Cockroach: sql: upgrade 1.1.8 to 2.0.4 created a large number of schema change rollbacks
When upgrading a cluster from 1.1.x to 2.0.2, a user noticed that a number of new jobs were added to the jobs table. When upgraded, a schema change that had compeleted a month before was rolled back. After each node in the cluster was restarted, the previous roll back was also rolled back. This created a cascade of rollbacks. Right now it doesn't look like this actually did any harm, but it is still indicative of an issue.
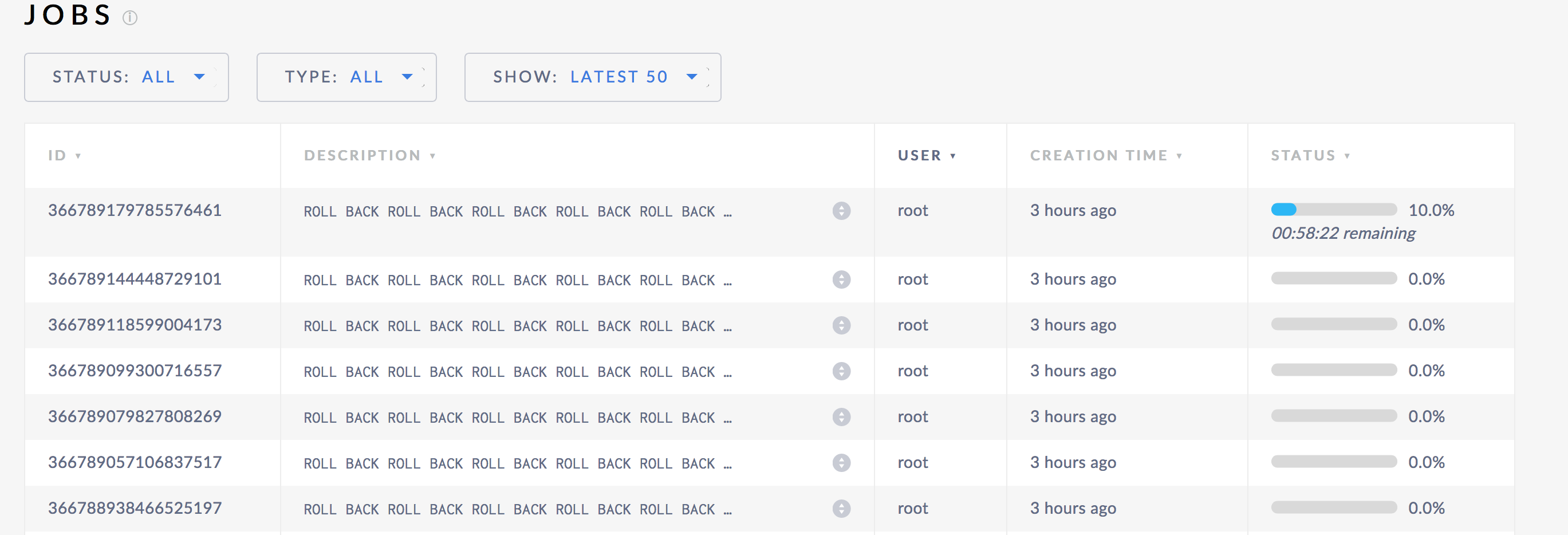
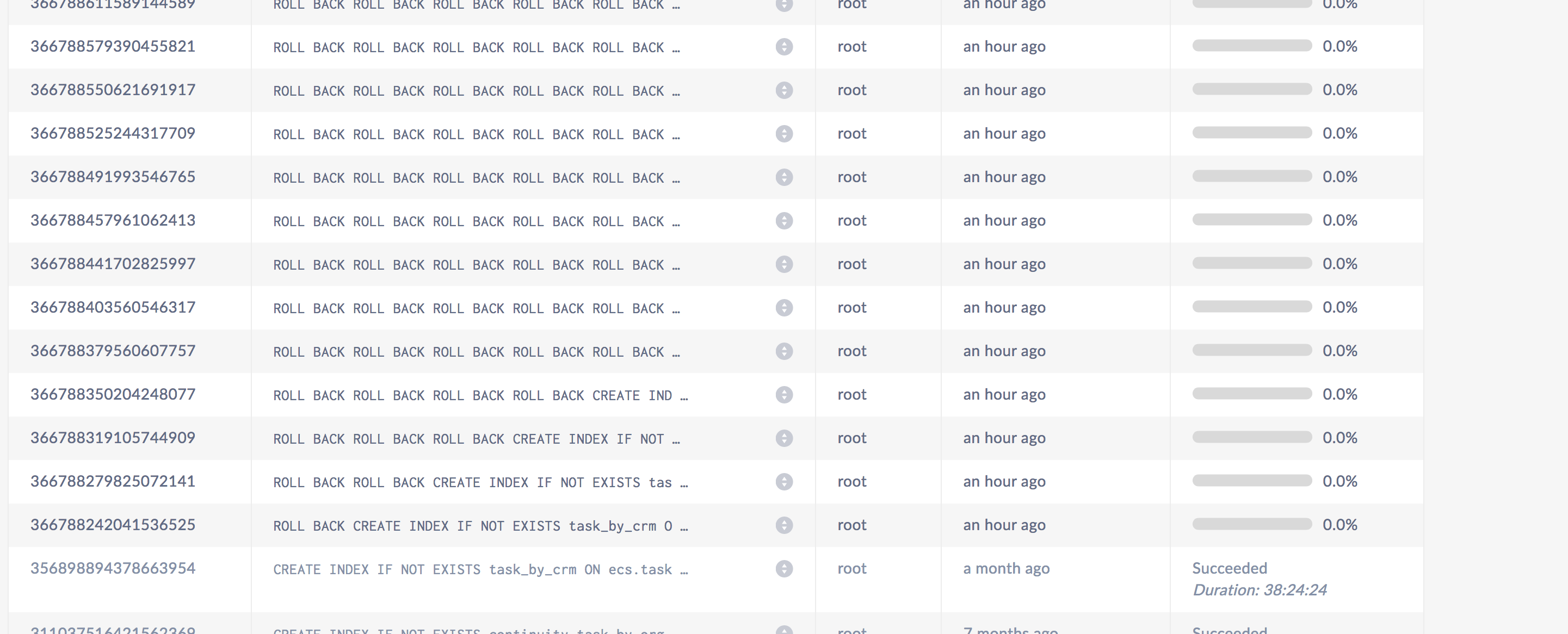
Some logs from grepping for schema:
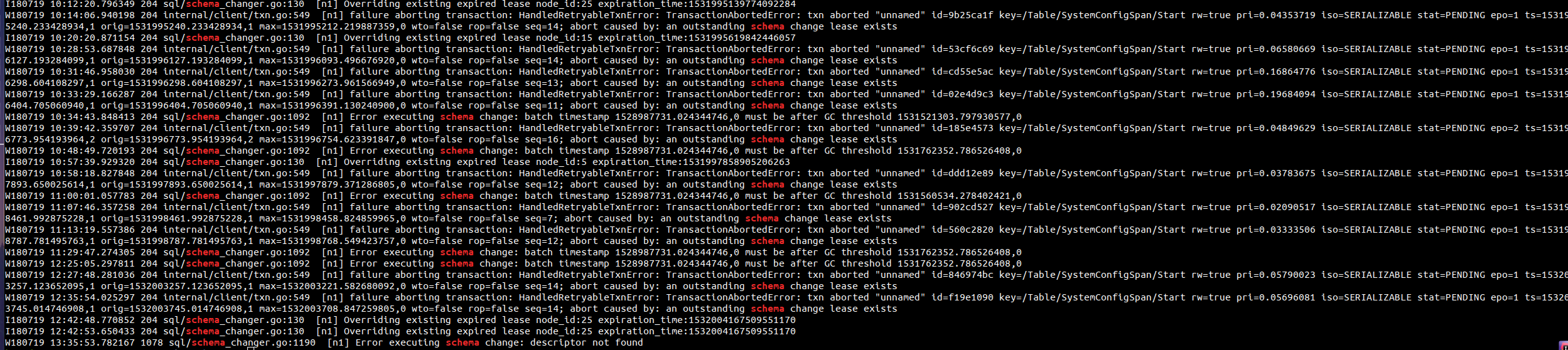
@bsnyder788 could you run debug zip and provide the output? If the data you are storing is sensative then you may not want to publish it publicly or at all, in which case we can still get some targetted information but it might be a bit harder.
cc. @vivekmenezes @mjibson @benesch
 nvanbenschoten
nvanbenschoten
All 28 comments
To clarify: it was an upgrade from 1.1.8 directly to 2.0.4.
 bsnyder788
on 19 Jul 2018
bsnyder788
on 19 Jul 2018
Thanks for the clarification @bsnyder788. Did you see the discussion above about running debug zip?
nvanbenschoten
on 20 Jul 2018
@nvanbenschoten no problem, I did generate a debug zip and read over the page you linked to. Unfortunately for compliance reasons we can't send it. I have no problems getting targeted info for you manually if need be.
bsnyder788
on 20 Jul 2018
this is likely to be similar to #27273 . Let's work on that issue and see if this one gets fixed too.
 vivekmenezes
on 23 Jul 2018
vivekmenezes
on 23 Jul 2018
In the meantime, is there any way for us to safely manually remove these jobs? Possibly manually deleting each one from the system.jobs table?
bsnyder788
on 25 Jul 2018
let me get a working solution so that I can say with confidence that these jobs are dummy jobs. My current thinking is these jobs are indeed dummy jobs . I suspect I'll have an answer for you this week. Sorry for the inconvenience.
vivekmenezes
on 25 Jul 2018
@vivekmenezes what's the path to recovering a cluster that experienced this problem? Is it safe to delete the dummy jobs?
 benesch
on 2 Aug 2018
benesch
on 2 Aug 2018
It's okay for you to delete all these ROLL BACK jobs after you've confirmed that the output of
select * from crdb_internal.schema_changes
is empty.
vivekmenezes
on 2 Aug 2018
@vivekmenezes Indeed, the crdb_internal.schema_changes is empty on our cluster.
Do I just issue a manual deletion for each row of bad data in the system.jobs table to actually remove the dummy jobs or are there other tables that also need to be manually fixed up?
Also, are you planning on back-porting the fix to 2.0.x? I have another index I want to create and would prefer to not have the same situation arise if at all possible when it is created.
Thanks!
bsnyder788
on 2 Aug 2018
@bsnyder788 you can manually delete each row of bad data.
I'm looking at back porting this change to the next 2.0.x
vivekmenezes
on 2 Aug 2018
@vivekmenezes The cleanup definitely works. After cleaning up I tried creating the new index we need and the same thing happened overnight - a bunch of rollback jobs. I cleaned them up again and seems we are still fine (other than not being able to add the index). Let me know if you think you will be able to backport the fix (I saw you closed the first attempt).
bsnyder788
on 3 Aug 2018
@bsnyder788 while I work on figuring out how to patch this into the next release, we need to investigate why your CREATE INDEX is being rolled back. While my fix is not going to result into the ROLL BACK ROLL BACK madness it doesn't fix the underlying problem of why the rollback is happening in the first place? Perhaps you have a record of the jobs table when the rollback occurred. It will contain the error reasons for rollback. Thanks!
vivekmenezes
on 3 Aug 2018

@vivekmenezes That is the error from the one run last night.
bsnyder788
on 3 Aug 2018
It looks like while creating an index the schema change lease didn't get extended for a little more than (1533237264721535799 - 1533236030215253788) nanoseconds > 20 minutes. Why did it happen? We're expecting the lease to be extended every 30 seconds. It's possible that a table scan got stuck forever even though the table is rather small. That might happen on a table with a very large number of deletion tombstones. Can you run SELECT COUNT(*) FROM ecs.public.task and see how much time it takes. I'd appreciate it if you can also report on the size of the table. Thanks!
vivekmenezes
on 3 Aug 2018


bsnyder788
on 3 Aug 2018
@vivekmenezes See the comment above with screenshot from admin UI and cockroach sql client.
bsnyder788
on 3 Aug 2018
@vivekmenezes We tried to create the index one more time to see if we got lucky and the same behavior happened again overnight. The latest message is CREATE INDEX IF NOT EXISTS task_by_crm_synced ON task (crm, synchronized, initiation_time DESC) -> ;pq: span /Table/51/1/"urn:iland:task:2{873798a-bb43-42c5-abb3-12e794a0ac6d"-aa38a5b-edbd-4dbc-801d-cc5bdb9463bb"} not found among [/Table/51/1{-/"urn:iland:task:0705a0ef-54ae-41e0-8268-f6a7f597cdd3"} /Table/51/1/"urn:iland:task:0{74d7c00-5821-4768-9e27-b3823d3cabce"/0-b4245fd-f68e-4ecd-87fd-a2e3a54b5865"} /Table/51/1/"urn:iland:task:0{bae5f7b-3d9f-4635-97c1-441db3d027b0"/0-c920934-5c63-4c15-9673-8e9e53987cd0"} /Table/51/1/"urn:iland:task:{0cf596a3-6043-4c26-b4c3-41ae6bc8abc1"/0-100e971d-dbe2-4423-8d1c-a8b2f7842dad"} /Table/51/1/"urn:iland:task:1{0bd7918-eb8d-40a7-8c92-07050d75611b"/0-554a874-b4f4-4104-a594-1e630ac0d953"} /Table/51/1/"urn:iland:task:1{5c6bd0d-2451-40e6-bf5f-1a1dfb7206e2"/0-ad64472-08d0-4694-bf1c-efec0771374f"} /Table/51/1/"urn:iland:task:{1b187322-5c37-4c62-8d2a-a91fe0418e6a"/0-2873798a-bb43-42c5-abb3-12e794a0ac6d"} /Table/51/1/"urn:iland:task:2{90bebde-2781-4db5-a477-e29194485ee7"/0-aa38a5b-edbd-4dbc-801d-cc5bdb9463bb"} /Table/51/1/"urn:iland:task:{2b5a8491-2e03-4060-9ac6-657ef1dbed7d"/0-31bc105c-96a4-4d7d-95c6-faf3953fa209"} /Table/51/1/"urn:iland:task:{325b2e38-090f-4748-9074-48a43ec3bbf0"/0-42a54ec1-42b3-4ee6-be17-9bcc00f7e88b"} /Table/51/1/"urn:iland:task:4{2dd1d77-9483-4d13-8c8d-7e405c25844b"/0-c5249f5-a6ff-486c-95de-65921bbc1cd3"} /Table/51/{1/"urn:iland:task:4c524d18-589e-4cac-bd9c-ee0e2a16820a"-2}]
bsnyder788
on 7 Aug 2018
@bsnyder788 thanks for the information. I'm looking into it.
vivekmenezes
on 7 Aug 2018
This error is again indicative of a problem with one index backfill taking a very long time to complete. In this case another index backfiller took over and ran a backfill updating the resume span in the backfill checkpoint, and when the main backfiller after having completed after a long delay tried to update the resume span it couldn't find a matching entry to update in the backfill checkpoint.
vivekmenezes
on 7 Aug 2018
@vivekmenezes thanks for checking it. Is there anything we can do in the interim to work around that type of issue. Setting / tweaking a property or something to get our index built?
bsnyder788
on 7 Aug 2018
@bsnyder788 I'm afraid there is no configuration change you can make to work around this. I'm still mystified by the 20 minute delay in the index backfill your system is seeing. If you can run your binaries with more verbose logging -vmodule=backfiller=2,backfill=2,indexbackfiller=2 I'd appreciate it.
There are a couple of avenues I could take here including creating a cluster setting for the schema change lease timeout to work around your problem, but I'd like to understand what's going here. Thanks for your patience
Is there a lot of INSERT/UPDATEs on this cluster?
vivekmenezes
on 7 Aug 2018
I'm creating a PR to create cluster settings to better control your setup. It's just a good thing while I investigate this problem.
vivekmenezes
on 7 Aug 2018
@vivekmenezes Not a lot of updates / inserts - we have around 6-12 steady state upserts per second (according to the admin UI). And we have other tables besides the task one so it should be even less than that on that particular table.
bsnyder788
on 7 Aug 2018
@vivekmenezes any updates on whether some of these fixes will be backported to 2.0.x?
bsnyder788
on 20 Aug 2018
@bsnyder788 that PR makes the most sense for you. With it in the next 2.0 release you should not see your schema change roll back. We'll keep this issue open until you're satisfied. Thanks!
vivekmenezes
on 21 Aug 2018
@vivekmenezes thanks for the update, that sounds good!
bsnyder788
on 21 Aug 2018
@vivekmenezes We built a custom version from latest 2.0.x a few days back after you merged the above fix. We deployed it into our prod. cluster this morning and it instantly picked up the index (we didn't even have to re-add it) and queries are working with the index now. So it looks like this has been resolved! Thanks again for your help and for the quick fix!
bsnyder788
on 23 Aug 2018
Glad it's working well for you. The next major 2.1 release out in October will have all the fixes and is well worth upgrading to. Thanks!
vivekmenezes
on 23 Aug 2018
Related issues
 petermattis
·
4Comments
petermattis
·
4Comments
 intech
·
3Comments
intech
·
3Comments
 HeikoOnnebrink
·
4Comments
HeikoOnnebrink
·
4Comments
 tim-o
·
3Comments
tim-o
·
3Comments
 otan
·
4Comments
otan
·
4Comments