Ckeditor5: Pressing "Spacebar" twice at empty paragraph inserts only one space
Steps to reproduce
- Create a new empty line.
- Press Spacebar twice.
Current result
Space was inserted only once.
Expected result
Space should be inserted on every Spacebar press.
Other information
OS: Windows 10, MacOS X, Ubuntu 16.04
Browser: Chrome, Safari, Edge, Firefox
Release: 0.10.0
 Mgsy
Mgsy
All 19 comments
It indeed stopped working.
 Reinmar
on 21 Jun 2017
Reinmar
on 21 Jun 2017
The reason for that is that a normal space is rendered at the beginning of the block:

And natively you get hard spaces at both ends:

Reinmar
on 25 Jul 2017
It's broken since [email protected].
Reinmar
on 28 Jul 2017
But it worked in v0.7.0 because we didn't handle nbsps at all. So in v0.8.0 we introduced nbsps cleanup.
Reinmar
on 28 Jul 2017
Interestingly, Chrome doesn't render the spaces in a most optimal way and it's surprisingly unsymmetrical (compare 3 spaces before and after the letter):

Reinmar
on 28 Jul 2017
Firefox implements a rendering hack and allows putting the selection after a space which shouldn't be visible:

Reinmar
on 28 Jul 2017
In fact, FF is funny:

Reinmar
on 28 Jul 2017
This is really tricky. There must never be a nbsp before a letter because this may happen:
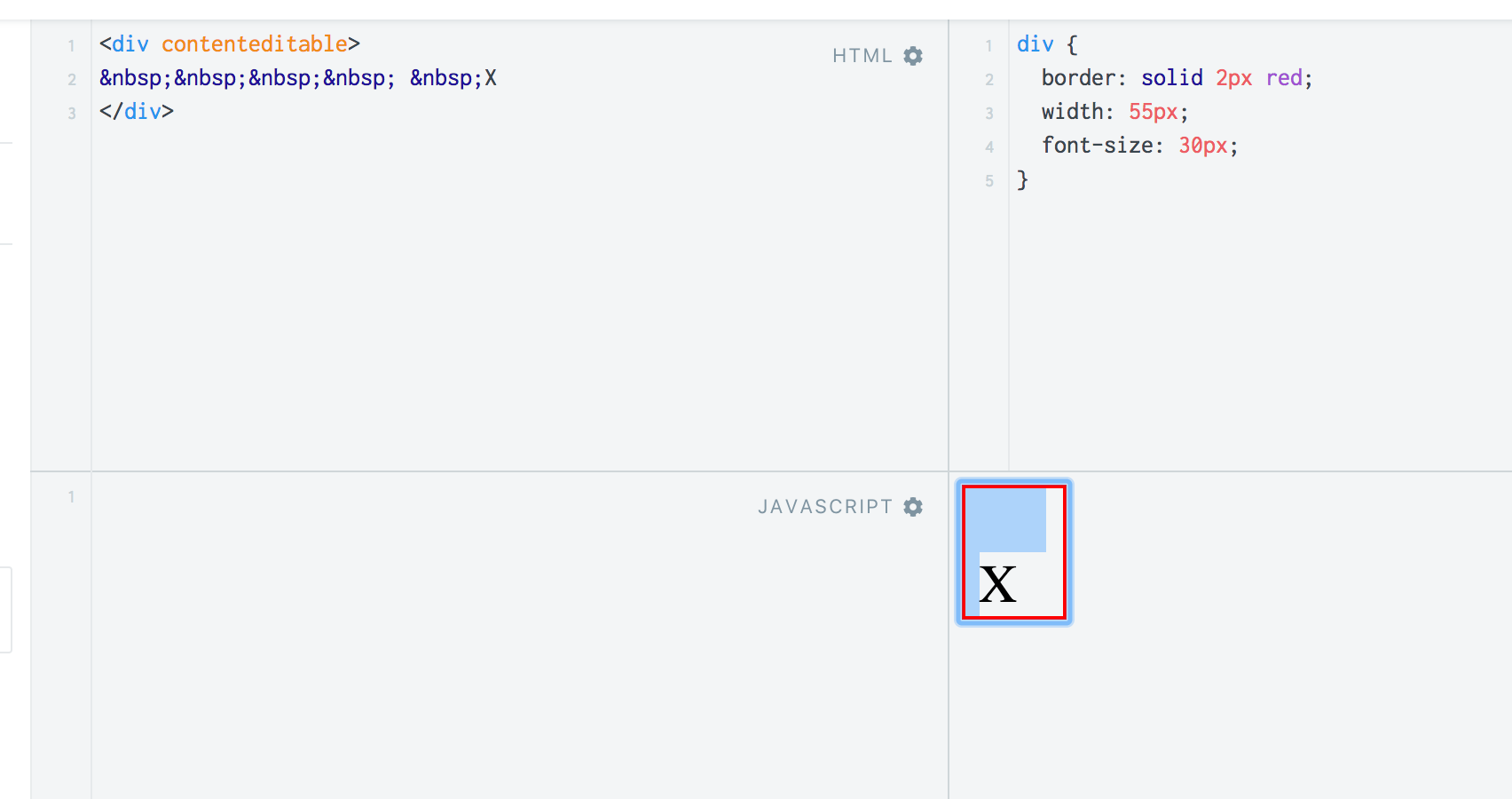
Despite the fact that it'd fit in the previous line it will stay with the letter (because it behaves like a letter).
Reinmar
on 29 Jul 2017
So, the rules seem to be:
- a block cannot start or end with a normal space,
- a letter should never be preceded with a nbsp,
- ideally, a letter shouldn't also be followed by a nbsp unless case 1. also applies.
Chrome fails to implement rule 2. so you can get this (all these spaces should fit in the previous line):
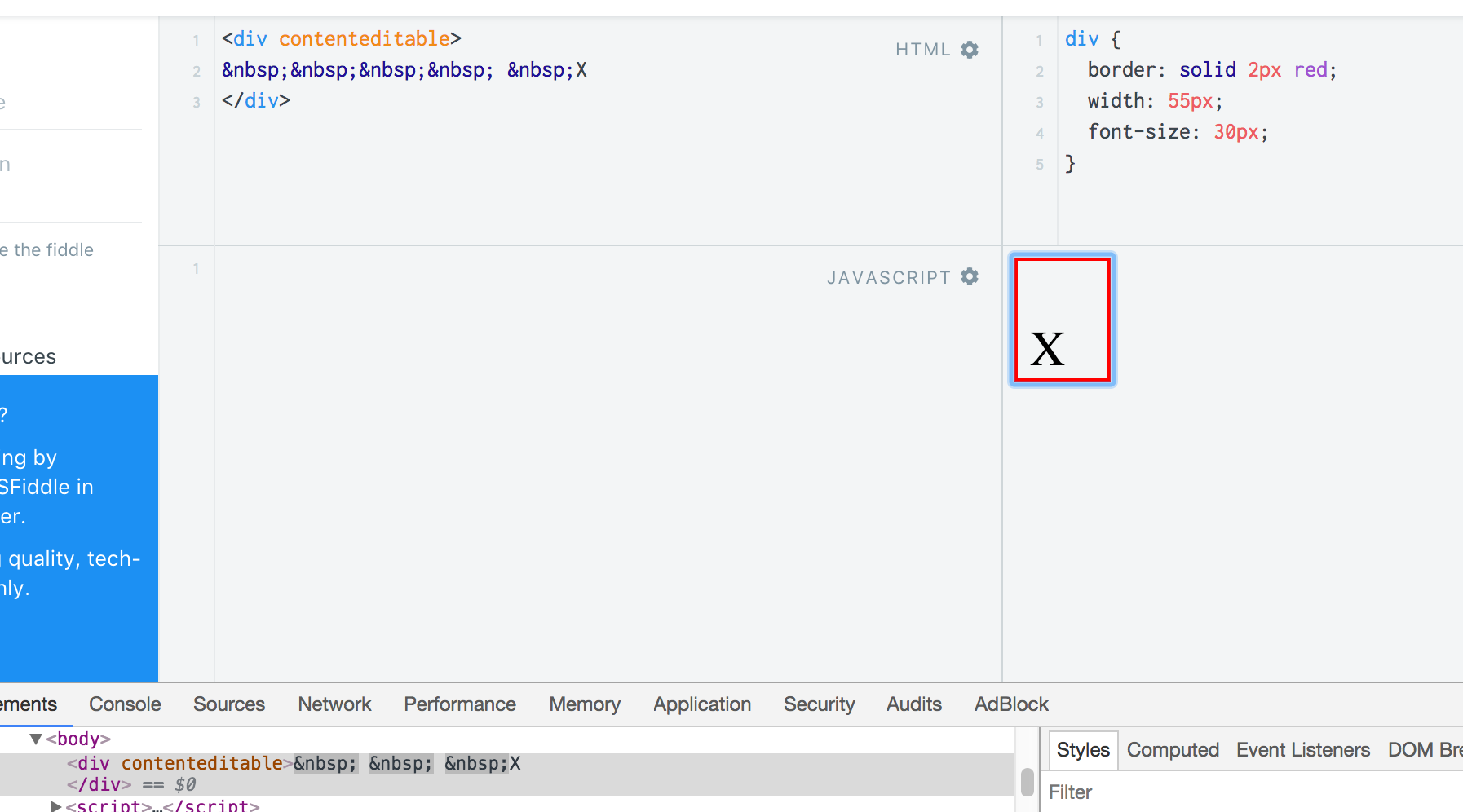
Reinmar
on 29 Jul 2017
I can see that _processDataFromViewText() is already unpleasantly complex, so I'd focus now on fixing the 1. rule while ignoring 2 and 3.
After all, playing with too many subsequent spaces is not common in text editing and a chance to hit the space-in-new-line scenario is extremely low too.
Reinmar
on 29 Jul 2017
I tried to analyse the current algorithm but it's hard. I especially don't like the split to "textStart" and "textEnd" which is the actuall reason of the bug we're dealing here (unescaped leading space in an empty paragraph).
Initial sketch
Therefore, I started thinking on a new algorithm. At first it seems that, it could work like this:
- Get the previous touching view text node and the next touching view text node.
- If the previous touching text node ends with a space or doesn't exist (block boundary case), replace the first space to nbsp;
- Do the same with the next touching text node and the last space.
- On the rest of the text do
s/ / \u00a0/g.
The above algorithm's behaviour for the following cases:
* <p> </p> -> <p>_</p> -> <p>_</p> -> <p>_</p>
* <p> </p> -> <p>_ </p> -> <p>__</p> -> <p>__</p>
* <p> </p> -> <p>_ </p> -> <p>_ _</p> -> <p>_ _</p>
* <p> </p> -> <p>_ </p> -> <p>_ _</p> -> <p>_ __</p>
* <p> X </p> -> <p>_ X </p> -> <p>_ X_</p> -> <p>_ _ X_</p>
Corrected algorithm
All fine, up to a point when we need to consider touching text nodes. They are kept in the view in their original format, so we also need to pass them through _processDataFromViewText() to be able to execute steps 2 and 3. This makes this algorithm recursively infinite, so we need to modify it a bit. A natural way will be thinking from left to right, so making the algorithm care less about what's on the right hand side.
- Get the previous touching view text node. If it doesn't exist, replace the first space with a nbsp (block boundary case). If it exists, pass it through
_processDataFromViewText()and if the returned data ends with a normal space, replace the first space of the current text node with nbsp. - If the current text node doesn't have a following touching text node (block boundary case), replace the last space with nbsp.
- On the rest of the text do
s/ / \u00a0/g.
* <p><i> </i> </p>
-> <p><i>_ </i> </p> (first text node)
-> <p><i>_ </i>__</p> (second text node)
* <p><i> </i> </p>
-> <p><i>_ _</i> </p> (first text node)
-> <p><i>_ _</i> __</p> (second text node)
Further considerations
Of course, this algorithm may be slow if an element contains a couple of text nodes because the
_processDataFromViewText()will be called 1+2+3+4+5+6+...+N = N(N+1)/2 times. For a simple paragraph with 4 links this means 910/2=45 calls. This has a great chance to visibly slow down rendering due to pretty heavy_getTouchingViewTextNode().Therefore, we should look for a simple optimisation. Caching may be one, but this is a kind of problem which attempted with cache will make two problems.
Hence, I'd propose modifying the first point of the algorithm a bit:
If the current text node doesn't start with a spac, skip this point. Get the previous touching view text node. If it doesn't exist, replace the first space with a nbsp (block boundary case). If it exists and ends with a space, pass it through
_processDataFromViewText()and if the returned data ends with a normal space, replace the first space of the current text node with nbsp.This will stop the chain of
_getTouchingViewTextNode()calls in most cases as, usually, at least one of subsequent text nodes will not end with a space:This is <a>a link</a> followed by nothing.If I haven't missed anything and this algorithm makes sense, it seems that it should be fairly easy to implement rules 2 and 3. But I'd still ignore this and report a followup.
- Looking at https://github.com/ckeditor/ckeditor5-typing/issues/101#issuecomment-318693782 I think that Chrome implements exactly this algorithm. Secure boundary spaces and then replace the rest.
Reinmar
on 29 Jul 2017
Okay I'll look into this issue. If fixing this will be easy in current algorithm, I'll leave most of current algorithm. If not, I will try to to use your analysis and conclusions to write a new one.
On the surface, it seems that what you described as "Initial sketch" is exactly what is written in _processDataFromViewText doc:
Following changes are done:
* multiple spaces are replaced to a chain of spaces and ` `,
* space at the beginning of the text node is changed to ` ` if it is a first text
node in it's container element or if previous text node ends by space character,
* space at the end of the text node is changed to ` ` if it is a last text
node in it's container.
Edit: although the order is a bit different, and maybe that the cause of the bug.
 scofalik
on 4 Aug 2017
scofalik
on 4 Aug 2017
That description isn't correct, AFAIR. The algorithm which is currently implemented splits the text into two pieces (beginning and end) and treats them separately. IMO, this is the cause of the issue, because in some cases the first string may be empty and only the latter (the end) is processed. But the beginning of the ending string is not checked, which is the problem here.
Reinmar
on 4 Aug 2017
Okay, I see that the current algorithm does not work if a text node has only spaces.
scofalik
on 4 Aug 2017
It's also overly complicated which is a problem when you want to fix the bugs like this one.
Reinmar
on 4 Aug 2017
One other idea that might simplify the algorithm is to not process text-node-by-text-node but container-element-by-container-element. I don't know if it is applicable though (if we need text-node-by-text-node for some cases).
scofalik
on 4 Aug 2017
This is tricky. One text node change may affect how the other ones should be rendered and currently we don't do that:
Not OK
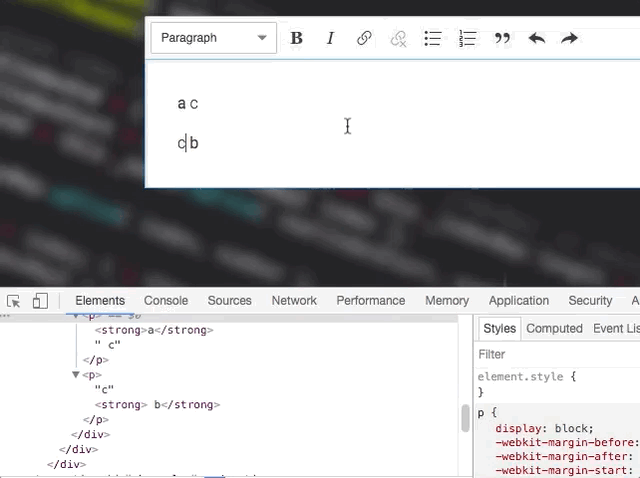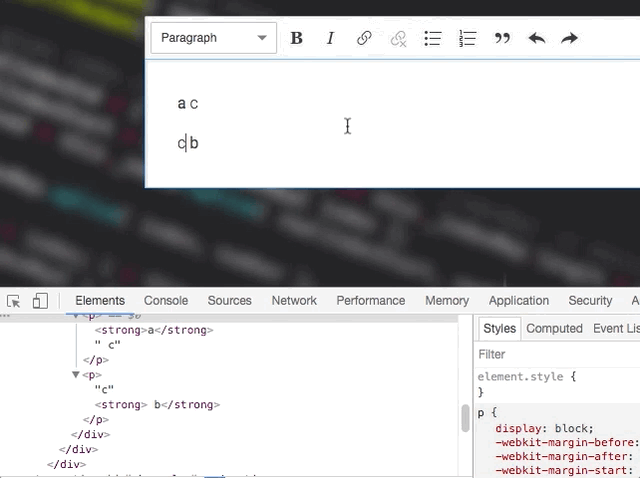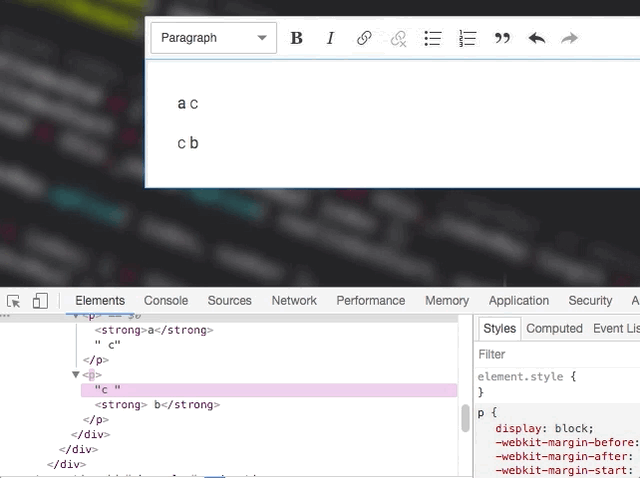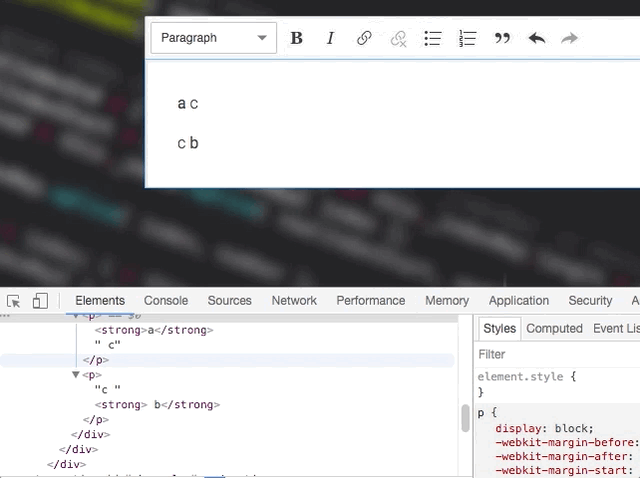
OK by coincident
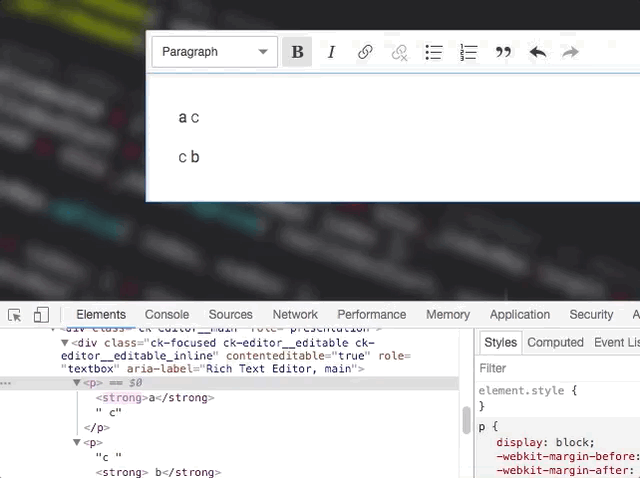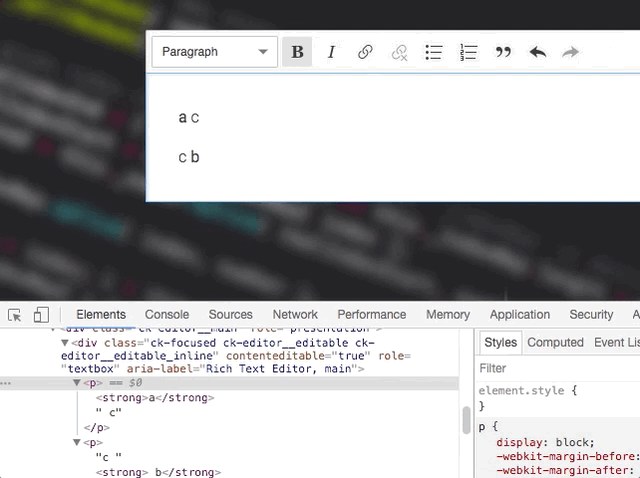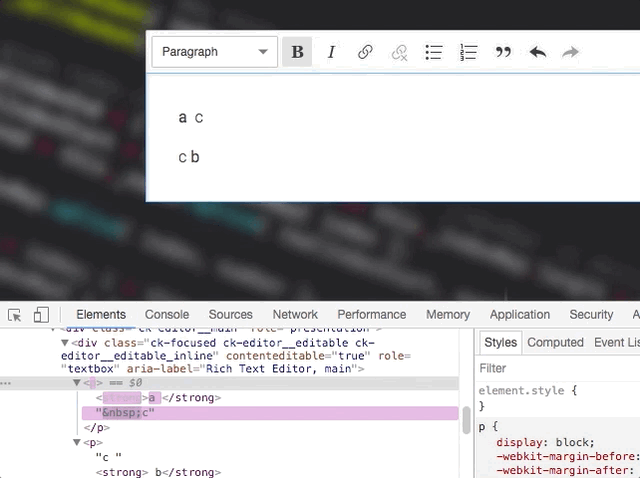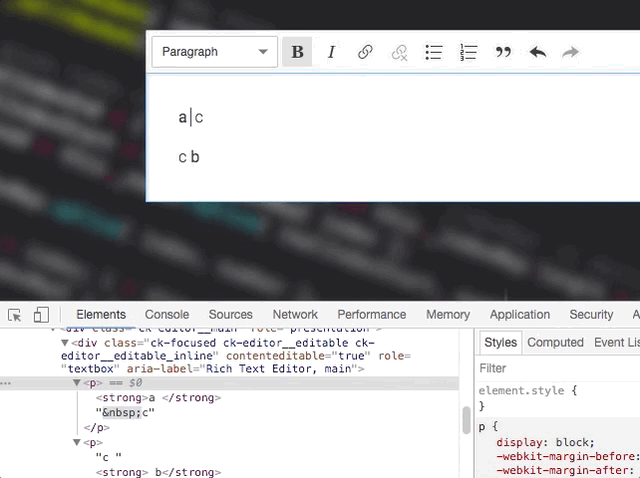
Unfortunately, I don't think that processing text nodes by container would help. It won't change much here. What matters is really how we mark text nodes to re-render. This must be smarter. For example – the renderer could keep re-rendering touching text nodes after changing the marked one. So, it'd start with the marked one, if it changed, then it would also mark the touching ones and move to the next item in the queue.
Reinmar
on 4 Aug 2017
One note: if the algorithm for processed text node bases on the text node before* then if that text node needs to be changed, we need to process only nodes on the right. True?
* - before processed text node there can be: no text nodes, text node ending on space (which is always converted to nbsp) or text node ending on non-space.
scofalik
on 4 Aug 2017
So here are guides that the new algorithm will follow:
- If there is a space at the end of text text node -> change it to nbsp.
- If there is a space at the beginning of text text node -> change it to nbsp if this is the first text node in it's container element.
- Space chunks are looked for and converted to
nbsp+space+nbsp+spacechain if they are even, orspace+nbsp+space+nbsp+spacechain if they are odd.
This algorithm should handle some edge cases that the previous does not handle:
" " -> "_" (instead of " ")
" " -> "__" (instead of " _")
" " -> "_ _"
" " -> "__ _" (instead of " _ _")
" " -> "_ _ _"
" " -> "__ _ _"
Also this should be correct:
"x" " " -> "x" " _"
"x " " " -> "x_" " _"
"x " " " -> "x_" "_ _"
"x " " " -> "x_" " _ _"
And of course this:
" x " -> "_x_"
" x " -> "_ x _"
" x " -> "__ x_ _"
" x " -> "_ _ x _ _"
In renderer, during text update, if the last character was space and is not a space anymore, update also next sibling (we can skip updating if the character "type" is same). We should also re-render if the first text node in it's container was removed. I am not sure we are doing this now.
Edit:
This case is unfortunately a bit questionable.
" x " -> "__ x_ _"
It's the question whether we want to have spaces mixed with nbsp or whether we want to have space before a character.
scofalik
on 4 Aug 2017
Related issues
 hybridpicker
·
3Comments
hybridpicker
·
3Comments
 jodator
·
3Comments
jodator
·
3Comments
 metalelf0
·
3Comments
metalelf0
·
3Comments
 devaptas
·
3Comments
devaptas
·
3Comments
 pandora-iuz
·
3Comments
pandora-iuz
·
3Comments