Chalice: [proposal] Add support for S3 events
We've received numerous requests for S3 event support, but we never had a tracking issue for it. As we start to flesh out sources for lambda events, I wanted to make sure we have a consistent approach.
I propose adding an on_s3_event() decorator, and that all future event sources use the on_<service>_<something else> naming convention. The input parameter is a small abstraction over the event payload to support the most common use case: downloading the object from S3.
Because we don't yet support managed resources (https://github.com/aws/chalice/issues/516), I initially wanted this first version to support pre-existing S3 buckets. That is, you tell us what existing bucket you want us to configure, and we'll configure the appropriate s3 bucket notifications for you (along with the needed policy updates). Here's a complete example of the famous s3 image resizer:
from chalice import Chalice
import boto3
app = Chalice(app_name='s3resize')
s3 = boto3.client('s3')
@app.on_s3_event(bucket='my-preexisting-bucket')
def resize_image(event):
with tempfile.NamedTemporaryFile('w') as f:
s3_client.download_file(event.bucket, event.key, f.name)
resized_file = f.name + '.thumbnail'
with open(Image.open(f.name)) as image:
image.thumbnail(tuple(x / 2 for x in image.size))
image.save(resized_file)
s3_client.upload_file(filename=resized_file,
bucket='my-preexisting-dest-bucket',
key='%s-thumbnail' % event.key)
That's the entire thing. You run chalice deploy, and assuming the source and dest bucket exists, everything just works.
A few things to note in this example:
- There's an optional
filtersandeventskwarg in the decorator. The defaulteventsiss3:ObjectCreated:*so it's omitted from the example. - The
eventparam has a.bucketand.keyattribute to make it easy to download objects from s3. Note this is assuming a single record is sent in the event payload.
Concerns
The biggest concern is that due to us not managing the S3 bucket for you, you have to use a pre-existing bucket, which means that the SAM template generation won't work. The notification configuration is a property of an AWS::S3::Bucket which means you have to create the S3 bucket as part of your CFN template. I see a few possible options here:
- Just don't support
on_s3_eventin SAM templates, generate a helpful error message. This feature would only be available viachalice deploy. - "Make it work" by using custom CFN resources. I haven't done a whole lot of research on this, other than to confirm that this is a viable approach. I'd need to think this through more. It also feels a bit odd leaving a lambda function/custom resource lying around. This has a lot of risk and uncertainty, so it would probably delay this feature being released.
- Add preliminary support for resources (#516). We'd start with an S3 bucket, and we'll need to do another pass through the original proposal. You could then say something like:
@app.resource('s3.Bucket')
class MyBucket:
name = 'some-bucket-name'
@app.on_s3_event(bucket=MyBucket)
def resize_image(event): pass
In this example, we'd also create the S3 bucket for you. Even if we did option (3), we'd still need to decide whether or not to support chalice deploy working with pre-existing S3 buckets. The only benefit of (3) is that it gives people a path forward that rely on the chalice package command, you just have to be ok with us managing the S3 bucket for you.
FWIW I have most of this implemented. We just need to decide on which of the above options we want to go with for chalice package. Let me know what you all think.
cc @stealthycoin @kyleknap
 jamesls
jamesls
All 12 comments
The notification configuration is a property of an AWS::S3::Bucket which means you have to create the S3 bucket as part of your CFN template
That's my personal number one annoyance when it comes to CloudFormation :(
If Chalice starts creating buckets, do I end up with a bucket per stage (or per Chalice app in general)? I tend to either put buckets in separate stacks (NotificationConfigurations can be updated), or use SNS for fanout.
I have only used CF custom resources for AMIs, had not considered them for this usecase. Have similar concerns about the "leftover" Lambda functions and roles needed for custom resources.
 kadrach
on 30 May 2018
kadrach
on 30 May 2018
Not sure if you covered this, but I am assuming that things such as events, prefixes, and suffixes must be configured before hand on the bucket, and are not to be specified in the decorator?
 aalvrz
on 30 May 2018
aalvrz
on 30 May 2018
If Chalice starts creating buckets, do I end up with a bucket per stage (or per Chalice app in general)?
It would be a bucket per stage.
Not sure if you covered this, but I am assuming that things such as events, prefixes, and suffixes must be configured before hand on the bucket, and are not to be specified in the decorator?
The way I have it implemented now, chalice would configure all that for you based on what you specify in the decorator. That way the only requirement is that the S3 bucket exists. So a more fully fleshed out example would be:
@app.on_s3_event(bucket='my-preexisting-bucket',
events=['s3:ObjectCreated:*', 's3:ObjectRemoved:*'],
prefix='images/')
def s3_handler(event):
pass
In the above example, in addition to the normal creation of the lambda function it also makes:
- A
lambda_client.add_permission()call that givess3.amazonaws.compermission to invoke the lambda function along with the s3 bucket as theSourceArn - An
s3.put_bucket_notification_configuration()call with the args from theon_s3_eventdecorator. This call is also smart about injecting the appropriateLambdaFunctionConfigurationfor the chalice lambda function while leaving any existing bucket notification configuration untouched. Given the bucket exists outside of chalice we account for other notification configs you might already have set up on the bucket. It's also smart about deletion, it only removes the config snippet we added.
Of course this only applies to the chalice deploy case. Still haven't figure out what to do about chalice package.
jamesls
on 30 May 2018
Looks like a good start. I do have some question as well that it would be great to clarify:
1) What does the event interface look like for the object passed into the lambda function? I agree that providing the bucket and key is nice because that information is really nested. I think I am mostly interested in if there is some to_dict() method to get the full event?
2) How is the filters parameter suppose to work? Is it going to be essentially the FilterRules member for PutBucketNotificationConfiguration? Where the value would look something like:
python
[
{
'Name': 'prefix'|'suffix',
'Value': 'string'
}
]
3) About this comment: "Note this is assuming a single record is sent in the event payload" Will there ever be more than one event coming back from s3 in a single event payload? If it can potentially happen, what's the plan for that?
As to the concern with SAM, I am leaning toward option 3 (I have not thought too much about the actual interface though, but just the general idea of managed resources) for the following reasons:
1) If you provide just a pre-existing bucket name, it undermines the use of stages as you would using the same bucket for each stage. If there was a way to programatically set that based on the stage, that would be a fine compromise.
2) I think we should get this working with CloudFormation (despite the limitations). The package command with full CI/CD is pretty powerful and I want us to avoid falling into the problem we had before where chalice package only supported a subset of chalice deploy.
3) Chalice usually gives the option for managing the resource on your behalf (I think the only exception today to this is VPC). It would be nice if s3 event followed suit.
I think the ideal solution for me would be one:
1) Both allows for the specification of a pre-existing bucket or the option for chalice to manage the bucket
2) If a pre-existing bucket is specified, have an option for configuring the name of the bucket per stage.
Option 3 almost reaches this, but the second point is still not really covered.
 kyleknap
on 30 May 2018
kyleknap
on 30 May 2018
I want to go through your feedback in more detail later on, but one of your comments also reminded me of another option I wanted to throw out there:
I think we should get this working with CloudFormation (despite the limitations). The package command with full CI/CD is pretty powerful and I want us to avoid falling into the problem we had before where chalice package only supported a subset of chalice deploy.
So at least for my use cases, I care more about having full CI/CD more than I do it being done through cloudformation. As long as I have some chalice command that generates a pipeline for me such that whenever I git push it deploys my app, I'm satisfied. We could offer another version of the generate-pipeline command, that instead of generating SAM templates in the codebuild job, instead generated an alternate "Deploy" stage that ran chalice deploy either via a lambda function or via another (separate) codebuild job.
I realize there's other benefits to using cfn as well, but I still think it would be interesting to explore.
jamesls
on 30 May 2018
What does the event interface look like for the object passed into the lambda function?
This is what I currently have:
@app.on_s3_event(bucket='foo')
def my_handler(event: S3Event): pass
class S3Event(object):
def __init__(self, event):
s3 = event['Records'][0]['s3']
self.bucket = s3['bucket']['name']
self.key = s3['object']['key']
self.original_payload = event
# And then in the on_s3_event() decorator:
class S3EventHandler(object):
def __init__(self, handler):
self.handler = handler
def __call__(self, event, context):
event_obj = self._convert_to_obj(event)
return self.handler(event_obj)
def _convert_to_obj(self, event_dict):
return S3Event(event_dict)
Not that picky on the name, just that I have easy access to the bucket and key so it's trivial to download the S3 object. Having to_dict() instead of original_payload works for me.
How is the filters parameter suppose to work?
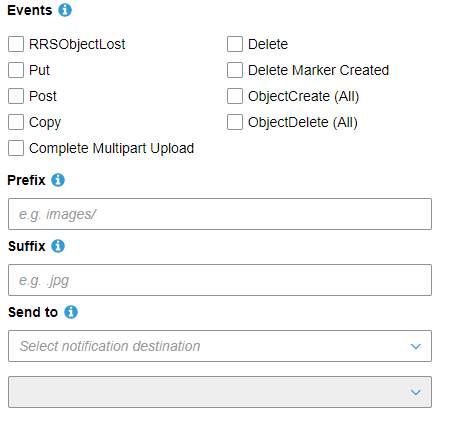
It's not directly exposed. Instead I opted for what's surfaced in the console, take a look at the screenshot from @BigChief45, you just provide an optional prefix and a suffix. And I was planning on just supporting one prefix and suffix for now.
About this comment: "Note this is assuming a single record is sent in the event payload" Will there ever be more than one event coming back from s3 in a single event payload?
From the testing I've done, no that's not the case (it's only a single event) but I can follow up and double check. It's a good question about what to do if there's ever multiple records. I'm not sure. Updating the interface to assume more than one record isn't that bad, it just makes the code slightly more verbose:
def handler(event):
for record in event:
s3.download_file(record.bucket, record.key, '/tmp/foo')
Regarding having per-bucket stages for pre-existing buckets, one option that builds on https://github.com/aws/chalice/issues/608 is to also allow names to be templated based on not only "app params" but also on built-in keys like the stage name. It would be similar in spirit to how you can use ${AWS::Region} in a CFN template. So perhaps, something jinja2-esque like:
@app.on_s3_event(bucket="mybucket-{{ chalice_stage }}")
def handler(event): pass
Another option would be to just expose the stage name on the app object. I can't find the issue now, but I think there was a request to have access to the current stage within your app.py file. So maybe:
@app.on_s3_event(bucket=f"mybucket-{app.chalice_stage}")
def handler(event): pass
Just responding...
Having
to_dict()instead of original_payload works for me.
Yeah I think it makes sense especially since it will make sure we are consistent with the CloudwatchEvent class that we expose.
I can follow up and double check
Yeah it may be good to check. The operations that I am particularly interested in are the batch operations like DeleteObjects.
As to configuring pre-existing bucket names per-stage, I think I prefer exposing the chalice_stage on the app. That in itself would be pretty useful and hopefully is not too difficult to expose.
kyleknap
on 1 Jun 2018
So I went ahead and cleaned up the branch and sent a PR: https://github.com/aws/chalice/pull/860
This branch is ready to be reviewed with docs/tests as well. The only thing left is to figure out what we want to do with chalice package. Right now, chalice package will fail in that PR if you try to use on_s3_event.
After thinking about it more, I see three realistic options, in order of effort (and therefore amount of delay it will add to shipping this feature):
- Don't support it in
chalice package. Clean up the error message to be more instructive. - Add some flag that specifies we should create the bucket for you, but don't actually implement managed resources.
- Implement the minimal subset of managed resources to get this working.
For item 2, I don't think it was discussed in this issue, but the gist would be that we you can indicate that you want us to create the bucket for you, but you couldn't get any of the other functionality/APIs specified in the managed resources proposal. So something like:
@app.on_s3_event(bucket='mybucket', create_bucket=True)
def foo(event): ...
and we'd try to create a bucket with a name <app>-<stage>-<nameprovided>-<randomsuffix> for you. Not sure on the actual interface, maybe that looks too similar to the existing bucket case, so maybe it would be @app.on_s3_event(bucket=Bucket('mybucket', other_params=...)). The bucket would end up in .chalice/deployed/<stage>.json but there wouldn't be any way to query for the deployed bucket name in your app.
At any rate, I think the ability to connect this to an existing bucket is too useful of a feature to remove just because we can't support it in SAM/CFN, and I think custom resources for this need a lot more time to think through before committing to that approach.
So if you agree with that statement, then that means no matter what, chalice package isn't going to work with an existing bucket, and it comes down to whether or not we want to give some path forward for people using chalice package (i.e if you want to use chalice package you have to let us create the bucket for you). FWIW doing (1) for now does not preclude implementing the other options in a future release.
jamesls
on 4 Jun 2018
@jamesls A quick question. If we specify we want to send the notification to a SNS topic. I am guessing that this topic should also already exist before-hand?
aalvrz
on 4 Jun 2018
@jamesls that makes sense. I think that is fine for now to have it only work for existing buckets using chalice deploy.
kyleknap
on 4 Jun 2018
@BigChief45 that's what I had in mind. Fortunately for SNS this isn't going to be an issue (I think) because the subscriptions are a separate resources from the topic (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-sns-subscription.html). I haven't actually confirmed this via chalice package yet, but everything should just work.
jamesls
on 4 Jun 2018
https://github.com/aws/chalice/pull/860 has been merged.
jamesls
on 14 Jun 2018
Related issues
 Erstwild
·
4Comments
Erstwild
·
4Comments
 davidolmo
·
3Comments
davidolmo
·
3Comments
 jarretraim
·
3Comments
jarretraim
·
3Comments
 whatsdis
·
4Comments
whatsdis
·
4Comments
 calz1
·
3Comments
calz1
·
3Comments
Most helpful comment
It would be a bucket per stage.
The way I have it implemented now, chalice would configure all that for you based on what you specify in the decorator. That way the only requirement is that the S3 bucket exists. So a more fully fleshed out example would be:
In the above example, in addition to the normal creation of the lambda function it also makes:
lambda_client.add_permission()call that givess3.amazonaws.compermission to invoke the lambda function along with the s3 bucket as theSourceArns3.put_bucket_notification_configuration()call with the args from theon_s3_eventdecorator. This call is also smart about injecting the appropriateLambdaFunctionConfigurationfor the chalice lambda function while leaving any existing bucket notification configuration untouched. Given the bucket exists outside of chalice we account for other notification configs you might already have set up on the bucket. It's also smart about deletion, it only removes the config snippet we added.Of course this only applies to the
chalice deploycase. Still haven't figure out what to do aboutchalice package.