Cache: [warning]Cache service responded with 503 during chunk upload.
Hi,
Today, we have experienced above cache step failure reason almost always with the following case:
- Workflow runs on a self-hosted runner that has a slow upload rate (~4Mbits per sec)
- Cached content is large (~80MB tar)
This makes cache action pretty unreliable. We would be ok for very slow cache uploads, but getting 503 makes our workflows very hard to optimize.
Is this a known issue that GitHub team is actually working on? There are #154 and #200 , but I didn't see a progress on any of them.
Thanks!
 manuyavuz-pointr
manuyavuz-pointr
All 10 comments
Could you please post here or e-mail the org and repo name to dhadka (at) github (dot) com? I'll then take a look at the logs to see what's causing the 503s.
 dhadka
on 14 Apr 2020
dhadka
on 14 Apr 2020
Given a few issues have been opened reporting this problem, I've created a "catch all" issue to track the investigation and mitigation: https://github.com/actions/cache/issues/267
dhadka
on 21 Apr 2020
I am also getting it with Mac OS: https://github.com/ankitects/anki/pull/584 - https://github.com/ankitects/anki/pull/584/checks?check_run_id=639592894#step:56:3
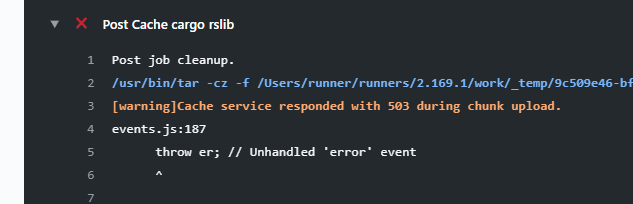
This is a quite frequent and useless issue with Mac OS. If it does not have internet connection/whatever error, it should not fail my build by any means other than making us waist time looking at why the build failed.
 evandrocoan
on 3 May 2020
evandrocoan
on 3 May 2020
@evandrocoan Tracking the fix with this issue: https://github.com/actions/cache/issues/287. There's an unhandled 'error' event coming from NodeJS. Even though the upload call is within a try-catch block, it's still failing.
dhadka
on 3 May 2020
I'm seeing this intermittently on my self-hosted macOS runners. It's very annoying since it requires my to re-run all of my jobs on something that should just be an optimization.
 wagenet
on 7 May 2020
wagenet
on 7 May 2020
PR to handle error events on streams - https://github.com/actions/cache/pull/300
dhadka
on 9 May 2020
@dhadka looks like the error handling has been fixed in master. However, it's still very annoying that it happens, since losing a cache means more CI time. Are there any plans to fix the underlying issue?
wagenet
on 12 May 2020
Now I am having issues of the cache post-action handling indefinitely and having the job canceled by CI: (https://github.com/ankitects/anki/runs/666759676)

evandrocoan
on 12 May 2020
@wagenet We have a bunch of fixes being ported to @v1 at the moment - https://github.com/actions/cache/pull/308. That should help significantly with the lost cache issue caused by upload errors.
If you do have a self hosted runner with potentially slow upload speeds, you could also consider setting the CACHE_UPLOAD_CHUNK_SIZE env var on the cache step to something smaller. The default is 33554432 (32 MBs). Using smaller chunks could help ensure each upload completes within the request timeout (60 seconds).
Edit: Having said that, we'll be looking next at the server-side to see if there is room for improvement there.
dhadka
on 12 May 2020
@dhadka Thanks. FWIW, I've got a claimed 25Mbps upload, speed tests are getting between 15 and 20 right now. (I'm using a runner on my local machine right now.)
wagenet
on 12 May 2020
Related issues
 ConorSheehan1
·
4Comments
ConorSheehan1
·
4Comments
 KhaledSakr
·
3Comments
KhaledSakr
·
3Comments
 Cerberus
·
5Comments
Cerberus
·
5Comments
 gladhorn
·
4Comments
gladhorn
·
4Comments
 s-weigand
·
5Comments
s-weigand
·
5Comments
Most helpful comment
I'm seeing this intermittently on my self-hosted macOS runners. It's very annoying since it requires my to re-run all of my jobs on something that should just be an optimization.