Cockroach: ui: non-table, non-TS ranges not shown on databases page
Bug report
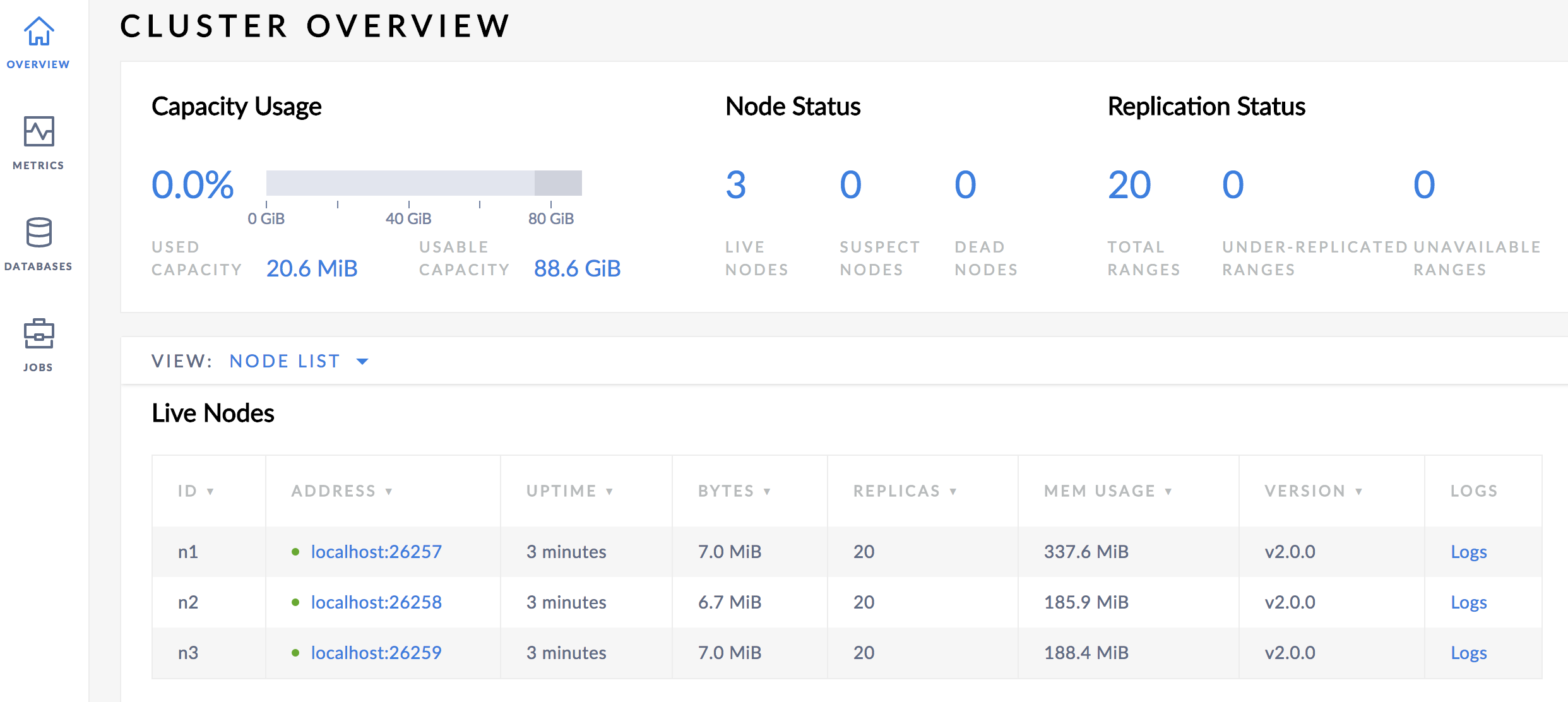
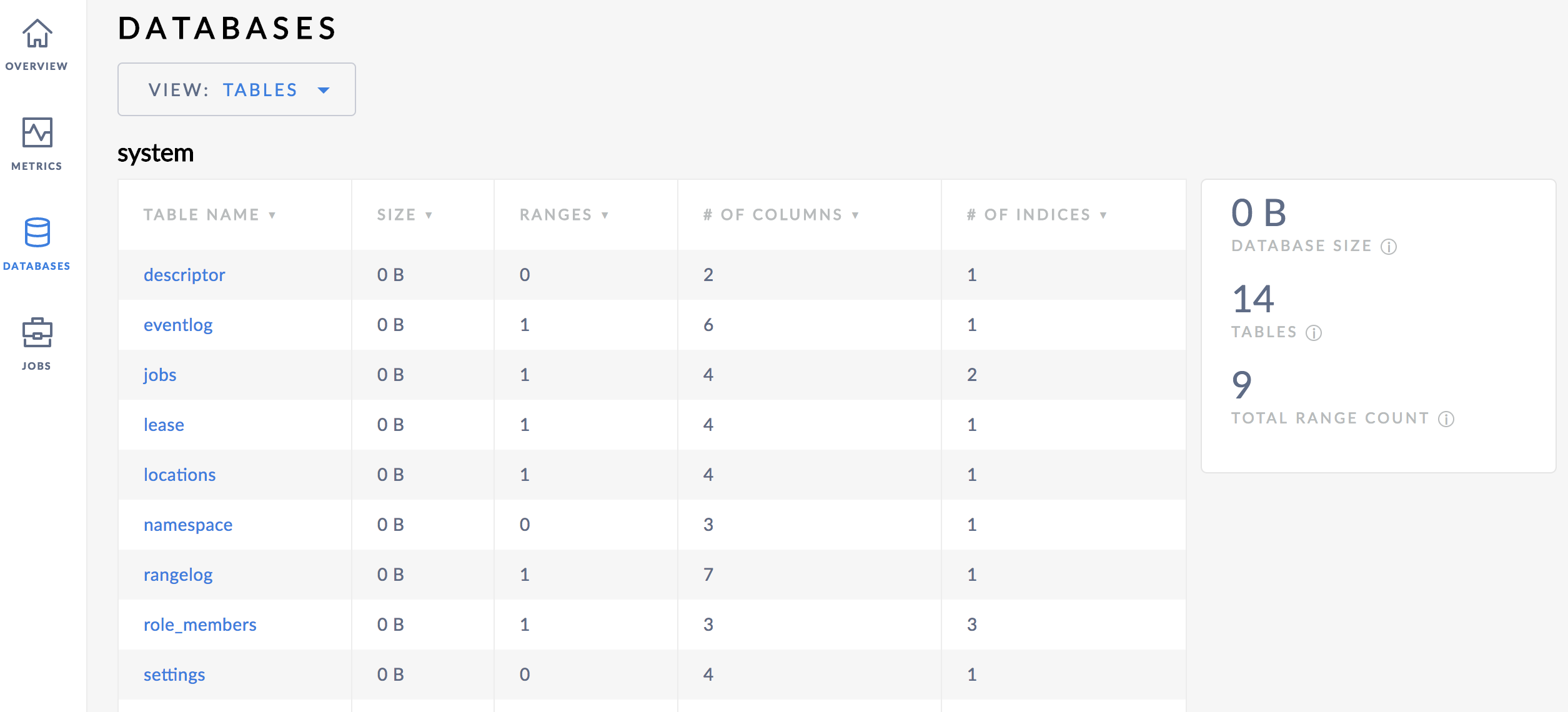
When I first start a 2.0 cluster with 3 nodes, the range count on the Cluster Overview is 20, but the range count on the Databases page is 9 for system and 1 for timeseries.
~/cockroachdb-training$ grep -F '[config]' node1/logs/cockroach.log
I180413 08:19:58.241060 1 util/log/clog.go:1104 [config] file created at: 2018/04/13 08:19:58
I180413 08:19:58.241060 1 util/log/clog.go:1104 [config] running on machine: JESSEs-MacBook-Pro
I180413 08:19:58.241060 1 util/log/clog.go:1104 [config] binary: CockroachDB CCL v2.0.0 (x86_64-apple-darwin13, built 2018/04/03 20:52:33, go1.10)
I180413 08:19:58.241060 1 util/log/clog.go:1104 [config] arguments: [./cockroach start --insecure --store=node1 --host=localhost --port=26257 --http-port=8080 --join=localhost:26257,localhost:26258,localhost:26259]

 jseldess
jseldess
All 7 comments
The underlying issue here is simply that the "Non-Table Cluster Data" table is incomplete. There are seven ranges of non-table cluster data, but only the one time series range is listed here. We should add entries for other types of non-table data; this was briefly discussed in #22398 but no action was taken other than reserving the opportunity.
As an aside, there are also four ranges for table descriptors that aren't actually tables. It would seem that there are always four empty ranges for historical reasons... I'm digging into that now.
 couchand
on 16 Apr 2018
couchand
on 16 Apr 2018
Maybe (some of) the ghost ranges are because each database has an empty range (see #24847)
 vilterp
on 16 Apr 2018
vilterp
on 16 Apr 2018
Oh, I figured it out, but I didn't follow up here. The four extra ranges are for the table descriptors 17, 18, 19, and 22 (a.k.a. MetaRangesID, SystemRangesID, TimeseriesRangesID, and LivenessRangesID in pkg/keys). The descriptors are allocated to support zone configs for these types of system data (see #14740). The ranges are automatically split for them, even though no data is ever really written to them since they don't have actual tables. Some backend work could probably be done to eliminate these empty ranges, but it may be more trouble than it's worth -- we can probably just sweep them up under some kind of general-purpose "internal use" label.
couchand
on 16 Apr 2018
The other ranges not accounted for (besides those four I mentioned above) are all legitimately storing non-table, non-timeseries cluster data, and we should just add accounting for them to the "Non-Table Cluster Data" table.
couchand
on 16 Apr 2018
As mentioned on chat earlier, in clusters where users have dropped tables, all the dropped tables ranges also get left around (although a lot less will get left around after the work on https://github.com/cockroachdb/cockroach/issues/2433 is done).
 a-robinson
on 17 Apr 2018
a-robinson
on 17 Apr 2018
I worry that a solution for this that involves explicit accounting for all the ranges is going to be hard to maintain. Besides it's not clear why a user would care about the specifics unless the range count for some specific system/dropped table was really large. The timeseries data range count is valuable to see separately because sometimes timeseries data can grow by quite a bit. Do you think it makes sense to group everything else into a bucket like "internal"?
 vivekmenezes
on 19 Oct 2018
vivekmenezes
on 19 Oct 2018
That makes sense, and seems to be in line with proposals from the core team: so under "Non-Table Cluster Data", we'll keep Time Series, and then add an additional "Internal use" row, which'll sum up non-table, non-timeseries data.
 celiala
on 22 Oct 2018
celiala
on 22 Oct 2018
Related issues
 bdarnell
·
4Comments
bdarnell
·
4Comments
 rafiss
·
3Comments
rafiss
·
3Comments
 intech
·
3Comments
intech
·
3Comments
 mjibson
·
3Comments
mjibson
·
3Comments
 tim-o
·
3Comments
tim-o
·
3Comments
Most helpful comment
That makes sense, and seems to be in line with proposals from the core team: so under "Non-Table Cluster Data", we'll keep Time Series, and then add an additional "Internal use" row, which'll sum up non-table, non-timeseries data.