Clickhouse: Throttle recovery speed
We're in a process of migration from older hardware under ClickHouse to the newer generation.
Older machines have 12x6T disks, 128GB RAM and 2x10G NICs, newer machines have 12x10T disks, 256GB RAM and 2x25G NICs. Dataset per replica is around 35TiB. Each shard is 3 replicas.
Our process is:
- Stop one replica from shard.
- Clear it from zookeeper.
- Remove it from cluster topology (znode update for
remote_servers). - Add new replica to cluster topology.
- Start new replica and let it replicate all the data from peers.
The issue we're seeing is that source replicas saturate disks, starving user queries and merges.
It takes ~7h to replicate full dataset, below are the graphs for 12h around that time:
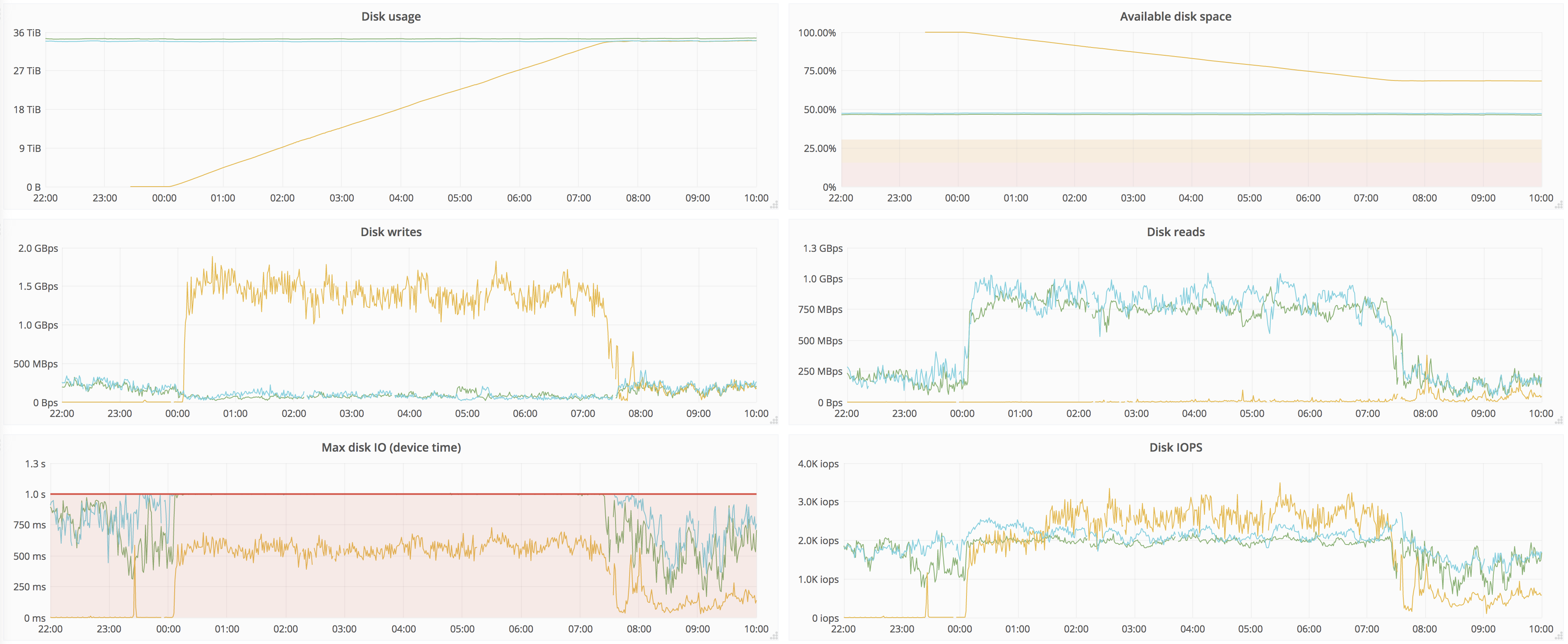


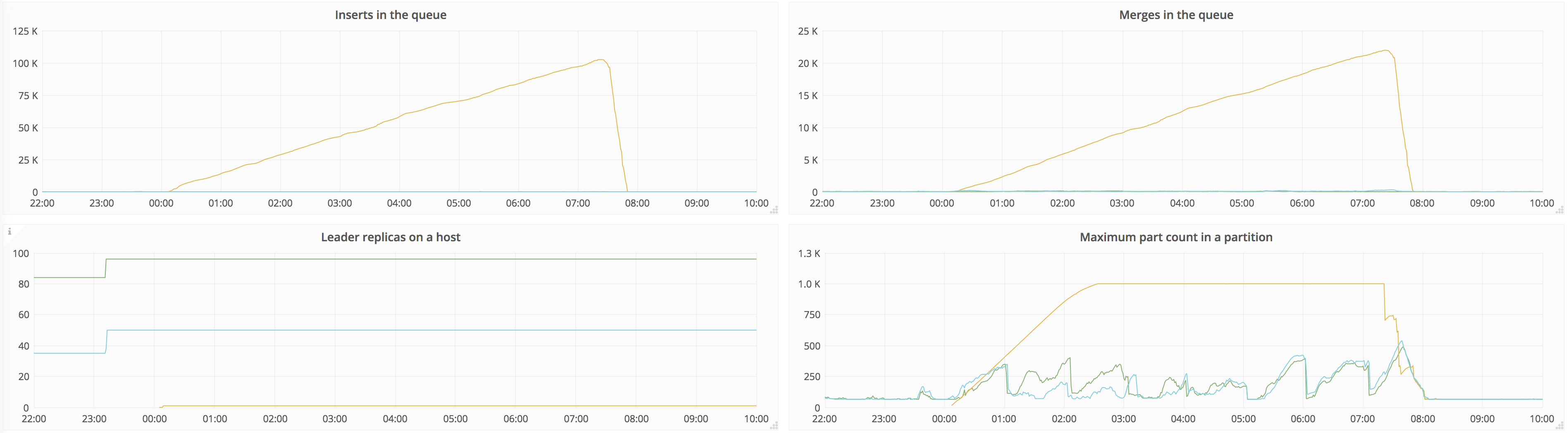

Source peer:
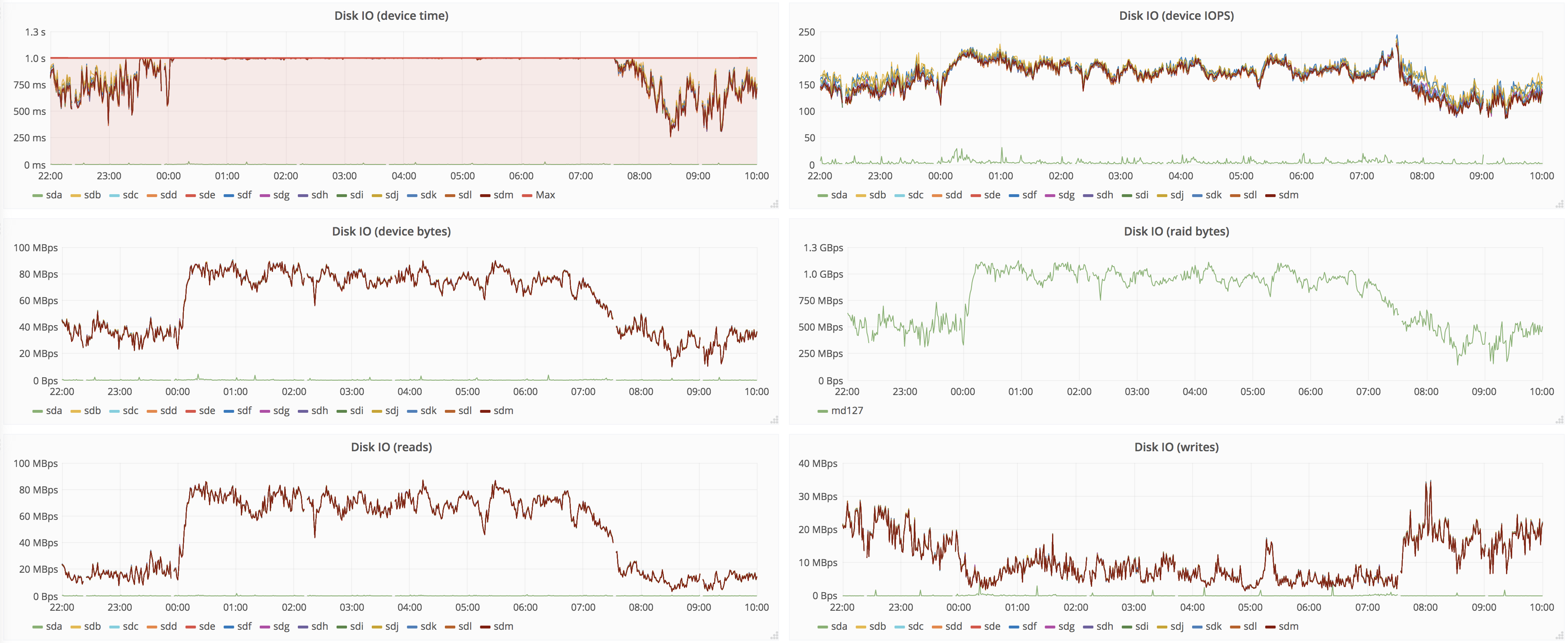
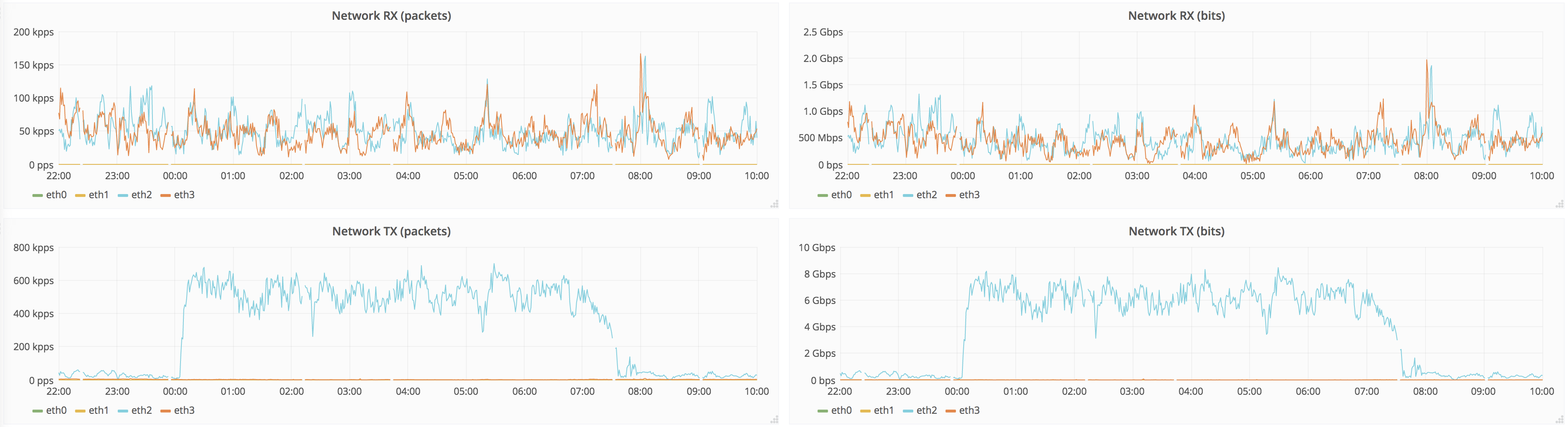
Target peer:
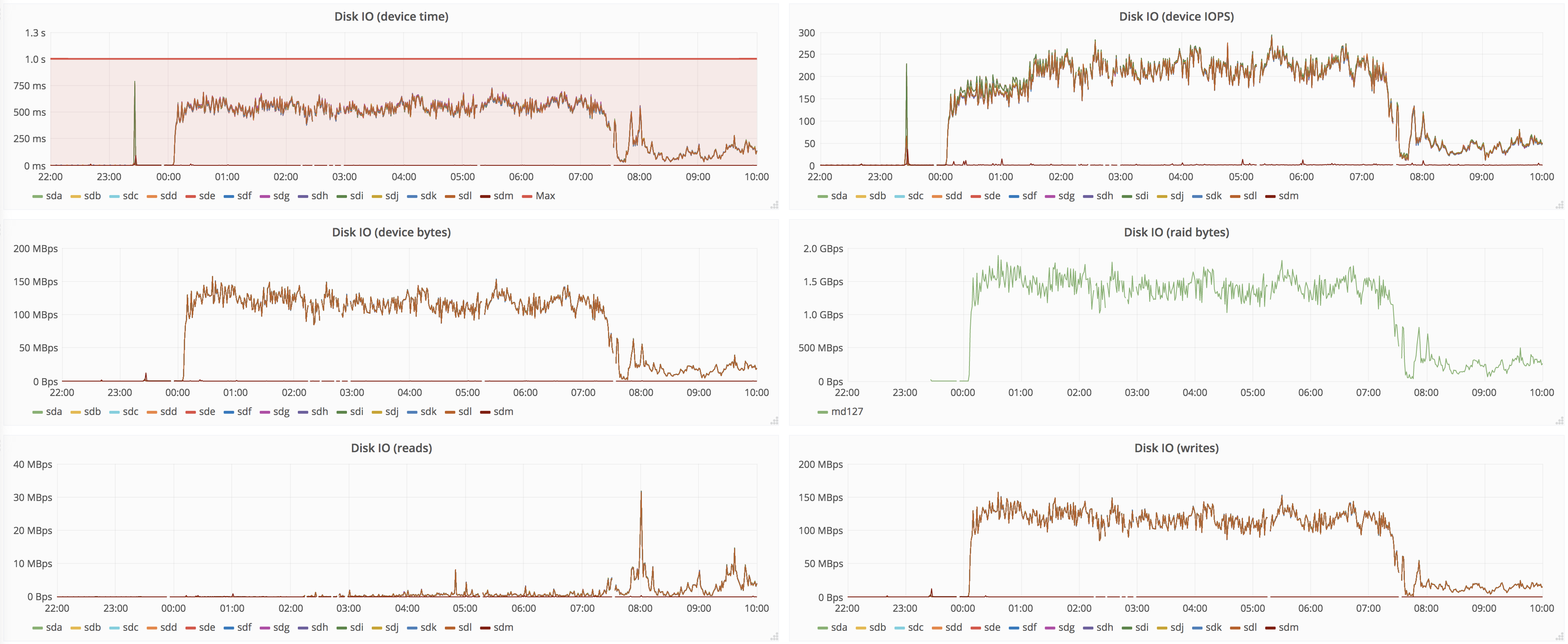
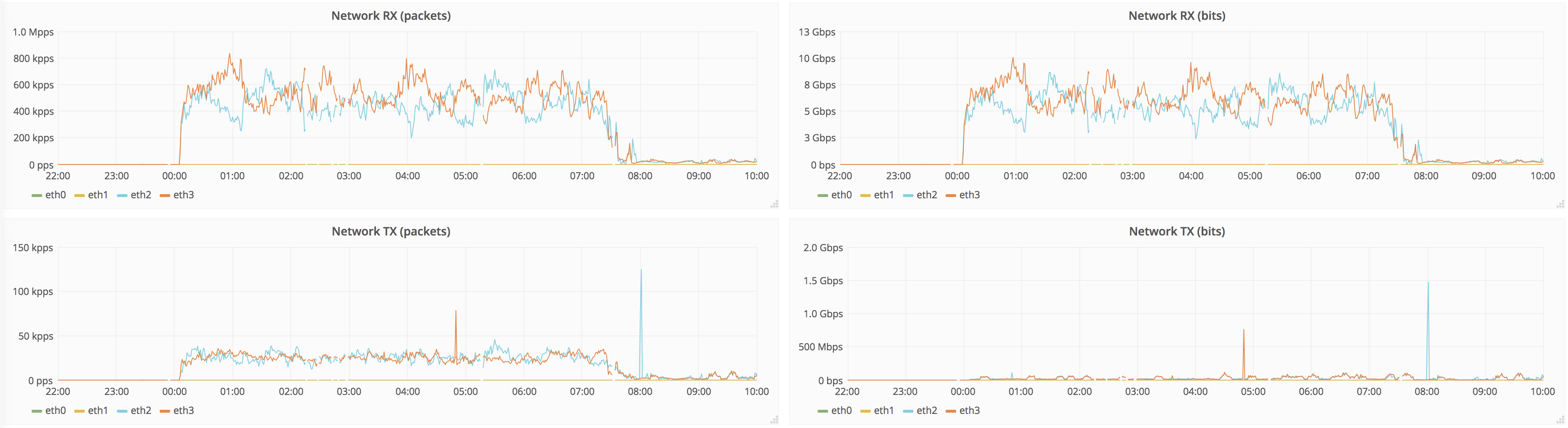
Naturally, source peers are not great at IO in the first place (that's why we're upgrading), but having 7h of degraded service is not great. It'd be nice to be able to set recovery speed, so it doesn't starve other activities like user queries and merges.
Moreover, max number of parts in partition quickly reaches the max (we set to 1000) on the target replica, where inserts are throttled, which doesn't make things any better. With throttled recovery at lower speed but with higher duration, this will probably be even longer period. Maybe we should split threads that do merges and threads that do replication, it seems like whole pool is busy just replicating.
It is also possible that we're just doing it wrong, then it'd be great to have a guide describing the process.
cc @vavrusa, @dqminh, @bocharov
 bobrik
bobrik
All 6 comments
If anyone stumbles on this issue, we worked around it by throttling 50G interface to 4G-8G with comcast tool, depending on disk performance:
./bin/comcast --device vlanXYZ --stop; ./bin/comcast --device vlanXYZ --packet-loss=0% --target-bw $((4 * 1000 * 1000)
Linux is still not great at throttling ingress, so this has to be run on source replicas.
bobrik
on 29 Jan 2018
Looks like you have successfully went through this.
 blinkov
on 13 Sep 2018
blinkov
on 13 Sep 2018
Limit on number of connections and throttling of recovery speed is actual task.
 alexey-milovidov
on 13 Sep 2018
alexey-milovidov
on 13 Sep 2018
 filimonov
on 12 Mar 2019
filimonov
on 12 Mar 2019
+1, running into similar issues when adding/replacing nodes during our tests, any ETA on the fix?
 xichen2020
on 30 Apr 2019
xichen2020
on 30 Apr 2019
Surprisingly, it affects our hypervisors during deploy of new nodes as well... Would like to see either speed or threads limitation
 Felixoid
on 11 Jun 2019
Felixoid
on 11 Jun 2019
Related issues
 zhicwu
·
3Comments
zhicwu
·
3Comments
 igor-sh8
·
3Comments
igor-sh8
·
3Comments
 derekperkins
·
3Comments
derekperkins
·
3Comments
 atk91
·
3Comments
atk91
·
3Comments
 lttPo
·
3Comments
lttPo
·
3Comments
Most helpful comment
If anyone stumbles on this issue, we worked around it by throttling 50G interface to 4G-8G with
comcasttool, depending on disk performance:Linux is still not great at throttling ingress, so this has to be run on source replicas.