash.
On the other hand, giving them different seeds and a long cycle len does reproduce the crash, even though naively I would think that that'd lead to no overlap between the two (except hitting the same range):
./bin/workload run kv --cycle-length 100000 --seed $i --concurrency 4 --init --max-rate 10 --min-block-bytes $((1024)) --max-block-bytes $((1 << 20)) --sequential &
I went ahead and tried with this patch
diff --git a/pkg/storage/replica_raft.go b/pkg/storage/replica_raft.go
index 2cf8b3af2e..395420f0b8 100644
--- a/pkg/storage/replica_raft.go
+++ b/pkg/storage/replica_raft.go
@@ -14,6 +14,8 @@ import (
"context"
"fmt"
"math/rand"
+ "os"
+ "path/filepath"
"sort"
"time"
@@ -769,7 +771,10 @@ func (r *Replica) handleRaftReadyRaftMuLocked(
default:
return stats, err.(*nonDeterministicFailure).safeExpl, err
}
-
+ if err := r.store.engine.CreateCheckpoint(filepath.Join(r.store.engine.GetAuxiliaryDir(), fmt.Sprintf("r%d.%d", r.RangeID, rd.CommittedEntries[len(rd.CommittedEntries)-1].Index))); err != nil {
+ log.Error(ctx, err)
+ os.Exit(1)
+ }
// etcd raft occasionally adds a nil entry (our own commands are never
// empty). This happens in two situations: When a new leader is elected, and
// when a config change is dropped due to the "one at a time" rule. In both
which helpfully reproduced immediately. Bisecting on the resulting dirs, I have a good one (applied log index 133) and a bad one (log index 135).
The offending command is thus 134 or 135. ./cockroach debug raft-log r25.135 25 shows
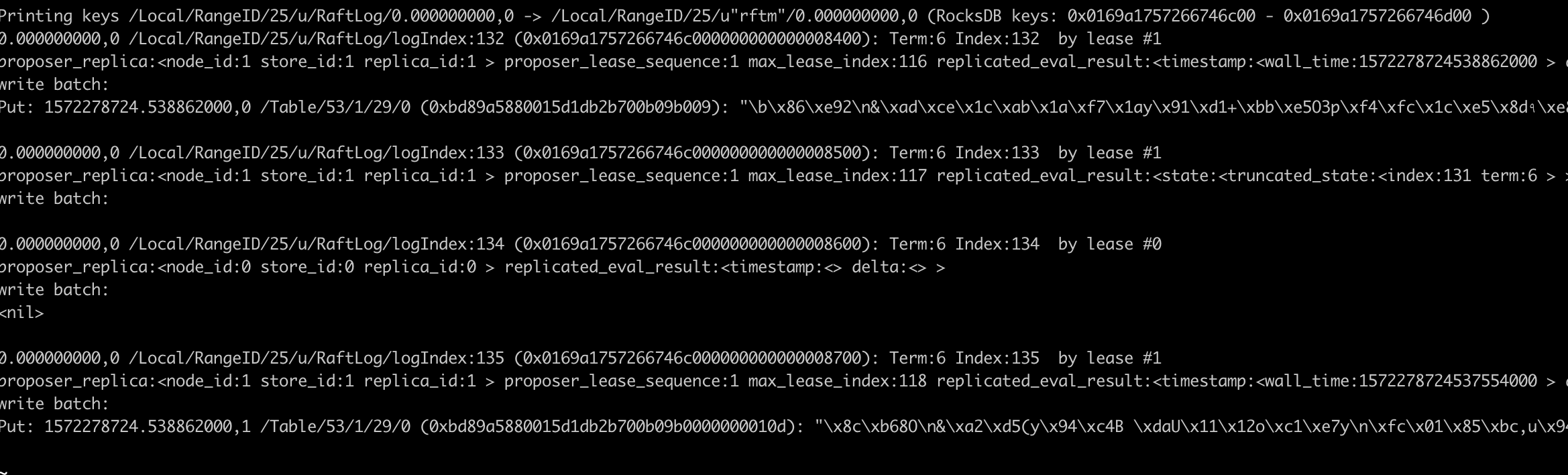
The offending command introduces this delta:
delta:<last_update_nanos:1572278724538862000 live_bytes:-358632 key_bytes:24 val_bytes:1135970 val_count:2
while check-store on the 135 dir shows
LiveBytes: 24143612 != 24322928,KeyBytes: 882 != 870,ValBytes: 37124763 != 36556778,ValCount: 61 != 60
This makes sense: val_count:2 in the delta is weird since we're doing only one put (= touching one MVCC version), how can that change two values at once? Taking the deltas in the divergence shows
delta(stored, recomputed) = live:-179316, keybytes=12, valbytes=567985, valcount=1
This means that the delta for the command should've really been exactly half of what it ended up being. I'm super puzzled how this could come to be, and also what the bug could be.
@irfansharif I'm going to leave the thunder for you, hope this shaved some trial and error from it. My final script is
cat s.sh
#!/bin/bash
set -euxo pipefail
export COCKROACH_ENFORCE_CONSISTENT_STATS=true
killall -9 cockroach || true
killall -9 workload || true
sleep 1
rm -rf cockroach-data || true
mkdir -p cockroach-data
./cockroach start --insecure --host=localhost --port=26257 --http-port=26258 --store=cockroach-data/1 --cache=256MiB --background
sleep 5
./cockroach sql --insecure -e 'alter range default configure zone using range_max_bytes = 1048471142400;'
for i in $(seq 0 1); do
./bin/workload run kv --cycle-length 100000 --seed $i --concurrency 4 --init --max-rate 10 --min-block-bytes $((1024)) --max-block-bytes $((1 << 20)) --sequential &
done
tail -Fq cockroach-data/*/logs/cockroach.log
Heh, you weren't kidding about being excited about this bug.
 irfansharif
on 28 Oct 2019
irfansharif
on 28 Oct 2019
Heh, you weren't kidding about being excited about this bug.
Yep, slightly obsessed... I just had a few spare cycles and continued pulling. Here's the diff that fixes it:
diff --git a/pkg/storage/replica_write.go b/pkg/storage/replica_write.go
index 9ce99772ee..edcc56f4cd 100644
--- a/pkg/storage/replica_write.go
+++ b/pkg/storage/replica_write.go
@@ -362,6 +362,7 @@ func (r *Replica) evaluateWriteBatchWithLocalRetries(
spans *spanset.SpanSet,
canRetry bool,
) (batch engine.Batch, br *roachpb.BatchResponse, res result.Result, pErr *roachpb.Error) {
+ goldenMS := *ms
for retries := 0; ; retries++ {
if batch != nil {
batch.Close()
@@ -417,6 +418,7 @@ func (r *Replica) evaluateWriteBatchWithLocalRetries(
break
}
ba.Timestamp = wtoErr.ActualTimestamp
+ *ms = goldenMS
continue
}
if opLogger != nil {
We have this internal retry that evaluates the batch again on WriteTooOld. It discards the batch, but doesn't reset the MVCCStats, so that we'd end up with a single evaluation accounted for twice, oops.
I found this by adding this diff (with the fatal uncommented)
index 99498ecd33..13d1e8b8eb 100644
--- a/pkg/storage/replica_evaluate.go
+++ b/pkg/storage/replica_evaluate.go
@@ -367,6 +367,14 @@ func evaluateBatch(
// which the batch executed.
br.Timestamp.Forward(baHeader.Timestamp)
+ if len(ba.Requests) == 1 && ba.Requests[0].GetPut() != nil && ms.ValCount == 2 {
+ put := ba.Requests[0].GetPut()
+ put.Value = roachpb.Value{}
+ pErr := roachpb.NewError(errors.Errorf("%+v in %+v", ms, put))
+ //log.Fatal(ctx, pErr)
+ return nil, result, pErr
+ }
+
return br, result, nil
}
and observing that no error would be returned from the workload if I commented out the fatal, but miraculously the problem would also go away. That made me think that there's likely some local retry (I was thinking 1PC commit at the time, which turned it is really what swallows the error returned here). Going through the call hierarchy, I quickly found the problem above. BTW, this retry is only possible in 1PC txns that don't have anything to refresh, which is why it's been rare in practice.
tbg
on 29 Oct 2019
Related issues
 lwsanty
·
4Comments
lwsanty
·
4Comments
 HeikoOnnebrink
·
4Comments
HeikoOnnebrink
·
4Comments
 xudongzheng
·
3Comments
xudongzheng
·
3Comments
 intech
·
3Comments
intech
·
3Comments
 petermattis
·
4Comments
petermattis
·
4Comments
Most helpful comment
Yep, slightly obsessed... I just had a few spare cycles and continued pulling. Here's the diff that fixes it:
We have this internal retry that evaluates the batch again on WriteTooOld. It discards the batch, but doesn't reset the MVCCStats, so that we'd end up with a single evaluation accounted for twice, oops.
I found this by adding this diff (with the fatal uncommented)
and observing that no error would be returned from the workload if I commented out the fatal, but miraculously the problem would also go away. That made me think that there's likely some local retry (I was thinking 1PC commit at the time, which turned it is really what swallows the error returned here). Going through the call hierarchy, I quickly found the problem above. BTW, this retry is only possible in 1PC txns that don't have anything to refresh, which is why it's been rare in practice.