Bull: Question: may a jobId related key exist and jobId:lock key be absent?
Hi.
The question: if some key bull:xxx exists in Redis, does this mean that bull:xxx:lock key must also always exist there? (Assuming removeOnComplete: true, removeOnFail: true usage.) Or not necessarily?
Context: we're using queue.add({..., jobId: xxx, removeOnComplete: true, removeOnFail: true }) feature to prevent jobs double-scheduling. And sometimes a job gets stuck completely (although finished long time ago), because its jobId related redis key is in the database, but there is no corresponding jobId:lock key there. Such jobs are also invisible in Arena; the only way to see them is to do redis-cli KEYS "bull:*" | grep ... and search for keys which have no :lock coupled.
Also, if I run hgetall for such "orphaned" keys, the output looks like:
1) "failedReason"
2) "Missing key for job abb18569499f62ab finished"
3) "stacktrace"
4) "[\"Error: Missing key for job abb18569499f62ab finished\\n at Object.finishedErrors..."
5) "attemptsMade"
6) "1"
I've seen similar symptoms mentioned here in Issues many times, but I couldn't find a resolution. So I just think about brute-force scanning through all bull keys every minute, finding the ones which look "suspicious" (i.e. have no :lock counterparts and also have failedReason), then removing them entirely.
 dko-slapdash
dko-slapdash
All 27 comments
No, this error is not related to lock key. Lock keys have TTL (default 30 secs) and removed automatically. Existing lock key is used as evidence of that some worker is processing a job.
Looks like moveToFinished-6.lua script called twice, first time it removes job key, and second time it fails with job key missing error, then new job key is created to persist that error.
 stansv
on 5 Aug 2019
stansv
on 5 Aug 2019
I see. It kinda prevents this job from restarting (despite removeOnComplete/removeOnFail), because it occupies the key.
dko-slapdash
on 5 Aug 2019
Here is a piece of code I had to run periodically as a hacky work-around:
UPDATE: DON'T DO THIS! It can remove the keys for healthy jobs if they were double-scheduled. See explanations (and solution) below.
async function bullRemoveStuckKeysHack(
redis: Redis,
logger: (text: string) => void
) {
let cursor = 0;
for (;;) {
const [newCursor, keys] = await redis.scan(
cursor,
"MATCH",
"bull:*",
"COUNT",
1000
);
await mapJoinSafe(keys.filter(k => !k.match(/:lock$/)), k => processKey(k));
if (newCursor == "0") {
break;
}
cursor = parseInt(newCursor);
}
async function processKey(key: string) {
const type = await redis.type(key);
if (type == "hash") {
const value = await redis.hget(key, "failedReason");
if (value && value.match(/Missing key|Missing lock/)) {
logger(
"Deleting bull job stuck key " +
key +
" due to unhandled error: " +
value
);
await redis.del(key);
}
}
}
}
Looks good, It should work as long as only Bull can produce such message pattern to fill error. But I think you're safe enough with this check.
stansv
on 5 Aug 2019
So it seems that for some reason the same job was processed twice, and as @stansv mentioned the second time it tries to move to finish it fails because it was already moved (and removed) by another worker. The only way this could happen (that I know of), is if a worker hangs for too long with a synchronous operation (keeping the event loop busy), and therefore the job is moved back to the waiting list and picked up by another worker. In this case you will have 2 workers working on the same job at the same time. If this is the case, please make sure that the workers do not perform CPU intensive tasks for too long, so that node has a chance to update the stalled jobs set in time.
 manast
on 6 Aug 2019
manast
on 6 Aug 2019
@manast, but IMO that means that at least one of moveToFinished calls is done with ignoreLock. Otherwise this script can only alter job state once.
stansv
on 6 Aug 2019
We are seeing this a lot on our redis cluster. Any way we can validate that indeed moveToFinished-6.lua is being called twice and get a fix in? We are running "bull": "3.10.0"
 dwisecup-cs
on 7 Aug 2019
dwisecup-cs
on 7 Aug 2019
@dwisecup-cs so the error emitted is the actual check we have now :). It is better to understand why this happens in the first place.
manast
on 8 Aug 2019
@manast The only theory provided was that it was being called twice (one without the lock file). My question was if we could verify that is indeed what is happening. Right now it breaks our queueing system from making any forward progress. Should I open a bug?
dwisecup-cs
on 8 Aug 2019
this is just a symptom to a problem. Checking if moveToFinished has been called twice (btw, I do not know how that could be done) will not solve the issue, we need to understand how we got into this situation in the first place. I gave a theory above. If you have a way to consistently reproduce the issue you can fill an issue, otherwise it will be quite difficult for us to fix it.
manast
on 8 Aug 2019
Yeah, it's intermittent on our end so repo may be difficult. "CPU intensive tasks for too long" about how much is too long? Then I can attempt to set up a scenario.
dwisecup-cs
on 8 Aug 2019
If you use any task that blocks the event loop for a few seconds you should try to run the workers in a separate process, for example by using sandboxed processes.
manast
on 8 Aug 2019
What's strange is that such stuck keys (with errors) are not shown in Arena. They're also not returned by bull API, so there is no way to locate them programmatically, through Bull. I think this is not expected anyway, right?
dko-slapdash
on 8 Aug 2019
that is because they have been removed from the completed/failed set and only the job itself is left.
manast
on 9 Aug 2019
I have meet this problem too. Queue#getJobs cannot get it, and Queue#add doesn't add a job to process.
 zyf0330
on 30 Aug 2019
zyf0330
on 30 Aug 2019
@manast, is there a way for a stalled worker process (after it unstalled eventually) to periodically check, is someone else running somewhere and, if yes, kill itself? I.e. if someone else took over the job due to a blocked event loop of the previous worker, the original worker must terminate itself. It's like heartbeats or STONITH concepts.
Regarding the topic, in our case it indeed happens due to a stale event loop (we don't know who's blocking the event loop though - seems like it's garbage collector or internals of some unknown library). Very hard to reproduce and to profile this, I approached a few times.
To detect the stale event loop, we run the following code:
const CHECK_INTERVAL = 5000;
const THRESHOLD = 2.0;
for (;;) {
const timerStale = timeSpan();
await delay(CHECK_INTERVAL);
const dt = timerStale.rounded();
if (dt > CHECK_INTERVAL * THRESHOLD) {
loggers.worker.log(
"STALE EVENT LOOP: expected %d ms, but spent %d ms",
CHECK_INTERVAL,
dt
);
}
}
Sometimes (rarely) we see that delay wakes up not in 5 seconds as expected, but in 2-10 minutes (!).
My point is that, even if something blocked event loop, in an ideal world this must not prevent the job with the same key from being re-injected in the future, and it must not be invisible in Arena.
dko-slapdash
on 14 Sep 2019
...actually, it may be something else too. Here is a chart (number of log lines from the worker per 5 second) which shows that the job was picked up by worker00 in 15 seconds after it was picked up by worker01.
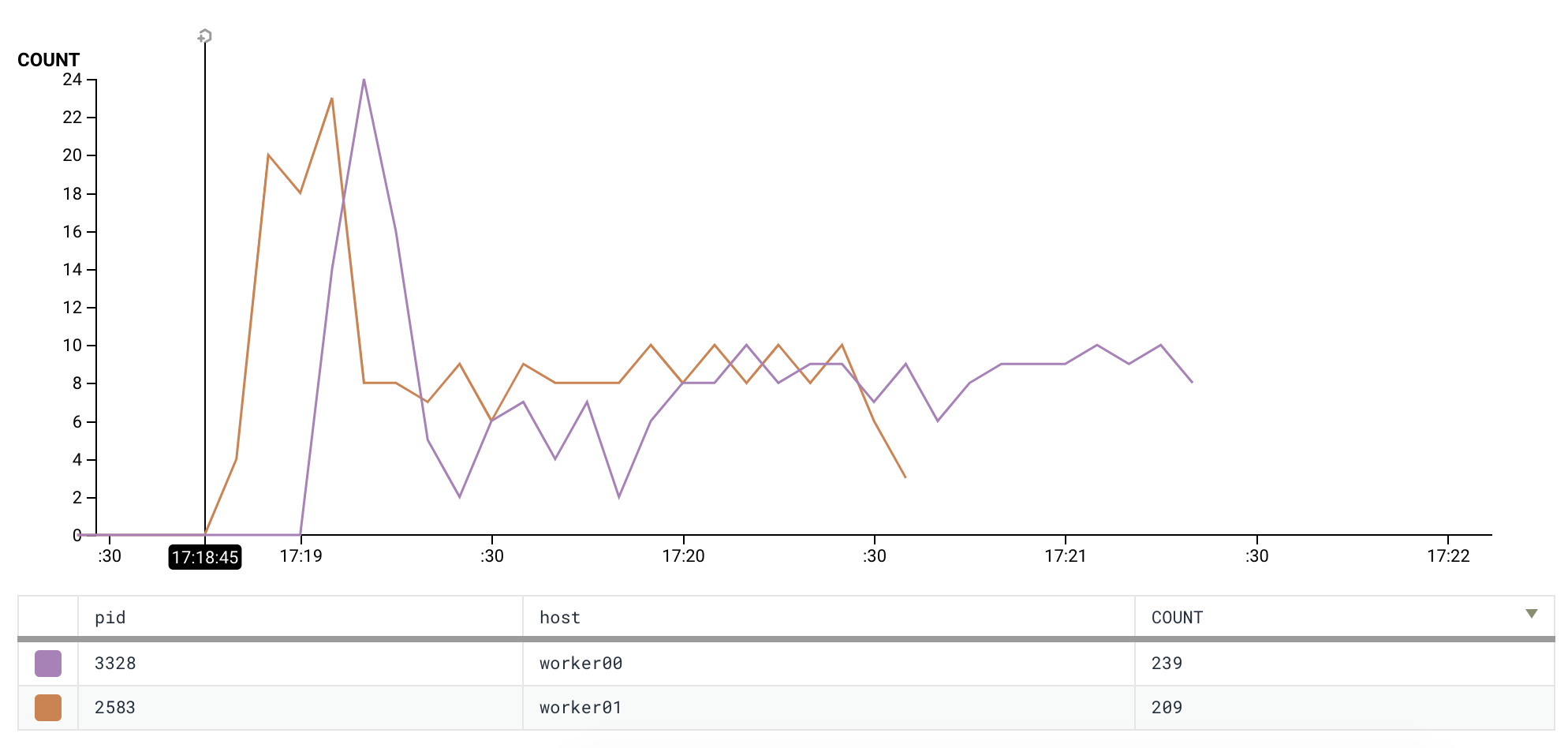
What's funny is that we have lockDuration=stalledInterval=5*60*1000 (i.e. 5 minutes) - way more than 15 seconds.
How could this happen at all? There was indeed enough time to refresh the lock.
bull:index-app-full:5fae49880c2e88d6
1) "name"
2) "__default__"
3) "data"
4) "{\"id\":\"1000148966982951722\",\"title\":\"\"}"
5) "stacktrace"
6) "[\"Error: Missing lock for job 5fae49880c2e88d6 finished\\n at Object.finishedErrors (/srv/slapdash/server/node_modules/bull/lib/scripts.js:182:16)\\n at job.queue.client.moveToFinished.then.result (/srv/slapdash/server/node_modules/bull/lib/scripts.js:169:23)\\n at <anonymous>\\n at process._tickCallback (internal/process/next_tick.js:182:7)\"]"
7) "opts"
8) "{\"priority\":20,\"jobId\":\"5fae49880c2e88d6\",\"removeOnComplete\":true,\"removeOnFail\":true,\"attempts\":1,\"delay\":0,\"timestamp\":1568420330698}"
9) "processedOn"
10) "1568420347579"
11) "stalledCounter"
12) "1"
13) "failedReason"
14) "Missing lock for job 5fae49880c2e88d6 finished"
15) "timestamp"
16) "1568420330698"
17) "priority"
18) "20"
19) "delay"
20) "0"
21) "attemptsMade"
22) "1"
What we maybe do differently for such job is that we re-add it regularly assuming that if the job is running somewhere right now, this queue.add() will be a no-op, and if it's running, then it will start:
queue.add(input, {
jobId: "5fae49880c2e88d6",
removeOnComplete: true,
removeOnFail: true
})
Can it somehow explain why the job was picked up twice on two different machines (although lock intervals are way higher than defaults)? Maybe queue.add() works not the way I expect, and it's not a no-op if the job with same id is already running?
dko-slapdash
on 14 Sep 2019
it is a no-op if a job with the same id exists at the moment you add it to the queue.
manast
on 14 Sep 2019
@manast, I spent half-day today learning Bull code, and here is what I found.
In short: the internally called Job._saveAttempt() updates failedReason field of the job key blindly, without checking if the current process is still the one "owning" the job key.
So we must never delete the keys having e.g. "Missing lock for job" in failedReason (as in the snippet above), else we risk to remove the job key for some really alive and healthy job (which was double-scheduled following a loss of lock in the previous process).
- Some job starts and runs happily in process $1, but even look gets stuck for some long period of time, so it loses its lock key.
- moveStalledJobsToWait-7.lua (runs periodically) finds that its key has a missing lock and thus moves the job to waiting list (maxStalledCount=1 by default).
- The job is immediately picked up by another worker process $2 (from waiting), so now we have two processes running the same job.
- Process $1 finishes successfully. It tries to move the job to finished state, but moveToFinished-6.lua realizes that the lock belongs to another process $2 (since it compares the lock value with queue.token internally).
- So process $1 fails and calls Job._saveAttempt() which writes stacktrace+failedReason field to the job key, but this job key logically belongs to process $2, not to $1 (overriding its failedReason if it was there BTW)!
- And when process $2 finishes too, we have both returnvalue and failedReason in the main job key. Total mess.
I see some kind of protection in the code regarding this "ownership" (comparison of the lock value with queue.token), but _saveAttempt() doesn't respect queue.token (it always updates/overrides no matter what), and also queue.token has the same value within Node process, so most likely it's there for some different purposes, not for ownership protection.
P.S.
I now experiment with setting settings.maxStalledCount=0 and also with removeOnComplete=removeOnFail=true; unfortunately removeOnFail doesn't suppress the jobs failed with "job stalled more than allowable limit" error from moveStalledJobsToWait-7.lua, so I also have to run queue.clean(0, "failed") to make sure there are no keys stuck in failed state.
dko-slapdash
on 16 Sep 2019
@dko-slapdash thanks for the throughout analysis. This hazard has been known for a while, but has not been prioritised in the believe that it happens so seldom that it is not that harmful.
So it seems to me the biggest problem is that in step 5 the job worker that has lost the lock should not fail, just realize it has lost the lock and do not try to store any other state on the queue.
In Bull 4.x we have even got rid of the locks, since I have been suspecting for a long time that they may not be needed. However, the case you are reporting could also happen. I am not sure how to handle this correctly, maybe as Promise.race(), where the first worker that actually completes the job is the one that wins and the other ones just will ignore the result when they complete, not ideal, but I am not sure how to solve this in a better way.
manast
on 16 Sep 2019
The classical way this topic is solved in other projects is called "heartbeats": workers time to time (e.g. once every 10 seconds) send a message to the queue broker (redis) and analyze the response: if the response says that someone else took over the job (worker id is different than response id), the worker kills itself. Such heartbeats are pretty cheap in terms of network/perf since they're batched across all workers on the same machine.
Another way is to rely on TCP connection with keep-alives: if it's active, then the workers behind this TCP connection are alive, if not - both workers die and jobs are released. But redis doesn't have support for it AFAIK, so the only way to do heartbeats is through auto-expirable locks.
Locks in the current version of Bull are similar to the heartbeats, the difference is that there is no "worker unique id" concept, and there is no way to propagate a "broken" heartbeat back to the worker.
I suspect you guys (the main developers of Bull) use Bull with auto-generated jobId in your primary products, and maybe with very short-lived jobs only. That's why the problems appear when jobId is custom, and jobs are long-lived.
dko-slapdash
on 16 Sep 2019
yes, I acknowledge that we need a unique token per concurrent worker in order to get it right, but the biggest problem I see is that the worker that has stalled cannot currently "kill himself" so that you do not end having several semi-stalled jobs running in parallel causing issues as the one you described above. Using sandboxed processes we could actually kill the process running the worker, with whatever trade-offs that may have. The other alternative I have been thinking is that the lock renewal procedure can be changed so that instead of being done automatically by the worker must be done explicitly by the user code handling the job, this will move the responsibility to the user of the library, which is how SQS in AWS works for example... but one of the wining features in Bull is ease of use, so I am not sure yet what is the best solution.
manast
on 17 Sep 2019
another idea could be to use a RXJS stream instead of promises in the worker, such that the stream can be cancelled gracefully externally, but the worker code will not be as clean as when using await/async...
manast
on 17 Sep 2019
Ultimately I think that a good solution would be to provide a cancellation token as input parameter to the processor function, this token will have a status method for checking if the job has been cancelled or not (could be due to being stalled or maybe a TTL setting), also will be an event emitter so it can also be used to listen to the cancelation event. The user will be able to freely respond to this token the way he sees fit, however, when the worker completes, the token is checked and if the job has been cancelled, the job is just ignored and will not try to modify anything in the queue.
manast
on 17 Sep 2019
OK, so THE SOLUTION (more a work-around) which worked is following.
The problem
I once a minute inject a job with some CONSTANT jobId=1234, removeOnComplete=true, removeOnFail=true via queue.add(...). Sometimes, presumably when event loop is blocked for a long time (why is it blocked is unclear in my case, and the time is unpredictable), this job becomes "stalled", so Bull starts it again implicitly, while the previous job "process" is still running. I.e. we have 2 workers running the same job.
When this happens, the main redis key of the job eventually gets stuck in redis: the job becomes invisible in Arena, and queue.add() for it becomes a no-op. An error inside the redis key (if I do HGETALL for it) is either "Missing key for job" or "Missing lock for job".
The work-around
- Set maxStalledCount=0 in queue constructor's
settingsparameter. This disables Bull to implicitly rerun the job when it becomes stalled, and this is VERY important. - Run
queue.clean(0, "failed")time to time in some background script. Having justremoveOnFail=trueis NOT enough, since the stalled job will anyway be moved to the failed list, independently on removeOnFail. - Make sure you don't run queue.clean() in multiple processes in parallel. I'm not 100% sure that it helped in my case, but I have a strong suspect that it did. I was previously running queue.clean() for ALL my queues in ALL worker processes, and it was baaaad. After I started doing queue.clean() in just ONE process (in addition to 1 and 2), the problem with stuck job key disappeared.
dko-slapdash
on 21 Sep 2019
this seems like an insane work-around, lets create an issue with the bug report and we can fix it properly.
manast
on 22 Sep 2019
Related issues
 thelinuxlich
·
3Comments
thelinuxlich
·
3Comments
 pigaov10
·
3Comments
pigaov10
·
3Comments
 davedbase
·
3Comments
davedbase
·
3Comments
 rodrigoords
·
4Comments
rodrigoords
·
4Comments
 inn0vative1
·
4Comments
inn0vative1
·
4Comments
Most helpful comment
Ultimately I think that a good solution would be to provide a cancellation token as input parameter to the processor function, this token will have a status method for checking if the job has been cancelled or not (could be due to being stalled or maybe a TTL setting), also will be an event emitter so it can also be used to listen to the cancelation event. The user will be able to freely respond to this token the way he sees fit, however, when the worker completes, the token is checked and if the job has been cancelled, the job is just ignored and will not try to modify anything in the queue.