Cht-core: Bulk Delete often fails when using select all to delete the maximum
We currently support deleting 500 docs at a time. The more docs you have, the less likely the delete is to succeed. Unfortunately 500 still doesn't work a lot of the time.
We should either:
- Put the effort into improving the code so that 500 docs always deletes properly
- Work out what size comfortably works, and see if users / @sglangevin are OK with that number and just roll with that.
See original ticket text below.
@sglangevin mentioned that Bulk Delete is still very slow.
We should investigate the performance of this feature.
Questions, perhaps for @sglangevin:
- How many documents would you expect bulk delete to support in a performant way?
- What is a level of performance that is acceptable, _or_ how is the current performance unacceptable?
 SCdF
SCdF
All 47 comments
@SCdF the current issue seems to be a bug. I recall agreeing that the max number of docs we should be able to delete at one time should be 500. If I go to the Reports/History tab and click Select All, it selects 500 records. When I then hit delete, I get and error most of the time, even on fast internet. If I go and select 50-100 records by hand, it deletes successfully. Ideally, I should be able to successfully delete the number of records that are selected when I click "Select all". So we should either make that work with 500 records or we should reduce the number selected when clicking Select all. Does that make sense?
 sglangevin
on 23 Jan 2018
sglangevin
on 23 Jan 2018
@sglangevin yep that makes sense. I've added labels that I think fit. Feel free to chuck it in the project you think it belongs in.
SCdF
on 23 Jan 2018
Ideally this should be fixed as soon as we can - I'm adding it to 2.15.0 for now but if someone wants to pick it up, we could also fix it in 2.14.0 and release a new beta.
sglangevin
on 23 Jan 2018
@sglangevin just had a few questions on this:
- Which environment(s)/version(s) did you see this on?
- Is the error that you see in the actual "Delete All" modal (something generic like
Error deleting documents) or is it at a later point? - Do you know if the app otherwise continued to work normally after you got the bulk delete error?
 rmhowe
on 31 Jan 2018
rmhowe
on 31 Jan 2018
- I've seen this on a few different versions, 2.13.0 and higher and I think I've seen it both in production and on test servers, but I can't remember the exact ones.
- Yes, the error is in the modal and I think it says "Error deleting documents". In the console it looked like it could be some sort of timeout issue but I'm not sure.
- Yes, everything worked normally after the error.
sglangevin
on 31 Jan 2018
Experimentation so far (on v2.14.0 locally and on beta.dev):
- Restricted users: When deleting 500 documents, they are first processed by PouchDB client-side, and then sent in batches of 100 to the server. I have not been able to produce an error locally or on beta.dev deleting 500 docs (tested up to 1000 locally). In theory this should never produce an error due to Pouch's ability to batch.
- Admin/Full access users: When deleting 500 documents, they are NOT processed by PouchDB client-side and instead one big payload is sent to the server (CouchDB). Both locally and on beta.dev this will produce a timeout error (seen in the modal as
Error deleting document), as Couch takes a long time to process this giant request. While an error IS displayed in the UI, Couch has actually received the request and so will delete those documents (may take a while to show in the UI depending on connection). Possible solution here is to increase timeout (seems to be 10s currently), or to show a different error message on timeout.
@sglangevin does the admin/full access case above match your experience? Or were the documents never deleted?
rmhowe
on 1 Feb 2018
@rmhowe for full access users we probably need to create an api endpoint to bulk delete, which manages batching etc. You would pass it a collection of ids (and if you want to be fancy, _revs, though perhaps this explicitly would ignore that kind of thing), and it either returns once it's all done, or returns a hook that you can query to see if it's done, or slowly streams back some kind of indicator that you can use to determine when it's finished and it's progress.
Another option that is kind of appealing but kind of crazy, is to spin up local pouchdbs that one-way replicate to the server, and push deletes into that. The problem is that while you might have the whole document downloaded locally, you also might not, which would mean situations where you download an entire document to add _deleted: true to it and then replicate that back up. If we didn't have filtered replication you'd only need the _id and the _rev, because you could just generate {_id: 'foo', _rev: '1-hash', _deleted: true} documents, but unfortunately that is not an option for us.
SCdF
on 1 Feb 2018
@rmhowe I don't think all of the docs were actually deleted in my case, but in general that sounds like what I was experiencing for full access users.
In terms of what the expected functionality is, the full access user needs to be able to delete up to 500 docs at a time, even on a slow connection. I'm not sure whether increasing the timeout will help that, but I don't think changing the error message is useful at this point. I like the idea @SCdF put forth of adding an API endpoint for bulk delete. This would also be very valuable for tech leads and others who need to bulk delete more than 500 docs. Tech leads currently have a lot of challenges when bulk deleting due to timeouts.
sglangevin
on 1 Feb 2018
New dedicated endpoint sounds good 👍
rmhowe
on 2 Feb 2018
@sglangevin @amandacilek in terms of showing progress when deleting all these documents, is the UI important? I've currently got it just showing this
Before confirming deletion:
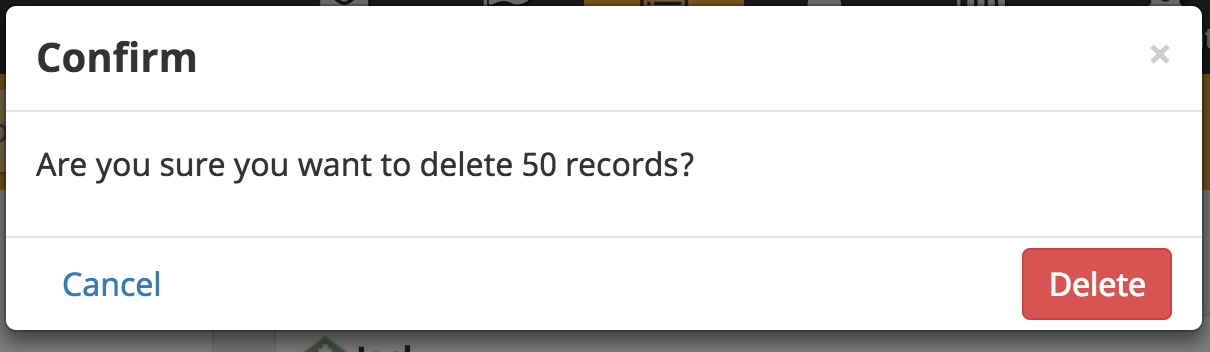
After confirming deletion:
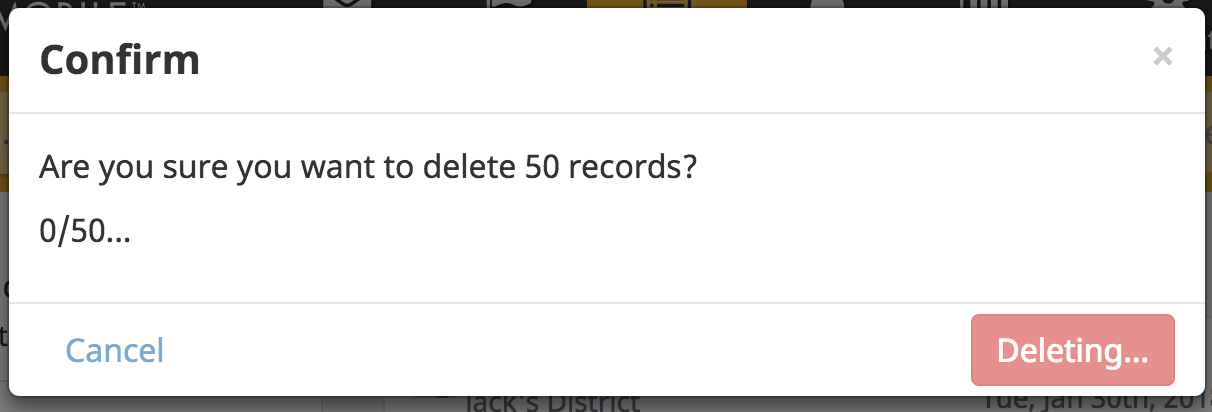
(and the number on the left updates as more documents get deleted) mostly for development purposes as it was the simplest option, but not sure if we want a bar that fills up or something to that effect?
rmhowe
on 15 Feb 2018
I'm confused about whether this screenshot is before or after you've confirmed deletion should begin. Can we separate the appearance and text for before and after?
Before:
Confirm
Are you sure you want to delete 50 records?
(lower right button says "Delete"... On a related note, I've never understood why our buttons in these dialogues are red when they are almost always _confirming_ "Yes, go ahead with something or other")
After:
Deletion in progress (or something similar)
0/50 records deleted
(Maybe at this point there is only one button on the bottom which says "Cancel".)
Curious, what happens if someone hits Cancel halfway through the deletion process: do half of their records remain deleted? We might need a third screen if this happens saying something like "Deletion cancelled. 20 of 50 records were deleted". Is there any recovery process or are they permanently gone? If we have a recovery method we should tell them how to go about it (after they've cancelled).
Tagging @diannakane @sglangevin
 amandacilek-zz
on 15 Feb 2018
amandacilek-zz
on 15 Feb 2018
@amandacilek good point I've updated my previous comment to show before/after, again this was mostly just for development purposes to make sure it was all working correctly so I'm not in any way tied to positioning/style.
The Cancel button is disabled once a user confirms deletion (and it becomes slightly grayed out). As far as I'm aware there's currently no recovery process once the records are deleted.
(Also I imagine the red colouring on the button here is to denote something potentially dangerous that cannot be undone but not entirely sure)
rmhowe
on 15 Feb 2018
Thanks for sharing the updated screenshots.
At a minimum the two things I would suggest are related to the second view (after deletion has begun). I'd change the text so it's no longer in question format and simply states "Deletion in progress" and secondly, IMO we should get rid of the two buttons on the bottom if neither is actionable. Curious what Dianna and Sharon think though.
What about the X in the upper right, does that not work either after you've started the deletion process? Kinda scary from a UX perspective to begin something that you have no way out of.
amandacilek-zz
on 15 Feb 2018
Changing the text once the user has confirmed the deletion shouldn't be a problem 👍
The X in the upper right is also disabled once you've started the deletion process. Once the request has been sent it can't be cancelled and unfortunately as far as I can tell it would be very technically complex to allow this.
rmhowe
on 15 Feb 2018
We can't undo deletion once it is initiated and we don't currently have a recovery method. Perhaps instead of keeping the same modal, we should have another one that just says: "Deletion in progress" at the top and then displays 0/50... below that. The user wouldn't be able to get out of that modal until deletion completed.
The downside of this could be that on slow connections, the deletion could take a while and they'd just be stuck waiting. Do we have any idea what the response time is for deleting the max of 500 docs?
sglangevin
on 15 Feb 2018
@sglangevin connection speed shouldn't affect response time too much as the bulk of time will be spent by couch actually processing the documents and deleting them. This means response time will vary depending on how much couch is doing at that particular point in time. While I've been messing around with docs it's gone as high as ~180 seconds for 500 documents, although even if I let it settle down before performing a bulk delete it's still at least ~30 seconds for 500 docs. This is a long time to hold the user but I'm assuming we want to restrict them from using the app too much during this time as it'll be showing documents that are currently being deleted.
It's also an option now though to remove the 500 limit if we choose to as the documents are being batched.
rmhowe
on 16 Feb 2018
If 500 docs can take up to 3 minutes, then I think we need to keep the limit in place. You're right, we do want to restrict the user from using the app while we are deleting. Let's start with keeping the limit in place and see how it works in practice and we can make tweaks if we need to.
sglangevin
on 16 Feb 2018
LGTM
 ngaruko
on 9 Mar 2018
ngaruko
on 9 Mar 2018
This was working on alpha.dev but I can't delete reports (either singular or bulk delete) on beta.dev, which was updated to 2.15.0-beta.1 today. This is happening every time for me when logged in as admin.
sglangevin
on 16 Mar 2018
Since @rmhowe is out, assigning to @SCdF - feel free to redistribute.
sglangevin
on 16 Mar 2018
Confirmed this was an issue with the instance. Moving back to ready.
sglangevin
on 20 Mar 2018
I selected 208 records and tried again. Overall, I found the experience to be very slow. Are there ways we can speed it up? I was stuck here for a while and my computer was using a lot of CPU
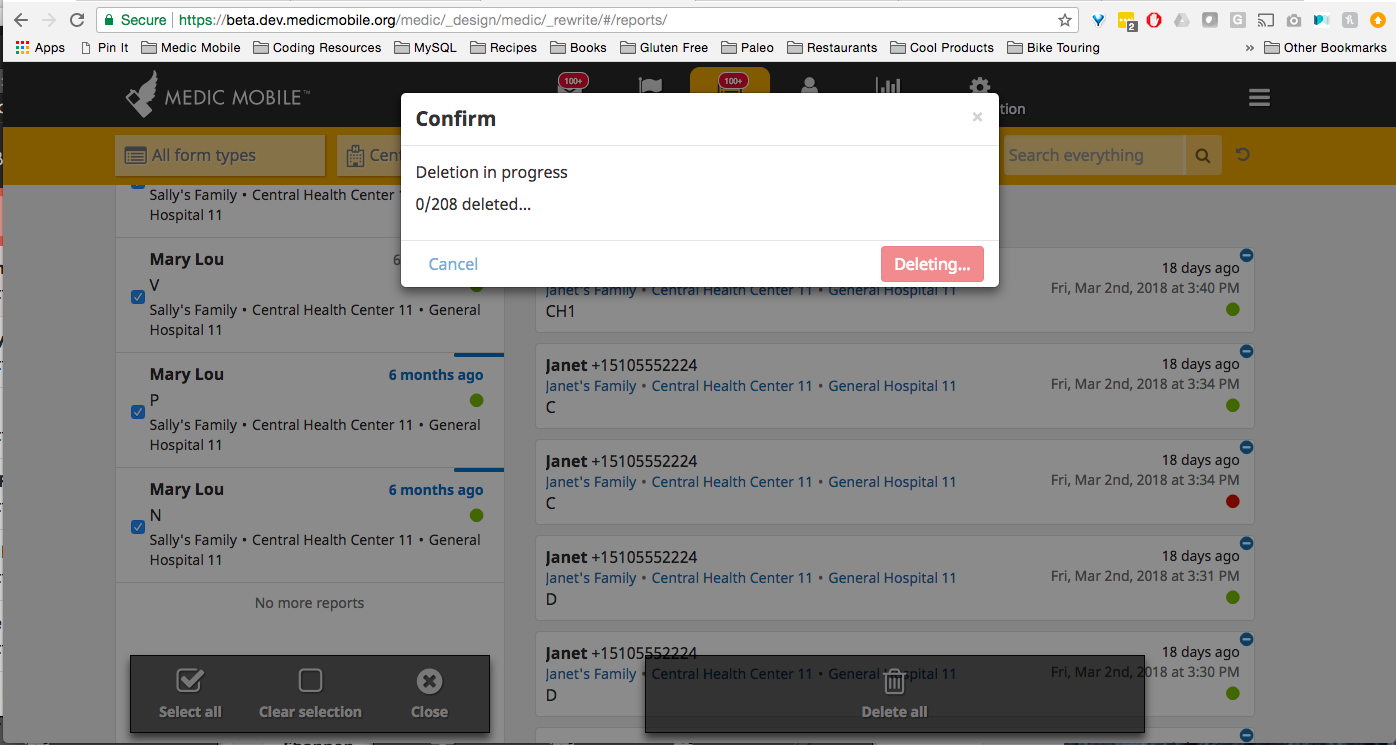
Then I got back here but still had to wait a while for the UI to update with the reports showing as deleted:
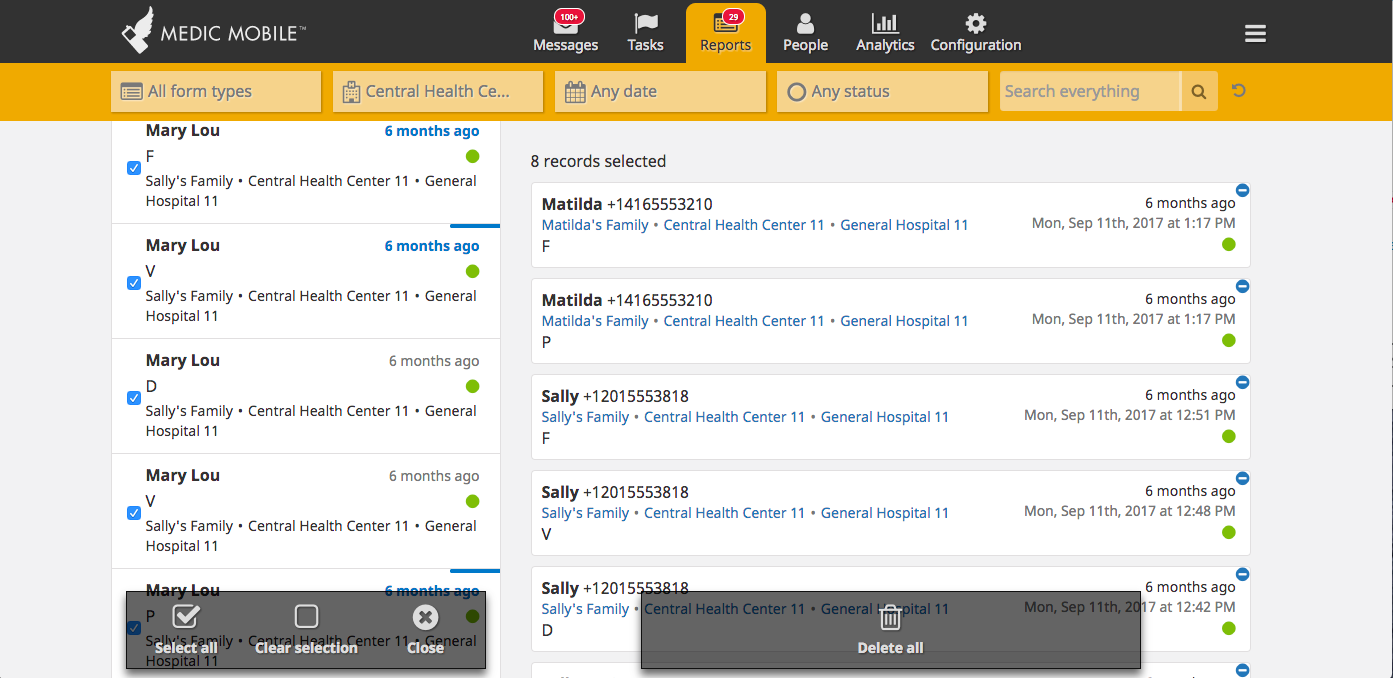
Thoughts on how we might improve this? I'm not sure this will be acceptable. I ended up with 8 reports left that weren't deleted. Trying to delete those was much faster, but I think we need to support the deletion of a few hundred reports well.
sglangevin
on 21 Mar 2018
Also, have we confirmed these deletes propagate to restricted users? The deleted reports still show up when I log in as a restricted user so I'm wondering how the deletion is being done.
My bad - I realized the ones I was still seeing were from Unknown senders and therefore didn't fit the filter I had while bulk deleting.
sglangevin
on 21 Mar 2018
@sglangevin I can have a look, I'm interested in which bit is slow.
My current guess is:
- load is coming from the deletes replicating down (because admin means all doc changes are replicated to you while the app is open)
- and the LHS is having to dodge duck dip dive and... dodge, to constantly update.
This is an interesting problem, because it's inherent in our design. We expect to see all documents in the system to keep the UI up to date. Offline users don't cause much issue because all the data is already there, but admins basically download the entire DB while their page is open.
One option specifically for here is: turn off change following, then refresh the browser (which would reset following and all views etc) afterwards.
In general though, I think we might need to deal with this elephant at some point. Presumably by changing our design to not rely on this architecture. Perhaps to something where api interprets the changes feed and send much smaller custom changes to the front end. Or perhaps just not sending any updates to the UI at all unless they are critical (ddoc is updated)
SCdF
on 21 Mar 2018
This is assuming the delay is on the client side (which, fits with Sharon saying "...was using a lot of CPU").
I agree the online user experience does not scale. It was really designed for the clinic administrator level rather than the massive deployments we're seeing now. I feel like ultimately to support admins at scale we'll need to turn off change monitoring altogether and force users to refresh the screen (or do some sort of timed polling of the LHS) to get the latest.
A short term solution would be to put a delay on Changes notifications so instead of getting 200 notifications each containing 1 doc you would get 2 notifications each containing 100 docs. This would greatly reduce the amount of rendering and re-rendering without a great deal of development effort.
 garethbowen
on 21 Mar 2018
garethbowen
on 21 Mar 2018
So I tried to delete 200 records on beta.dev. There is something weird going on for sure. It hasn't caused CPU issues for me, but the progress bar doesn't seem to work in deployed instances (it works locally). For me actually, it hung for ages, and then went back to the model with an error, even though it deleted everything.
SCdF
on 21 Mar 2018
Tried it a second time. This time it finished quickly (though the progress bar didn't work), and then visible cleaned up after itself (ie the delete happened and then the UI caught up after the progress window closed).
FWIW @sglangevin I'm bulk importing documents with the window closed, because this is half of the performance problem (lots of doc changes at once), and isn't (probably) a real-life scenario we have to worry about. I then wait until sentinel has finished for similar reasons. FWIW sentinel sucks at this kind of situation: it actually has a hard cap of 50ms delay per change (for "stability"), which leaves you with a maximum of 20 changes per second, but the real answer is much slower, more like ~5 IIRC.
SCdF
on 21 Mar 2018
Tried it a third time. This time because I'm a crazy risk taker (#nolimits) I did it with 500 documents. I know, sell 3/4ths of your seat because you only need the edge!
It still worked, though again the progress bar didn't work.
Interestingly it also seems to be interacting with #4312, as suddenly the user db gets to go and frantically starts updating read statuses while the delete is going on.
It does complete though, and it's not _that_ slow.
@sglangevin let's talk about it when you're around. Maybe we can share screens and take a look at each other's experiences with it :-)
SCdF
on 21 Mar 2018
Here's the plan:
- We're definitely going to fix the progress bar
Then we're going to do one of two things:
- Look at using the debouncing service on the report list. This may reduce CPU usage
- Disable the changes watching entirely and then refresh the page once the delete is done
If we do the latter we will probably also add the search terms to the URL
SCdF
on 21 Mar 2018
So the progress bar does work locally, but it's pretty inconsistent: you definitely don't get every batch report back. I am wondering if this is because of all of the other downloads going on at the same time?
SCdF
on 22 Mar 2018
Update: I've tried various approaches to make this fast. tl;dr; there are no good options for a minor release. Sorry.
Pretty much the only thing that works without a large amount of refactoring is simply to kill the changes feed and then refresh once it's done. Our general approach is not scalable and there is no clever fixes I can see to make it so. There is good work we can do around debouncing some of our updates, but there would be a lot to rewrite, and it doesn't affect the core loop of pulling down way too much data.
I also tried to add search params to the URL, so that when the refresh happens you keep your search params. Unfortunately this is also super complicated because of (among other things) the live-list optimisation code we've written[1], which prevents search params propagating correctly, arguably by design. Because we allow you to have two different states going at the same time (the LHS and how search affects it, and what is in the RHS) I don't see how to have this working consistently and not randomly break user expectations. The current way it works is not great but at least it's _consistently_ not great :-)
We may / should be able to make this work once we replace AngularJS with Angular or React (ie we should be able to drop livelist then).
At a glance, unfortunately it's also challenging to have the modal wait until you click a button for it to refresh, as we have our own modal library that doesn't support multi-state modals (ie we already use the button for "start").
I'll take a quick look, but we might be left with it auto-refreshing on 2.15 and 3.0, perhaps fixable in 3.1 or 3.2.
[1] Tech people: we can neither bind dynamically or call a scoped angular function from the LHS because that code is consumed by jQuery not angular. It currently statically links to the id of the doc we want to open, so if you click it your search would reset in the current model. It works right now because the search isn't bound to anything and is just hidden JS data. If we expect it to link in one place it has to link everywhere though.
SCdF
on 28 Mar 2018
Please review @rmhowe , and either merge and forward port to master or leave to me.
SCdF
on 29 Mar 2018
Back to you @SCdF, just a minor change and some questions
rmhowe
on 29 Mar 2018
Merged to 2.15.x and master
SCdF
on 3 Apr 2018
Tested on alpha.dev and beta.dev....(3.0.0-alpha.9880 and 2.15.0-beta.9 respectively).
The delete takes a while and comes with this popup:
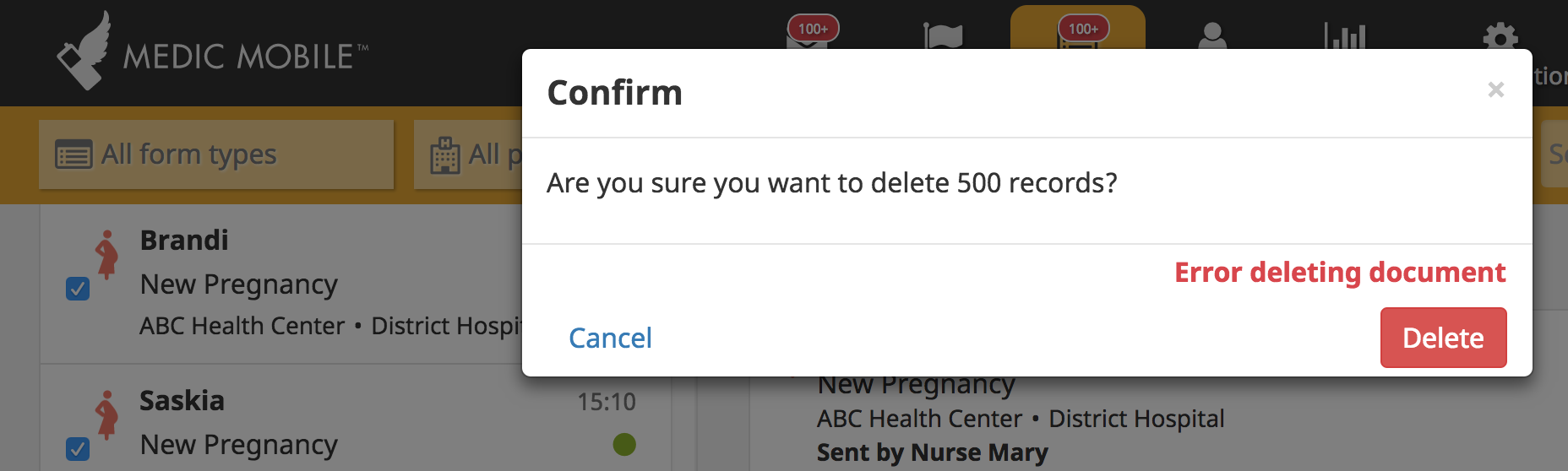
Apparently, behind the scene, 100 reports have been deleted. If 'delete` is clicked on this popup, the UI freezes again for a while and the same popup comes back (with another 100 reports deleted) and it goes on until the 500 reports are deleted.
Looking back at the UI (after accepting delete 3 times then cancel), reports have been deleted:

AND it is not consistent.
ngaruko
on 17 Apr 2018
Can you give it a quick test @SCdF or @rmhowe ? I created quick report with either a Postman runner or curl
for i in {1..50}
do
curl admin:pass@localhost:5988/api/sms \
--header 'Content-Type: application/json' \
--data '{ "messages": [{ "from": "+1 4152319901","content": "1!P!04637#17", "id": "04637"}]}'
done
ngaruko
on 17 Apr 2018
@ngaruko was there an error in the log? Either API or the web console?
SCdF
on 17 Apr 2018
Console errors @SCdF (on beta.dev):
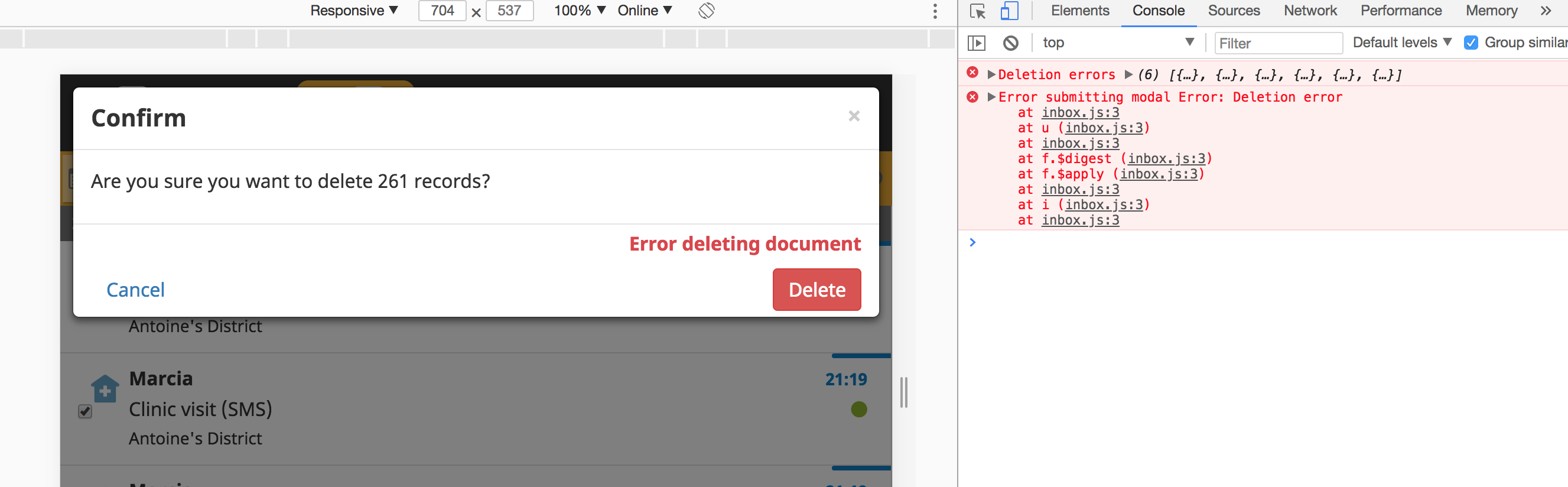
ngaruko
on 17 Apr 2018
@ngaruko what were the expanded errors? (ie expand the deletion errors above).
SCdF
on 17 Apr 2018
inbox.js:3 Deletion errors (6) [{…}, {…}, {…}, {…}, {…}, {…}]
(anonymous) @ inbox.js:3
(anonymous) @ inbox.js:3
u @ inbox.js:3
(anonymous) @ inbox.js:3
$digest @ inbox.js:3
$apply @ inbox.js:3
(anonymous) @ inbox.js:3
i @ inbox.js:3
(anonymous) @ inbox.js:3
setTimeout (async)
c.defer @ inbox.js:3
o @ inbox.js:3
o @ inbox.js:3
s.onprogress @ inbox.js:3
XMLHttpRequest.send (async)
f @ inbox.js:3
h @ inbox.js:3
(anonymous) @ inbox.js:3
t.submit @ inbox.js:3
fn @ VM2380:4
Et.r.(anonymous function) @ inbox.js:3
fn @ VM2371:4
i @ inbox.js:3
$eval @ inbox.js:3
$apply @ inbox.js:3
(anonymous) @ inbox.js:3
dispatch @ inbox.js:3
m.handle @ inbox.js:3
inbox.js:3 Error submitting modal Error: Deletion error
at inbox.js:3
at u (inbox.js:3)
at inbox.js:3
at f.$digest (inbox.js:3)
at f.$apply (inbox.js:3)
at inbox.js:3
at i (inbox.js:3)
at inbox.js:3
(anonymous) @ inbox.js:3
r.setError @ inbox.js:3
(anonymous) @ inbox.js:3
u @ inbox.js:3
(anonymous) @ inbox.js:3
$digest @ inbox.js:3
$apply @ inbox.js:3
(anonymous) @ inbox.js:3
i @ inbox.js:3
(anonymous) @ inbox.js:3
setTimeout (async)
c.defer @ inbox.js:3
o @ inbox.js:3
o @ inbox.js:3
s.onprogress @ inbox.js:3
XMLHttpRequest.send (async)
f @ inbox.js:3
h @ inbox.js:3
(anonymous) @ inbox.js:3
t.submit @ inbox.js:3
fn @ VM2380:4
Et.r.(anonymous function) @ inbox.js:3
fn @ VM2371:4
i @ inbox.js:3
$eval @ inbox.js:3
$apply @ inbox.js:3
(anonymous) @ inbox.js:3
dispatch @ inbox.js:3
m.handle @ inbox.js:3
ngaruko
on 17 Apr 2018
@SCdF :
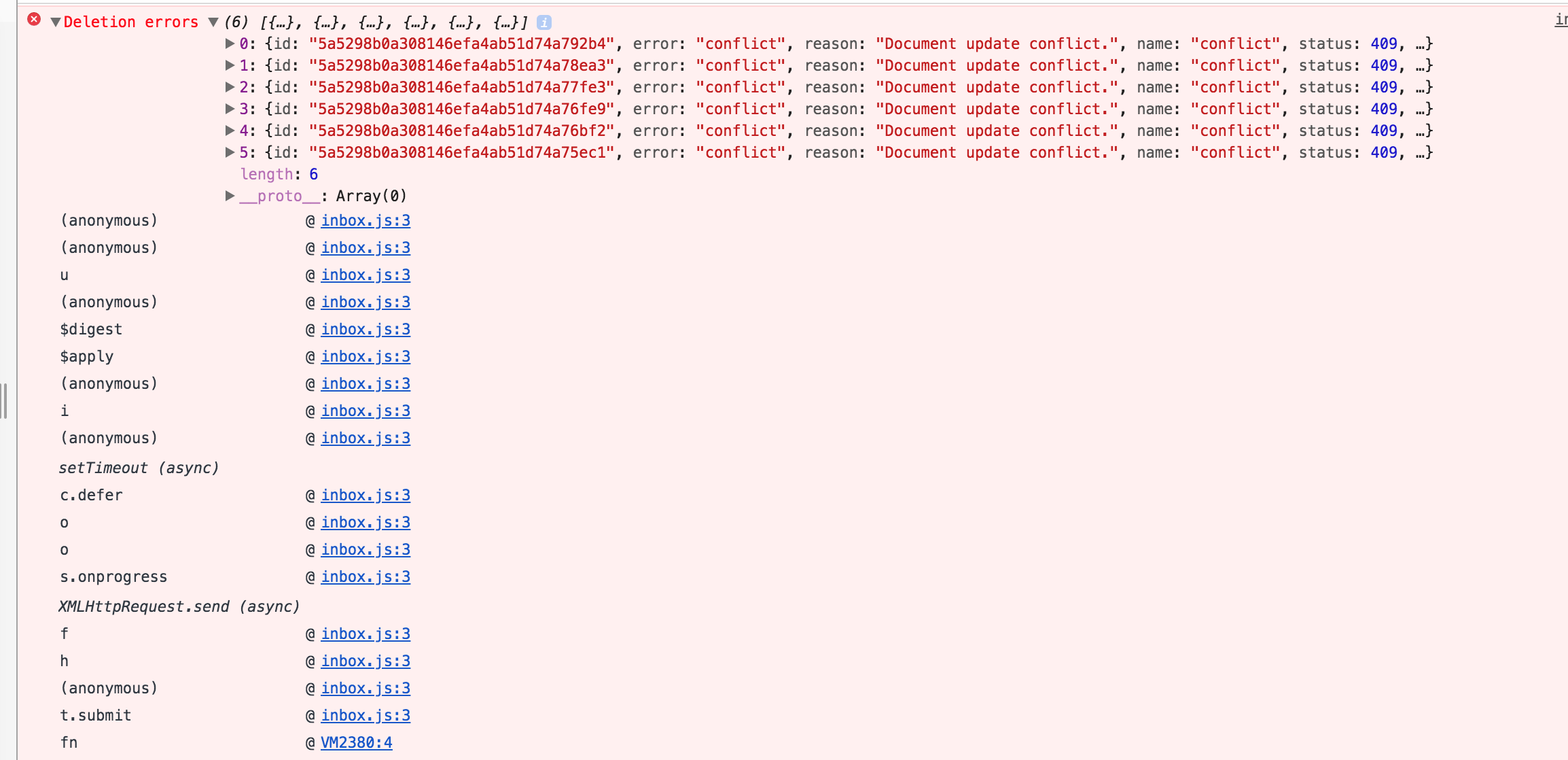
and
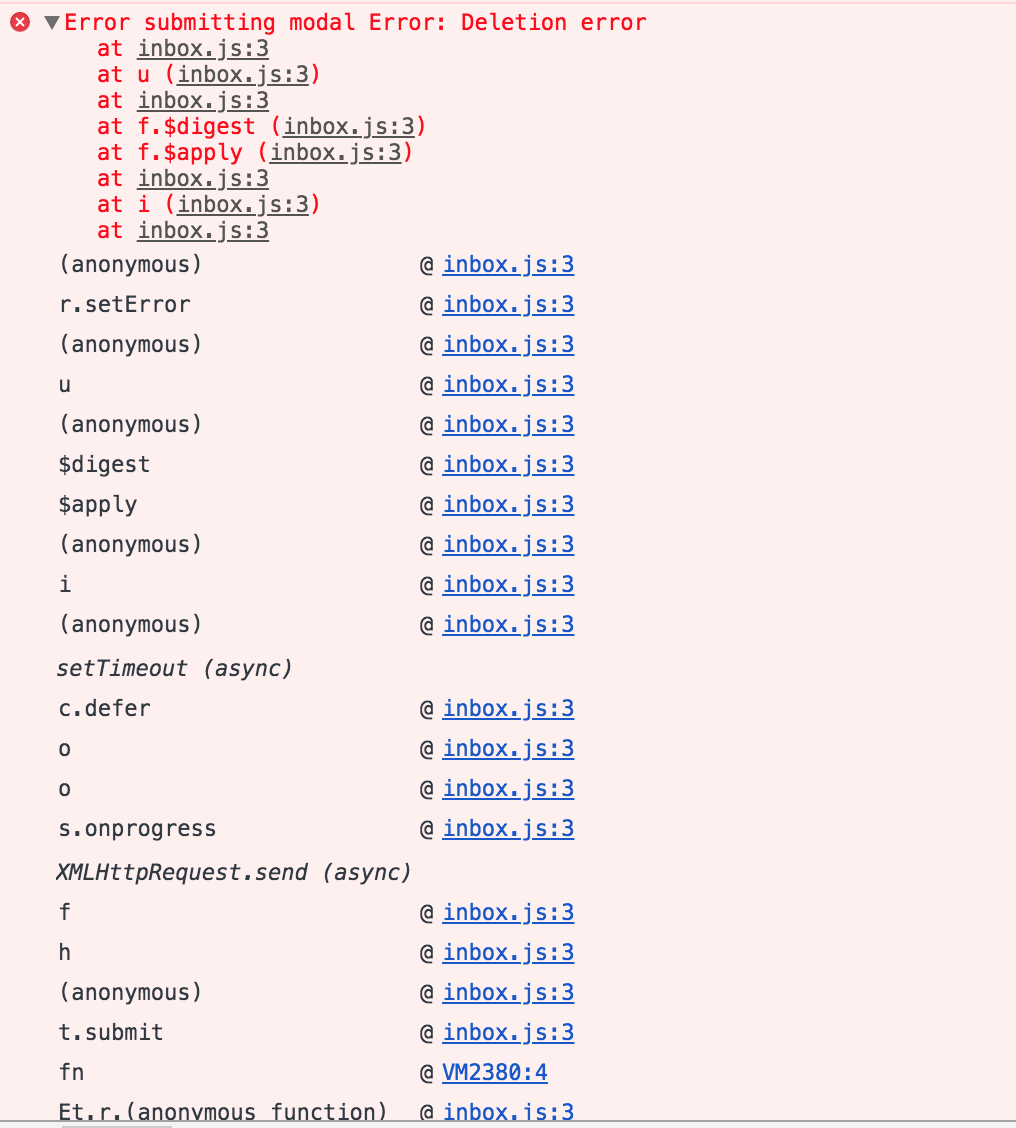
ngaruko
on 17 Apr 2018
OK so those are document update conflicts. Were you running sentinel and had just pushed those documents? If so sentinel was probably working on them at the same time.
Regardless though, we should make a decision about how bulk delete handles conflicts. My vote is that bulk delete indicates that you want it gone from the system: if there is a conflict add it to the back of the queue and keep trying until you can delete it. @garethbowen / @sglangevin how does that make you feel?
SCdF
on 17 Apr 2018
Agree @SCdF . Those errors showed when in the backend I was still pushing some reports. But I guess it is not the problem. For, in many cases, there are no errors in the console apart from the usual Error watching for db changes Error: ETIMEDOUT that has been raised elsewhere with #4312 .

ngaruko
on 18 Apr 2018
The bulk-delete works on beta.dev....
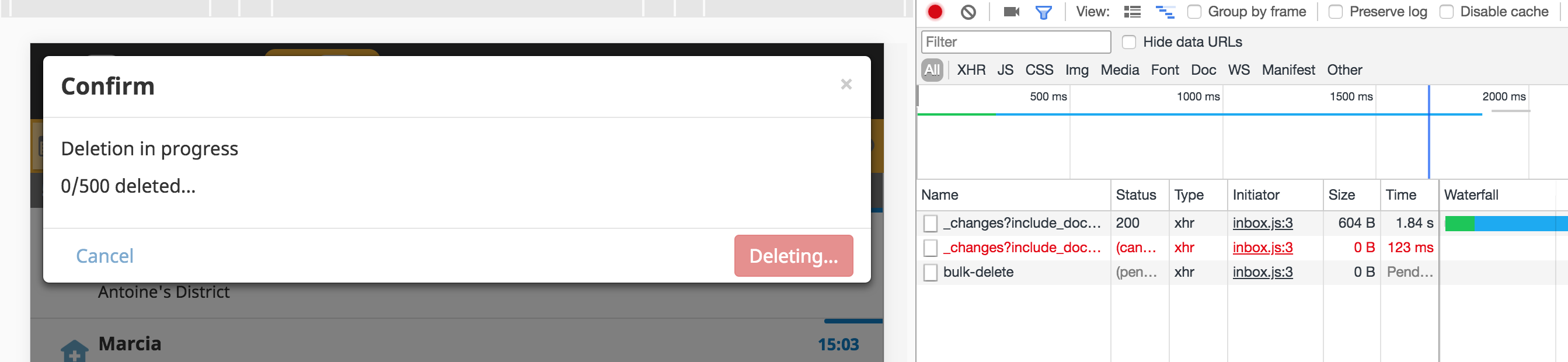
though it takes quite a bit but I guess that's tolerable.
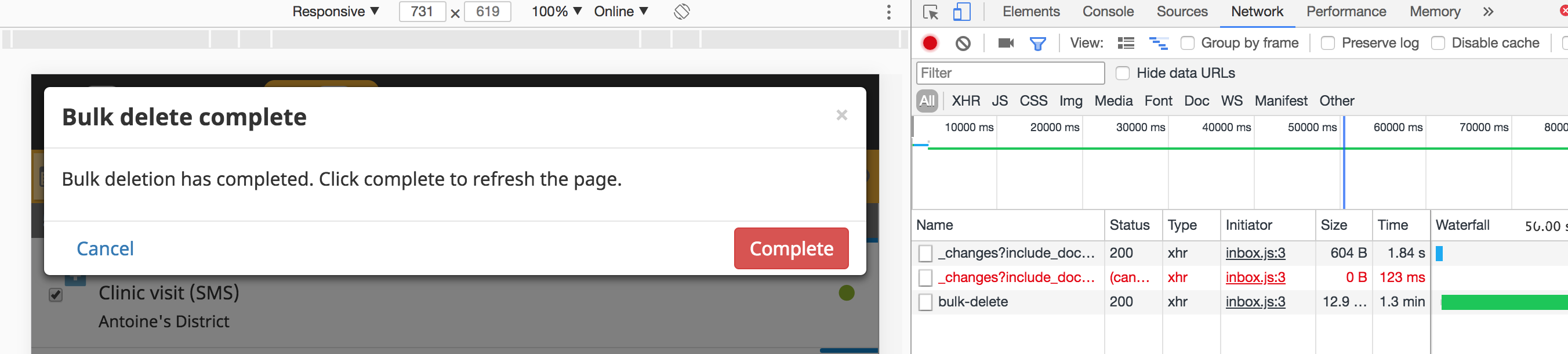
and there is a network error that I think is raised in another issue.
Closing this. Would be good to test it on other instances to see how it goes!
ngaruko
on 19 Apr 2018
@ngaruko are you saying that the 409s are not actually problem?
SCdF
on 19 Apr 2018
@SCdF I agree - we should add them to the end of the queue until they can be deleted, as long as that doesn't cause the app to hang indefinitely.
sglangevin
on 24 Apr 2018
Cool. I still have no idea why this ticket was closed then, since it didn't pass AT, but I'll just raise another one and chuck it into 2.15.x, this one has gotten long anyway.
SCdF
on 25 Apr 2018
Related issues
 mrjones-plip
·
37Comments
sglangevin
·
35Comments
SCdF
·
38Comments
mrjones-plip
·
37Comments
sglangevin
·
35Comments
SCdF
·
38Comments
 alxndrsn
·
31Comments
alxndrsn
·
31Comments
 benkags
·
41Comments
benkags
·
41Comments
Most helpful comment
OK so those are document update conflicts. Were you running sentinel and had just pushed those documents? If so sentinel was probably working on them at the same time.
Regardless though, we should make a decision about how bulk delete handles conflicts. My vote is that bulk delete indicates that you want it gone from the system: if there is a conflict add it to the back of the queue and keep trying until you can delete it. @garethbowen / @sglangevin how does that make you feel?