I understand that Issue is not related to the code of this repository, but I would like to discuss with many people, so I open Issue here. (and I know community forums exist. but many people probably don't know yet.)
First, I really appreciate the GitHub team for adding the cache feature to GitHub Actions. That's great for us! But, In recent years, node_modules is too large. 200MB can't cover it. It's the same in other languages. For example, using esy to install the opam packages, it can easily exceed 800MB. Is there a way to increase the cache limit? or if individual cache limits are removed, it becomes a relatively realistic limit. I know that if the file size is too large, save/restore may insanely slow down. but it shouldn't be limited on the cache action side.
 smorimoto
smorimoto
All 108 comments
Individual caches are limited to 200MB and a repository can have up to 2GB of caches. Once the 2GB limit is reached, older caches will be evicted based on when the cache was last accessed.
Yes please remove individiual cache limit. 2GB per repo is reasonable.
 cemo
on 31 Oct 2019
cemo
on 31 Oct 2019
For our middle-sized react-native project, archived node_modules directory is 260 MB and CocoaPods directory is 202 MB
 dentuzhik
on 31 Oct 2019
dentuzhik
on 31 Oct 2019
Typically python virtualenv are also >500MB these days. These are cached to avoid re-compiling some modules each time like lxml, numpy etc.
 sidmitra
on 31 Oct 2019
sidmitra
on 31 Oct 2019
In my opinion, 2GB per repository is still small for medium ~ large project.
smorimoto
on 31 Oct 2019
The file size limit is defined here, so I think we can easily remove the individual limit. but, we can't do anything about the limit per repository. 2GB is probably enough for JavaScript developer, but not so good for a native developer like me.
smorimoto
on 31 Oct 2019
I would appreciate a higher limit (e.g. 5BG) for enterprise/paying customers as wel.
 hazcod
on 31 Oct 2019
hazcod
on 31 Oct 2019
Well, my guess is that you will be able to increase the cache limit by charging like Git LFS.
smorimoto
on 31 Oct 2019
We are working on the long term plan for how we will enable larger limits. Charging for it like we do for packages or actions artifacts is something we are considering.
 chrispat
on 31 Oct 2019
chrispat
on 31 Oct 2019
The compiled deps for my small Rust project is 500 MB, the cache will need to be considerably larger to support Rust.
 lpil
on 31 Oct 2019
lpil
on 31 Oct 2019
For what it's worth, a project I'm on has a 766MB node_modules folder, but the caching works fine. It compresses the folder before caching, so I assume the 200MB limit is on the compressed asset.
 andrewhampton
on 31 Oct 2019
andrewhampton
on 31 Oct 2019
Well, I understand that there is such an example when compressed. But other existing CI providers do not limit individual cache size. (Although they recommend keep it under 500MB.) I think there is no need to limit it.
smorimoto
on 31 Oct 2019
so I assume the 200MB limit is on the compressed asset.
That's correct, the limit is after we tar and gzip the directory specified by path. I'll update the README to make that more clear
 joshmgross
on 31 Oct 2019
joshmgross
on 31 Oct 2019
This is a great start, but we've also hit the limit before trying.
We have a monorepo, four apps. The total is around 600 MB.
We also need the ability to cache the node_modules for each of the packages. CircleCI took this approach - https://www.benpickles.com/articles/77-caching-yarn-workspaces-on-circleci
 mrmckeb
on 1 Nov 2019
mrmckeb
on 1 Nov 2019
Couldn't github implement a cross-repository deduplication system for cached assets, if storage costs are a problem ?
 lovasoa
on 1 Nov 2019
lovasoa
on 1 Nov 2019
Couldn't github implement a cross-repository deduplication system for cached assets, if storage costs are a problem ?
Especially for a lot of patterns like specific paths in things like programming language compiled objects, node_modules subdirectories, etc... are all ripe for de-duplication in a very very efficient way if made in such a way that the patterns are known, and that can then be made generic.
 OvermindDL1
on 1 Nov 2019
OvermindDL1
on 1 Nov 2019
It's easy to say about deduplication. However, it is more difficult to make an effective system in this area that will work efficiently for many small files. If deduplication will be performed at the data block level, this solution is ineffective in the case of data compression. If deduplication will be performed at the file level, it is easy to achieve a large communication overhead. In this way, the GitHub team opens up a huge problem, which should rather be the task of the team responsible for Azure Storage Blob service.
 ad-m
on 1 Nov 2019
ad-m
on 1 Nov 2019
On my first attempt to use this to cache docker layers I hit the file limit.
Cache size of 945984259 bytes is over the 200MB limit, not saving cache.
 tuler
on 1 Nov 2019
tuler
on 1 Nov 2019
@tuler , have you tried to fork action? Is the limit verified also on the GitHub side?
ad-m
on 1 Nov 2019
@tuler , have you tried to fork action? Is the limit verified also on the GitHub side?
The per file limit is here
The repo limit is on GitHub side.
Not sure that forking will help.
tuler
on 1 Nov 2019
945984259 bytes is under 2 GB per repo limit.
I saw this code for per file limit, hence I wonder if the limit is also verified on the server side.
ad-m
on 1 Nov 2019
Per file and repo limit are verified server-side. The per-file limit in the action is to avoid an unnecessary upload that the server will reject.
joshmgross
on 2 Nov 2019
When do you think you can remove individual limit? (if you will do)
smorimoto
on 2 Nov 2019
On a react native project, .tgz cache file for yarn cache is 666Mib, so it worth having a limit ≈ 1Gib.
 shouze
on 4 Nov 2019
shouze
on 4 Nov 2019
For reference: installing the latest haskell compiler, runtime and standard libraries (which is necessary for every compilation) takes up 1.59 GB
So even the 2 GB repo-wide limit would hardly fit an actual project cache (which probably has dozens of dependencies)
 ilyakooo0
on 4 Nov 2019
ilyakooo0
on 4 Nov 2019
@ilyakooo0 Have you already tried actions/setup-haskell?
smorimoto
on 5 Nov 2019
@imbsky not really, no
I just call stack directly
Skimming the source code it looks like setup-haskell just caches ghc and cabal somewhere, which doesn’t seem like it take more than 5 minutes off compiling a whole project.
ilyakooo0
on 5 Nov 2019
I'm doing a gradle build on a relatively small project and I'd like to save Github some effort by not downloading the world on every build. However, 200MB is simply not adequate for that even on a small project. My tiny project blew right through that on the first build and I got a warning (411485068 bytes).
As this is an OSS project I don't mind the extra build time but I imagine that having a lot of OSS gradle and maven builds without meaningful caching is going to be quite a strain on the infrastructure and I assume the goal with this would be to save some money on not doing pointless things over and over again. So from that point of view, I'd just raise the per build limit to 2GB.
 jillesvangurp
on 5 Nov 2019
jillesvangurp
on 5 Nov 2019
Same problem here. I hit the cache limit on my first build for the node_modules folder on a really small Vue CLI project. It'd be great to have the cache limits increased or configurable in some way.
 ryanjwilke
on 5 Nov 2019
ryanjwilke
on 5 Nov 2019
@jillesvangurp I think it's probably more expensive to use computing resources than the network bandwidth of downloading caches. but your thoughtfulness is amazing!
smorimoto
on 5 Nov 2019
Yes please a increase of size would be awesome, even if paid - we're in the rust boat too and even small rust stuff racks up megabytes of cache really really fast :sob:
 Licenser
on 5 Nov 2019
Licenser
on 5 Nov 2019
The individual limit has been bumped to 400MB, ensure that you're pinned to v1 or v1.0.1 to get that update. We're working on increasing it further.
joshmgross
on 5 Nov 2019
The individual limit has been bumped to 400MB
I'm very happy that this issue seems to have made progress!
We're working on increasing it further.
Great!
smorimoto
on 6 Nov 2019
That's correct, the limit is after we
tarandgzipthe directory
@joshmgross, consider using zstd as a drop-in-replacement for gzip, which is very much deprecated on modern environments. Zstandard will give you:
- smaller results if you give it the _same runtime_ as gzip, or
- faster results at the _same compressibility_ of gzip.
In all scenarios, decompression is multiples faster than gzip, and will likely be disk bound even if writing to solid state storage; which is fantastic on cache-hits (even faster extraction!)
 kcgen
on 6 Nov 2019
kcgen
on 6 Nov 2019
@krcroft how do you recommend implement it in NodeJS? AFAIK GitHub Cache API doesn't enforce any compression format, so we can fork that action & make PR.
ad-m
on 7 Nov 2019
@krcroft how do you recommend implement it in NodeJS? AFAIK GitHub Cache API doesn't enforce any compression format, so we can fork that action & make PR.
@ad-m, I'm not a NodeJS developer, but maybe a wrapper like this: https://github.com/zwb-ict/node-zstd would do (provided it allows you to use the latest zstd version).
kcgen
on 7 Nov 2019
If the GitHub action team installs zstd in all virtual environments by default, we can switch to zstd in five minutes. (and wrapper library isn't required) but currently it's not installed, so I don't know how to do it simply.
smorimoto
on 7 Nov 2019
gzip, which is very much deprecated on modern environments
Oh! I didn't know this. Please could you point me to further info about which envs have deprecated gzip and when?
 hugovk
on 7 Nov 2019
hugovk
on 7 Nov 2019
gzip, which is very much deprecated on modern environments
Oh! I didn't know this. Please could you point me to further info about which envs have deprecated gzip and when?
Linux BTRFS filesystem: _ZSTD -- (since v4.14) compression comparable to zlib with higher compression/decompression speeds_, here: https://btrfs.wiki.kernel.org/index.php/Compression
Arch Linux's package management format (as of Sept-2018) is migrating to zstd: _"zstd brings faster compression and decompression, while maintaining a compression ratio comparable with xz. This will speed up package installation with pacman, without further drawbacks."_ , here: https://www.archlinux.org/news/required-update-to-recent-libarchive/
Ubuntu package management moving to zstd: _"We had a coding day in Foundations last week and Balint and Julian added support for zstd compression to dpkg [1] and apt [2]."_ here: https://lists.ubuntu.com/archives/ubuntu-devel/2018-March/040211.html, adoption began in Ubuntu 18.10.
Fedora's RPMs are now packed by zstd: _"RPMs have switched to zstd compression level 19. Users will benefit from faster package decompression. Users that build their packages will experience slightly longer build times."_, here: https://fedoraproject.org/wiki/Changes/Switch_RPMs_to_zstd_compression#Contingency_Plan
Nintendo switch's latest homebrew format has 'switched' exclusively to zstd compression: https://github.com/nicoboss/nsz (versus the prior that also supported lzma, https://github.com/nicoboss/nsZip)
RFC8478 allows web pages and content to be compressed with zstd, here: https://tools.ietf.org/html/rfc8478
Pretty much everywhere compression is used, zstd is in place or is being considered.
kcgen
on 7 Nov 2019
Thanks for the info, good to know! And especially as this caching system is fully internal: the cache action is the only producer and consumer of the files.
Some quick tests (macOS Mojave) on a 162 MB node_modules directory, first archived to a 110 MB node_modules.tar:
| command | time | command | time |
| - | - | - | - |
| zstd node_modules.tar | 0.730s | gzip node_modules.tar | 3.625s |
| unzstd node_modules.tar.zst | 0.855s | gunzip node_modules.tar.gz | 0.490s |
| total | 1.662s | total | 4.138s |
-rw-r--r-- 1 hugo wheel 110M 7 Nov 11:43 node_modules.tar
-rw-r--r-- 1 hugo wheel 21M 7 Nov 11:43 node_modules.tar.gz
-rw-r--r-- 1 hugo wheel 18M 7 Nov 11:43 node_modules.tar.zst
That's at default zstd compression level 3. Some more, including min and max:
| level | time | size |
| - | - | - |
| 1 | 1.489s | 22 MB |
| 3 | 1.662s | 18 MB |
| 7 | 3.631s | 16 MB |
| 10 | 7.087s | 14 MB |
| 19 | 51.584s | 12 MB |
$ tar --version
bsdtar 2.8.3 - libarchive 2.8.3
$ gzip --version
Apple gzip 272.250.1
$ zstd --version
*** zstd command line interface 64-bits v1.4.3, by Yann Collet ***
@hugovk excellent work in getting actual ground truth! Extraction of zstd should be faster, so we might be seeing variability in underlying IO storage influencing the numbers.
Do you know of pure-ram, user-writeable area on macOS, like /dev/shm on linux? This will help remove the underlying storage from both sets of numbers, giving you a pure apples to apples comparison. (as much as possible anyway.. we still can't control CPU contention coming from other VMs on the same host; but you can take "the best of" X runs instead, to try to discover it).
You can also prefix the commands with 'time' to see wall clock versus cpu clock times, the latter which excludes resource wait-times.
kcgen
on 7 Nov 2019
@krcroft in all of our tests the underlying storage has always been the bottle neck. The I/O for storage on any cloud hosted VM is never going to match a local SSD. I would be very surprised if zstd vs gzip made a material difference on a normal sku VM over say a 1000 samples.
chrispat
on 7 Nov 2019
Interesting @chrispat; if you're IO bound on both sides, then you can keep increasing the compression ratio 'for free' until the point when zstd is not able to read data faster than the disk can provide it. During extraction of cache hits, zstd will afford your lower CPU cycles per MB written vs gzip, so it frees those cycles for other VMs to use.
@hugovk, can you add -T0 to the zstd compression arguments? This enables threaded compression.
kcgen
on 7 Nov 2019
$ cat 1.sh
rm node_modules.tar.zst
time zstd -1 -T0 node_modules.tar
rm node_modules.tar
time unzstd node_modules.tar.zst
$ time sh 1.sh
node_modules.tar : 19.96% (115219968 => 22995765 bytes, node_modules.tar.zst)
real 0m0.579s
user 0m0.719s
sys 0m0.270s
node_modules.tar.zst: 115219968 bytes
real 0m1.028s
user 0m0.197s
sys 0m0.595s
sh 1.sh 0.92s user 0.93s system 109% cpu 1.691 total
I used the real values for each command in the table above, and the total as the total.
With -T0:
| level | time | size |
| - | - | - |
| 1 | 1.691s | 22 MB |
| 3 | 1.966s | 18 MB |
| 7 | 5.252s | 16 MB |
| 10 | 6.708s | 14 MB |
| 19 | 49.307s | 12 MB |
These are just rough numbers to get the general idea. Someone could set up a test on GHA to compress and uncompress at different levels.
hugovk
on 7 Nov 2019
Right on @hugovk. Your numbers should give the GitHub crew something to play with.
zstd's extraction user_time of < .2s for 110MB of resulting data means zstd is extracting at 550MB/s, but we see the kernel burning 3-fold that likely primarily spent in the filesystem layer of the kernel (CPU bound at roughly 220MB/s; we should see similar kernel overhead on Windows and lower overhead under Linux).
Finally, the IO subsystem itself needs a full second to lay down the 110MB worth of data, confirming what @chrispat mentioned.
So in order of bottlenecks, first we have the underlying storage which appears to only write at 110MB/s, then the OS X kernel at roughly 220MB/s, and finally zstd capable of 550MB/s (atleast for this particular data set under test).
kcgen
on 7 Nov 2019
@chrispat:
@krcroft ... I would be very surprised if zstd vs gzip made a material difference on a normal sku VM over say a 1000 samples.
Please see this report of how Facebook has reaped various benefits by replacing zlib with zstd across their organization: https://engineering.fb.com/core-data/zstandard/
kcgen
on 7 Nov 2019
For accurate comparisons, it'd be best to try these tests on the hosted runners.
And as mentioned above, note that we tar and gzip in a single tar command so an accurate test would be comparing:
- Tar
node_moduleswith-zflag - Tar
node_modulesand then compress that tar file withzstd
We also should optimize for speed for the restore scenario, since with a proper cache key and setup that will be more common and will contribute to any savings gained from caching. Thus, decompression time should be weighed more heavily in any comparisons.
joshmgross
on 7 Nov 2019
To be fair, please perform the zstd compression across a pipe on-the-fly (similar to how tar feeds the zlib library internally), which avoids writing an intermediate .tar file.
Here's a side-by-side comparison you can paste into your shell.
Adjust the DIR= value to match a largish directory you have.
DIR=node_modules
time (tar -czf "${DIR}.tar.gz" "${DIR}" && sync); du -sh "${DIR}.tar.gz"
time (tar -c "${DIR}" | zstd -T0 -q -f -o "${DIR}.tar.zstd" && sync); du -sh "${DIR}.tar.zstd"
time (tar -c "${DIR}" | zstd -10 -T0 -q -f -o "${DIR}.tar.zstd" && sync); du -sh "${DIR}.tar.zstd"
Note that we sync after compression to remove variability in the kernel's VFS write-buffer.
Description of the commands are:
- gzip with defaults
- zstd with defaults (
-qonly report errors and-foverwrites, both to match tar's behavior) - zstd with compression set to match gzip's CPU time (on my system, that's
-10, but VMs or desktops with faster or more cores will be able to go higher).
Results:
time (tar -czf "${DIR}.tar.gz" "${DIR}" && sync); du -sh "${DIR}.tar.gz"
real 0m0.528s
user 0m2.666s
sys 0m0.073s
50M node_modules.tar.gz
time (tar -c "${DIR}" | zstd -T0 -q -f -o "${DIR}.tar.zstd" && sync); du -sh "${DIR}.tar.zstd"
real 0m0.259s
user 0m0.256s
sys 0m0.133s
43M node_modules.tar.zstd
time (tar -c "${DIR}" | zstd -10 -T0 -q -f -o "${DIR}.tar.zstd" && sync); du -sh "${DIR}.tar.zstd"
real 0m0.999s
user 0m2.592s
sys 0m0.133s
32M node_modules.tar.zstd
zstd wins in both cases:
- at default compression: 10x faster with a 14% smaller archive, or
- at level 10 (*): equivalent speed to gzip with a 36% smaller archive
(*) Your gzip-performance-equivalent compression might be different; adjust it until zstd's user time matches gzip's user time.
kcgen
on 7 Nov 2019
@joshmgross Could you pin this issue for extra visibility? Many people around me are confused because they couldn't find this issue.
smorimoto
on 12 Nov 2019
@imbsky Great suggestion, I've pinned the issue
joshmgross
on 12 Nov 2019
@joshmgross Thank you!
smorimoto
on 12 Nov 2019
For caching Haskell packages built in ~/.cabal/store, our repository of one executable exceeds 800MB as reference
 bubba
on 13 Nov 2019
bubba
on 13 Nov 2019
@joshmgross It seems that zstd can be installed in the following way. Is it possible to include these into this action?
Ubuntu:
apt install zstd
macOS:
brew install zstd
Windows:
choco install zstandard
and this works on all platform.
tar --use-compress-program zstd -cf cache_directory.tar.zst cache_directory/
@imbsky Thanks! Will have to factor in the install time for any potential savings. Ideally, it's added to the hosted runners (via https://github.com/actions/virtual-environments/issues/89)
I'll follow up with that team
joshmgross
on 14 Nov 2019
@joshmgross That's cool! Thank you!
smorimoto
on 14 Nov 2019
@joshmgross, if possible, allow the user to specify the compression level (up to -22 --ultra --long). This will let the user trade-off longer one-time cache-creation times for improved success of squeezing their data under the going limit.
These 'long pole' use-cases are exactly those that benefit the most from caching.. because their huge number of dependencies typically take the longest amount of time to fetch and install.
kcgen
on 14 Nov 2019
I don’t like the idea of adding a bunch of extraneous inputs for things like compression level. I think it might be better if we update the logic such that if the user specifies a file instead of a directory we will just upload that file instead of running our tar and compress. That way the user could use anything they wanted but would be responsible for dealing with compression and extraction.
chrispat
on 16 Nov 2019
I'm sorry, I was misread it. (I'm not a native speaker...) The compression level option is too overkill. But CircleCI works just by specifying a directory and/or file. Zstandard is a good algorithm, but I think the discussion about it has shifted the original purpose a little. What our community wants is a bump of the cache limit, not an improvement of how it works.
smorimoto
on 16 Nov 2019
Of course, I understand that better compression and decompression times will make the cache faster, but the current 400 MB limit doesn't even allow caching for projects that really need it.
smorimoto
on 16 Nov 2019
I agree @imbsky;
Compiling '_hello world_' with Clang on Windows requires installing msys2 and clang: a 15 minute task that (after compressing) exceeds the 400MB limit by three-fold.
GitHub: if you're are serious about caching then please provide a sane cache limit.
A sane limit is one that allows caching "hello world" for common dev-stacks across your three platforms.
kcgen
on 16 Nov 2019
Could you increase or remove (Increase to 2GB) individual cache limits to 1GB?
smorimoto
on 19 Nov 2019
By doing so, many companies and people can use GitHub Actions.
smorimoto
on 19 Nov 2019
@krcroft the goal of this feature is not to cache the entire VM as I very much doubt that would have the desired results. The point of the feature is to cache things that are either expensive to generate or don't change often that are part of your project.
Defining a sane limit is also very subjective one persons 2 GB sane limit might seem too small to the person that wants 1 TB.
As for software that should already exist on the virtual environments please file an issue at github.com/actions/virtual-environments
chrispat
on 19 Nov 2019
For reference, the well-known packages of OCaml called Core and Core_kernel and more were compressed to 1.2GB. Bumping individual limit to 2GB should avoid a lot of build time for quite a few ecosystems.
smorimoto
on 19 Nov 2019
@chrispat,
Yes, I'm currently caching the installed dependencies needed to compile hello world in C++ per your criteria: large, slow to install, and rarely change. It also matches GitHub's own cache examples that exclusively depict caching development dependencies for various languages.
When not cached, installation takes between 4 minutes (macports+gcc on OSX) and 7 minutes (msys2+gcc on Windows). Restoring from hot cache collapses these to roughly 30s or less.
You mentioned tackling this via having these dependencies built into the VM: yes, I see GitHub provides Go, Ruby, Python, Gradle, and other heavyweights on the macOS image, where as C/C++ is non-existent across the board except for VisualStudio on Windows, so I will take your suggestion and open an issue.
(If C++ is to be given equal footing, then GCC and Clang should be available on all three VMs out of the box).
kcgen
on 19 Nov 2019
In addition to an increased individual cache size, it would be lovely to cache the vcpkg/installed/-directory. Building dependencies takes for us actually 12 min (in comparison to the build time of project: 10 Minutes) and this is still not cachable because it's outside of GITHUB_WORKSPACE.
__EDIT:__ What would be perfect actually would be either adding some software from vcpkg to the images. But I think what could be also a solution would be to exclude directories like vcpkg/installed from counting into the individual cache size or to make an own action for it that takes care of the caching itself and has higher limits.
 simonsan
on 20 Nov 2019
simonsan
on 20 Nov 2019
Space-sensitive cache-crew: here are real-world cache results operating with Zstandard, which really put the clamps to my MacPorts C++ dev stack:
700MB packed to just under 100MB:
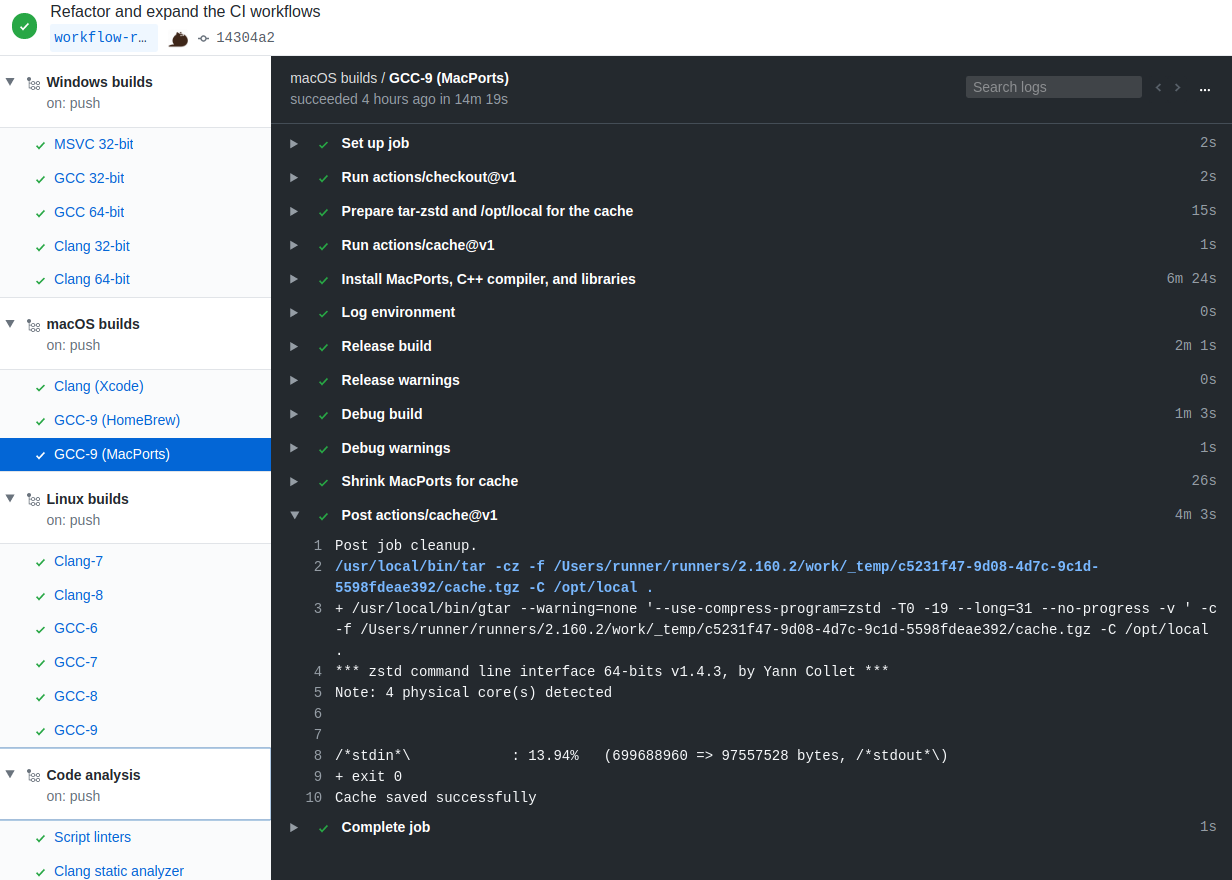
Hot-cache restored in 13s; sure beats the 6 minutes and 24 seconds it took to install it (first screenshot):
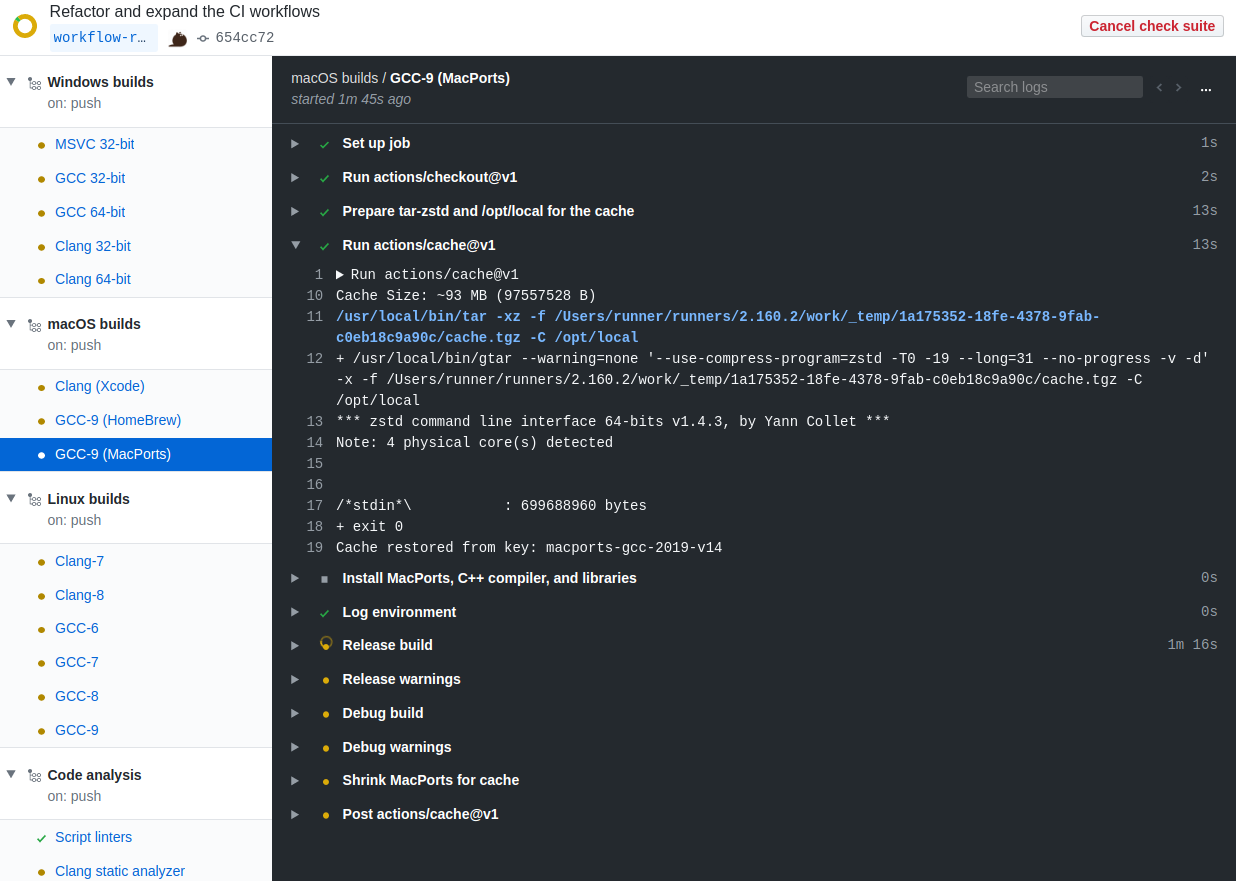
OK -- will now promptly shut up about using zstd :zipper_mouth_face: I won't further detract from the focus of growing the limit, but wanted to share some real-world data :-)
Thumbs up to GitHub's cache-team and considering raising the allotment: less time and fewer CPU cycles is good for our sanity and the environment.
kcgen
on 20 Nov 2019
Don't get me wrong! I like Zstd, too! It's especially great because it's used internally. But what is needed earliest is the bumping the individual limit. I wanted to share this with the GitHub team!
smorimoto
on 20 Nov 2019
The "too small" debate is endless.
You need to put a price tag on it.
Is this already part of the "Storage for Actions and Packages" I see in my billing page?
tuler
on 20 Nov 2019
Yes, I agree. and if I can bump the cache limit per repository by paying for it, that would be good. But why are there individual cache limit?
smorimoto
on 20 Nov 2019
It's essentially meaningless to bump the per-repository limit by paying for it if there are individual limits.
smorimoto
on 20 Nov 2019
I don't agree with "put a price tag on it". We make FLOSS and I'm not willing to pay a multi-billion dollar company ("Hello Microsoft!") for a few MiBs while I spent my spare time doing things on this platform. Either this platform is welcoming FLOSS-devs with open arms and gives them an environment to grow/feel good - or I will just use an alternative, as I did before. I don't want to cast a poor light on GH Workflows/Actions, though. It's a nice development for the platform, but it has a long way to go. Better caching and adopting images to the needs of devs, while saving build time and reducing the ecological fingerprint is just a small step.
simonsan
on 20 Nov 2019
@simonsan all I'm saying is that storage costs money. GH can, and probably will, establish a "free" quota, for FLOSS. But for some people that won't be enough, and they must charge for it, as they already do for everything else. It's a business.
tuler
on 20 Nov 2019
@tuler For sure, businesses keep being business and I've got no problem to charge them for the service they get. The point is, that with 400 MiB individual cache size you can probably cache smaller projects, but as soon as you have a complete compiler collection (llvm/clang) or GUI stuff (Qt) [that again is not pre-installed] you are basically far over. That this is not considered seems a bit odd for me. As caching is basically something that you don't need to redownload/rebuild software/parts of software all over again. To set a limit at 400 MiB is a joke to me, because what do you want to do with that amount? Caching basically starts at this filesize and GH sets the limit there. It's seems kind of absurd to me, honestly. And even more, I need to take more effort to get to tweak my workflow file to get under that limit. You know how many hours I spent to figure out what I need to not cache that I come under the 400 MiB? A few - just a waste of time honestly. I could have been productive in this time, but no, Github wants me to find a way how I can build my Software fast without them investing too much. So I now need to make the work for them (basically) to figure out how I get their system up and running.
You know, if you don't want me to use your Github Workflow/Actions stuff - why don't you say it directly to me? :-D I could spare all this time and effort then^^
simonsan
on 21 Nov 2019
A lot of people who come to this repository are doing web development and talking from their experience, but 400 MB is clearly NOT enough for native development. 400 MB in the native development field is only about 40 MB in the Web development field.
smorimoto
on 21 Nov 2019
We understand the business and the cost, but we can't cache anything.
smorimoto
on 21 Nov 2019
Caching should be a thing that you don't spend hours with to optimize everything. It should be as easy as possible to stay productive. If someone needs many options, fine, give it to him => optional. But make the basic caching as easy as possible. Take Travis Caching as an example. Give a directory to cache (not relative to some build/runner dir) and it gets cached for the next builds as long as it doesn't change during the build, otherwise it gets updated and then cached in the last state. I could cache the brew cache under MacOSX without problems. Here I need to make a complete cleanup (because of for me unecessary pre-installed dependencies) - which means deinstall everything and then install my stuff to then cache it etc. It's absurd. With this people come with the idea to you to pre-install the smallest bit of software (as in doxygen & co) to not use the cache for it. Instead of making it easy to (auto)cache dependencies and keeping the images as small as possible (what you might already do, no offense).
I basically mean:
name: Ubuntu-CI
on: [push, pull_request]
cache:
directories:
/usr/local/
$GITHUB_WORKSPACE/.bin
software:
apt
pip
brew
Bam, ready. For example.
simonsan
on 21 Nov 2019
@simonsan: You know how many hours I spent to figure out what I need to not cache that I come under the 400 MiB?
Well said! To cache C++ dependencies (Brew's GCC installation), I've had to resort to brutal mass deletions, stripping binaries, and subverting the cache to use zstd unbeknownst to it.
# If we don't have /usr/local then brew hasn't installed anything yet
cd /usr/local || exit 0
# Ensure we have sudo rights
if [[ $(id -u) -ne 0 ]] ; then echo "Please run as root" ; exit 1 ; fi
user="${SUDO_USER}"
group="$(id -g "${user}")"
# Purge unnecessary bloat
for dir in lib/ruby Cellar/go Cellar/gradle Cellar/azure-cli lib/node_modules \
share/powershell Caskroom/fastlane Cellar/ruby opt/AGPM Caskroom Cellar/node \
miniconda Cellar/python@2 Cellar/git lib/python2.7 Cellar/git-lfs Cellar/subversion \
Cellar/maven Cellar/aria2 Homebrew/Library/Homebrew/os/mac/pkgconfig/fuse \
.com.apple.installer.keep microsoft; do
rm -rf "${dir}" || true
done
# Cleanup permissions and attributes
chflags nouchg .
find . -type d -exec xattr -c {} +
find . -type f -exec xattr -c {} +
chown -R "${user}:${group}" ./*
find . ! -path . -type d -exec chmod 770 {} +
# Strip all binaries
find Cellar -name '*' -a ! -iname 'strip' -type f -perm +111 -exec strip {} + &> /dev/null
find Cellar -name '*.a' -type f -exec strip {} + &> /dev/null
@krcroft Yeah, thanks to your beautiful work in dreamer/dosbox-staging#48 it didn't cost me days but just hours. And I'm not even ready. Instead of fixing bugs from clang-tidy or designing a new website for our project I needed to sit and figure out how to get under 400 MiB of individual cache size to not let the build run the double amount of time as on other platforms, till I found your PR by accident due to your posts here.
simonsan
on 21 Nov 2019
@simonsan and @krcroft
Caching apt packages does not seem like a reasonable thing to do as those packages could put binaries all over the file system at that point you may as well cache the entire OS which also does not make sense. The same hold true for brew between where it downloads the packages and where all of the symlinks are created. Doing this, as seen in the example above, requires deep knowledge of each brew package. Even the Travis documentation tells you not to cache apt packages https://docs.travis-ci.com/user/caching/#things-not-to-cache.
We are working on updating the individual filesize to 2GB but in order to do that we had to make some API changes to allow for parallel chunked uploads in order to avoid timeouts.
chrispat
on 21 Nov 2019
We are working on updating the individual filesize to 2GB but in order to do that we had to make some API changes to allow for parallel chunked uploads in order to avoid timeouts.
Thank you 👏
smorimoto
on 21 Nov 2019
Caching apt packages does not seem like a reasonable thing to do as those packages could put binaries all over the file system at that point you may as well cache the entire OS which also does not make sense
Normally one caches the downloaded packages (ie debs in apt's or wheels in pip's case), not the files that get installed from these packages.
 simonvanderveldt
on 23 Nov 2019
simonvanderveldt
on 23 Nov 2019
Normally one caches the downloaded packages (ie debs in apt's or wheels in pip's case), not the files that get installed from these packages.
Yey, that's what I was talking about, didn't have time to answer to that one, till now. In case of vcpkg you're fine to cache $VCPKG_DIR/installed though, in case of homebrew you could also cache /usr/local/homebrew and $HOME/Library/Caches/Homebrew (more Information on this here). Apt and pip you already said.
To make that more obvious and accesible to everyone it would be really cool, to make that as easy as possible, as said above something like:
- name: Cache
uses: actions/cache@v1
with:
directory: |
$GITHUB_WORKSPACE/.bin
~/.ccache
~/Qt
software: |
apt
pip
homebrew
vcpkg
Crosslink: #94
simonsan
on 23 Nov 2019
I think part of this issue could be solved with #55
Let's say you have 3 branches actively developed, one with the original dependencies, one updating the dependencies and one adding a new dependency. By caching all dependencies together, you use 3 times as much cache compared to only having a single branch while caching each dependency separately, you use probably 1.2 times the cache and your individual caches will be smaller. It would also help build times when some of the dependencies change.
Currently if you want to do that, your workflow file will most likely get unreadable and it won't get updated once someone finds an optimization for the same problem in another repository. By allowing caching inside actions, you would just call your "resolve-dependencies" action corresponding to the dependency manager you use and it would handle all the cache management for you and it would get updated when others find better way to handle dependencies.
 Cyberbeni
on 1 Dec 2019
Cyberbeni
on 1 Dec 2019
@joshmgross @chrispat Any updates on this?
smorimoto
on 2 Dec 2019
@imbsky No significant updates
There may be another update soon to up the limit a little (~700MB or so), but as it increases we increase the risk of network timeouts (since it's a single HTTP upload right now).
We're working on updating our API to support chunked uploads which will remove any network issues.
We would still have the 2GB per repo limit until we integrate billing, so there would be some concern about thrashing the cache if the individual limit matched the per repo limit.
joshmgross
on 3 Dec 2019
I see. Thanks for your efforts!
smorimoto
on 4 Dec 2019
My monorepo using Bazel builds both a rust project and a python project and (presumably) caches both the rust compiler and the python interpreter, resulting in a cache of just over a GB (the project is otherwise empty, I'm just setting it up). The per-file limit is disappointing.
Important to note is that bazel also caches test results meaning that bazel only re-runs the code that changes.
 arlyon
on 11 Dec 2019
arlyon
on 11 Dec 2019
Guys, do you have any updates about cache size (single cache)(https://github.com/actions/cache/issues/6#issuecomment-561332267). I have file 500 mb, so the single cache size ~700 MB will be brilliant for me
 IgorKey
on 24 Dec 2019
smorimoto
on 24 Dec 2019
IgorKey
on 24 Dec 2019
smorimoto
on 24 Dec 2019
Just an update, #128 will increase the size limit to the 2 GB repository limit.
We're waiting on some server-side changes to deploy before we can complete that PR. Due to holidays in the US, this will likely be in a couple of weeks.
joshmgross
on 26 Dec 2019
The latest release has bumped the per-cache limit to 2GB to match the per-repo limit https://github.com/actions/cache/releases/tag/v1.1.0
joshmgross
on 6 Jan 2020
Great! Thank you so much!
smorimoto
on 6 Jan 2020
Great! Thank you so much!
 Et7f3
on 6 Jan 2020
Et7f3
on 6 Jan 2020
Closing since the cache limit increase has rolled out. Thanks everyone for contributing to this discussion!
 dhadka
on 7 Jan 2020
dhadka
on 7 Jan 2020
So far, 2GB is enough in my project, but is there any way to increase it? For example, is there a possibility that it will be increased more in the future? (either paid or free)
smorimoto
on 7 Jan 2020
Also, tar is slow. Not caching can be faster in some cases, so we should use zstd. I opened an issue requesting that zstd be installed in each environment by default, but I have received no response.
https://github.com/actions/virtual-environments/issues/89 and https://github.com/actions/virtual-environments/issues/219
smorimoto
on 7 Jan 2020
@imbsky Thanks, I'll follow up with that team. It looks like one of those issues has been assigned so it may be added soon.
joshmgross
on 7 Jan 2020
@imbsky tar is not slow, it does no compression or compaction, it's fairly identical to files stuffed end to end with a header. Usually gz or so is then used to compress that single file (often on the stream that tar directly outputs so it really becomes basically no-cost), and compression is the slow part.
OvermindDL1
on 7 Jan 2020
Yeah, you're right. I meant "the current implementation calling the tar command is slow".
smorimoto
on 7 Jan 2020
2GB seems relatively enough when running tests on only one operating system, but when running tests on three operating systems, 2GB is not enough and feels like a lot of cache is wasted each time. What do other people think?
smorimoto
on 8 Jan 2020
Also, this is an issue that the cache limit is not enough, and I feel that this issue should not be closed just because cache actions can handle huge sizes. Because the two problems are completely different.
smorimoto
on 8 Jan 2020
@chrispat Can you please comment on @imbsky's questions above regarding cache limits (if we have any plans to increase beyond the new 2 GB limit or offer a paid tier?)
dhadka
on 8 Jan 2020
2GB seems relatively enough when running tests on only one operating system, but when running tests on three operating systems, 2GB is not enough and feels like a lot of cache is wasted each time. What do other people think?
Yes. We cannot cache the large and time-consuming Clang installation on macOS using MacPorts because it will evict our even heavier and more time-consuming Clang caches under 32bit and 64bit MSYS2 (native install is ~15 min vs 2 min to extract from cache).
Also, all three of the above /would/ fit if @joshmgross had access to use zstd on the VMs (+1 hoping the VM team adds it across the board!); but until then or a higher limit we can only cache two items.
kcgen
on 8 Jan 2020
@imbsky we are collecting data on cache usage across the service and evaulating that to determine of we can raise the individual repo limits. As far as paid options go, we already have paid storage of artifacts and we are looking at including cache storage as part of that overall offer.
chrispat
on 9 Jan 2020
I see! That sounds good. 2GB is definitely better than before, so I will wait for a little more.
smorimoto
on 10 Jan 2020
As far as paid options go, we already have paid storage of artifacts and we are looking at including cache storage as part of that overall offer.
Is there any news on that?
We are building a Rust project across 3 operating systems and each one would need a cache of 1.7GB. Meaning the caches invalidate themselves constantly, resulting in them not being useful.
 thomaseizinger
on 1 Jul 2020
thomaseizinger
on 1 Jul 2020
I just opened this as a new discussion. It may change if there are many demands. https://github.com/actions/cache/discussions/497
smorimoto
on 4 Jan 2021
Related issues
 jwt27
·
3Comments
jwt27
·
3Comments
 Fatme
·
3Comments
Fatme
·
3Comments
 Cerberus
·
5Comments
Cerberus
·
5Comments
 jcornaz
·
4Comments
jcornaz
·
4Comments
 s-weigand
·
5Comments
s-weigand
·
5Comments
Most helpful comment
The latest release has bumped the per-cache limit to 2GB to match the per-repo limit https://github.com/actions/cache/releases/tag/v1.1.0