Cockroach: teamcity: failed test: bank/node-restart
The following tests appear to have failed:
--- FAIL: roachtest/acceptance/bank/node-restart (32.231s)
test.go:503,bank.go:291,bank.go:398,acceptance.go:59: stall detected at round 1, no forward progress for 30s
--- FAIL: roachtest/acceptance/bank/node-restart (32.231s)
test.go:503,bank.go:291,bank.go:398,acceptance.go:59: stall detected at round 1, no forward progress for 30s
Please assign, take a look and update the issue accordingly.
 cockroach-teamcity
cockroach-teamcity
All 111 comments
https://github.com/cockroachdb/cockroach/issues/29678 also has a failure for this test, though a different failure mode.
 petermattis
on 12 Sep 2018
petermattis
on 12 Sep 2018
I'm unable to reproduce this failure locally. Seems to have happened several times on CI.
petermattis
on 12 Sep 2018
It's interesting that the stall occurs on round 1. Looks like the cluster never came up. The logs on the nodes don't show anything interesting:
I180911 14:27:07.082225 1 util/log/clog.go:1151 [config] file created at: 2018/09/11 14:27:07
I180911 14:27:07.082225 1 util/log/clog.go:1151 [config] running on machine: c688e08a1da4
I180911 14:27:07.082225 1 util/log/clog.go:1151 [config] binary: CockroachDB CCL v2.2.0-alpha.00000000-670-g83a7cb5 (x86_64-pc-linux-gnu, built 2018/09/11 14:25:15, go1.10.3)
I180911 14:27:07.082225 1 util/log/clog.go:1151 [config] arguments: [/home/roach/local/1/cockroach start --insecure --store=path=/home/roach/local/1/data --log-dir=/home/roach/local/1/logs --background --cache=6% --max-sql-memory=6% --port=26257 --http-port=26258 --locality=region=local,zone=local --host=127.0.0.1]
I180911 14:27:07.082225 1 util/log/clog.go:1151 line format: [IWEF]yymmdd hh:mm:ss.uuuuuu goid file:line msg utf8=✓
Here's something odd. The test indicated that it started the cluster, then stopped node 3 and restarted it. Yet I see 2 log files on nodes 1, 2 and 4 while I only expect to see 1. Simple manual test of this scenario shows only 1 log produced on the nodes that were started once.
Oh, it looks like one of the log files is from the invocation of cockroach with the --background flag. That doesn't seem to reproduce on Mac OS X. Perhaps a Linux specific bug. Unlikely to be the cause of the stall.
petermattis
on 12 Sep 2018
While investigating another acceptance failure, I reproduced the problem seen in the original message:
--- FAIL: acceptance/bank/node-restart (47.53s)
test.go:503,bank.go:291,bank.go:402,acceptance.go:60: stall detected at round 6, no forward progress for 30s
> /usr/local/bin/roachprod destroy local
local: stopping
local: wipingclient 1 shutting down
Unfortunately, I didn't specify the --debug flag so the cluster was wiped. The reproduction occurred on a 24-CPU GCE worker machine running roachtest -l --count=100 acceptance/bank.
petermattis
on 25 Sep 2018
Starting to repro this too.
--- FAIL: acceptance/bank/node-restart (32.14s)
test.go:503,bank.go:291,bank.go:402,acceptance.go:60: stall detected at round 1, no forward progress for 30s
Don't think a single write to the DB has happened (the db is running happily and has a fresh accounts table). Going to add some stack traces and retry.
 tbg
on 27 Sep 2018
tbg
on 27 Sep 2018
Hmm, looking at a stuck run in round 18.
The cluster is happy, and the accounts table has only zeroes as well. Wouldn't be surprised if the test is doing something silly.
tbg
on 27 Sep 2018
I CTRL+C'ed a test and can't sure whether this is why that happened, but I got stuck with this stack trace:
oroutine 59 [IO wait, 1 minutes]:
internal/poll.runtime_pollWait(0x7fc2683adc90, 0x77, 0xc42062eea0)
/usr/local/go/src/runtime/netpoll.go:173 +0x57
internal/poll.(*pollDesc).wait(0xc42068d518, 0x77, 0xc42062ee00, 0xc42062eef0, 0xc42062ee01)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:85 +0x9b
internal/poll.(*pollDesc).waitWrite(0xc42068d518, 0xc42068d500, 0x0, 0x0)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:94 +0x3d
internal/poll.(*FD).WaitWrite(0xc42068d500, 0xc420042070, 0xc420042070)
/usr/local/go/src/internal/poll/fd_unix.go:440 +0x37
net.(*netFD).connect(0xc42068d500, 0x1b95b80, 0xc420042070, 0x0, 0x0, 0x1b7f8c0, 0xc4202f7880, 0x0, 0x0, 0x0, ...)
/usr/local/go/src/net/fd_unix.go:152 +0x299
net.(*netFD).dial(0xc42068d500, 0x1b95b80, 0xc420042070, 0x1b9d080, 0x0, 0x1b9d080, 0xc4206b8270, 0xc42062f0f0, 0x75d83e)
/usr/local/go/src/net/sock_posix.go:142 +0xe9
net.socket(0x1b95b80, 0xc420042070, 0x19adb98, 0x3, 0x2, 0x1, 0x0, 0x0, 0x1b9d080, 0x0, ...)
/usr/local/go/src/net/sock_posix.go:93 +0x1a6
net.internetSocket(0x1b95b80, 0xc420042070, 0x19adb98, 0x3, 0x1b9d080, 0x0, 0x1b9d080, 0xc4206b8270, 0x1, 0x0, ...)
/usr/local/go/src/net/ipsock_posix.go:141 +0x129
net.doDialTCP(0x1b95b80, 0xc420042070, 0x19adb98, 0x3, 0x0, 0xc4206b8270, 0x0, 0x0, 0x0)
/usr/local/go/src/net/tcpsock_posix.go:62 +0xb9
net.dialTCP(0x1b95b80, 0xc420042070, 0x19adb98, 0x3, 0x0, 0xc4206b8270, 0x1d6c7b5dbbd31, 0x2008ed4, 0x2008ed401b95b80)
/usr/local/go/src/net/tcpsock_posix.go:58 +0xe4
net.dialSingle(0x1b95b80, 0xc420042070, 0xc42068d480, 0x1b83ec0, 0xc4206b8270, 0x0, 0x0, 0x0, 0x0)
/usr/local/go/src/net/dial.go:547 +0x375
net.dialSerial(0x1b95b80, 0xc420042070, 0xc42068d480, 0xc4202bc360, 0x1, 0x1, 0x0, 0x0, 0x0, 0x0)
/usr/local/go/src/net/dial.go:515 +0x22d
net.(*Dialer).DialContext(0xc42062f630, 0x1b95b80, 0xc420042070, 0x19adb98, 0x3, 0xc4202e8940, 0xf, 0x0, 0x0, 0x0, ...)
/usr/local/go/src/net/dial.go:397 +0x678
net.(*Dialer).Dial(0xc42062f630, 0x19adb98, 0x3, 0xc4202e8940, 0xf, 0x5ff7a7, 0x0, 0xc42062f660, 0x3)
/usr/local/go/src/net/dial.go:320 +0x75
net.Dial(0x19adb98, 0x3, 0xc4202e8940, 0xf, 0xbeb668, 0x5c5920, 0x19bd16a, 0x19bd197)
/usr/local/go/src/net/dial.go:291 +0x99
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.defaultDialer.Dial(0x19adb98, 0x3, 0xc4202e8940, 0xf, 0x182d8c0, 0xc4206247e0, 0xc420624838, 0x10)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:95 +0x49
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.dial(0x1b85040, 0x28808a8, 0xc4206b8150, 0x0, 0xc4206248a8, 0x1, 0x2)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:379 +0x35e
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.DialOpen(0x1b85040, 0x28808a8, 0xc4204ca1c1, 0x2f, 0x0, 0x0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:338 +0x553
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.Open(0xc4204ca1c1, 0x2f, 0xc42062fa60, 0x5fc165, 0xc420827500, 0xc420646000)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:251 +0x4d
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.(*Driver).Open(0x28808a8, 0xc4204ca1c1, 0x2f, 0x9325bd, 0xc40000003a, 0xc4206b80c0, 0x86)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:45 +0x35
database/sql.dsnConnector.Connect(0xc4204ca1c1, 0x2f, 0x1b7e8a0, 0x28808a8, 0x1b95b80, 0xc420042070, 0x0, 0x0, 0xc420545f00, 0x7fc268400000)
/usr/local/go/src/database/sql/sql.go:600 +0x45
database/sql.(*DB).conn(0xc4204ba8c0, 0x1b95b80, 0xc420042070, 0xc42062fd01, 0x94595c, 0xc4204bb540, 0xc4206246c0)
/usr/local/go/src/database/sql/sql.go:1103 +0x131
database/sql.(*DB).exec(0xc4204ba8c0, 0x1b95b80, 0xc420042070, 0x1a1cf11, 0xb5, 0xc42062fee8, 0x3, 0x3, 0x4db34b9682630c01, 0xc42062fdb8, ...)
/usr/local/go/src/database/sql/sql.go:1367 +0x66
database/sql.(*DB).ExecContext(0xc4204ba8c0, 0x1b95b80, 0xc420042070, 0x1a1cf11, 0xb5, 0xc42062fee8, 0x3, 0x3, 0x10, 0x1756f20, ...)
/usr/local/go/src/database/sql/sql.go:1349 +0xe1
database/sql.(*DB).Exec(0xc4204ba8c0, 0x1a1cf11, 0xb5, 0xc42062fee8, 0x3, 0x3, 0xc42062fed0, 0x6b3676, 0xbee34825c2005275, 0xb6362116)
/usr/local/go/src/database/sql/sql.go:1363 +0x85
main.(*bankClient).transferMoney(0xc420447950, 0x3e7, 0x3e7, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:63 +0x206
main.(*bankState).transferMoney(0xc42042cd70, 0x1b95b40, 0xc4204c2640, 0xc4205ee0c0, 0x1, 0x3e7, 0x3e7)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:152 +0xb6
created by main.runBankNodeRestart
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:390 +0x3af
Hrm, this test is a bit nonsensical, look at this query:
UPDATE bank.accounts
SET balance = CASE id WHEN $1 THEN balance-$3 WHEN $2 THEN balance+$3 END
WHERE id IN ($1, $2) AND (SELECT balance >= $3 FROM bank.accounts WHERE id = $1)
This is a noop if the withdrawal account $1 doesn't have an amount of $3 on it, but how would it? We never initialize any account with a nonzero value in this test.
tbg
on 27 Sep 2018
this test is a bit nonsensical
Did I cut&paste something incorrectly from the old acceptance test? Doesn't look like it.
petermattis
on 27 Sep 2018
Got the stall error too, on the first round. The cluster is healthy and happy to respond to queries.
=== RUN acceptance/bank/node-restart
> /home/tschottdorf/go/bin/roachprod wipe local
local: stopping
local: wiping
> /home/tschottdorf/go/bin/roachprod put local /home/tschottdorf/go/src/github.com/cockroachdb/cockroach/cockroach ./cockroach
local: putting /home/tschottdorf/go/src/github.com/cockroachdb/cockroach/cockroach ./cockroach
1: done
2: done
3: done
4: done
> /home/tschottdorf/go/bin/roachprod start local
local: starting
local: initializing cluster settings
SET CLUSTER SETTING
monkey starts (seed -3775595060315039375)
round 1: restarting nodes [2]
round 1: restarting 2
> /home/tschottdorf/go/bin/roachprod stop local:2
local: stopping
> /home/tschottdorf/go/bin/roachprod start local:2
local: starting
round 1: monkey sleeping while cluster recovers...
round 1: client counts: (0)
goroutine 31 [running]:
runtime/debug.Stack(0x6b3676, 0xbee34ddc05743323, 0x771c1682b)
/usr/local/go/src/runtime/debug/stack.go:24 +0xa7
runtime/debug.PrintStack()
/usr/local/go/src/runtime/debug/stack.go:16 +0x22
main.(*bankState).waitClientsStop(0xc42042c0f0, 0x1b95e00, 0xc42002a200, 0xc42038fe40, 0xc4208d20c0, 0x6fc23ac00)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:299 +0x76e
main.runBankNodeRestart(0x1b95e00, 0xc42002a200, 0xc42038fe40, 0xc4208d20c0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:418 +0x662
main.registerAcceptance.func1(0x1b95e00, 0xc42002a200, 0xc42038fe40, 0xc4208d20c0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/acceptance.go:60 +0x8e
main.(*registry).run.func2(0x1a758b0, 0xc42038fe40, 0xc420292780, 0xc4204e43e0, 0xc42000e098, 0x1b95e00, 0xc420661300, 0xc420823400)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/test.go:792 +0x458
created by main.(*registry).run
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/test.go:638 +0x2ed
round 1: not waiting for recovery due to signal that we're done
> /home/tschottdorf/go/bin/roachprod get local logs artifacts/acceptance/bank/node-restart/logs
local: getting logs artifacts/acceptance/bank/node-restart/logs
1: done
2: done
3: done
4: done
--- FAIL: acceptance/bank/node-restart (32.18s)
test.go:503,bank.go:300,bank.go:418,acceptance.go:60: stall detected at round 1, no forward progress for 30s
Did I cut&paste something incorrectly from the old acceptance test? Doesn't look like it.
Might've been nonsensical for a long time. We just need to initialize with, say, 100, instead of a zero balance and it'll actually do something. But first let's deflake it...
tbg
on 27 Sep 2018
The "stall detected" message comes with this goroutine stack (the other goroutines are doing harmless stuff):
goroutine 47 [IO wait]:
internal/poll.runtime_pollWait(0x7f7105916bc0, 0x72, 0xc420233388)
/usr/local/go/src/runtime/netpoll.go:173 +0x57
internal/poll.(*pollDesc).wait(0xc4205d4d18, 0x72, 0xffffffffffffff00, 0x1b81060, 0x2607d20)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:85 +0x9b
internal/poll.(*pollDesc).waitRead(0xc4205d4d18, 0xc420575000, 0x1000, 0x1000)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:90 +0x3d
internal/poll.(*FD).Read(0xc4205d4d00, 0xc420575000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/go/src/internal/poll/fd_unix.go:157 +0x17d
net.(*netFD).Read(0xc4205d4d00, 0xc420575000, 0x1000, 0x1000, 0xc42005e570, 0xc42005e500, 0xc4208ca098)
/usr/local/go/src/net/fd_unix.go:202 +0x4f
net.(*conn).Read(0xc42033e008, 0xc420575000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/go/src/net/net.go:176 +0x6a
bufio.(*Reader).Read(0xc4202c2180, 0xc4201302e0, 0x5, 0x200, 0x50, 0x0, 0x0)
/usr/local/go/src/bufio/bufio.go:216 +0x238
io.ReadAtLeast(0x1b7c2c0, 0xc4202c2180, 0xc4201302e0, 0x5, 0x200, 0x5, 0x8, 0x18, 0xc4202943e0)
/usr/local/go/src/io/io.go:309 +0x86
io.ReadFull(0x1b7c2c0, 0xc4202c2180, 0xc4201302e0, 0x5, 0x200, 0x1ff, 0x50, 0xc420233620)
/usr/local/go/src/io/io.go:327 +0x58
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.(*conn).recvMessage(0xc4201302c0, 0xc4202943e0, 0x1ff, 0x50, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:947 +0xfe
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.(*conn).recv(0xc4201302c0, 0xc420233768, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:977 +0x7c
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.(*conn).startup(0xc4201302c0, 0xc4204c25d0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:1099 +0x962
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.DialOpen(0x1b85400, 0x28808a8, 0xc42043c3c1, 0x2f, 0x0, 0x0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:344 +0x646
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.Open(0xc42043c3c1, 0x2f, 0x0, 0x0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:251 +0x4d
github.com/cockroachdb/cockroach/vendor/github.com/lib/pq.(*Driver).Open(0x28808a8, 0xc42043c3c1, 0x2f, 0x0, 0x0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/lib/pq/conn.go:45 +0x35
database/sql.dsnConnector.Connect(0xc42043c3c1, 0x2f, 0x1b7ec60, 0x28808a8, 0x1b95f40, 0xc420042070, 0x0, 0x0, 0x0, 0x0)
/usr/local/go/src/database/sql/sql.go:600 +0x45
database/sql.(*DB).conn(0xc4203d8820, 0x1b95f40, 0xc420042070, 0x1, 0x0, 0x0, 0x0)
/usr/local/go/src/database/sql/sql.go:1103 +0x131
database/sql.(*DB).exec(0xc4203d8820, 0x1b95f40, 0xc420042070, 0x1a1d299, 0xb5, 0xc420233ee8, 0x3, 0x3, 0x7f7105974f01, 0xc42047d505, ...)
/usr/local/go/src/database/sql/sql.go:1367 +0x66
database/sql.(*DB).ExecContext(0xc4203d8820, 0x1b95f40, 0xc420042070, 0x1a1d299, 0xb5, 0xc420233ee8, 0x3, 0x3, 0x10, 0x17572a0, ...)
/usr/local/go/src/database/sql/sql.go:1349 +0xe1
database/sql.(*DB).Exec(0xc4203d8820, 0x1a1d299, 0xb5, 0xc42047d6e8, 0x3, 0x3, 0x3a98cde8, 0xc42047d6d0, 0x6b3676, 0xbee34edc50d05a97)
/usr/local/go/src/database/sql/sql.go:1363 +0x85
main.(*bankClient).transferMoney(0xc4204c3590, 0x3e7, 0x3e7, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:65 +0x212
main.(*bankState).transferMoney(0xc4204c0cd0, 0x1b95f00, 0xc4204be580, 0xc4204da0c0, 0x1, 0x3e7, 0x3e7)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:159 +0xba
created by main.runBankNodeRestart
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/cmd/roachtest/bank.go:410 +0x48a
The server is happy. I'm afraid this means that what I want is a stack trace of the node the client is talking to. Let's see.
tbg
on 27 Sep 2018
Hmm. I had what I thought was a failing test run:
test finished, waiting for shutdown of 4 clients
round 26: not waiting for recovery due to signal that we're done
[ 2] acceptance/bank/node-restart: ??? (0s)
[ 3] acceptance/bank/node-restart: ??? (0s)
[ 4] acceptance/bank/node-restart: ??? (0s)
[ 5] acceptance/bank/node-restart: ??? (0s)
client 1 shutting down
11666 transfers (36.4/sec) in 320.4s
The client 1 shutting down line coincided exactly with my running select * from bank.accounts where balance = 0; against the cluster. Maybe a coincidence. I'll do the same next time.
tbg
on 27 Sep 2018
Yeah - the same thing happened again. client 1 shutting down precisely as I query the table.
round 14: monkey sleeping while cluster recovers...
round 14: client counts: (8977)
[ 1] acceptance/bank/node-restart: ??? (0s)
round 14: not waiting for recovery due to signal that we're done
[ 2] acceptance/bank/node-restart: ??? (0s)
client 1 shutting down
8978 transfers (55.3/sec) in 162.3s
> /home/tschottdorf/go/bin/roachprod get local logs artifacts/acceptance/bank/node-restart/logs
local: getting logs artifacts/acceptance/bank/node-restart/logs
1: done
2: done
3: done
4: done
--- PASS: acceptance/bank/node-restart (164.61s)
Next hang. This time, the cluster is not fine (connecting via the SQL shell times out).
[ 1] acceptance/bank/node-restart: ??? (0s)
test finished, waiting for shutdown of 4 clients
round 25: not waiting for recovery due to signal that we're done
[ 2] acceptance/bank/node-restart: ??? (0s)
[ 3] acceptance/bank/node-restart: ??? (0s)
[ 4] acceptance/bank/node-restart: ??? (0s)
[ 5] acceptance/bank/node-restart: ??? (0s)
[ 6] acceptance/bank/node-restart: ??? (0s)
[ 7] acceptance/bank/node-restart: ??? (0s)
[ 8] acceptance/bank/node-restart: ??? (0s)
[ 9] acceptance/bank/node-restart: ??? (0s)
Okay, here's what the node4 (the one the client connects to) say about this connection:
goroutine 547 [IO wait]:
internal/poll.runtime_pollWait(0x7f022e731bc0, 0x72, 0xc429fd1730)
/usr/local/go/src/runtime/netpoll.go:173 +0x57
internal/poll.(*pollDesc).wait(0xc42061c518, 0x72, 0xffffffffffffff00, 0x2f2a900, 0x4142248)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:85 +0x9b
internal/poll.(*pollDesc).waitRead(0xc42061c518, 0xc42526c000, 0x1000, 0x1000)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:90 +0x3d
internal/poll.(*FD).Read(0xc42061c500, 0xc42526c000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/go/src/internal/poll/fd_unix.go:157 +0x17d
net.(*netFD).Read(0xc42061c500, 0xc42526c000, 0x1000, 0x1000, 0x0, 0xc429fd1868, 0x82419c)
/usr/local/go/src/net/fd_unix.go:202 +0x4f
net.(*conn).Read(0xc420842038, 0xc42526c000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/usr/local/go/src/net/net.go:176 +0x6a
github.com/cockroachdb/cockroach/vendor/github.com/cockroachdb/cmux.(*MuxConn).Read(0xc4208245a0, 0xc42526c000, 0x1000, 0x1000, 0x0, 0
x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/cockroachdb/cmux/cmux.go:218 +0x119
github.com/cockroachdb/cockroach/pkg/sql/pgwire.(*readTimeoutConn).Read(0xc420389280, 0xc42526c000, 0x1000, 0x1000, 0x0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/sql/pgwire/conn.go:1372 +0x110
bufio.(*Reader).fill(0xc425232060)
/usr/local/go/src/bufio/bufio.go:100 +0x11e
bufio.(*Reader).ReadByte(0xc425232060, 0xbee351ab872a5d51, 0x4c92b6824, 0x46c8ca0)
/usr/local/go/src/bufio/bufio.go:242 +0x39
github.com/cockroachdb/cockroach/pkg/sql/pgwire/pgwirebase.(*ReadBuffer).ReadTypedMsg(0xc4252321d0, 0x2f3ab20, 0xc425232060, 0x2f34220
, 0x4717650, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/sql/pgwire/pgwirebase/encoding.go:120 +0x35
github.com/cockroachdb/cockroach/pkg/sql/pgwire.(*conn).serveImpl(0xc425232000, 0x2f51de0, 0xc420a16400, 0xc4202bb6b0, 0xc420890100, 0
x5400, 0x15000, 0xc4205d9c70, 0xc420b38090, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/sql/pgwire/conn.go:285 +0x5bd
github.com/cockroachdb/cockroach/pkg/sql/pgwire.serveConn(0x2f51de0, 0xc420a16380, 0x2f6cb00, 0xc4208245a0, 0x0, 0x0, 0xc42522e01e, 0x4, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/sql/pgwire/conn.go:163 +0x207
github.com/cockroachdb/cockroach/pkg/sql/pgwire.(*Server).ServeConn(0xc4205d9b00, 0x2f51de0, 0xc420a16380, 0x2f6cb00, 0xc4208245a0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/sql/pgwire/server.go:453 +0x711
github.com/cockroachdb/cockroach/pkg/server.(*Server).Start.func19.1(0x2f6cb00, 0xc4208245a0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/server/server.go:1631 +0x180
github.com/cockroachdb/cockroach/pkg/util/netutil.(*Server).ServeWith.func1(0xc420b38090, 0x2f51ea0, 0xc42070c3f0, 0xc420304420, 0x2f6cb00, 0xc4208245a0, 0xc42070c420)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/netutil/net.go:141 +0xa9
created by github.com/cockroachdb/cockroach/pkg/util/netutil.(*Server).ServeWith
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/netutil/net.go:138 +0x249
Interesting. I can actually connect to the SQL shell and query the table on n4, but not on n1 and n2. Then I tried n1 again and it worked. n2 still doesn't. Hmm. I wonder if this has something to do with it:
$ lsof | grep tschottdorf | wc -l
11562
Restricting to network file descriptors there are only a few dozen which seems reasonable, so back to the nodes itself... n1 is clearly unhappy:
goroutine 26 [select, 19 minutes]:
github.com/cockroachdb/cockroach/pkg/kv.(*RangeDescriptorCache).lookupRangeDescriptorInternal(0xc420824550, 0x2f51ea0, 0xc420a90180, 0xc420309c50, 0x10, 0x10, 0x0, 0x0, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/kv/range_cache.go:356 +0x4f7
github.com/cockroachdb/cockroach/pkg/kv.(*RangeDescriptorCache).LookupRangeDescriptor(0xc420824550, 0x2f51ea0, 0xc420a90180, 0xc420309c50, 0x10, 0x10, 0x0, 0x3fc3333333333300, 0xc420b36540, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/kv/range_cache.go:241 +0x92
github.com/cockroachdb/cockroach/pkg/kv.(*DistSender).getDescriptor(0xc420264600, 0x2f51ea0, 0xc420a90180, 0xc420309c50, 0x10, 0x10, 0x0, 0xc420b36500, 0x2faf080, 0x3b9aca00, ...)
... leading down to this sort of goroutine...:
goroutine 423 [select, 19 minutes]:
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420d28400, 0x1, 0xc420cb5c20)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport/transport.go:240 +0xff
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).RecvCompress(0xc420d28400, 0xc420cb5c20, 0xc424f15940)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport/transport.go:251 +0x2b
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.(*csAttempt).recvMsg(0xc4209495f0, 0x28ae640, 0xc420cb5aa0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/stream.go:525 +0x639
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.(*clientStream).RecvMsg(0xc420716a00, 0x28ae640, 0xc420cb5aa0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/stream.go:405 +0x43
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.invoke(0x2f51ea0, 0xc420a90660, 0x2a32331, 0x21, 0x29ba100, 0xc420716980, 0x28ae640, 0xc420cb5aa0, 0xc4208d0600, 0xc4203e48a0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/call.go:83 +0x183
github.com/cockroachdb/cockroach/vendor/github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc.OpenTracingClientInterceptor.func1(0x2f51ea0, 0xc420a90660, 0x2a32331, 0x21, 0x29ba100, 0xc420716980, 0x28ae640, 0xc420cb5aa0, 0xc4208d0600, 0x2b50000, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc/client.go:44 +0xe28
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.(*ClientConn).Invoke(0xc4208d0600, 0x2f51ea0, 0xc420a90660, 0x2a32331, 0x21, 0x29ba100, 0xc420716980, 0x28ae640, 0xc420cb5aa0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/call.go:35 +0x109
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.Invoke(0x2f51ea0, 0xc420a90660, 0x2a32331, 0x21, 0x29ba100, 0xc420716980, 0x28ae640, 0xc420cb5aa0, 0xc4208d0600, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/call.go:60 +0xc1
github.com/cockroachdb/cockroach/pkg/roachpb.(*internalClient).Batch(0xc420d680e8, 0x2f51ea0, 0xc420a90660, 0xc420716980, 0x0, 0x0, 0x0, 0x2f51ea0, 0xc420a90660, 0xc400000002)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/roachpb/api.pb.go:6570 +0xd2
github.com/cockroachdb/cockroach/pkg/kv.(*grpcTransport).sendBatch(0xc420a90ea0, 0x2f51ea0, 0xc420a90660, 0x2f2eaa0, 0xc420d680e8, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/kv/transport.go:199 +0x138
github.com/cockroachdb/cockroach/pkg/kv.(*grpcTransport).SendNext(0xc420a90ea0, 0x2f51ea0, 0xc420a90660, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, 0x0, ...)
Similar story on all nodes, actually:
$ grep -B 1 waitOnHeader 26*.log
26258.log-goroutine 140 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420265500, 0x1, 0xc4253c5500)
--
26258.log-goroutine 423 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420d28400, 0x1, 0xc420cb5c20)
--
26258.log-goroutine 455 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420ba4900, 0x1, 0xc42521c9c0)
--
26258.log-goroutine 103 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420d28500, 0x1, 0xc420cb5f80)
--
26258.log-goroutine 106 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420d28600, 0x1, 0xc42549a9c0)
--
26258.log-goroutine 112 [select, 19 minutes]:
26258.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420d28900, 0x1, 0xc4256c02a0)
--
26260.log-goroutine 442 [select, 19 minutes]:
26260.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc424ff4100, 0x1, 0xc420946720)
--
26260.log-goroutine 602 [select, 19 minutes]:
26260.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc424ff4700, 0x1, 0xc4258bef00)
--
26262.log-goroutine 536 [select, 19 minutes]:
26262.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc425466200, 0x1, 0xc4209b2ae0)
--
26262.log-goroutine 1096 [select, 19 minutes]:
26262.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc426e43a00, 0x1, 0xc420600300)
--
26262.log-goroutine 1082 [select, 19 minutes]:
26262.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc420beec00, 0x1, 0xc427034480)
--
26264.log-goroutine 845 [select, 19 minutes]:
26264.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc42609f100, 0x1, 0xc4283aa2a0)
--
26264.log-goroutine 1117 [select, 19 minutes]:
26264.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc4273a0400, 0x1, 0xc426c2ac60)
--
26264.log-goroutine 1157 [select, 19 minutes]:
26264.log:github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc426fb2800, 0x1, 0xc42821ede0)
Ah, some of those are false positives though. They also occur in this, which is benign:
goroutine 1117 [select, 19 minutes]:
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).waitOnHeader(0xc4273a0400, 0x1, 0xc426c2ac60)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport/transport.go:240 +0xff
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport.(*Stream).RecvCompress(0xc4273a0400, 0xc426c2ac60, 0xc424e88e50)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/transport/transport.go:251 +0x2b
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.(*csAttempt).recvMsg(0xc428955860, 0x284ba00, 0xc4286feed0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/stream.go:525 +0x639
github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc.(*clientStream).RecvMsg(0xc4297a2000, 0x284ba00, 0xc4286feed0, 0x30, 0x286efe0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/vendor/google.golang.org/grpc/stream.go:405 +0x43
github.com/cockroachdb/cockroach/pkg/storage.(*multiRaftRaftMessageBatchClient).Recv(0xc4204413a0, 0x286efe0, 0xc4286feea0, 0x268d200)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/raft.pb.go:366 +0x62
github.com/cockroachdb/cockroach/pkg/storage.(*RaftTransport).processQueue.func1.1.1(0x2f6c860, 0xc4204413a0, 0xc420329100, 0xc420b3a4d0, 0x2f51ea0, 0xc4286feea0, 0x68e749, 0xc400000008)
Ah, I found the server-side end of this. That makes things easier.
goroutine 510 [select, 19 minutes]:
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).redirectOnOrAcquireLease.func2(0xc42038cf90, 0xc4206f4000, 0x2f51ea0, 0xc425592b40, 0xc42010fab0, 0xc4203349a0, 0xc4203349a0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:1513 +0x273
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).redirectOnOrAcquireLease(0xc4206f4000, 0x2f51ea0, 0xc425592b40, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:1569 +0x238
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).executeReadOnlyBatch(0xc4206f4000, 0x2f51ea0, 0xc425592b40, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:2946 +0xb8b
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).sendWithRangeID(0xc4206f4000, 0x2f51ea0, 0xc425592b40, 0x1, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:2027 +0x2bf
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).Send(0xc4206f4000, 0x2f51ea0, 0xc425592b10, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:1972 +0x90
github.com/cockroachdb/cockroach/pkg/storage.(*Store).Send(0xc420b6c580, 0x2f51ea0, 0xc425592b10, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/store.go:3181 +0x606
github.com/cockroachdb/cockroach/pkg/storage.(*Stores).Send(0xc420712dc0, 0x2f51ea0, 0xc425592ab0, 0x1558420aec8a1996, 0x0, 0x200000002, 0x2, 0x1, 0x0, 0x0, ...)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/storage/stores.go:185 +0xdb
github.com/cockroachdb/cockroach/pkg/server.(*Node).batchInternal.func1(0x2f51ea0, 0xc425592ab0, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/server/node.go:1009 +0x19a
github.com/cockroachdb/cockroach/pkg/util/stop.(*Stopper).RunTaskWithErr(0xc4201fd050, 0x2f51ea0, 0xc425592a50, 0x2a0892e, 0x10, 0xc4255eb3c8, 0x0, 0x0)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/util/stop/stopper.go:303 +0xed
github.com/cockroachdb/cockroach/pkg/server.(*Node).batchInternal(0xc420673880, 0x2f51ea0, 0xc425592a50, 0xc424f84500, 0xc425592a50, 0xc7e2b1, 0xc420cd5668)
/home/tschottdorf/go/src/github.com/cockroachdb/cockroach/pkg/server/node.go:996 +0x201
github.com/cockroachdb/cockroach/pkg/server.(*Node).Batch(0xc420673880, 0x2f51ea0, 0xc425592a50, 0xc424f84500, 0xc420673880, 0xc42000e2b0, 0xc4254150c0)
A problem is definitely that the "Slow Requests" tab doesn't show any slow requests. It should show this sort of thing.
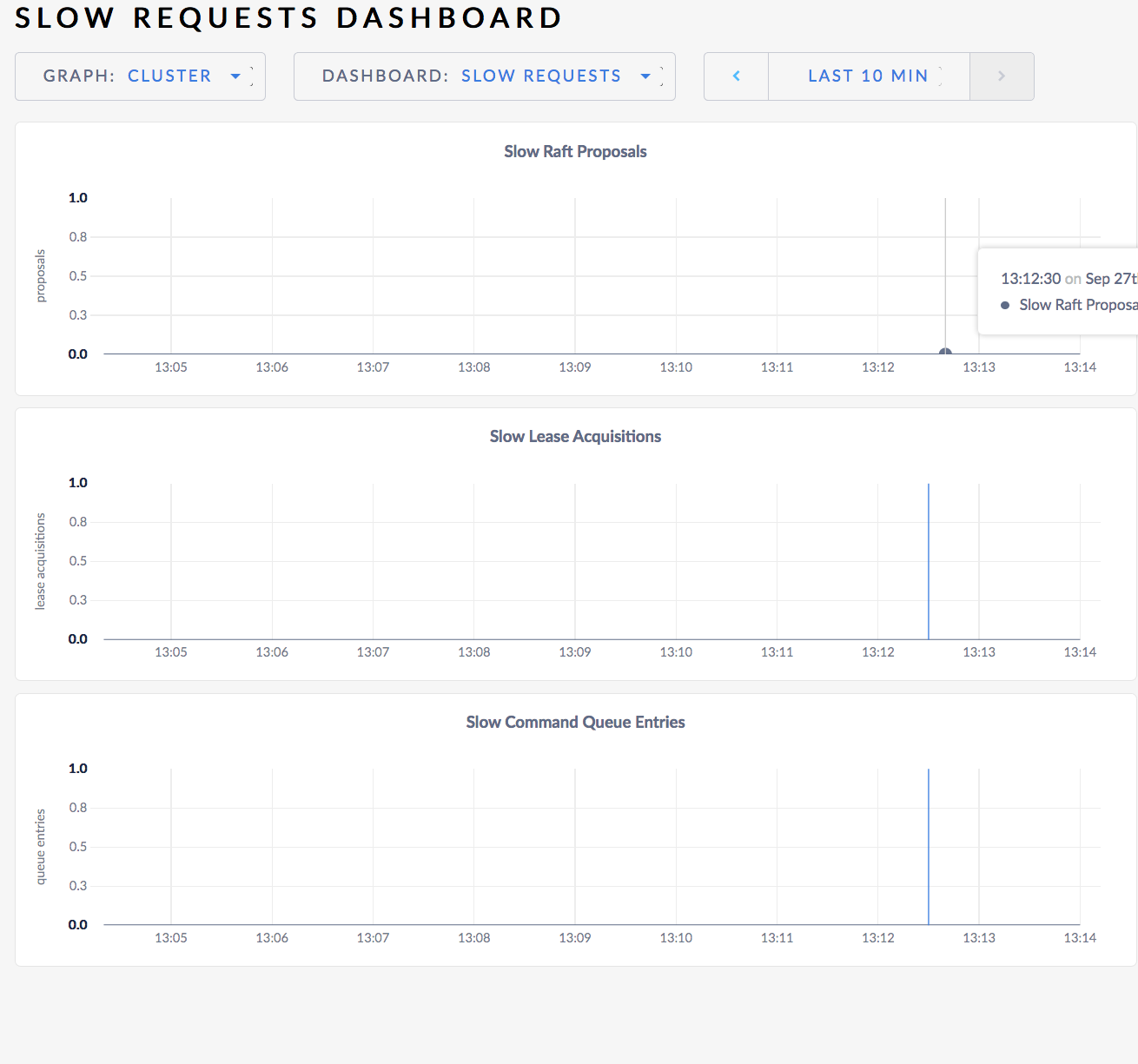
tbg
on 27 Sep 2018
No problem ranges except for r18 (/Table/2{1-2}) which has the below (this is just a problem with problem ranges, #28969).
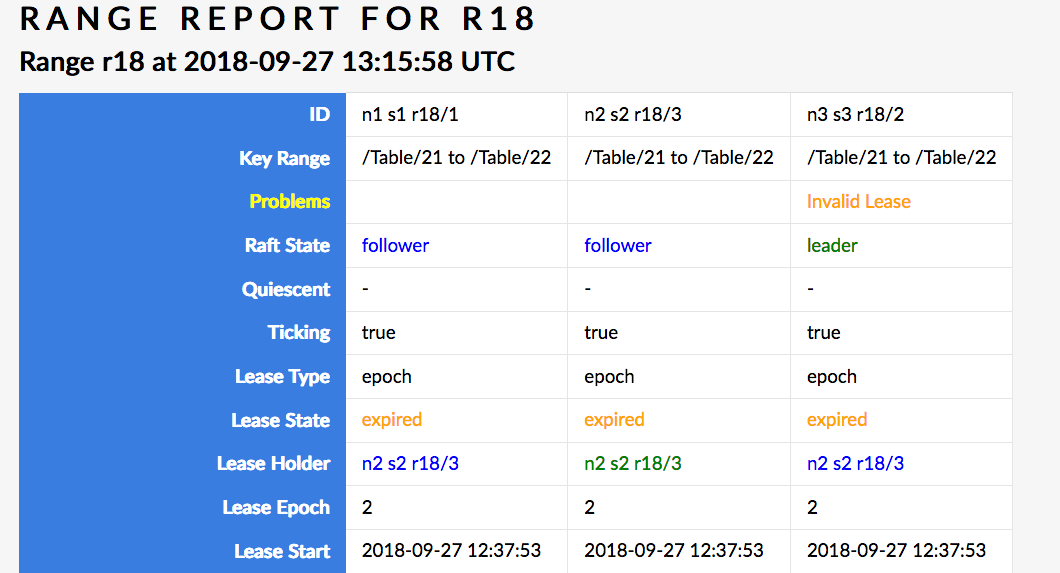
This cluster claims to be perfectly happy.
tbg
on 27 Sep 2018
Aha! This here seems like a much bigger problem (but apparently not a problem that gets you into problem ranges): n3 is Raft leader but is quiesced, while the other two replicas are alive and I'd bet my butt that they're trying to acquire a lease but the leader just isn't having it.
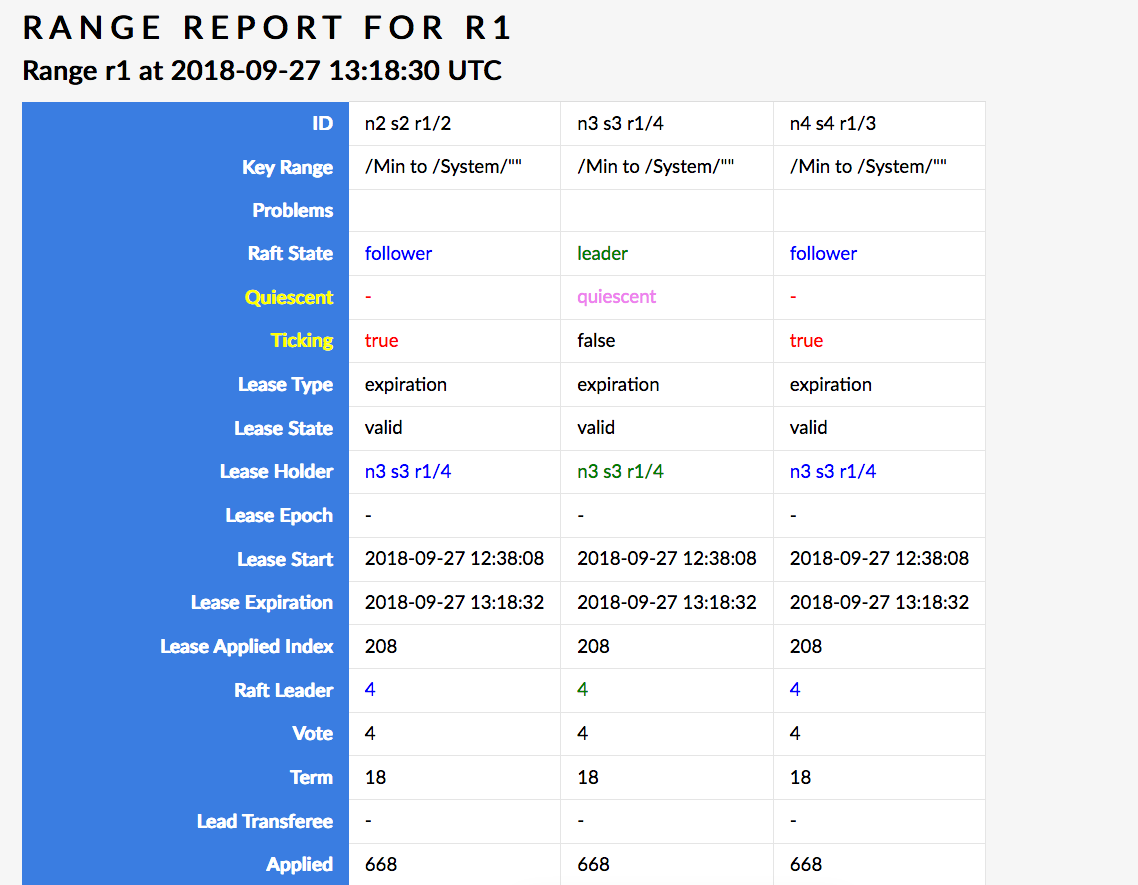
I'm attaching the full PDF printout of this page, which also shows that n1 and n3 have a pending command (certainly a lease acquisition request, since the lease is expired).
tbg
on 27 Sep 2018
Hmm, the ticking situation has resolved itself and the lease is now valid, but the two followers still have pending commands. The applied index also keeps going up.
Could this have to do with https://github.com/cockroachdb/cockroach/pull/27774 (prevent unbounded raft log growth)? After all, the mechanism there lets a leader ignore forwarded proposals from followers. If it ignored one erroneously, the followers would get stuck. cc @nvanbenschoten
I'm going to logspy in.
tbg
on 27 Sep 2018
Hmm, unfortunately there's no code in #27774 that would be visible under logspy (the dropping is silent). I'm seeing the leader trying to quiesce the followers continuously, but the followers don't want to because they have a pending command that they repropose every few seconds at they ought to:
I180927 13:42:02.046019 371 storage/replica.go:4904 [n4,s4,r1/3:/{Min-System/}] pending commands: sent 0 back to client, reproposing 1 (at 914.210) reasonTicks
I180927 13:42:05.045984 193 storage/replica.go:4904 [n4,s4,r1/3:/{Min-System/}] pending commands: sent 0 back to client, reproposing 1 (at 914.210) reasonTicks
I180927 13:42:08.046061 262 storage/replica.go:4904 [n4,s4,r1/3:/{Min-System/}] pending commands: sent 0 back to client, reproposing 1 (at 914.210) reasonTicks
On another note, why doesn't http://localhost:26262/debug/logspy?count=1000&duration=30s&grep=.*raft.go.*r1.* return anything? If I reduce to raft.go it finds lines that should match raft.go.*r1. Hmm I'm confused. Similarly http://localhost:26260/debug/logspy?count=1000&duration=5s&grep=raft.go.134 doesn't find anything even though raft.go shows matches with raft.go:134. Is this just doing a literal string match?
@nvanbenschoten would you mind getting pulled in here? I'm pretty confident that this is a bug in #27774 and you might be able to "just spot it".
tbg
on 27 Sep 2018
One thing that stands out to me is that we don't take the remote proposal count into consideration when deciding whether to quiesce or not. It's possible we need some logic like:
diff --git a/pkg/storage/replica.go b/pkg/storage/replica.go
index 3b58dfb469..0f3317de18 100644
--- a/pkg/storage/replica.go
+++ b/pkg/storage/replica.go
@@ -3890,6 +3890,12 @@ func (r *Replica) quiesceLocked() bool {
}
return false
}
+ if len(r.mu.remoteProposals) != 0 {
+ if log.V(3) {
+ log.Infof(ctx, "not quiescing: %d pending remote commands", len(r.mu.remoteProposals))
+ }
+ return false
+ }
if !r.mu.quiescent {
if log.V(3) {
log.Infof(ctx, "quiescing %d", r.RangeID)
@@ -4569,7 +4575,7 @@ func (r *Replica) tick(livenessMap IsLiveMap) (bool, error) {
// correctness issues.
func (r *Replica) maybeQuiesceLocked(livenessMap IsLiveMap) bool {
ctx := r.AnnotateCtx(context.TODO())
- status, ok := shouldReplicaQuiesce(ctx, r, r.store.Clock().Now(), len(r.mu.localProposals), livenessMap)
+ status, ok := shouldReplicaQuiesce(ctx, r, r.store.Clock().Now(), len(r.mu.localProposals)+len(r.mu.remoteProposals), livenessMap)
if !ok {
return false
}
I don't understand why this would be necessary though, as a follower with local proposals should still be able to wake up the leader if it ever quiesces. That was necessary for correctness before and after #27774. Perhaps the followers are able to wake up the leader but it immediately quiesces again.
 nvanbenschoten
on 27 Sep 2018
nvanbenschoten
on 27 Sep 2018
https://github.com/cockroachdb/cockroach/pull/29618 should have ensured that we don't keep track of empty proposals, which followers send to unquiesce a range and wake the leader. These wakeup messages should pass straight through the duplicate proposal protection because they always have a new ID.
nvanbenschoten
on 27 Sep 2018
Perhaps the followers are able to wake up the leader but it immediately quiesces again.
This is likely true. I see the leader flipflop (though it's mostly quiesced). Note also that this is an expiration-based range which auto-renews its lease. The followers do get these updates, there is steady Raft progress. And yet, I think the followers have outstanding lease proposals that the leader never actually managed to put into Raft but that it tracks as having done so (or some variation of that theme).
Would be really nice to be able to see the remoteProposals map (or logging when messages get dropped). The leader must be dropping these messages, right? It's unlikely that it actually puts them through Raft and they pop out everywhere but the followers just "miss" them.
tbg
on 27 Sep 2018
Btw, there's some connection to https://github.com/cockroachdb/cockroach/issues/26448 here. If the new leases that get proposed all the time unblocked the pending requests for a lease that's clearly never going to become active, we wouldn't have noticed this problem in the first place.
tbg
on 27 Sep 2018
There are two things here that scare me. #27774 works under the assumption that stepping a Raft leader with a new proposal will always insert the proposal into its log where it will stay until it is either applied or the leader changes. However, we check whether a node is a leader or not by checking the replica's r.mu.leaderID field. I think it's possible for these to diverge temporarily if the raft group is stepped multiple times before a handleRaftReady call.
I'm also a little worried about our remoteProposals eviction policy. We evict it whenever a handleRaftReady call detects that a leader changes. Is it possible for a leader to switch away and back to a node between handleRaftReady calls? Should we be checking the term for this leadership change detection?
nvanbenschoten
on 27 Sep 2018
I've been trying unsuccessfully to reproduce the stall detected error. I've been working off of the tschottdorf/acceptance/stress branch, with the changes to pkg/storage reverted and the branch rebased on master (bd5e0256f438dd0c6649f84f4a0111a160356105). I've gone through hundreds of cycles with no stalls. I have hit https://github.com/cockroachdb/cockroach/issues/29149 multiples times, though.
I wonder if something was fixed between c0549789cafa2d3aa1b77e98bc6557b211e1aebc (the parent of @tschottdorf's branch) and bd5e0256f438dd0c6649f84f4a0111a160356105 (the parent of my branch). Or perhaps I'm just getting unlucky in not being able to reproduce.
@tschottdorf Were you reproducing this error on Mac or Linux?
petermattis
on 30 Sep 2018
I believe @tschottdorf was running with a local roachprod cluster on his gce worker.
nvanbenschoten
on 1 Oct 2018
Ack. I'll give Linux a try.
petermattis
on 1 Oct 2018
FYI, I failed to reproduce on a gce-worker yesterday. I did get a new context cancelled failure. @tschottdorf Do you have some sort of magic incantation to reproduce this?
petermattis
on 2 Oct 2018
Let me see if my magic wand still works.
tbg
on 2 Oct 2018
It does! @nvanbenschoten is poking.
PS it's cool that GCEWORKER_NAME=gceworker-tschottdorf works out of the box for other CRL employees.
tbg
on 2 Oct 2018
It does!
What branch were/are you running on?
petermattis
on 2 Oct 2018
https://github.com/tschottdorf/cockroach/tree/acceptance/stress (identical to the old acceptance/stress mod a cleanup and rebase)
# on gceworker
git checkout tschottdorf/acceptance/stress
roachprod destroy local; git fetch tschottdorf && git reset --hard @{u} && make bin/{workload,roachtest} build && while [ $? -eq 0 ]; do ./bin/roachtest run --local --debug acceptance/bank/node-restart && rm -rf artifacts; done
I finally saw a reproduction of the stall problem. Still debugging what is going on. The stall occurred after n2 was restarted. Poking around and the first thing I see is that r24 has an invalid lease:
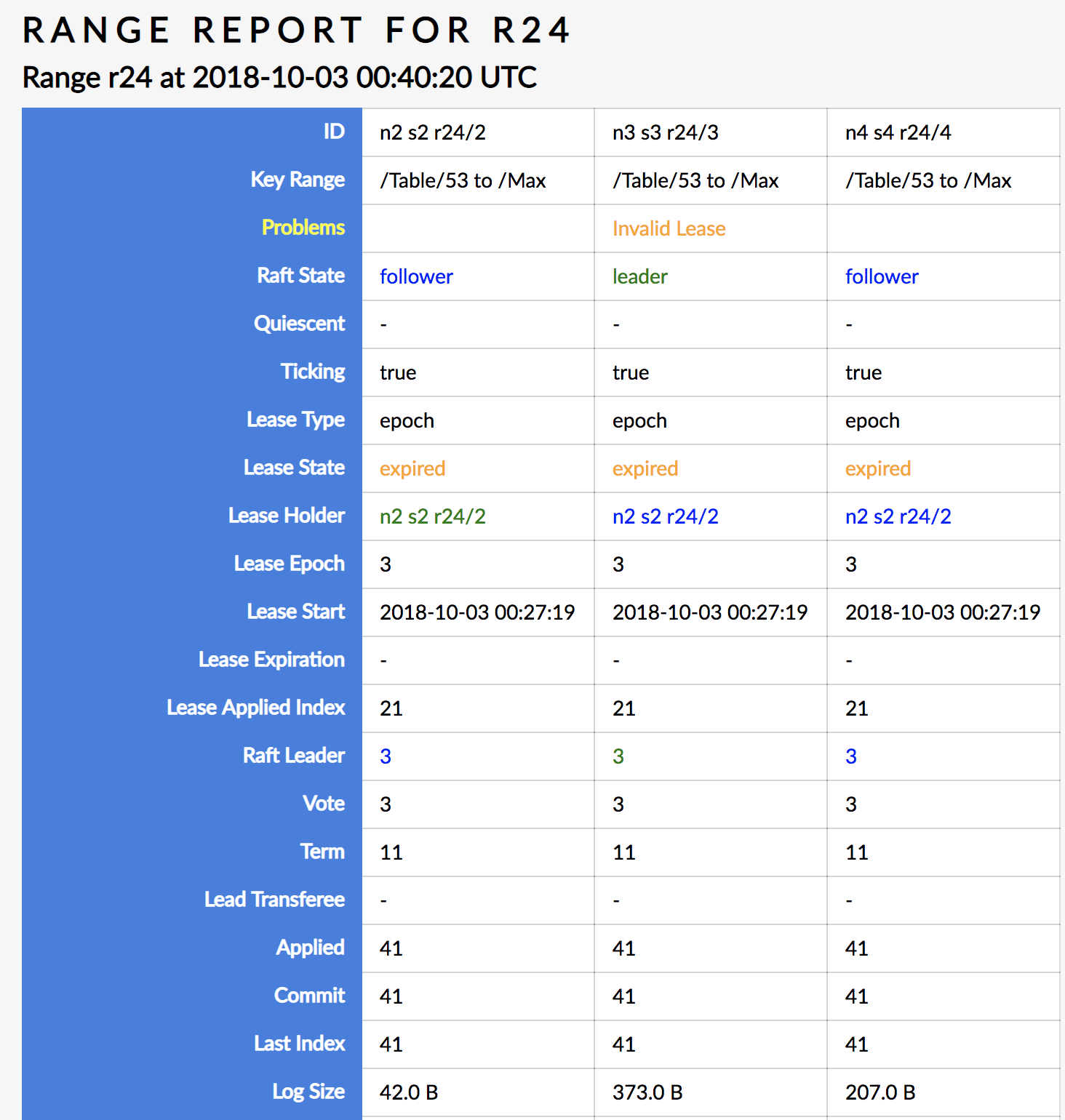
r24 corresponds to the single range on the bank.accounts table. So without a valid lease we'd expect a stall. This is an epoch-based lease, so why don't we have a valid lease? I need to step away from my computer for a little bit, but I'll be back to continue the story shortly.
petermattis
on 3 Oct 2018
Doh, the problem resolved itself! Going to poke around the logs some more to see if anything turns up.
petermattis
on 3 Oct 2018
The problem occurred very soon after r24 was created.
00:27:09 - r24 created on n1
00:27:09 - replica of r24 added on n2
00:27:18 - replica of r24 added on n3
00:27:18 - n3 restarted
00:27:19 - n2 acquires the lease
00:27:22 - n2 restarted
Sometime right around here the stall occurs.
00:49:29 - n3 acquires the lease
I believe the lease acquisition at 00:49:29 was caused by my poking around the SQL shell. The image above showing that r24 had an invalid lease was taken after the stall but before that poking. Part of that image is sensical in that n3 had been restarted since the lease mentioned that had been acquired which means that another node likely bumped n3s liveness epoch. But why didn't another node also grab the lease?
petermattis
on 3 Oct 2018
On n1 I see log evidence that a liveness heartbeat failed at around 00:27:28 and a number of lease acquisitions happened on that node and on n3 and n4 at around that time.
petermattis
on 3 Oct 2018
In case it helps, one more occurrence here: https://teamcity.cockroachdb.com/viewLog.html?buildId=939811&tab=buildResultsDiv&buildTypeId=Cockroach_UnitTests_Roachtest
And another one in the issue closed above.
 andreimatei
on 3 Oct 2018
andreimatei
on 3 Oct 2018
I was just able to reproduce this. I can see r23 stuck in a similar state to what Peter posted above. n2 is the leader and n3 has an expired lease. n2 is not quiescing because not quiescing: not leaseholder and n3 and n4 are not quiescing because not quiescing: not leader. It's surprising that the lease isn't moving over.
nvanbenschoten
on 3 Oct 2018
I'm able to query the bank.account table from all nodes except n4.
Interestingly, I see a goroutine stuck in
goroutine 586 [select, 33 minutes]:
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).redirectOnOrAcquireLease.func2(0xc424f091e0, 0xc420701800, 0x2fb6060, 0xc4264f9380, 0xc4264a8b60, 0xc4203fb338, 0xc4203fb338)
/home/nathan/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:1513 +0x273
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).redirectOnOrAcquireLease(0xc420701800, 0x2fb6060, 0xc4264f9380, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/home/nathan/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:1569 +0x238
That lease acquisition is stuck in:
goroutine 588 [select, 35 minutes]:
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).tryExecuteWriteBatch(0xc420701800, 0x2fb5fa0, 0xc426504780, 0x155a2bc32d97756a, 0x0, 0x0, 0x0, 0x8, 0x0, 0x0, ...)
/home/nathan/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:3258 +0x961
github.com/cockroachdb/cockroach/pkg/storage.(*Replica).executeWriteBatch(0xc420701800, 0x2fb5fa0, 0xc426504780, 0x155a2bc32d97756a, 0x0, 0x0, 0x0, 0x8, 0x0, 0x0, ...)
/home/nathan/go/src/github.com/cockroachdb/cockroach/pkg/storage/replica.go:3075 +0xab
So we have a stuck lease acquisition on n4. I suspect that n4 doesn't have the leaseholder for r23 in its leaseholder cache, so it directs traffic to its local replica, which gets stuck on this lease acquisition. This would explain why queries succeed on all other nodes.
nvanbenschoten
on 3 Oct 2018
n4/r23 doesn't have any pending commands, but n2/r23 does have a single dropped command:

nvanbenschoten
on 3 Oct 2018
EDIT: I got the nodes switched. n3 is the one with the goroutine stuck in tryExecuteWriteBatch and n3 is the one that can't query bank.account. We should be running these roachtests with --sequential.
The /debug/requests page showed that the query wasn't even making it to the replica:

On n3 I could see frequent logs like
I181003 18:59:10.941479 289 storage/replica.go:4913 [n3,s3,r8/4:/Table/1{1-2}] pending commands: sent 0 back to client, reproposing 1 (at 132.101) reasonTicks
This is on the table lease range, r8. I suspect that n3 has a stale table lease and is getting stuck on r8, which looks like:
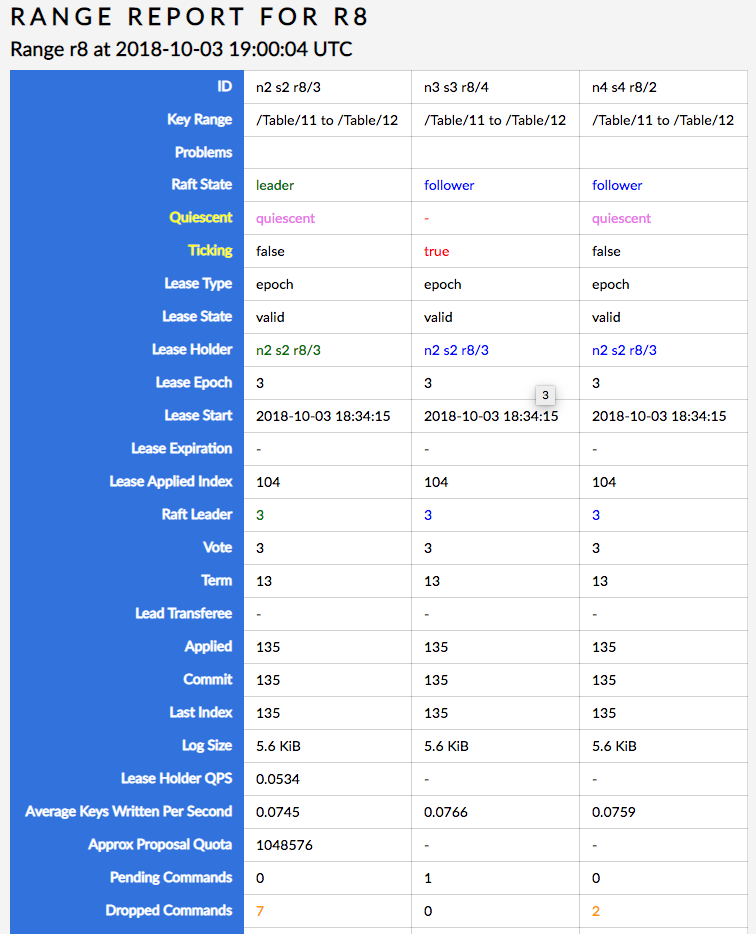
nvanbenschoten
on 3 Oct 2018
So the leader must be dropping the forwarded proposals. I see lots of logs on the leader that look like:
I181003 19:08:30.641787 322 storage/replica.go:3921 [n2,s2,r8/3:/Table/1{1-2}] unquiescing 8
I181003 19:08:30.652168 302 storage/replica.go:3895 [n2,s2,r8/3:/Table/1{1-2}] quiescing 8
So it's receiving the proposal and waking up, but not doing anything with it. I need to add more logging in here. I think @tschottdorf nailed it when he suspected issues with https://github.com/cockroachdb/cockroach/pull/27774.
nvanbenschoten
on 3 Oct 2018
I just had a stall detected at round 1, no forward progress for 30s failure that got stuck and didn't exhibit any of these symptoms. The accounts table is queryable from all nodes and none of the ranges look stuck. Hmm.
nvanbenschoten
on 4 Oct 2018
I finally got a reproduction where I can see the forwarded proposals repeatedly being dropped by the leader. The leader does have one entry in its remoteProposals map, but I don't see anything else in the logs indicating why this command entered the map without being applied.
nvanbenschoten
on 4 Oct 2018
If shouldDropForwardedProposalLocked returns false, Raft is still allowed to drop the proposal. Perhaps we should remove the entry from the remoteProposals map if Raft indicates it dropped the proposal. It is possible I'm not understanding something about the way this is supposed to be working.
petermattis
on 4 Oct 2018
It's working off the assumption that if r.mu.replicaID == r.mu.leaderID, Raft will never drop the proposal and it will stay in the Raft log until it is either applied or the Raft leader changes. I'm skeptical that that assumption holds in all cases. For instance, see https://github.com/cockroachdb/cockroach/issues/30064#issuecomment-425157919.
nvanbenschoten
on 4 Oct 2018
I also think there are multiple problems here. Let's focus on this one for now.
nvanbenschoten
on 4 Oct 2018
Aha! That assumption was wrong. Specifically, it was wrong when raft's leadTransferee was set. We'll need to check for ErrProposalDropped before adding to this map, like @petermattis suggested.
nvanbenschoten
on 4 Oct 2018
Ok, the fix for this should be easy. It will need to be backported to 2.0 and 2.1.
On a side note, we really need to make raft.Status cheaper so that we can avoid duplicating state everywhere and make better informed decisions. This was mentioned in https://github.com/cockroachdb/cockroach/issues/30512.
nvanbenschoten
on 4 Oct 2018
With the fix in #30990, I haven't been able to reproduce the stuck proposal issue. I do still see failures that look like https://github.com/cockroachdb/cockroach/issues/30064#issuecomment-426827798 though.
nvanbenschoten
on 5 Oct 2018
How does the following work? Wouldn't it result in us sending on the errChan twice and deadlocking? I'll try fixing that and see if it makes a difference.
nvanbenschoten
on 5 Oct 2018
How does the following work? Wouldn't it result in us sending on the errChan twice and deadlocking? I'll try fixing that and see if it makes a difference.
Heh, seems bad that way, even if it isn't at fault here.
tbg
on 5 Oct 2018
@nvanbenschoten Are you still seeing a deadlock during shutdown? I've been running this in a loop on current master and I'm not seeing any failures. Perhaps I need to try on a gce worker.
petermattis
on 5 Oct 2018
No, because after adding a pprof server so I could peek at the active goroutines, I realized that the "deadlock" was actually just this. 🤦♂️
I still see stalls occasionally, but I suspect they're related to https://github.com/cockroachdb/cockroach/issues/29149 because I also see errors like pq: unable to dial n2: breaker open. I'm going to continue stressing this on master for the rest of the day. If nothing fails, I'll close this issue.
nvanbenschoten
on 5 Oct 2018
Nice "deadlock". The breaker open failures should be fixed by #30987. Definitely ping me if you see such an error again.
petermattis
on 5 Oct 2018
Haha, sorry about that Nathan.
On Fri, Oct 5, 2018, 9:53 PM Peter Mattis notifications@github.com wrote:
Nice "deadlock". The breaker open failures should be fixed by #30987
https://github.com/cockroachdb/cockroach/pull/30987. Definitely ping me
if you see such an error again.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/cockroachdb/cockroach/issues/30064#issuecomment-427480570,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AE135FJd68VfxI-Yhx13kk6w8VdLtyZ6ks5uh7jKgaJpZM4Wje-q
.>
-- Tobias
tbg
on 5 Oct 2018
I am still seeing this fail occasionally. All failures look like the failure @tschottdorf saw in https://github.com/cockroachdb/cockroach/issues/30064#issuecomment-425077931 and I saw in https://github.com/cockroachdb/cockroach/issues/30064#issuecomment-426827798. Interestingly, most of the time the failure resolves itself in exactly 60 seconds. I hooked the cluster up to Jaeger and that pointed to this being the result of a range lease acquisition timeout.
I did get one case where the failure did not resolve itself. The issue is a stuck range lease acquisition like always, but the cause is strange. The stuck range is r1. The replica proposing the lease acquisition is having a hard time joining the Raft group. I see it dropping proposals with logs like 3 no leader at term 20; dropping proposal and then sending out PreVote messages with the following logs:
I181008 07:42:20.358755 303 vendor/go.etcd.io/etcd/raft/raft.go:872 [n4,s4,r1/3:/{Min-System/}] 3 is starting a new election at term 20
I181008 07:42:20.358764 303 vendor/go.etcd.io/etcd/raft/raft.go:705 [n4,s4,r1/3:/{Min-System/}] 3 became pre-candidate at term 20
I181008 07:42:20.358773 303 vendor/go.etcd.io/etcd/raft/raft.go:770 [n4,s4,r1/3:/{Min-System/}] 3 received MsgPreVoteResp from 3 at term 20
I181008 07:42:20.358791 303 vendor/go.etcd.io/etcd/raft/raft.go:757 [n4,s4,r1/3:/{Min-System/}] 3 [logterm: 19, index: 229] sent MsgPreVote request to 1 at term 20
I181008 07:42:20.358803 303 vendor/go.etcd.io/etcd/raft/raft.go:757 [n4,s4,r1/3:/{Min-System/}] 3 [logterm: 19, index: 229] sent MsgPreVote request to 2 at term 20
I181008 07:42:20.358874 303 storage/raft.go:134 [n4,s4,r1/3:/{Min-System/}] raft ready (must-sync=false)
SoftState updated: {Lead:0 RaftState:StatePreCandidate}
Outgoing Message[0]: 3->1 MsgPreVote Term:21 Log:19/229
Outgoing Message[1]: 3->2 MsgPreVote Term:21 Log:19/229
I181008 07:42:20.358961 303 storage/replica.go:5132 [n4,s4,r1/3:/{Min-System/}] sending raft request range_id:1 from_replica:<node_id:4 store_id:4 replica_id:3 > to_replica:<node_id:1 store_id:1 replica_id:1 > message:<type:MsgPreVoteMsgPreVote to:1 from:3 term:21 logTerm:19 index:229 commit:0 snapshot:<metadata:<conf_state:<> index:0 term:0 > > reject:false rejectHint:0 > quiesce:false
I181008 07:42:20.359017 303 storage/replica.go:5132 [n4,s4,r1/3:/{Min-System/}] sending raft request range_id:1 from_replica:<node_id:4 store_id:4 replica_id:3 > to_replica:<node_id:3 store_id:3 replica_id:2 > message:<type:MsgPreVoteMsgPreVote to:2 from:3 term:21 logTerm:19 index:229 commit:0 snapshot:<metadata:<conf_state:<> index:0 term:0 > > reject:false rejectHint:0 > quiesce:false
I181008 07:42:20.359738 342 vendor/go.etcd.io/etcd/raft/raft.go:772 [n4,s4,r1/3:/{Min-System/}] 3 received MsgPreVoteResp rejection from 1 at term 20
I181008 07:42:20.359755 342 vendor/go.etcd.io/etcd/raft/raft.go:1171 [n4,s4,r1/3:/{Min-System/}] 3 [quorum:2] has received 1 MsgPreVoteResp votes and 1 vote rejections
I181008 07:42:20.359767 342 vendor/go.etcd.io/etcd/raft/raft.go:772 [n4,s4,r1/3:/{Min-System/}] 3 received MsgPreVoteResp rejection from 2 at term 20
I181008 07:42:20.359772 342 vendor/go.etcd.io/etcd/raft/raft.go:1171 [n4,s4,r1/3:/{Min-System/}] 3 [quorum:2] has received 1 MsgPreVoteResp votes and 2 vote rejections
I181008 07:42:20.359790 342 vendor/go.etcd.io/etcd/raft/raft.go:677 [n4,s4,r1/3:/{Min-System/}] 3 became follower at term 20
The interesting part is that the other two replicas respond to the PreVote messages but don't begin sending heartbeats or any other messages to n4 after they reject it:
I181008 07:42:09.959055 221 vendor/go.etcd.io/etcd/raft/raft.go:915 [n1,s1,r1/1:/{Min-System/}] 1 [logterm: 20, index: 364, vote: 1] rejected MsgPreVote from 3 [logterm: 19, index: 229] at term 20
I181008 07:42:09.959101 221 storage/raft.go:134 [n1,s1,r1/1:/{Min-System/}] raft ready (must-sync=false)
Outgoing Message[0]: 1->3 MsgPreVoteResp Term:20 Log:0/0 Rejected
I181008 07:42:09.959177 221 storage/replica.go:5132 [n1,s1,r1/1:/{Min-System/}] sending raft request range_id:1 from_replica:<node_id:1 store_id:1 replica_id:1 > to_replica:<node_id:4 store_id:4 replica_id:3 > message:<type:MsgPreVoteRespMsgPreVoteResp to:3 from:1 term:20 logTerm:0 index:0 commit:0 snapshot:<metadata:<conf_state:<> index:0 term:0 > > reject:true rejectHint:0 > quiesce:false
The following line on the leader indicates that n4 is "paused" and not recently active. I need to page back in what that means and whether that explains the lack of heartbeats or entries being sent to it:
I181008 07:42:10.130809 295 storage/replica.go:4733 [n1,s1,r1/1:/{Min-System/}] skipping node 4 because not live. Progress={Match:0 Next:230 State:ProgressStateProbe Paused:true PendingSnapshot:0 RecentActive:false ins:0xc4253b4c60 IsLearner:false}
n1 has plenty of logs like:
W181008 07:42:02.314735 156 storage/replica_range_lease.go:474 can't determine lease status due to node liveness error: node not in the liveness table
Presumably because n4's stuck r1 lease acquisition is preventing it from updating its liveness record.
nvanbenschoten
on 8 Oct 2018
My best guess is that we messed something up with https://github.com/cockroachdb/cockroach/commit/53dc851d96fa05ec37e0b75ae2089e8f2de38534. Every single r1 heartbeat sets quiesce: true, so it seems possible that we drop every heartbeat to n4 and it never catches up, receives a heartbeat message, or proposes its lease request.
I think we need to change this logic to how it was originally. We shouldn't be dropping heartbeats, we should just set their commit index to the minimum of the leader's commit index and the follower's match index.
nvanbenschoten
on 8 Oct 2018
Good find. I agree that by excluding nodes categorically when they're not live we can end up in this situation in which a node needs a heartbeat to manage to become live. Just to get this right in my head, this is the situation, right:
- n4 is not live because its liveness heartbeat is stuck on its replica of r1
- its replica of r1 is stuck on a lease acquisition
- because it drops the proposals because it hasn't received heartbeats, ever
- because the leader sees that n4 is not live and so
5 doesn't heartbeat it (plus always quiesces right away)?
tbg
on 8 Oct 2018
Yes, exactly. So we end up in a persistent starvation scenario. I'm re-running the test with a fix so we'll see if that helps or whether there are still other issues.
nvanbenschoten
on 8 Oct 2018
The range quiescence is critical here. If r1 wasn't always quiesced then it would occasionally send real heartbeats to all followers and n4 would recognize the leader. The problem is that r1 wakes up because of the MsgPreVote and immediately quiesces again, meaning that the quiescing heartbeats are the only heartbeats ever sent. Because the misguided logic above skips over n4 whenever we send a quiescing heartbeat, it is never sent any heartbeats at all.
nvanbenschoten
on 8 Oct 2018
On the plus side, this test is great at finding these kinds of issues!
nvanbenschoten
on 8 Oct 2018
I do wonder though, didn't this test pass until recently? Or maybe we just didn't look at it closely enough.
tbg
on 8 Oct 2018
It takes about 2 hours to fail, so it's possible that it just wasn't stressed often. It might also be a lot faster now that it's out of the grips of Docker.
nvanbenschoten
on 8 Oct 2018
@tschottdorf I chalk this up to the docker based acceptance tests not properly cleaning up after themselves. One would fail hiding the subsequent failures of others. I'm quite pleased that we're finding these issues with these tests.
PS I also saw a reproduction of the stall failure last night. I was going to ping this issue this morning, but I see you're already on top of it.
petermattis
on 8 Oct 2018
I think I tracked down the last cause of failures in this issue to the following logic:
I'm seeing a case where a leader has a stuck LeaseRequest proposal and is refusing to re-propose it because it is the leader so it assumes that the proposal had to have made it into the Raft log. This detection is really hairy and has already bitten us twice in this issue. I'm starting to think we should rip all of it out and upstream a change to Raft to bound the size of the uncommitted portion of the Raft log. Proposals that would push the log above this size could harmlessly return an ErrProposalDropped. The effect of this is that we wouln't need to be nearly as careful about duplicate proposals as we are now. If the logic was in Raft then it would be more localized, easier to reason about, and much easier to test. @bdarnell do you have any thoughts about this?
nvanbenschoten
on 9 Oct 2018
That sounds like a good idea to me, this logic seems broken. (On the fence about returning a different error so that they can be disambiguated more easily, but that's in the noise).
We could also add a hook to RawNode that lets us inspect the size of the uncommitted Raft log, though that still means we have to add code to Raft that tracks it.
tbg
on 9 Oct 2018
I just opened https://github.com/etcd-io/etcd/pull/10167 to make this change.
nvanbenschoten
on 9 Oct 2018
Yeah, pushing this logic down into raft makes sense to me.
 bdarnell
on 9 Oct 2018
bdarnell
on 9 Oct 2018
I mentioned to @tschottdorf that even with https://github.com/cockroachdb/cockroach/pull/31112 and etcd-io/etcd#10167 I was still seeing another failure. This one was interesting though because it always took between 60 and 70 seconds to unwedge and never got stuck indefinitely like the other failures. I originally thought it was a lease acquisition timeout, but I could find anything of the sort in the code.
I then stumbled on something interesting while tracing https://github.com/cockroachdb/cockroach/issues/18684. I saw a good number of requests take almost exactly 60 seconds. I looked through their traces and they all looked almost exactly the same:
1.25s:event=[n3] 1000 InitPut
1.25s:event=[n3,s3] executing 1000 requests
1.25s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] read-write path
1.25s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] command queue
1.26s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] applied timestamp cache
1.27s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] evaluated request
1.27s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] acquired replica mu
1.46s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] re-submitting command 1459af440c9ab627 to Raft: reasonNewLeader <nil> {"id":"3","term":6,"vote":"3","commit":10,"lead":"3","raftState":"StateLeader","applied":10,"progress":{"1":{"match":0,"next":11,"state":"ProgressStateProbe"},"2":{"match":0,"next":11,"state":"ProgressStateProbe"},"3":{"match":26,"next":27,"state":"ProgressStateProbe"}},"leadtransferee":"0"}
61.27s:event=storage/replica.go:3360 [n3,s3,r109/3:/Table/5{5/2/821/…-6}] have been waiting 1m0s for proposing command [txn: 3bb69d99], ...
72.08s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] re-submitting command 1459af440c9ab627 to Raft: reasonNewLeaderOrConfigChange <nil> {"id":"3","term":6,"vote":"3","commit":14,"lead":"3","raftState":"StateLeader","applied":10,"progress":{"1":{"match":0,"next":1,"state":"ProgressStateSnapshot"},"2":{"match":14,"next":40,"state":"ProgressStateReplicate"},"3":{"match":39,"next":40,"state":"ProgressStateProbe"}},"leadtransferee":"0"}
72.51s:event=[n3,s3,r109/3:/Table/5{5/2/821/…-6}] applying command
72.51s:event=storage/replica.go:3369 [n3,s3,r109/3:/Table/5{5/2/821/…-6}] slow command [txn: 3bb69d99], ...
(I added the proposal error and the raft status to the re-submitting logs)
We see that the command is re-proposed shortly after the request is originally proposed with a reasonNewLeader reason. It then seemingly stalls for 60-ish seconds until it is re-proposed again with the reasonNewLeaderOrConfigChange reason. This stall is very common and has almost the exact same duration each time. The re-proposal reasons are also always the same. Have others seen this pattern before or have an idea of what might be causing it?
nvanbenschoten
on 10 Oct 2018
Guessing wildly, but what if the range quiesced erroneously and some queue would pick it up after ~1 min? In https://github.com/cockroachdb/cockroach/issues/30613#issuecomment-427410961 I also saw stalls that took ~1min though I thought this was just how long it took for some queue to pick the replica up again (and then the phenomenon disappeared when I wanted to look at it again)
tbg
on 10 Oct 2018
Also, might this sort of thing be of interest for your situation? https://github.com/cockroachdb/cockroach/pull/28521
tbg
on 10 Oct 2018
Guessing wildly, but what if the range quiesced erroneously and some queue would pick it up after ~1 min?
That's possible, but its very interesting that we always see this pattern of reproposing because of reasonNewLeader and then reproposing again after 60 seconds because of reasonNewLeaderOrConfigChange. I've seen that same pattern like 20 times, and even seen multiple proposals get tripped up on that at the exact same time on the same range.
Also, might this sort of thing be of interest for your situation? #28521
I think it would have helped me get to where I am now faster. Not sure that I can use it to dig any further though.
nvanbenschoten
on 10 Oct 2018
Can you squeeze more information out by adding a boolean to *Replica that is set to true while a lease proposal has been waiting for > 30s and which, while set, enables verbose logging for all (ok, some interesting) ops on that replica? So basically while something is stuck, flip the Raft logger into verbose mode.
tbg
on 10 Oct 2018
I got verbose raft logging of this twice without any of that complexity, just dumb luck.
nvanbenschoten
on 10 Oct 2018
These aren't just lease requests, by the way.
nvanbenschoten
on 10 Oct 2018
Oh, ok. And you're not seeing any smoking guns in the verbose logging for the affected Replicas?
Would you notice if the Raft scheduler got all of its workers stuck on something (just grasping at straws)?
tbg
on 11 Oct 2018
No I am, just writing it up and getting distracted intermittently. It's gonna be juicy.
nvanbenschoten
on 11 Oct 2018
So what we see here is pretty interesting. We see a range split get proposed and committed at some point and the leader of the original range immediately apply the command and call splitPostApply. The other two replicas don't immediately apply the command, which should be fine.
When the first replica is created is immedaitely campaigns and sends MsgPreVote to the other two replicas which should be joining it shortly. Perhaps surprisingly, the MsgPreVote actually succeeds. withReplicaForRequest lazily creates the replica on the followers upon receiving the message and withRaftGroupLocked and lazily creates the Raft group. The pre-vote succeeds and so does the following vote.
From the leader, this looks like:
I181011 00:18:05.856174 368 storage/stateloader/stateloader.go:527 [n1,s1,r33/?:/Table/5{5/1/937/…-6}] loaded from truncated state {10 5} -> 10
I181011 00:18:05.857283 2193 vendor/go.etcd.io/etcd/raft/raft.go:679 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 became follower at term 5
I181011 00:18:05.857368 2193 vendor/go.etcd.io/etcd/raft/raft.go:366 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] newRaft 1 [peers: [1,2,3], term: 5, commit: 10, applied: 10, lastindex: 10, lastterm: 5]
I181011 00:18:05.857764 2193 vendor/go.etcd.io/etcd/raft/raft.go:874 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 is starting a new election at term 5
I181011 00:18:05.857775 2193 vendor/go.etcd.io/etcd/raft/raft.go:707 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 became pre-candidate at term 5
I181011 00:18:05.857787 2193 vendor/go.etcd.io/etcd/raft/raft.go:772 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received MsgPreVoteResp from 1 at term 5
I181011 00:18:05.857854 2193 vendor/go.etcd.io/etcd/raft/raft.go:759 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [logterm: 5, index: 10] sent MsgPreVote request to 2 at term 5
I181011 00:18:05.857947 2193 vendor/go.etcd.io/etcd/raft/raft.go:759 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [logterm: 5, index: 10] sent MsgPreVote request to 3 at term 5
I181011 00:18:05.858015 2193 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 5; dropping proposal
I181011 00:18:05.864029 2408 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 5; dropping proposal
I181011 00:18:05.864351 2331 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 5; dropping proposal
...
I181011 00:18:05.876713 364 vendor/go.etcd.io/etcd/raft/raft.go:772 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received MsgPreVoteResp from 2 at term 5
I181011 00:18:05.876732 364 vendor/go.etcd.io/etcd/raft/raft.go:1173 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [quorum:2] has received 2 MsgPreVoteResp votes and 0 vote rejections
I181011 00:18:05.876744 364 vendor/go.etcd.io/etcd/raft/raft.go:692 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 became candidate at term 6
I181011 00:18:05.876751 364 vendor/go.etcd.io/etcd/raft/raft.go:772 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received MsgVoteResp from 1 at term 6
I181011 00:18:05.876836 364 vendor/go.etcd.io/etcd/raft/raft.go:759 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [logterm: 5, index: 10] sent MsgVote request to 2 at term 6
I181011 00:18:05.876907 364 vendor/go.etcd.io/etcd/raft/raft.go:759 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [logterm: 5, index: 10] sent MsgVote request to 3 at term 6
I181011 00:18:05.877025 2430 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 6; dropping proposal
I181011 00:18:05.877460 2049 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 6; dropping proposal
I181011 00:18:05.877845 2509 vendor/go.etcd.io/etcd/raft/raft.go:1160 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 no leader at term 6; dropping proposal
...
I181011 00:18:05.895028 336 vendor/go.etcd.io/etcd/raft/raft.go:772 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received MsgVoteResp from 2 at term 6
I181011 00:18:05.895043 336 vendor/go.etcd.io/etcd/raft/raft.go:1173 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [quorum:2] has received 2 MsgVoteResp votes and 0 vote rejections
I181011 00:18:05.895066 336 vendor/go.etcd.io/etcd/raft/raft.go:729 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 became leader at term 6
From a follower, this looks something like:
I181011 00:18:05.869005 257 storage/stateloader/stateloader.go:527 [n3,s3,r33/?:{-}] loaded from truncated state {0 0} -> 0
I181011 00:18:05.869173 257 vendor/go.etcd.io/etcd/raft/raft.go:679 [n3,s3,r33/2:{-}] 2 became follower at term 0
I181011 00:18:05.869240 257 vendor/go.etcd.io/etcd/raft/raft.go:366 [n3,s3,r33/2:{-}] newRaft 2 [peers: [], term: 0, commit: 0, applied: 0, lastindex: 0, lastterm: 0]
I181011 00:18:05.869346 257 vendor/go.etcd.io/etcd/raft/raft.go:679 [n3,s3,r33/2:{-}] 2 became follower at term 1
I181011 00:18:05.869474 257 vendor/go.etcd.io/etcd/raft/raft.go:899 [n3,s3,r33/2:{-}] 2 [logterm: 0, index: 0, vote: 0] cast MsgPreVote for 1 [logterm: 5, index: 10] at term 1
I181011 00:18:05.884229 199 vendor/go.etcd.io/etcd/raft/raft.go:814 [n3,s3,r33/2:{-}] 2 [term: 1] received a MsgVote message with higher term from 1 [term: 6]
I181011 00:18:05.884240 199 vendor/go.etcd.io/etcd/raft/raft.go:679 [n3,s3,r33/2:{-}] 2 became follower at term 6
I181011 00:18:05.884440 199 vendor/go.etcd.io/etcd/raft/raft.go:899 [n3,s3,r33/2:{-}] 2 [logterm: 0, index: 0, vote: 0] cast MsgVote for 1 [logterm: 5, index: 10] at term 6
So that whole process takes about 10ms. We can see in those logs that the leader already has commands waiting to be proposed.
What happens next is interesting. The new leader sends the usual empty MsgApp to each of its followers. These followers still haven't performed their splitPostApply, so they don't have a lastIndex set. Because of that, we see the following on the leader:
I181011 00:18:05.918117 336 vendor/go.etcd.io/etcd/raft/raft.go:1014 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received msgApp rejection(lastindex: 0) from 2 for index 10
I181011 00:18:05.918138 336 vendor/go.etcd.io/etcd/raft/raft.go:1017 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 decreased progress of 2 to [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:05.918254 336 vendor/go.etcd.io/etcd/raft/raft.go:491 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [firstindex: 11, commit: 10] sent snapshot[index: 10, term: 5] to 2 [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:05.918267 336 vendor/go.etcd.io/etcd/raft/raft.go:494 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 paused sending replication messages to 2 [next = 1, match = 0, state = ProgressStateSnapshot, waiting = true, pendingSnapshot = 10]
I181011 00:18:05.918569 336 vendor/go.etcd.io/etcd/raft/raft.go:1014 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 received msgApp rejection(lastindex: 0) from 3 for index 10
I181011 00:18:05.918588 336 vendor/go.etcd.io/etcd/raft/raft.go:1017 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 decreased progress of 3 to [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:05.918681 336 vendor/go.etcd.io/etcd/raft/raft.go:491 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [firstindex: 11, commit: 10] sent snapshot[index: 10, term: 5] to 3 [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:05.918691 336 vendor/go.etcd.io/etcd/raft/raft.go:494 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 paused sending replication messages to 3 [next = 1, match = 0, state = ProgressStateSnapshot, waiting = true, pendingSnapshot = 10]
And on the follower:
I181011 00:18:05.895420 253 vendor/go.etcd.io/etcd/raft/raft.go:1260 [n3,s3,r33/2:{-}] 2 [logterm: 0, index: 10] rejected msgApp [logterm: 5, index: 10] from 1
What happened is that each follower hasn't yet written its truncated state, so it doesn't have the expected raftInitialLogIndex (10) as its LastIndex. Instead, it has a last index of 0 and rejects the MsgApp. The leader reacts as expected - it decides both followers need snapshots!
I181011 00:18:05.957943 2634 vendor/go.etcd.io/etcd/raft/raft.go:1098 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 snapshot failed, resumed sending replication messages to 2 [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
E181011 00:18:05.957980 2634 storage/queue.go:791 [n1,raftsnapshot,s1,r33/1:/Table/5{5/1/937/…-6}] snapshot failed: (n3,s3):2: remote couldn't accept Raft snapshot 4f6005af at applied index 10 with error: [n3,s3],r33: cannot apply snapshot: snapshot intersects existing range [n3,s3,r31/2:/Table/5{5/1/750/…-6}]
I181011 00:18:07.005075 447 vendor/go.etcd.io/etcd/raft/raft.go:491 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [firstindex: 11, commit: 10] sent snapshot[index: 10, term: 5] to 2 [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
...
I181011 00:18:16.005045 400 vendor/go.etcd.io/etcd/raft/raft.go:491 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 [firstindex: 11, commit: 10] sent snapshot[index: 10, term: 5] to 2 [next = 1, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:16.005066 400 vendor/go.etcd.io/etcd/raft/raft.go:494 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 paused sending replication messages to 2 [next = 1, match = 0, state = ProgressStateSnapshot, waiting = true, pendingSnapshot = 10]
I181011 00:18:16.006283 2958 storage/store_snapshot.go:615 [n1,raftsnapshot,s1,r33/1:/Table/5{5/1/937/…-6}] sending Raft snapshot 516f984f at applied index 10
...
I181011 00:18:20.414050 2958 storage/store_snapshot.go:657 [n1,raftsnapshot,s1,r33/1:/Table/5{5/1/937/…-6}] streamed snapshot to (n3,s3):2: kv pairs: 427973, log entries: 0, rate-limit: 8.0 MiB/sec, 4408ms
I181011 00:18:20.414647 2958 vendor/go.etcd.io/etcd/raft/raft.go:1094 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 snapshot succeeded, resumed sending replication messages to 2 [next = 11, match = 0, state = ProgressStateProbe, waiting = false, pendingSnapshot = 0]
I181011 00:18:20.416013 2958 storage/store_snapshot.go:615 [n1,raftsnapshot,s1,r33/1:/Table/5{5/1/937/…-6}] sending Raft snapshot 3baea57a at applied index 10
...
I181011 00:18:24.823571 2958 storage/store_snapshot.go:657 [n1,raftsnapshot,s1,r33/1:/Table/5{5/1/937/…-6}] streamed snapshot to (n2,s2):3: kv pairs: 427973, log entries: 0, rate-limit: 8.0 MiB/sec, 4408ms
I181011 00:18:24.824187 412 vendor/go.etcd.io/etcd/raft/raft.go:1030 [n1,s1,r33/1:/Table/5{5/1/937/…-6}] 1 snapshot aborted, resumed sending replication messages to 3 [next = 11, match = 10, state = ProgressStateSnapshot, waiting = true, pendingSnapshot = 10]
Take note of the cannot apply snapshot: snapshot intersects existing range log. I think we've been wondering about these lately. They happen once a second for a range in this state.
This process goes on until the followers finally applies their split command. I'm seeing the difference between the leader applying the command and the followers applying the command range from a few seconds to up to 60! Once the followers finally do apply the split command and execute splitPostApply, something even worse happens - the snapshot request that was being rejected during the initial handshake actually goes through, only to be ignored by each follower with logs like [commit: 10] ignored snapshot [index: 10, term: 5]. So we basically get in a situation where every split results in two 32MB snapshots. I suspect that this is what's slowing the cluster down to the point where we get these 60 second splitPostApply differences between leaders and followers.
There's a lot to decompress here and I'm still trying to figure out what the right fix for this actually is. I think we can start with checking whether a snapshot will be ignored before we accept the snapshot request so that we can avoid wasted 32MB transmissions.
I can't think of any great way to ensure that a follower isn't a little behind on its entry application. That said, being behind by 60 seconds is very surprising. Other that the snapshot attempts themselves being to blame, I don't have a good idea about what could cause these gaps. If the leader was able to apply the split then at least one of the two followers should be a single raft ready iteration away from applying it too. Maybe the commit notification is being delayed because of all of the network traffic related to snapshots? That doesn't sound very plausible. Maybe we're hitting some degenerate locking that's starving the split application on followers?
nvanbenschoten
on 11 Oct 2018
I think we can start with checking whether a snapshot will be ignored before we accept the snapshot request so that we can avoid wasted 32MB transmissions.
I tried this and it didn't seem to make a difference.
nvanbenschoten
on 11 Oct 2018
If the leader was able to apply the split then at least one of the two followers should be a single raft ready iteration away from applying it too.
Turns out this was wrong. I can see both followers in these ranges falling about a minute behind the leader in syncing specific commit indexes and applying them. The one minute period corresponds to the followers trailing the leader by about 2000 commit indices and about 800 unique HardState syncs. The range doesn't start with such a large gap between the leader and the follower and there don't seem to be any events that trigger it, the leader just slowly gets further and further ahead.
nvanbenschoten
on 11 Oct 2018
It's surprising to me that this is possible. I would expect MaxInflightMsgs to put an upper bound on the amount that a follower can trail a leader in terms of its uncommitted Raft log if the follower was part of the quorum. On top of this, I would expect a leader to quickly catch up the commit index of any follower who was part of the quorum through future MsgApps or heartbeats. The fact that they're diverging without bound leads me to believe there's some queuing somewhere, but if that was the case then I would also expect that to have an effect on live traffic because the queuing would also affect proposals.
nvanbenschoten
on 11 Oct 2018
Nice sleuthing. That seems pretty bad. This is a hot range splitting, right?
I tried this and it didn't seem to make a difference.
Still a good change! These discarded snapshots sound terrible.
You say that the followers are just slowly falling behind -- I assume that's during normal operation already? What happens if you throw in a WaitForApplication in the split txn before it commits? That should make sure the catch-up happens before the actual split does. On the flip side, it'll aggressively block the range to writes until the catchup has happened. But as an experiment, that might be worth trying.
I'm also confused why the followers are falling behind in the first place. I always assumed that things that at least one of the followers would have to be up-to-date because it participated in the quorum. Perhaps this is a little taste of the kind of problem #17500 can introduce.
tbg
on 11 Oct 2018
Perhaps surprisingly, the MsgPreVote actually succeeds. withReplicaForRequest lazily creates the replica on the followers upon receiving the message and withRaftGroupLocked and lazily creates the Raft group. The pre-vote succeeds and so does the following vote.
It's definitely kind of surprising, but this is deliberate and required by raft. (As an aside, it would be nice to skip the MsgPreVote in the post-split campaign and go straight to MsgVote)
The leader reacts as expected - it decides both followers need snapshots!
FYI this is exactly the scenario tested in detail in the SplitSnapshotRace tests.
I'm seeing the difference between the leader applying the command and the followers applying the command range from a few seconds to up to 60! Once the followers finally do apply the split command and execute splitPostApply, something even worse happens - the snapshot request that was being rejected during the initial handshake actually goes through, only to be ignored by each follower with logs like [commit: 10] ignored snapshot [index: 10, term: 5]
This is the unexpected part to me. The snapshot protocol has a handshake before any snapshot data is produced that is supposed to determine whether or not the snapshot can be applied. It sounds like we're not doing enough validation in Store.reserveSnapshot and/or canApplySnapshot. We reject snapshots whose application would be an error but we don't check whether the snapshot would be redundant when applied.
I agree that it seems unlikely that the snapshot traffic itself is the reason the nodes are lagging 60s behind. Things like MaxInFlightMsgs also seem unlikely since they're per-replica (what else would be using up the in-flight slots of the LHS of the split?). The raft transport does have some cross-replica limits, but raftSendBufferSize is set pretty high.
bdarnell
on 11 Oct 2018
This is the unexpected part to me. The snapshot protocol has a handshake before any snapshot data is produced that is supposed to determine whether or not the snapshot can be applied. It sounds like we're not doing enough validation in Store.reserveSnapshot and/or canApplySnapshot. We reject snapshots whose application would be an error but we don't check whether the snapshot would be redundant when applied.
We don't have this check, but Raft does. The problem is that this is handled after the snapshot is already streamed to the receiver. My solution was to move an almost identical check into canApplySnapshot so that we can catch the situation early.
The raft transport does have some cross-replica limits, but raftSendBufferSize is set pretty high.
That's my best guess at the moment about where the delay is being introduced, but I don't have any real proof yet. The thing that doesn't really add up is that I wouldn't expect a fixed size buffer to allow peers to slowly drift apart without bound after we hit the limit. It's possible that we haven't hit the limit yet and that the 10000 msg capacity is enough to allow this separation.
nvanbenschoten
on 12 Oct 2018
My current thought is that we could be getting some strange oscilation behavior which slowly causes followers to fall behind because of https://github.com/cockroachdb/cockroach/blob/62c976dafc7f48f0a52142310a8fdc42908c30a5/pkg/storage/raft_transport.go#L468
Testing that out now.
nvanbenschoten
on 12 Oct 2018
Do you have evidence that we're sending super-large batches on the Raft transport?
petermattis
on 12 Oct 2018
Do you have evidence that we're sending super-large batches on the Raft transport?
No, and that theory didn't pan out. I still see all followers slowly fall behind the leader under heavy load.
nvanbenschoten
on 12 Oct 2018
Everything I've written about so far is concerning and deserves continued investigation. It is pretty easy to reproduce with https://github.com/cockroachdb/cockroach/pull/31081 if you disable nobarrier and use Jaeger to watch for long requests. However, I think I've convinced myself that it's not the issue we see here in this test with the stalls because we don't see any of its symptoms in the log. I've opened https://github.com/cockroachdb/cockroach/issues/31330 to continue tracking it.
To recap, we've fixed three separate stalls so far and the test passes reliably for about 2-3 hours of stress. When it does fail, it doesn't stall indefinitely as it did with the other issues. Instead, it stalls for only about 60 seconds. I suspect that the following log explains these 60-second stalls. We see these on n4, which is serving as the SQL gateway in the test, whenever it fails.
E181012 22:26:54.548553 99 sqlmigrations/migrations.go:370 [n4] failed attempt to acquire migration lease: lease /System/"system-version/lease" is not available until at least 1539383274.491341436,0
The logs continue for exactly a minute before going away. These logs originate from EnsureMigrations, and they indicate that the Server is not yet accepting SQL connections. I suspect that the issue here is that we kill a node which has acquired but not yet released thie sql migration lease. To back this up, I see that n2 was killed immediately after logging
I181012 22:26:54.413824 90 cli/start.go:507 initial startup completed, will now wait for `cockroach init`
We then establish a SQL connection to a node stuck trying to acquire this lease and needing to wait for the abandoned lease to expire. I don't have a good solution here in the general case, but there are a few things we could do in the test to fix this and prevent the flake:
- we could round-robin the SQL connection instead of only using a single node that could get stuck
- we could ensure that all nodes can serve SQL connections before begining the chaos monkey
- we could adjust roachprod to wait until server initialization is complete before returning from
roachprod start
I think the second option is the way to go, but I want to make sure it's not undermining the purpose of the test. @petermattis could you weigh in on that? Are we trying to test everything from the server startup process onwards while under chaos?
Also for what it's worth, I only noticed this because I searched for ^E in the logs. I don't think I would have caught it if my branch had included https://github.com/cockroachdb/cockroach/pull/31270. Depending on the outcome of this investigation, we may want to revert that.
nvanbenschoten
on 13 Oct 2018
Interesting. Is it really an inability to get the migrations lease which is causing these 60s stalls? If we disable that code do the stalls go away? Why are we even trying to get the migrations lease? Looks to me like EnsureMigrations only tries to get the lease if there are migrations to run. So what migration hasn't been run given that the cluster is created and only ever using a single version of cockroach?
Of the mitigation options, the second sounds the best.
petermattis
on 13 Oct 2018
I'm also confused why this is happening. Are there really any outstanding migrations? If so, do you see this only just after the cluster got booted up? Something seems fishy here.
tbg
on 13 Oct 2018
If we disable that code do the stalls go away?
I'm testing that right now. I suspect that they will unless there's another class of stalls.
Why are we even trying to get the migrations lease? Looks to me like EnsureMigrations only tries to get the lease if there are migrations to run. So what migration hasn't been run given that the cluster is created and only ever using a single version of cockroach?
It doesn't look like there is any protection against a fresh cluster running these SQL migrations, and I can certianly see all backwardCompatibleMigrations with a workFn run in a fresh cluster if I drop some logging into that area of the code. The cluster will search for migrations keys, find none, and run all available migrations. I supose they should all be quick because they are mostly all no-ops, and it's important that they create migration keys as they complete. @benesch do you know whether this was intentional, an oversight, or somewhere in between?
nvanbenschoten
on 14 Oct 2018
It doesn't look like there is any protection against a fresh cluster running these SQL migrations, and I can certianly see all backwardCompatibleMigrations with a workFn run in a fresh cluster if I drop some logging into that area of the code. The cluster will search for migrations keys, find none, and run all available migrations. I supose they should all be quick because they are mostly all no-ops, and it's important that they create migration keys as they complete. @benesch do you know whether this was intentional, an oversight, or somewhere in between?
It's intentional. I've never liked it much, but we use migrations as a convenient place to run cluster bootstrapping code (i.e., code that must be run at least once when a cluster is first created). For example: https://github.com/cockroachdb/cockroach/blob/396077240ff8bbae6c4327ae78e66d6a4e789d2a/pkg/sqlmigrations/migrations.go#L95-L99
(which I think Tobi added actually 😀)
 benesch
on 14 Oct 2018
benesch
on 14 Oct 2018
Also, even without these "permanent" migrations, fresh clusters still tend to have migrations:
benesch
on 14 Oct 2018
Somehow I thought you said that there was a lease acquired every time a node started, but I just verified (and it seems that you're all implying that) this only happens once at the beginning of a new cluster (assuming all the migrations get applied before something gets killed). I think it's fine if we just work around that then. Should be enough to SELECT 1 in the monkey before going for the kill, right?
tbg
on 15 Oct 2018
Should be enough to SELECT 1 in the monkey before going for the kill, right?
Yeah exactly, and in doing so I've only had a single stall (which was persistent) in the last 36 hours of stressing the test. I'll make that change, fix the proposal forwarding issues now that https://github.com/etcd-io/etcd/pull/10167 is merged, and rebase the test on master to continue the hunt. It's possible we've already fixed this stall, and if not, it appears to be exceedingly rare.
nvanbenschoten
on 15 Oct 2018
Should be enough to SELECT 1 in the monkey before going for the kill, right?
I think it would be sufficient to verify all nodes can serve a SELECT 1 before starting up the test proper. This doesn't have to be done before every node kill, though I suppose that doesn't hurt.
petermattis
on 15 Oct 2018
I was doing it at the beginning of bankState.chaosMonkey, which has the effect you're describing.
nvanbenschoten
on 15 Oct 2018
Yeah exactly, and in doing so I've only had a single stall (which was persistent) in the last 36 hours of stressing the test.
I'm not confident I actually had all of the fix from #31408 in place when I hit this stall, and after ensuring that, I haven't been able to trigger a stall again in more than 24 hours. I'm closing this for now but will keep stressing it for the next few days. We'll see if it ever comes up again.
nvanbenschoten
on 18 Oct 2018
4 days of continuous stress without a failure. I'm declaring this stable.
nvanbenschoten
on 19 Oct 2018
4 days of continuous stress without a failure. I'm declaring this stable.
🎉 🎉 🎉
petermattis
on 19 Oct 2018
Related issues
 intech
·
3Comments
petermattis
·
4Comments
intech
·
3Comments
petermattis
·
4Comments
 ajwerner
·
4Comments
ajwerner
·
4Comments
 richardanaya
·
3Comments
richardanaya
·
3Comments
 HeikoOnnebrink
·
4Comments
HeikoOnnebrink
·
4Comments