Client: "All the local files deleted" -- wrong?
Hello,
We had a case today of a user who got this message:
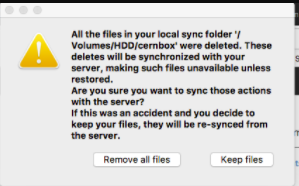
We suspect that was triggered by a transient problem on our server. However, local files were all good and not removed. Also his files on the server were all OK. The user chose "Keep" and all was good.
The problem: this message is clearly wrong -- all local files were there.
In order to understand how to fix this message: what exactly is the condition that triggers this message? https://github.com/owncloud/client/blob/master/src/libsync/syncengine.cpp#L1020
Is it absence of local files in the sync folder?
Is it a PROPFIND response with xml body but no content in it? Is it a PROPFIND response with no body (0 content length)?
Any combination of the above?
 moscicki
moscicki
All 30 comments
This happens if all the files were changed, and at least one of them is removed.
The detection of local vs. remote in that case might be bogus.
This may very well happen if the PROPFIND has no contents, yes.
 ogoffart
on 19 Jan 2018
ogoffart
on 19 Jan 2018
@ogoffart We could at least have two versions of this dialog: all remote files seem to change vs all local files seem to change?
 ckamm
on 22 Jan 2018
ckamm
on 22 Jan 2018
@ckamm there's already two versions:
What I was thinking about the other day is whether the dialog can close by itself (in case of server-deletion) when we (implement a way to and) detect it was indeed a bogus PROPFIND.
 SamuAlfageme
on 22 Jan 2018
SamuAlfageme
on 22 Jan 2018
How can we detect bogus propfinds? As a general principle we should make sure that this message is triggered only after a positively verified reply from the server which cannot be generated by accident such as a proxy stripping down content from the response etc.
moscicki
on 22 Jan 2018
@SamuAlfageme Oh, thanks for showing that. That means @moscicki's slotAboutToRemoveAllFiles got triggered with SyncFileItem::Up. If the only thing that happenend was a PROPFIND having no items we should have observed Down.
Now, the logic isn't particularly sophisticated and just takes the direction of the very first syncitem so there are cases where it still might have been caused by that kind of issue.
Also note that a PROPFIND reply without a body would be rejected. It must at least start with some valid xml. I'll add a test that checks whether truncated responses will be accepted as valid.
Edit: Yes, truncated responses are also considered invalid.
ckamm
on 22 Jan 2018
I can reproduce this situation with the client now. Do you want to check the client logs / tcpdump traffic to the proxy? I would need to communicate these out-of-bound as it contains real user filenames etc.
After first inspection I don't see anything particularly wrong with the propfinds...
moscicki
on 22 Jan 2018
@moscicki Yes please! A full log with --logdebug would probably be sufficient. mail at ckamm de.
ckamm
on 23 Jan 2018
I did more investigation on this. It is not that simple. I will provide you with the logs soon but first let me explain.
This event happens when I reconfigure my cernbox client to talk via a proxy that runs a newer version of nginx. Everything else is the same on the storage server. So when I change the https endpoint to the new proxy then I eventually get this problem after the initial scan after restart. This happens for my normal account which I use as a user (so I can reproduce the original user problem that appeared for someone else).
But this is not all. I did a test with a fresh sync folder (my other test user account). I cannot reproduce this. So it ALSO has to do with the state of the local syncdb that I have as a normal user.
I also suspected that this could be related to the upgrade path of the syncdb from older client version. So I re-tested everything on a fresh account. First running against the current nginx (working) proxy with version 1.7.2. Then restarted with 2.1.1. 2.2.4 and finally 2.3.3. At that point I reconfigured to the new proxy and hoped to see the problem. Nope.
So in summary: it has to do both with newer nginx proxy version at the endpoint AND statedb but not trivially reproducible.
moscicki
on 26 Jan 2018
Finally, I reconfigured the new proxy machine to downgrade to the older nginx version that we currently use in prod. When I make this flip in the config file everything is fine. This is just to re-confirm that we can flip between these two server proxy endpoint transparently for the user IF they run exactly the same nginx version.
moscicki
on 26 Jan 2018
@moscicki Thanks for the investigation. It sounds like it will be tricky to nail down but I'm up for digging through the logs to see whether I can spot something.
ckamm
on 29 Jan 2018
@moscicki Were you able to reproduce and capture logs? (remember --logdebug)
ckamm
on 20 Feb 2018
@ckamm: yes, please give few more day. it is not forgotten.
moscicki
on 21 Feb 2018
@ckamm: log sent by email -- thanks!
moscicki
on 26 Feb 2018
@moscicki The log shows a normal reconcile client side, but all remote files get tagged as "UPDATE_METADATA". This tag is set if either the permissions or the file_id changed. The log prints the discovered and the db permissions and they look identical. So presumably the file_id changed.
The log contains the discovered file_id: and that is the empty string for all entries (lots of [file_id= size=...])! This string should be coming directly from the "id" property of the PROPFIND responses. Can you check whether that's set correctly for your different nginx setups?
This would explain why you can't reproduce with a fresh sync folder: If all file_ids were empty from the start, no UPDATE_METADATA would occur. But missing file_ids is a bug, it will make remote rename detection not work at all.
ckamm
on 27 Feb 2018
While the particular cause is quite likely a bug with the server setup, the code looks like UPDATE_METADATA should already be equivalent to NONE for the purposes of issuing this warning. Apparently there's a bug there too.
EDIT: Not a bug. That behavior was introduced in 2.4.0 by @ogoffart with 800b9cf167092ff86e14929d1de85d0df523e22a - so with a newer client version you wouldn't be getting these warnings.
ckamm
on 27 Feb 2018
Thanks a lot for your input -- it was very helpful. I think I understand what happened.
Nginx proxy misconfiguration was stripping the request body of PROPFIND. In that case it is equivalent to allprop, according to RFC4918 (https://tools.ietf.org/html/rfc4918#page-35):
A client may choose not to submit a request body. An empty PROPFIND
request body MUST be treated as if it were an 'allprop' request.
However, allprop is not required to return all properties:
Note that 'allprop' does not return values for all live properties.
and
The semantics of PROPFIND 'allprop' (Section 9.1) have been
relaxed so that servers return results including, at a minimum,
the live properties defined in this specification, but not
necessarily return other live properties
Hence, a webdav-compliant server will not be robust in such a case and may leave out oc:id property out of the response. That's precisely what happened.
I am not sure if it can even be classified as a software bug because the behaviour is according to the spec. This is yet another proof that webdav is really a bad protocol choice (especially for synchronization).
moscicki
on 28 Feb 2018
What is exactly the effect of the 2.4.0 patch 800b9cf by @ogoffart ?
moscicki
on 28 Feb 2018
Nginx proxy misconfiguration was stripping the request body of PROPFIND.
Is that valid according to the spec? Can a proxy just strip the request body?
What is exactly the effect of the 2.4.0 patch 800b9cf
Not to show the "All local file deleted" warning when metadata have changed for all files.
Here the reason they all change is because the fileid was changed for all files, but another reason might be because a permission of flag is added in a new version of the server and is added to all files. This warning should only be shown when the etag has changed for all files.
ogoffart
on 28 Feb 2018
@moscicki I'd add a check to the client for whether the critical properties have actually been retrieved by the PROPFIND.
ckamm
on 28 Feb 2018
Clearly the problem was the reverse proxy misconfiguration. Thanks to your help we understood the problem to the bottom -- thank you.
My rant on webdav is that it is not robust as such. One has to make protections and actually provide a much stricter (application-specific) specification on top of it to make it robust.
Adding property check in the client is a very good idea. Thanks!
moscicki
on 28 Feb 2018
 guruz
on 1 Mar 2018
guruz
on 1 Mar 2018
mint linux tara
client-2.5.0~beta1, demo.powncloud.org, no proxies.
Reproduced today with demo.owncloud.org -- this system resets itself each hour, and the reset just triggered this. I am afraid, I cannot re-trigger it intentionally.
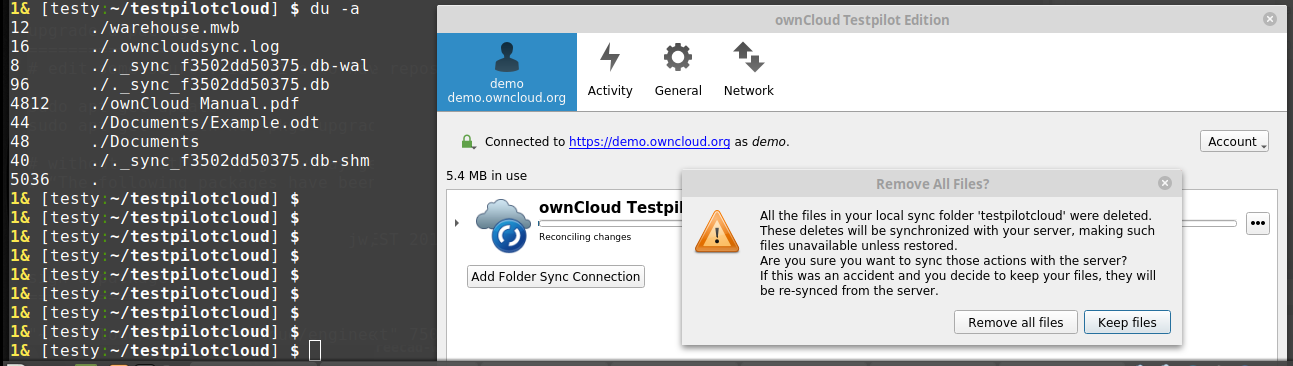
It claims that all my local files are gone, while they still exist.
BAD there still seems to be one codepath that leads to the false popup.
@ogoffart this should not be possible, if I understood correctly what you said about https://github.com/owncloud/client/commit/800b9cf167092ff86e14929d1de85d0df523e22a
 jnweiger
on 10 Aug 2018
jnweiger
on 10 Aug 2018
The popup is good here. Since the server was reset, we don't want to delete all the files locally. (And re-download the default files)
What might be confusing is the fact that it mention the local sync folder, while in fact, it is the other way. But the detection of which part was removed is a bit tricky. It is possible that you also deleted or modified files locally.
ogoffart
on 10 Aug 2018
We know that the current wording adds more detail than we actually have. How about broadening it like this:
"All files were either deleted in your local sync folder $DINGENS or on the server. These deletes will be synchronized everywhere making such file unavailable unless restored. Are you sure ..."
But it is strange that the client cannot distinguish on which end the deletion was. One successful stat() could reveal that we still have some files locally.
jnweiger
on 10 Aug 2018
@jnweiger Does the demo.owncloud.org reset everything and re-installs or just wipes some data? I wonder if the data fingerprint is changing. (...this does not reproduce the original issue that @moscicki saw btw).
@ogoffart How is this influenced by https://github.com/owncloud/client/pull/6674 ? (which is not in beta1)
Wouldn't @jnweiger get a better message in that case?
guruz
on 10 Aug 2018
@guruz I think you are confusing the backup restoration feature and the server reset ("all file deleted" feature. These are two unrelated things. Backup restoration happens only when the data finger print is changed. (and indeed, this feature is broken in 2.5 currently, #6674 fixes it, but is completely unrelated to this).
What happens here is that the etag of all files in the server is changing. So the client correctly detects that something is fishy and ask the question to the user.
ogoffart
on 10 Aug 2018
@ogoffart Wouldn't we want the same for newly installed servers?
CC @PVince81
guruz
on 10 Aug 2018
afaik demo.owncloud.org disappears, and a completely new server is instantiated.
But as a user: whatever happens to the server just happens outside his scope.
The scenario is, that the user has the only remaining copy of the files locally, and the client tries to confuse the user with false statements. This is calling for user errors.
jnweiger
on 10 Aug 2018
@jnweiger As an user, if the server disappear, i don't want to loose all my data. That's why the client is asking if it is correct that one wants to delete all the data.
The only thing that's broken is the detection that the data was removed remotely rather than locally.
ogoffart
on 13 Aug 2018
@jnweiger I made a fix for the dirrection detection so the wording should be more accurate
--> #6706
(Anyway, this is not the same issue as the one from the original task, so let's follow the issue on the PR)
ogoffart
on 14 Aug 2018
Related issues
 michaelstingl
·
5Comments
michaelstingl
·
5Comments
 dartcafe
·
4Comments
dartcafe
·
4Comments
 ogasser
·
4Comments
ogasser
·
4Comments
 ctrlbru
·
5Comments
ctrlbru
·
5Comments
 xmana
·
5Comments
xmana
·
5Comments
Most helpful comment
Thanks a lot for your input -- it was very helpful. I think I understand what happened.
Nginx proxy misconfiguration was stripping the request body of PROPFIND. In that case it is equivalent to allprop, according to RFC4918 (https://tools.ietf.org/html/rfc4918#page-35):
However, allprop is not required to return all properties:
and
Hence, a webdav-compliant server will not be robust in such a case and may leave out oc:id property out of the response. That's precisely what happened.
I am not sure if it can even be classified as a software bug because the behaviour is according to the spec. This is yet another proof that webdav is really a bad protocol choice (especially for synchronization).