Title
Cilium agent memory leak
General Information
- Cilium version (run
cilium version)
Client: 1.2.4 740fe0b 2018-10-05T23:42:20+02:00 go version go1.10.3 linux/amd64
Daemon: 1.2.4 740fe0b 2018-10-05T23:42:20+02:00 go version go1.10.3 linux/amd64
- Kernel version (run
uname -a)
Linux ip-172-23-82-122.us-west-2.compute.internal 4.14.67-coreos #1 SMP Mon Sep 10 23:14:26 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
a
- Orchestration system version in use (e.g.
kubectl version, Mesos, ...)
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.0", GitCommit:"91e7b4fd31fcd3d5f436da26c980becec37ceefe", GitTreeState:"clean", BuildDate:"2018-06-27T20:17:28Z", GoVersion:"go1.10.2", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"10", GitVersion:"v1.10.8", GitCommit:"7eab6a49736cc7b01869a15f9f05dc5b49efb9fc", GitTreeState:"clean", BuildDate:"2018-09-14T15:54:20Z", GoVersion:"go1.9.3", Compiler:"gc", Platform:"linux/amd64"}
Kubernetes cluster v1.10.8 installed in AWS with Kops 1.10 using cilium as CNI provider using CoreOS stable as SO in r4.large instances (3 masters and 4 nodes)
The cluster runs ~200 pods and four times per day this number increases to ~300 (K8s Jobs)
After one day: (consuming ~300MB or RAM)
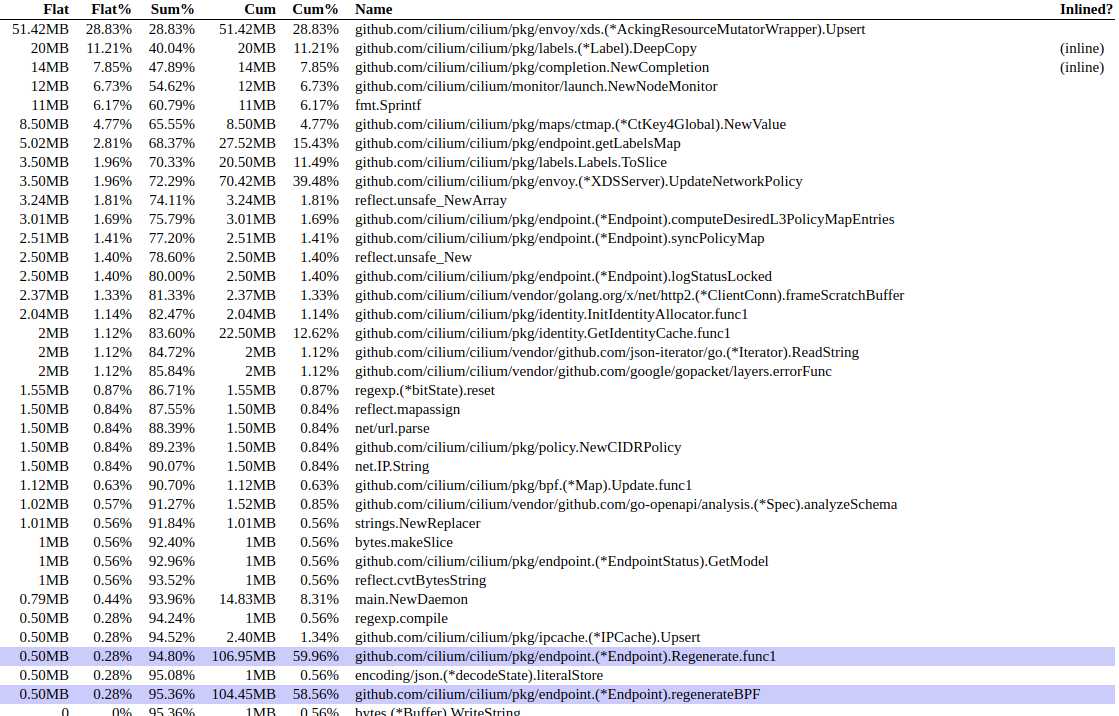
After 5 days: (consuming ~900MB or RAM)
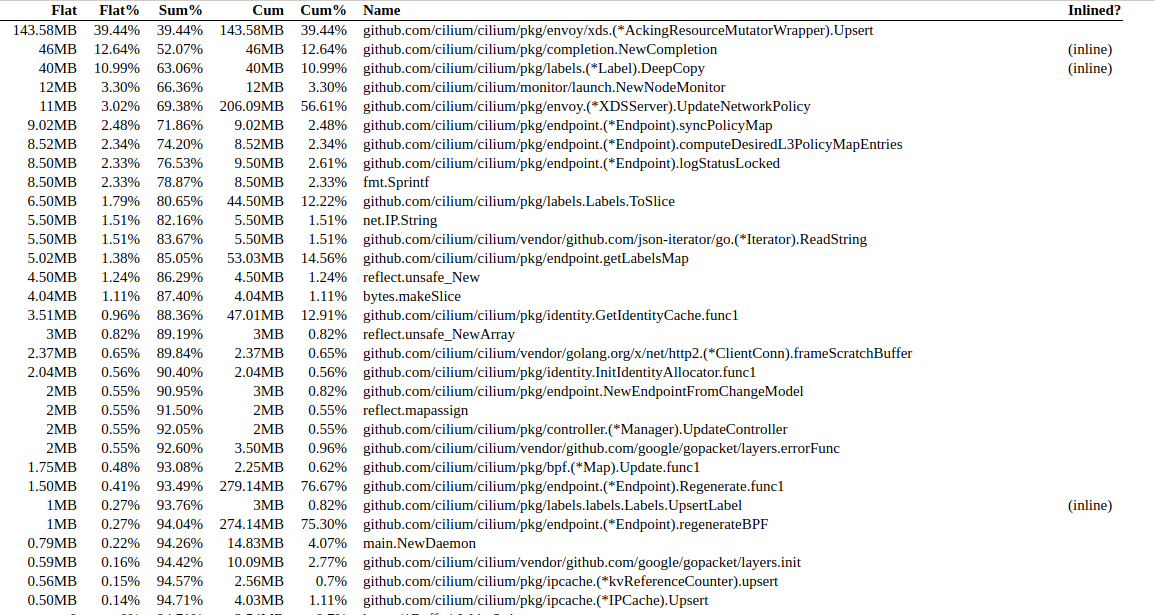
Is this expected?
 aledbf
aledbf
All 4 comments
Thanks for the report @aledbf. This was indeed a memory leak and has been fixed by the commit #5919. The fix will be released in 1.2.5 and 1.3.0.
You may also be interested in the discussion of #5913 with the workaround mentioned in the thread.
 tgraf
on 22 Oct 2018
tgraf
on 22 Oct 2018
Closing, fixed.
 joestringer
on 25 Oct 2018
joestringer
on 25 Oct 2018
@tgraf after two days running 1.3.0 I see this is working without issues :)
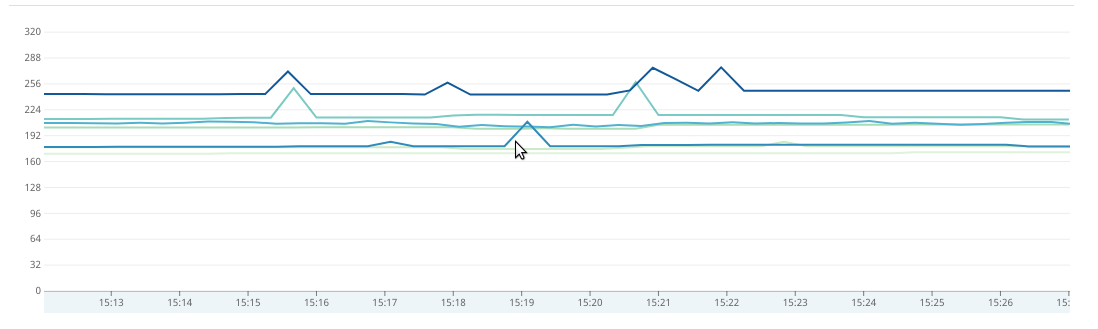
Now, are this cpu spikes expected?
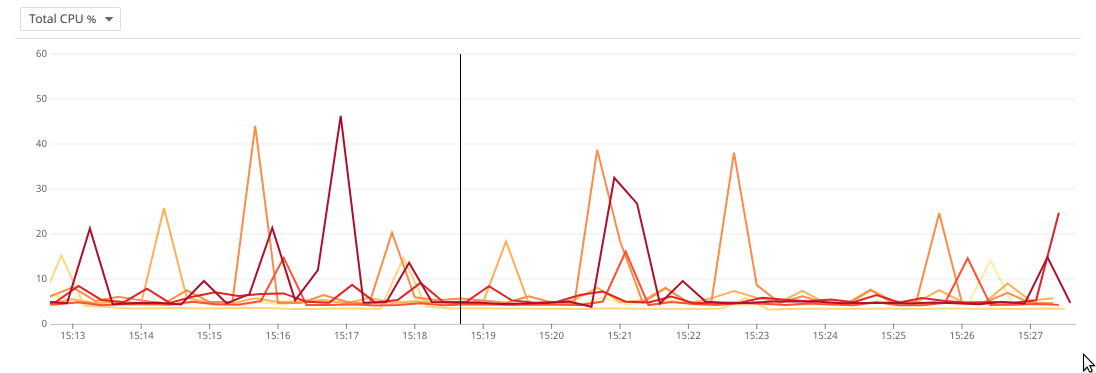
aledbf
on 26 Oct 2018
@aledbf Thanks for confirming. The CPU spikes are currently valid. We are working to reduce the overhead further:
- More efficient connection tracking garbage collection
- BPF templating to avoid recompilation
- More efficient calculation of allowed policy
- ...
tgraf
on 26 Oct 2018
Related issues
 aanm
·
3Comments
aanm
·
3Comments
 tklauser
·
3Comments
joestringer
·
3Comments
tklauser
·
3Comments
joestringer
·
3Comments
 manalibhutiyani
·
3Comments
manalibhutiyani
·
3Comments
 Jianlin-lv
·
3Comments
Jianlin-lv
·
3Comments
Most helpful comment
@aledbf Thanks for confirming. The CPU spikes are currently valid. We are working to reduce the overhead further: