Cockroach: Cluster /health endpoint, used by load balancers, cannot respond to HTTP requests, causes LB to fail request
Cockroach Version 1.0.2
As detailed in this documentation bug referenced below, any request to the /health endpoint using http instead of https will fail with a 309 re-direct to the https URL.
https://github.com/cockroachdb/docs/issues/1602
For example, here is a curl request to /health from the local host of a running secure CRDB cluster member.
$ curl -k -i http://0.0.0.0:8080/health
HTTP/1.1 308 Permanent Redirect
Location: https://0.0.0.0:8080/health
Date: Sat, 17 Jun 2017 04:32:44 GMT
Content-Length: 63
Content-Type: text/html; charset=utf-8
<a href="https://0.0.0.0:8080/health">Permanent Redirect</a>.
The impact of this issue, is that some load balancers health checks can only happen over http. Google's TCP (Network) load balancer is the example I am having issues with. Since CRDB is redirecting with a 309 response on every HTTP call, the load balancer sees that as a failed request and marks the host unavailable. This forces removal of the LB health check, and now it will never mark a downed CRDB as being unavailable for use.
A fix would be to answer the health request whether over http or https.
 grempe
grempe
All 11 comments
Thanks for the report, @grempe! It's unfortunate that Google is requiring HTTP-only for its network load balancer health checks, but we might be able to respond to certain endpoints over HTTP even when running in secure mode.
cc @mberhault and @tamird as experts on security and our server code, respectively.
 a-robinson
on 17 Jun 2017
a-robinson
on 17 Jun 2017
Thanks @a-robinson, and nice meeting you at the CRDB meetup last evening.
grempe
on 17 Jun 2017
Responding to /health over HTTP is fine from a security perspective as long as we can make it work with our serving stack (i.e. as long as the 308 response is coming from somewhere we control instead of deep in some third-party library).
 bdarnell
on 19 Jun 2017
bdarnell
on 19 Jun 2017
One thing to consider: the single-zone TCP load balancer does not support HTTPS (or anything other than HTTP), but the multi-zone TCP load balancer does. It's a bit more tedious to set this up since it requires instance groups (which requires instance templates) but it seems like it would be a reasonable solution.
I believe the single-zone TCP-level LB also caused us problems a while back due to the weird network-level magic it does, but I haven't checked in a while.
I'll try to set it up on our existing cluster (if possible) or create a new one, then see what quirks are needed for proper configuration.
 mberhault
on 19 Jun 2017
mberhault
on 19 Jun 2017
Ok, I can confirm that it works.
You can setup a multizone TCP-level load balancer which uses the newer health checks, including HTTPS.
It was a bit tedious for me to setup since we don't use instance groups, so I had to create separate unmanaged instance groups for each zone, add the instances to the group in the right zone, then add each instance group as a backend to the load balancer.
I added the following health check:
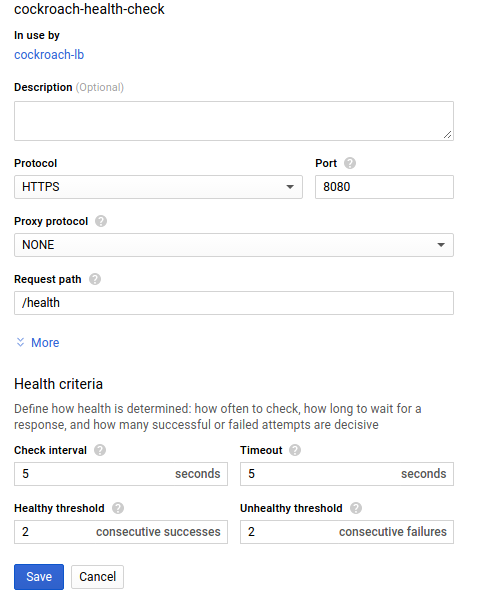
The load balancer shows all instances healthy, and talking sql to the load balancer landed me on different instance (I saw that by looking at the count of sql connections on each instance).
Given how limited the single-zone TCP load balancer is, and the fact that the multi-zone TCP load balancer has HTTPS health checks, I don't think this is much of a priority and would recommend just staying away from the old-school GCE load balancer.
mberhault
on 19 Jun 2017
Responding to /health over HTTP is fine from a security perspective as long as we can make it work with our serving stack (i.e. as long as the 308 response is coming from somewhere we control instead of deep in some third-party library).
Yes, we control this behaviour. I'll work up a PR to allow responding to /health over HTTP.
 tamird
on 19 Jun 2017
tamird
on 19 Jun 2017
Thanks @tamird !
If you were to ballpark it, how long until this shows up in a release? (I won't hold you to it!)
grempe
on 19 Jun 2017
Probably a while, since it'll be in 1.1 unless we decide to cherry-pick it
to 1.0.x. @bdarnell?
On Mon, Jun 19, 2017 at 5:02 PM, Glenn Rempe notifications@github.com
wrote:
Thanks @tamird https://github.com/tamird !
If you were to ballpark it, how long until this shows up in a release? (I
won't hold you to it!)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/cockroachdb/cockroach/issues/16578#issuecomment-309572797,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ABdsPJj5zJQoxqfkHLFE73T1wqZRFlDgks5sFuH-gaJpZM4N9IN-
.
tamird
on 19 Jun 2017
Yeah, I think this'll be in 1.1.
bdarnell
on 19 Jun 2017
In other words, end of September / early October.
It'll be available in alpha releases before that, but those are of course not fully vetted for production use.
a-robinson
on 19 Jun 2017
OK. Thanks for being so responsive for the fix. I have also built a little proxy server to run as a sidecar image on that host which will translate an HTTP request into the HTTPS request for /health on the local host (not tested yet). I'll look into the other flavor of load balancer as helpfully tested above as well.
It would be nice to get the fix in sooner as your docs will be broken until fixed as well.
grempe
on 19 Jun 2017
Related issues
 danhhz
·
3Comments
danhhz
·
3Comments
 tim-o
·
3Comments
tim-o
·
3Comments
 melskyzy
·
3Comments
melskyzy
·
3Comments
 nvanbenschoten
·
3Comments
nvanbenschoten
·
3Comments
 intech
·
3Comments
intech
·
3Comments