Carla: add semantic label to lidar point cloud
The projection of semantic label on lidar data is not accurate
I do the following to add semantic labels to point cloud data from lidar sensor in carla:
1.I get the intrinsics as stated in #56.
2.Project 3d points into semantic segmentation image of different views(front, left, right, rear).
effect:
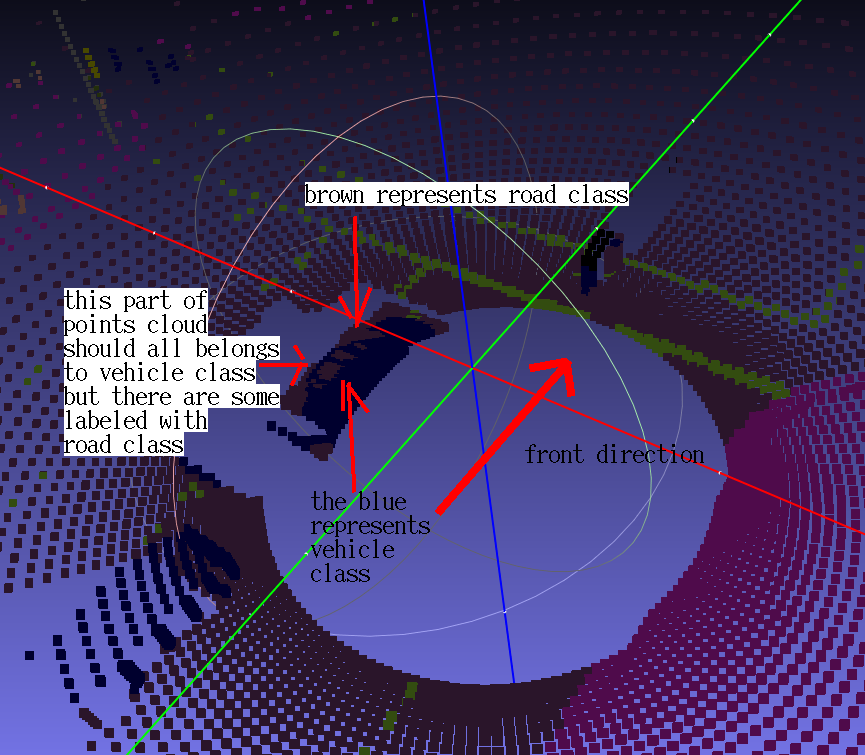
Totally, the road, buildings and surrounding look good, but the vehicles and pedestrains seem to have some errors.
The general effect:

The local accuracy is not accurate:
The corresponding semantic images of front, left, right and rear views:
front:

left:

right:

rear:

The problem is: the lidar data points cast onto the vehicle does not have the same shape as the vehicle. As a result, the projection has deviation. Does anybody have any idea of how to improve the accuracy?
 Tom-Huang
Tom-Huang
All 5 comments
#1010 might be helpful.
 user025
on 14 Jun 2019
user025
on 14 Jun 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 13 Aug 2019
stale[bot]
on 13 Aug 2019
Could you please share your code for projection? It will be very helpful.
 heshameraqi
on 6 Feb 2020
heshameraqi
on 6 Feb 2020
Could you please share your code for projection? It will be very helpful.
You can check my github repo carla_data_collection. Hope it will help!
Tom-Huang
on 6 Feb 2020
This feature has been added in CARLA in #3131, with better performance and more accurate bounces in vehicles and pedestrians.
 marcgpuig
on 31 Jul 2020
marcgpuig
on 31 Jul 2020
Related issues
 gkahn13
·
24Comments
gkahn13
·
24Comments
 nicksunyang
·
25Comments
nicksunyang
·
25Comments
 rohanb2018
·
27Comments
rohanb2018
·
27Comments
 rikardomarenzzi
·
39Comments
rikardomarenzzi
·
39Comments
 FelixTFD
·
20Comments
FelixTFD
·
20Comments
Most helpful comment
You can check my github repo carla_data_collection. Hope it will help!