Cluster-api: Possible memory leak with remote cluster cache tracker
What steps did you take and what happened:
- Create a management cluster
- Create lots of workload clusters
- Watch metrics and pprof heap output
process_resident_memory_bytesgets really big (such as9.303556096e+09- 9gb!), pprof shows a lot of memory sticking around from REST mappers, which are created by the remote cluster caches.
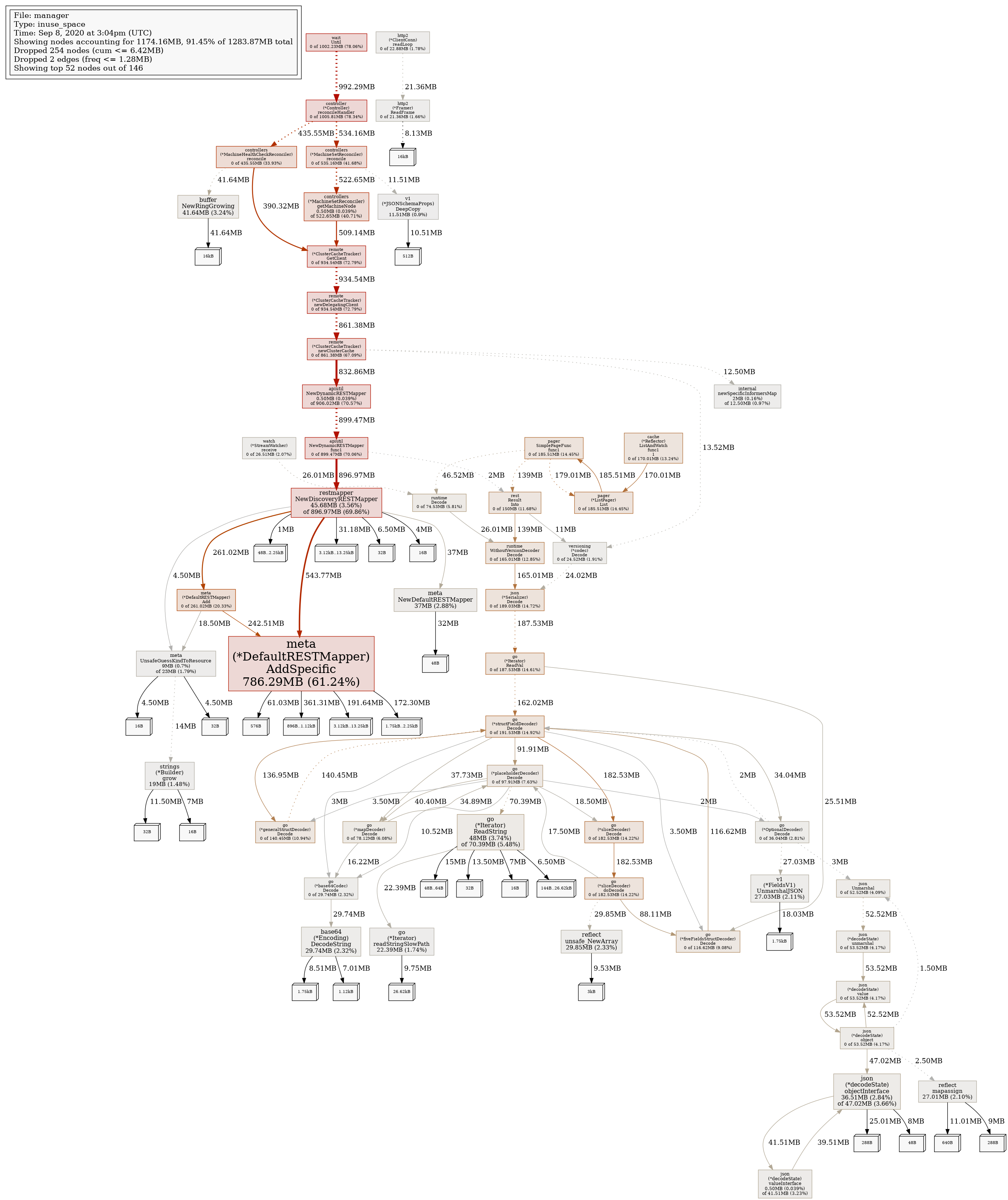
What did you expect to happen:
- Stable memory
Anything else you would like to add:
We do periodically delete & recreate remote cluster caches/clients if they fail health checks and/or when a cluster is deleted, but we shouldn't be leaking data from the REST mappers.
Environment:
- Cluster-api version: v0.3.9
/kind bug
cc @fabriziopandini @yastij as you are helping look into this
 ncdc
ncdc
All 8 comments
I think we may be seeing the increase with every resync, but I'm not certain of that
ncdc
on 8 Sep 2020
FYI https://github.com/kubernetes-sigs/cluster-api/issues/3610 << we are failing health checks and continuously delete/recreate caches (with the related REST mappers).
TBD if this is related to the memory consumption described in this issue
 fabriziopandini
on 8 Sep 2020
fabriziopandini
on 8 Sep 2020
/milestone v0.3.10
/assign
 vincepri
on 9 Sep 2020
vincepri
on 9 Sep 2020
The 3 PRs merged above help significantly. There is probably still a real memory leak when a client+cache+watches are deleted from the cluster cache tracker, but #3615 fixes the initial, most critical problem; namely, that the client+cache+watches were constantly being deleted & recreated due to the broken health check.
ncdc
on 11 Sep 2020
I have 1 more PR coming to simplify some aspects of the tracker (and avoid some possible deadlocks), and congrats to @vincepri who has root-caused the memory leak. It's actually in controller-runtime. Vince is prepping a PR and we'll link to it once it's open.
ncdc
on 15 Sep 2020
ncdc
on 15 Sep 2020
I think it's ok to close this now that #3615 and #3646 have merged.
/close
ncdc
on 16 Sep 2020
@ncdc: Closing this issue.
In response to this:
I think it's ok to close this now that #3615 and #3646 have merged.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 16 Sep 2020
k8s-ci-robot
on 16 Sep 2020
Related issues
 mboersma
·
5Comments
mboersma
·
5Comments
 timothysc
·
6Comments
timothysc
·
6Comments
 alexeldeib
·
4Comments
alexeldeib
·
4Comments
 wfernandes
·
5Comments
wfernandes
·
5Comments
 invidian
·
5Comments
invidian
·
5Comments